
融合记忆增强的视频异常检测
2022-08-09 05:48陈澄,胡燕
计算机工程与应用 2022年15期
陈 澄,胡 燕
武汉理工大学 计算机科学与技术学院,武汉 430070
随着监控设备的增多,视频异常检测在过去几年已经吸引了很多关注[1-5]。自动识别监控视频中的异常事件是该领域相关研究中的一项基本任务,因为它在构建智能视频监控系统中起着重要作用[6]。由于不同场景中异常的歧义和多样性,从视频中自动检测异常行为、事件或对象仍然具有挑战性[2]。由于异常事件很少发生,视频片段中大多数都是正常事件,并且几乎不可能收集所有事件。因此获取足够多的异常样本是困难的,大多数训练数据仅包含正常视频,这就限制了传统的监督学习的方法在视频异常检测上的应用。因此,视频异常检测通常作为半监督或无监督任务[7]。
大多数方法都通过训练模型来表示视频序列中的常规事件,并认为测试集中任何异常值都是异常事件[8]。一些研究集中在手工特征的提取上,这些特征用于精确表示视频片段中的外观和运动特征,包括HOG/HOF[4]、光流特征[9]。但是,这些手工特征仅提供了复杂运动的有限表示,这限制了传统机器学习的使用。
随着深度神经网络的广泛流行,通过神经网络进行异常检测的方法取得了较好的效果。文献[10]认为视频中的正常事件更可能是可重构的,异常事件相对于正常事件来说无法通过学习到的模型进行良好的重构,因此通过真实帧与重构帧之间的重构误差来区分正常和异常[1,6]。Cong等人[10]利用稀疏重建成本来衡量测试样本是否异常。受文献[10]启发,Luo等人[1]通过堆叠的RNNs框架来计算重构误差,提出了一种时间相干的稀疏编码模型。文献[11]的工作表明卷积自动编码器可以有效地学习视频中的时间规律。
由于异常事件定义为和期望不符,文献[2]认为正常帧比异常帧更可预测,提出通过视频帧预测来检测视频中的异常。通过视频的前几帧来预测下一帧,并且将预测的帧和真实的帧进行比较。这样学习到的模型对正常事件有一个较好的预测,对异常事件有一个较差的预测。有学者提出两分支预测自动编码器[12],包括重构解码器和预测解码器,从而将端到端框架中的重构和预测方法统一起来。在文献[13]中,Ye等人使用卷积LSTM和RGB差异来捕获长期的运动信息。
U-Net代替自动编码器来预测未来帧[2],通过在不同卷积层间添加跳跃连接使预测的图片细节更加清晰。但是这种方法不能保证异常事件对应于较高的重构错误或预测错误[12]。由于自动编码器的“泛化”能力太强,异常帧也可能被完整地重构或预测。为了解决模型“泛化”能力太强的问题,MemAE[7]通过一个简单的记忆增强模块,对正常场景高维特征进行稀疏映射,这样学习到的模型限制了对异常场景的预测。
