
改进孪生BERT的石油钻井文献相似度分析研究
2022-08-15 04:06:54杨庆川
吉林大学学报(信息科学版) 2022年2期
张 岩, 王 斌, 杨庆川, 李 玮
(1. 东北石油大学 a. 计算机与信息技术学院; b. 石油工程学院, 黑龙江 大庆 163318; 2. 安达市庆新油田开发有限责任公司 数据管理中心, 黑龙江 安达 151413)
0 引 言
石油钻井是一门专业性很强的复杂系统性工程学科, 涉及许多基础理论及新技术的应用, 该领域科研人员面临的文献具有交叉学科多且专业理论性强的特点。随着研究的扩展与深入在该领域中积累的文献数量呈指数级增长, 如何提高文献的检索效率, 把握相关研究方向的文献发展动态, 避免重复科研是非常重要的问题。常规的文献检索通常从搜索研究主题的关键词或期刊来源出发, 包括特定的专业词汇、 期刊、 会议论文集或高质量的出版物等; 后续的研究工作通常会引用所检索到的相关出版文献, 此类模式可称为“滚雪球法[1]”。虽然常规的文献检索和滚雪球法可以检索出一些相关文章, 但如果检索词不标准、 语义模糊, 会导致检索结果存在偏差, 从而影响科研工作效率。文本相似性度量是解决该问题的一个重要途径, 是对文本或句子之间相似程度的评价, 其主要利用信息检索[2]等技术从文本中提取主要结构, 进行文本相似性的预测。在信息检索、 文本分类、 文档聚类、 主题检测、 主题跟踪、 问题生成、 问答、 论文评分、 简答题评分、 机器翻译等文本相关研究和应用中, 文本相似性度量发挥着越来越重要的作用[3]。
目前, 文本相似性度量方法分为3类[4]。1) 基于字符匹配方法, 以两文本字符匹配程度衡量文本间的相似程度, 主要方法包括最长公共子序列[5]、 N元模型[6]和汉明距离[7]等方法, 但此类方法仅考虑文本本身的字面相似性未考虑文本本身真实含义。2) 基于知识库计算文本相似度方法, 使用基于语义词典HowNet(知网)、 维基百科、 百度百科等知识库进行语义相似度计算, 虽然知识库有庞大丰富的语义信息, 但对特定领域知识库缺少相关技术词汇, 另外其信息驳杂数据噪声大, 导致计算效果相对不好。3) 基于语料库计算文本相似度方法, 通过从大型语料库获得的信息计算文本间的相似度, 对词语的上下文进行统计分析, 动态构建语义表示, 是文本相似度研究的热点。深度学习在文本处理方面表现出极高的性能, 目前结合深度学习方法进行文本相似度的研究已引起学者们的关注, 相关研究可以分为两类。1) 通过无监督学习算法Word2vec[8]和 Glove[9]方法将语料库中词语变为向量表示进行相似度计算, 此类方法不能动态对词向量进行构建, 一旦有新词需要进行向量表示, 需要对整体的语料库进行重新的计算。2) 有监督学习算法, 如DSSM(Deep Structured Semantic Models)[10]语义匹配模型, 其采用有监督方式对模型进行训练, 不需要在中间过程中做无监督模型映射, 因此精准度比较高。但DSSM采用词袋(BOW: Bag-Of-Words)模型, 在一定程度上损失语序信息及上下文信息导致效果难以进一步提高。由于中文文本内部包含了更加丰富的语义信息, 在中文文本相似度分析领域, 中文词向量语言模型对文本相似度分析的准确性更加重要。
