
基于改进ELman神经网络的台风风暴潮损失测度❋
2022-08-15 06:36:04郝婧,刘强
中国海洋大学学报(自然科学版) 2022年8期
郝 婧, 刘 强
(中国海洋大学工程学院, 山东 青岛 266100)
随着全球气候变暖加剧,中国沿海地区遭受台风风暴潮灾害频率不断增加,人员和财产的损失逐渐加大,严重威胁人民健康安全和经济社会发展[1]。因此,对台风风暴潮进行快速、有效和准确的损失评估,是保障海洋经济可持续发展刻不容缓的研究课题,是防灾减灾的重要环节。
灾害损失的评估方法在灾害理论上来说主要分为两大类,一类是基于统计模型的评估,另一类是基于风险关联的评估[2]。基于统计模型的评估,国外有FCHLPM[3]、FPHL[4]和HAZUS[5]模型等,国内学者赵昕等[6]运用投入产出模型从经济学角度进行了风暴潮损失评估分析。基于风险关联的评估,主要包括危险概率评估、脆弱性曲线和指标体系评估等[2]。Manik等[7]通过GIS分析物理和人口变量,评估了沿岸风暴潮的脆弱性;Yang等[8-9]基于扩展卡尔曼滤波和极限理论建立了中国风暴潮灾害风险预测模型,实现了对直接经济损失和伤亡人口的预测。目前,很多学者将机器学习方法应用于风暴潮损失评估。Sun等[10]、江斯琦等[11]、刘晓庆等[12]使用XGBoost算法、BP神经网络和ELman神经网络等机器学习方法有效的对风暴潮灾害的各方面损失进行定量预测。基于对已有的灾害研究,各模型均有其优缺点,为进一步提高传统模型的评估效果和普适性,本文应用天牛须搜索(BAS)算法优化ELman神经网络进行台风风暴潮损失测度,评估结果表明该方法进一步提高了预测精确度。
1 材料与方法
1.1 资料来源与指标选取
广东省坐落于中国东南沿海地区,位于太平洋西岸,每年台风风暴潮的成灾率高且经济损失过重,因此本文选取了广东省1995—2018年的50组记录完整的台风风暴潮信息及损失数据。其中台风风暴潮信息、灾害损失和气候数据主要来源于自然资源部和《中国风暴潮灾害史料集》[13],人口、设施和经济等数据主要来源于广东省统计局。
快速准确的测度灾害损失的前提是建立合理全面的灾害损失指标体系,依托风险评估理论,结合台风风暴潮的形成机制和实际数据的易取性,从气候变化、危险性、易损性和防灾减灾能力4个角度构建损失评估指标体系。其中,气候变化5个指标包括X11沿海海平面高度、X12年平均降雨量、X13年平均气温、X14年日照时数、X15二氧化碳浓度;危险性6个指标包括X21最大增水、X22中心最低气压、X23最大风力、X24最大风速、X25超警戒水位、X26灾害过程持续日数;易损性8个指标包括X31总人口、X32人口密度、X33人口自然增长率、X34地区生产总值、X35人均地区生产总值、X36海洋生产总值、X37耕地面积、X38大陆海岸线长度;防灾减灾能力6个指标包括X41森林覆盖率、X42医疗卫生机构数、X43卫生机构人员、X44医疗机构床位数、X45人均可支配收入、X46电话普及率。灾情选取了X01受灾人口、X02死亡(含失踪)人数、X03直接经济损失、X04农田受灾面积、X05海水养殖受灾面积、X06海岸工程损毁、X07倒塌房屋、X08船只损毁8个指标进行损失评估。
