
表情识别技术综述
2022-08-16 12:21:10洪惠群沈贵萍黄风华
计算机与生活 2022年8期
洪惠群,沈贵萍+,黄风华
1.阳光学院 人工智能学院,福州350015
2.阳光学院 空间数据挖掘与应用福建省高校工程研究中心,福州350015
3.阳光学院 福建省空间信息感知与智能处理重点实验室,福州350015
表情、声音、文本、姿态等,都可以用来表达人类情感,面部表情是人类情感表达的重要依据之一,因此,计算机可以尝试通过分析人的面部表情来理解人的情感,并在众多人机交互系统中融入,例如:各类服务型机器人、辅助检测疲劳驾驶、医疗服务、远程教育中学生学习状态监测等。尽管在人们社交过程中,逐渐演化出各种复杂的面部动作和表情来表达内心的情感,但是学术界普遍研究的都是由Friesen 和Ekman 等心理学家提出的6 种基本情感类别,即“高兴、愤怒、悲伤、吃惊、厌恶、恐惧”。
随着计算机视觉及人工智能技术的发展,人脸表情识别吸引着越来越多的学者进行研究。表情识别侧重于识别面部的表情及情感,而情感分析则可以根据面部表情、语音、文本、姿态、脑电信号等各种信号来进行情感分析,在情感分析的过程中,有可能没有对面部表情这一模态进行分析。因此,可以将表情识别看作情感分析的一个研究方向。本文侧重于从面部表情识别的角度去归纳总结。
在面部表情识别过程中,研究者常常会尝试结合语音、文本、姿态、脑电波等多种模态信息进行分析,根据在面部表情识别过程中所使用的数据集是单一模态的面部表情数据还是面部表情数据结合其他模态的数据进行情感识别的不同,本文将表情识别算法分为基于单模态数据的面部表情识别和基于多模态数据的面部表情识别。
1 基于单模态数据的面部表情识别
基于单模态数据的面部表情识别主要根据面部表情这一模态来进行分析识别,包含如图1 所示步骤:数据集采集、图像的预处理、表情识别及判断类别等。

图1 单模态人脸表情识别主要步骤Fig.1 Main steps of unimodal facial expression recognition
1.1 数据集采集
表1 总结了常见的表情识别数据集的图像特点、标注类别及图像/视频数。其中:A1 代表实验室受控环境下的数据,A2 代表网站上非受控环境下的数据;B1 代表数据很少,B2 代表数据较少。
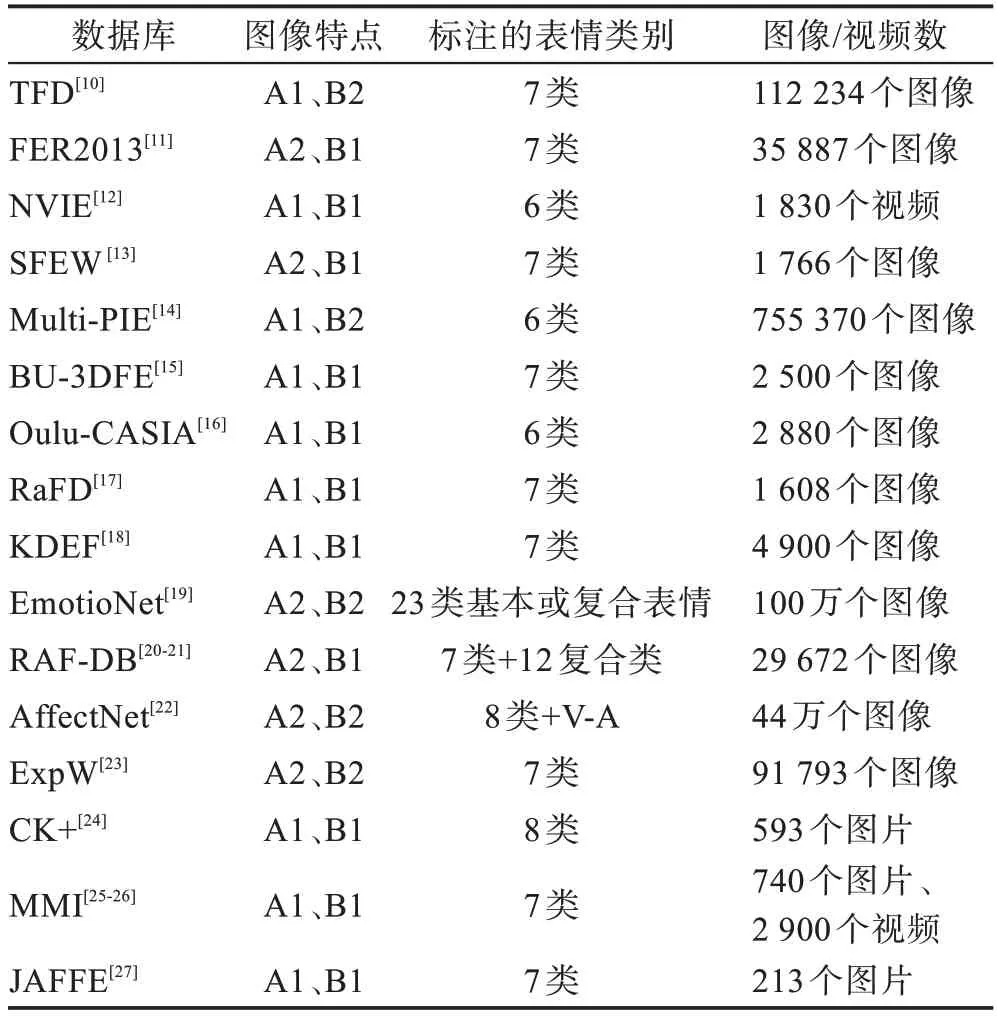
表1 常见的表情识别数据集Table 1 Common expression recognition datasets
