
改进的HOG和SVM的硬笔汉字分类算法
2022-08-16 03:11肖爱迪骆力明
计算机工程与设计 2022年8期
肖爱迪,骆力明,刘 杰
(首都师范大学 信息工程学院,北京 100048)
0 引 言
传统的基于图像处理的汉字分类算法[1]分为3类:①基于汉字特征点标注的分类方法,该方法充分利用了汉字的端点、折点、交叉点、T形拐点等信息,但汉字分类的准确性依靠特征点标注的准确性[2];②基于汉字骨架特征的相似度计算方法,该方法利用图像的骨架、不变矩、灰度投影等方法对汉字进行特征描述,再结合相似度计算方法,根据差异区间实现汉字等级分类,但汉字细化过程中可能形态发生微变,引入新的毛刺[3];③基于汉字结构特征的重叠模糊规范化双弹性网格划分方法,该方法在双弹性网格中采用8邻域模糊化特征方法,增加了特征间的相关性,但特征类间类内方差计算量大,提取速度较慢[4]。
针对以上问题,本文提出一种改进的分层HOG特征提取方法,在特征块无重叠遍历的前提下,均匀提取汉字网格特征,再分层统计2×2区域内的特征边缘信息。该方法在保证特征稳定提取的同时,有效降低维度。该算法再采用SVM作为分类器,实现中小学汉字分类评价。实验结果表明,提取的特征稳定、维度适中且分类准确率较高。
1 算法介绍
1.1 HOG特征提取
1.1.1 传统HOG特征提取
方向梯度直方图(histogram of oriented gradient,HOG)是一种计算并统计图像局部区域的梯度方向直方图来表示图像特征的方法[5]。HOG表达的是图像形状信息分布,通过分割、统计、整合细胞单元(cells)内的直方图构成图像特征描述子。与其它特征描述方法相比,HOG提取的特征不仅稳定,而且对汉字轮廓信息有较好的体现。
HOG特征提取的详细步骤如下:
(1)Gamma校正,调节图像亮度的不均匀性,降低汉字图像阴影和光照变化所带来的影响[6]。本文采用的是一种非线性的Gamma校正方法,如式(1)所示
g(I)=Iγ
(1)
其中,I是指图像中某点的像素值,g(I)为转化后的像素值,γ为Gamma值。当γ<1时,提高了低灰度值区间的像素对比度,汉字框架呈现暗灰色;当γ>1时用于增强高灰度值区间的对比度,突出体现汉字整体结构特征。
(2)梯度计算。获取水平方向和垂直方向的梯度分量是获取HOG特征的前提条件。通过水平方向模板k=[-1,0,1] 和垂直方向模板k=[-1,0,1]T对原图像做卷积运算,得到水平、垂直方向的梯度。如式(2)~式(5)所示
