
基于双输入卷积神经网络的环境声事件识别
2022-08-10 08:12李芳足罗丽燕
计算机应用与软件 2022年7期
李芳足 罗丽燕 王 玫,2*
1(桂林电子科技大学认知无线电与信息处理教育部重点实验室 广西 桂林 541004) 2(桂林理工大学信息科学与工程学院 广西 桂林 541007)
0 引 言
视频监控在公共安全管理中发挥着重要作用,为保护人民生命财产安全提供了有力支撑。但由于室外环境下视频数据的采集过程易受环境因素的干扰,且视频采集设备通常布点固定,所以会出现“监控盲区”的问题。单纯地以增加视频采集设备为代价解决“监控盲区”问题,无疑会较大地增加设备成本与存储成本。因此,如何在低成本的条件下实现监控无死角覆盖成为了急需解决的问题。而声传播的全向性、声接收设备成本较低等优点使得基于声的监控手段得到了广泛关注,例如针对道路交通环境下的异常声事件监测[1]、针对动物声识别的动物习性和生活区域监测[2]、针对地铁环境的异常声事件监测[3]等。
环境声事件识别是指对采集的环境声数据进行分析进而识别出其中包含的声学事件的技术。经过近年来对该技术的研究,研究人员借鉴语音识别框架总结出一套环境声事件识别框架。该框架包含两个重要部分:声学特征提取和分类器识别[4]。早期的环境声事件识别的研究中,由于识别任务较为简单加之计算机的算力不足,常使用K近邻算法(K-Nearest Neighbor,KNN)[5]、支持向量机(Support Vector Machines,SVMs)[6-7]和随机森林算法(Random Forest,RF)[8]等作为分类器,梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCCs)作为声学特征。但是随着将环境声事件识别投入实际场景应用的需求增加,环境声事件识别技术所面临的应用场景更加复杂多变,上述分类器由于对复杂数据的建模能力有限,无法满足当前的环境声事件识别的要求。
近些年,随着计算机的算力提升,深度学习受到环境声事件识别领域研究人员的广泛关注,目前主流的环境声事件识别技术常使用卷积神经网络(Convolutional Neural Networks,CNN)[9-12]作为分类器,对数梅尔谱(Log-mel spectrogram,Log-mel)作为声学特征,卷积神经网络因具有强大的特征提取能力和复杂函数建模能力而使得环境声事件识别性能得到有效的提升。然而在机器学习领域中,数据、特征和分类算法是决定机器学习性能的关键因素,文献[9-12]尽管采用了不同的卷积策略和不同的激活函数提升了分类算法的性能,但其只采用Log-mel特征作为卷积神经网络的输入,使得环境声事件识别性能受限。