
基于交易不可信度的比特币非法交易检测
2022-08-12 02:29俞莎莎牛保宁
计算机工程 2022年8期
俞莎莎,牛保宁
(太原理工大学信息与计算机学院,山西晋中 030600)
0 概述
比特币是一种去中心化、匿名且不可篡改的加密货币[1]。与依赖中心化监管体系的银行金融系统不同,加密货币基于去中心化的共识机制[2],缺乏集中控制。由于比特币钱包地址是一个包含27~34 个字母数字的标识符,不包含关于所有者的任何信息,因此很多非法活动选择以比特币作为支付手段。
近些年,比特币非法交易的检测问题备受关注[3]。非法交易是指参与诈骗、恶意软件、恐怖组织、勒索软件、庞氏骗局、洗钱[4-6]、毒品交易[7]等活动的交易[8]。非法交易检测方法分为实体检测和交易检测。实体检测根据交易之间的引用关系,采用聚类算法将交易归属于不同实体(实体是具有单个或多个地址的个人或组织),再提取实体特征,并对实体进行分类,通过识别异常实体来分析鉴别非法交易[9]。交易检测是利用机器学习分类模型和图卷积网络(Graph Convolutional Network,GCN)分类模型直接检测非法交易。机器学习分类模型,如逻辑回归(Logistic Regression,LR)[10]、随机森林(Random Forest,RF)[11]、多层感知机(MultiLayer Perceptron,MLP)[12]等,通常根据交易本身特征(如交易输入或输出的数量、交易费用、交易输入或输出的平均交易额)反映交易的非法程度。该分类方法的分类效果有限。图卷积网络分类模型及其变体[13-14]不仅根据交易本身特征,而且基于交易网络拓扑结构构建交易间的关联关系,用于训练识别非法交易。因此,与传统机器学习分类模型相比,卷积网络分类模型具有更优的检测效果。
在实体检测中,聚类方法本质上是把交易包含的非法信息传递到实体上,将非法实体作为非法交易的代表。然而,比特币所有者为规避非法交易检测,通常会将非法交易和合法交易混合在一起。因此,一个包含成千上万笔交易的非法实体可能只含少量非法交易。为减少合法交易对非法实体特征的影响,通过实体特征鉴别非法实体的方法并不准确。在交易检测中,不论是机器学习分类器,还是GCN都假设交易的属性包含交易是否非法的信息,并尝试从各种可能的交易属性中挖掘能够代表交易非法性的特征。
比特币交易的非法性取决于交易是否用于违法犯罪活动。两个具有相似或相同属性的交易用于违法犯罪活动属于非法交易,没有用于违法犯罪活动属于正常交易。因此,现有的比特币非法交易检测方法根据交易属性难以准确地判断非法交易,但是非法交易之间有关联,即具有可传递性。本文设计基于交易不可信度的比特币非法交易检测方法。结合非法交易之间的传递性,提出交易不可信度,度量交易的不可信程度,同时将度量结果融合到已有的判别模型中。在此基础上,通过迭代训练集的方式扩增非法交易样本,从而提高模型的判别精确度和召回率。
1 相关工作
比特币非法交易检测本质上是交易不可信度的度量和排序问题。因此,分析其度量原理、设计相对准确的交易不可信度度量算法是提高检测精确率和召回率的有效方法。