Gx(x,y)=Pixel(x+1,y)-Pixel(x-1,y)
(2)
Gy(x,y)=Pixel(x,y+1)-Pixel(x,y-1)
(3)
(4)
θ(x,y)=arctan(Gx(x,y)/Gy(x,y))
(5)
式中:Gx(x,y)、Gy(x,y) 分别表示水平、垂直方向的梯度,Pixel(x,y) 表示图像在 (x,y) 点处的像素值。V(x,y)、θ(x,y) 分别表示像素点(x,y)处的梯度幅值和夹角。如图1(a)、图1(b)中分别代表HOG下的沿x、y方向的梯度图。图1(a)中突出描述汉字的垂直特征,对竖、斜竖笔画提取较好,图1(b)中则重点突出了水平方向特征。
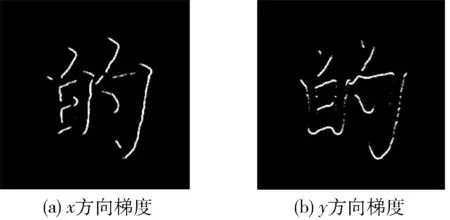
图1 图像梯度
(3)构建细胞梯度直方图并组合形成块(block)。HOG特征提取的最小处理单元是细胞(cell),将图像划分为若干个cells,将多个cell组成block,用block来表示汉字图像的局部区域。HOG将梯度方向等分为9个bin梯度,梯度大小作为投影的权值。
(4)区间特征归一化。由于block间存在特征间的重叠提取,局部光照变化不均等现象。因此,特征归一化就尤为重要。采用L2范式作为归一化公式,如式(6)所示
(6)
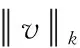
在传统算法中,若利用一个128×128像素窗口(window),以8个像素为步幅长度扫描,以8×8个像素为一个cell,形成了16×16=256个cells,将4×4个相邻的cells视为一个block,那么,一张图片包括13×13=169个像素块,梯度方向为9,故得到HOG特征向量的维数为:4×4×169×9=24336维。不难发现,传统HOG汉字特征提取时特征维度是巨大的。
1.1.2 改进HOG特征提取
基于1.1.1节的分析,不难看出HOG针对汉字特征提取时存在特征维度过大的现象,原因是HOG特征提取时会出现特征块重叠现象,由此造成特征块数量增加,每个块中都包含多个9梯度的cells特征直方图,由此导致了最终特征维度过大。为了解决该问题,参考汉字中基于网格技术的特征提取算法[7],提出改进的HOG特征提取方法。
