
轻量化的YOLOv4 目标检测算法
2022-08-12 02:30张宝朋康谦泽李佳萌郭俊宇陈少华
计算机工程 2022年8期
张宝朋,康谦泽,李佳萌,郭俊宇,陈少华
(大连交通大学计算机与通信工程学院,辽宁大连 116028)
0 概述
目标检测是计算机视觉中的重要分支,广泛应用于图像分割、物体追踪、关键点检测等任务,主要分为Two Stage 和One Stage 两类算法。Two Stage目标检 测算法包括R-CNN[1]、Faster RCNN[2]、Fast-RCNN[3]等算法,先进行区域生成,此区域通常称为候选区域(Region Proposal,RP),即可能包含需要检测物体的预选框,再通过卷积神经网络进行分类;One Stage 目标检测算法包括YOLO[4-6]系列、SSD[7]、RetinaNET[8]等算法,不使用RP,通过特征提取网络提取图像特征,直接利用提取的特征预测物体分类和位置。相较于Two Stage 目标检测算法复杂的网络结构,One Stage 目标检测算法具有检测速度快、模型简单轻量的特点,适合部署在移动端嵌入式设备上。
YOLOv4 算法是YOLO 系列算法中的第4 版,相较于之前的YOLO 系列算法,在原有YOLO 目标检测架构的基础上,分别在加强特征提取、增强网络模型非线性、防止过度拟合等方面做了优化。从YOLOv1 到YOLOv4[9],YOLO 算法在经过数次迭代之后,逐渐弥补了许多缺陷,同时在保持速度优势的前提下,兼顾了检测准确度和实时性能。
本文在YOLOv4 目标检测算法的基础上对其网络结构进行改进,将CSPDarkNet53 主干特征提取网络替换为改进的ShuffleNet V2 网络,并使用深度可分离卷积替换原算法网络中的普通卷积,进一步降低算法参数量、计算量和模型占用空间,使其满足移动端嵌入式设备存储容量小、算力低的要求。
1 YOLOv4 和ShuffleNet V2 网络结 构
1.1 YOLOv4 网络结构
YOLOv4 网络结构如图1 所示,主干特征提取网络CSPDarkNet53 结合了CSPNet[10]和DarkNet53 的优点,在提高网络推理速度和准确性的同时,又能降低主干网络的计算量。相较于YOLOv3,YOLOv4的颈部网络NECK 采用空间金字塔池化(Spatial Pyramid Pooling,SPP)[11]和路径聚合网络(Path Aggregation Network,PANet)的网络结构。SPP 可以使得图片数据矩阵以固定大小的格式输出到YOLOv4 的预测网络模块(Head),避免直接对图片进行剪裁缩放造成数据信息丢失,进而导致预测网络可信度降低。同时,在提取图片各维度特征方面,不再使用YOLOv3 算法中的特征金字塔网络(Feature Pyramid Networks,FPN),而是采用一种金字塔和倒金字塔并行的PANet 网络结构。

图1 YOLOv4 网络结构Fig.1 YOLOv4 network structure
1.2 ShuffleNet V2 网络结构
ShuffleNet V2 是一种适合部署在移动端的轻量化网络结构。MA 等[12]在相同的硬件实现平台上,分别对ShuffleNet V1 和MobileNet V2[13]的执行情况进行研究,结合理论分析和实验数据得出以下4 条轻量化网络模型设计准则:
1)输入输出通道数相同,则内存占用量最小。
2)过多的分组卷积会增加内存占用量。
3)多路结构的网络分支会降低并行性,应尽量减少网络分支。
4)合理剪裁元素级运算,例如ReLU[14]和Add 函数,可加快模型推理速度。
本文后续对ShuffleNet V2 和YOLOv4 网络结构的改进也依据以上4 条设计准则展开。
ShuffleNet V2 网络模型的基本组件(如图2 所示)大致可分为:1)基本组件1,在特征图输入后有一个通道分支(Channel Split)操作,该操作将输入通道数为c的特征图分为c−c′和c′,左边的分支不做任何操作,右边的分支包含3 个卷积操作,并且2 个1×1卷积已经由ShuffleNet V1 中的分组卷积更换为普通卷积,再将这2 个分支通道中的数据用Concat+Channel Shuffle 操作进行合并,这样不仅可以使得该基础模块的输入输出通道数一样,而且避免了Add操作,加快模型了推理速度,最后进行通道重组(Channel Shuffle)操作;2)基本组件2,该组件没有Channel Split 操作,因此输出通道数是输入通道数的2 倍,左右分支的操作过程和基本组件1 基本一致,此处不再赘述。