在实体检测中,现有方法通常根据比特币中所有者和钱包地址与交易之间的关联关系,将交易归属于不同的地址或所有者[15]。文献[16-17]提出启发式聚类方法将地址链接到实体。文献[9,18]从海量交易记录中提取出多个实体,将其分为赌博、勒索交易等类别,使用有监督的机器学习方法对实体进行分类。文献[19-20]对地址和交易流进行统计分析,根据交易基本信息构建地址特征,识别非法比特币地址。文献[21]使用贝叶斯方法对用户的行为特征建模,将交易与钱包地址和IP 对应。文献[22]提出基于特征的网络分析架构,寻找比特币中提供混合服务的地址,从而为比特币反洗钱提供线索。这些方法将交易非法性转移到地址或所有者,通过识别非法实体来鉴别非法交易。
在交易检测中,GCN 基于非欧氏空间特征的预测性能比机器学习分类器[23]更好。2019 年,Elliptic加密货币情报公司公开发布Elliptic 数据集,构造的交易特征包括本身特征和聚合特征[4]。聚合特征描述了邻居交易的信息,相比只用本地特征,其具有更优的检测效果,但是在交易网络中,聚合特征无法构建更广泛的交易链接关系。同时,文献[4]利用加权交叉熵损失函数训练GCN 模型,相比LR、RF、MLP等传统机器学习模型,具有更高的精确率和召回率。在实际情况中,根据比特币构造的交易网络会随着新顶点增加而不断扩展的特点,文献[4]和文献[14]提出EvolveGCN,该模型通过循环神经网络演化GCN 参数来捕获图序列的动态性。现有的交易检测方法存在以下2 个共同问题:1)相较于机器学习算法,神经网络训练模型结合交易网络特征,进一步加强交易特征之间的关联,但是从特征角度寻找非法交易,而没有根据交易的链接关系对其本身的非法性程度进行量化分析;2)在Elliptic 数据集上标注的非法交易仅占2%,影响模型的检测性能,通过扩增非法交易样本提高训练集中非法交易占比。因此,本文提出度量交易不可信度,设计算法在最大程度上正确反映交易的非法性程度。由于不可信度特征值是对交易不可信度的直接体现,因此选择不可信度高的交易作为样本来扩增非法样本。本文将不可信度作为新的特征,融合到已有判别模型,进一步提高分类模型的检测性能。
2 交易不可信度
2.1 交易不可信度量化
交易的非法性源于其参与非法活动,非法活动一般涉及多个相关交易。比特币交易具有多个输入交易和输出交易的性质,表明交易的非法性是可传递的。
2.1.1 交易不可信度传递
比特币交易结构如图1 所示。每个交易由多项交易输入(in-link)和交易输出(out-link)组成,表示一次交易将多个来源的比特币合并后转给多个账户。比特币交易构成的网络可以抽象成一个有向图,图中节点表示交易,边表示从一个交易到另一个交易的比特币流动。因此,交易不可信度是单向传递的。若非法交易A 指向交易B,即交易A 是交易B的输入,则认为交易A 把自身非法性传递给B。

图1 比特币交易结构Fig.1 Structure of Bitcoin transaction
在交易网络中通常存在2 种不可信度传递模式,即不可信度分割和聚集。
1)不可信度分割
交易不可信度传递模式如图2 所示。从图2 可以看出,某组织参与非法活动,执行过大宗交易A,与其有关的赃款必然会以交易的形式输出,根据该非法交易及其流向B、C,寻找传递后的非法交易是检测不可信度的有效方法。