表1 所示的数据集中,部分数据集为受控环境下的数据,数据少且皆为正面清晰人脸,标注可经过心理学专家反复确认,一般认为这些数据库标注是完全可靠的,如CK+、JAFFE 等。部分数据集如RAFDB、AffectNet 等大规模数据集,是在非受控环境下取得的,受标注者感知的主观性影响较大,标注质量相对比较低。因此,现有的数据集在数量和质量上均较为不足,数据量小,不足以很好地训练目前在人脸识别任务中取得良好效果的较大深度网络结构。此外,现有的数据集缺乏具有遮挡类型和头部姿态标注的大型面部表情数据集,也会影响深度网络解决较大类内差距,学习高效表情识别能力特征的需求。
1.2 图像预处理
图像预处理主要对原图像进行人脸对齐、数据增强及人脸归一化等操作,是在计算特征之前,排除掉与脸无关的一切干扰。恰当的预处理能够减少因图像质量对识别效果的影响,同时也能提升算法的鲁棒性。
人脸对齐也叫人脸关键点定位,在人脸检测的基础上,找到眉毛、眼睛、鼻子、人脸轮廓等的位置,最少的有5 个关键点,常见的有68 个关键点。
数据增强是通过随机改变训练集样本,以降低网络模型对某些属性的依赖,从而提高识别率,防止过拟合现象的发生。
人脸归一化主要指亮度归一化和姿态归一化。
1.3 面部表情识别
传统的表情识别方法主要为浅层学习或采用人工设计特征,需要人工较多地参与,常见的算法有:基于全局特征的提取方法、基于局部的提取方法、混合提取方法的静态图像表情识别以及基于光流法的动态视频的表情识别。具体方法及优缺点如表2 所示。
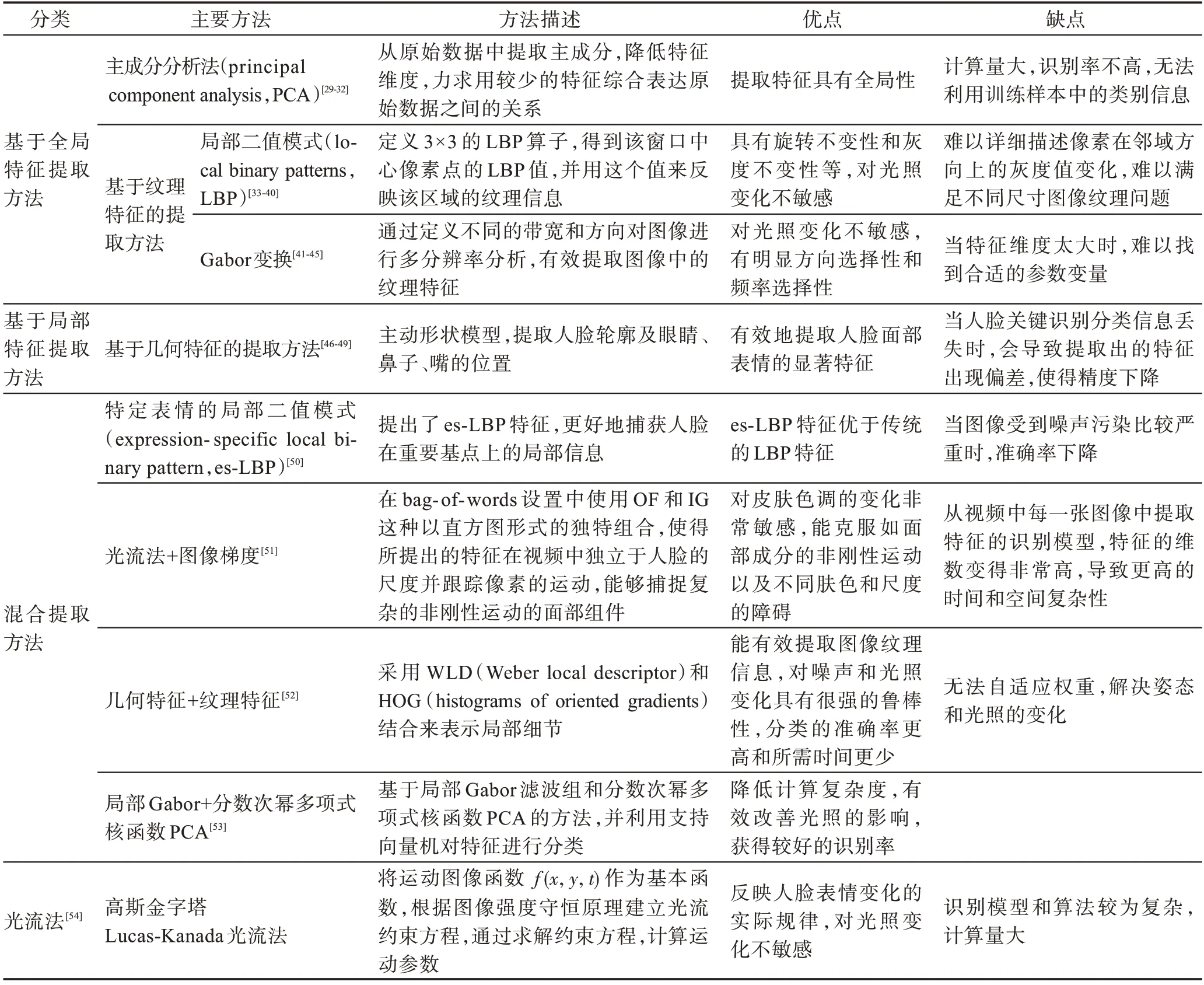
表2 传统表情特征提取方法Table 2 Traditional expression feature extraction methods
基于深度学习面部表情识别方法大体也可以分为基于静态图像的深度表情识别网络以及基于动态视频的深度表情识别网络。鉴于目前人脸表情数据库相对较小,直接进行深度学习网络训练,往往导致过拟合。为了缓解过拟合的问题,通常有如下几种方法:自建网络、卷积网络微调、分阶段微调、多网络融合、多通道级联、生成对抗网络、基于迁移学习的跨域人脸表情识别等,现总结如表3。
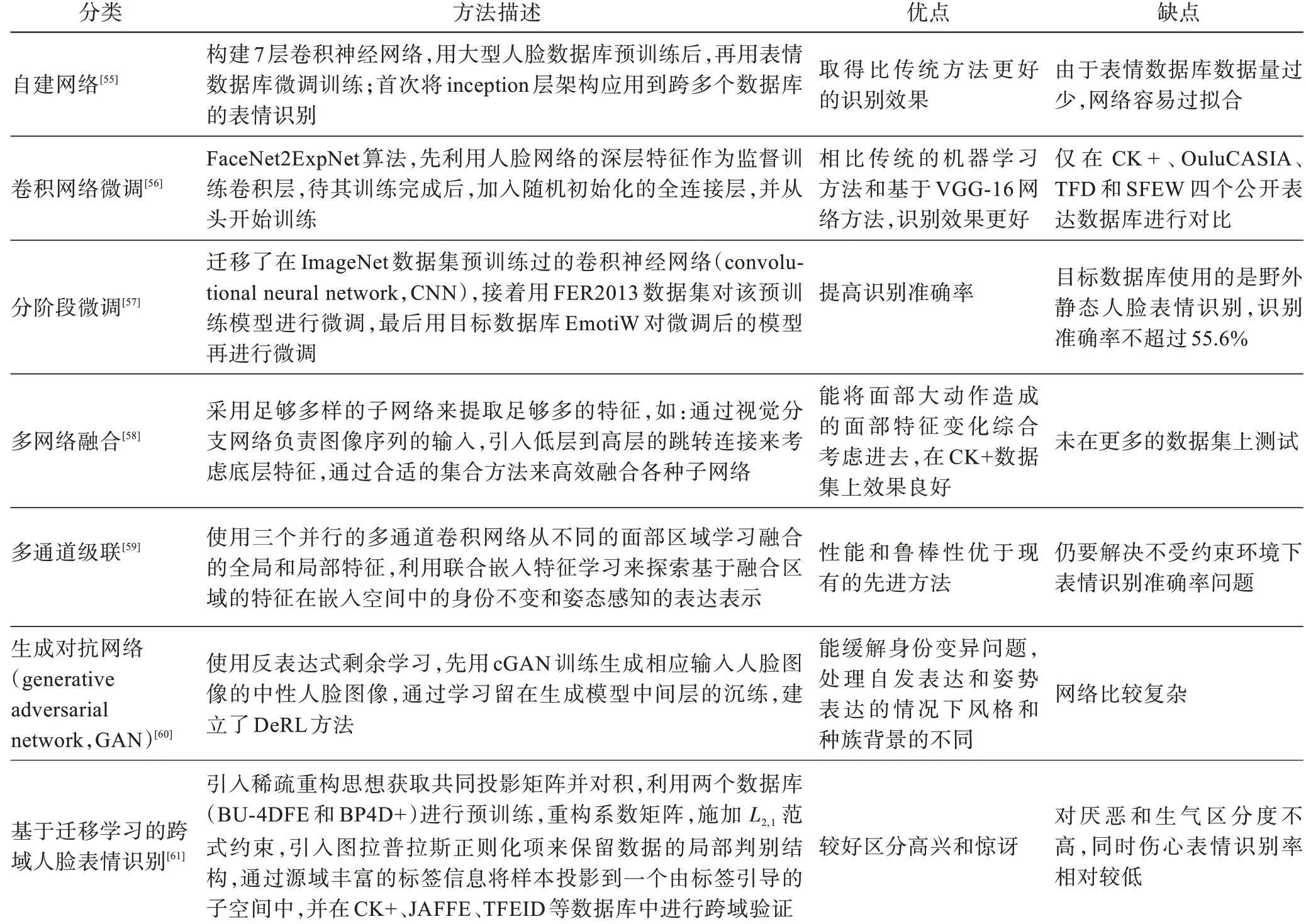
表3 基于深度学习表情识别方法Table 3 Expression recognition methods based on deep learning
基于单模态数据的表情识别准确率普遍不高,目前仍停留在实验室研究阶段,无法在实际生活中广泛运用。
2 基于多模态数据的面部表情识别