图2 ShuffleNet V2 网络模型的基本组件Fig.2 Basic components of ShuffleNet V2 network model
2 目标检测算法的改进
2.1 总体改进思路
YOLOv4 目标检测算法在采用众多优化策略改进自身不足后性能表现优异,但在移动端设备部署目标检测算法的背景下,根据应用环境的不同,算法不一定需要很高的精确度,但需要较快的预测速度,在移动端设备算力及内存资源有限的情况下,算法模型的大小也变得尤为重要。显然,原YOLOv4 算法很难适用于移动端的目标检测设备。
基于此,本文对YOLOv4 目标检测算法进行改进,具体改进工作主要从以下2 个方面展开:
1)改进轻量化网络模型ShuffleNet V2,使模型在进一步剪裁、压缩和降低计算量和参数量的同时,尽可能地使其精度符合预期要求,并使用改进的ShuffleNet V2 网络替换原YOLOv4 目标检测算法中的主干特征提取网络CSPDarkNet53。
2)剪裁YOLOv4颈部网络尾部的CBL+Conv(CBL=Conv+BN+ReLU)结构,压缩模型容量,降低计算量。
2.2 ShuffleNet V2 网络结构的改进
2.2.1 卷积剪裁
在观察ShuffleNet V2 网络模型的基本组件后发现,在组件的单侧分支中,输入特征首先经过一个以普 通1×1 卷 积(Conv1×1)为主的Conv1×1+BN+ReLU 卷积处理模块,然后进入一个DWConv3×3+BN 模块,其中DWConv3×3 是一个卷积核大小为3的深度可分离卷积,最后进入一个普通Conv1×1,也就是说DWConv3×3 的前后各有一个普通的Conv1×1。在一般情况下,在深度可分离卷积前后使用1×1 卷积的目的有两种,一种是为了升维或者降维,另一种是为了通道信息融合。在ShuffleNet V2 模型设计时为了遵循轻量化网络模型设计准则中的准则1,每一分支的卷积层都需要保证输入输出通道相同,因此普通的Conv1×1 并不是为了对卷积核的通道数进行降维或者升维操作,而是为了融合通道信息,弥补深度可分离卷积的通道信息融合能力。
根据以上分析,在每一分支上使用2 个普通的Conv1×1 进行通道信息融合略显冗余,使用1 个Conv1×1 便可以满足移动端目标检测设备对精度的要求。因此,将图3 中虚线部分的普通Conv1×1 剪裁掉。

图3 ShuffleNet V2 网络模型基本组件的1×1 卷积剪裁Fig.3 1×1 convolution clipping in the basic components of ShuffleNet V2 network model
2.2.2 卷积核扩大
在卷积神经网络中,感受野的大小是衡量这个网络性能的重要指标参数,更大的感受野可以提取到图片中的更多细节特征。根据文献[15]得到如下感受野反向计算公式:

其中:Ri是第i层卷 积层上的感 受野;Ri+1是 第i+1 层上的感受野;Si是第i层的卷积步长(Stride);Ki是第i层的卷积核大小。
根据式(1)可以得知,感受野的大小和卷积步长和卷积核大小有直接关系,扩大卷积步长和卷积核大小可以有效增大卷积层上的感受野。然而根据式(2)可以看出,扩大卷积步长和卷积核大小都会对卷积输出产生影响,其中卷积步长的增大对卷积输出的影响更为明显。

