
基于时空Transformer的社交网络信息传播预测
2022-08-12 13:29范伟刘勇
计算机研究与发展 2022年8期
范 伟 刘 勇
(黑龙江大学计算机科学技术学院 哈尔滨 150080)
随着社交网络应用的日益普及,社交网络分析已经成为数据挖掘领域的一个主要研究方向.目前,许多研究人员正通过对历史信息传播数据进行建模来探索信息传播机制,预测信息传播过程.信息传播过程预测在谣言检测[1]、流行病学[2]、病毒式营销[3]、媒体广告[4]、新闻和模因[5]等领域具有广泛的应用.
传统的信息传播预测方法试图从信息传播数据中学习信息传播模型.但这些方法通常依赖于网络结构、时间信息[6]、用户特征[7]、信息内容[8]和用户间的交互[9]等显式特征来构建传播模型.虽然这些特征工程方法能提高预测的性能,但它需要大量的人力和广泛的领域知识,缺乏泛化性,在不同的社交网络平台中效果不稳定.
近年来,随着深度学习的快速发展,许多工作都试图用神经网络来解决信息传播预测问题,并取得了良好的效果[10-11].现有大部分研究或者利用信息传播序列,或者利用社交网络进行信息传播预测,传播序列能反映信息传播趋势.基于这个观点,许多研究(例如DeepDiffuse[10],Topo-LSTM[11],CYAN-RNN[12]和SNIDSA[13])学习信息传播序列的链式结构,并使用RNN对生成的有向无环图的传播结构进行建模.社交关系能加速信息传播过程,因为人们普遍会和他们的朋友有着一致的兴趣爱好,并且人们会有更高的概率转发或评论他们朋友所发布的消息.基于这个观点,许多研究[7,14-15]利用用户在社交网络中的相互影响来预测信息传播过程.
然而,现有工作仍存在3个方面问题:1)现有的研究要么仅利用信息传播序列,要么仅利用社交网络,很少同时利用这2个重要因素,导致难以捕获传播过程的复杂性;2)现有研究通常使用RNN或其变体来进行信息传播预测,但它们捕捉信息相关性的能力不强,导致预测准确率不高;3)现有研究通常将时序特征和结构特征进行简单拼接,难以对信息传播过程中的时空特征进行有效建模.
为解决上述问题,我们提出了一种基于时空Transformer(spatial-temporal transformer, STT)的社交网络信息传播预测模型.该模型能将信息的社交网络图和动态传播图结合起来进行信息传播预测.对于问题1,我们构建了一个由社交网络图和动态传播图组成的异构图,然后使用GCN来获取用户的结构特征;对于问题2,我们使用改善的Trans-former[16]模型来进行序列任务预测,来改善捕捉信息相关性能力;对于问题3,我们将时序特征作为Transformer的Query集,将结构特征作为Key和Value集来有效融合时序特征和结构特征,从而捕获用户的时空特征.
此外,在实验中我们发现Transformer中原有的残差网络融合的效果并不理想,所以我们提出了一个新的残差融合方法,进一步融合用户的时序特征和结构特征,改善融合效果.
本文工作的主要贡献有4个方面:
1) 提出了一种新的基于时空Transformer的神经网络(STT)用于社交信息传播预测;
2) 使用由社交图和传播图组成的异构图来联合建模社交关系和信息传播关系;
3) 将Transformer模型应用到信息传播预测领域,并提出了一种新的时空特征融合方式,用Transformer模型的Query,Key和Value集将时序特征和结构特征进行融合,同时提出了一个新的残差融合方法来进一步改善融合效果;
4) 在3个真实数据集上的实验结果表明:所提出的STT模型能显著改善预测效果.
可以下载本文的源码(1)https://github.com/DHGPNTM/STT.
1 相关工作
本节主要从2个方面介绍相关工作,1)信息传播预测方法;2)Transformer及其应用.
1.1 信息传播预测
1.1.1 基于传播序列的方法
基于传播序列的方法根据观察到的传播序列来解释用户之间的影响.早期的一些工作假设在信息传播过程中存在着一个先验传播模型,如独立级联模型[17]或线性阈值模型[18].虽然这些模型[17-19]刻画了用户之间的隐式影响,但这些方法的有效性依赖于先验信息传播模型的假设,而且这些假设很难验证.
随着神经网络的发展,一些研究[20-22]应用深度学习从信息传播序列中自动学习底层传播序列的表示来进行传播预测.例如,Topo-LSTM[11]构建了由传播序列组成的动态有向无环图(DAG),并使用基于拓扑感知的节点嵌入扩展了LSTM机制以学习有向无环图的结构.CYAN-RNN[12]将传播序列建模为树型结构,并采用了编码器-解码器框架来捕获传播序列中的交叉依赖.DeepDiffuse[10]为了能利用用户转发信息的时间戳,采用了注意力机制和嵌入方法,根据之前观察到的传播序列来预测何时以及何人将转发信息.
大多数基于传播序列的方法都将传播预测问题视为一个序列预测任务,其目的是按顺序预测传播用户,并根据历史传播序列来研究如何影响未来的传播趋势.这些方法在对传播过程建模时往往忽略了用户之间的社交关系及其相互作用.此外,这些方法也忽略了信息传播的全局影响.因此,如果只考虑传播序列很难准确地预测信息传播过程.