基于先前研究[2,7],为了让模型仅能预测出正常事件,同时能够有清晰的细节信息,结合U-Net[14]和MemAE[7]的优势,在编码器和解码器的低层次特征间添加跳跃连接,同时叠加记忆增强模块,将记忆增强模块添加到U-Net的每一层以构建含有跳跃连接和记忆增强模块的预测网络,在预测图片的清晰度和异常事件区分度间达到一个平衡。由于监控视频中背景所占空间较大,传统的获取预测误差的方法是通过预测帧和真实帧中每个像素的差异来计算,当异常区域较小时无法突出异常。通过增加背景提取模块,对当前帧的背景进行提取,在计算预测帧与原始帧差异时,只计算前景部分的差异,通过这样的约束,可以突出异常区域对最终异常得分的影响。
在UCSD Ped2[15]、Avenue[16]和ShanghaiTech[1]数据集上将改进后的模型与最新的基于自动编码器的方法进行对比,同时分析了添加背景提取模块对实验结果的影响,证明了方法的有效性。
1 异常预测模型
视频异常检测的整体框架如图1所示。网络通过预测模块对输入的前4帧进行预测得到预测帧。通过背景提取模块获取背景。通过重构的背景与真实帧I t计算出前景区域,得到一个标记每个像素点是否为前景的掩码MASK。最后通过预测帧、真实帧和掩码来计算异常得分。
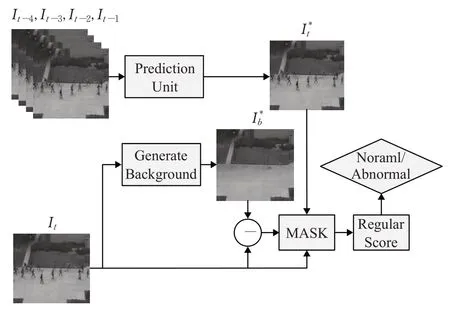
图1 异常检测的总体流程图Fig.1 Flow chart of anomaly detection
1.1 MemAE中记忆增强模块回顾
MemAE模型是为了解决自动编码器泛化能力太强的问题而提出的[7]。MemAE模型由编码器、解码器、内存模块组成。存储模块通过基于注意力的寻址运算检索记忆存储单元中最相关的项,然后通过这些项进行高维特征的重建。给定一个测试样本,该模型仅使用记录在存储器中的有限数量的正常模式执行特征重建。最终得到的输出趋于接近正常样本,导致正常样本的重建误差较小,异常样本的重建误差较大。
1.1.1 记忆增强模块的实现
图2介绍了记忆增强模块的结构,由于输入存储模块的特征z都由正常样本组合而成,记忆存储单元M通过特征优化得到的,经过记忆增强模块的输出ẑ也主要由正常样本的特征组成,迫使预测后的图像接近正常样本。具体的,将所有正常样本经过编码得到的特征保存在存储单元中。w表示当前输入特征与记忆存储单元M的相关系数,ŵ是经过硬压缩后的相关系数。通过硬压缩的操作,促使模型使用更少的记忆存储单元中的项来重建输入的特征z。
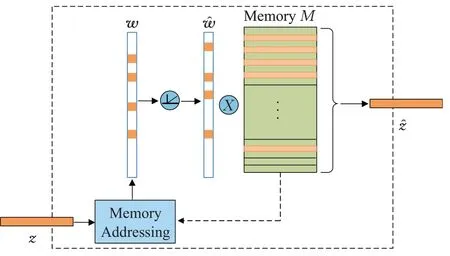
图2 记忆增强模块结构Fig.2 Structure of memory augmented module
记忆增强模块的输出通过权重向量与记忆存储单元相乘得到的:

w是一个和为1的非负行向量,w i表示w中的其中一项。权重向量是通过输入z计算得到的。N表示记忆存储单元的容量。
在训练和预测过程中,w通过z和记忆项M的相似性来计算:
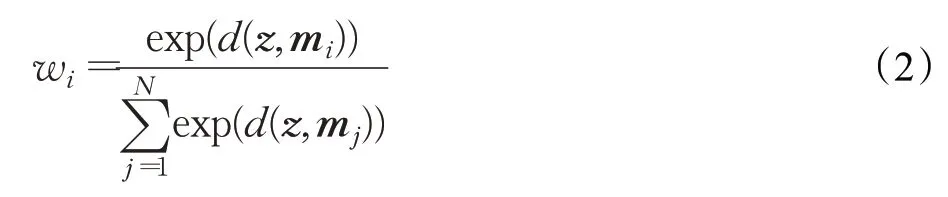