针对这个问题,许多研究人员对多特征融合进行了调研,并指出融合特征的表现要优于单一特征[13],例如文献[2]将投影特征和局部二元模式变化特征进行融合从而完成了低信噪比环境下动物声的自动识别任务。文献[14]融合梅尔频率倒谱系数(MFCC)和Gammatone倒谱系数(GFCC)解决了有噪声环境下的说话人识别问题。然而上述文献的特征融合方式均采用前融合方式(early fusion-based method),尽管此类融合方式已经取得一定成效,但是并不适合于卷积神经网络,因为这种融合方式存在如下缺陷:单位或尺度不同的两种特征拼接在一起会使得融合特征存在内部数值差异较大以及产生无规律的拼接边界,从而影响卷积神经网络的特征提取能力。文献[13,15]使用不同的声学特征对不同的模型进行训练,然后将训练好的模型使用DS证据理论(Dempster-Shafer evidence theory)进行融合,经Urbansound8K、ESC-10和ESC-50数据集评估结果表明基于DS证据理论的后融合方式(late fusion-based method)具有较好的识别表现。这种基于DS证据理论的后融合方式尽管避免了前融合方式带来的弊端,但是需要对两个模型分开训练使得识别方法更繁琐并且无法保证特征进行有效的融合。因此,寻找一种适合卷积神经网络的特征融合方式成为必要。
为解决上述问题,本文作出如下贡献:(1) 提出一种基于双输入卷积神经网络的特征融合框架,该框架的核心是为MFCCs特征和Log-mel特征匹配合适的卷积和池化策略。(2) 通过实景实验,探索了该融合框架在实际场景中应用的可行性。
1 MFCCs和Log-mel特征提取
声学特征是影响环境声事件识别性能的重要因素,不同类型的声学特征可以从不同角度描述声音信号,该融合框架选择MFCCs特征和Log-mel特征作为融合对象,两种特征提取流程如图1所示。Log-mel特征是经过梅尔滤波器过滤后的频谱特征,符合人耳的听觉特性,描述了声音信号频谱的全局信息,被广泛应用于环境声事件识别和声场景识别中;MFCCs特征是Log-mel特征经过离散余弦变换之后得到的倒谱特征,该特征反映了信号的倒谱特征,被广泛应用于语音识别和说话人识别中。图2是对汽车鸣笛声、枪声和尖叫声分别提取Log-mel特征和MFCCs特征得到的特征图,可以看出,Log-mel特征图可以更直观地看到三种声音的区别,在图像上更具辨识度,而MFCCs特征由于只保留了低频部分的谱包络信息无法直观地分辨出三种声音。对这两种特征进行融合不仅可以从全局的频谱信息中对声音信号进行区分,还可以通过低频的包络信息对特征进行补充,有效地提高了特征的描述能力和抗噪能力。除此之外,Log-mel特征是MFCCs特征的中间产物,同时提取这两种特征时不会增加额外的计算消耗,可以满足在实际应用中对特征提取的实时性要求,因此选择这两种声学特征来描述环境声信号。两种特征的提取步骤如下[16]。
