
基于决策树和DFA的老挝文敏感信息过滤算法
2022-08-10 08:12王艺皓丁洪伟王丽清
计算机应用与软件 2022年7期
王艺皓 丁洪伟 王丽清 李 波 李 浩
1(云南大学信息学院 云南 昆明 650500) 2(云南大学科技处 云南 昆明 650500)
0 引 言
近年来随着互联网的发展和对外门户的开放,我国与东南亚地区的交流日益频繁,大量参差不齐的跨境语言产品涌入其中,给跨境语言网络的舆情监管工作带来了一定的挑战。跨境语言网络缺乏有效的技术和统一的管理,大量有关政治、宗教等敏感信息充斥其中,给区域稳定和社会和谐带来了极大的威胁。由于跨境语言网络上的敏感内容大多以文本形式呈现,因而对文本敏感信息的检测和过滤成为了维护跨境网络舆情安全的关键技术之一,其相关算法的研究则显得尤为重要。
鉴于跨境语言的多样性和复杂性,本文以老挝文为切入口,针对老挝文的语言特点,提出了一种面向老挝文的敏感信息过滤算法。经研究发现,老挝文有以下几种特点:一是单词构成复杂,一个老挝文单词由辅音、元音和声调共同组成,其音节字母和声调的不同位置会对词的含义产生影响,这给处理老挝文信息带来了一定的难度;二是语法形式单一,老挝文属于孤立型语言[1],它只能通过虚词和词序的不同组合来表达含义,老挝文没有像汉语那样丰富的形式变化;三是句子词汇切分度低,老挝文词与词之间没有类似空格这样明显的分界符,需要选取一种合适的分词方法对老挝文句子进行词汇划分;四是语料匮乏,由于老挝文没有类似汉语、英语这样庞大的语料集,因此它含有大量的未登录词,这会对分词的精确程度产生一定的影响,进而给老挝文信息处理工作带来了极大的挑战。
目前,针对老挝文的敏感信息检测和过滤技术尚没有独立的模型和算法,但是对于中文的敏感信息识别和过滤问题已经取得了较多的研究成果。本文在研究了老挝文语言特点的基础上,提出了一种基于确定有穷自动机(Deterministic Finite Automaton,DFA)[2]和决策树(Decision Tree,DT)[3]的老挝文敏感信息过滤算法LDTDFA(Laos Decision tree DFA),实现了老挝文敏感信息的检测、过滤和报警,并取得了较好的过滤效果。
1 相关工作