1.1.2 基于社交网络的方法
人们和他们的朋友会有一些共同的兴趣,如果他们的朋友转发了一条推特或者微博,那么他们也会有很大的概率去转发它.基于这种假设,最近的一些研究[14,23-24]利用社交网络解释人际关系对传播预测的影响并且用来提高信息传播预测的效果.例如,文献[7]尝试利用用户社会角色之间的相互作用及其对信息传播的影响,提出了一种基于角色感知的信息传播模型.该模型将社会角色识别和传播序列预测结合到一个框架中.文献[13]利用社交网络中邻居之间的结构特征和具有顺序性质的局部结构模式,并采用基于循环神经网络(recurrent neural network, RNN)的框架对传播序列进行建模.文献[15]提出多尺度信息传播预测模型.在微观视角下他们使用RNN和强化学习共同预测下一个转发信息的用户,在宏观视角下使用基于多任务的学习框架在传播序列中评估转发信息用户的总数量大小.
然而,大多数这些方法都过度关注于当前的信息传播序列,忽略了其他信息的传播序列对当前信息传播的影响,这不能捕获全局信息的转发关系,所以它们不足以模拟信息传播过程中的复杂关系.与只基于社交网络的模型不同,我们通过构建由社交网络图和动态传播图来共同学习信息传播的全局结构,可以显著提高模型预测的准确性.
1.2 Transformer
在Transformer出现之前,seq2seq任务主要做法是使用RNN及其变体或者CNN构成的编码器解码器框架.但RNN具有无法并行运算和计算复杂度高等缺点,因此自Transformer模型提出以来,很多NLP问题尝试使用Transformer来解决.文献[25]提出了Transformer-XL,通过递归机制和一种新型相对位置编码方案来捕捉更长距离的上下文依赖,解决上下文碎片问题.文献[26]提出了一个预训练的语言表征模型,不再采用传统的单向语言模型进行预训练,而是生成深度的双向语言表征.Transformer在计算机视觉领域中也有很多的应用.例如:文献[27]尽可能使用原始Transformer结构,用self-attention机制完全替代CNN,对于输入图像进行切片,每个切片之间没有重叠,将切片结果作为Transformer的序列输入.
目前在信息传播预测任务中,主要使用RNN及其变体LSTM[28]和GRU[29].RNN及其变体在训练时必须是对数据进行顺序处理即逐个用户进行处理,因此无法并行训练.此外RNN及其变体对用户的编码仅在下一个时间步被保留,这意味着当前用户的编码仅强烈影响下一个用户的表示,在几个时间步长之后其影响很快消失. 而Transformer模型可以避免递归,允许并行计算减少训练时间,并减少由于长期依赖性而导致的性能下降,而且相对于RNN及变体,其结构灵活性和通用性更强,可以捕捉信息相关性的范围更广.此外,在NLP领域中Transformer对句子的处理是非顺序的,句子是整体处理的,而不是逐字处理.Transformer不依赖于过去的隐藏状态来捕获对先前单词的依赖性,而是整体上处理一个句子,所以不存在丢失或忘记过去信息的风险.基于以上诸多优势,本文尝试将Transformer应用到信息传播预测任务中.
2 问题定义
本节我们将要介绍用到的符号,并阐述要解决的信息传播预测任务.
定义1.静态社交图.静态社交图定义为有向图G=(V,E),其中V和E分别表示用户集和边集.如果用户u关注了用户v,那么eu,v=1.
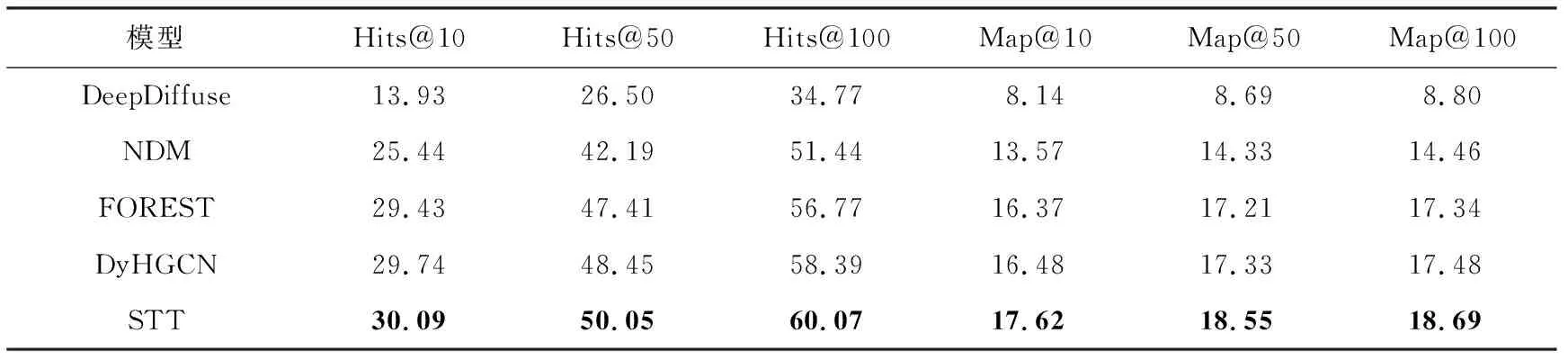