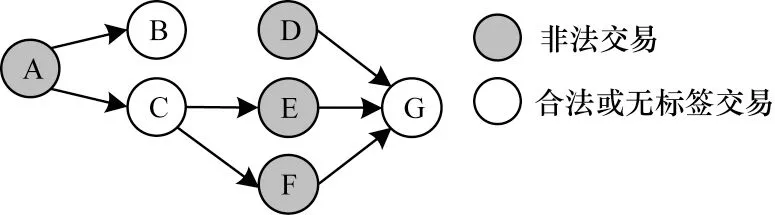
图2 交易不可信度传递模式Fig.2 Delivery mode of transaction unreliability
2)不可信度聚集
对于具有多个in-link的交易,其非法性是in-link非法性的聚合。图2中某用户接收赃款,发生交易D、E、F,销赃时发生交易G,D、E、F 把不可信度传递到G。
在实际情况中,交易网络往往错综复杂,发生的非法交易通常是上述两种方式的结合与变体。另外,在多个不同的非法活动之间也可能产生交易上的关联。以图2 为例,A 的不可信度会传递到C,再经由E 传递到G,G 会得到来自A、D、E、F 的不可信度。随着产生的交易越来越多,交易网络会越来越庞大。
2.1.2 交易不可信度计算
交易不可信度的计算主要是计算每个交易的不可信度分割和聚集。对于不可信度分割,即非法交易具有多个out-link 的情况,本文认为这些out-link具有相同的非法性概率,因此交易的不可信度在out-link 之间平均分配。交易A 的不可信度为rA。若交易A 有n个out-link,则每个link 的权重为rA/n。图2 中A 是非法交易,箭头代表交易之间的比特币流动在不可信度聚集的情况下,交易自身的不可信度是它所有in-link 的权重之和。图2 中D、E、F 代表非法交易,rG=rD+rE+rF。
在比特币交易网络中的交易数量庞大,计算所有交易的不可信度需要遍历网络,计算量大。为此,本文构建计算交易不可信度模型。
G(N,E)是一个比特币交易网络,其中N是节点集合,代表交易,E是边集合,代表从一个交易到另一个交易的比特币流动。本文定义邻接矩阵Mn×n,行和列都表示按时间顺序排列的全部交易,数量为n。设交易i的out-link 数量为di,若i→j,那 么mji=1/di,否则mji=0。γ=[r1,r2,…,rn]T代表交易不可信度向量,其中每个交易的不可信度对应一个分量。不可信度流动计算如式(1)所示:

其中:γ(t)和γ(t+1)分别为更新前后的交易不可信度向量;邻接矩阵Mn×n为交易之间的链接关系;n为总交易数量。邻接矩阵Mn×n中每个元素mji的定义如式(2)所示:其中:di为交易i的out-link 数量。γ(t)向量的初始值来自交易的标签,若交易i非法,则ri=1,若交易j合法,则rj=0。

交易不可信度的计算如图3 所示。
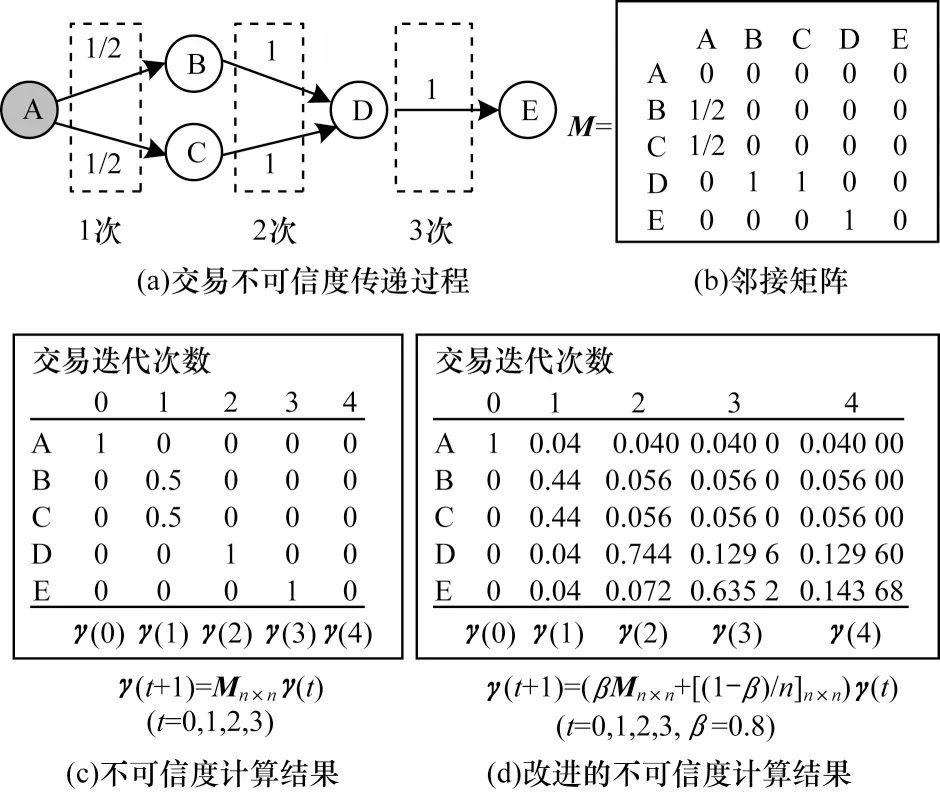
图3 交易不可信度的计算Fig.3 Calculation of transaction unreliability
图3 中存在交易不可信度传递过程A →(B,C)→D →E,A 是非法交易,不可信度初始化为1,其他交易初始化为0。每迭代1 次,表示将每个交易的不可信度传递给自己的交易输出。从A 的角度分析,经过1、2、3 次迭代后,A 的不可信度分别传递给B、C、D 和E。从E 的角度分析,经过1、2、3 次迭代后,E 分别得到来自D、B、C 和A 的不可信度,结果如图3(c)所示。将迭代结果累加后得到A、B、C、D、E 的不可信度分别为1、0.5、0.5、1 和1。