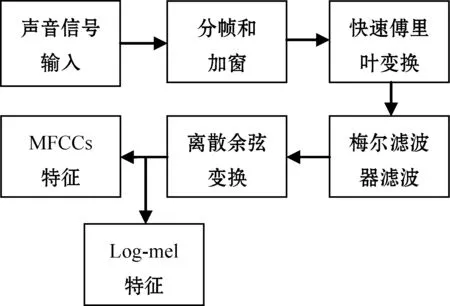
图1 MFCCs和Log-mel特征提取流程

图2 Log-mel和MFCCs特征图
(1) 分帧和加窗:将一段声音信号分为一系列重叠的短帧s(n),帧长设为1 024,帧移设为512。然后对帧信号s(n)加汉明窗ω(n)来减轻边界效应,汉明窗ω(n)为:
(1)
式中:N为总的采样点数。
(2) 快速傅里叶变换:进行快速傅里叶变换(Fast Fourier Transform,FFT)得到其复数谱。假设输入信号为x(n),该信号的离散傅里叶变换(Discrete Fourier Transform,DFT)公式为:
(2)
式中:N表示进行DFT变换的点数;X(k)表示第k个频率点的值。然后将得到的复数谱取模平方得到功率谱。
(3) 梅尔滤波器滤波:将功率谱通过一组梅尔滤波器,即:
(3)
式中:Hm(k)为梅尔滤波器组;M为滤波器组中三角滤波器的数量,取M=40。梅尔滤波器组计算公式为:
(4)
式中:f(m)为第m个三角滤波器的中心频率,1≤m≤M。
然后将梅尔频谱取对数,得到对数梅尔谱特征。
(4) 离散余弦变换:对数梅尔谱做离散余弦变换得到MFCCs系数,即:
(5)
本文取前12个系数作为最终的MFCCs特征,即L=12。
2 基于双输入卷积神经网络的特征融合框架
不同声学特征的描述能力不同,经过有效的融合可以极大地提高环境声事件识别的性能,本文采用基于双输入卷积神经网络的特征融合框架,通过双输入方式为Log-mel和MFCCs匹配不同的卷积和池化策略,然后通过展平和拼接操作对提取到的高阶特征进行融合。同时,使用Batch Normalization、正则化、Dropout等技巧提升了网络的训练速度以及泛化能力。
2.1 双输入卷积神经网络的网络结构及特征融合方式
本文借鉴经典的卷积神经网络[9,17]和BP神经网络,设计了如图3所示的双输入卷积神经网络。该网络有两条输入并分别使用MFCCs特征和Log-mel特征作为输入数据,其数据维度分别为Xmfcc∈R12×80、Xlogmel∈R40×80。详细的模型结构描述如下。
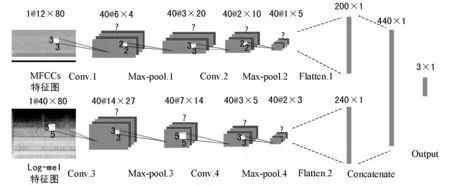
图3 双输入卷积神经网络结构
在前向传播过程中,每次输入Xmfcc和Xlogmel,数据从前一层网络流向下一层网络,直到输出层得到分类结果,并且前一层流向下一层网络的数据需经过非线性映射F(·|Θ),从输入层Xmfcc和Xlogmel到Max-pool2和Max-pool4的操作分别为:
Zmax-pool2=F(Xmfcc|Θ)=
fl(…f2(f1(Xmfcc|θ1)|θ2)|θl)l=4
(6)
Zmax-pool4=F(Xlogmel|Θ)=
fl(…f2(f1(Xlogmel|θ1)|θ2)|θl)l=4
(7)
式中:fl(·|θl)表示对第l层网络的操作,例如l∈{Conv.1,Conv.2,Conv.3,Conv.4}为卷积层,其卷积运算为:
Zl=fl(Xl|θl)=h(W*Xl+b),θl=[W,b]
(8)
式中:Xl为输入的三维张量;W为卷积核;*表示卷积操作;b为偏置向量;h(·)表示激活函数。然后在每层卷积层后接最大池化层l∈{Max-pool.1,Max-pool.2,Max-pool.3,Max-pool.4},用来减小特征映射的维度和提升训练速度。
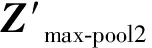
Zconcatenate=concatanate(Zmax-pool2,Zmax-pool4)
(9)
最后,将融合后的一维张量与输出层进行全连接,操作为:
Zl=fl(Xl|θl)=h(WXl+b),θl=[W,b]
(10)
式中:Xl表示Concatenate层输出的一维张量;W表示权重;b为偏置参数;h(·)表示激活函数。
基于双输入卷积神经网络的特征融合方式可归为后融合方式。而前融合方式是在卷积神经网络输入前对声学特征进行如图4所示的操作。这种融合方式会存在如下缺点:单位或尺度不同的两种特征拼接在一起会使得融合特征存在内部数值差异较大以及产生无规律的拼接边界的问题,从而干扰卷积核更新有效的权值,影响卷积神经网络的特征提取能力。针对这个缺点,基于双输入卷积神经网络的特征融合框架的优势在于为不同的特征匹配不同的卷积和池化策略,充分发挥卷积神经网络的特征提取能力,最后将得到高阶特征进行融合并输送到Softmax层,对提取到的高阶特征进行选择和非线性拟合,极大地提高了网络的分类性能。
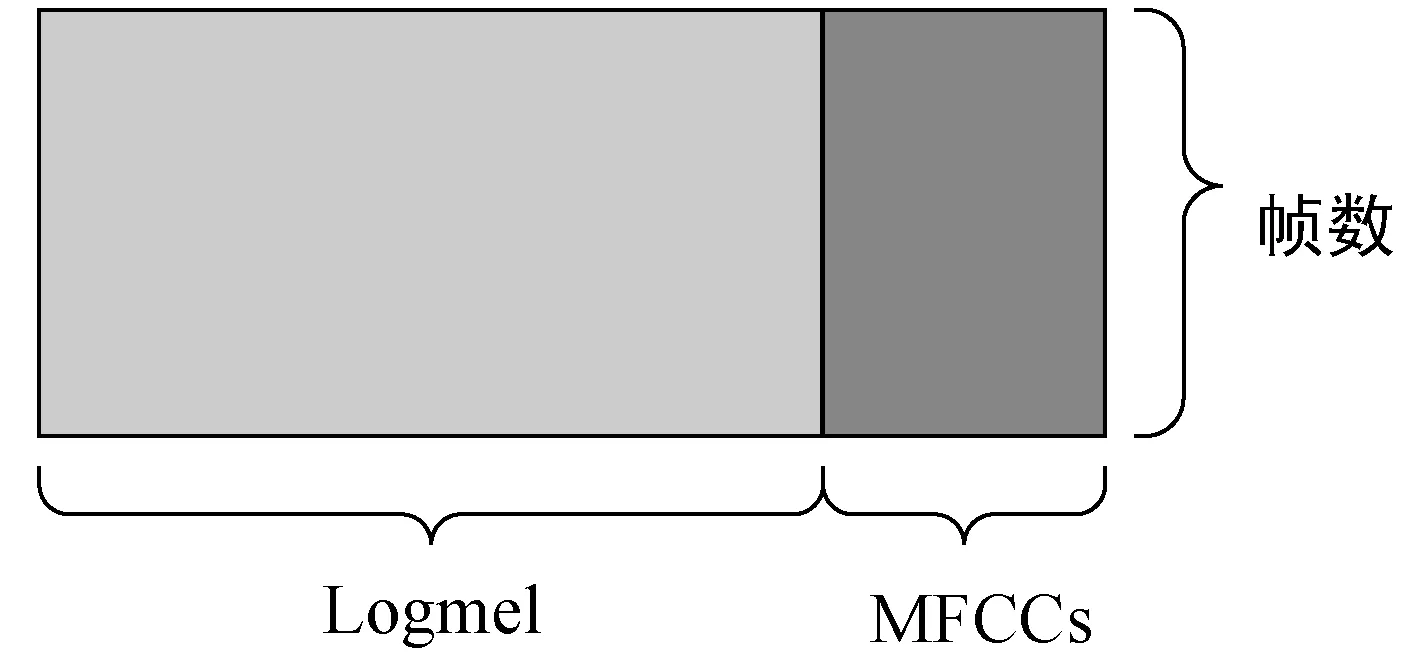
图4 以前融合方式融合Log-mel和MFCCs
2.2 网络参数分析
本文提出的卷积神经网络有两个特点:(1) 双输入结构,不同的输入经过不同的卷积层和池化层,充分发挥不同特征的描述能力,从而提高网络的分类性能;(2) 无额外的全连接层,这种结构可以有效地减少模型的参数和降低模型的复杂度,提高模型的泛化能力[18]。具体的网络参数设置如下。
(1) Conv.1和Conv.2:这两层卷积层均使用40个3×3的卷积核,卷积核的滑动步长为2。这种小尺寸卷积核用于提取MFCCs特征图中的局部高阶特征并且有效地减少了模型的参数。然后将卷积核的输出用修正线性单元(Rectified Linear Unit, ReLU)[19]进行非线性映射,其映射关系为:
f(x)=max(0,x)
(11)
同时,在每个卷积核和激活函数之间引入Batch Normalization技术[20],用来提高神经网络训练的速度和稳定性。
(2) Conv.3和Conv.4:这两层卷积层均使用40个5×5的卷积核用于提取Log-mel特征图的深层特征,卷积核滑动步长为2,同样采用ReLU作为激活函数并且在激活函数前引入Batch Normalization技术。
(3) Max-pool.1和Max-pool.2:这两层池化层均采用2×2的最大池化滤波器来下采样上层输出,以达到减小输出数据的尺寸和特征选择的目的。
(4) Max-pool.3和Max-pool.4:这两层池化层均采用3×3的最大池化滤波器。
为了进一步提高模型的泛化能力,本模型在输出层前添加概率为0.5的Dropout机制,即在每批次的训练过程中,随机地让网络中的某些隐藏层节点的权重暂时失效,通过Dropout机制可以减轻网络节点之间的联合适应性,防止网络发生过拟合现象[21]。此外,网络还使用了L2参数范数惩罚,使得权重更加接近原点,防止过拟合[21],即通过向目标函数添加一个正则项:
(12)
式中:向量w表示所有应受范数惩罚影响的权重;向量θ表示所有参数(包括w和无须正则化的参数)。
针对多分类任务,本模型使用目标函数-分类交叉熵损失(Categorical Cross-entropy)来衡量当前训练得到的概率分布与真实分布之间的距离,交叉熵损失函数定义为:
C=-∑ylog(a)
(13)
式中:y表示期望输出;a表示模型得到的输出,而a=σ(z),其中σ(·)表示激活函数,z=∑WX+b。输出层的激活函数使用Softmax函数,即每个神经元的输出映射为:
(14)
而且要保证:
(15)
式中:J为输出层神经元个数,要求与预定义的类别数量保持一致。
在做反向传播时,采用Adam[22]优化器来训练网络,Adam是一种学习率自适应的优化算法,它采用了偏置修正,修正从原点初始化的一阶矩(动量项)和(非中心的)二阶矩的估计,使得其对超参数的选择更鲁棒[20]。
3 基于环境声数据集的实验分析
3.1 环境声数据集
实验使用公开的环境声数据集Google AudioSet[23],该数据集是目前声音种类最丰富、数量最多的声音数据集,常用于评估环境声事件识别方法。本文从该数据集中选取了三种比较典型的环境声:枪声、尖叫声和汽车鸣笛声,每种类别的声音样本数量均为900余条,每条声音样本均采用44.1 kHz采样和16 bits位深度编码为WAV格式。然后按照7∶3将声音样本随机划分为训练集和测试集。
3.2 实验设置