定义2.信息传播序列.信息i的传播序列被表示为一系列的带有时间戳的转发行为,即xi={(vi,1,ti,1),(vi,2,ti,2),…,(vi,Nc,ti,Nc)},其中(vi,j,ti,j)元组表示用户vi,j在第i个信息传播过程中在时间ti,j转发信息,Nc表示信息被转发的最大数量.转发信息的用户通常按照时间进行排序,因此ti,j-1 定义3.动态传播图.信息i的有向动态传播图表示为Gxi=(Vxi,Exi),其中Vxi⊂V表示转发或评论信息i的所有用户.如果用户u转发或评论了用户v发布的信息,则ev,u=1.给定一个信息级联集合X={x1,x2,…,xM},对应的动态传播图集合表示为GX={Gx1,Gx2,…,GxM}. 本文研究问题定义:给定信息i的传播序列xi={(vi,1,ti,1),(vi,2,ti,2),…,(vi,Nc,ti,Nc)},预测下一个转发信息的用户vi,Nc+1.具体来说,根据观测到的历史信息传播序列集合,学习一个信息传播预测模型Ψ.当遇到一个新的传播序列xi={(vi,1,ti,1),(vi,2,ti,2),…,(vi,Nc,ti,Nc)}时,使用模型Ψ计算下一时刻每个用户u转发信息的条件概率P(u|{(vi,1,ti,1),(vi,2,ti,2),…,(vi,Nc,ti,Nc)}). 本节我们详细描述所提出的STT模型.该模型的框架如图1所示.首先,我们构造了一个由社交图和动态传播图构成的异构图;然后使用GCN从异构图上学习用户的结构特征;再将用户的时序特征和结构特征分别添加位置嵌入,把添加位置嵌入后的时序特征作为Transformer的Query集,把添加位置嵌入后的结构特征分别作为Transformer的Key和Value集;最后用Transformer预测下一个转发信息的用户. Fig. 1 The structure of spatial-temporal Transformer neural network图1 时空Transformer神经网络的结构 实验中我们发现Transformer原有的残差网络融合效果并不理想,所以提出了一个新的残差融合方式,能够有效融合用户的时序特征和结构特征. 异构图的构建过程如图2所示.我们利用用户之间的社交关系来构建一个用户社交图G=(V,E),这是一个有向无权图.同时使用信息传播级联集合X={x1,x2,…,xM}对应的动态传播图集合GX={Gx1,Gx2,…,GxM},这是一个有向图集合.我们将动态异构图定义为GH=(V,EH),其中EH=E∪EX,EX为动态传播图集合GX的边集. 在构建动态异构图GH的过程中,不同的动态传播图之间可能存在着相同的边.例如:在图2中,在消息1的动态传播图中有边v2→v3,在消息M的动态传播图中也有边v2→v3.在异构图中,我们需要为每条边分配相应的权重.我们用传播图中某条边出现的次数作为异构图中该边的权重.例如:在图2的异构图中,边v2→v3的权重为2. Fig. 2 The construction process of dynamic heterogeneous graph图2 动态异构图的构建过程 如图1右下角所示,异构图有2种类型的边关系:关联关系和转发关系.我们利用用户节点和2种边关系构造邻接矩阵D∈|V|×|V|,|V|表示用户的数量.