
智能商品分类系统的设计与实现
2022-08-09 08:43朱安东石文玉
科技风 2022年19期
朱安东 石文玉
安徽新华学院大数据与人工智能学院 安徽合肥 230087
随着信息技术的飞速发展,移动互联网渗透到人们生活的方方面面,诸如京东等电商平台蓬勃发展,商品的种类越来越丰富,数量也越来越多。随着数字化时代的发展,各大电商平台也处于日益激烈的竞争中,如何在用户浏览网络页面时,提供一些有效信息,提升用户使用感是各大电商平台面对的一个重难点问题。面对大数据时代下大量的商品信息,如何对商品进行有效的分类是研究的热点问题之一。日益增长的商品种类和数量使得商家进行商品分类也越来越难,但若对商品进行了错误的分类或者未进行分类,都会导致客户无法快速查找到想要购买的商品,降低成交量,久而久之商家平台会被淘汰。传统的人工分类方法成本高、效率低且易出错等问题已经无法适应当下社会发展的趋势。随着大数据和人工智能技术的发展,依托于计算机数据处理及分类技术设计出一种快速、准确的分类方法,将大量杂乱的文本信息利用算法进行自动分类,其方法可以有效地降低人工成本,提高效率和准确率,从而满足信息技术发展的各项需求。
1 文本预处理
从网络中获取的数据大多含有大量的噪声、比较粗糙,不能够直接用于计算机的文本分类使用,如直接使用将会耗费大量的训练和预测时间,也会影响到分类模型的性能。因此需要通过数据预处理技术,对相应文本进行清洗、分词、去除停用词等操作后才能使用。
1.1 数据清洗
对网络上获取的数据进行清洗,是提高系统使用数据质量的关键一步,需要较长时间操作。对文本进行数据清洗主要包括处理缺失值、冗余值和噪音[1],对于其两者的操作可以通过条件判断后直接删除整条数据。网络文本中的噪声处理主要包括将文本中的HTML符号、数字、换行等用空白替代,对URL或一些与语义无关的解释性语句用正则表达式将其过滤。常用的正则表达式匹配规则如表1所示。