BERT[11](Bidirectional Encoder Representation from Transformers)作为近年自然语言处理领域内在众多模型中性能突出的算法, 采用迁移学习方式, 通过将模型在通用语料库中训练得到预训练模型, 再使用文本标注数据对模型进行微调得到特定任务模型, 其在多个自然语言任务测试集上均取得优异的结果。虽然BERT在语义相似度任务上产生了较好的效果, 但其本身多头注意力机制的结构, 使其对长文本的计算产生了非常巨大的开销。对文献间的相似度度量任务, BERT需要将一对句子使用分割符将句子对拼接为一个整体作为模型的输入, 导致模型训练效率下降。孪生网络[12]结构已应用于许多度量学习任务中, 其通过将网络分为两个子网用于并行输入数据。可使用孪生网络结构将BERT作为两个子网络, 将成对句子分别输入两个子网络中以减少向BERT子网中输入的文本长度, 达到减少计算量, 提高训练效率的效果。
目前相似度度量方法用于石油钻井领域文献分析, 还存在如下两点主要问题: 1) 常规的文本相似度任务数据无需相关的专业经验就能完成数据集标注任务, 石油钻井文献相似度数据集专业性要求很高, 需要多年从业经验才能完成数据集的标注; 2) 文本相似度匹配任务中会采用池化方式将BERT模型输出的结果变为相同维度的向量表示进行相似度计算, 但通常的池化方式, 如最大池化和平均池化, 使最为突出的一个特征作为最后整句的文本表示, 而石油钻井文献通常涉及到多个学科知识, 因此其相似度应由文献中所涉及的相关学科依据重要程度共同表达的特征决定, 单个特征不能全面表达出这种文本间的相似性。鉴于以上分析, 笔者提出一种基于BERT孪生网络的注意力池化方法, 首先由专业人员对文献进行组织, 然后在原有的BERT模型基础上, 根据石油钻井领域文献的特点, 使用注意力池化方法全面考虑文本的全部特征, 通过向每个特征分配不同的注意力权重, 将文本特征进行加权融合, 并应用于文本相似度任务中, 使模型的预测效果更加准确。
1 样本数据组织
1.1 文献预处理
石油钻井文献样本的组织对相似性度量分析结果的影响很大, 样本组织过程可划分为文献样本预处理、 特征选择两个步骤, 而预处理步骤又包括文献采集与样本标定。
笔者在数据采集方面利用scrapy框架开发网络爬虫, 以“石油钻井”为主题词对石油钻井文献进行获取, 经过筛选并过滤干扰文献后得到544篇文献; 然后以此为源头, 对其引用文献及被引文献进行整理得到扩展文献列表。再使用爬虫检索扩展文献, 获取相关的标题、 摘要和关键字; 最后将源头文献与扩展文献做为样本数据。
在样本标定过程, 根据石油钻井文献的特点, 定义5个文献相似度评价指标对两篇文献的相似度进行度量: 1) 文献研究背景所涉及的理论基础和交叉学科是否相同; 2) 文献要解决的问题是否相近; 3) 文献所采用的方法是否类似; 4) 文献同时被另一文献所引用的数量(文献共引); 5) 文献都引用同一文献的数量(文献共耦)。将上述5个指标作为评估文献相似度的原则, 并依据指标相关程度的强弱对两文献间的相似度进行评分, 评分指标如表1所示。