我们使用图卷积网络(GCN)从异构图中学习用户节点的表示.GCN对邻居节点信息聚合方式定义为 H(l+1)=σ(DH(l)W(l)), (1) 其中,H(0)∈|V|×d是通过正态分布随机初始化的用户嵌入,W(l)∈d×d是可学习的参数,d是用户嵌入的维度,l是GCN的层数,σ(·)是一个激活函数. 设图卷积网络的层数为L,则使用GCN学习到的节点表示HL隐含包括了节点的结构特征. 通过异构图神经网络学习后,我们获得了异构图中所有节点的结构特征表示HL.因此我们可以利用HL直接获取消息i中每个用户的结构特征Hi={hi,1,hi,2,…,hi,Nc}∈NC×d,其中Nc表示所有消息中被转发的最大数量,hi,j∈d是第i个消息中第j个用户的结构特征表示.如果某个消息转发数量小于Nc,则用零向量补齐. 值得注意的是,在不同消息中出现的相同用户,他们的结构特征也相同.例如:如果某个用户是第2个转发消息1的用户,同时也是第3个转发消息2的用户,那么该用户在不同消息中的结构特征表示h1,2和h2,3也是相同的.因此,不相同的结构特征数量最多是全体用户数.通过这种方式,我们获取到的结构特征是用户全局的结构特征,可以捕获用户全局的转发行为. 因为用户转发或评论消息的时间戳对预测效果也起着至关重要的作用,所以我们也需要获取用户的时序特征.为了方便表示用户的时序特征,我们把整个时间分成n个时间间隔,把每个用户转发消息的时间戳映射到这n个时间间隔中的一个,就可以得到消息i中每个用户的时序特征Ti={ti,1,ti,2,…,ti,Nc}∈NC×d,其中ti,j∈d表示第i个消息中第j个用户的时序特征表示. 值得注意的是,如果两用户之间的转发或评论时间很接近,那么这2个用户很可能被划分到同一个时间间隔中,则他们的时序特征也是相同的.因此,在用户时序特征T中只有n个不相同的时序特征. 因为相对位置信息可以反映用户转发或评论消息的先后顺序, 所以在得到用户的时序特征和结构特征表示之后,我们使用位置嵌入分别与时序特征和结构特征进行结合.具体地来,我们为消息的每个位置j定义一个位置嵌入pj,pj∈d是可学习的参数, 用来表示相对位置信息.结构特征hij添加位置嵌入后变为时序特征tij添加位置嵌入后变为设为消息i中用户结构特征添加位置嵌入后所得到的用户结构特征,为消息i中用户时序特征添加位置嵌入后所得到的时序特征.显然,我们有Nc×d. Transformer 中的decoder层如图3所示.我们将N个decoder层进行叠加,来进行最后的序列任务预测,其中带有掩码的多头注意力层定义为 Fig. 3 Transformer decoder layer图3 Transformer中的decoder层 (2) Ai=[ai,1:ai,2:…:ai,Head]WQ, (3) 在经过多头注意力层之后,会使用残差网络来强化用户特征,但是原有的残差网络连接在实验中效果并不理想,因为它只是将2个特征进行简单的相加.所以我们提出了一个新的特征融合方式来代替原有的残差网络连接,能够有选择性地集成用户的时序特征和结构特征,同时摒弃掉冗余的信息.