
基于特征选择的物联网设备流量异常检测算法
2022-08-16 03:11:02刘祥军江凌云
计算机工程与设计 2022年8期
刘祥军,江凌云,2+
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003; 2.江苏省物联网技术与应用协同创新中心 智慧家居安防分中心,江苏 南京 210003)
0 引 言
随着物联网(internet of things,IOT)的快速发展,全球部署的物联网设备的数量急剧增加[1]。然而,大多数的物联网设备由于受到生产成本的限制,设备的计算、存储能力有限,不能安装复杂的安全机制。另外,很多物联网设备的生产商都是不具备网络安全专业知识的传统家用电器制造商,这些厂商的开发团队往往不遵循安全的软件开发惯例[2]等,这都使得物联网设备成为完美的僵尸网络节点[3]。
目前传统网络中的流量异常检测方案非常丰富,但是由于物联网设备的特点和网络协议等问题,传统的检测技术难以应用于物联网中[4],因此针对物联网设备特点的流量异常检测方案还比较少。相对于传统互联网,物联网中的设备具备以下特点[5]:
(1)大多数的物联网设备硬件资源受限[6],如计算能力低,存储及电池电量小;
(2)异构物联网设备的流量类型差异性很大;
(3)单台物联网设备产生的流量很少,但海量设备与服务器之间的流量巨大;
(4)物联网设备工作模式和用户的使用习惯有很大关联,在不同的时间段,流量变化很大。
对于流量异常行为的检测,决定检测效果和效率的要素主要有算力、算法和数据,三者相辅相成。由于物联网边缘设备的算力普遍较低,所以本文的研究重点放在检测算法和数据处理上。
1 相关工作
1.1 检测算法
从检测策略角度,网络异常检测算法可以分为监督学习算法和半监督学习算法两大类[7]。监督学习在检测已知类型的攻击行为方面,其检测效果非常准确,但是对于未知类型的攻击行为,其检测效果较差。半监督学习是只学习检测目标的正常行为,当目标行为偏离正常行为并超过某个阈值时,就认为发生了异常。半监督学习可以检测到新类型的攻击,但是学习正常行为并不简单,所以容易产生误报,具有较高的假正率(false positive rate,FPR)[4]。
检测算法还可分为基于深度学习和基于传统的机器学习两大类。深度学习也属于机器学习算法的一种,它源于人工神经网络。基于深度学习的异常行为检测方法常见的有如下3种[8]:①基于深度玻尔兹曼机(deep boltzmann machines,DBM),它是将多个受限玻尔兹曼机串联堆叠而形成的深层神经网络。该类方法通过学习高维流量数据来提取流量的特征,从而提高检测效率,但该类方法提取特征的鲁棒性较差,当输入数据含有噪声时,其检测性能变差;②基于卷积神经网络(convolutional neural networks,CNN),该类方法检测性能较高,具有较强的鲁棒性,但需要先将网络流量转换为图像,加大了数据预处理负担;③基于堆栈自编码器(stacked auto-encoder,SAE),它是多个自编码器串联堆叠形成的深层神经网络。该类方法通过对高维流量数据进行学习,提取出流量特征,但当待测数据遭到破坏时,该类方法检测准确率会降低。深度学习方法优点是具有学习复杂行为模式的能力,但是,深度学习需要训练大量参数,且容易陷入局部最优问题,更重要的是深度学习对执行设备的计算,存储能力要求高,需要高性能的设备进行训练模型,难以在边缘设备上部署[9]。