表1 文献相似度评分原则
依据笔者所给出的相似度评估指标, 结合石油钻井领域的专业知识对文献的标题、 摘要、 关键词进行相似度标定, 标定示例如表2所示。

表2 样本相似度标定示例
相似度分数整体范围为0~5之间, 通过和标定后总计获得2 380条数据, 选取1 700条作为训练集, 340条作为验证集, 340条作为测试集。样本数据分布情况如图1所示。
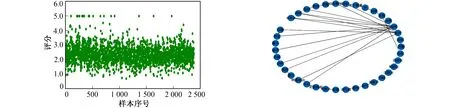
图1 石油钻井文献数据集样本分布 图2 关键词特征关系
1.2 特征选择
由于科研文献的标题、 关键字和摘要可以很好概括文献阐述的研究内容, 笔者对文献的标题、 关键字和摘要采用不同的方式对重要特征进行提取和处理。
1) 对文献的标题, 进行分词操作后再对去除标题中的停用词(停用词是指对文本分析不起作用的字符、 介词、 副词、 连接词之类的词), 去停用词后将会降低训练所需的词向量维度。
2) 对文献的关键词是作者本人深思熟虑所给出的, 能直指文献的核心主题, 代表文献的重要特征, 因此不进行分词处理。
3) 对文献的摘要首先对其进行分词, 分词后的摘要中各关键词特征间的关系图谱如图2所示。
笔者引入Textrank[13]算法提取摘要中的主要特征, 算法使用图模型表示为G=(V,E), 由关键词集合V与边集合E组成,E为V×V的子集。每个节点设置的初始权重为1, 其计算方法为
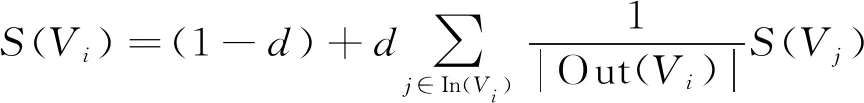
(1)
其中S(Vi)为文本Vi的权重,d为阻尼系数, 代表图中某一节点指向其他任意节点的概率, 一般取值为0.85, In(Vi)为Vi的链入节点, Out(Vi)为文件Vi的链出节点。
依据上述的文本特征提取方法, 分别计算词汇集合V中每个关键词的权重, 选取每个文本词汇集合中权重较高的前m个特征词, 并将所有摘要文本特征词与去除停用词后的标题及文献的关键词进行合并形成文献的整体特征集Cn, 表示一共包含n个特征的数据样本。
根据石油钻井文献的文本特性, 相似度不考虑情感分析的词性标注。最后将处理后的文献的标题、 摘要和关键词进行合并整理, 样本示例如表3所示。

表3 石油钻井文献主要特征样本示例
2 孪生BERT模型原理
石油钻井文献通常涉及到众多交叉学科, 孪生网络(Siamese network)可提取两篇文献中所涉及学科的共有特征。具有较强的非线性相似性度量学习能力, 可以高效自然地学习到成对文献之间的相似特征和单个文献独有的特征。笔者的模型整体架构采用孪生网络思想进行设计, 文本表示流程如图3所示。

图3 文本表示流程
2.1 BERT词嵌入层
为使模型更好理解石油钻井领域文献语义特征, 利用迁移学习的思想, 预训练模型采用全词的MASK策略(WWM:Whole Word Masking)[14], 在此基础上训练笔者模型。
BERT将输入样本文献特征的每个词条(token)[15]输入词嵌入层并转化为词向量, 采用3种词嵌入方式: 1) 字向量(Wtoken), 对应文本的每个字符构建词向量之后的相似度任务; 2) 文本向量(Wwords), 为单个构建句向量做分类任务; 3) 位置向量(Wposition), 将词的位置信息添加都模型中。模型同时使用3种向量表示, 使用归一化的方式将上述向量进行更加深层次的融合, 使用dropout方法进行随机丢弃使获得的词向量更加具有泛化能力, 将转化好的词向量表示输入至BertEncoder层表达式为
W=Wtoken+Wwords+Wposition
(2)
2.2 BertEncoder层
BertEncoder层使用自注意力机制(self-attention), 即注意力[16]机制从众多信息中找到与自身最相关的部分, 其整体算法计算流程如图4所示。

图4 自注意力机制处理计算流程
自注意力[17]是在Q(Query),K(Key),V(Value)3个矩阵相等的情况下挖掘句子的内在关系, 通过点积计算句子中每个单词的权重, 再将句子中的每个单词的向量进行加权, 计算公式为

(3)
其中dk为多头注意力机制的头数,QKT为Query的矩阵向量与Key的矩阵向量进行点积操作, 两项点积可表示两项的相似性, 表达式为
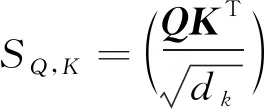
(4)
对点积后的结果进行适度的缩放, 防止做点积时结果太大, 计算方法为