本实验使用公开的环境声数据集对如下十种环境声事件识别方法进行评估对比。
方法一:使用文献[11]中的识别方法作为Baseline方法,该方法使用对数梅尔谱作为声学特征,使用卷积神经网络作为分类算法。
方法二:采用MFCCs作为声学特征,单输入卷积神经网络作为分类器,卷积神经网络结构如图5所示。其中卷积层和池化层结构与本文设计的双输入卷积神经网络中关于MFCCs输入部分的卷积层和池化层结构保持一致,在Flatten层与输出层之间添加一层全连接层。
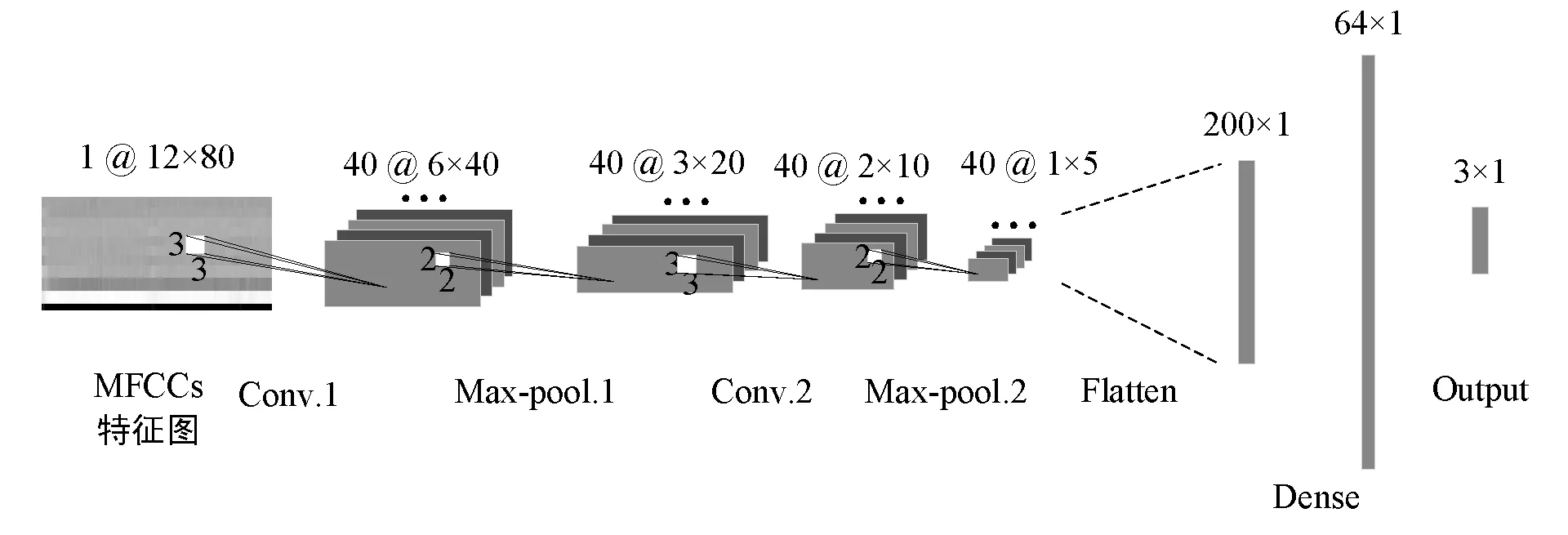
图5 以MFCCs特征作为输入的卷积神经网络结构
方法三:采用Log-mel作为声学特征,单输入卷积神经网络作为分类器,其结构如图6所示。该网络中卷积层和池化层与本文设计的双输入卷积神经网络中有关Log-mel输入部分中的卷积层和池化层结构保持一致,同样在Flatten与输出层之间添加一层全连接层。
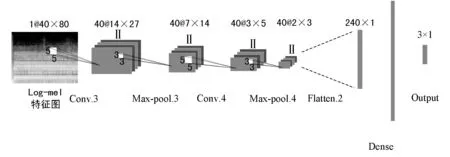
图6 以Log-mel特征作为输入的卷积神经网络结构
方法四:声学特征采用前融合方式融合MFCCs特征与Log-mel特征,分类器采用K近邻算法。
方法五:声学特征采用前融合方式融合MFCCs特征与Log-mel特征,分类器采用支持向量机算法。
方法六:声学特征采用前融合方式融合MFCCs特征与Log-mel特征,分类器采用随机森林算法。
方法七:声学特征采用前融合方式融合MFCCs特征与Log-mel特征,分类器采用包含两个隐含层的多层感知机。
方法八:声学特征采用前融合方式融合MFCCs特征与Log-mel特征,分类器采用图6所示的卷积神经网络。
方法九:使用文献[13,15]中采用的DS证据理论对方法一和方法二中训练好的模型进行融合,以此作为基于后融合的对比方法。
方法十:即本文方法,采用MFCCs和Log-mel作为声学特征,双输入卷积神经网络作为分类器。
所有的实验均在Windows平台下完成,硬件设备使用酷睿i7 6800K处理器和GTX1080TI显卡,软件部分中涉及到的特征提取和分类算法的建模和应用借助Python 语言中的librosa、sklearn和TensorFlow等模块完成。
3.3 评估指标
评估环境声事件识别方法常采用如下的评估指标[24]:
(1) 查全率(Recall):正确识别到的鸣笛声数量占鸣笛声真实发生数量的比率。
(16)
(2) 查准率(Precision): 正确识别到的鸣笛声数量占识别到鸣笛声数量的比率。
(17)
(3) F1-度量(F1-measure):
(18)