比特币交易网络存在很多分散的交易,它们无法得到来自之前交易的不可信度,也不能将自己的不可信度传递给之后的交易。这些交易阻断了不可信度的传播,导致最终计算得到的很多非法交易不可信度为0,这将影响分类模型对非法交易的判定。本文设置每个交易把自身不可信度的大部分权重(占比β)传递给自己指向的交易,将少部分权重(占比1-β)传递给所有交易。改进的不可信度流动结果如式(3)所示:

其中:[(1-β)/n]n是所有n项都为(1-β)/n的向量;β为每个交易把自身不可信度传递给自己指向交易的比例。不可信度流动公式经过改进后,交易不可信度结果如图3(d)所示。式(3)迭代m次后,不可信度趋于稳定,即‖ ‖γ(t+1)-γ(t) ≤ε,实际是一笔交易的不可信度在经过m次传输后,可传递到它的大部分后代交易。网络中每个非法交易把不可信度传递到末端交易的次数不同,本文需要确定合适的次数,使得大部分非法交易能把不可信度传递到末端交易,m是该次数的近似值。本文对经过迭代的交易,通过对上级或上上级交易获得的不可信度进行累加,将其作为最终的不可信度,如式(4)所示:
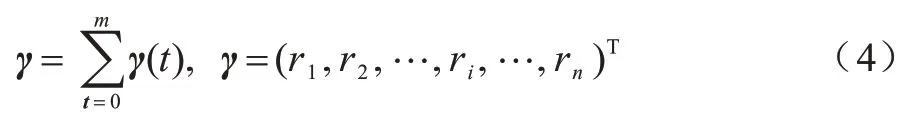
改进的不可信度计算对γ进行标准化处理[24],如式(5)所示:
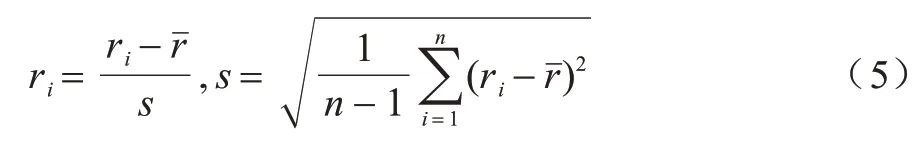
其中:ri为每个交易的不可信度为n个交易的不可信度均值;s为n个交易不可信度的标准差。适当调整不可信度流动公式中的参数β,使算法在测试阶段的非法交易检测能力达到最优。
本文对度量算法进行以下直观描述:若交易的不可信度高,则交易的非法性程度较大,交易不可信度是其in-link 不可信度的总和。较高的不可信度既包含交易中许多非法in-link 的情况,也包含交易的in-link 不可信度值很高的情况。令X为所有交易不可信度的初始向量。度量算法主要有4 个步骤:1)令γ(0)=X;2)执行直 到||γ(t+1)-γ(t)||≤ε;3)计 算4)标准化处理γ,ri←
步骤2 中||γ(t+1)-γ(t)||是迭代前后两个不可信度向量的欧氏距离,用于衡量相似度。若欧氏距离小于等于ε,则认为两个向量相似,停止迭代。ri的初始值为1 或0,即非法或合法。若交易i具有多个非法的上一级交易或上上级交易,则在迭代过程中,交易i将从中获得非法性,因此ri大于1。ri越大,表示从上几级交易中获得非法性的概率越大。
2.2 不可信度融入
由于实验数据收集不完整,因此交易网络存在交易缺失和一些交易没有标签的情况,阻碍交易不可信度的传播。另外,在交易网络中存在一些相对独立的非法交易,其交易不可信度的获取和传递受到限制,不能反映交易的非法性。这种情况需要根据交易本身的特征来判断非法交易。因此,本文提出将不可信度融合到现有的分类模型中,提高模型的准确度,即把不可信度作为一种新的特征和交易本身特征合并,共同判断非法交易。
交易不可信度本质是对交易是否非法的量化表征,是一个包含信息量的特征。
3 非法交易样本扩增