基于网格的分层HOG特征提取方法。在汉字网格划分的思想下,优化HOG特征提取中出现的特征块重叠现象,利用HOG算法将一张汉字图片分成多个相同的无交叉区域,统计每个区域的方向梯度直方图,这种方法虽能解决特征块重叠现象,但会导致图像出现网格边缘化问题,即在网格分隔区域内出现特征断裂现象。
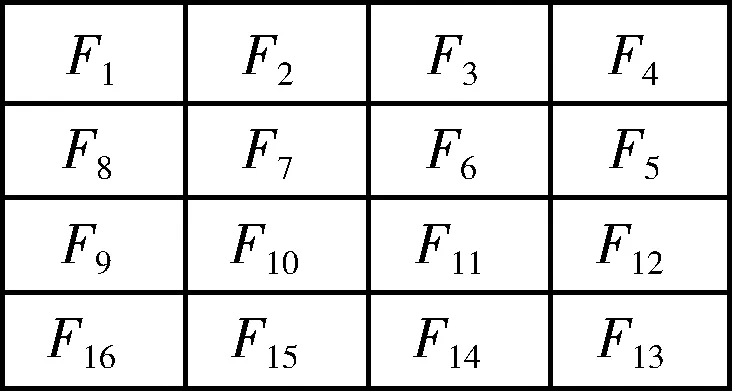
图2 网格特征
针对网格边缘化问题,本文增加一个底层HOG特征提取层,将图像分为4个cell区间,每个cell有9个bin通道,故底层产生36维特征向量。本文考虑以下3种网格划分方式,有针对网格面积相同的均匀网格划分如图3(a)所示,有根据汉字图像中的45°和135°方向上的对角密度的网格划分如图3(b)所示,还有以汉字结构特点的重心为圆心形成的圆形网格划分如图3(c)所示。
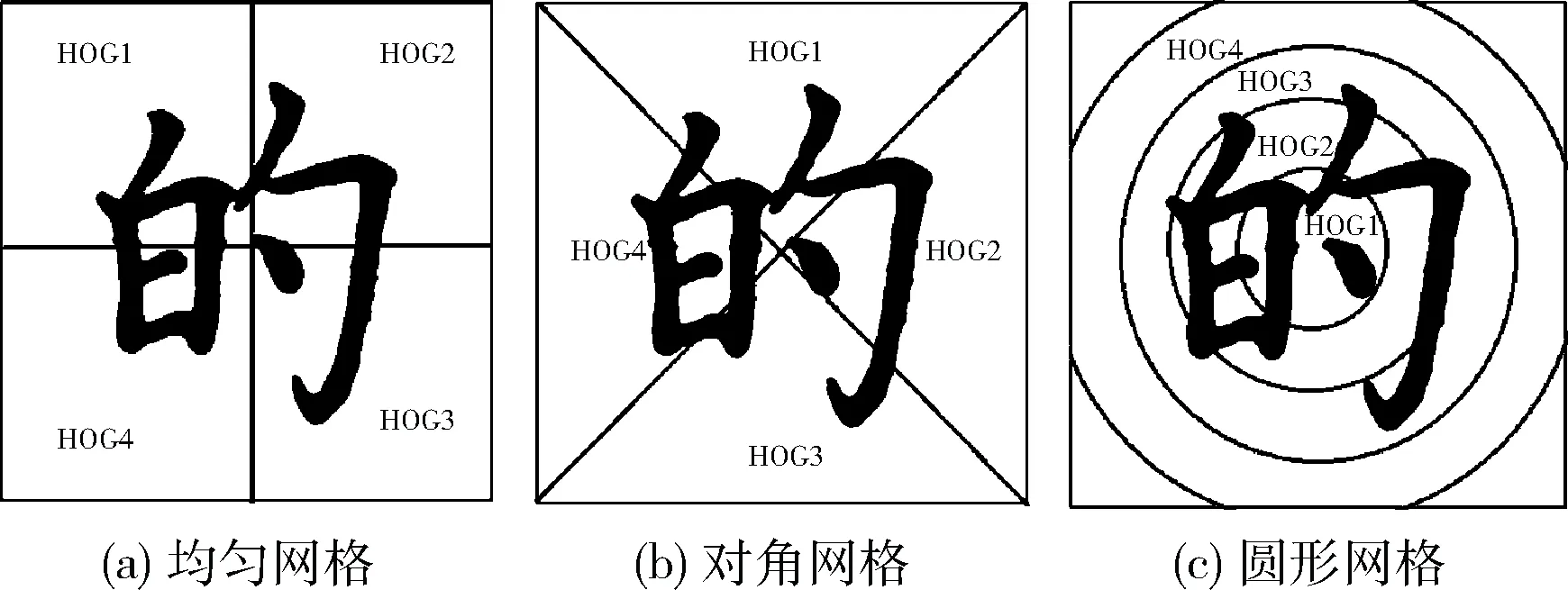
图3 四区域网格划分
底层HOG特征提取拟采用均匀网格的形式,相比于其它两种划分方式,均匀网格划分的特征更符合汉字的结构特征,特别是对于汉字左右部件划分较明确,所产生的网格边缘干扰也是最小的。对角网格虽能稳定提取特征,但产生的网格边缘干扰也较多。圆形网格提取特征不符合汉字结构特征,对“横”“竖”“撇”“捺”四笔画方面保留效果是最差的,同时产生了更多的网格干扰信息。
本文提出的基于网格的分层HOG提取汉字特征方法,可有效降低汉字维度,减少网格边缘化现象。
算法步骤如下:
步骤1 将尺寸为128×128的汉字图像以32×32的像素邻域网格作为采样窗口,以无重叠的方式遍历整个汉字图像,由此将一张汉字图像分成了4×4个block,共计16个网格。由于网格的引入,造成了图片在网格处边缘化现象,给整个汉字轮廓特征带来了干扰信息。
步骤2 引入底层的HOG特征提取向量,其提取采用类似步骤1的方法,将图像划分为均匀分布的2×2个网格单元,分别统计每个网格单元中的特征向量。然后,将两层的特征向量相加,形成了分层次的HOG特征。再通过水平模板[-1.0,1]和垂直模板[-1,0,1]T来计算分层HOG的梯度方向和幅值。
步骤3 根据0°~180°的区间划分为9个梯度通道来计算各层网格区域的梯度直方图,并整合两层的特征梯度直方图。
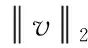