由上可知,基于单模态数据的表情识别具有一定的局限性,为了解决这些局限性,越来越多的学者们开始研究基于多模态数据的表情识别,希望能提高识别的准确率及稳定性。基于多模态数据的表情识别中,需要分别处理各模态的数据和对处理后的数据进行融合。在本文研究的多个模态中,有一个模态为面部表情数据。常见的辅助表情识别的模态有:语音、声音情绪、头部运动、手势识别、眼神交流、身体姿势、生理信号等。基于多模态数据的面部表情系统的处理框架如图2所示,该系统包含各个模态特征提取及模态信息融合。需要注意的是,单一模态数据的处理效果和多模态融合方式都很重要。在特征提取阶段,表情识别分析所采用的方法与上述基于单模态数据的面部表情的特征提取方法相同,模态融合的过程主要有三种方式:基于特征级、决策级以及混合。下面将分别总结常见的多模态数据集、多模态表情识别技术、模态融合技术等。
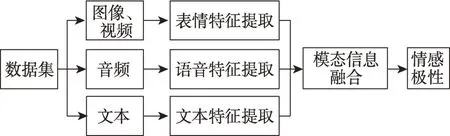
图2 多模态表情识别的框架Fig.2 Framework of multimodal expression recognition
2.1 多模态数据集
本文中所提到的多模态数据集应包含表情图片或视频作为其中一个模态,具体数据集总结如表4。
表4 中的多模态数据集都有表情视频或图像模态,辅以文字、音频、脑电、身体姿态等模态中的一个或多个,收集渠道有实验室录制、网上视频录制、实际环境中录制,包含有情绪或情感标签,基本都是小数据集。其中,数据模态的缩写规定如下:视频(video,V)、生理信号(physiological signal,PS)、音频(audio,A)、文字(text,T)、身体动作(body movement,BM)、面部动作(facial movements,FM)、图像(image,I)等。
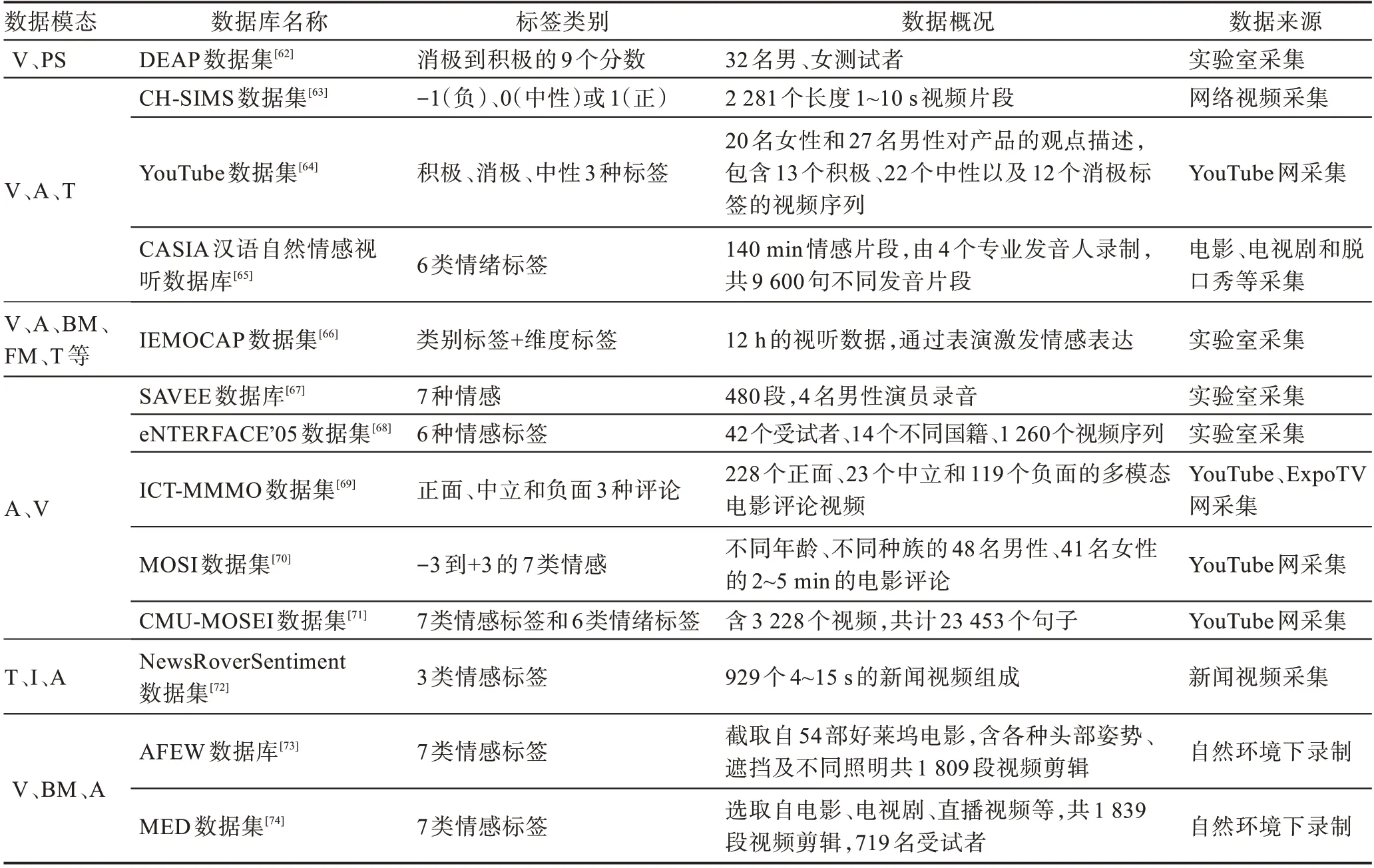
表4 多模态情感数据集Table 4 Multimodal affective datasets
2.2 基于多模态数据集的表情识别技术
现有的文献中,基于多模态数据集的表情识别技术主要根据面部表情、文本、语音以及脑电等的一个模态进行分析。文献[75-77]针对视频和音频模态进行分析,文献[78-79]针对视频和脑电模态进行分析,文献[80]针对表情视频和多模态传感器采集数据如眼动跟踪器、音频、脑电图(electroencephalogram,EEG)、深度相机等模态进行分析,具体分析方法及优缺点如表5 所示。文献[80]采用的视觉和非视觉传感器集成到面部表情识别的整体框图如图3 所示。由表5 及图3 可知,基于多模态数据集的情感识别与融合虽然能够在一定程度上解决基于单模态表情识别的局限性,然而仍存在系统较复杂、识别准确率不够高等问题,需要进一步解决。
