
电力物联网用户侧数据深度挖掘方法研究
2022-08-15 04:06:30颜远海
吉林大学学报(信息科学版) 2022年2期
颜远海
(广州华商学院 数据科学学院, 广州 511300)
0 引 言
电力数据中蕴含着大量的有用信息[1], 随着电网信息化水平的不断提升, 在巨大规模数据集里挖掘有价值信息, 逐渐成为电网规划建设、 增容改建、 可靠运行的主要手段。计算机技术与信息技术高速发展, 推动了数据挖掘技术[2]在电力领域中的普及与应用, 使深层次的电网数据挖掘成为可能。
目前人们主要以确保电网平稳、 安全运行进行数据挖掘研究, 例如高翔等[3]与浦雨婷等[4]分别针对电力信息系统网络安全态势与电压暂降的评估问题, 以数据挖掘为技术支撑, 各自引入支持向量机与靶心度优化算法, 建立了电力信息系统网络安全态势评估模型与电压暂降严重度评估模型, 确保电网安全稳定运行; 而郭阳等[5]则从电力企业内部管理角度出发, 利用大数据挖掘技术, 提取电力企业的影响因素历史特征, 经聚类分析, 构建了电力企业评价体系, 为决策者提供可行的管理建议。
互联网技术的革新推动了电力系统与物联网的耦合发展, 电网用户规模日益庞大使用户侧数据量持续上升, 因此笔者针对电力物联网, 设计一种新的用户侧数据深度挖掘方法。关联规则是较为普及且有效的一种数据规律发现策略, 可使无法确切描述的信息都实现清晰展示, 且可提升挖掘精准度。
1 用户侧数据关联规则映射
为降低用户侧数据特征的挖掘复杂度, 以用户侧数据间的关联映射为依据, 分析数据集的关联规则, 以便快速、 准确地挖掘出用户侧的用电量水平走势等相关电力数据, 为用户用电特征提取、 电力负荷预测提供参考。
假设电力物联网用户侧数据的网状拓扑结构可通过一个有向图[6]G=(V,E)表示, 该图中各数据点及其连接线分别是V、E,Vi=(x1i,x2i,…,xmi)是n个数据点集合V=(V1,V2,…,Vn)中的一个数据集,i是1~n之间的正整数, 表示数据集序号,xji是数据集Vi中第j个有效的用户侧数据,j的取值范围是1~m之间的正整数。若第i个数据集Vi与第k个数据集Vk间存在一定的关联性, 其大小关联、 语义关联以及种类关联分别为αik、βik和θik, 则采用关联属性组(αik,βik,θik)界定该关联程度, 则k取值范围同i。
基于上述设定条件与关联映射关系, 得出以下结论。
1) 数据集Vi、Vk的关联属性组(αik,βik,θik)可以描述两数据集内任意数据间的关联程度。
2) 对关联属性组(αik,βik,θik), 可通过下列关联系数矩阵形式完成设置, 则数据集Vi与Vk中所有数据间的关联程度均值如下