步骤5 将归一化后的直方图向量组成一个n×m的矩阵用于表示汉字图像的HOG特征,其中n为网格内直方图的向量维数,m为整个汉字图像所要计算的网格个数。
基于改进的HOG特征计算步骤如图4所示,结果表明,改进算法将原本24 336维特征缩减为2340维。因此,该算法可有效解决汉字特征提取时维度过大的问题。
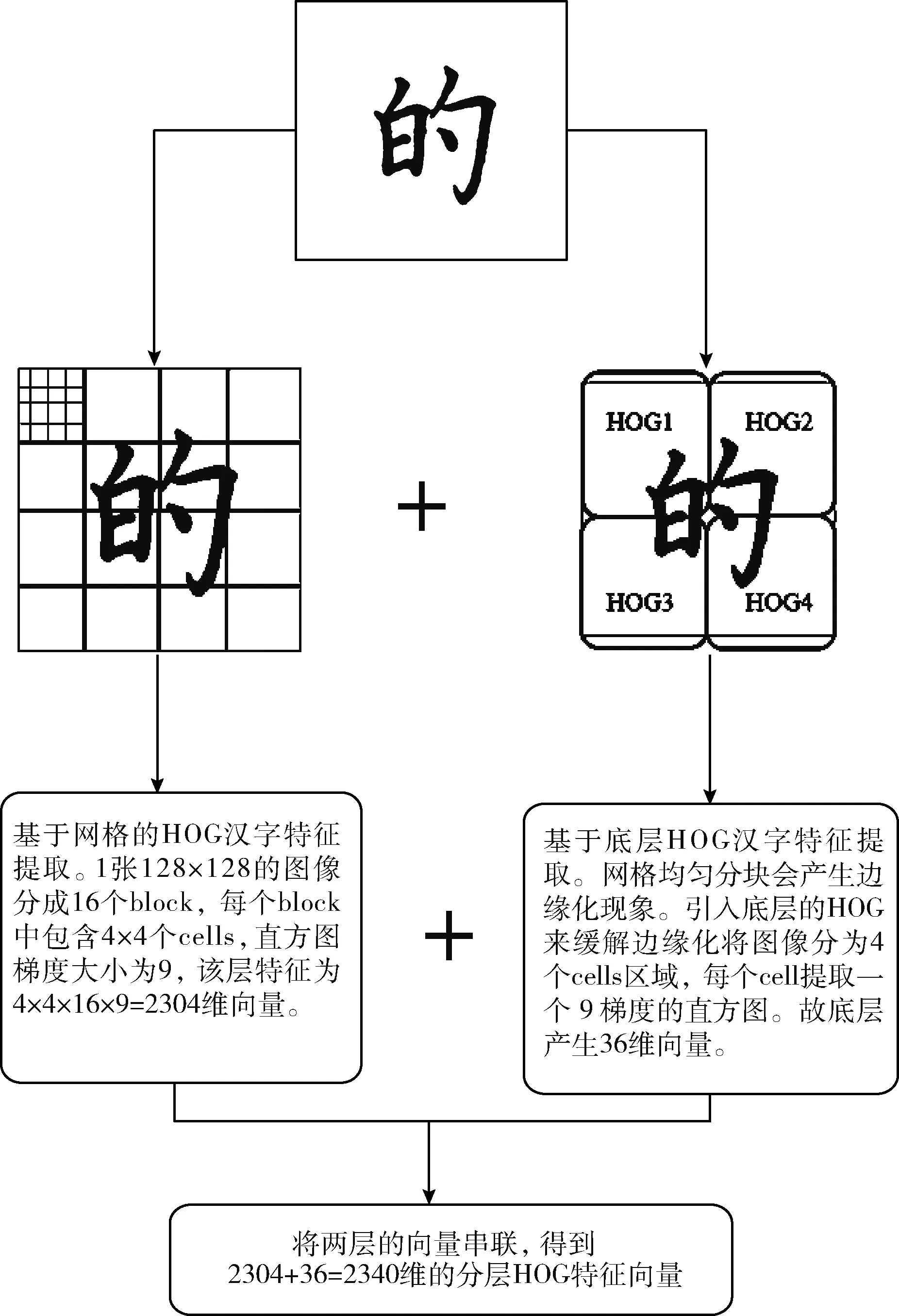
图4 基于网格的分层HOG特征计算步骤
1.2 特征降维
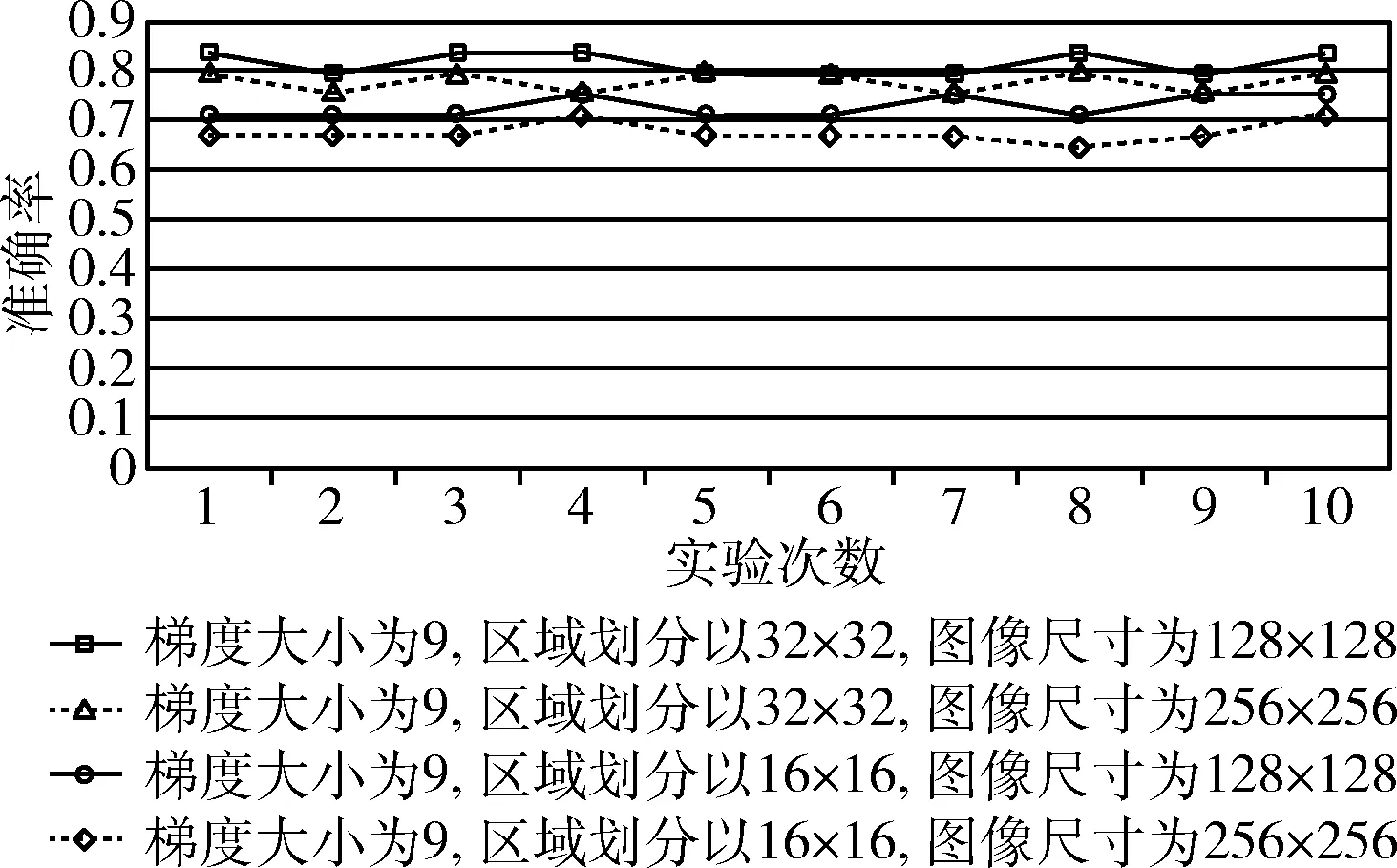
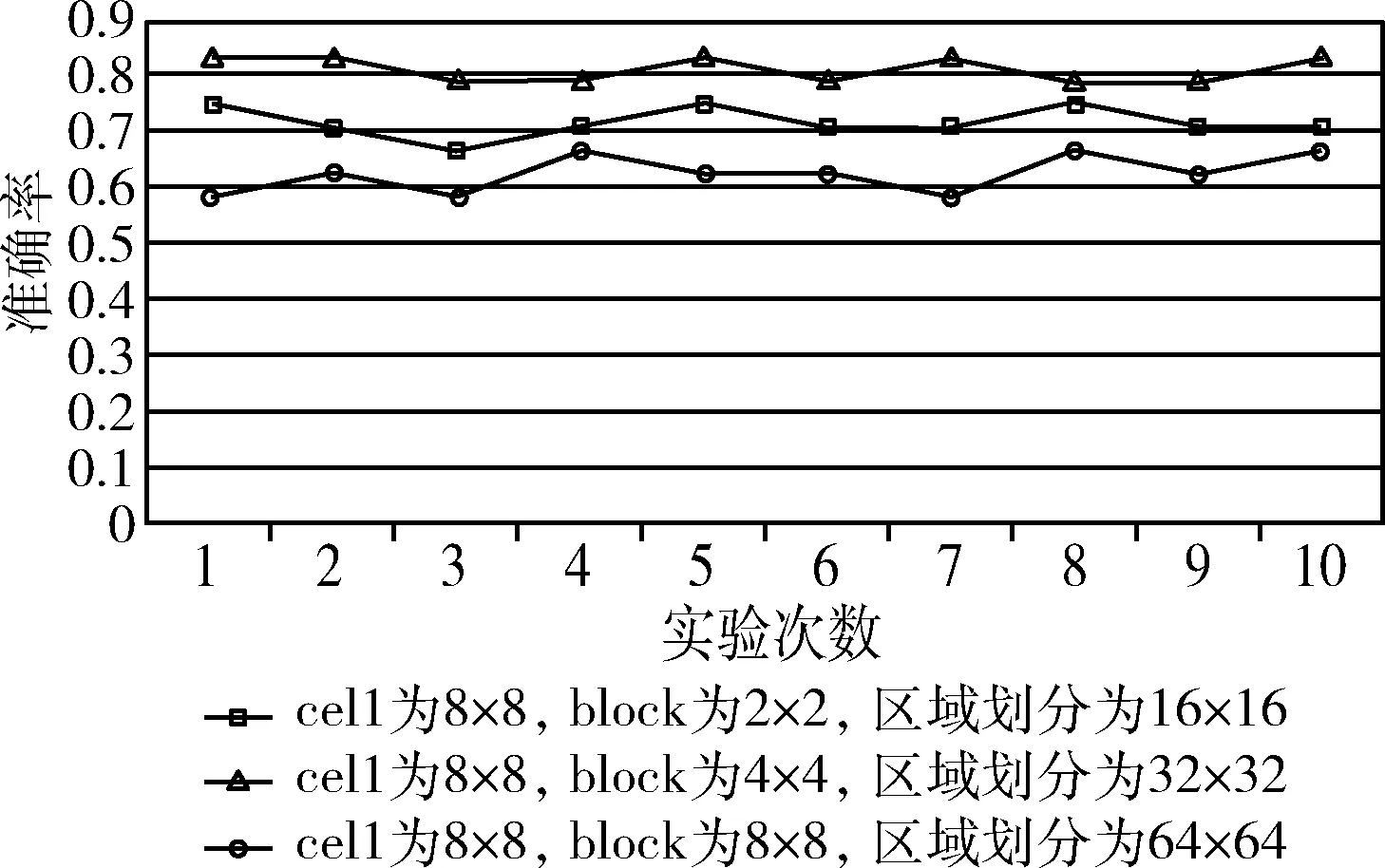
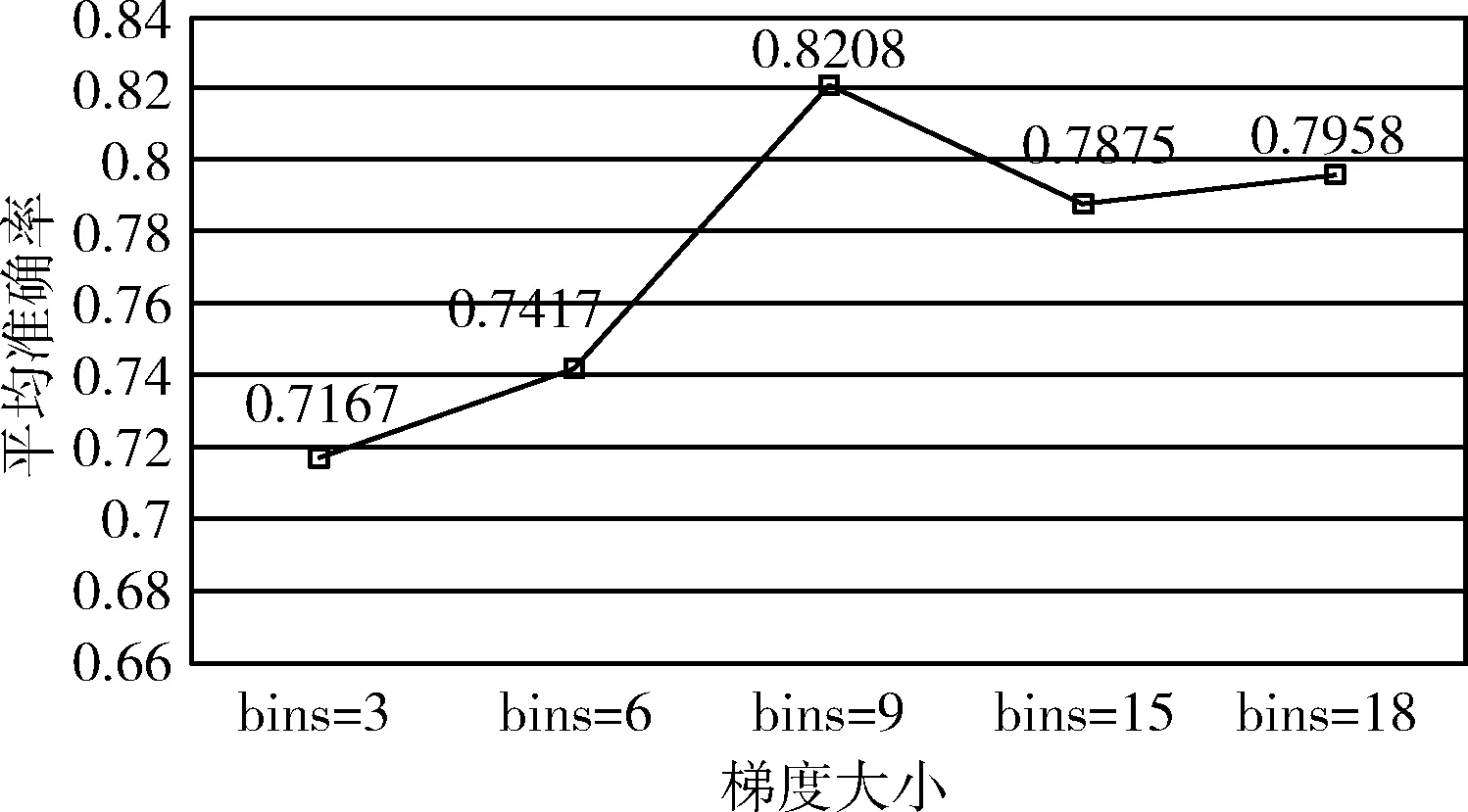
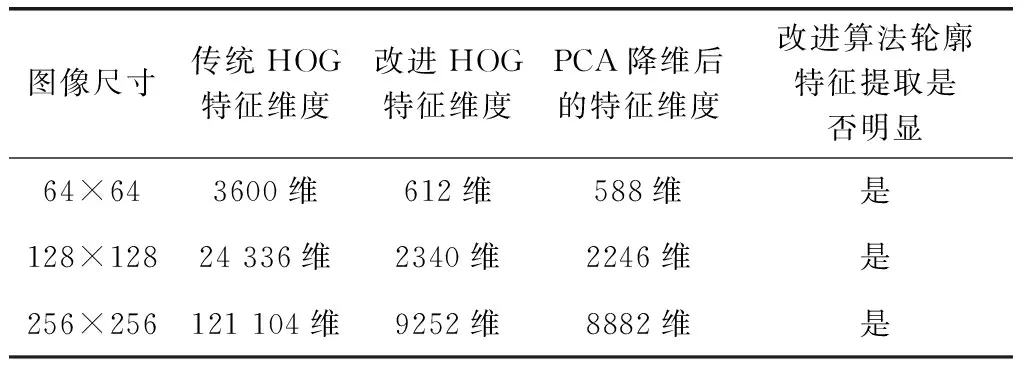
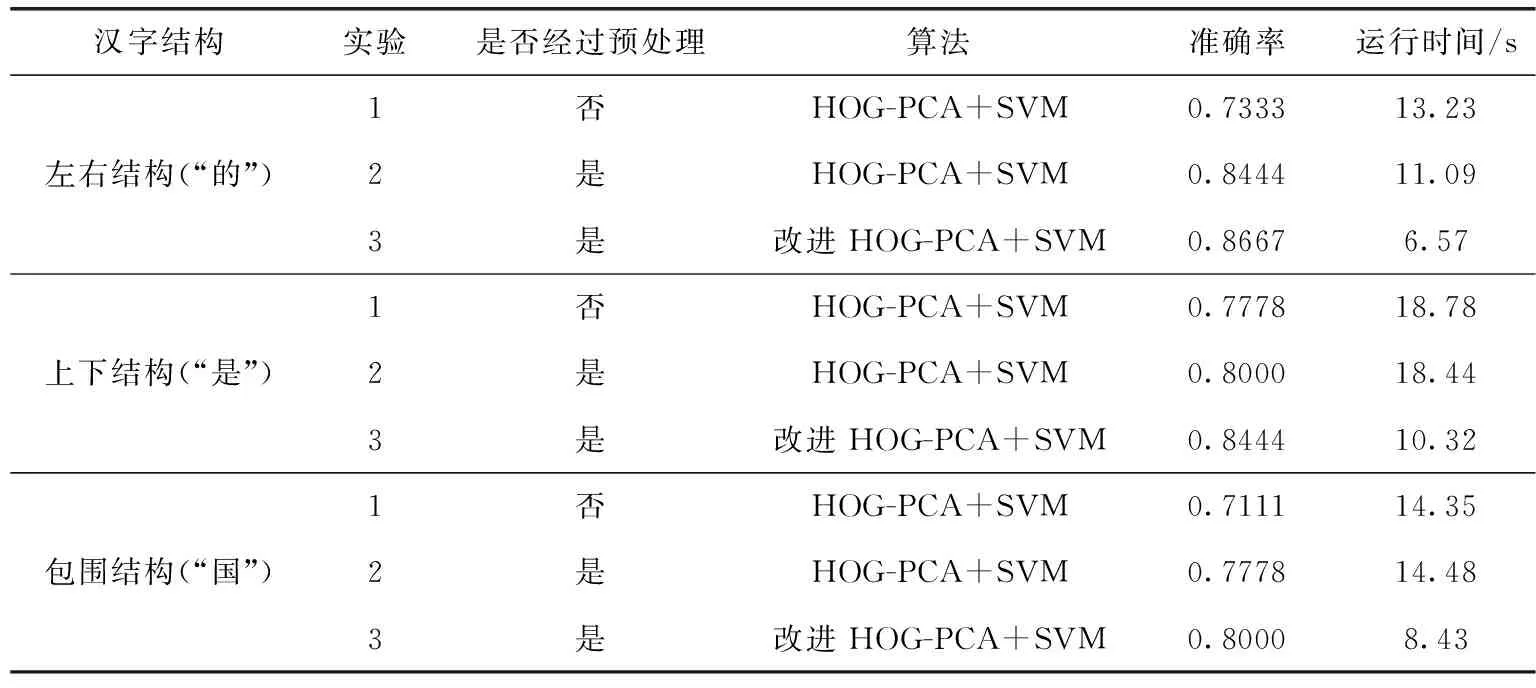
采用基于网格的分层HOG特征提取后,汉字图像维度得到了有效的降低,但图像中的冗余信息和无关信息的干扰依旧存在。因此,特征降维就至关重要。主成分分析(principal components analysis,PCA)是对特征信息处理、压缩和抽提的方法,将n维特征映射到k维上(k 假设I(x,y) 是大小为N×N的一幅汉字图片,将其每一列相互连接,组成一个N2维度的向量。假设有m张汉字训练样本图片,样本集可以表示为 {xi∈RN×N,i=1,2,…,m}, 其中xi表示第i幅汉字图像所构成的列向量,将所有的汉字样本训练图像按列排成特征矩阵X,汉字图像的均值向量η记为式(7) (7) 则所有训练样本的协方差矩阵Sτ为式(8) (8) 令A=[x1-η,x2-η,…,xm-η], 有Sτ=AAT, 其维数为N2×N2,又令P=ATA, 矩阵Sτ的特征向量为μi,P的特征向量为vi,则需计算Sτ矩阵的非零特征值对应的特征向量,但由于协方差Sτ的维度过大,需采用奇异值分解定理[9],μi和vi满足式(9),归一化特征为式(10) μi=Xvi (9) (10) 期望特征向量与总特征向量之比为阈值φ,阈值φ记为式(11)。阈值φ的选择为PCA降维的核心,通过多组实验,选用φ=0.96时效果最优 (11) 支持向量机[10](support vector machine,SVM)是一种建立在统计学VC维理论[11]和结构风险最小化基础上的机器学习算法,其最早应用于二分类,也可解决多分类问题,较好地解决小样本、非线性、高维数和局部极小值等问题[12]。 (12) (13) (14) 中小学硬笔汉字分类评价的总体框架分为:三级评价策略的建立、数据采集和样本库的建立、数据预处理、特征提取、特征降维、特征分类及比对,实验总体框架如图5所示。本节将在中小学硬笔汉字三级评价、样本库的建立、预处理3个部分进行分述。 图5 实验框架 经过与书法专家讨论,并结合《中小学书法教育指导纲要》[13]的要求所编写的《书法教学指导》,总结形成了以横平竖直、布白均匀、依字取势、穿插呼应、有主有次、笔画间关系为主的硬笔汉字评价原则。领域专家依据评价原则对左右结构、上下结构、包围结构等结构各200个汉字进行三级制评价,即一级代表优,二级代表良,三级代表差。以左右结构汉字“的”字为例,评价示例图见表1。 表1 书法汉字图像评价示例 样本来自北京市某两所学校的在读中小学生所书写的硬笔汉字字帖。针对左右结构的汉字“的”部分样本集如图6所示,不难看出,直接采集到的图片存在噪声和笔迹污染现象,因此,需要对汉字图像进行预处理。 图6 部分汉字“的”预处理后的样本集 2.3.1 图像尺寸归一化 经OCR扫描后的汉字图像为1400×1400像素,图像尺寸过大,会有不必要的细节像素、部分噪声的干扰,影响最终的实验结果。现将图像像素归一化为128×128和256×256大小。 2.3.2 图像光滑去噪 图像去噪是通过移除噪声来修复、完善原始图像,其中主要的难点在于移除噪声的同时,尽可能地保留图像的细节、边缘以及结构特征等。本文比较了3种滤波方式:双边滤波[14]、高斯滤波[15]、中值滤波[16]。随机选取一张汉字图片,效果对比如图7所示。 图7 3种滤波效果比较 实验结果显示,中值滤波相比于其它两种算法,去噪效果较好且轮廓信息保留的也好,实验结果最佳。 2.3.3 图像二值化 图像二值化是图像处理中重要的一步。目前常用的二值化方法有:全局阈值法、局部阈值法、迭代法等[17]。 全局阈值法中最具代表性的就是OTSU算法,其基本思想是求取前景与背景两部分最佳门限阈值。式(15)、式(16)表示从某一点到q点时,μ为平均灰度值,μi为i点处灰度值,ξ为类间方差,w0(μ0-μ)2、w1(μ1-μ)2分别为前景、背景两部分类间方差,当存在某一阈值T时,式(16)取得最大值,此时T即为最佳阈值[18] (15) ξ=w0(μ0-μ)2+w1(μ1-μ)2 (16) 局部阈值法[19]中最具代表性的是Bersen算法,其基本思想是根据每个像素点所在局部窗口中像素的最值来获取像素的阈值。