1.2 构建损失评估指标体系
1.2.1 熵权法-灰色关联分析 灾害损失的发生由多种因素导致,单一的指标无法全面刻画灾害信息和社会因素,但简约冗余因素可以提高预测效率和评估准确性。灰色关联分析法对于小样本无规律评价问题具有较高的决策准确性,是建立在客观数据的基础上,计算评价指标与最优理想方案的接近度[14]。针对于本文选取的8个灾情评估指标,原始的灰色关联分析使用平权处理或专家打分计算关联度,不能使权重达到最好的分配。但熵权法可以充分利用客观数据的信息来确定权重,进行客观赋权,避免了主观臆断对结果的影响。
1.2.2 影响因子预处理 根据熵权法的公式步骤[14],计算出灾情评估8个因子的权重,如表1所示。将灰色关联分析中灾情评估的8个因子赋予权重后,根据步骤[15]得出各评价指标的关联度进行排序,筛选出前12个指标为预测的输入因子,其中:气候变化相关因子包括年平均降雨量X12、年平均气温X13、年日照小时X14、二氧化碳浓度X15;危险性相关因子有最大增水X21、超警戒水位X25、最大风速X24、最大风力X23、灾害过程持续日数X26、中心最低气压X22;易损性相关因子包括人口自然增长率X33;防灾减灾能力相关因子包括森林覆盖率X41(见表2)。

表1 灾情评估指标的权重值Table 1 Weight value of disaster assessment index

表2 前12个指标的关联度Table 2 Correlation degree of top 12 indicators
2 台风风暴潮灾害损失测度
2.1 ELman神经网络原理
ELman神经网络是在1990年由ELman提出的动态递归神经网络,在前馈网络结构的隐含层中增加了一个承接层,作为延时算子来记忆和存储隐含层前一时刻的输出值,使该网络具有时变特性,相比前馈式BP神经网络具有更强的网络稳定性和计算能力[16],其结构如图1所示。
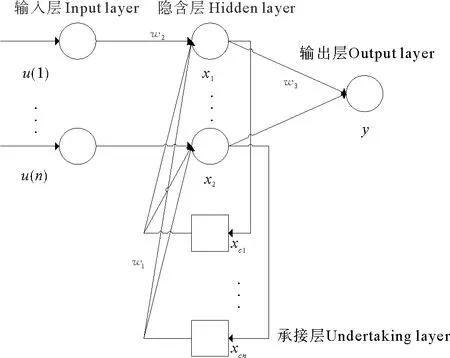
(u1为第一个输入层的输入向量;un为第n个输入层的输入向量;x为隐含层节点向量,xc1为第一个承接层的反馈状态向量;xcn为第n个承接层的反馈状态向量;y为输出层的输出向量;w1为承接层到隐含层的连接权值;w2为输入层到隐含层的连接权值;w3为隐含层到输出层的连接权值。u1 is the input vector of the first input layer; un is the input vector of the nth input layer; x is the hidden layer node vector; xc1 is the feedback state vector of the first undertaking layer; xcn