(1)
其中K1是关联系数[7]。
3) 利用各关联属性倒数[8]描述集合区别, 即下列差异系数矩阵

(2)
其中K2是差异系数。
利用式(2)与关联系数矩阵[9], 推导出两数据集间的关联映射, 其表达式如下

(3)
若要有效区分数据集Vi与Vk, 根据该关联映射关系, 利用下列相互关系矩阵, 联立出两数据集之间的关联规则
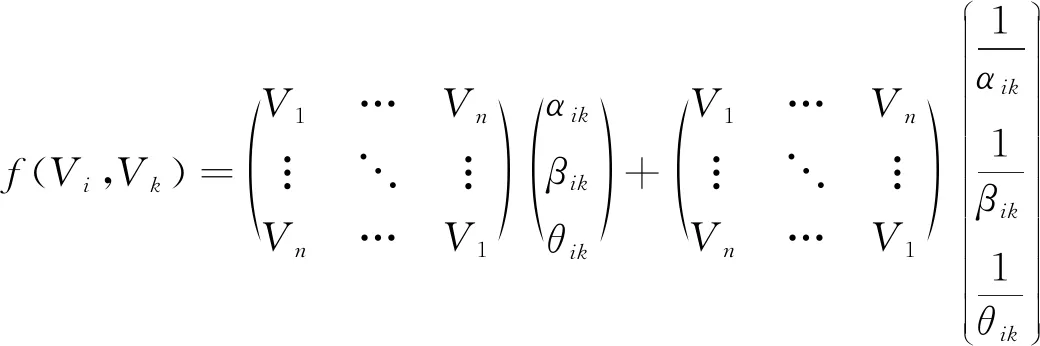
(4)
针对区分出的数据集Vi与Vk, 再次结合关联映射关系, 完成两数据集的区分, 为后续从电力物联网中深度挖掘用户侧数据提供精准的数据支撑。
2 电力物联网用户侧数据深度挖掘
2.1 用户侧数据预处理
在电力物联网用户侧数据深度挖掘过程中, 存在数据量级差异与连续属性不同值过多等不利因素, 为解决该问题, 引入极值规范化策略与径向基函数神经网络, 构建出减小数据量级差异的无量纲方法与离散化处理多个连续属性的聚类方法。
为实现用户侧数据的无量纲处理, 采用极值规范化策略线性变换初始的用户侧数据。已知数据属性A的极值分别是mA、xA, 则通过下列极值规范化表达式, 在区间[nmA,nxA]内完成属性A值v的映射, 得到映射值v′, 由此消除数据挖掘时因量级[10]差异而造成的偏差

(5)
径向基函数神经网络[11]具有聚类能力, 利用该网络分类数据的连续属性, 将初始连续值替换为网络中心, 令各属性变成离散值, 这既有助于维持初始属性间的关联性, 还能降低属性的赋值数量, 凸显出连续数据属性规律。
径向基函数神经网络中的隐藏层神经元主要用于输入层的特征提取结果的非线性变换[12], 若选择高斯函数作为转换函数[13], 当第k个数据在位置是i的神经元上时, 输出结果为xk,i, 此时的数据向量是Hk, 神经元的中心与系数为Hi、σi, 则第i个神经元的转换函数表达式如下

(6)
其中exp是Lyapunov函数[14],Γ是Lyapunov-Krasovskii泛函形式[15]。
神经网络输出层神经元的聚类过程: 已知一个n维空间Rn中的数据集Vi, 经径向基函数神经网络划分为n个类别后, 令数据类别及其网络中心之间的间距最短。
该神经网络训练过程由两个阶段构成: 获取隐藏层神经元的网络中心; 利用最小二乘法[16]求解隐藏层与输出层的连接权重。其中, 各数据点的类别标记则通过输出层转换函数实现。由于篇幅限制, 笔者仅描述第1阶段隐藏层神经元的网络中心获取流程。
利用K均值聚类算法[17]明确神经元网络中心的具体操作步骤描述如下:
1) 初始化处理径向基函数神经网络中前几个训练数据的簇中心;
2) 以目前簇中心为标准, 聚类训练数据, 求解各数据点与簇中心之间的欧几里得距离[18], 按最短距离将所有数据点划分至对应簇中心;

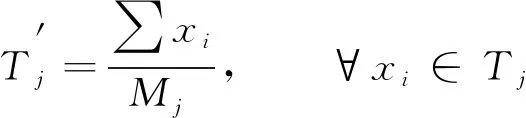
(7)
实现簇中心更新;
4) 返回第2)步, 直到簇中心没有变化后停止循环, 得到最终的网络中心。
用户侧连续数据经过K均值算法聚类后, 实现了属性离散化处理。若神经网络隐藏层的神经元数量是偶数, 则网络的数据评价分类形式如图1a所示; 若是奇数, 则如图1b所示。从图1可以看出, 各数据点均会被分类至给予最高评价的网络中心, 以此将数据点值替换为对应的网络中心, 以离散化处理连续属性, 令数据点取值范围为相应网络中心的集合。

图1 数据评价分类示意图
2.2 用户侧数据深度挖掘
在电力物联网中, 用户侧数据分为显性数据与隐性数据两种。当对用户为交易的电力项目进行评分时, 该评分就是用户侧的显性数据, 挖掘此类数据有助于分析用户的电力偏好需求, 以此设计相关对策提升电力物联网的交易数量。对目标用户及与其拥有相同偏好项目的邻域用户, 利用用户-项目评分矩阵[19], 得到任意项目的用户兴趣度。已知q类别的项目总数是Nq, 被用户p评分的项目数量是Mp,q, 故兴趣度可由