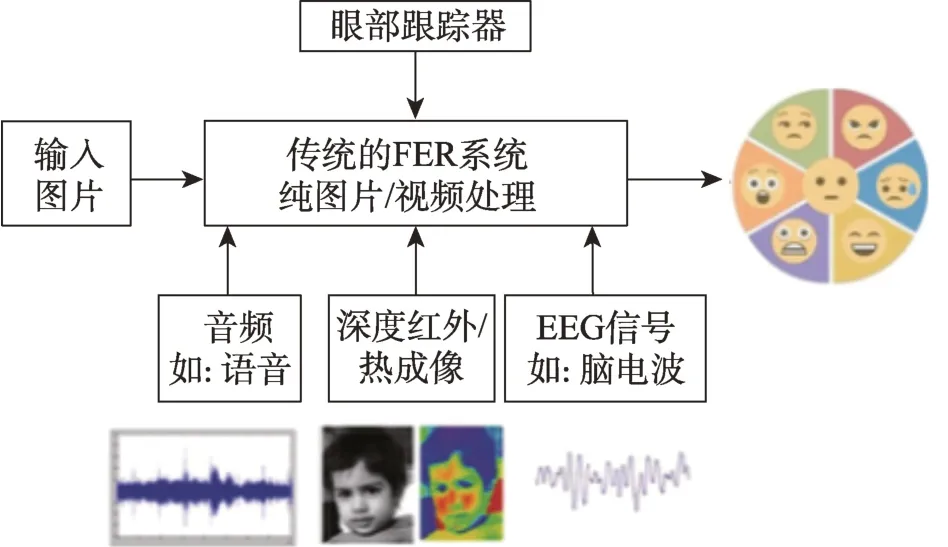
图3 视觉和非视觉传感器集成到面部表情识别Fig.3 Integration of visual and nonvisual sensors into facial expression recognition
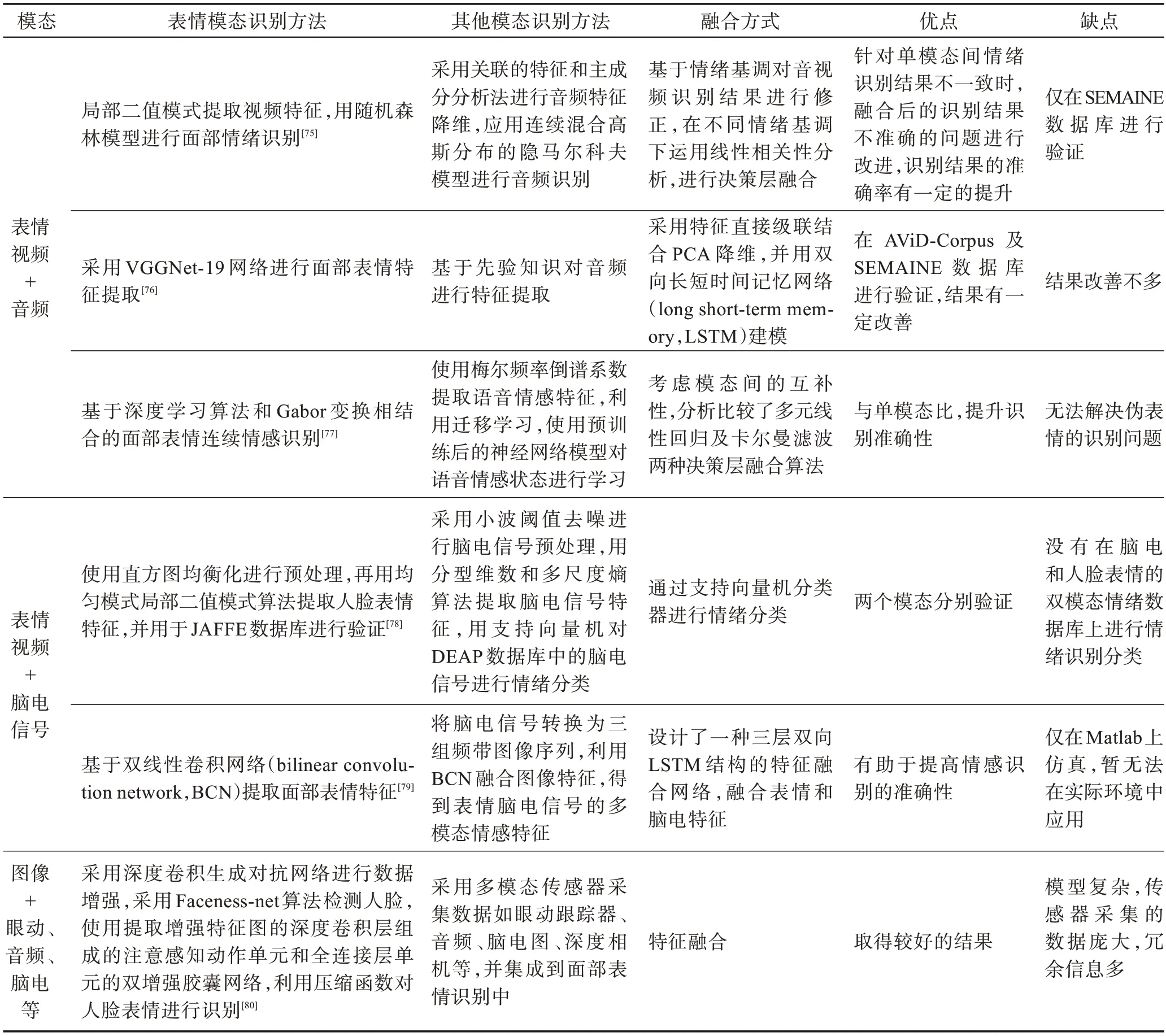
表5 多模态情感识别Table 5 Multimodal emotion recognition
2.3 多模态数据的融合方式
在基于多模态数据的表情识别中,除了各个模态的特征识别外,模态融合也是十分重要的。因此选择合适的模态融合方式可以提高识别的准确性及稳定性,融合是从不同模态中提取信息集成多模态特征。常见的融合方式有:特征级的融合、决策级的融合和混合融合等。
特征级的融合属于中间层级的融合,通常需要从原始信息中提取有效的特征,然后对这些特征信息进行分析和处理。特征级的融合对信息压缩有利,提取的特征与决策分析直接相关,因此,特征级的融合结果能为决策分析提供所需的特征信息,但是当不考虑模态间的关联性,直接将各模态的特征进行级联时,且当过多模态融合时,其产生的特征向量可能产生维度灾难。其融合框图如图4 所示。
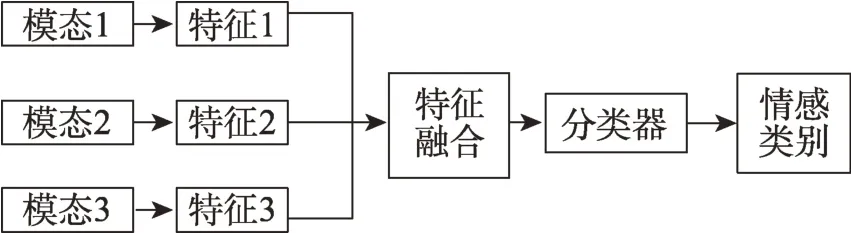
图4 特征级的融合框图Fig.4 Fusion block diagram of feature level
多模态情感识别方法中,研究者大量使用基于特征级的融合方法,但大多研究是将不同模态的特征直接级联,鲜少考虑模态间的信息互补关联。文献[85]利用开源软件OpenEAR、计算机表情识别工具箱进行语音和面部的情感特征的提取,删除视频中出现频率低的单词,剩余单词与每个话语转录内频率的值相关联,得到简单的加权图特征作为文本情感特征,并使用特征级融合法将三种特征融合,利用支持向量机分析得到情感极性。具体实现过程如图5所示。
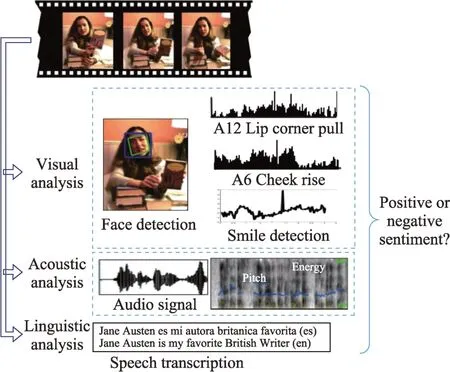
图5 多模态特征提取Fig.5 Multimodal feature extraction