表1 常用的正则表达式匹配规则
1.2 中文分词预处理
中文在书写时没有使用分隔符将词进行分割,但是语言中的最小文字单位是词,因此为了便于对文本的语义进行理解,算法模型需要进行中文的分词预处理。在深度学习算法中,通过神经网络对文本特征进行自动提取,近年来越来越多的神经网络模型,如卷积神经网络、长短期记忆网络等被用于中文分词中。目前,在中文分词领域中开发出了一些性能较好的开源工具,如NIPIR分词系统、Jieba分词工具等。在本文中选用了Python的中文分词组件Jieba进行中文分词处理,其分词模式包括三种,如表2所示。

表2 Jieba分词模式
2 循环卷积神经网络
循环卷积神经网络(Recurrent Convolutional Neural Networks,RCNN)结合了卷积神经网络(CNN)[2]和循环神经网络(RNN)[3]的优点。卷积神经网络包括输入层、卷积层、池化层与全连接层,如图1所示。循环神经网络使用循环的操作把上一时刻的隐藏状态与当前时刻的序列输入当成此时的输入,从而更好地表达文本的上下文语义信息,如图2所示。而循环卷积神经网络中,循环卷积层代替了卷积层,从输入层中提取目标对象后使用变化的循环神经网络进行处理,从而进行特征的抽象提取。图3给出了以“新款女春装长针织衫”为例的循环卷积神经网络模型结构图。从模型结构中来看,RCNN使用了CNN的最大池化层和RNN的循环结构的优点,减少了噪声并且提出了文本中的特征信息。
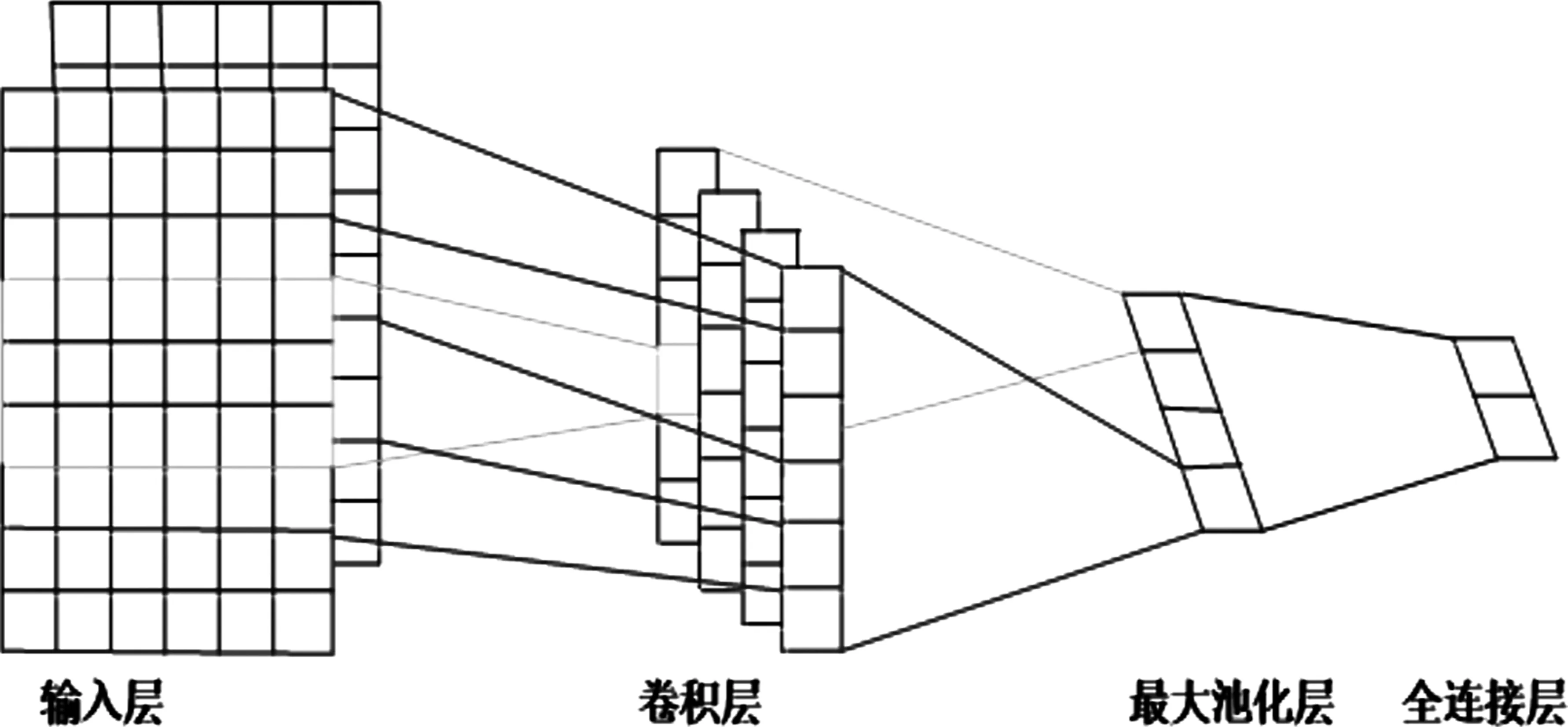

图3 循环卷积神经网络模型结构
3 模型介绍
本文对商品标题进行特征提取时使用循环卷积神经网络的方法,首先在学习文本特征时将循环结构作为卷积层,得到词表示后进行最大池化处理,从而得到文本的向量表示,最后从输出层获得文本表示,如图4表示。
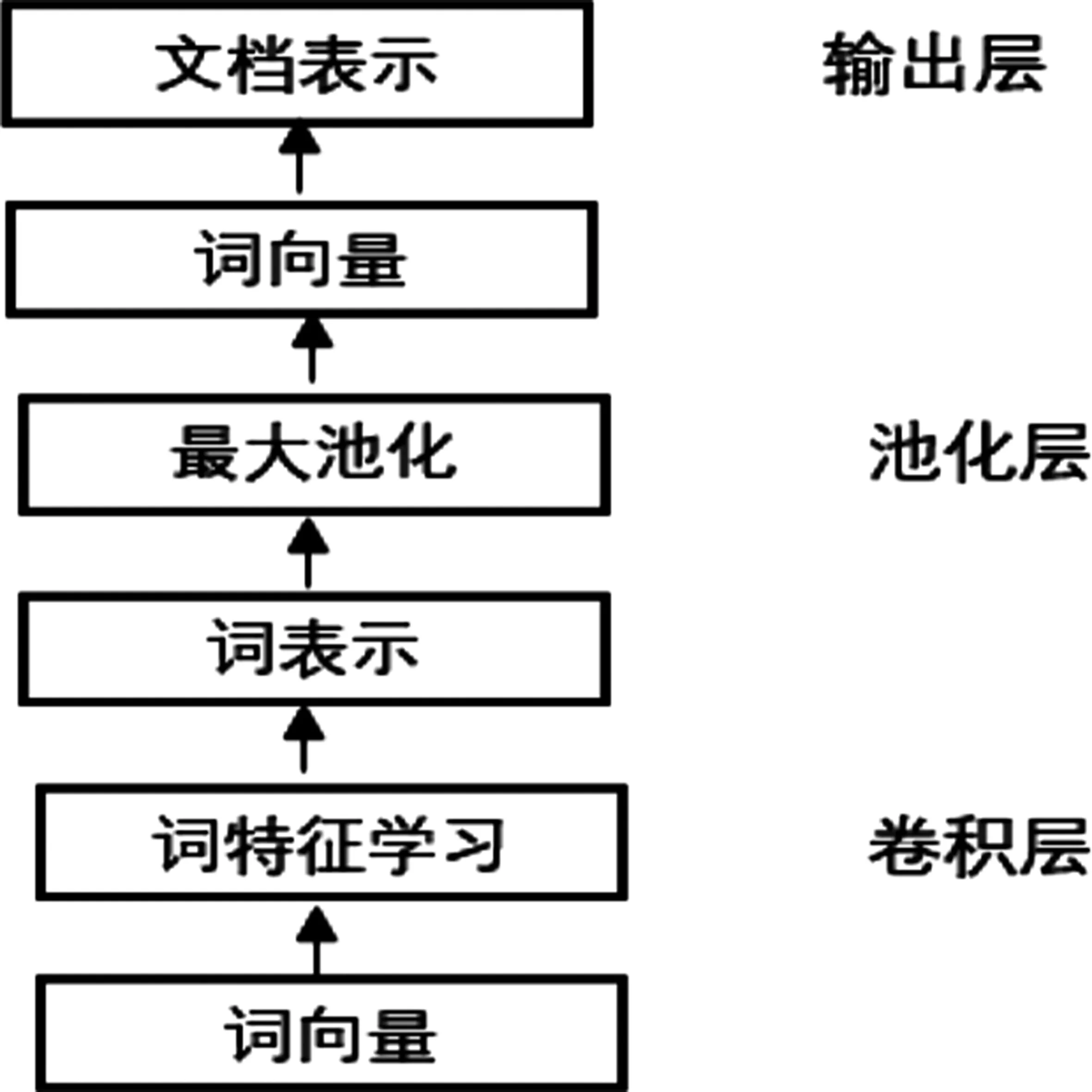