文献[4-6]详细介绍分析了老挝文的语言特点,为本文解决老挝文语法分析、词汇划分以及词干提取提供了借鉴方法。对于老挝文分词方面,如文献[7]提出了最长音节匹配和命名实体相结合的混合方法,该方法虽简单高效,但对于老挝文这样的低资源语言来讲,获取高质量的语言资源难度较大,同时可移植性较差,不能很好地解决未登录词和歧义问题;文献[8]提出了一种基于条件随机场(Conditional Random Field,CRF)的老挝语分词模型(LaoWS),该模型把分词问题当作字母序列标注任务,词首用字母B表示,词中用I表示,相当于将其转化成了一个二分类问题。与基于词典的方式[7]相比,在语料库规模不大且测试语料相同的情况下,该模型实现了更高的准确率和召回率。所以选取一种高效率的分词方法是保证老挝文敏感信息检测效率的前提,更是实现老挝文敏感信息过滤的基础。
文献[9]提出了改进BM(Boyer Moore)算法,通过增大模式串移动的距离和失配时大的移动距离出现的概率,减少了窗口移动次数和字符比较次数,从而加快了匹配速度,提高了平均匹配效率。但是这种基于模式匹配的检测算法应用于老挝文敏感信息的过滤中效果并不理想。
文献[10]提出了一种敏感信息决策树过滤算法,通过构建敏感词决策树的方式提高了检测效率,并通过给出敏感词权重的方式实现敏感信息的检测和过滤。该方法依赖人工标记敏感级别,难以客观地表现文本的敏感程度,而且没有实现决策树的实时更新以及敏感词的屏蔽替换。
文献[11]针对中文拼音的特点,提出一种基于确定有穷自动机(DFA)的改进算法,通过敏感词拼音的第一个字母来构建敏感信息决策树,相比较于传统的DFA过滤算法[12]严重依赖于敏感信息语料库且匹配检测重复率高的缺点,其优点是不依赖敏感信息语料库,实现了敏感信息决策树的实时更新,提高了检测和过滤的效率。DFA算法是一种面向网络安全检测的高效匹配算法,它几乎可以处理任意类型的字符匹配操作。
2 算法设计
2.1 准备阶段
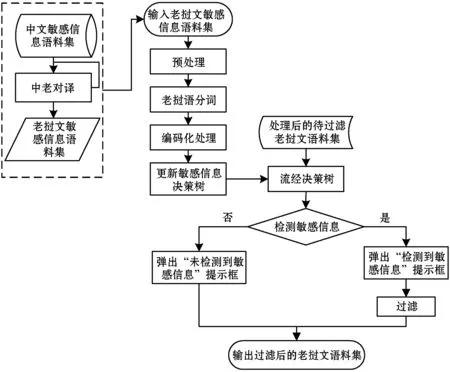
要想实现对老挝文的敏感信息过滤,首先需要进行以下三个准备步骤。第一,实现老挝文内容语料采集以及文本预处理;第二,对老挝文进行词汇划分和词干提取;第三,由于老挝文结构、语法与编码的特殊性,需要对老挝文进行编码化处理。准备阶段的过程如图1所示。