is the feedback state vector of the nth undertaking layer; y is the output vector of the output layer; w1 is the connection weight from the undertaking layer to the hidden layer; w2 is the connection weight of the input layer to the hidden layer; w3 is the connection weight from the hidden layer to the output layer.)
Elman神经网络的数学模型表达式为:
y(n)=g(w3x(n)),
(1)
x(n)=f(w1xc(n)+w2(u(n-1))),
(2)
xc(n)=x(n-1)。
(3)
式中:y为输出层的输出向量;n为输入层的样本数量;g为输出层神经元的传递函数;w1、w2和w3分别为承接层到隐含层、输入层到隐含层和隐含层到输出层的连接权值;x为隐含层节点向量;xc为承接层的反馈状态向量;f为中间层神经元的传递函数,常采用Sigmoid函数。
2.2 BAS原理
天牛须搜索(Beetle Antennae Search,BAS)算法[17]是受天牛觅食原理启发的新型智能算法,天牛无法分辨食物的方位,需依靠食物气味的强弱来找到食物。食物的气味相当于函数,此函数在三维空间的任意不同值点,天牛通过两须感知气味的强弱,目的是寻找空间内气味值最强的点,通过这一原理来求解函数的最优值。
BAS算法步骤如下[18]:
(1)建立天牛须朝向的随机向量且归一化处理:
(4)
式中:n为空间维度;rands为随机函数:
(2)建立天牛左右须空间向量:
(5)

(3)确定均方根误差MSE为适应度函数fitness来判断左右须气味强弱,函数表达式为:
(6)

(4)迭代更新天牛位置:
(7)
式中:δt为第t次迭代时的步长因子;sign为符号函数。
2.3 BAS-ELman神经网络模型建立
传统ELman神经网络进行训练时,连接权值和阈值通常依赖于训练者的试错训练和先验经验,没有一定的理论基础依据,往往导致全局搜索性差且易导致训练失败。BAS算法作为高效的全局寻优算法,其优化后的权值阈值能较大程度的提高训练效果和网络性能,避免随机初始化导致网络陷入局部最优、网络不稳定等问题。
BAS-ELman模型构建具体步骤如下[16,18]。
(1)确定ELman网络的拓扑结构。
(2)建立天牛左右须空间向量和设置步长因子。
(3)确定均方根误差MSE为适应度评价函数f,迭代停止时函数值最小的味值为该模型最优解。
(4)迭代更新得出最优解,判断适应度函数值是否达到精度要求,满足则生成最优解,否则继续迭代更新。
(5)将BAS算法优化后的最优权值阈值带入ELman神经网络进行二次训练,直至误差收敛至给定精度,训练结束,形成最终的台风风暴潮损失测度模型。