文献[86]通过挖掘话语前后视频页面的关系,提出了基于LSTM 的情感分析模型。进行特征提取时,先用text-CNN、3D-CNN 和openSMILE 分别对单模态文本、图像、语言数据进行特征提取,这提取的是上下文无关的特征向量;然后将这些特征输入LSTM 网络捕捉上下文之间的关系;最后进行特征融合得到判断的结果。具体实现过程如图6所示,其中Contextual LSTM 的实现过程是:首先将数据输入到LSTM 中,得到了一个上下文有关的特征,然后经过全连接层得到一个预测结果,再进行一个Softmax得到预测概率。具体实现过程如图7所示。
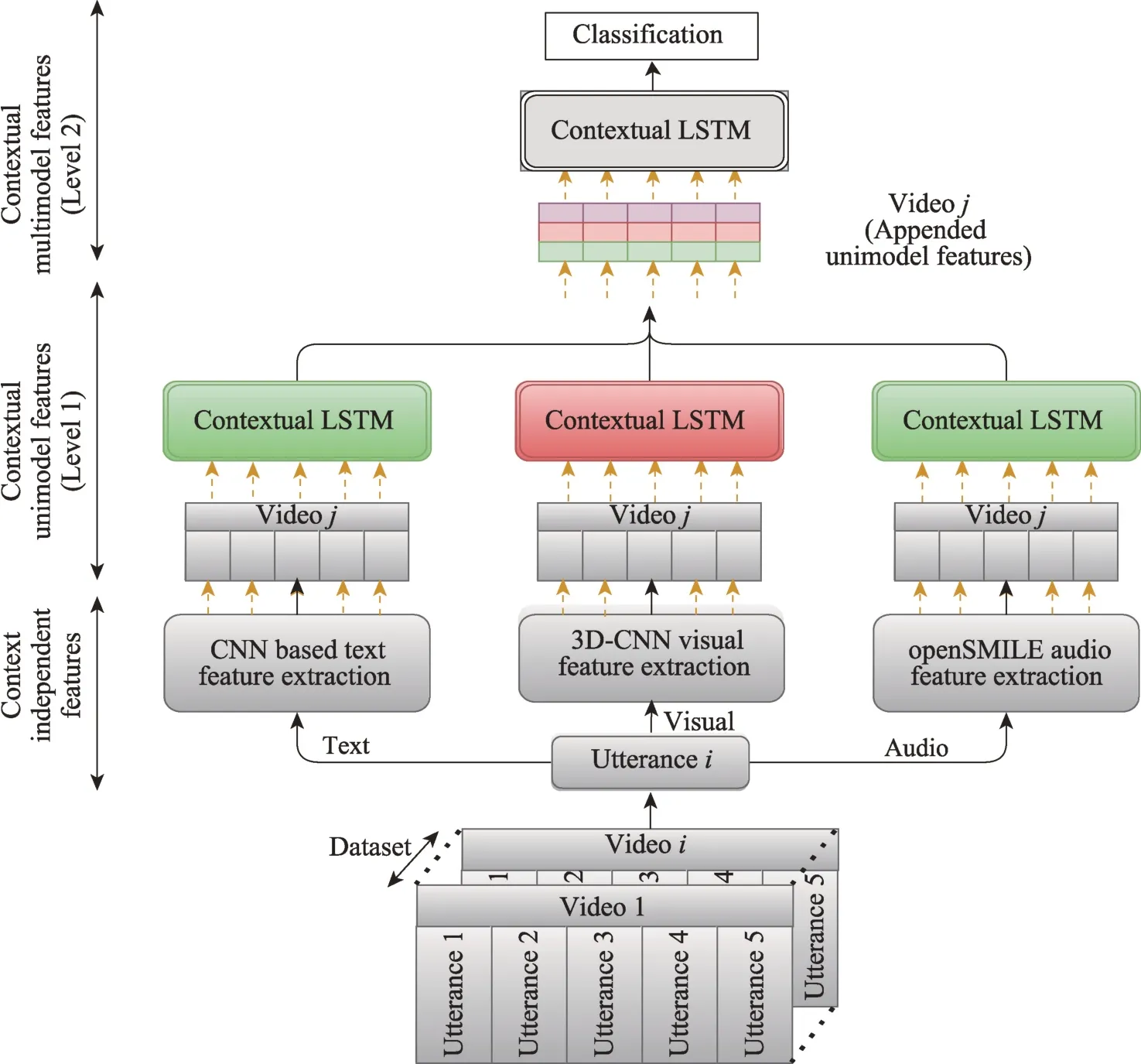
图6 提取上下文相关多模态话语特征的层次结构Fig.6 Hierarchical architecture for extracting context dependent multimodal utterance features
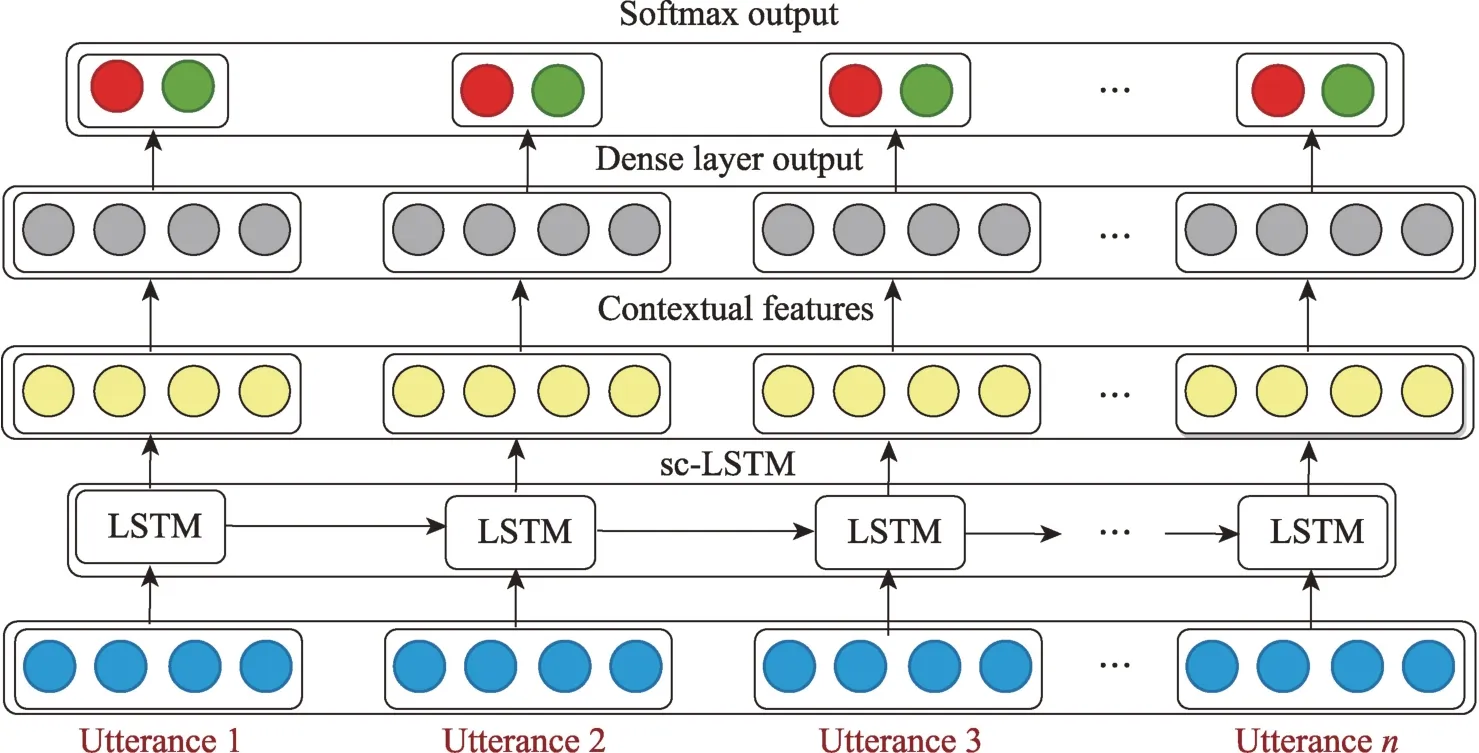
图7 Contextual LSTM 网络Fig.7 Contextual LSTM network
文献[87]提出了能识别面部表情、姿态、身体动作和声音的多模态情感识别框架,利用级联三维卷积神经网络以及深度置信网络得到新的深度时空特征,对视频和音频等呈现的时空信息进行有效建模实现情感识别,并且提出了一种基于双线性池理论的新的音视频特征级融合算法,在多模态情感数据集eNTERFACE 以及FABO 中,都取得了不错的结果。
文献[88]提出了一种基于深度置信网络的多模情绪识别方法。如图8,首先,对语音和表达式信号进行预处理和特征提取,获得单模信号的高级特征;然后,利用双模态深度置信网络融合高级语音特征和表达特征,得到用于分类的多模态融合特征,并去除模态之间的冗余信息;最后,利用LIBSVM 软件对多模态融合特征进行分类,实现最终的情感识别。在多模态特征融合阶段,采用3 个隐藏层的多模态融合深度置信网络(deep confidence network,DBN)结构。在初始阶段,两个DBN 网络分别训练。当训练到第三隐含层时,将第三层的两个特征值结合起来输入到后面反向传播(back propagation,BP)层。在微调阶段,根据分类器的实际输出对第三隐藏层进行微调。从第三隐含层到两个DBN 各自的隐含层,进行微调。最后,提出了一种基于DBN 的多模态融合情感识别模型。DBN 训练后,确定其权重和偏差。对于训练样本和测试样本,输入DBN,通过第三隐藏层提取的特征值为多模态融合后的特征值。然后进入LIBSVM 分类器进行情感分类。但数据集采用的是《老友记》十季的视频片段,同一个人的脸部细节发生了变化,给表情识别带来了更多的困难。