然后我们将时空特征跟时序特征进行残差融合,再进入层归一化,紧接着进入2层全连接网络,之后再进行残差连接跟层归一化,详细过程定义为 (4) (5) Outputi=LayerNorm(Fusion(FFNi,Fi)), (6) 其中,W1,W2∈Nc×d都是可学习的权重参数,Fi,FFNi,Outputi∈Nc×d,LayerNorm(·)是层归一化函数,Relu(·)是一个激活函数,Fusion(·)函数是我们新提出的残差融合方式,能够有选择性地集成用户的时序特征和结构特征,具体定义为 Fusion(f1,f2)=g⊙f1+(1-g)⊙f2, (7) (8) 在获得消息i中每个用户最后的特征表示Outputi∈Nc×d之后,使用2层全连接网络和Softmax函数来计算消息i中每个节点被激活的概率 (9) 我们使用交叉熵损失函数作为消息i的损失函数,具体定义为 最后,使用所有消息的损失函数作为模型总的损失函数,具体定义为 根据文献[13,15]的研究,我们在3个公共可用的数据集上进行了实验对提出的模型进行评估.详细的统计数据如表1所示.#Users表示社交网络中用户数量,#Links表示社交网络中用户之间关联关系的数量,#Cascades表示数据集中信息传播序列的数量,Avg.Length表示信息传播序列的平均长度. Table 1 Datasets Statistics表1 实验数据描述 1) Twitter数据集[30]记录了2010年10月期间包含URL的所有推文,每个URL都被解释为一个在用户之间传播的信息项. 2) Douban数据集[31]是从豆瓣的社交网站上收集的,用户可以更新他们的图书阅读状态,并可以关注其他用户的状态.每本书或电影都被认为是一个信息项,如果2个用户参与同一讨论超过20次,他们将被视为朋友. 3) Memetracker数据集[5]是从在线网站上收集的数百万篇新闻和博客文章,并追踪最常见的引用和短语即模因,以分析模因在人们之间的迁移.每个模因被视为一个信息项,每个网站的URL被视为一个用户.值得注意的是,这个数据集没有潜在的社交图. 按照之前的研究[13,15],我们随机抽取80%的数据进行训练,10%用于验证,剩余10%用于测试. 为了验证提出的STT效果,我们与最新的信息传播预测深度学习方法进行比较,具体方法为: 1) Topo-LSTM[11].将信息传播序列建模为动态有向无环图,并扩展标准的LSTM模型,学习具有拓扑感知的用户嵌入进行信息传播预测. 2) DeepDiffuse[10].使用嵌入技术和注意力机制处理转发时间戳信息.该模型可以根据之前观察到的级联序列来预测社交网络中何时及何人将转发信息. 3) NDM[22].建立一个基于自注意力机制和卷积神经网络的微观级联模型,可以缓解长期依赖问题. 4) SNIDSA[13].是一个对信息传播具有结构关注的序列神经网络.采用递归神经网络框架对序列信息进行建模,结合注意力机制来捕获用户之间的结构依赖关系,并开发一种门控机制来整合序列和结构信息. 5) FOREST[15].是一种基于强化学习的多尺度信息传播预测模型.该模型将宏观传播范围信息纳入了基于RNN的微观传播模型中,它是最新的序列模型并取得了较好的实验效果. 6) DyHGCN[32].利用动态异构图卷积神经网络和自注意力机制来获得用户表示.据我们所知,该模型目前在信息传播预测方面取得了最好的实验效果. 根据观察到的信息传播序列来评估下一个转发用户,这个预测任务通常被认为是一个检索问题,在所有用户的输出概率中,下一个实际转发信息的用户将得到更高的概率.我们利用2个广泛使用的排名指标Map@k和Hits@k进行评估. 对比方法的超参数与原论文中的设置相同.我们的模型是由PyTorch实现的,这些参数由Adam优化器进行更新,学习速率设置为1E-3,批处理大小batch=16,用户的各个特征维度大小d=64,Transfomer中的decoder层数N=2,时间间隔n=8,最后将Transfomer中多头注意力的头数Head=8. 