该方法会导致汉字局部区域出现笔画断裂现象。 迭代法[19]的基本思想是利用循环迭代的方法,逐步逼近最佳阈值,此种方法通过多次迭代动态选择最优的阈值。实验结果如图8所示。 图8 平滑去噪后图像二值化处理结果 实验结果表明,预处理后,汉字图像有效去除了网格虚线和油墨污染处的噪声,为后续实验进展奠定基础。 实验在WINDOWS 10操作系统,硬件配置为Inter(R) Core(TM) i7-6700CPU 3.4 GHz,8 GB RAM,编译软件为Visual Studio Code并结合4.1.1版本的opencv计算机视觉库。本节将在参数分析实验和对比实验这两个方面来分述中小学硬笔汉字分类算法。 汉字的结构类型以左右和上下结构为主[20],特别是左右结构的汉字在汉字学习的初级阶段中占比很高。故,选用代表性汉字“的”作为左右结构汉字进行参数分析实验。选取195张经过预处理的图片,其中评价为优、良、差各50张,共计150张汉字“的”组成训练集,评价为优、良、差各15张,共计45张“的”组成测试集。 为了确保结论的可靠性,在评价为优、良、差各50张训练集“的”中,每部分任选25张,共计75张作为一次实验的训练集。同理,每次的测试集在三级评价中任选8张,共计24张作为一次实验的测试集,共计进行了10次独立实验。由于每次抽取的训练和测试样本集略有不同,所以准确率有一定波动。下面将分别分析图像尺寸、区域划分大小、梯度大小对实验准确性的影响。 3.1.1 图像尺寸参数实验 由于汉字在不同尺寸下,提取特征维度、运行效率、分类准确率不同,故在128×128和256×256尺度下进行了10次独立实验,准确率如图9所示。图9中折线由上到下的平均准确率分别为:0.8124、0.7750、0.7249、0.6724。实验结果显示,在相同梯度、区域划分时,128×128尺寸比256×256平均高出0.0374和0.0525。由此说明,图像尺寸不能过大,过大的图像反而带来更多的噪声,降低鲁棒性。最终,以128×128尺寸构成汉字样本集。 图9 验证图像尺寸准确率对比 3.1.2 区域划分参数实验 比较不同区域大小(block)对实验准确率的影响。