图4 本文模型
3.1 卷积层
考虑到现在的网络平台为了能使商品被更多的用户搜索到,商家会为商品添加较长、较多的商品信息标签,用户在搜索商品时也会将自己的详细需求写入商品信息中,而中文中的词不是孤立的,词和词之间的关联往往也会和词的含义有关,因此本模型中采用双向长短时记忆网络(BLSTM)[4]来学习词的上下文表示。其中包括左上下文信息和右上下文信息。
3.2 池化层
本模型中使用卷积神经网络模型的方法,将学习到的所有词的表示统一进行最大池化的方式进行处理[5],该方法能够充分利用词的特征,减少文本噪声,从而使得获取的文本表示能够更大程度地作为文本的重要特征。
3.3 输出层
在获得文档表示后,像传统的神经网络模型一样,本模型使用全连接作为模型的输出层,最后通过概率函数来统计输出的文档属于哪一类的概率,从而计算模型的性能。
4 实验结果与分析
4.1 实验环境
本实验是在本地计算机上进行的,具体的实验环境详情如表3所示。
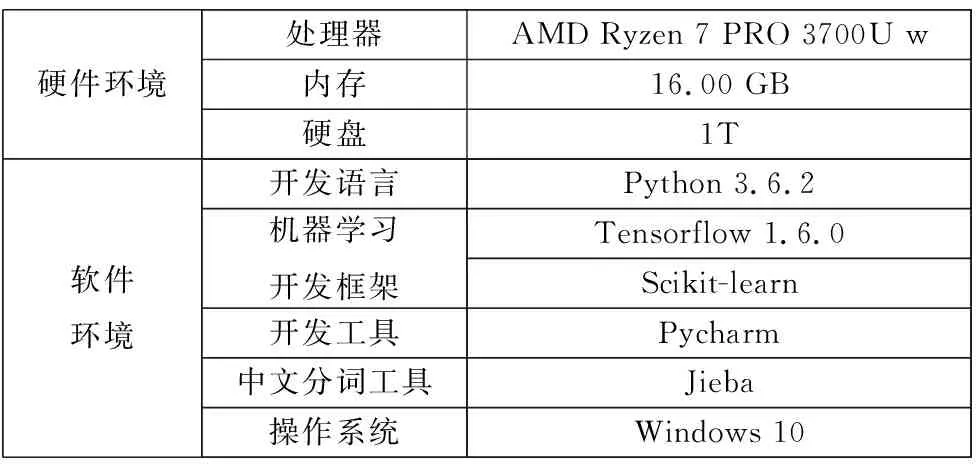
表3 实验环境
4.2 实验数据与统计分析
本文使用的商品信息数据为网络开源数据,共有11369条,其中测试集有7639条,训练集有3730条。
4.3 性能指标
针对文本分类算法的性能指标有很多种,如查准率P(Precision)、召回率R(Recall)以及F1-measure等。这些指标都和预测结果有关,以实际类别为A为例,预测结果有四种,如表4所示。其中TP为样本被正确预测到A类的数量,FN指不属于A类的样本被错误预测到A类的数量,TN为A类的样本被错误预测为其他类的数量,FP为不属于A类的样本被正确地预测为其他类的数量。

表4 预测结果举例
查准率、召回率及F-measure(F值)的计算公式如下:
(1)
(2)
(3)
其中,α为调和查准率和召回率的平衡值,在文本分类技术中通常另α=1,即为F1-measure,如式(4)所示:
(4)
4.4 实验设计及结果分析
本文选择了深度学习模型中的CNN、RNN与RCNN对文本进行分类,并对上述三种算法的查准率、召回率及F1-measure进行比较分析,实验结果如表5所示。
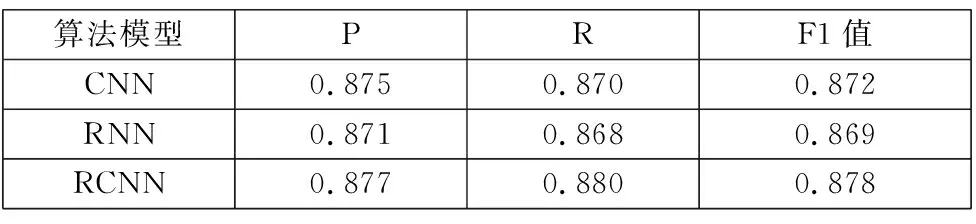
表5 实验结果对比
从实验结果对比中可以看出,RCNN相比较于其他算法在查准率、召回率和F1值三方面都有着较好的结果,实验结果表明本文所采用的模型能够更好地对文本进行分类,从而提高文本分类的性能。
5 智能商品分类系统的实现
在前面工作的基础上,本文设计并实现了一个商品分类的可视化系统。本文中将使用Eclipse软件作为开发软件来编写代码,系统采用B/S架构、HTML、CSS等技术来编辑网页,把MySQL数据库和动态交互网页相连。系统功能模块如图5所示。
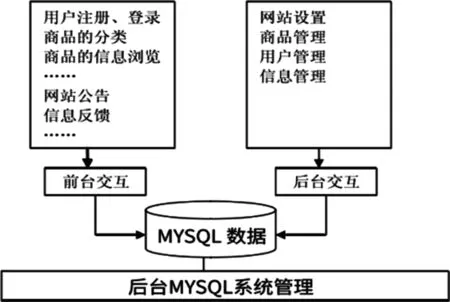
图5 系统功能模块
结语
本文采用RCNN模型对商品信息进行分类,分类结果表明,相对于CNN和RNN,该模型具有较好的性能指标,此外通过相关技术实现了可视化系统界面设计。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
校园英语·月末(2021年13期)2021-03-15
电子制作(2019年13期)2020-01-14
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电子制作(2019年11期)2019-07-04
现代电子技术(2018年16期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
现代电子技术(2017年23期)2017-12-20
计算机应用(2016年10期)2017-05-12