我们在3个公共数据集上比较了STT模型与基线模型,实验结果如表2~4所示.我们提出的STT模型在3个数据集上的指标Map@k和Hits@k均优于所有基线模型.值得注意的是粗体字体表示最高数值,由于Memetracker数据集中缺乏社交关系,因此我们在Memetracker数据集中没有给出Topo-LSTM和SNIDSA模型的实现结果. Table 3 Result of Douban Dataset Information Diffusion Prediction表3 Douban数据集信息传播预测结果 Table 4 Result of Memetracker Dataset Information Diffusion Prediction表4 Memetracker数据信息集传播预测结果 STT模型与Topo-LSTM,DeepDiffuse和NDM相比,在Map@k和Hits@k指标上取得了明显的优势.这些基线方法只将传播路径建模为一个序列,它们不使用社交网络,然而社交网络可以反映用户间的关联关系,促进用户间的信息流动.实验结果表明,用户间的社交网络对信息传播预测有着重要的影响. STT模型与SNIDSA和FOREST相比,在Map@k和Hits@k方面也有着较大的改进.虽然SNIDSA和FOREST利用用户之间的社交关系来预测信息的传播,但它们只将传播路径视为一个序列,而没有考虑传播路径中所包含的结构信息.因此SNIDSA和FOREST不能充分建模信息传播过程导致性能较差.STT模型不仅利用社交网络信息,而且还利用传播图来建模信息传播行为,显著提高了预测性能. STT模型与DyHGCN模型相比也有明显的改善.为了量化改善的程度,我们计算了STT模型相对于DyHGCN模型改善的百分比,如表5所示.从表5可以看出,STT模型在Douban数据集的Map@k指标上均提高超过20%,由此可看出STT模型的有效性.虽然DyHGCN同时使用社交网络图和传播图来建模传播行为,但它没有有效地利用用户的时序特征和结构特征.因此DyHGCN将在一定程度上降低信息传播预测的性能.在STT模型中,我们使用Transformer模型把用户时序特征和结构特征进行有效结合来获取用户时空特征,同时我们使用新提出的残差融合方式来替代Transformer中原有的残差融合方式来进一步改善融合效果.因此STT模型在Map@k和Hits@k方面都优于DyHGCN. Table 5 Percentage Increase of STT Model Compared with DyHGCN Model表5 与DyHGCN模型相比STT模型提高的百分比 % 为了研究STT模型中各个组成部分所起的作用,我们对模型的不同组成部分进行了一系列的消融实验.消融实验结果如表6和表7所示,我们没有给出Memetracker数据集的消融实验,因为这个数据集没有社交网络.STT模型及其变体模型定义为: Table 6 Ablation Study on Twitter Dataset表6 在Twitter数据集上的消融实验 Table 7 Ablation Study on Douban Dataset表7 在Douban数据集上的消融实验 1) STT-S.这个模型移除掉了社交网络图. 2) STT-D.这个模型移除掉了信息传播图. 3) STT-H.这个模型移除掉了动态异构图,并且随机初始化用户的特征表示. 