在传统的机器学习算法中,可用于异常检测的分类算法有很多,常见的有[10]:①支持向量机(support vector machine,SVM),该方法可解决小样本的分类任务和高维数据问题,但大样本的分类任务计算效率并不高,而且对非线性问题很难找到一个合适的核函数;②一类支持向量机(one-class SVM),支持向量机在半监督学习上的推广;③KNN(K-nearest neighbor),该方法易于实现,无需估计参数,无需训练,但需要计算出待测样本与所有样本的距离,计算量很大;④局部异常因子(local outlier factor,LOF),通过计算每个点和其邻域内点的密度来判断该点是否为异常点,该算法需要计算每个点与其邻域点之间的距离,计算量大;⑤决策树(decision tree),该方法计算量较小,能给出每个特征的重要性程度,适合高维数据,但它没有考虑属性间依赖,容易过拟合;⑥孤立森林(isolation forest),是一种集成学习算法,通过构建多棵孤立树,计算样本在每棵孤立树上的路径长度来得到一个异常得分,最后综合所有孤立树的异常得分,做出决策。它容易实现、计算开销小;⑦随机森林是一种集成学习算法,它是包含多棵决策树的分类器,通过将多棵决策树的预测结果组合成一个模型,进行预测。随机森林容易实现、计算开销小、泛化性能强,被誉为“代表集成学习技术水平的方法”。
在上述算法中,深度玻尔兹曼机、卷积神经网络、堆栈自编码器、一类支持向量机、局部异常因子、孤立森林是半监督学习算法,支持向量机、KNN、决策树、随机森林是监督学习算法。在物联网中,被僵尸网络控制的设备发起的攻击类型有很多,但是基本都是已知的,所以本文采用随机森林算法进行设备流量的异常检测。
1.2 数据处理
数据处理一般指从采集到的原始测量数据中先筛选掉干扰信息,再用数理统计的方法从中提取出能刻画检测目标行为的统计量的过程。处理后的检测数据通常包含多个特征,其中一些特征对检测效果并不起作用或者存在多个特征作用相同。这些冗余特征不但会增加特征提取阶段的工作量,而且检测数据在高维情形下会出现数据样本稀疏、距离计算困难等问题,被称为“维数灾难”[10]。缓解维数灾难的方法有两种:一是降维(dimension reduction);二是特征选择(feature selection)。