d(z,m i)表示输入特征z和记忆存储单元的第i项m i的相似性度量,被定义为:

通过公式(1)~(3)记忆增强模块会从记忆存储单元检索和输入z最接近的存储在M中的项来重建特征输出ẑ。为了限制对异常特征的重建,对相关系数w进行约束,将小权重系数设置为0进行硬压缩。

λ作为一个稀疏阈值,参考文献[7],在实验中取值为1/N。由于不是连续的函数,无法在训练中实现反向传播,使用连续的ReLU激活函数,重写约束系数:

其中,ε是一个非常小的正标量。
1.1.2 针对MemAE异常检测模型的改进
MemAE模型[7]通过在自动编码器的编码器和解码器之间添加记忆增强模块对视频中异常帧的预测进行约束。为了捕获视频的运动特征,文献[7]将堆叠的16帧灰度图作为编码器的输入,使用3D卷积来学习视频中的运动信息。同时,考虑到视频特征的复杂性,文献[7]在编码器和解码器两个模块之间,仅对在编码器最后一层提取到的高层次特征矩阵上的一个特征点进行记忆增强约束,这只对应于视频数据中某个固定区域。
在本文的模型中,将文献[7]中的记忆增强模块用在视频帧预测和背景重构两个分支上。在预测分支上,编解码器不同层之间添加跳跃连接的同时在跳跃连接之间添加记忆增强模块,使得预测帧的细节信息更加清晰,并对多个层次的特征进行约束。如图3所示,在编码器和解码器第2、3、4层之间采用了和文献[7]相同的连接方式对特征矩阵上的一个特征点进行约束。不同的是在跳跃连接的第1层,将特征矩阵进行压缩后将所有特征点压缩为一维向量传入记忆增强模块,并在解码器的对应层进行不同比例的连接。采取这样的做法主要是考虑到自动编码器的输入是将每个视频片段上的连续帧在通道维度上进行叠加,这样经过第一层的卷积操作提取到了一部分的运动信息,这部分运动信息会在后续的编码过程中逐渐减弱。为了对提取到的运动特征进行约束,在编码器和解码器第一层之间添加跳跃连接的同时,通过记忆增强模块来约束运动特征。
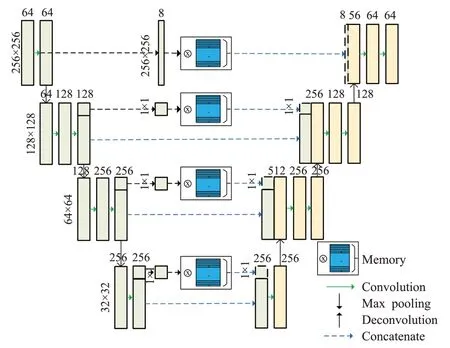
图3 预测模块的结构Fig.3 Structure of prediction module
由于3D卷积需要做更多的运算,同时在编码器和解码器之间添加跳跃连接的方式可以对运动特征进行约束,采用和文献[2]中相同的方式,将连续的4帧作为编码器的输入获取第5帧的预测,与文献[2]中通过光流对运动信息进行约束不同的是,使用RGB差异[3]来代替光流对运动信息进行约束。
1.2 跳跃连接融合记忆增强模块
MemAE通过在编码器和解码器之间添加记忆增强模块让异常事件无法很好的重建,从而提高对异常事件的识别能力。但是原始的自动编码器无法很好的对预测图片的细节信息进行预测,无法重现图片的细节信息导致生成图片和预测图片之间的差别较大。
受U-Net[14]的启发,通过在低层次特征之间添加跳跃连接可以使预测图片细节清晰。但是,直接将低层次特征进行连接,通过跳跃连接会传递到最终的预测结果中去,导致记忆增强模块在高层次无法有效地约束异常特征。为了解决这个问题,如图3所示,将跳跃连接应用到本文的模型中,同时在原有连接每层之间添加记忆增强模块。