在128×128尺寸下保证梯度不变,划分不同block,进行了10次独立实验,实验结果如图10所示。由上到下平均准确率分别为:0.7167、0.8125、0.625。实验结果表明,不能对图像进行过分割,并且block存在极值。故最终选择block大小的32×32像素大小为最佳。 图10 区域划分大小对实验准确率的影响 3.1.3 梯度参数实验 比较不同梯度(bins)方向大小对实验准确率的影响。在“的”字样本集中,图像尺寸128×128,以32×32像素分块时,且在0°~180°的区间内梯度9等分时,不同梯度大小对实验准确率影响,即在bins=3,6,9,15,18分别进行了10次独立实验,平均准确率如图11所示。根据结果显示在bins为9时达到极值点。故最终选取bins=9为最佳。 图11 180°梯度方向分块个数对准确的影响 本节针对基于网格的分层HOG特征提取方法与传统HOG特征提取在特征维度和轮廓特征提取方面作对比,并依据该方法实现对左右结构、上下结构、包围结构汉字的三级分类并与传统方法作对比。 3.2.1 特征实验对比 针对中小学汉字的特殊性,即中小学生缺少大量书写临习实践的能力,书写的汉字样本集会出现笔画过粗、过深、油墨污染的现象,会带来特征提取不准确的问题。传统HOG可以很好的描述汉字的轮廓特征,起到细化汉字特征的作用,但传统HOG存在特征提取维度大,易受外界无关因数的干扰问题。基于此,本文提出了基于网格的分层HOG特征提取算法,在保证汉字轮廓特征得到有效保留后,有效降低特征维度,优化运行效果,见表2。 表2 特征实验比较 根据3.1节,表中传统算法均按cells大小为8×8像素划分,block大小为4×4个cells组成,梯度方向大小为9进行实验。改进算法以32×32像素为一网格并按照不重叠的方式遍历汉字图像并结合底层的防止网格边缘干扰的特征划分作计算。实验结果表明,改进后的基于网格的分层HOG特征提取相比传统算法,在保证轮廓信息有效提取的同时,降低了特征维度。 3.2.2 分类实验对比 基于上述参数分析实验,本研究采用128×128的图像大小,以32×32像素为一个网格区域,并以梯度大小为9进行实验。由于汉字结构的多样性,难以实现全部结构的汉字的对比。因此,本研究基于中小学常用汉字的背景下,对中小学生最常用的左右结构、上下结构、包围结构的汉字样本作为实验对象。根据统计,选用最常用的汉字“的”字代表左右结构,“是”字带表上下结构,“国”字代表包围结构。