图8 多模态情感识别模型总体架构Fig.8 Overall architecture of multimodal emotion recognition model
决策级的融合通常是指对单模态的信息进行逐个预处理及特征处理,然后经过分类器,得到各自的分类结果后,再将各自的分类结果按照某种形式进行融合,得到最终的情感分类结果。由于各个模态的分类结果的量纲等通常是一致的,决策级的融合相较于特征级融合更为简单,但是决策级融合往往只是对单模态的情感识别结果进行二次加工,并没有对数据本身的特点进行充分挖掘,产生结果容易受到某一模态的情感识别效果的影响。决策级的融合框图如图9 所示。
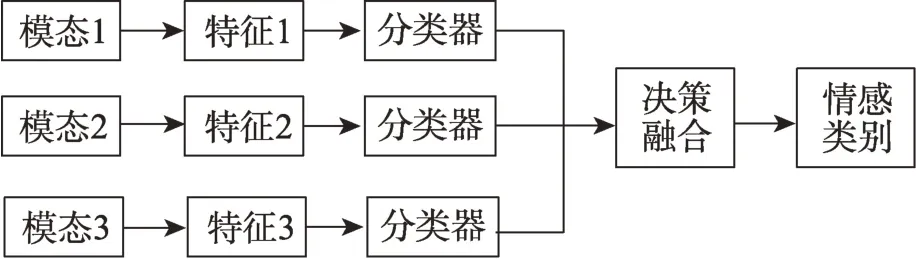
图9 决策级的融合框图Fig.9 Fusion block diagram of decision level
文献[89]利用了三个模态(视频、音频、文本)的组合特征向量来训练一个基于多核学习的分类器,同时提出了一种并行决策级数据融合方法,能更快得到结果,但是准确率有待进一步提高。
文献[90]提出了一种融合面部表情以及血容量脉冲BVP 生理信号的多模态情感识别法。该方法先对视频进行预处理获取面部视频,然后对面部视频分别提取局部二值模式-3 维正交平面(local binary patterns from three orthogonal planes,LBPTOP)、梯度方向直方图-3维正交平面(gradient direction histogram-3D orthogonal plane,HOG-TOP)两种时空表情特征后,送入BP 分类器进行模型训练;同时,利用视频颜色放大技术获取血容量脉冲(blood volume pulse,BVP)信号,并提取生理信号情感特征,将特征送入BP 分类器进行模型训练。最后将分类器得到的结果用模糊积分进行决策级融合,并得出识别结果。具体实现流程如图10 所示,但是生理信号情感判别的准确率还是偏低。
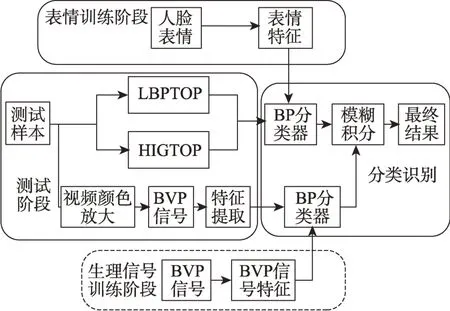
图10 双模态情感识别系统流程图Fig.10 Flow chart of dual-modality emotion recognition