由于视频图片应用的复杂性,在高层次特征的约束方面和文献[7]做了相同的处理,选取了特征中的某一个点进行约束。然后将经过记忆增强模块的特征点和原始的特征拼接起来。与其不同的是,在低层次中这样的特征提取方式并不能有效地抑制对异常事件低层次特征的重建。考虑到在第一层的特征结构为(256,256,64),提取其中的一个像素点对整体约束不大。通过卷积操作将低层次特征进行压缩,获取低层次的关键特征信息,之后将压缩后的特征向量转换为一维向量,输入到记忆增强模块进行处理。通过记忆增强模块重建的特征数量减少,对应地调整了在解码阶段从跳跃连接得到的特征和从高层次得到特征的权重,每一层的具体设置在图3中标出。
1.3 背景提取模块
由于监控视频中背景所占空间较大,传统的获取预测误差的方法是通过预测帧与真实帧中每个像素的差异来计算异常,本文增加了一个背景提取模块,对当前帧的背景进行提取。在计算预测帧与真实帧差异时,只计算前景部分的差异,通过这样的约束,可以突出异常区域对最终异常得分的影响。
图4展示了背景提取模块的结构,由于只需要提取当前帧的背景信息,只用输入当前帧I来进行重构得到提取到的背景,其中记忆增强模块采用和预测模块相同的实现。
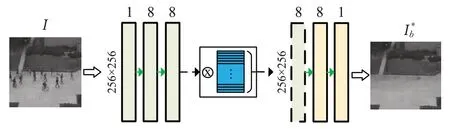
图4 背景提取模块的结构Fig.4 Structure of background extraction module
1.4 网络训练的约束函数
在图像预测阶段,为了更好地获得预测图片,采用了和文献[2]类似的做法,包括对预测帧和真实帧之间的强度和梯度进行约束。为了约束运动信息,将文献[2]中采用的通过FlowNet计算光流的方法改为计算之前帧和当前帧之间的RGB差异来进行约束。为了让正常特征可以通过稀疏的相关系数从记忆增强模块中的记忆存储单元获得重建特征,对每次训练得到的特征和记忆项之间相关系数的熵进行最小化优化。
1.4.1 记忆增强模块的优化目标
记忆增强模块能够限制对异常特征的重建,为了得到̂的稀疏表示。对于第t张图片I t,在生成预测图片的过程中,用表示某一次训练过程中记忆存储单元的相关系数。在训练阶段对̂的熵进行最小化约束[7]:

在预测模型中使用了4个记忆存储单元,每次迭代过程中获得的相关系数的熵,分别记为L w1、L w2、L w3、L w4。在背景重构中使用了一个记忆存储单元将需要优化的E记为L w0。得到了针对记忆存储模块的约束:
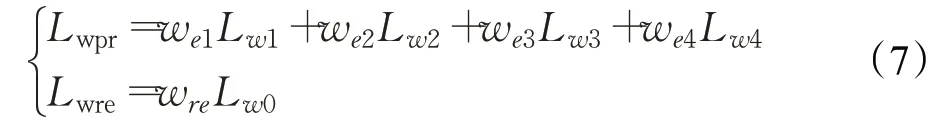
Lwpr表示预测模块中需要优化的记忆模块,其中w e1、w e2、w e3、w e4分别为每个稀疏项对应的权重,这里简单地对每个系数取值为0.25。