降维也称为维数约简,指通过某种数学变换将原高维空间中的数据点映射到低维度的子空间中。在降维产生的子空间中,样本密度会大幅提高,距离计算也变得更为容易。常见的降维算法有PCA[11]、LDA(linear discriminant analysis)、局部线性嵌入(locally linear embedding,LLE)。对比LDA、PCA 算法,LLE算法的计算复杂度极高,因为它需要计算出降维前所有样本点之间的欧氏距离或测地距离。LLE和PCA对数据的降维范围没有限制,最少可以降到一维,LDA算法的降维的范围有限制,假设样本数据包含k类,LDA算法的降维范围是[1,k-1],特别地,对于k=2时,LDA算法只能把样本数据降到一维。
特征选择是指根据优化目标从已有的特征集合中选择若干个特征构成最佳特征子集。常见的特征选择方法有过滤式(Filter)、包裹式(Wrapper)、嵌入式(Embedding)。过滤式方法的特征选择过程与后续使用的检测算法是相互独立的。包裹式方法是把检测算法的检测效果作为特征子集的评价标准。嵌入式方法是将特征选择过程与检测算法训练过程融为一体,在检测算法训练过程中自动地进行了特征选择。过滤式和包裹式方法针对所有的算法都可以实现,而嵌入式方法只适合某些算法,如支持向量机、逻辑回归等。对比包裹式特征选择,过滤式可以快速缩小特征的范围,具有计算简单,收敛速度快的特点,但是并不能保证选择出无冗余的特征子集。包裹式特征选择针对某个特定的检测算法优化,实际中表现出的性能比过滤式好很多,但是计算复杂度较高,收敛速度慢。
综上,本文根据物联网中设备海量异构的特点以及异常检测的要求,提出一种基于随机森林的包裹式特征选择方法RFCVFS,通过对设备流量中提取出的特征信息进行选择,为不同类型的物联网设备分别筛选出有效的特征信息,并用于训练检测模型,实现对攻击流量的高效检测。本文主要内容和创新如下:
(1)设备流量采集与特征信息提取。采用阻尼时间窗口的方法[12],在5个不同时间窗口,从设备产生的流量中提取出描述设备行为的特征信息。
(2)特征信息选择。提出一种特征选择方法RFCVFS,为不同类型的物联网设备选择出适合该设备的特征信息。
(3)实验与结果分析。使用UCI公开的僵尸网络数据集[13]进行实验,根据为不同类型设备选出的特征信息,用随机森林算法为每种类型设备训练出独立的检测模型。结果显示,本文提出的检测方法能够有效降低物联网边缘设备的流量预处理负担,大幅降低模型训练时间,流量检测时间。
2 设备流量采集与特征信息提取
在物联网环境中,设备产成的数据流首先在网关处汇聚,多个网关设备数据流再汇聚到路由器,连接到互联网上。汇聚后的数据流包含多台设备流量,增加了对于某台设备异常流量检测的难度[14]。因此,本文把安全检测系统部署在离设备较近的边缘网关处。
本文流量异常检测系统的工作流程如图1所示,可分为如下步骤:①流量采集。边缘网关利用不同的物理端口区分来自不同类型物联网设备产生的流量,然后基于阻尼时间窗口方法进行流量采集;②特征信息提取。从设备产生的流量中提取出描述设备行为的特征信息;③特征信息选择。执行特征选择算法RFCVFS,为不同类型的设备选择有效的特征信息,训练检测模型并保存;④设备流量检测。根据流量来源,选择对应的检测模型,实现对设备行为的实时监控。

图1 检测系统工作流程
2.1 设备流量采集