不可信度是交易不可信的本质体现,本文将不可信度高的交易作为样本来扩增非法样本。实验发现,将不可信度作为交易唯一特征,通过LR 检测未知交易类型,精确率可达91%以上。本文提出将LR 检测到的非法交易放入训练集中,重新计算交易不可信度,以新的不可信度作为唯一特征,再次把检测到的非法交易放回训练集,如此循环,直到无法检测出新的非法交易。非法交易样本扩增过程如图4 所示。

图4 非法交易样本扩增流程Fig.4 Expanding procedure of illicit transaction samples
4 实验结果与分析
本文通过实验验证交易不可信度特征与交易原有特征合并后,以及扩增非法交易样本在提高精确率和召回率方面的有效性。
4.1 评价指标
本文将精确率、召回率、F1 值作为客观评价指标,以评价检测能力。精确率、召回率分别如式(6)和式(7)所示:

其中:TTP表示把非法交易判定为非法交易的数量;FFP表示把合法交易判定为非法交易的数量;FFN表示把非法交易判定为合法交易的数。P值越高,表示检测精确率越高。R值越高,表示样本中非法交易被正确预测的比例越高。精确率和召回率会相互影响,精确率提高,召回率则会降低。为综合衡量两者的关系,F1 值定义如下:

F1 对P和R进行加权,F1 值越高,方法的检测性能越好。
4.2 实验对比方法
本文使用逻辑回归(LR)[10]、随机森林(RF)[11]、多层感知机(MLP)[12]这3 种基准机器学习方法[4]和图卷积网络(GCN)[13]检测非法交易。融入交易不可信度和扩增训练集对提高现有模型的检测性能具有重要意义。LR 根据现有数据确定分类边界线,再拟定回归函数式并进行分类。RF 是一种集成学习算法,由多棵决策树组成。MLP 中的每个输入神经元接收一个数据特征,每个隐藏层的输出通过softmax进行变换,最后得到每个类别的概率向量。GCN 则充分利用了图的结构信息。
4.3 实验环境与设计
实验环境:Java,MapReduce,Python3.8,PyTorch,处理器为Inter®CoreTMi7-8750H CPU@2.20 GHz,内存为16 GB。
Elliptic 数据集(www.elliptic.co)是当前世界上最大(665 MB)、含标签、公开可用的比特币交易数据集[4]。由于该数据集所含交易数据量大且特征完善,因此本文在Elliptic 数据集上进行分析和实验。在数据集中非法交易、合法交易、未标记交易占比分别为2%(4 545 个)、21%(42 019 个)和77%。每个交易有94 个本地特征(记为LF),表示交易本身的特征;有72 个聚合特征(记为AF),表示邻居交易特征。交易数据时间跨度约为2 周,分为49 个时间段,记为T1~T49,在同一个时间段内交易互相关联且具有时序性,在不同时间段之间的交易无关联。不同时间段所含交易总量和非法交易数量均不同。
本文选择非法交易数量达到200 以上的T20,T29 和T32,将交易不可信度作为唯一特征,利用LR模型检测非法交易。训练集与测试集的比例为8∶2。