2.4 损失评估与分析
本次实验按时间序列选取较近年份的10个样本为测试集,其余40个样本为训练集,神经网络部分使用MATLAB自带的神经网络工具箱。使用熵权法-灰色关联分析筛选的12个指标作为输入因子,灾情评估中的受灾人口、直接经济损失、海水养殖受灾面积、海岸工程损毁分别作为输出因子。引入均方根误差(Root mean square error, RMSE)进行参数选择,归一化均方根误差(Normalized root mean square error, NRMSE)、相关系数(Related coefficient, CC)和单次运行时间作为模型评估的检验指标。NRMSE越接近于0、CC越接近于1的预测效果越好,精确度越高,计算公式如下[19]:
(8)
(9)
经过多次反复实验,受灾人口评估的BAS-Elman神经网络采用12-2-1的结构,步长更改系数eta为0.994;直接经济损失评估模型采用12-5-1结构,eta为0.988;海水养殖受灾面积评估模型采用12-10-1结构,eta为0.99;海岸工程损毁评估模型采用12-3-1结构,eta为0.995,迭代次数和d0均为200次和0.5。
为了测试BAS-ELman(以下均称:优化BAS-Elman)模型相较于其他算法是否具有优越性,本文选择传统的ELman神经网络、BAS-BP、随机森林(Random forest,RF)和支持向量回归(Support vector machine for regression,SVR)模型进行比较。同时,为了体现熵权法对灰色关联分析客观赋权的有效性,采用传统平权处理的灰色关联分析筛选出12个新输入因子后的模型,作为对比BAS-ELman(以下均称:BAS-Elman)模型。结果见表3、图2所示。
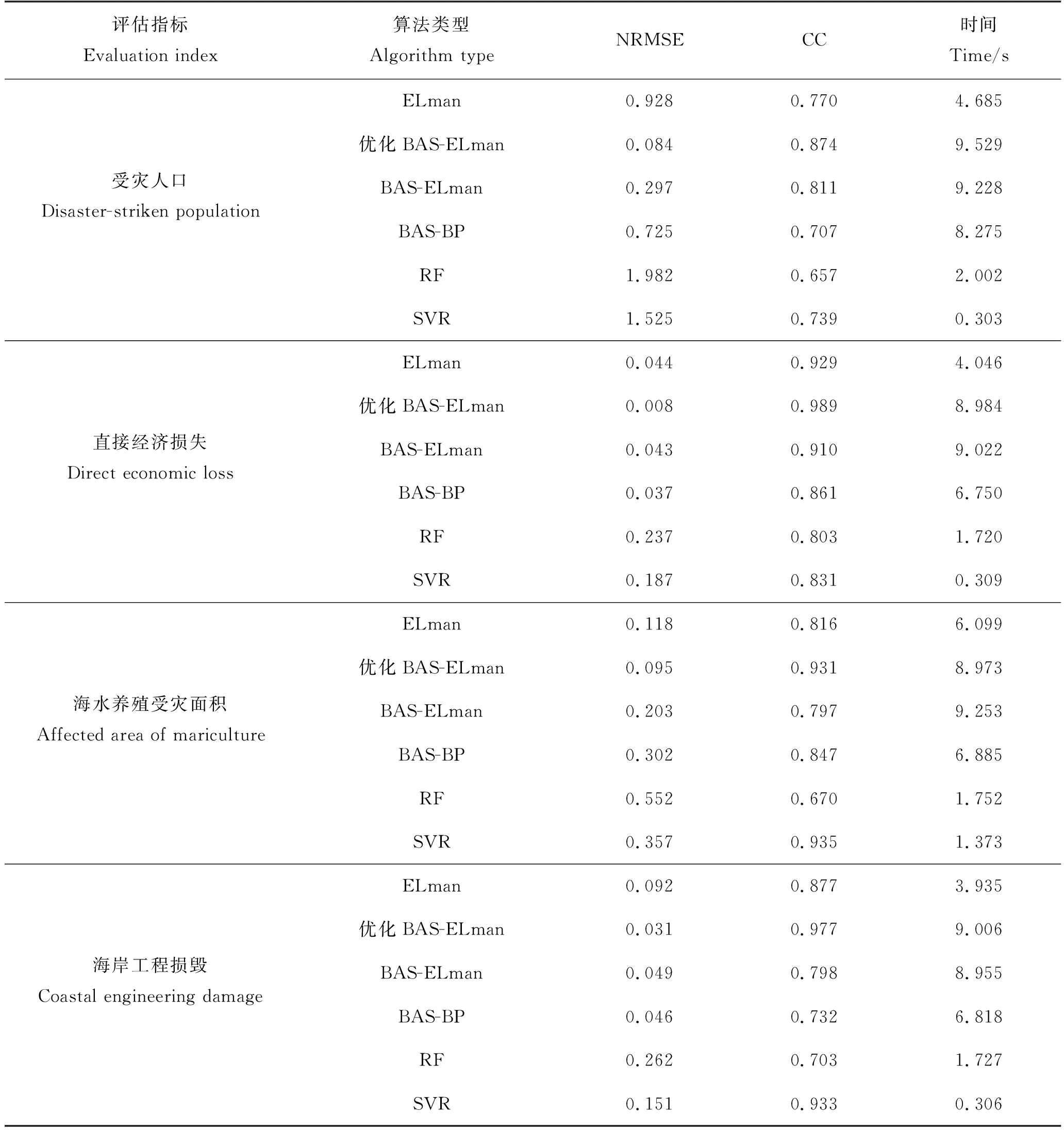
表3 四种损失指标测试集拟合结果Table 3 Fitting results of four loss indicators test sets
综上可以看出,4种灾情评估指标均呈现优化BAS-ELman相比于传统的ELman的拟合效果更好,NRMSE平均优化0.241,CC平均提高0.095;优化BAS-ELman相比于BAS-BP的误差更低,NRMSE平均优化0.223,CC平均提高0.156;优化BAS-ELman的预测效果优于随机森林模型,NRMSE平均优化0.704,CC平均提高0.235;优化BAS-ELman较支持向量回归模型的预测误差更好,NRMSE平均优化0.501,CC平均提高0.083,虽然支持向量回归模型在海水养殖受灾面积的预测CC值较优,但NRMSE值较大,因此从总体的拟合效果来看,优化BAS-ELman模型的预测准确性更高。熵权法客观赋权灰色关联分析的BAS-ELman模型比传统模型的预测精度要好,NRMSE平均优化0.094,CC平均提高0.115。单次预测的支持向量回归模型收敛速度最快,优化BAS-ELman模型相比于其他3个模型均较缓慢,但相差不大。从图2的多个峰值预测效果可以看出,对于中小型台风风暴潮的预测效果较好,但对于出现重大灾害时的预测效果还需提高。从4种评估指标和6个回归模型的整体预测效果来看,优化BAS-ELman回归预测模型的预测效果最佳、精确度较高,对台风风暴潮损失测度方面具有较高的适用性。