设备的异常行为检测是根据设备流量的特征信息是否发生变化,但是从流量中提取这些特征信息存在许多的挑战[12]:①不同的会话分组是相互交织的;②在任何给定时刻都有多个信道同时进行通信;③分组到达率不稳定,有时会很高。因此,为了得到能代表数据流最近行为的特征信息,必须丢掉相对较老的数据包,简单的方法是去维持一个滑动窗口,窗口共包含N个数据包,每次有新的数据包加入时,窗口会丢弃最旧的数据包,然后就可以在窗口上计算特征信息。
滑动窗口方法简单容易实现,但是会带来有两个缺点:①没有考虑在一个窗口内N个数据之间的时间跨度。例如,假设一个窗口维护N=1000个数据包,前900个数据包在1 s内达到,最后100个数据包是在之后1 min内到达,这就导致利用该窗口内的数据计算出的特征信息并不能描述设备最近的行为;②该方法的空间复杂度是O(N), 设备产生的海量数据会导致检测系统的内存消耗太大。
为了解决用滑动窗口采集的流量有时不能描述设备最近行为问题,本文采用了阻尼时间窗方法。在阻尼窗口模型中,它不规定窗口内的数据包个数N,而是规定窗口的时间间隔T,所以阻尼时间窗口内的数据个数是一个变化值,数据包权重随时间呈指数下降,对应的衰变函数为dλ(t)=2-λt式中λ(>0) 是衰变因子,t是在阻尼时间窗口内该数据包到最后一个接收数据包的时间间隔,即最后一个数据包对应t=0, 第一个数据包t=T。
为了解决滑动窗口占用内存过大的问题,本文采用了一种基于数据增量来计算特征信息的框架,它可以在动态数量的数据流上进行高速的特征信息的提取。例如,对于一个数据流S={x1,x2,…},xi∈,xi代表数据包的大小,要计算S的均值μs, 方差O(1), 标准差σs, 可以通过维护三元数组IS=(N,LS,SS) 来计算得到,其中N代表数据流S中元素个数,LS代表S中元素之和,SS代表S中元素的平方和,当S中增加一个数据xn, 此时即不用把S中每个元素xi都记录在内存中,当有新的数据到达时,只需要更新IS即可。该方法具有的空间复杂度。
2.2 特征信息提取
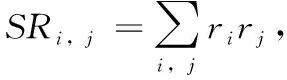
算法1: 五元数组更新算法
输入:ISi,λ,xcur,Tcur,rj
输出:ISi,λ
(1)计算衰减系数γ:γ=dλ(Tcur-Tlast)
(2) 计算衰变量:ISi,λ←(γw,γLS,γSS,γSR,Tcur)
(3) 更新ISi,λ:
(4)返回(1)

表1 特征类型和计算方法
如表2所示,本文从4种数据流中提取上述的特征信息,这4种数据流分别是:①相同MAC和IP地址产生的数据流,定义为SrcMAC-IP;②相同源IP地址产生的数据流,定义为SrcIP;③相同源IP地址和目的IP地址之间产生的数据流,定义为Channel;④相同源IP-Socket和目的IP-Socket地址之间产生的数据流,定义为Socket。在一个阻尼时间窗口内共提取23个特征。为了全面描述出流量随时间变化的特征,共设置了5个时间窗口,分别为:100 ms、500 ms、1.5 s、10 s和1 min,对应的衰变因子λ:5、3、1、0.1、0.0。