本文选取非法交易数量达到300 以上的T29,将不可信度融入到LR、RF、MLP 和GCN 分类模型检测非法交易。训练集与测试集的比例为8∶2,即在一定时间序列上,前80%交易作为训练集,后20%交易作为测试集。在训练集中非法交易初始化为1,训练集中其他交易和测试集中所有交易初始化为0。本文通过计算交易不可信度并扩增非法交易样本,将最新的不可信度(记为R)和Elliptic 数据集中原有特征合并,验证本文方法的有效性。实验采用两种合并方式,先把R 和LF 合并,再把R和LF、AF合并,最后分别使用LR、RF、MLP、GCN分类模型检测非法交易。
4.4 结果分析
当不可信度流动式(3)中的β取值0.60~0.85 时,实验分类结果较优且基本稳定。本文实验的β设为均值0.7。LR 使用sklearn Python 包默认参数。RF 使用sklearn Python包,设置n_estimators=50,max_features=50。MLP 使用PyTorch 框架,neurons=50,epoch 为10,采用Adam 优化,学习率为0.001。GCN 使用torch_geometric 框架,epoch 为1 000。
4.4.1 非法交易预测
本文将交易不可信度作为唯一特征,在数据集T20、T29 和T32 上,利用LR 分类模型检测非法交易类型的精确率、召回率,如表1 所示。

表1 在不同数据集上LR 模型的非法交易检测结果Table 1 Illicit transaction detection results of LR model on different datasets %
LR 分类模型的精确率可达91%~100%,但召回率较低。在交易网络中因交易缺失阻断不可信度的传递,导致很多非法交易无法找到他们引用的交易,难以得到准确的不可信度,因此召回率较低。此外,交易网络存在一些散发的非法交易,仅利用不可信度检测很难发现该交易。对于这些交易只能利用交易特征判别其交易类型。为利用LR 检测精确率高的优点,避免召回率低的缺点,本文提出融合不可信度R 和交易特征来检测非法交易。
4.4.2 交易不可信度与扩增训练集融合结果
本文在数据集上加入不可信度R 和扩增训练集,与仅用本地特征LF 和聚合特征AF 检测进行对比。
在Elliptic 数据集中未知交易占比达77%,实验中测试集的未知类型交易会被预测为合法交易或非法交易。本文将未知类型的交易剔除后进行结果评估。LR、RF、MLP 和GCN 分类模型加入不可信度R 后和扩增训练集的非法交易检测结果分别如表2~表5 所示。

表2 LR 模型非法交易检测结果Table 2 Illicit transaction detection results of LR model %
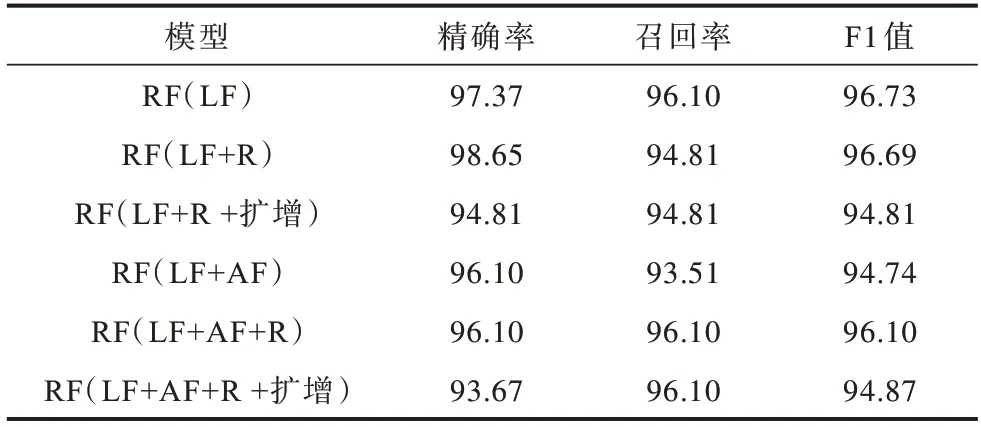
表3 RF 模型的非法交易检测结果Table 3 Illicit transaction detection results of RF model %

表4 MLP 模型的非法交易检测结果Table 4 Illicit transaction detection results of MLP model %
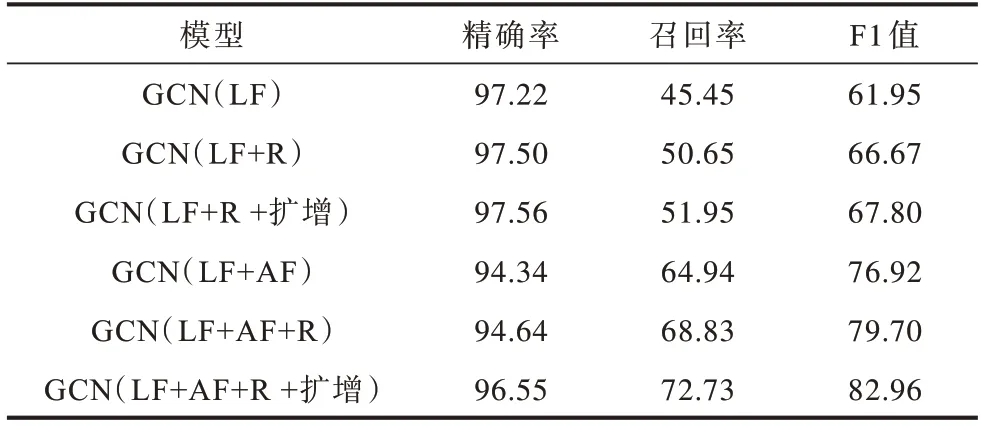
表5 GCN 模型的非法交易检测结果Table 5 Illicit transaction detection results of GCN model %