图1 准备阶段流程
2.1.1语料采集和文本预处理
目前对于信息采集有很多开源的工具,对于老挝文的语料采集并不困难,本文所用老挝文语料集主要来自纪录片字幕翻译中老双语平行语料数据集,同时也通过老挝文网页爬虫的方式不断完善补充老挝文语料集,已提取中老对齐语料文本近10 000条。

表1 阿拉伯数字与老挝数字对照表
2.1.2老挝文分词
词是自然语言中最小的有意义的构成单位,老挝文是由元音、辅音、尾辅音和声调组成的多音节文字[4],老挝语分词就是将一连串的老挝语字符按一定的规则划分成单个老挝词语序列的过程。虽然针对老挝文词法分析的相关研究相较于中英文起步较晚,但国内外已有实验室设计并实现了准确率较高的老挝语分词算法[8,13],近些年有关老挝语命名实体识别的研究[6]也逐渐兴起。老挝语分词的准确率和效率都在逐步提高。由于CRF具有特征选取灵活、拟合程度好、训练时间不长等优点,故本文选择采用了基于条件随机场(CRF)的老挝语分词模型[8],其基本原理如下:
假设x为观测序列,y和y*为标注序列,αj为对应的权重因子,hj为j处的转移特征函数,{Ri(x)|||i=1,2,…,n+1}为n+1个矩阵集合,每个Ri(x)均为|x×x|阶矩阵,Ri(x)由式(1)计算得出,其矩阵元素的乘积如式(2)所示。
(1)
(2)
式中:N(x)为x对应的归一化因子,由式(3)计算可得:
(3)
2.1.3编码化处理
为了提高老挝文敏感信息过滤的算法效率,需要将老挝语的词汇进行编码化处理。这样做的原因有以下三点:① 由于数据存储格式编码的差异性,处理后的老挝文语料集在输出的过程中可能会由于编码方式不当而出现乱码问题;② 由于DFA算法和决策树算法的特殊性,检测到的敏感信息会以字母的形式输出,难以重新还原成原本的词;③ 由于老挝文元音字母和辅音字母的特殊关系,元音字母可以在辅音字母的前后、上下出现,同一个字母出现在词汇的不同位置就会有不同的表达含义,同时声调的存在也会影响词表达意思的不同,这都给敏感信息的检测带来了一定的难度。