针对“的”“是”“国”字样本集,将专家评价为优、良、差的汉字各50张,共计150张汉字图像作为训练集,评价为优、良、差各15张共计45张组成汉字测试集,统计195张各结构汉字作为样本集。测试预处理对实验分类效果的影响,并且测试了改进的基于网格的分层HOG特征提取对实验准确率、运行时间的影响。实验结果见表3。 表3 算法结果比较 通过以上实验可知,本文所提的改进算法,能够有效应用在硬笔汉字的分类领域。实验1和实验2表明,经过预处理后的左右结构、上下结构、包围结构汉字比原图的分类效果提高11.1%、2.9%、9.4%,表明了预处理操作对本研究的重要性。实验2和实验3表明了本文所提改进方法与传统方法相比,在汉字左右、上下、包围结构下分类结果提高2%~5%,并使分类速度平均提高了约40%。 在中小学硬笔汉字分类评价的背景下,解决了汉字特征提取时特征冗余、维度过大,以及边缘化的问题。并提出一套较为完整的中小学硬笔汉字评价框架。提出了针对不同结构汉字样本集的基于网格的分层HOG特征提取算法,并且通过实验预处理,去除汉字的噪声和毛刺,又结合PCA进一步降维后采用SVM分类器实现了中小学硬笔汉字左右、上下、包围结构的三级分类评价。实验结果表明,在准确率提高的前提下,分类速度也获得较大提升。评价指标的完善以及多结构汉字实验是下一步的研究重点。1.3 SVM训练分类器
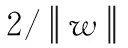
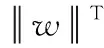
2 实验设计
2.1 中小学硬笔汉字三级评价

2.2 样本库的建立

2.3 预处理
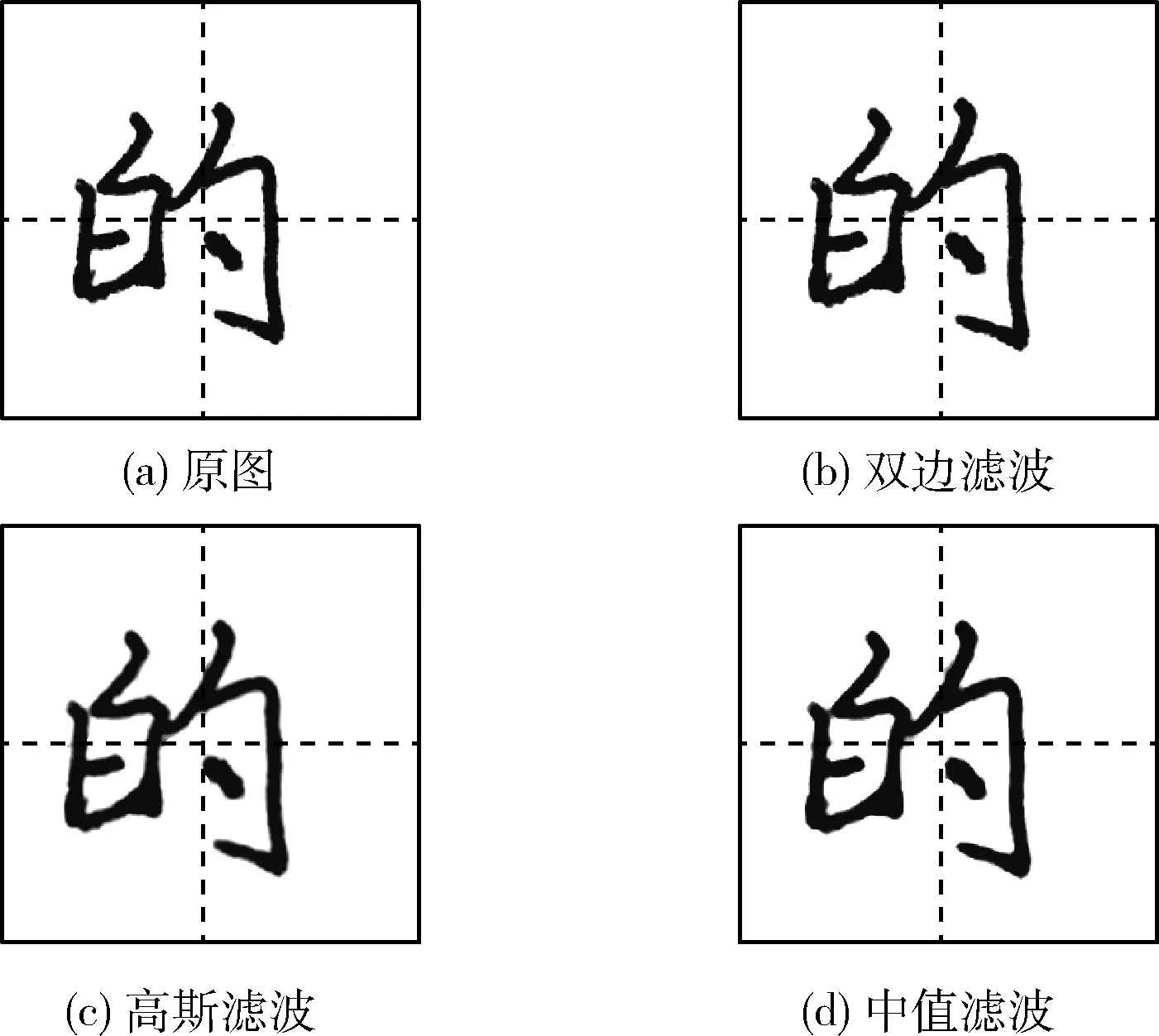
3 实验分析
3.1 参数分析实验
3.2 对比实验
4 结束语
猜你喜欢
数学物理学报(2022年5期)2022-10-09
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2019年9期)2019-10-26
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
电子制作(2018年19期)2018-11-14
电子制作(2018年1期)2018-04-04
北京航空航天大学学报(2017年12期)2017-04-23