(8)
求出。为全面了解用户电力需求, 需结合用户针对任意电力项目的网页浏览时长等隐性数据, 深度挖掘用户侧数据。假设t是某项目网页的停留时长阈值, 则用户的隐性兴趣度矩阵架构如下

(9)
其中矩阵的列和行分别是电力项目类型与用户,Ipq与Tpq是第q类项目第p个用户的兴趣度与浏览时长[20]。
根据显性与隐性的不同用户侧数据类型以及用户-项目评分矩阵与兴趣度矩阵, 实现数据深度挖掘。
3 用户侧数据深度挖掘仿真实验
以由关联规则产生的真实数据集mushroom_exp.db与生成数据集AT60_AP10.db为基础, 采用笔者方法进行电力用户侧数据挖掘仿真实验。
为验证方法时效性, 测试不同用户支持度下笔者方法对两种数据集的挖掘效果。真实数据集mushroom_exp.db中包括近百个项目与近万条记录, 生成数据集AT50_AP8.db中含有150多个项目产生的近5万条记录。对不同规模数据集进行10组深度挖掘模拟实验, 计算执行时间均值, 得到不同支持度下的两种数据集挖掘时长, 如图2所示。
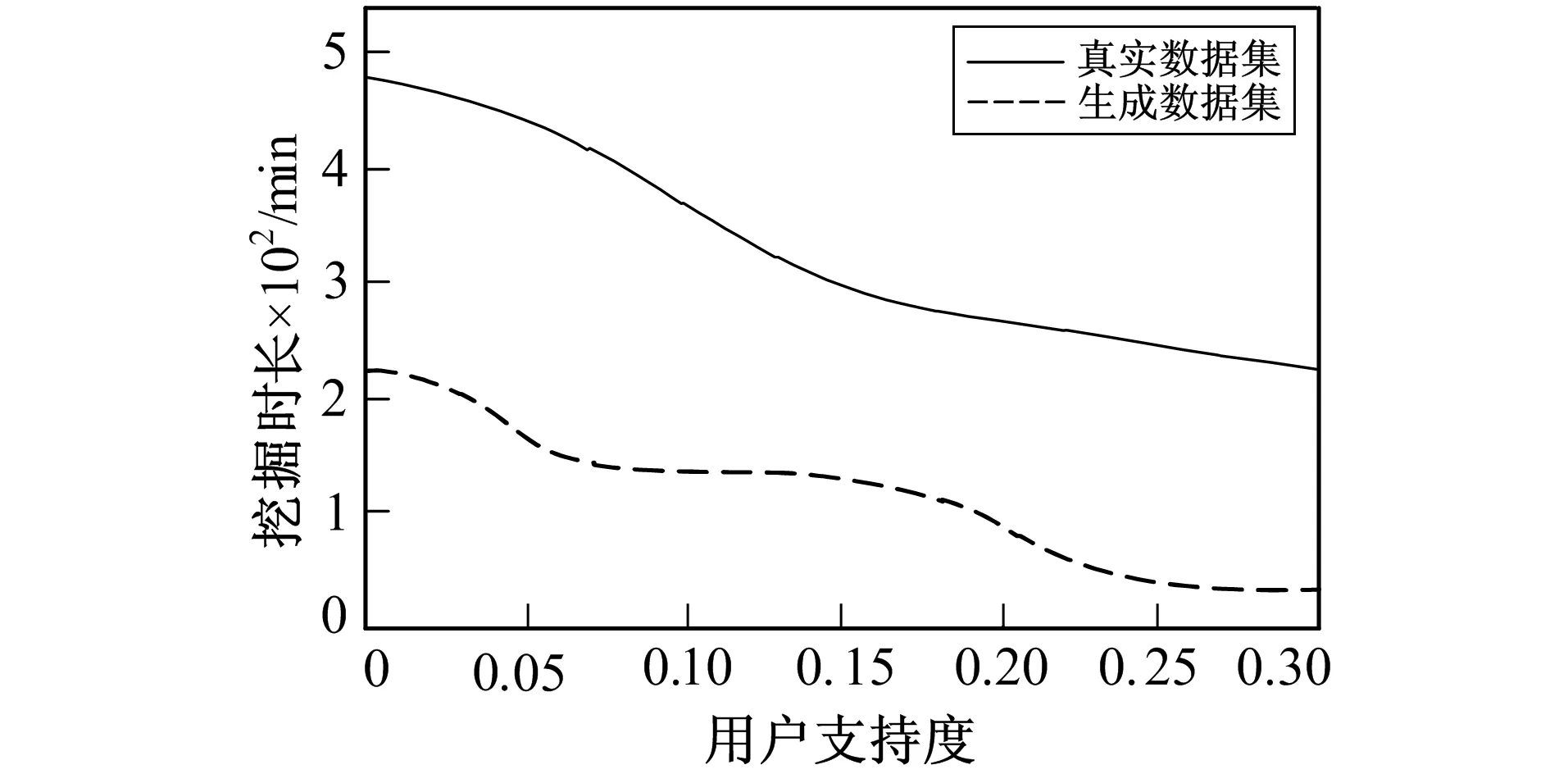
图2 不同数据集的支持度与挖掘时长相关性
由图2可以看出, 挖掘时长均随着用户支持度上涨而不断下降, 与数据集规模无关, 即使在支持度较小时, 该方法仍然可以根据用户侧数据间的关联映射关系, 用较短的时间完成挖掘任务。
设置数据集的记录均长是60, 用户支持度是0.3。利用JVisualVM性能监测工具记录的整体挖掘过程如图3所示。图3显示了笔者方法在挖掘不同规模数据集时内存占用、 垃圾回收活跃度以及总堆大小、 已用堆大小等情况。
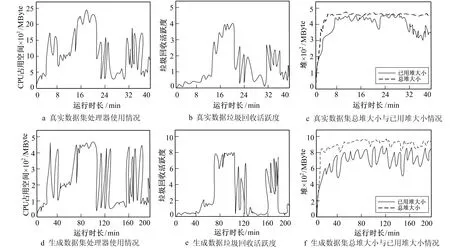
图3 不同数据集的挖掘效果