经过一系列的研究尝试,对比了几种不同的字符转化方式的编码解码效果,综合考虑了编码解码的易操作性、匹配的准确性以及对于老挝语词结构的适用性,本文决定采用常见字符代表的方式进行编码[14]。现行老挝文有33个辅音字母和28个元音字母,其中辅音相当于汉语中的声母,元音相当于汉语中的韵母。辅音字母分为单辅音和复合辅音,元音字母分为短音和长音。基于老挝文词的构成特点,本文将27个辅音字母映射为26个大写英文字母和一个0,由于老挝官方已经公告废除低辅音“”并以“”取代,但是民间仍然普遍使用,故在这里用“0”来映射以作区分;将28个元音字母用从1到9的阿拉伯数字和19个小写英文字母进行映射;将4个声调符号一一映射为小写英文字母“o、p、q、u”。对于老挝文字母及声调符号的映射关系如表2和表3所示。通过这样的映射关系,老挝语的词汇可以映射成由数字和大小写英文符号组成的符号串,如“”(森林)映射成的编码符号为“FoauWp”(书写顺序映射为从左到右,声调符号映射书写位置为该声调下方字母映射符号顺延一位)。通过字符映射的方式对老挝文语料集以及敏感信息语料集进行编码化处理,这样的做法不仅提高了敏感信息检测的算法效率,同时也对后面老挝文的还原工作有着重要的意义。
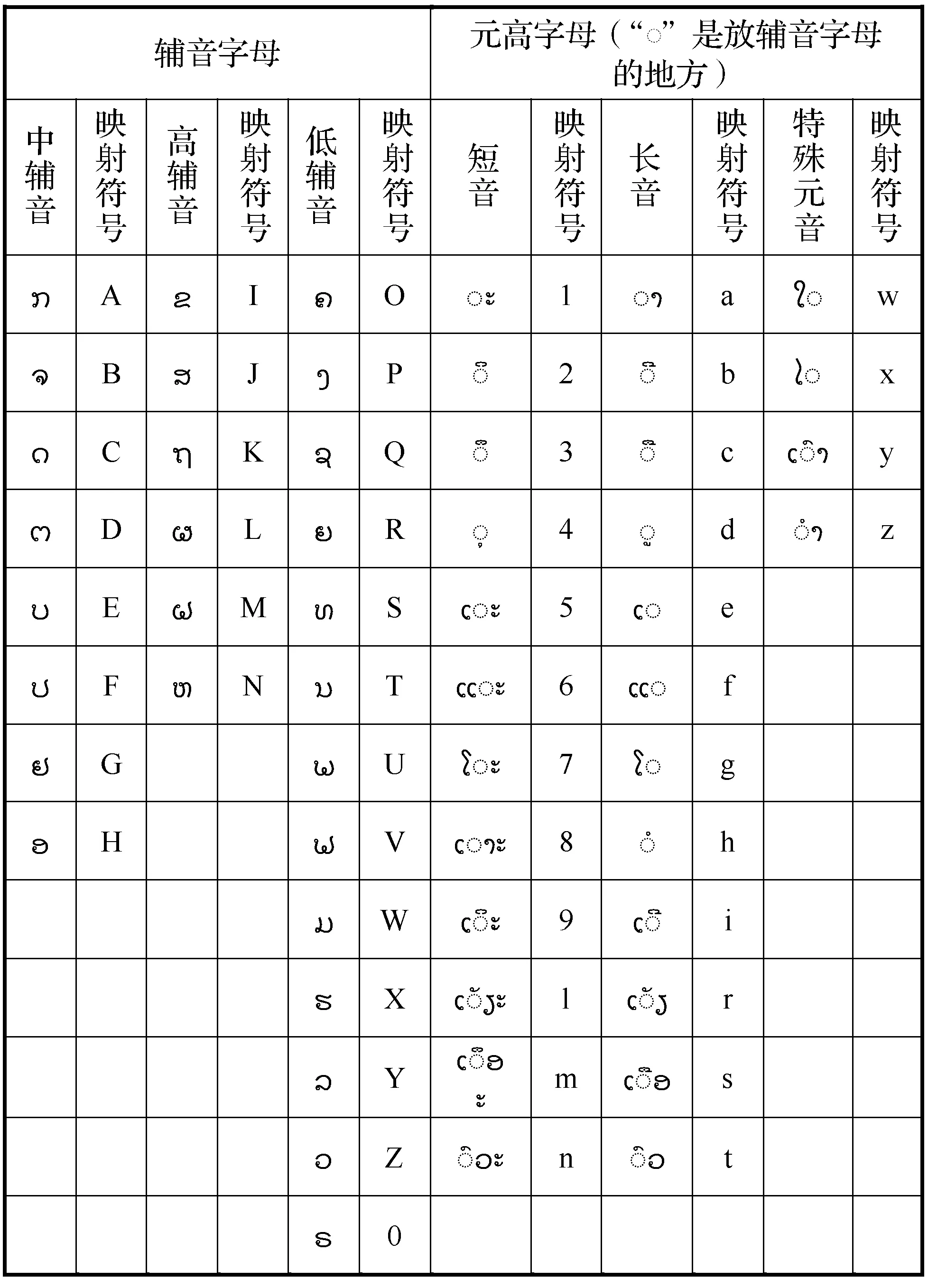
表2 老挝文字母映射表

表3 老挝文声调符号映射表
2.2 构建老挝文敏感信息树


图3 老挝文敏感信息决策树
由图3可以看出,本文构建的决策树不仅体现了老挝文字母和编码符号一一映射的关系,还包含了老挝文词汇的上下文信息和顺序信息,这为后文还原过滤后的老挝文提供了基础。
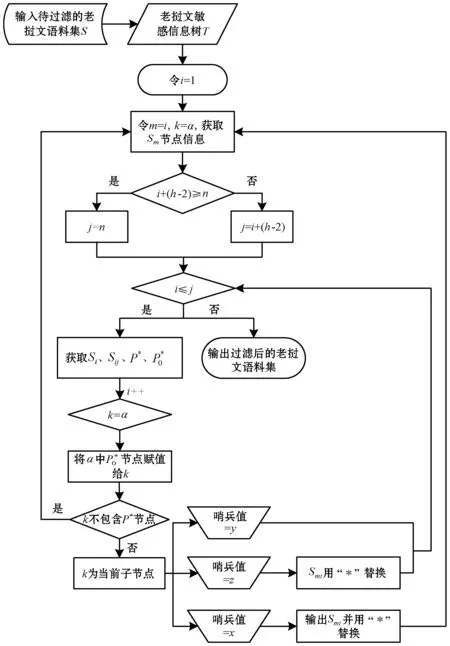
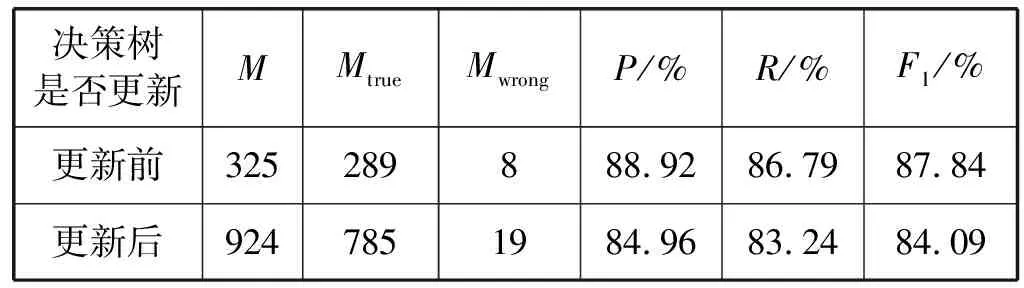
假设老挝文敏感词库集合为D={d1,…,di,…,dn-1},其中,1≤i 老挝文敏感信息决策树的构建并不复杂,主要是创建一个根节点α以及包含映射符号的59个子节点,如图3所示。接下来主要说明一下老挝文敏感信息树的更新算法,整个算法流程如图4所示。其中,叶子节点代表该节点是老挝文敏感信息中最后一个字符,同时没有子节点,用x表示;非叶子节点代表该节点不是老挝文敏感信息中最后一个字符,仍需继续向它的子节点进行匹配,用y表示;伪叶子节点代表该节点是老挝文敏感信息的最后一个字符,但存在子节点,用z表示;哨兵赋值表示是否需要按最大匹配原则继续检测敏感信息。 