Lwre表示背景重构模块需要优化的记忆模块,w re表示对应的权重,取值为0.5。
1.4.2 预测模块的优化目标
在预测模块中,对预测图片和真实图片的强度和梯度[17]做了约束:
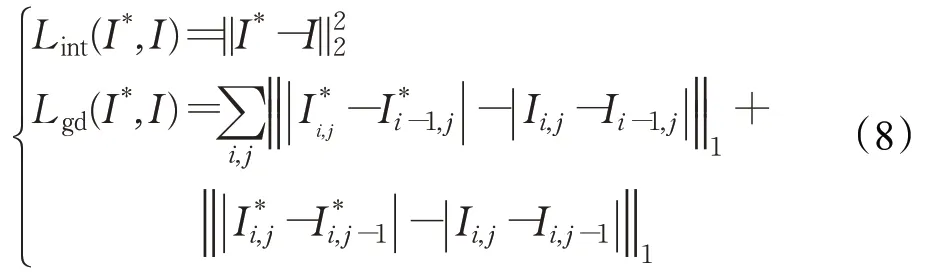
其中,I*表示预测帧,I表示原始帧,i、j表示视频帧的空间位置。
有很多研究通过提取光流来对视频的运动信息进行约束[2,12],尽管使用光流的方法能够获得较好的运动表现,但光流提取需要巨大的时间成本。为了解决这一问题,采用RGB差异[3,18],通过连续帧之间RGB像素强度的叠加差异约束运动特征:
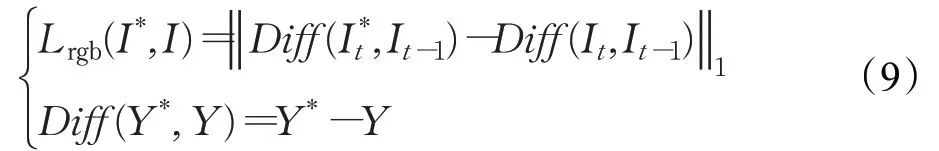
鉴于生成对抗网络在图片生成任务上表现出的良好效果,使用生成对抗网络来优化生成图片的质量。将预测模块作为生成器,鉴别器采用文献[19]的实现。生成对抗网络包括一个生成器G和一个鉴别器D,生成器生成图片让鉴别器很难区分,鉴别器尽可能正确区分生成的图片和原始图片。当训练鉴别器时,固定生成器,通过计算均方误差来进行约束:
i、j表示空间中每一个位置,均方误差定义为:

其中,Y取值{0,1},Y*∈[0,1]。
当训练生成器时,固定鉴别器,同样使用均方误差进行约束:
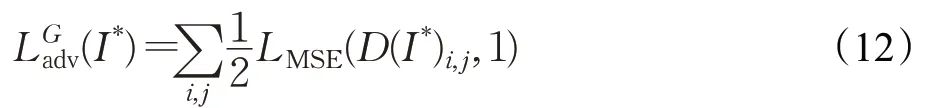
1.4.3 背景重构模块的优化目标
通过重构图片和原始图片的强度差异进行约束:

其中,I*b表示重构的背景,I表示原始帧。
1.5 目标优化函数
训练生成器通过最小化L G:
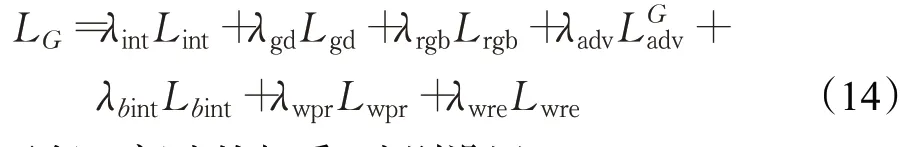
λ表示每一部分的权重,分别设置λint、λgd、λrgb、λadv、λbint、λwpr、λwre为1、1、2、0.05、1、0.002、0.000 2,这些设置和之前的工作[2,7]类似。
训练对抗器通过最小化L D:

针对不同的数据集,对灰度图使用单通道图片作为输入,彩色图片使用3通道作为输入,把每个像素的强度归一化到[-1,1]之间,并且将图片的输入裁剪为256×256大小。
1.6 测试集上的检测
得到训练模型后,在测试阶段可以通过比较预测图片和测试图片的差别峰值信噪比(PSNR)[20]来检测异常。和文献[2-3]不同的是,在计算PSNR时利用重建得到的背景图片与原始图片得到前景掩码:

其中,Fdiff是[-1,1]之间的值。
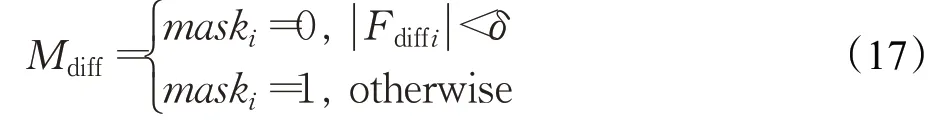
δ表示允许的背景I*b和原始图片I之间的误差,在实验中取值为0.06。Mdiff用来标记图片二维空间中前景位置,其中前景区域为1,背景区域为0。
为了消除背景区域对后续计算的影响,将原始图片和预测图片相应背景位置用0标记:

其中,I m、I*m分别表示真实帧和预测帧去掉背景后得到的像素空间。计算预测图片和原始图片去掉背景后的PSNR:
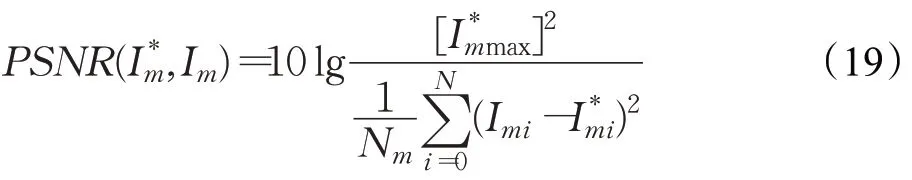
Im*max表示图片Im*像素的最大强度,N m表示掩码Mdiff中有多少个值为1的项,i表示每一个像素的位置。PSNR可以被归一化为:
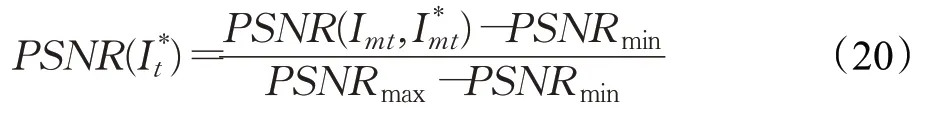
I mt、I*mt分别表示第t张图片的真实帧和预测帧去掉背景后的得到的像素空间。PSNRmax、PSNRmin指在每个测试视频的所有预测帧中,得到的PSN R的最大值和最小值。
将PSNR作为最终异常得分,更高的得分代表更不可能发生异常。
1.7 总体训练流程
步骤1数据预处理,对训练集和测试集的视频片段分帧,并对测试集的标签进行处理。
步骤2模型训练,采用批数据处理的方式,一次读取4批数据,每批数据包含5张图片,其中前4张图片作为预测模块的输入,第5张图片作为背景生成模块的输入,通过优化函数对模型进行更新。
步骤3模型测试,将预测模块和背景生成模块得到的图片和真实图片结合处理,得到每张图片的PSNR值。
步骤4判断模型效果,通过PSNR计算每个视频片段的异常得分,获取测试集的AUC。
2 实验
2.1 数据集
UCSD Ped2[15]数据集,训练集有16个视频片段,测试集有12个视频片段。异常场景包括穿过人行道的自行车、汽车、滑板手和轮椅等。
CUHK Avenue[16]数据集包含16个训练视频,共15 328帧,以及21测试视频,共15 324帧。每个视频帧的分辨率为360×640。异常场景包括奔跑,投掷物体和游荡等。
ShanghaiTech[1]数据集(SH.Tech)是用于异常事件检测的最大数据集之一。训练集有330个视频片段包含27万多个训练帧,测试集有107个视频片段包含4.2万多个测试帧(异常帧约1.7万个),覆盖了13个不同的场景。异常场景包括除行人(如车辆)以外的物体和剧烈运动(如打斗和追逐)。
2.2 评价指标
使用一系列常见的评估指标进行定量评估,通过更改异常得分的阈值并计算真阳性率(TPR)和假阳性率(FPR)来生成ROC曲线,与之前大多数工作[2,6,12]相同,采用帧级别ROC曲线下面积AUC来评估模型效果。
为了说明加入背景提取模块对异常检测性能的提升,利用正常帧和异常帧平均得分归一化后的差值Δs来评估模型对正常场景和异常场景的区分能力[3]。更大的Δs说明了模型的区分能力更强。
2.3 实验结果与分析
2.3.1 背景提取模块对模型性能的提升
为了说明添加背景提取模块对正常事件和异常事件区分能力的提高,表1中列出了在各个数据集中正常帧和异常帧归一化后平均得分的差值Δs以及添加背景提取模块对应AUC的影响,其中origin表示未使用提取到的背景参与PSNR计算得到的结果,rm-background表示将提取到的背景用于PSNR计算得到的结果。可以看出添加背景提取模块后模型在UCSD Ped2数据集和ShanghaiTech数据集上对正常样本和异常样本的区分能力有所增强,但在Avenue数据集上模型的区分能力提升较小。