混合融合是指将特征级的融合和决策级的融合相结合,比如,某个分类器可以对面部模态和身体手势模态进行特征级的融合,另一个分类器对语音模态、生理信号模态进行特征级融合,这两个分类器上有另外的决策级分类器可以处理两个特征级分类器的结果,并最终得到情感标签。混合融合的模型难度和复杂度比较高,能结合特征级的融合和决策级的融合的优点,混合融合框图如图11所示,但实用性较差。
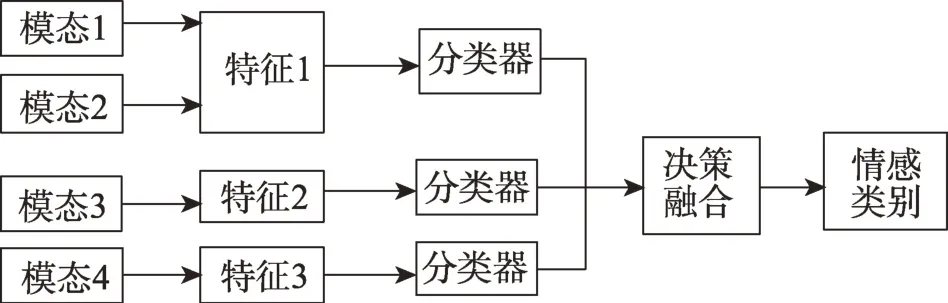
图11 混合融合框图Fig.11 Hybrid fusion block diagram
文献[91]引入了面部表情、皮肤电反应、脑电图等模态进行多模态识别与融合,采用基于混合融合的多模态情感分析,其中,采用CNNF 模型训练面部表情信号,采用CNN模型和CNN模型训练EEG 和皮肤电反应(galvanic skin response,GSR)信号,加权单元分别计算CNN模型和CNN模型输出的化合价和加权和,然后将结果送到距离计算器计算情感距离,并与CNN模型得到的面部识别结果一起送到决策树进行决策融合得到情感类别。文献[91]提出一种多模态情感识别的混合融合方法,采用潜在空间特征级融合方法,保持各模式之间的统计相关性,寻找共同的潜在空间来融合音频和视频信号,采用基于DS(Dempster-Shafer)理论的证据融合方法来融合视听相关空间和文本模态。该方法解决了声像信息的冗余和冲突的问题,兼顾了特征级和决策级的融合,但存在DS 融合方法的证据冲突问题。
3 总结与展望
随着计算机处理能力的不断提升,深度学习网络及融合算法的不断改进,基于多模态的数据的表情识别将得到快速的发展,本文通过总结基于单一模态数据的传统面部表情特征提取方法、基于单一模态的深度学习算法、基于多模态数据的表情识别与融合算法,将面临的挑战和发展趋势归纳如下:
(1)人脸图片的影响因素有很多,如角度旋转、遮挡、模糊、光线、分辨率、头部姿势、个体属性差别等,这些数据的处理技术不成熟,影响表情识别的进展。
(2)基于多模态的数据集偏少,大部分数据集大多是由视觉、文本、语音等模态的数据组成,姿势、脑电波及其他生理信号等模态的数据少。
(3)数据集中的数据分布不均衡,常见的高兴、伤心的表情多且容易识别,愤怒、蔑视等表情少且难捕获。
(4)现有的模态融合技术往往没有深入挖掘模态之间的相关性,以提高表情识别的准确性。
(5)算法大多十分复杂,在多模态数据分析过程中,如果选用的模态过多,则融合的算法就十分复杂,如果选太少,可能无法提高识别准确率。
(6)基于单模态数据的处理方法及各模态间的融合算法的选择是影响识别准确率的关键因素之一。各个步骤算法的选择都很重要。
针对上述观点,今后可以在如下几个方面做进一步的研究。