式中:TP称为真正例(True Positive);FP称为假正例(False Positive);TN称为真反例(True Negative);FN称为假反例(False Negative)。在评估指标中,查全率和查准率越高说明检测系统性能越好,但是这两者是相互矛盾的,因此引入F1-度量来权衡两者。
3.4 实验结果分析
将实验结果以混淆矩阵图的形式呈现在图7中,其中图7(a)-图7(j)是使用十种方法得到的评估结果。并将实验结果以查全率、查准率、F1度量的形式呈现在表1中。
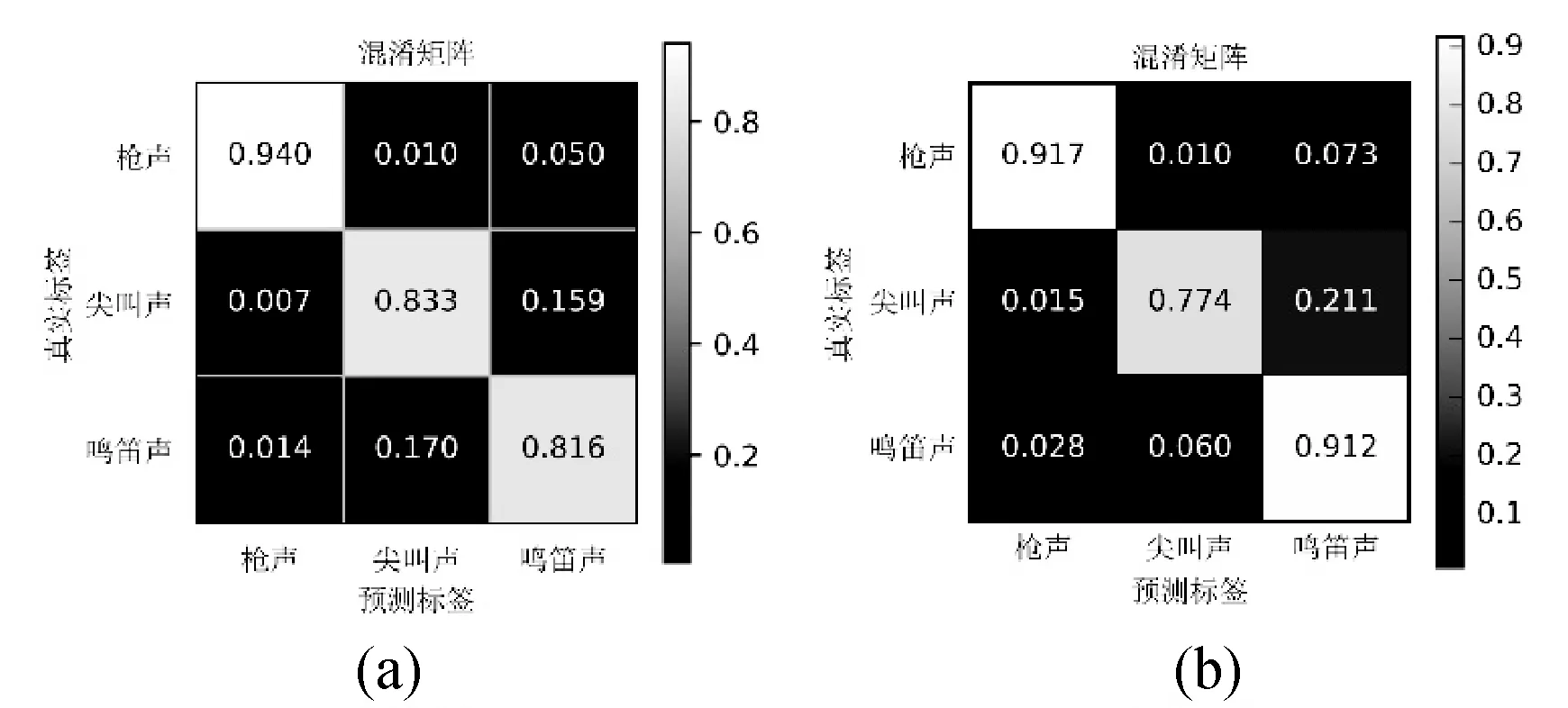
图7 十种识别方法得到的混淆概率矩阵
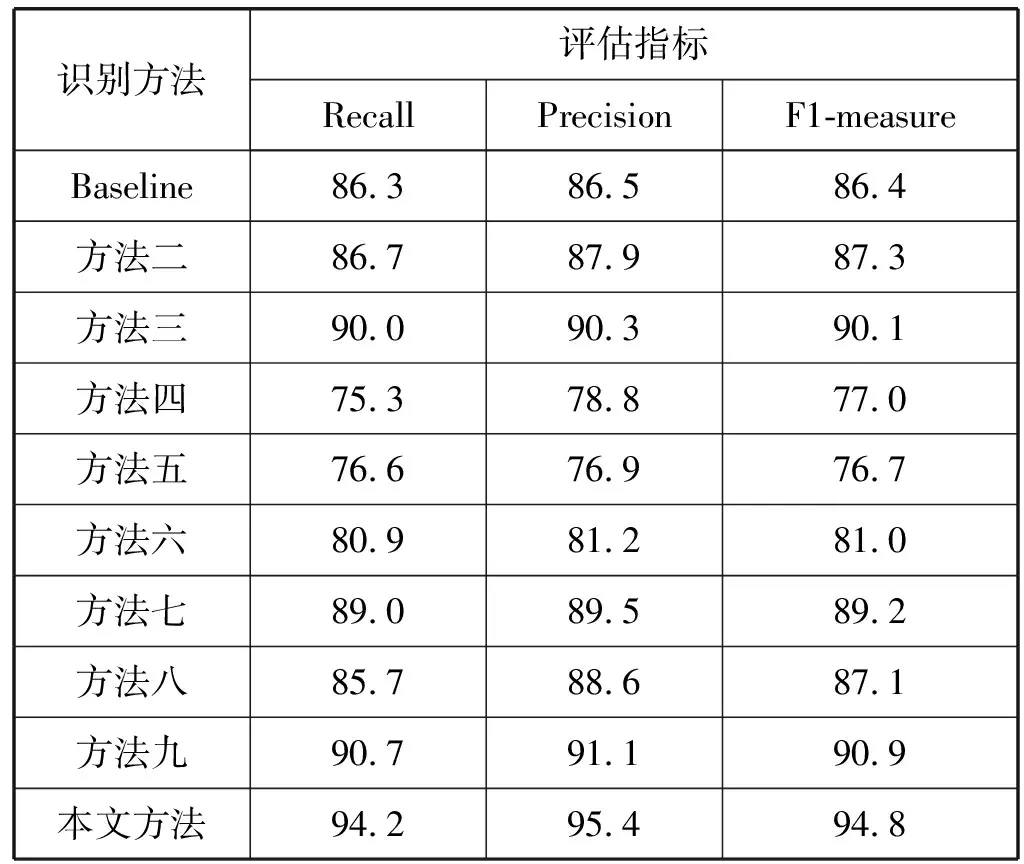
表1 十种方法的评估结果(%)
对比方法二和方法三的实验结果可以得出,使用MFCCs特征的方法仅对汽车鸣笛声的识别表现优于Log-mel特征,而从整体识别表现看,其识别表现不如使用Log-mel特征的方法,因此可以得出,Log-mel特征和MFCCs特征对不同声音信号的描述能力不同,而且使用Log-mel特征的方法要优于使用MFCCs特征的方法,通过将两种特征进行融合可以对特征的描述能力进行互补从而提高识别方法的性能。方法二和方法三的实验结果要优于Baseline方法,验证了本文所设计的卷积神经网络分类性能突出。
通过比较方法四-方法八的实验结果,可以对使用前融合方式的不同分类算法进行比较。分析实验结果,使用传统分类算法的方法相比使用深度学习的方法存在一定差距。因此证明了深度学习技术更适合处理环境声信号。
通过对比Baseline、方法二、方法三、方法八、方法九、方法十(本文方法)的实验结果,可以对单特征方法、基于前融合方式的融合特征方法和基于DS证据理论的后融合方法与本文提出的基于双输入卷积神经网络的方法进行对比。分析实验结果,方法二和方法三的识别结果优于方法八,因此验证了基于前融合的特征融合方式对卷积神经网络的分类性能产生了负面影响。方法九的表现优于方法二和方法三,证明了基于DS证据理论的融合方式是一种有效的特征融合手段。而本文方法在各项指标的表现相较于其他的方法有明显提升,因此本文提出的特征融合框架是有效且性能突出的。
4 基于实际场景的汽车鸣笛声识别实验
为了评估本文方法在实际场景中应用的性能,通过实景实验对上述性能较好的识别方法与本文方法进行对比。
4.1 环境声数据的采集
为了保证实验的真实性,在桂林电子科技大学金鸡岭校区正门前放置声音采集设备,对过往车辆的鸣笛声进行采集,采集场景及采集设备如图8所示。经过长时间的采集,最终得到1 742条鸣笛声数据,每条声音数据持续时间为0.6 s~1.5 s,均采用44.1 kHz的采样频率和16 bits的位深度保存为WAV格式。使用采集到的汽车鸣笛声数据用于训练分类算法,最终使用一段未参与训练的时长为10 min的街道环境声数据对该网络进行评价。