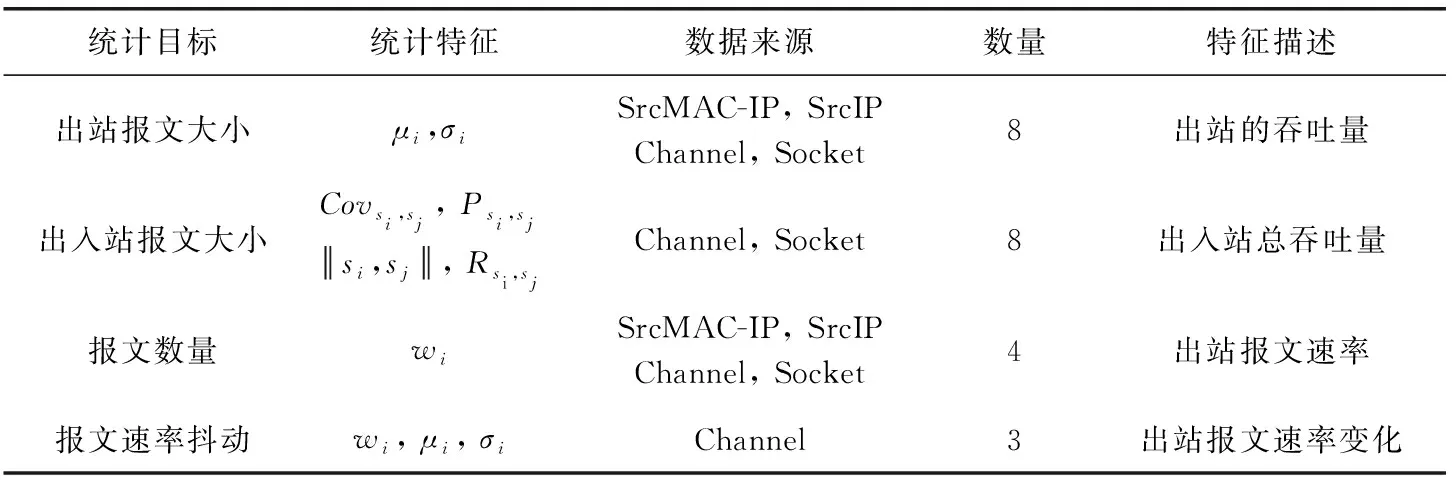
表2 4种数据流及其提取的特征信息
3 特征信息选择算法
特征选择算法包括特征子集评价和子集搜索两个环节。子集评价是根据选定的评价标准,本文的特征选择算法是一种基于随机森林包裹式特征选择算法,该算法的子集评价标准是F1,子集搜索机制是后向搜索。
3.1 随机森林
随机森林是以决策树为基学习器的集成学习分类算法,而且进一步在决策树的训练过程中引入了Bagging随机采样和随机属性选择。随机森林生成步骤如下:
(1)构建基决策树。对于基决策树的每个结点,先从该结点包含的d个属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。这里的参数k控制了随机性的引入程度,若令k=d, 则基决策树的构建与传统决策树相同;若令k=1, 则是随机选择一个属性用于划分,一般取k=1或者k=log2d;
(2)Bagging随机采样。从训练集中抽取M个样本,用这M个样本构建基决策树,同样方法抽取N次,则构建N棵决策树,这N棵基决策树就构成随机森林,一般取N=256;
(3)用随机森林对新样本进行分类,分类结果由每棵基决策树的分类结果进行投票得到。
3.2 特征重要性评估
提供特征重要性评估是决策树这一类算法的特点,基于决策树构建的随机森林算法可以计算出基于袋外数据分类准确率的特征重要性评估。该评估方式结合了决策树和Bagging随机采样特点,是最常用的一种特征重要性评估方式。具体原理如下:
(1)用Bagging从训练集中采样得到M个样本集,重复N次,用这N个样本集训练N棵基决策树,构成随机森林;
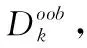
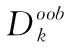

(5)计算得到,若给某个特征随机加入噪声之后,袋外的准确率大幅度下降,则说明这个特征对于样本的分类结果影响很大,所以特征Xj的重要性得分Sj越大,说明特征越重要。
3.3 本文特征选择算法RFCVFS
在实际使用过程中发现,上述特征重要性评估算法存在一个问题,即当我们采取交叉验证时,在每一折上计算出的特征的重要性得分和排名会有变化,所以针对这个问题,本文提出了一种算法RFCVFS,根据随机森林算法计算出的特征重要性得分,采用K折交叉验证的方式保证数据集中所有数据都可用于训练和验证,并将K次计算得分相加,达到降低计算结果误差的目的。大体过程如下:首先把数据集分成K份,用其中K-1份作为训练集,剩下1份作为验证集,依次计算出K个训练集上的特征重要性得分,把所有特征的K次特征重要性得分相加,根据K次得分之和给所有特征排序,得到最终的特征重要性排序。通常取K=5或10,本文取K=5。 之后采用后向搜索的方式,每次从特征重要性得分集合中删掉一个特征重要性得分最低的特征,然后重新计算,逐步迭代。具体实现过程如算法2和图2所示。
算法2: 特征选择算法RFCVFS
输入: 数据集D
输出: 特征重要性排序集合FSort