4) STT-T.这个模型移除掉了用户的时序特征,Transformer中Query集用用户的结构特征代替. 5) STT-TRM.这个模型移除掉了Transformer,并用循环神经网络RNN代替. 6) STT-F.这个模型移除掉了Transformer中新提出的残差融合方式,用原有的残差连接方式代替. 从表6和表7可以看出,当移除掉社交网络图时,与STT模型相比,实验效果有所下降.而当移除掉信息传播图时,也可以看到相同的现象.实验结果表明,STT模型中社交关系和转发关系对信息传播预测都是十分重要的. 当移除掉动态异构图时,与移除了社交网络图或信息传播图相比,预测效果进一步降低.实验结果表明,这2种信息特征可以互补,将它们联合使用有助于提高预测效果. 当移除掉用户的时序特征时,与STT模型相比.实验效果有很大程度的下降.实验结果表明,时序特征对信息传播预测起着至关重要的作用.将时序特征和结构特征进行有效结合,获取到用户的时空特征对信息传播预测有着积极的作用. 当移除掉Transformer模型,并用循环神经网络RNN代替时,与STT模型相比,实验效果有很大程度的下降,特别是在Twitter数据集上效果下降更为严重.实验结果表明,Transformer模型应用到信息传播预测领域效果非常显著,这说明Transformer模型内部的多头注意力可以大大提升实验效果. 当移除掉Transformer模型中新提出的残差融合方式,用原有的残差连接方式代替时,与STT模型相比,实验效果有很大程度的下降.实验结果表明,我们提出的新残差融合方式比原有的残差连接方式更有效,这是因为新的残差融合方式采用了融合门的机制,能够有选择性地集成用户的时序特征和结构特征. 我们在Twitter数据集上进行了一些超参数敏感性实验,研究了超参数的不同选择对模型性能的影响. 1) 时间间隔n.时间间隔n从{1,2,4,8,16}中选择,其不同值的选择在Twitter数据集上的表现如表8所示.随着时间间隔n的增加,STT模型的效果逐渐提高,但是当时间间隔n>8时Map@k和Hits@k没有进一步改进反而下降.这是因为随着时间间隔n的增加,用户的时序特征表示越准确,而增加到一定数值时, 学习的时序特征过多容易导致过拟合反而会使实验效果下降.因此,我们在本文中将时间间隔n=8. Table 8 Effect of Time Interval n on Twitter Dataset表8 时间间隔n在Twitter数据集上的影响 2) Transfomer中decoder层数N.层数N从{1,2,3,4,5,6}中选择,其不同值的选择在Twitter数据集上的表现如表9所示.从表9中的数据可以看出,当层数N=2时,实验的效果达到最优,并且随着层数N的增加,实验效果在逐渐下降.这是因为神经网络的层数增加到一定数值时,学习的信息过多导致过拟合反而会使实验效果下降.因此,我们在本文中将Transfomer中decoder的层数N=2. Table 9 Effect of the Number of Decoder Layers N on Twitter Dataset表9 decoder的层数N在Twitter数据集上的影响 3) 多头注意力的头数Head.头数Head从{1,2,4,8,16}中选择,其不同值的选择在Twitter数据集上的表现如表10所示.