(5)
计算结果通过softmax函数归一化为0~1之间的数值与value向量相乘作为attention计算的输出结果, 计算方法为
AAttention(Q,K,V)=sscaleV
(6)
自注意力机制大致的处理过程为, 首先将一个512维的句子分解成h个部分,h为多头注意力机制的头数, 每部分长度为512/h。然后分别计算每个部分分离开的Q,K,V的注意力权重, 多头注意力机制处理Q,K,V通过不同的线性变换对进行空间投影, 最后将每个注意力头的结果拼接在一起, 其计算表达式为

(7)

多头注意力机制允许模型加入来自不同位置的不同表示子空间的信息, 其计算方法为
MMulitHd(Q,K,V)=CConcat(h1,h2,…,hn)WO
(8)
其中WO为权重矩阵,CConcat(·)为拼接函数, 将向量进行拼接。
最后使用全连接层, dropout层和归一化[18](Norm layer)层完成多头注意力操作, 计算表达式为
MMulitHd(Q,K,V)=MMulitHd(Q,K,V)AT+b
(9)

(10)
其中γ和β为需要学习的参数。
上述输出结果进入线性层和激活函数后, 经过线性变换、 dropout和归一化后, 完成整体BertEncoder部分, 表示为

(11)
最后使用高斯误差线性单元(GELU: Gaussian Error Linear Units)作为激活函数, 表达式为
M=GGELU(M)=M*φ(M)
(12)
3 基于改进注意力池化层的孪生BERT网络
孪生BERT网络通过最后一层的池化层, 将两个子网的输出结果变为相同维度以进行两向量的相似度计算。可在保留重要信息的前提下, 减少数据计算量, 原本网络采用的池化方式为最大池化(max pooling)和平均池化(mean pooling), 这是使用最为突出的一个特征作为最后整个文献的特征表示, 但对石油钻井文献数据而言, 文献本身不仅有专业的理论基础知识, 还涉及相关交叉学科的理论知识, 导致两文献间相似度需要用多个重要程度不同的特征才能进行完整表达, 而不是仅适用最为突出的特征对文献间的相似度进行度量, 因此需要考虑每个特征对文献间相似度的贡献。
针对上述问题, 将注意力的思想引入BERT网络模型中, 采用注意力池化作为模型的池化层, 进行重要特征的抽取。网络整体结构如图5所示。
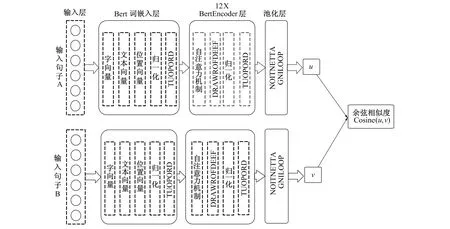
图5 改进的相似度度量网络结构
在文献特征经过BERT词嵌入层和BertEncoder层后, 整体特征的表示变为XCLS=[x1,x2,…,xi,…,xN], 文献中单个字符特征的表示变为Etoken=[e1,e2,…,ei,…,eN],xi,ei∈d,d为词向量的维度。 将XCLS和Etoken进行比较, 以计算注意力权重, 整体特征表示与每个局部表示之间的相似性越高, 分配给该局部表示的注意力权重就越大, 其计算方法为
αi=SSoftmax(sim(xi·ei))
(13)
其中αi表示注意力权重, 函数sim()用于度量其两个输入之间的相似性。本文模型中分别使用内积相似度和余弦相似度两种相似度评估函数进行相似度的计算, 最终注意力池化特征提取表示为