(1)构建更多自然环境下高质量的表情数据集或3D 人脸表情数据集,进一步解决角度旋转、遮挡、光线、头部姿势及个体属性差异等复杂情况下的表情识别准确率不高的问题。如:加入智能传感器用于解决诸如照明变化、主体依赖和头部姿势等重大挑战。
(2)构建基于含姿势、脑电波及其他生理信号等模态的多模态数据集,并研究多模态之间的模态相关性,以提高模型的泛化能力。
(3)未来与来自三维人脸模型、神经科学、认知科学、红外图像和生理数据的深度信息相结合,可以成为一个很好的未来研究方向。
(4)改进现有的表情识别技术,利用GAN 网络提高表情数据增强,解决表情数据量不平衡的问题。
(5)如何确定自然欺骗性面部表情的正确情绪状态也是未来研究方面,随着微表情在心理学领域的发展,可将现有的技术应用于微表情的提取,制作微表情方面的数据集。
(6)改进模态融合时的权值问题,对不同环境下,给不同模态不同的权值分配也是模态融合重点研究方向之一。
(7)为了让机器更全面、更有效地感知周围的世界,需要赋予它理解、推理和融合多模态信息的能力,如语音、图像、气味和生理信号等。利用多模态融合特征提高跨媒体分析的性能,如视频分类、事件检测、情感分析、跨模态翻译等也是研究方向之一。同时,多模态信息融合所产生的特征冗余、缺少关键特征等问题仍有待解决。
(8)基于多模态数据和深度学习网络的表情识别技术需要大量的优质数据集及计算力,如何将复杂的基于多模态数据的算法部署在计算资源有限的机器人终端上,研究如何对神经网络进行剪枝及轻量化,也是未来的研究方向之一。
4 结束语
本文对现有的面部表情识别领域的研究成果进行总结,归纳出基于单模态数据集和传统机器学习的表情识别技术、基于单模态数据集和深度学习的表情识别技术、基于多模态数据集表情识别技术及模态融合技术等领域的成果,概要地介绍了多模态数据库。最后,对当前表情识别存在的问题与挑战进行总结和展望,指出后续表情识别的一些研究方向,如非正面人脸表情识别、微表情、多模态情感分析、轻量级神经网络等。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
动漫星空(2018年9期)2018-10-26 01:17:14
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
发明与创新(2015年33期)2015-02-27 10:40:09
奇闻怪事(2014年5期)2014-05-13 21:43:01
电测与仪表(2014年15期)2014-04-04 12:05:20