其中:osize是卷积计算的输出值;isize是输入图像的矩阵大小;p是对输入图像矩阵高或宽上的补充(padding)值;Ksize是卷积运算中的卷积核大小。由此可见,S的大小对osize的影响很大,S过大会严重影响卷积层对特征图细节信息的提取,甚至完全遗漏掉两次卷积操作的中间信息。
如图4 所示,使用一个3×3 的卷积核对一个6×6的输入特征图进行卷积运算操作,其中黑色为参与1 次卷积计算部分,深灰色为参与2 次卷积计算部分,白色代表未参与卷积计算,浅灰色为第1、2 次卷积计算均有参与,虚线表示padding。在卷积运算时:如果Stride 为2,则卷积核大小范围的边缘部分数据参与2 次卷积计算,这样既不会造成边缘部分细节特征的丢失,又可以进一步加强提取边缘交叉处不易于提取的特征值;如果卷积操作时Stride 为3,则卷积核大小范围的边缘部分数据仅参与过1 次卷积计算,即1 次特征值的提取,这样很容易造成边缘处特征信息的丢失;如果卷积操作时Stride 为4,则会完全丢失2 次卷积操作间的特征信息。

图4 不同卷积步长的卷积操作Fig.4 Convolution operations with different convolution strides
由此可见,加大卷积步长和卷积核大小可以有效增加感受野,但是加大卷积步长会导致卷积操作中丢失部分特征信息,因此本文原本决定从扩大卷积核的大小入手,对深度可分离卷积进行一个卷积核的扩张,即将ShuffleNet V2 模型中原来的3×3 卷积核替换为5×5 卷积核,然而大尺寸的卷积核随之带来的是更多的参数量,在CNN 网络中参数量的计算和输入特征图的参数无关,仅和卷积核的大小、BN 以及偏置有关。假设卷积核kernel=(K,S,C,O),其中K、S、C、O分别是卷积操作时卷积核大小、步长、特征图输入通道数、输出通道数。卷积操作的参数量可以根据式(3)进行求解:

将K=5 和K=3 分别代入式(3),在输入输出通道数均相同的情况下,经计算得知K=5 时的参数量是K=3 时的2.6 倍。因此,本文借鉴文献[16]方法,采用2 个3×3 卷积核级联的方式代替5×5 卷积核,这种方式可以在有效降低计算量的同时,获得和5×5 卷积核相同的感受野。简化式(2),在Stride 为1 且不考虑padding 时得到式(4):

在卷积运算输出方面,假设isize的大小为9,Ksize的值为5,代入式(4)经计算得出osize的值为5。在同样情况下,将Ksize的值设为3,经过2 次级联的3×3 卷积核运算后得出osize的值也是5。同理,在参数量方面,假定输入输出通道的值均为3,分别将K=5 和K=3 代入式(3),经计算可知5×5 卷积操作的参数量为234,两个级联的3×3 卷积操作的参数量为180,远比一个5×5 卷积操作的参数量要低很多。
2.2.3 激活函数替换
Mish 函数是MISRA 于2019 年提出的一种新型激活函数[17],函数表达式如式(5)所示:

其中:x是由归一化层传入的参数值。
由如图5 所示的Mish 激活函数示意图可知:1)Mish 激活函数在负值时并非完全截断,更好地保证了信息流入;2)Mish 激活函数无边界,在左右极限的情况下梯度趋近于1,可避免梯度饱和;3)Mish 激活函数的梯度下降效果更好,可以尽可能地保证每一个点的平滑。基于此,本文将ShuffleNet V2 网络模型中原本的ReLU 函数替换为Mish 激活函数。

图5 Mish 激活函数示意图Fig.5 Schematic diagram of Mish activation function
2.2.4 改进的ShuffleNet V2 最小基本组件
综合以上关于ShuffleNet V2 网络模型的改进方法,得到新的ShuffleNet V2 网络模型最小基本组件,如图6 所示。