图8 声音采集场景
4.2 评估方式
汽车鸣笛声识别类似于跌倒声识别[25]属于二分类任务,要求在一段声音信号中检测并识别出是否存在汽车鸣笛声,因此采用如图9所示的评估方法。图9中上方的黑线表示鸣笛声检测的真实结果,中间的虚线表示模型检测得到的结果,底部的粗黑线表示时间轴,凸起的线条表示有汽车鸣笛声发生。图9中展示了在模型的识别结果中会出现的四种情况:TP、FP、TN、FN,当模型识别结果和真实结果均为汽车鸣笛声时表示为TP,反之表示为TN。当模型识别结果为汽车鸣笛声而真实结果中无汽车鸣笛声时表示为FP,反之为FN。
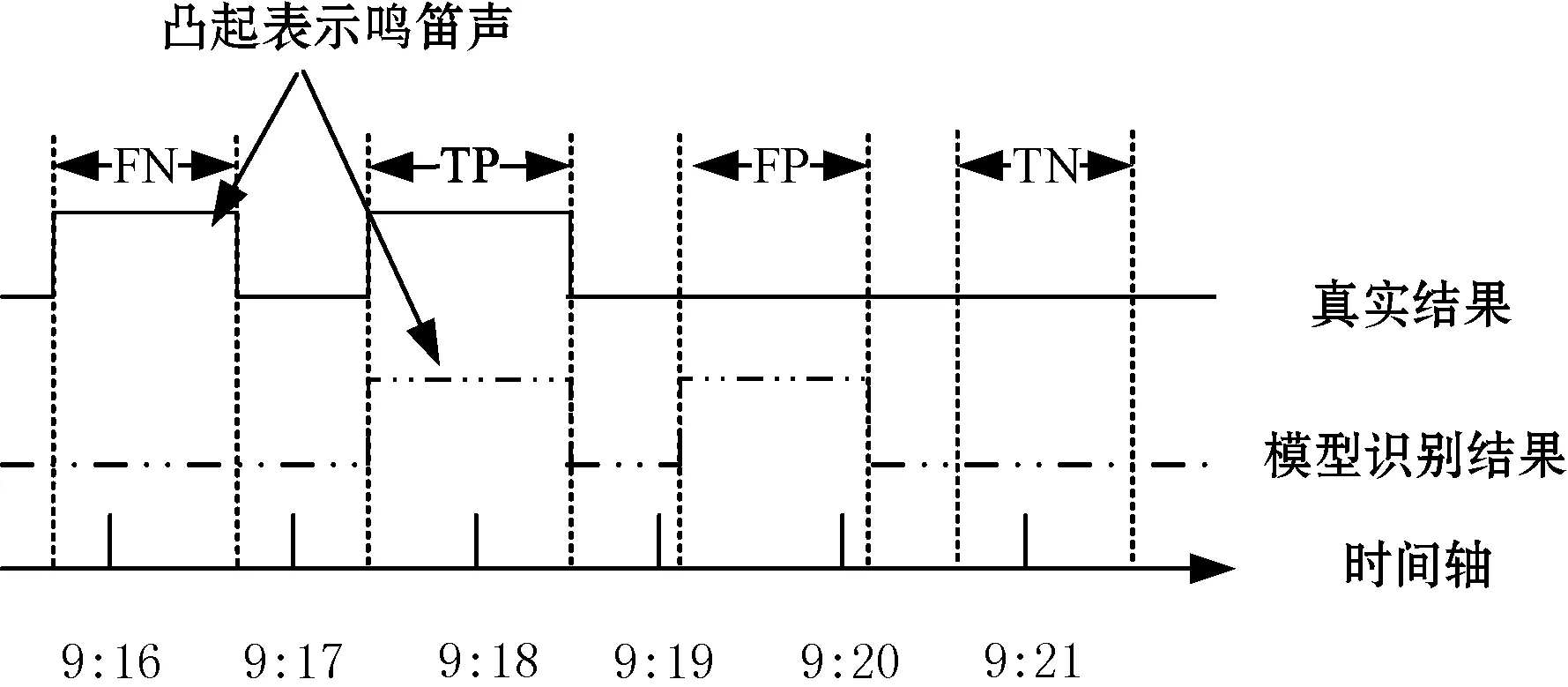
图9 鸣笛声识别评估策略
4.3 实验结果分析
表2呈现了汽车鸣笛声识别的实景实验结果,基于双输入卷积神经网络的环境声事件识别方法对汽车鸣笛声的识别拥有较高的查全率(Recall=87.7%),而且其查准率(Precision=84.7%)相比查全率也仅仅低了3百分点,综合这两个指标得到的F1-度量也能达到86.2%,而且相比Baseline、方法二、方法三、方法六、方法八和方法九表现也有较大提升。综合实验结果,基于双输入卷积神经网络的特征融合框架在实际环境声中仍具有较好识别性能,而且该识别方法明显优于单特征方法、基于前融合的融合特征方法和基于DS证据理论的模型后融合方法。
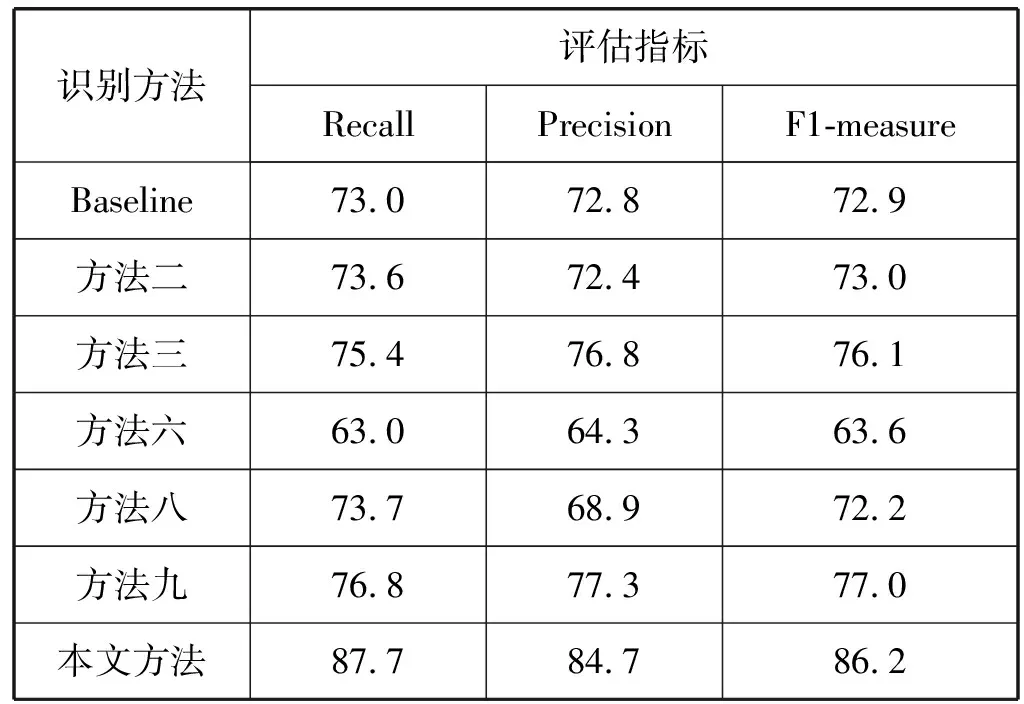
表2 鸣笛声识别的评估结果(%)
5 结 语
本文针对前融合的特征融合方式不利于卷积神经网络提取高阶特征的问题,提出一种基于双输入卷积神经网络的特征融合框架。经公开数据集评估以及实景实验验证,所提出的融合框架是有效的,并具备在实际场景中应用的可行性。但是,本文工作仍存在不足,例如还需对特征的选择做进一步探索。在以后的工作中将对更多的特征进行研究,探索性能更优以及鲁棒性更强的融合特征,推动环境声事件识别在实际场景中的应用。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
智慧电力(2022年4期)2022-05-19
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
源流(2020年4期)2020-07-14
南方周末(2020-01-02)2020-01-02
软件导刊(2017年4期)2017-06-20
中学生数理化·中考版(2014年5期)2016-12-22
中学生数理化·中考版(2016年5期)2016-05-14
作家(2008年7期)2008-10-27