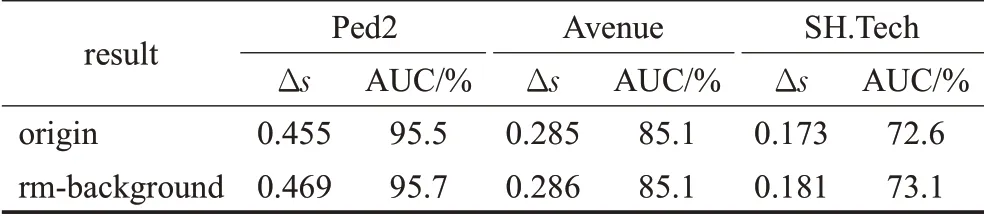
表1 叠加背景提取模块的效果Table 1 Effect of superimposed background extraction module
分析Avenue数据集的特点可以看出,由于Avenue数据集摄像头的拍摄方式为平视,这样视频画面中背景所占比例有限,其次Avenue数据集的前景区域和背景对比度不够明显,通过背景提取模块提取出的背景图片无法准确的获取前景所在位置,导致模型对正常事件和异常事件的区分能力没有明显提升。
在UCSD Ped2和ShanghaiTech数据集上的叠加背景提取模块对异常事件的区分能力的提升,主要因为这两个监控场景中背景区域占比较大,通过背景提取模块更能突出异常事件在整个视频帧中所占比例。考虑到ShanghaiTech数据集的场景复杂性(包含了13个不同的场景),背景提取模块因为记忆存储单元容量的限制,对部分场景无法提取出清晰的背景信息,尽管如此,通过背景提取模块仍然提高了模型在ShanghaiTech数据集上的异常检测能力。
2.3.2 对比其他模型的异常检测效果
为了说明模型对异常检测效果的提升,将本文的方法与其他现有的基于自动编码器的方法进行比较。表2列出了在不同数据集上使用不同方法得到的帧级AUC。在Avenue数据集上AUC达到85.1%,在ShanghaiTech数据集上AUC达到73.1%,证明所做的改进有助于异常事件的检测。
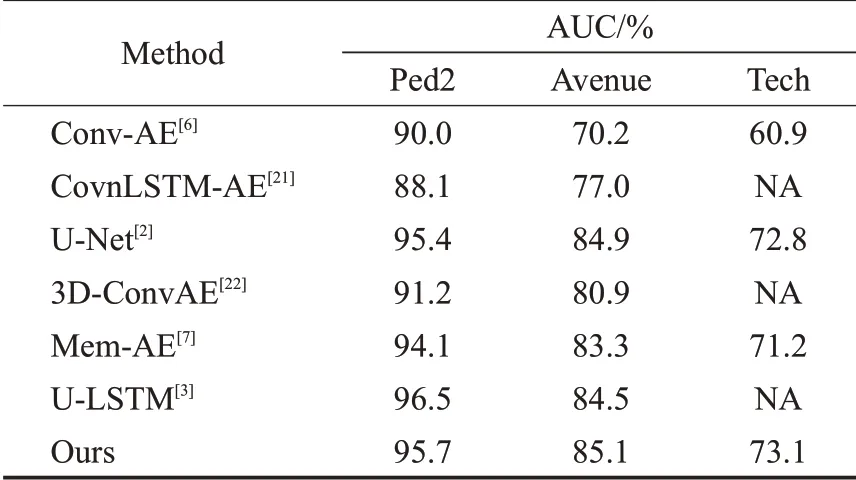
表2 异常检测结果对比Table 2 Comparison of abnormal detection results
相对于文献[3],模型在UCSD Ped2数据集上的表现有一定的下降。文献[3]将U-Net与LSTM结合来进行未来帧预测,与其他基于自动编码器方法不同的是,对于每一个视频片段(一个批次),为了在高层次特征之间通过ConvLSTM提取运动特征,文献[3]采用依次将连续的每帧图片输入自动编码器的方法来提取运动特征,这样在获取运动特征的同时会增加模型的运行时间。本文的模型将连续帧在通道维度上进行叠加,然后通过跳跃连接来对运动信息进行约束,在对运动信息进行约束的同时平衡了模型的运行时间。
在Avenue数据集和ShanghaiTech数据集上的实验结果表明本文的模型可以提高异常检测的能力。特别的ShanghaiTech数据集包含13个不同的场景,这增加了在该数据集上进行异常检测的难度。ShanghaiTech数据集中的的场景均为道路环境,对于包含的不同场景,正常事件和异常事件在不同场景有相同的定义,同时在高层次特征上也有相同的表现。在ShanghaiTech数据集上实验结果的提升说明,模型可以增加对异常事件的识别能力。