图6 改进的ShuffleNet V2 网络模型最小基本组件Fig.6 Minimum basic components of improved ShuffleNet V2 network model
2.3 YOLOv4 网络结构的改进
2.3.1 颈部网络结构剪裁
通过分析YOLOv4 网络结构可知,在其颈部网络和YOLO-Head 之间有CBL+Conv 结构,然而特征图在输入到这一结构之前,就已经在颈部网络中经过了5 次CBL 操作,而且如图7 所示的CBL 操作中也包含Conv 操作,这样共有6 次CBL 操作再加1 次Conv,然后输入到YOLO-Head 中进行预测。因此,在颈部网络和YOLO-Head 间进行1 次CBL+Conv 操作则显得多余,删除该操作不仅对后续的网络预测没有任何影响,而且还会加快网络推理速度。

图7 CBL 结构组成Fig.7 CBL structure composition
2.3.2 深度可分离卷积替换
通过进一步分析YOLOv4 网络结构可知,其在颈部网络中使用了大量的CBL 结构,而由于CBL 基本组成结构为CBL=Conv+BN+Leaky ReLU,因此颈部网络中包含了大量的普通卷积运算,借鉴文献[18]研究思想,采用深度可分离卷积代替普通卷积可以大大降低卷积运算的参数量,而在神经网络中参数量的多少直接影响了网络模型容量的大小和网络模型在计算过程中的浮点数计算量(Floating Point Operations Per second,FLOPs)。普通卷积和深度可分离卷积示意图如图8、图9 所示。由图8、图9可以看出,普通卷积是使用4 个3×3×3 的Filter(过滤器)对输入特征图进行卷积操作,先将特征图的每个Channel(通道)和对应的Kernel(卷积核)做卷积运算,然后将3 个Channel 的运算结果融合成一个Map(图层)输出,而深度可分离卷积是将以上操作步骤分解为两部分完成,首先使用3 个3×3×1 的Filter 对输入特征图的每个Channel 分别进行卷积得到由3 个Map 组成的特征图,这一过程称为逐通道卷积,然后再用4 个1×1×1 的Filter 对上一步的输出特征图进行卷积运算,最后输出由4 个Map 组成的特征图,这一过程称为逐点卷积。逐通道卷积和逐点卷积经过以上运算流程共同组成深度可分离卷积[19]。
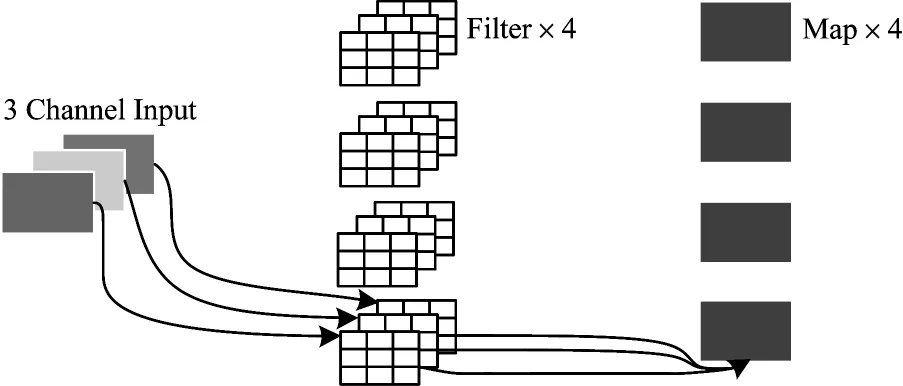
图8 普通卷积示意图Fig.8 Schematic diagram of ordinary convolution

图9 深度可分离卷积示意图Fig.9 Schematic diagram of depthwise separable convolution
由图9 可以分析得出深度可分离卷积的参数量计算公式:

根据式(3)化简后的深度可分离卷积参数量计算如下:

因为在逐通道卷积计算时,每个Filter 仅包含1 个Kernel,而普通 卷积的每个Filter 包 含3 个Kernel,相当于逐通道卷积时的Cdw=1,普通卷积和逐点卷积时Cpw=Cconv=Cinput,则深度可分离卷积和普通卷积的参数量比值[20]计算如下:

将图8、图9 的Filter 中卷积核大小和输入输出通道数代入式(6)、式(7)中可知:在普通卷积的情况下计算参数量Pconv为108,在深度可分离卷积的情况下计算参数量Pdw-conv为39。
假定输出特征层的宽和高分别为wout和hout,那么普通卷积和深度可分离卷积的计算量公式如式(9)、式(10)所示:

经化简后两者的比值如下:

由此可知,将YOLOv4 颈部网络中的普通卷积全部替换为深度可分离卷积能够直观有效地降低模型参数量和计算量。
2.3.3 改进的网络结构
在使用卷积剪裁、扩大卷积核、替换深度可分离卷积等方式对ShuffleNet V2、YOLOv4 网络结构进行轻量化改进后得到改进的YOLOv4 网络结构,如图10 所示。

图10 改进的YOLOv4 网络结构Fig.10 Improved YOLOv4 network structure
3 实验结果与分析
选用PC 和ZYNQ 7020 开发板卡为硬件实现平台,PC 的硬件配置CPU 为AMD R5 4600H,GPU 为GTX 1660,ZYNQ 平台为ALINX 公司的AX7020 型开发板,详细的逻辑资源此处不再赘述。实验数据集来自天津大学机器学习和数据挖掘实验室开源的VisDrone 2020 数据集[21],该数据集由航拍无人机捕获收集,横跨中国多个城市的市内及郊区环境,包含丰富的视频及图片数据。
3.1 消融实验
3.1.1 ShuffleNet V2 改进实验对比
针对改进的ShuffleNet V2 网络结构进行目标分类实验,得出如表1 所示的ShuffleNet V2 消融实验对比数据,其中剪裁普通Conv1×1 结构后的网络命名为ShuffleNet_lit,扩大卷积核后的网络命名为ShuffleNet_2DW,替换激活函数后的网络命名为ShuffleNet_M。
由表1 数据可知,除ShuffleNet_lit 外,ShuffleNet_M和ShuffleNet_2DW 相较于ShuffleNet V2 都提高了Top-1 准确率,其中ShuffleNet_2DW 提升效果更显著,但是这两个网络在提高检测精度的同时也带来了FLOPs、参数量及模型容量的增加。改进的ShuffleNet V2 网络的检测精度较原网络有了显著提高,并有效降低了原网络的计算量、参数量和模型容量。

表1 ShuffleNet V2 消融实验数据对比Table 1 Comparison of ShuffleNet V2 ablation experimental data
3.1.2 YOLOv4 改进实验对比
针对改进的YOLOv4 网络结构进行目标分类实验,得出如表2 所示的YOLOv4 消融实验对比数据,其中对颈部网络剪裁后的网络命名为YOLOv4_lit,替换深度可分离卷积的网络命名为YOLOv4_DW。

表2 YOLOv4 消融实验数据对比Table 2 Comparison of YOLOv4 ablation experimental data
由表2 数据可知,两种改进方式分别对YOLOv4网络的FLOPs、参数量和模型容量做了不同程度上的压缩,其中采用深度可分离卷积代替普通卷积方式改进的YOLOv4_DW 网络效果更明显。
3.2 GPU 平台上目标检测算法的性能对比
将YOLOv4 算法、改进 的YOLOv4 算法、文献[22]算法和YOLOv5 算法[23]在相同软硬件平台和VisDrone 2020 数据集上进行目标检测实验,输入图片固定为800×800 像素,得到的平均精度均值(mean Average Precision,mAP)、检测速度和模型容量结果如表3 所示。4 种算法在相同GPU 平台和VisDrone 2020 数据集上的图像目标检测实验可视化结果如图11~图14 所示。

图11 YOLOv4 算法在VisDrone 2020 数据集上的图像目标检测结果Fig.11 Image target detection results of YOLOv4 algorithm on VisDrone 2020 dataset