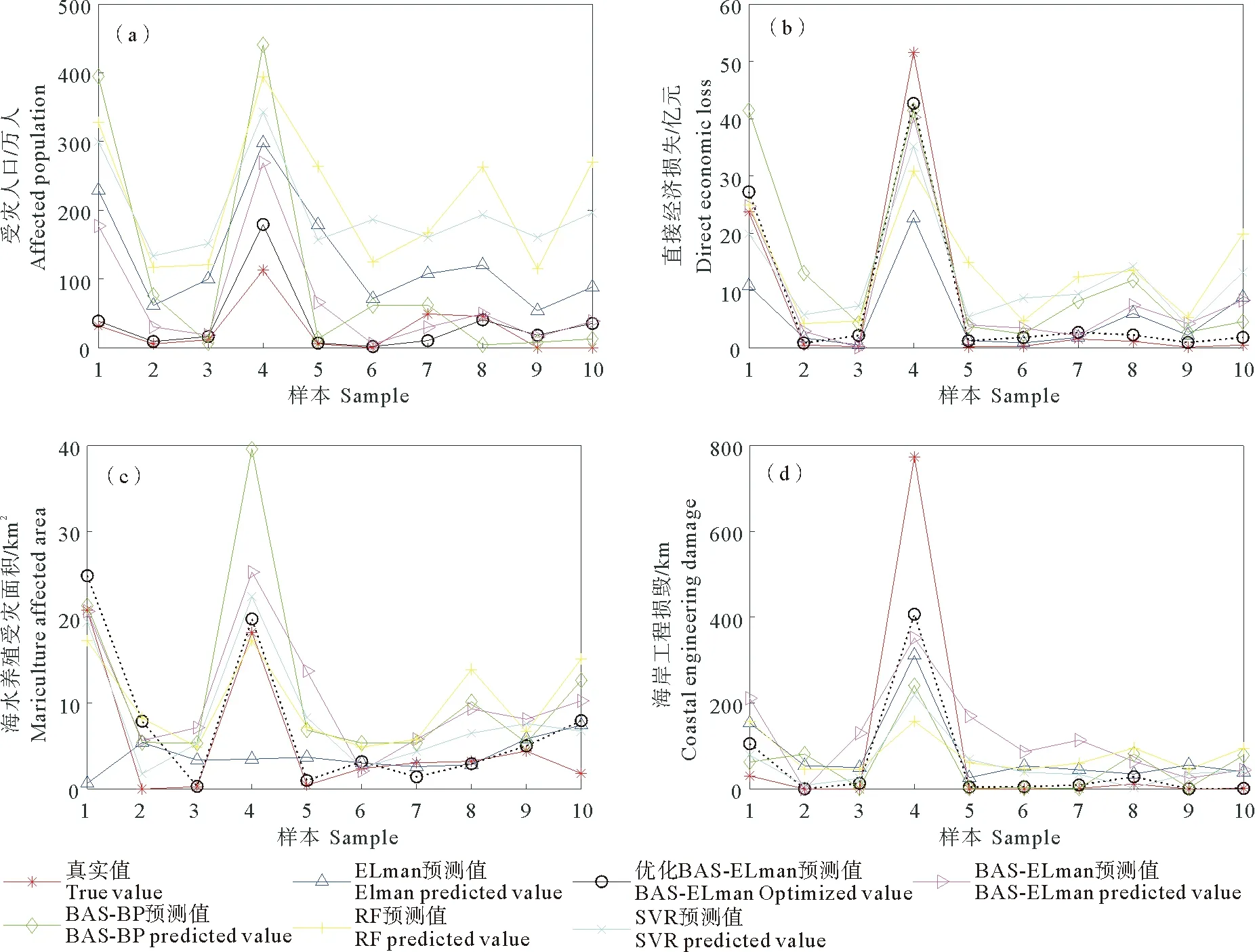
((a)受灾人口拟合结果Fitting result of affected population;(b)直接经济损失拟合结果Fitting result of direct economic loss;(c)海水养殖受灾面积拟合结果。Fitting result of affected area of mariculture;(d)海岸工程损毁拟合结果Fitting result of damage of coastal engineering.)
3 结语
本文从气候变化、危险性、易损性和防灾减灾能力4个方面构建台风风暴潮损失评估指标体系,基于8个灾情评估指标筛选主要影响因子,通过熵权法对灰色关联分析进行8个灾情评估指标的客观赋权,筛选出与灾害损失相关性较大的12个指标作为输入因子。经模型预测效果对比,表明熵权法优化灰色关联分析后筛选的指标有更好的评估效果。
使用BAS优化ELman神经网络预测模型,将优化后的权值和阈值带入ELman模型中,经对照传统ELman神经网络、BAS-BP、随机森林、支持向量回归模型的预测效果有较大提高,避免了ELman算法出现的随机初始化导致网络陷入局部最优的问题,预测模型具有较好的适用性。
本次实验较好的对受灾人口、直接经济损失、海水养殖受灾面积和海岸工程损毁4种台风风暴潮损失进行了测度,为今后研究提供了新的方法。但在样本数据搜集时,完整数据较少,重大灾情的评估样本不足,对模型整体影响较大。需提高输入指标的全面性,尤其气候类数据搜集应加强GIS和遥感工具的使用,进一步提高灾害损失测度的准确性,为防灾减灾工作提供依据。
猜你喜欢
江苏安全生产(2022年8期)2022-11-01 09:15:18
江西教育·职教版(2022年9期)2022-04-29 00:44:03
江苏安全生产(2021年6期)2021-08-05 07:47:14
海洋通报(2021年2期)2021-07-22 07:55:24
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
科学(2020年4期)2020-11-26 08:27:00
江苏安全生产(2020年5期)2020-06-15 09:38:52
海洋通报(2020年6期)2020-03-19 02:10:18
今日农业(2019年15期)2019-01-03 12:11:33
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