(14)
其中S表示注意力池化层输出结果。
最后通过两孪生子网注意力池化层的输出结果u,v计算两向量的余弦相似度表示为

(15)
4 实验结果与分析
4.1 实验相关参数
实验硬件采用英伟达2080 Super (8 GByte) GPU, 因特尔i7-9700k CPU, 软件使用Ubuntu 18.04.4系统, Python3.6语言, pytorch深度学习框架, 实验网络模型相关超参数配置如表4所示。

表4 超参数设置
笔者选用了皮尔森相关系数(Pearson)、 斯皮尔曼系数(Spearman)作为评价指标, 其计算方法为

(16)
其中X为预测值,Y为标签。

(17)
实验中的两种评价指标越大, 表明模型预测结果的准确率越高, 模型性能越好。
4.2 实验结果及分析
首先测试改进后的模型对石油钻井领域文献相似度计算的有效性, 通过引入不同的词向量、 注意力相似度评估函数, 以及不同的激活函数对模型准确率进行对比, 并与标准孪生BERT模型比较, 分析不同策略对模型效果的影响。
实验使用网络石油钻井文献作为数据样本, 词向量分别采用整句特征表示(CLS: Classification)与单个字符特征表示(token)两种方式。将不同改进策略与孪生BERT网络进行对比以测试提出算法性能。对模型进行50次训练获得实验结果如表5所示。

表5 不同改进策略效果对比
表5给出了在石油钻井文献数据集下, 不同池化方法在模型上的表现。表5中第1列为对模型及其改进策略, 第2、3列为注意力池化策略相应的相似度函数和激活函数, 第4~7列是在验证集和测试集中的皮尔森系数和斯皮尔曼等级相关指标结果。可见各种注意力池化操作对模型的效果均有所提升, 同时采用整句特征表示(cls)与单个字符特征表示(token)进行注意力池化操作优于其他方法。
为验证提出模型的收敛性, 采用皮尔森系数作为评价指标, 选取表5中效果最好的两种策略, 每种方法的epoch设置为300次, 实验结果如图6所示。

图6 网络收敛性能分析
从图6中可以看出, 当训练次数超过50次时, 效果仍能有所提升, 当训练次数达到300次时, 模型训练效果趋于稳定, 测试集结果如表6所示。采用Attention(token,cls)方法作为模型池化层在样本测试集中的标签值和预测值结果如表7所示。

表6 两种池化方法训练次数对比

表7 实验结果展示
为验证笔者提出的注意力池化层的泛化能力, 在STSbenchmark公共数据集(http:∥ixa2.si.ehu.eus/stswiki/index.php/STSbenchmark)上进行测试, 结果如表8所示。

表8 STSbenchmark数据集中测试效果
由表8可知, 使用注意力机制池化好于平均池化, 且有多种注意力池化方法都具有不错的效果, 证明笔者提出方法具有一定的泛化性能。
笔者模型效果在标准测试集上优于原始孪生BERT网络, 原因在于笔者模型更关注于多特征所表示出的整体语义表达, 适合石油钻井文献所表达的特征往往涉及到交叉领域的学科知识, 对公共数据集也具有一定的效果。
5 结 语
为研究石油钻井文献文本相似度问题, 笔者提出一种基于孪生BERT网络的注意力池化方法, 开发网络爬虫对石油钻井文献样本进行采集, 提出用5类文献相似度评估指标对样本文献进行综合标注, 并使用Textrank算法提取文献特征, 结合注意力机制的思想, 提出在文本转化为词向量过程中设计基于孪生BERT网络的注意力池化方法。实验证明, 采用注意力池化方法的孪生BERT网络能更好地依据特征的重要程度对其进行提取, 进而提升模型在石油钻井文献相似度评估上的效果。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
软件导刊(2022年3期)2022-03-25 04:45:04
海洋石油(2021年3期)2021-11-05 07:42:54
小哥白尼(趣味科学)(2019年5期)2019-08-27 02:46:54
计算机技术与发展(2019年1期)2019-01-21 00:56:38
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
西南石油大学学报(自然科学版)(2015年5期)2015-04-16 05:12:31