图4 老挝文敏感信息树更新算法 由图4可得,该算法不仅实现了老挝文敏感信息树的实时更新,而且具有较好的算法效率。 构建好老挝文敏感信息决策树之后,接下来就要实现老挝文敏感信息的检测和过滤。将预处理后的待过滤老挝文语料集以文本数据流的方式流经敏感信息树:如果检测到敏感信息,则立即弹出“检测到敏感信息”的警示框,进行敏感信息的过滤,即敏感信息用“*”替换,输出过滤后的老挝文语料集为“.txt”格式,并在控制台输出检测到的敏感词(注:在windows环境下输出格式设为“gb2312”,默认的“utf8”格式输出会出现乱码),同时输出算法运行时间;如果未检测到敏感信息,则弹出“未检测到敏感信息”提示框,输出老挝文语料集,并在控制台输出算法运行时间。 假设待过滤的老挝文语料集合为S={S1,…,Si},其映射符号集为P*,老挝文敏感信息的起点表示Sm,Sij表示第i和j个敏感字之间的老挝文字符串,检测到的敏感信息表示为Smi。则老挝文敏感信息的检测和过滤算法如图5所示。 图5 老挝文敏感信息的检测与过滤算法 由图4和图5可以共同看出,老挝文敏感信息决策树的高度与敏感信息的长度有一定关系,但对于老挝文而言,其敏感词长度是有限的,这有效降低了决策树的高度对算法空间复杂度的影响,从而在一定程度上提高了本文算法效率。 为了评估本文所提算法的性能表现,本文引入以下三个评价指标: (1) 查全率(Precision)。 (4) (2) 查准率(Recall)。 (5) (3) F1值(F1 score)。 (6) 本文所提出的面向老挝文的敏感信息过滤算法结合了决策树和DFA算法的优势,不但实现了对老挝文的检测和过滤,而且实现了敏感信息树的实时更新,对于老挝文的编码化处理更是提高了算法的效率和性能。本文算法的整体框架如图6所示。 图6 算法整体框架 由于算法主要采用了决策树和文本信息最大匹配的方法,所以取得了不错的查全率和查准率。其实验结果如表4所示。其中,M表示文本敏感信息总条数(人工过滤),Mtrue表示正确过滤敏感信息条数,Mwrong表示错误过滤敏感信息条数。 表4 LDTDFA算法实验结果 由表4可以看出,本文所提的老挝文过滤算法取得了88.92%的查全率和 86.79%的查准率,但是该算法在决策树更新的过程中,其查全率、查准率以及F1值下降了3~4个百分点,这说明决策树的更新会影响算法的性能。