(1)将数据集D随机划分成不重叠的5份, 选其中4份作为训练集Tri, 剩下一份为测试集Ti,i=1,2,3,4,5
(2)初始化参数随机森林算法参数
初始化每个特征重要性得分FScorek=0,k=1,2,…,N,N为特征数量。
初始化每个特征重要性得分总分TotalScorek=0,k=1,2,…,N,N为特征数量。
(3)循环开始:i=1∶5
用Tri构建随机森林分类器, 计算出所有特征的重要性得分FScorek=0,k=1,2,…,N
令TotalScorek=TotalScorek+FScorek
循环结束
(4)根据每个特征的TotalScorek得分, 将所有特征根据其TotalScorek由大到小排序
(5)在数据集D中删掉FSort中排在最后一位的特征
(6)若FSort中特征数量大于1, 则返回(2), 否则继续
(7)结束

图2 RFCVFS算法流程
4 实验与结果分析
4.1 实验环境
仿真环境包括的硬件Intel Core i7-4790 CPU@3.60 GHz,内存8 GB,软件有Windows 10×64操作系统,Python 3.8.4,Anaconda3,Jupyter Notebook。
4.2 数据集
本文采用UCI公开僵尸网络数据集,该数据集包含9台物联网设备产生的真实流量,这9台设备包含两个不同型号的门铃(Ⅰ,Ⅲ),一个恒温器(Ⅱ),一个婴儿监视器(Ⅳ),4台不同型号的监控摄像头(Ⅴ,Ⅶ,Ⅷ,Ⅸ),一个网络摄像头(Ⅵ)。在包含这9台设备组成的物联网中,用物联网中常见的僵尸网络病毒Mirai和BASHLITE去感染物联网设备,并发动如下8种类型攻击:
(1)基于Mirai病毒的攻击:扫描攻击Scan、Ack泛洪攻击、Syn泛洪攻击、UDP泛洪攻击、高速率UDP泛洪攻击UDPplain。
(2)基于BASHLITE病毒的攻击:扫描攻击Scan、垃圾邮件攻击Junk、TCP泛洪攻击、UDP泛洪攻击、指定IP和端口的垃圾邮件攻击COMBO。
如表3所示,该数据集包含9个子数据集,每个子数据集对应一种物联网设备,利用这9种设备发起了8种物联网环境中常见的拒绝服务攻击。这9个子数据集共包含7 062 607条数据,其中正常样本555 932条,恶意样本6 506 675条。

表3 数据集描述
4.3 评估标准
基于分类的检测模型,可以根据混淆矩阵中数据分布的情况对模型进行评估,该矩阵表示见表4。本文主要用到的评估标准有准确率、真正率、F1和AUC,具体的定义如下:
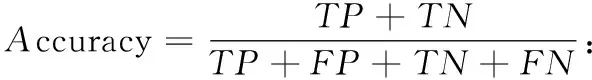
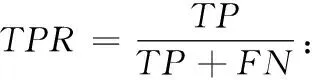
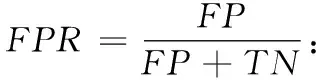

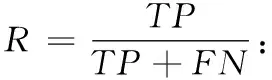

AUC:以FPR和TPR为横纵坐标画出的ROC曲线与横坐标的面积,取值范围0到1。

表4 混淆矩阵
4.4 参数设置