由于仅使用正常数据来训练模型,所以由正常事件组成的视频序列显示出比异常序列更高的分数。在图5中,当发生异常时(在图中的表现为人在奔跑),Avenue数据集视频帧的异常分数会明显降低,说明模型可以对异常的运动情况进行识别。在模型训练中,将连续的4帧图片作为通道信息输入网络,通过第一层卷积,可以对视频片段的运动特征进行学习。其次,异常的奔跑行为在空间上和正常场景也有区别。图5中的曲线是Avenue数据集上测试集中第4个视频片段对应的异常评分和标签。橙色虚线表示真实的标记标签,其中0表示正常帧,而1表示异常帧。蓝色实线为模型得到的每帧的异常得分。
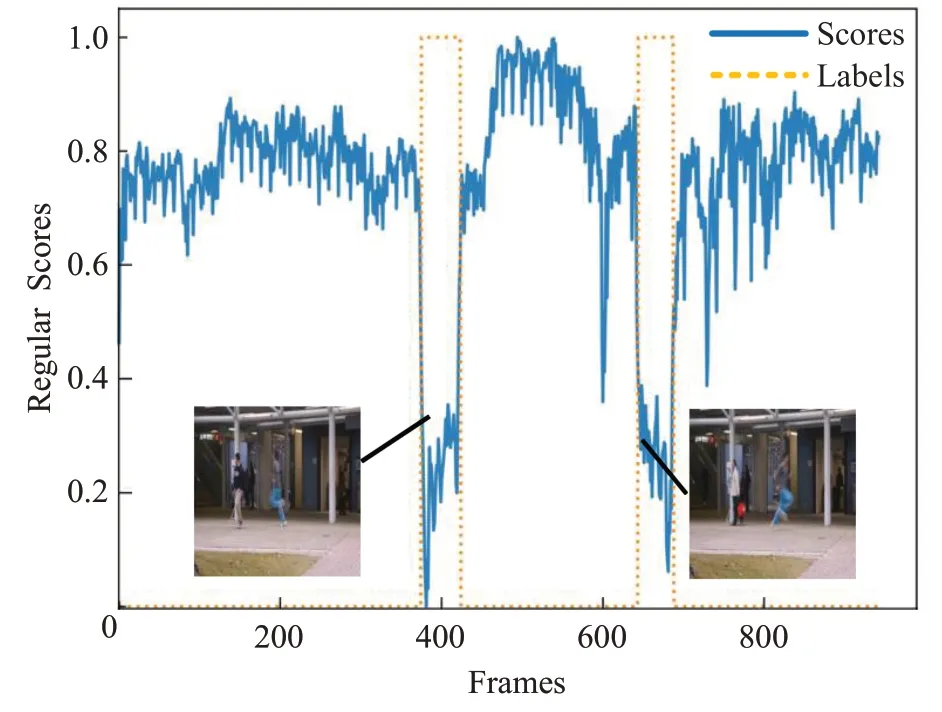
图5 在Avenue数据集获取的异常评分和标签Fig.5 Scores and tags obtained in Avenue dataset
图6对比了添加记忆模块和原有的基于U-Net的方法在3个数据集上的表现,在图6中可以看到通过添加记忆增强模块,对异常事件有一个较为模糊的预测,包括UCSD Ped2中的自行车,Avenue中人的跳跃,ShanghaiTech中人的跌倒。

图6 预测结果对比Fig.6 Comparison of prediction results
程序运行在NVIDIA GeForce RTX 2080 Ti GPU上,平均运行速度在单通道图片上大概为46 FPS,在三通道图片上大概为36 FPS。
3 结束语
将记忆增强模块应用在包含跳跃连接的自动编码器模型中,通过添加记忆存储单元来约束对正常事件特征的表示。由于监控视频背景区域所占面积较大,不便于异常事件的检测,通过背景提取模块获取前景像素级的掩码信息,仅对前景区域进行异常判断可以增强模型对正常场景和异常场景的区分能力。在一些数据集上的实验表明了方法的有效性。
低层次特征通过记忆存储单元对正常事件特征进行编码,需要记忆的内容过多,限制了对低层次特征的约束,同时增大了计算量,接下来研究工作的重点是找到一个可以更好约束低层次特征的方式,在降低计算量的同时继续提高模型对异常事件的识别能力。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
汽车工程师(2021年12期)2022-01-17
科学技术创新(2021年5期)2021-03-17
当代陕西(2020年14期)2021-01-08
——编码器
演艺科技(2020年7期)2020-08-13
奥秘(创新大赛)(2020年7期)2020-07-27
小学阅读指南·低年级版(2017年1期)2017-03-13
探测与控制学报(2015年4期)2015-12-15
人生十六七(2015年6期)2015-02-28
计算机辅助工程(2012年5期)2012-11-21