从表10中的数据可以看出,随着多头注意力的头数Head增加,实验效果在逐渐变好,当Head=8时实验效果达到最优,当Head继续增加时效果有些下降.这是因为随着多头注意力的头数Head增加,学到的不同空间维度信息也就越多,而增加到一定数值时学习的冗余信息过多将会导致实验效果下降.因此,我们在本文中将多头注意力的头数Head=8. Table 10 Effect of the Number of Heads of Multi-head Attention Head on Twitter Dataset表10 多头注意力的头数Head在Twitter数据集上的影响 4) 用户特征表示的维度d.维度d从{16,32,64,128,256}中选择,其不同值的选择在Twitter数据集上的表现如表11所示.从表11中的数据可以看出,随着维度d的增加,实验效果逐渐变好,但是当维度d超过64时,实验效果开始下降.这是因为随着用户特征表示的维度d增加,用户特征所蕴含的信息也就越多,而增加到一定数值时用户特征蕴含的冗余信息过多将会导致实验效果下降.因此,我们在本文中将用户特征表示的维度d=64. Table 11 Effect of Dimension Size of User Embedding d on Twitter Dataset表11 用户嵌入维度d在Twitter数据集上的影响 本文研究了信息传播预测问题,提出了一种基于时空Transformer神经网络的模型STT来预测传播过程.在STT模型中,我们通过由社交图和动态传播图组成的动态异构图来学习用户的结构特征,然后利用Transformer模型将用户的时序特征和结构特征相结合来学习用户的时空特征,并设计了一个新的残差融合方式来进一步改善融合效果.在3个数据集上的实验结果表明,我们提出的模型STT显著优于基线模型.未来我们准备加入用户属性特征和消息文本特征来尝试改善预测性能.3 基于时空Transformer的社交网络信息传播预测模型
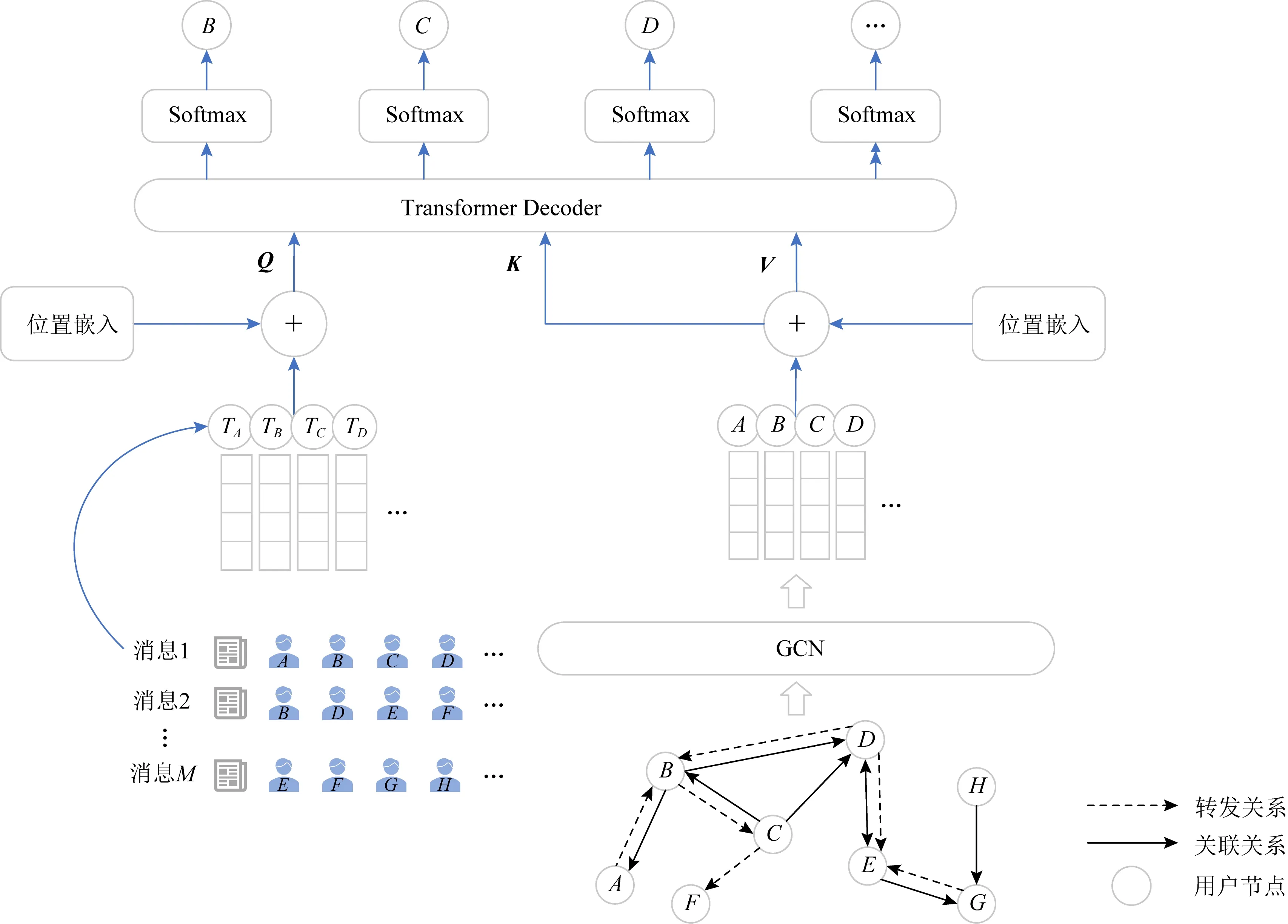
3.1 异构图构建

3.2 异构图神经网络
3.3 时空Transformer神经网络



3.4 信息传播预测
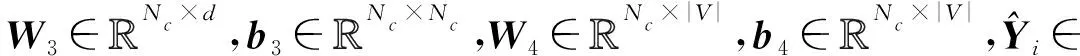
4 实验结果及分析
4.1 实验数据

4.2 对比方法
4.3 评价指标和参数设置
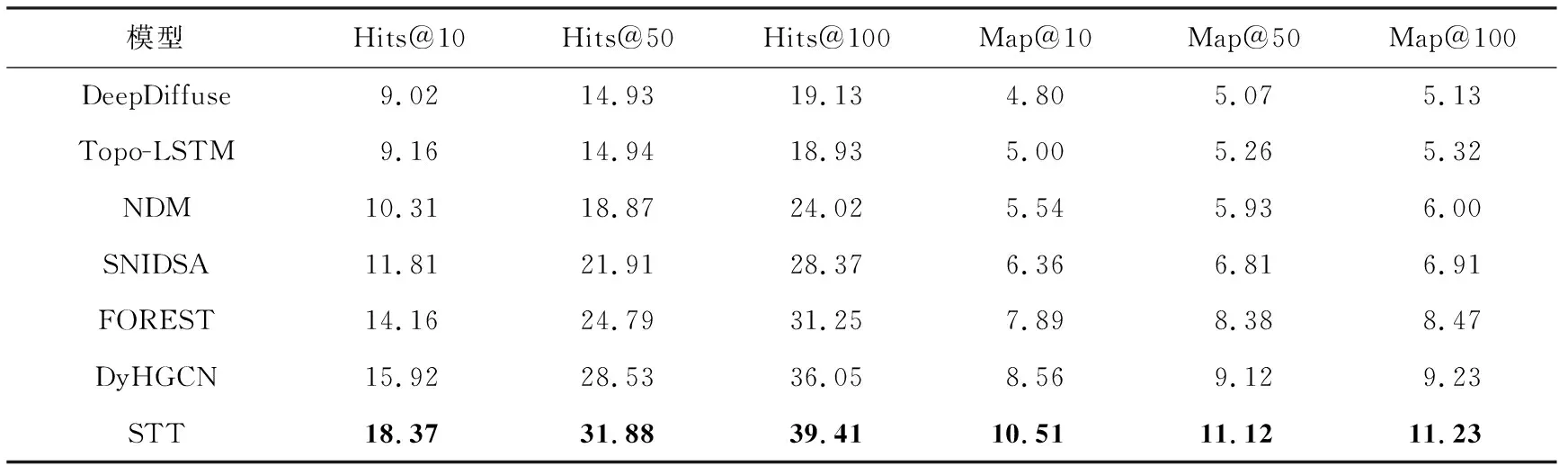
4.4 实验结果

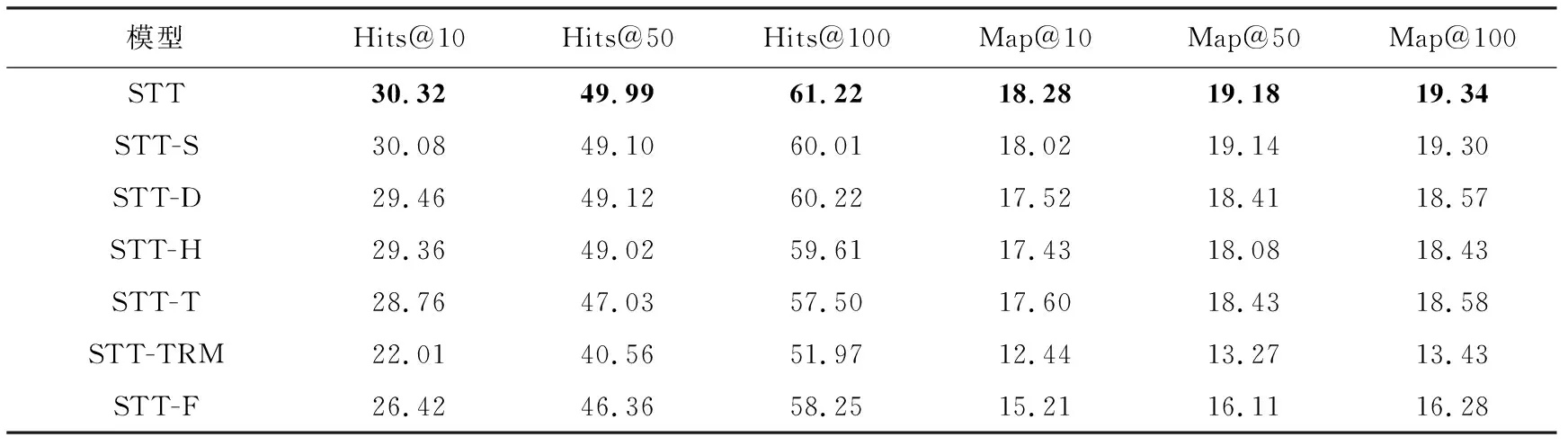
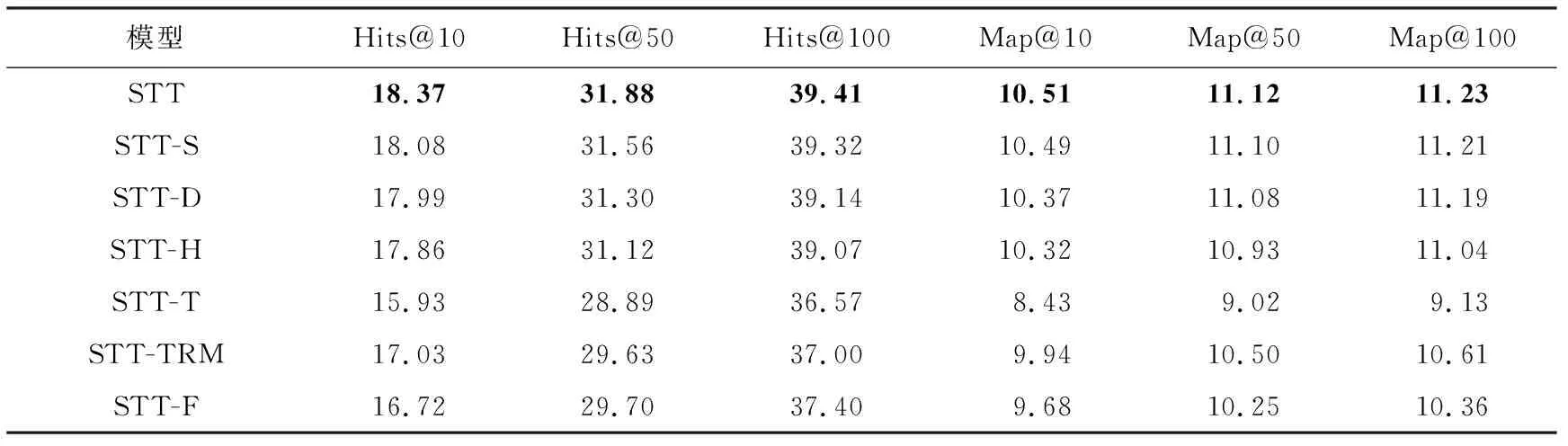
4.5 消融实验
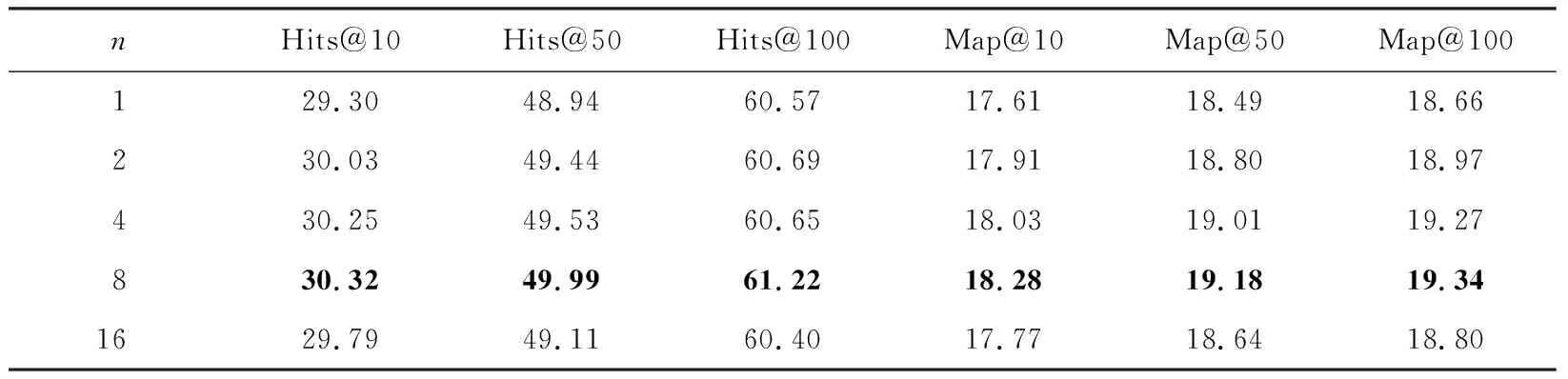
4.6 参数分析



5 结 论
猜你喜欢
天中学刊(2022年4期)2022-11-08
导航定位学报(2022年5期)2022-10-13
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
安徽农学通报(2022年8期)2022-05-06
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
土壤学报(2022年1期)2022-03-08
意林·作文素材(2021年23期)2021-01-22
高中生学习·高三版(2016年4期)2016-11-19