从表中可以看出,加入不可信度R 后,LR、RF、MLP 和GCN 分类模型的F1 值均有所提高,说明不可信度R 能够有效提高模型的检测能力,其原因为在非法交易之间有关联关系,非法性具有可传递性,交易不可信度能直接反映交易的非法性,相比仅用交易一般特征判断更准确。交易不可信度和交易一般特征共同作用得到更好的分类效果。在本地特征LF 和聚合特征AF 中加入不可信度R 后,LR、RF、MLP、GCN 这4 种模型的精确率分别平均提高11.19%、0.64%、12.45%、0.29%,召回率分别平均提高4.54%、0.65%、24.03%、4.55%。GCN 的精确率虽然仅略微提高,但F1 值提高3.75%。GCN 基于邻居交易特征利用交易网络拓扑结构对邻居交易信息进行刻画,而本文提出的不可信度是根据交易网络对不可信度直接刻画。因此,融合不可信度后,模型召回率明显提高。从表3 可以看出,RF 模型使用本地特征LF 和聚合特征AF 检测时,精确率、召回率已达到93%~97%,加入不可信度R 后,精确率、召回率只有略微提高。因此,R 对检测非法交易的有效性与选择模型有关。
模型对交易进行分类后,得到交易的合法和非法概率,记为P(交易y合法)和P(交易y非法),两者和为1。加入交易不可信度后,以逻辑回归为例,67.5%的非法交易获得更高的P(交易y非法),58.4%的合法交易获得更高的P(交易y 合法)。预测概率的变化直接导致上述分类精确率和召回率的提高,验证了不可信度对非法交易检测的有效性。
从表2、表4、表5 可以看出,本文通过LR 检测得到的非法交易对训练集进行迭代。在扩增训练集后,LR、MLP 和GCN 模型的F1 值均提高。LR、GCN的精确率平均提高0.6%、0.985%,召回率平均提高1.95%、2.6%。MLP 的精确率略微降低,召回率提高1.95%。由于扩增数据集时会加入一些有假阳性的交易,因此分类结果精确率略微降低,对RF 模型的影响较为明显,精确率平均降低了3.1%。召回率和F1 值提高,说明扩增训练集能够有效提高LR、MLP和GCN 模型的检测能力。
5 结束语
本文设计基于交易不可信度的比特币非法交易检测方法。定义交易不可信度,通过量化交易不可信度并构建不可信度计算模型,同时把交易不可信度融合到已有的判别模型中,提高模型的检测能力。针对非法交易样本不足的问题,本文在量化交易不可信度的基础上,通过迭代训练集的方式扩增非法交易样本。实验结果表明,该方法能够有效提高非法交易的精确率和召回率。后续将针对实时交易的非法检测问题进行研究,进一步优化本文方法的实时性。
猜你喜欢
中国外汇(2019年18期)2019-11-25
当代陕西(2019年5期)2019-03-21
海峡姐妹(2017年10期)2017-12-19
三联生活周刊(2017年33期)2017-08-11
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
银行家(2017年1期)2017-02-15
股市动态分析(2016年22期)2016-12-27
股市动态分析(2016年23期)2016-12-27
股市动态分析(2015年13期)2015-09-10