进一步分析可得,这是由于在决策树的更新过程中,部分新添加的敏感词没有及时完成节点的更新,导致进行老挝文敏感信息过滤时会忽略掉这部分未添加完全的敏感词,进而造成了查全率、查准率以及F1值的下降。但这仅仅发生在决策树更新时,对整体敏感信息的过滤影响不大,所以本文提出算法还是可以较好地完成老挝文敏感信息检测和过滤的任务。 LDTDFA算法主要分为构建敏感信息决策树和敏感信息过滤两部分,所以对于两个阶段分别进行时间复杂度和空间复杂度的分析[15]。对于构建敏感信息决策树,其时间复杂度为O(logkn)级,空间复杂度主要与敏感信息决策树的节点信息有关,为O(n)级,其中n为敏感信息语料集文本总条数;而对于老挝文敏感信息检测和过滤,其时间复杂度主要与决策树的规模有关,为O(h×m)级,其中h为决策树的高度,m为待检测的老挝文语料集文本总条数,空间复杂度则为决策树的大小,即O(n)级。 本文通过研究老挝文的语言特点,结合了DFA强大的字符匹配优势和决策树的分流特点,提出了一种面向老挝文的敏感信息过滤算法——LDTDFA算法。实验结果表明,该算法可以有效实现老挝文敏感信息的检测、过滤以及报警,并取得了较好的查全率和查准率。下一步的工作要在此基础上继续完善扩大老挝文语料集,不断优化算法,进一步提高算法的实时性和准确性。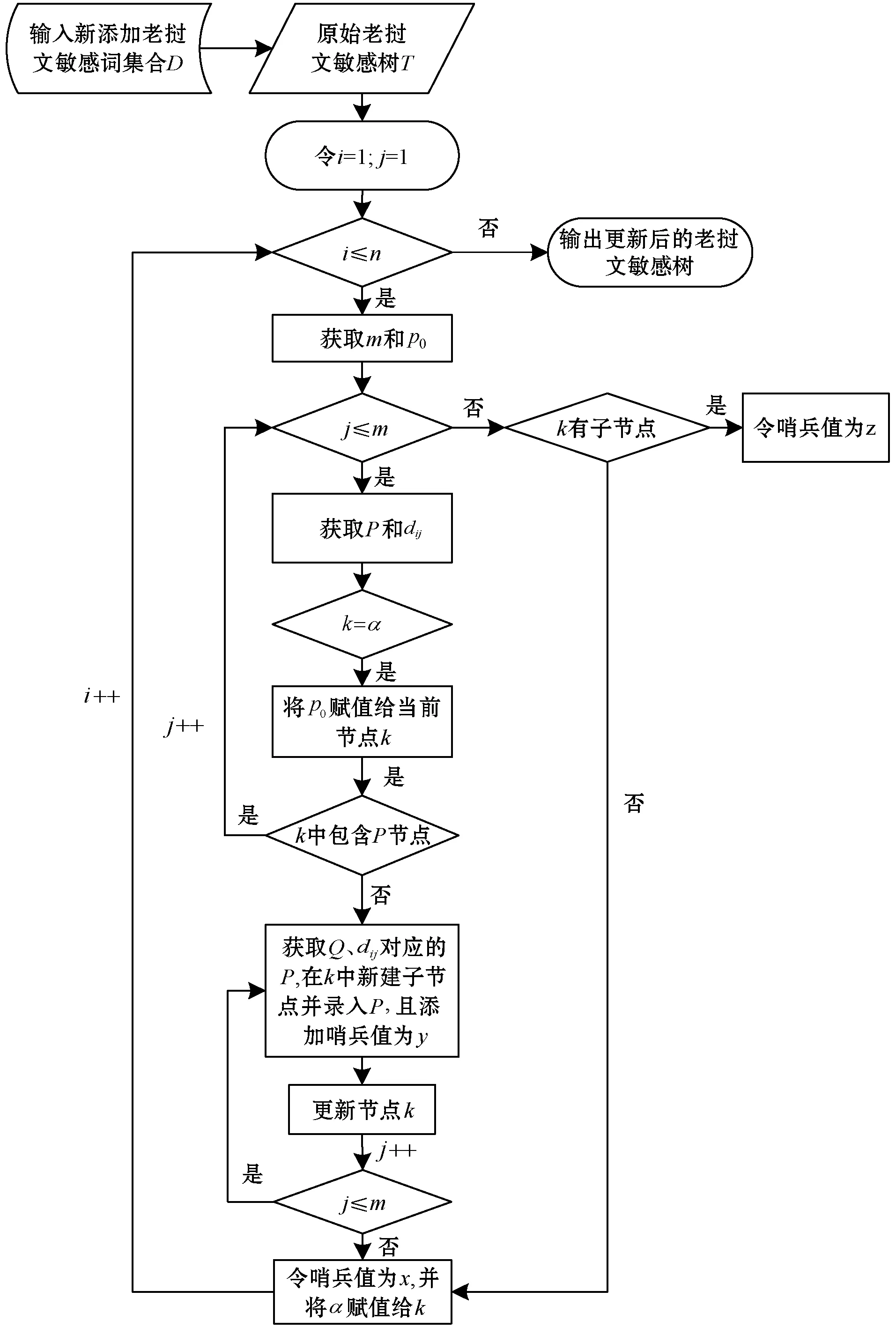
2.3 老挝文敏感信息的检测和过滤

3 实 验
3.1 评估指标
3.2 实验结果与分析

3.3 算法复杂度分析
4 结 语
猜你喜欢
现代计算机(2021年33期)2022-01-21
校园英语·月末(2021年13期)2021-03-15
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
科学与信息化(2019年28期)2019-10-21
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
科学与财富(2016年32期)2017-03-04
决策与信息·下旬刊(2013年1期)2013-03-11
教学与管理(理论版)(2009年9期)2009-11-04