随机森林算法包含256棵基决策树,基决策树节点的划分度量标准为基尼不纯度(Gini impurity),寻找最佳分割时需要考虑的特征数量为总特征数量的平方根值,分割内部节点所需要的最少样本数量为2,构建决策树的深度没有限制,采取五折交叉验证,模型随机种子设置为0。
4.5 结果及分析
(1)特征数量对检测效果的影响
通过对特征提取阶段收集到的特征进行选择,根据RFCVFS算法计算出的特征重要性得分,每次删去一个最不重要的特征,然后重新计算剩余特征重要性得分,重复这个过程。图3显示删去0到89个特征的过程,随着冗余特征数量的减少,这9台设备检测结果的F1几乎保持不变,且有上升的趋势;图4显示删去90到111个特征的过程,从图中可以看出,检测数据在删去90到108个特征的过程中,F1得分几乎不变,大约在删去108到110个特征后,多数设备的F1开始出现明显下降趋势,说明删去的特征不是冗余的,应该保留。综上,本文的RFCVFS算法能够筛选出数据中包含的冗余特征,可以用于给设备筛选出最佳特征子集。
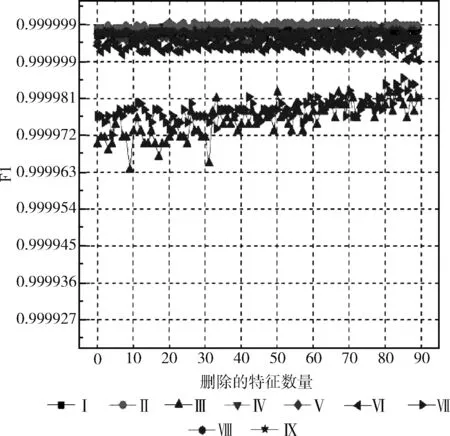
图3 删去0-89个特征
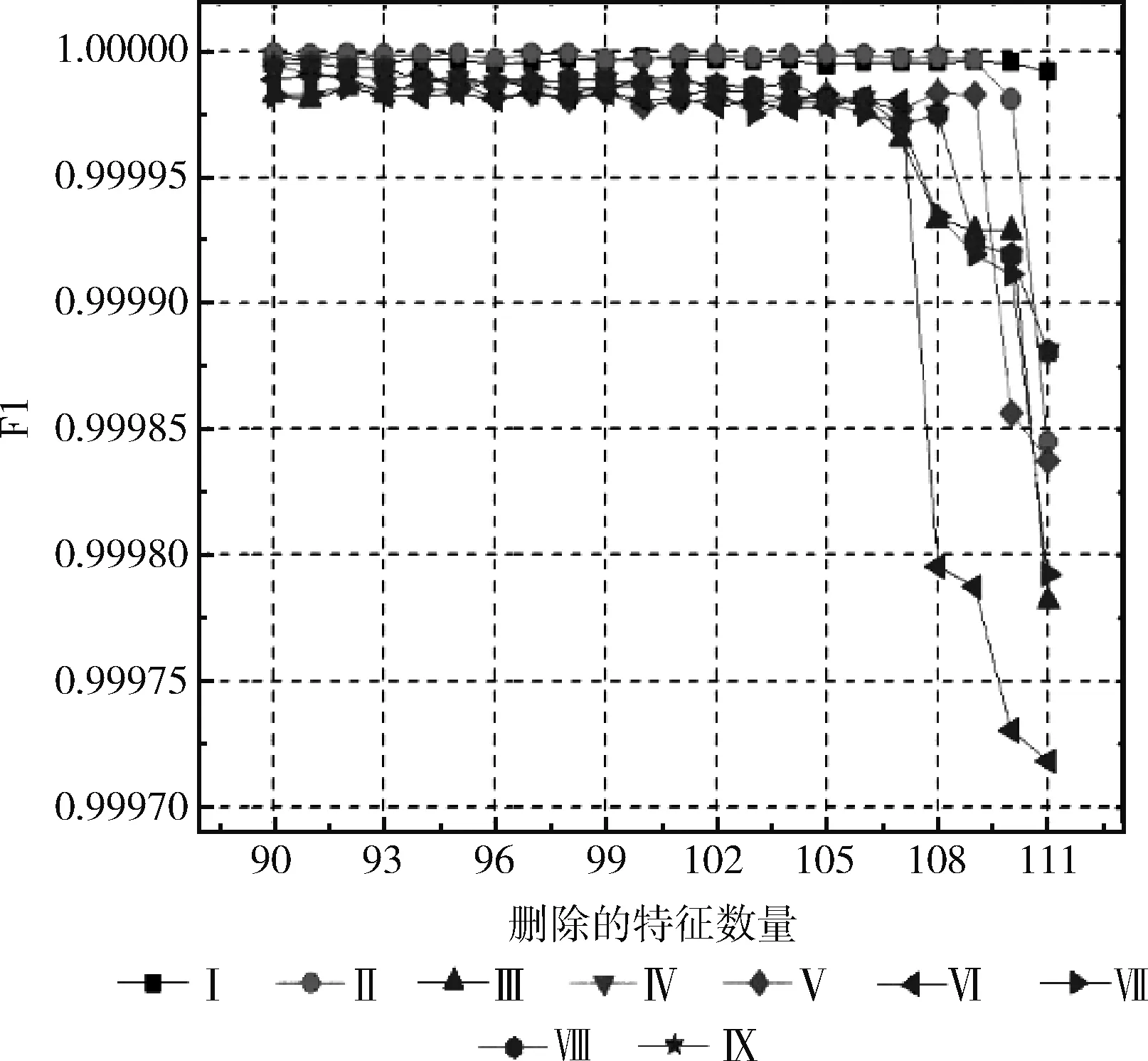
图4 删去90-111个特征
(2)特征数量对检测效率的影响
如表5所示,在保证F1≥99.99%时,9台设备选取最少的特征数量以及对应的特征序号,并将其命名为最佳特征集。对于这9台设备来说,只要分别选取3,5,5,5,6,5,5,2,8个特征进行检测,就能达到很好的效果。如图5、图6所示,对比了保留所有特征和采用RFCVFS筛选出的特征,这9台设备检测模型的训练时间最大降低82.67%,平均降低74.64%;流量检测所需的时间最大降低28.49%,平均降低17.63%。
(3)RFCVFS和PCA算法对比
如图7到图10所示,从准确率Accuracy、真正率TPR、F1和AUC这4种评价标准分别对比了RFCVFS和
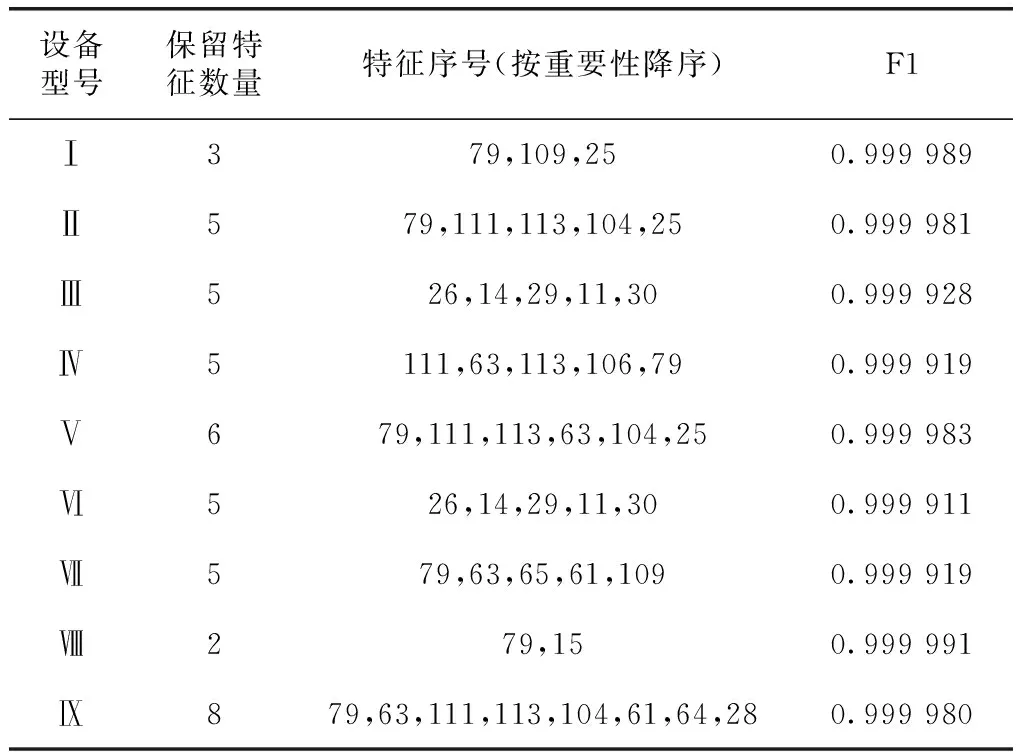
表5 选出的特征集(F1≥99.99%)
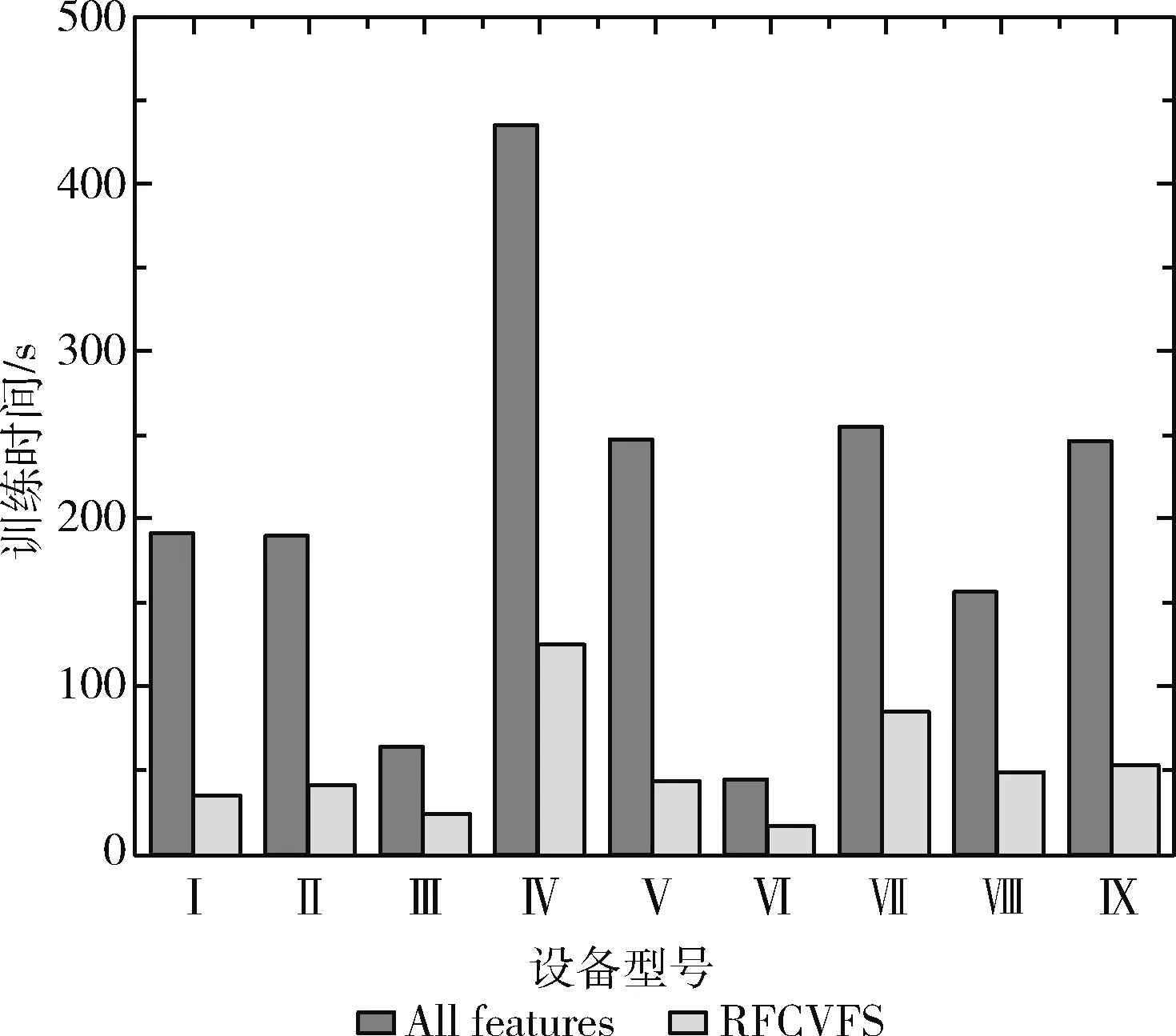
图5 特征选择前后的训练时间对比
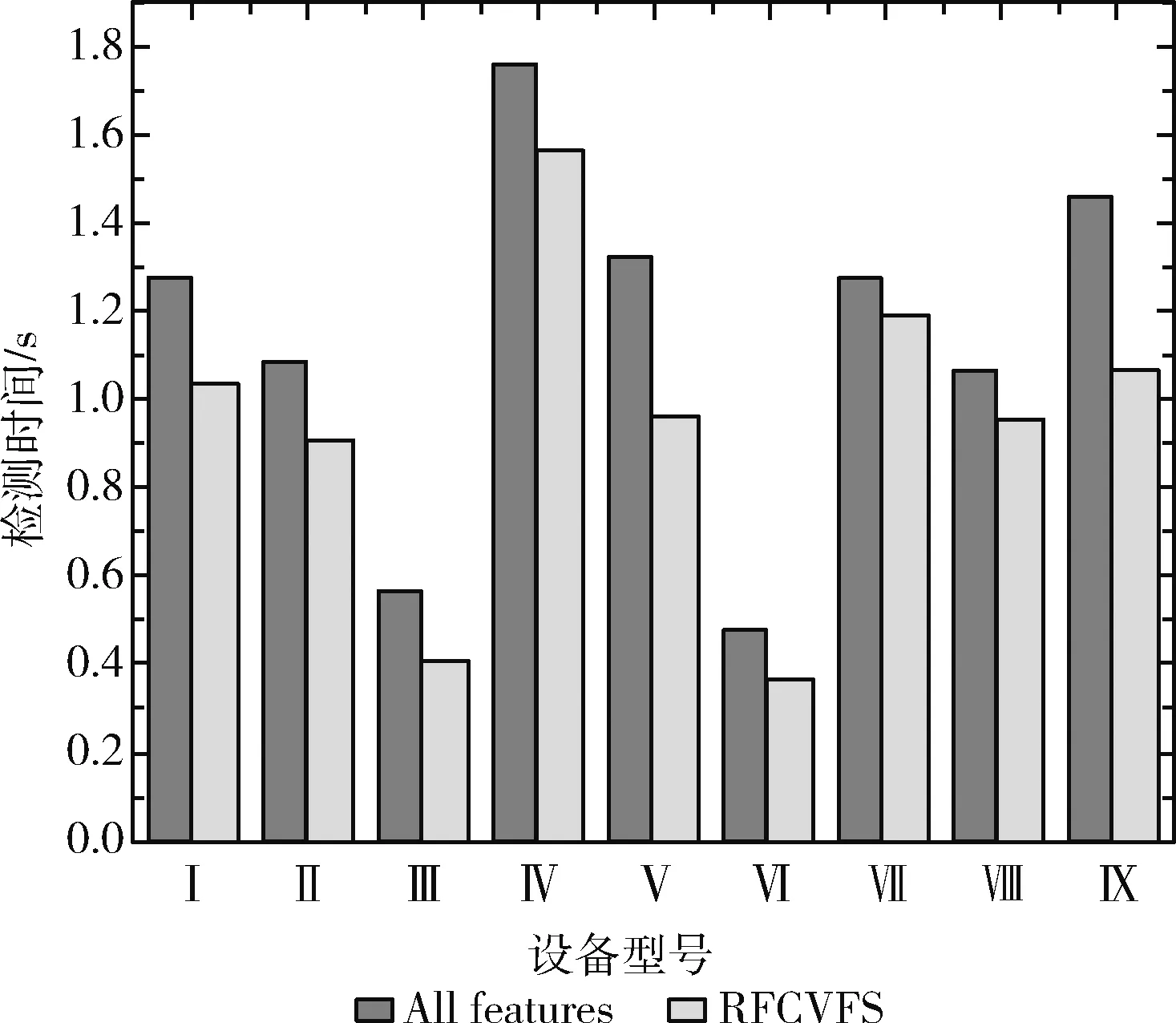
图6 特征选择前后的检测时间对比
PCA两种降维方法。根据每台设备最佳特征集中的特征数量,利用PCA把9台设备的检测数据对应地降到相同维度,检测结果显示,采用RFCVFS算法处理过的数据,其检测结果的Accuracy、TPR、F1、AUC分别最大高出13.82%、0.48%、7.63%、29.51%,平均高出5.38%、0.13%、2.88%、18.57%。这说明相比PCA算法产生的特征,RFCVFS算法筛选出的特征能更好的区分出恶意流量和正常流量,且无论是从准确率、误判率角度都是优于PCA算法生成的特征,此外,特征选择筛选出的特征保留了原有特征的物理意义,PCA算法产生的特征是原有特征的线性组合变换,失去了原有特征的物理意义。