图12 改进的YOLOv4 算法在VisDrone 2020 数据集上的图像目标检测结果Fig.12 Image target detection results of improved YOLOv4 algorithm on VisDrone 2020 dataset

图13 文献[22]算法在VisDrone 2020 数据集上的图像目标检测结果Fig.13 Image target detection results of the algorithm in reference[22]on VisDrone 2020 dataset

图14 YOLOv5 算法在VisDrone 2020 数据集上的图像目标检测结果Fig.14 Image target detection results of YOLOv5 algorithm on VisDrone 2020 dataset

表3 目标检测算法性能对比Table 3 Performance comparison of target detection algorithms
由表3 和图11、图12 和图13 检测结果可知,YOLOv4 算法、改进的YOLOv4 算法和文献[22]算法在VisDrone2020 数据集上具有大致相同的检测结果,但是改进的YOLOv4 算法相较于YOLOv4 算法,在mAP 上降低了1.8 个百分点,检测速度却提高了27%,模型容量降低了23.7%,相较于文献[22]算法,在mAP 上降低了0.5 个百分点,模型容量增加了13%,但运行速度却提高了18.75%。
由表3 和图14 检测结果可知,YOLO5 算法在检测速度和模型容量上均比改进的YOLOv4 算法有着极大的提高,但是在mAP 上却比改进的YOLOv4 算法降低了7.9 个百分点,而且对比图12 和图14 可以看出,YOLO5 算法对小目标的检测效果并不理想,甚至有些小目标未检测到,不适用于目标较多、目标尺度不均的复杂检测环境。
3.3 不同硬件平台上改进的YOLOv4 算法性能对比
使用改进的YOLOv4 目标检测算法分别在GPU平台和ZYNQ 平台上进行目标检测实验,结果如表4所示,这种纵向对比实验主要是为了衡量在相同功耗下,该算法能否发挥ZYNQ 功耗低、数据并行处理能力强的优势。改进的YOLOv4 算法在ZYNQ 平台和VisDrone 2020 数据集上的图像目标检测可视化结果,如图15 所示。

表4 改进的YOLOv4 算法在不同硬件平台上的性能对比Table 4 Performance comparison of the improved YOLOv4 algorithm on different hardware platforms
对比表4 和图12、图15 中的数据及检测结果可知,改进的YOLOv4 算法在GPU 平台上的检测速度更快,但是由于该纵向对比实验并不是为了证明GPU 和ZYNQ 检测速度,而是通过对比两者的功耗比,即处理一张图片所消耗的功率,从而验证改进的YOLOv4 算法能否发挥出ZYNQ 在处理任务时既速度快又功耗低的优势。通过对比和分析表4 中数据可知,虽然GPU 的处理速度比ZYNQ 快了1.6 倍,但是在功耗方面,GPU 却是ZYNQ 的10 倍多。显然,本文改进的YOLOv4 目标检测算法充分发挥了ZYNQ 平台的优势,非常适合部署在以ZYNQ 为硬件实现平台的移动端目标检测环境中。
4 结束语
本文在改进ShuffleNet V2 和YOLOv4 网络结构的基础上,提出一种轻量化的目标检测算法,并将其部署在GPU 和ZYNQ 平台上。实验结果表明,该轻量化算法在GPU 平台上运行时检测精度仅减少1.8 个百分点的情况下,降低了模型容量并提高了检测速度,充分发挥了ZYNQ 平台并行高速数据处理及低功耗的优势。下一步将继续研究目标检测算法的轻量化改进方法,在尽可能降低计算量、参数量和模型容量的前提下,进一步提升检测精度和检测速度。
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
北京航空航天大学学报(2021年9期)2021-11-02
西安邮电大学学报(2020年1期)2020-12-17
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
电子制作(2019年13期)2020-01-14
计算机系统应用(2019年9期)2019-09-24
电子制作(2019年11期)2019-07-04
福建基础教育研究(2019年6期)2019-05-28
北京航空航天大学学报(2018年1期)2018-04-20
军事运筹与系统工程(2016年4期)2016-07-10