根据图3a~图3d中的指标曲线走势可以看出, 对处理器使用情况与垃圾回收活跃度而言, 不管是两数据集的相同指标还是单一数据集的不同指标, 曲线趋势均趋于近似。这表明数据量越大CPU占用空间越大, 同时垃圾回收活跃度也越高。尽管在挖掘较大规模的生成数据集过程中, 内存应用结果多次趋近于可用极值512 MByte, 但结合图3f堆的使用情况可知, 已用堆大小并未超过总堆极值, 这表明所提挖掘方法可以较为理想地处理不同规模数据集, 且能在较小的内存空间内完成用户侧数据深度挖掘。这是因为笔者在设计过程中引入极值规范化策略与径向基函数神经网络, 利用构建的无量纲方法与聚类方法, 减小了数据量级差异, 离散化处理了多个连续属性, 且由于笔者方法建立了关联规则映射关系, 防止数据集被过早分解, 提升了数据处理性能。
4 结 语
随着智能电网日益普及, 电力物联网日趋成熟, 因此根据用户需求分析结果为用户提供优质的用电服务具有重要的意义。笔者根据数据集的关联规则映射相关性, 深度挖掘电力物联网用户侧数据, 以期为供电管理奠定决策依据。以优化数据挖掘方法性能为目标, 可从以下几个方面做进一步探究: 通过汇总大量更详实、 更准确的用户侧数据; 以此建立自动挖掘系统, 实现挖掘自动化与数据可视化, 进一步优化电网领域经济性。
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
当代陕西(2019年15期)2019-09-02 01:52:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
电子测试(2017年15期)2017-12-18 07:19:27
电力与能源(2017年6期)2017-05-14 06:19:37
读者(2017年5期)2017-02-15 18:04:18
智能系统学报(2015年4期)2015-12-27 09:38:39
信息通信技术(2015年6期)2015-12-26 01:16:46
电子设计工程(2015年6期)2015-02-27 12:04:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