图7 准确率的对比
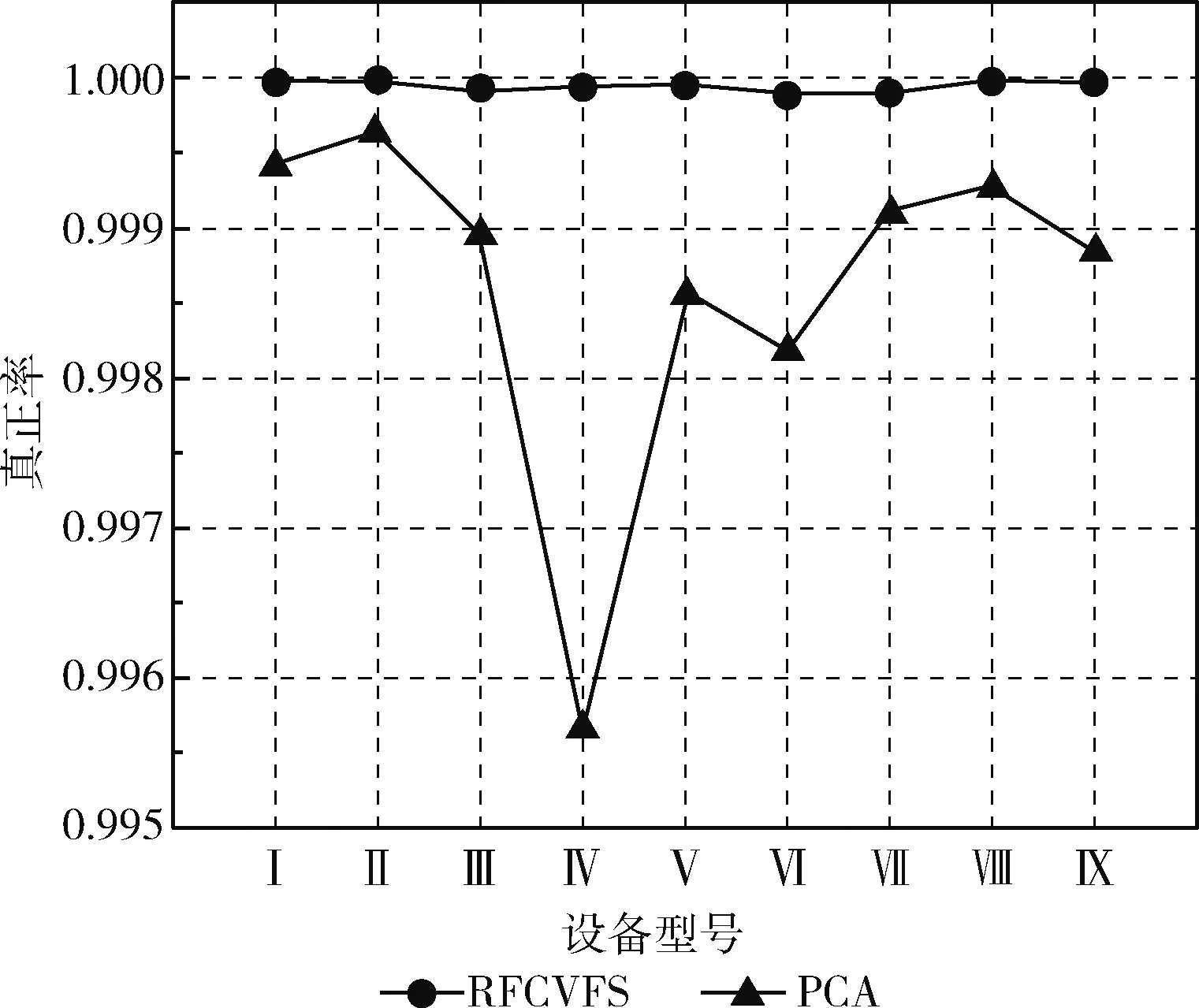
图8 真正率的对比
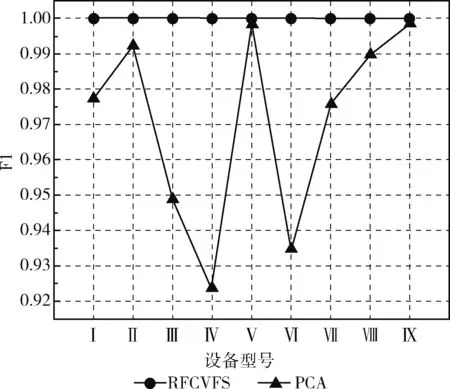
图9 F1的对比

图10 AUC的对比
另外,在实验过程中还发现,如图11、图12所示,相比RFCVFS选择出的数据,用 PCA生成的数据,其训练时间和检测时间分别平均高出67.13%,38.74%。虽然两者生成的数据是相同的维度,但是PCA降维的原理是按照原始数据各方向上的方差,从大到小依次选取,从而在计算决策树分叉点最佳阈值时就需要耗费较多的时间,且生成的决策树会更深,这就导致模型的训练时间,检测时间的增加。
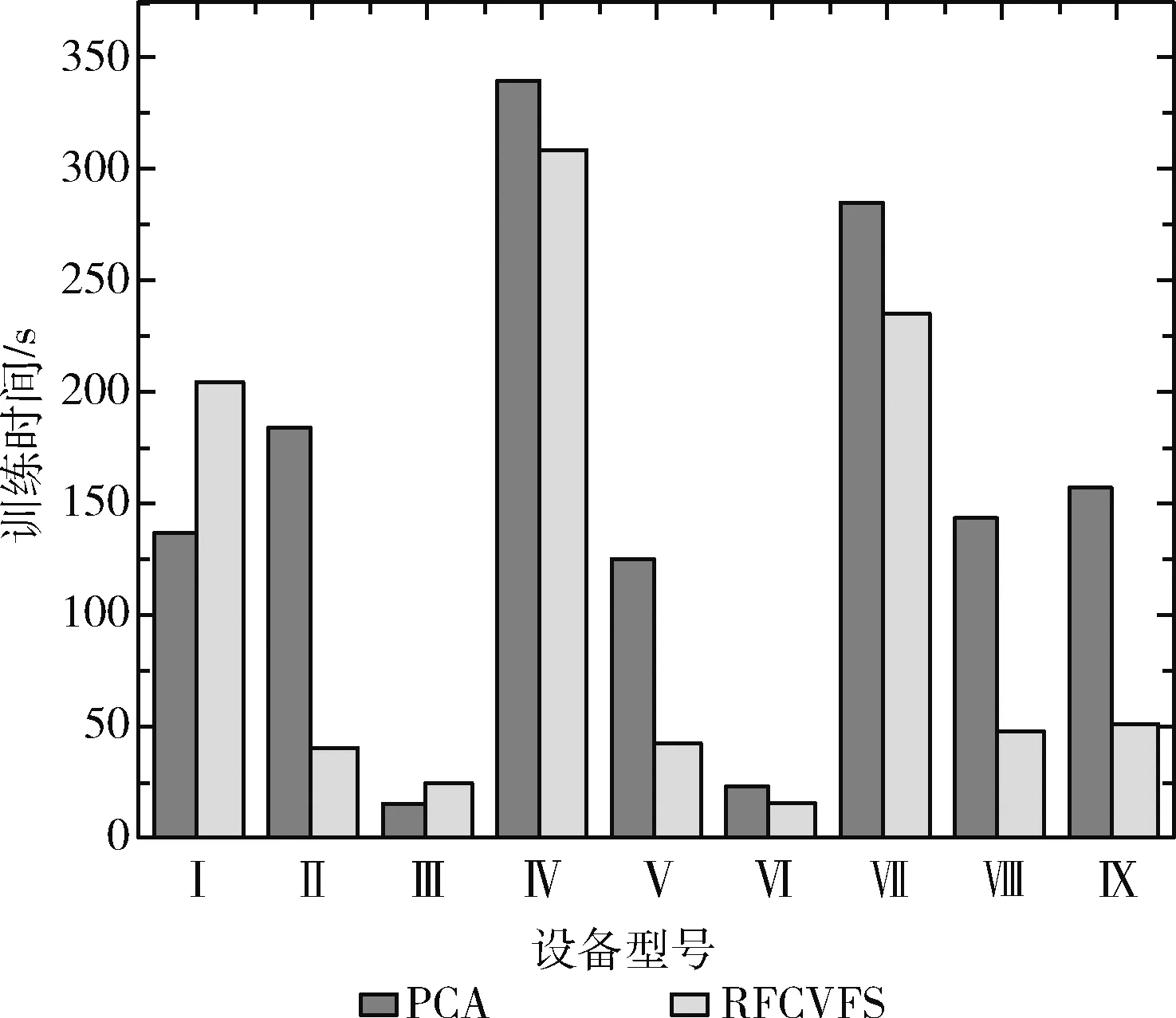
图11 模型训练时间的对比
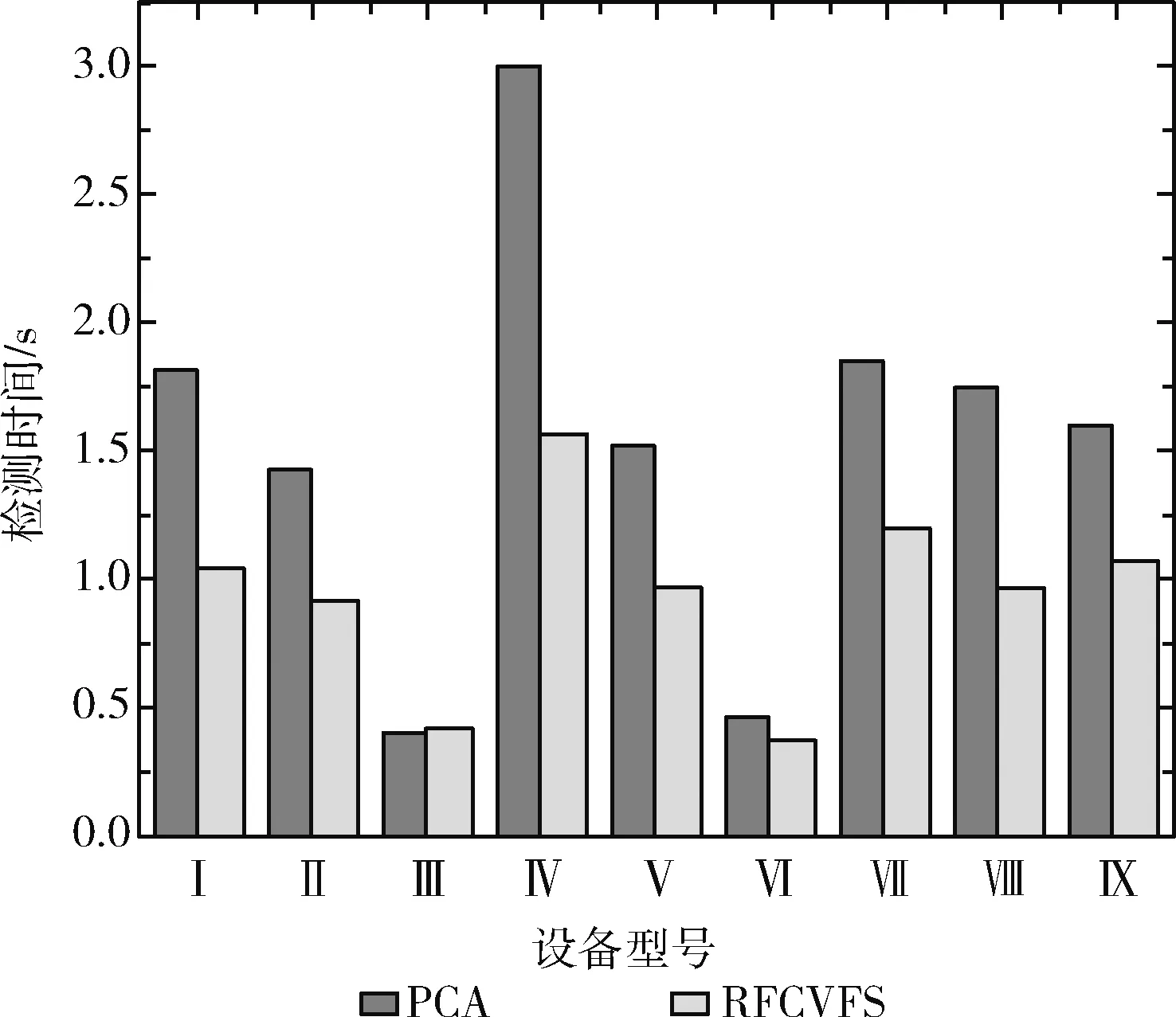
图12 模型的检测时间的对比
特征选择和PCA都能降低数据维度,但是特征选择具有更加明确的实际意义:①特征选择可以根据检测目标,给出每个特征对于检测结果的影响程度,有助于在检测某种类型攻击时进行特征的设计;②特征选择可以降低设备在流量特征提取阶段的负担。在特征提取阶段只需要提取有效特征即可组成待检测数据。
5 结束语
针对物联网环境中的僵尸网络攻击问题,本文从检测算法和数据两方面出考虑,提出一种基于特征选择的设备流量异常检测方法。首先,该方法可以给异构的物联网设备动态搜索出适合该设备型号的最佳特征子集,相比没有进行流量的特征选择,采用该方法可以有效降低模型的训练时间和检测时间。其次,在流量特征提取阶段,只需要根据设备型号提取出该设备的最佳特征,这对于性能受限的物联网边缘设备而言,可以有效降低特征提取阶段的工作负担。最后,对比经典降维方法PCA,采用特征选择方法得到的流量特征具有更高的准确性,模型训练时间和检测时间也更短。
下一步工作考虑将流量特征选择和半监督学习算法结合起来,降低人工标记数据的难度,提高检测模型应对未知类型攻击的能力。
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
网络安全和信息化(2018年4期)2018-11-09 12:01:54
电子制作(2018年16期)2018-09-26 03:27:06
电子制作(2017年23期)2017-02-02 07:17:06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
西北工业大学学报(2015年4期)2016-01-19 03:31:47
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
中国新通信(2014年11期)2014-09-11 19:27:52
振动工程学报(2014年4期)2014-03-01 01:15:41
计算机工程(2014年6期)2014-02-28 01:26:36
