
基于生成对抗网络的磁共振图像重建
2022-08-09 05:48胥祯浩
计算机工程与应用 2022年15期
胥祯浩,沈 茜,李 霞
中国计量大学 信息工程学院,杭州 310018
磁共振成像技术(magnetic resonance imaging,MRI)[1]通过外加磁场,激发氢原子产生共振,并捕捉在共振过程中释放的电磁信号进行成像操作。其与X射线、CT等医学影像技术相比,具有无创伤、无电离辐射等优点,因而成为临床诊断中常用的辅助诊断技术[2]。MR采集到的数据为K空间数据,对其进行逆傅里叶变换即可得到MR图像。其中K空间数据点越多,形成的图像分辨率也就越高。但高质量的MR图像意味着更长的扫描时间,从而造成以下一系列问题:(1)某些需要短时间扫描的场合,由于器官运动(例如呼吸、眨眼、吞咽等非自主运动)造成图像伪影。(2)磁共振成像环境较为封闭,过长的扫描时间导致病人产生幽闭恐惧心理,产生不自觉移动,降低成像质量[3]。因此,研究如何在短时间内快速获取高质量的MR图像具有重要的实用价值和现实意义。
压缩感知(compressed sensing,CS)原理[4]被Lustig等人[5]应用于MRI的采样和重建任务中,该理论以信号的稀疏性为前提,通过观测矩阵对稀疏信号压缩采样,从欠采样的信号中得到重建MR图像。虽然CS-MRI在一定程度上加快了K空间的重建,但是其仍然存在很多限制[6-7]:(1)目前CS-MRI使用的稀疏变换过于简单,无法捕捉复杂图像细节。(2)非线性优化解算器通常涉及迭代计算和更新,这往往会延长重建时间。(3)CS-MRI中不合适的超参数预测,会导致重建图像过于平滑以及不自然。
近年来随着深度学习的发展,利用卷积神经网络强大的特征提取能力,较大地改善了传统重建技术的不足。Li等人[6]提出structure-enhanced GAN(SEGAN)结构,SEGAN在生成器部分使用一个全新结构SU-net,在SU-net每一层的网络中使用多尺寸卷积核,并将其合并以增强特征表达能力。Hyun等人[8]通过使用U-net[9]结构,仅利用29%的K空间信息就重建出高质量的MR图像。Seitzer等人[10]提出一个二阶段的训练过程,将重建任务和改善视觉质量任务分成两个阶段来训练,提高重建后图像的视觉感受。Schlemper等人[11]通过对卷积网络的级联来实现对欠采样MR图像的重建。Yang等人[12]通过将交替方向乘子法(ADMM)与CNN进行联合,加快了重建时间。
虽然目前利用卷积神经网络对MRI图像进行重建已经取得了诸多成果,但仍存在一些问题,如:(1)现阶段常用模型是通过增加网络深度和宽度实现重建性能提升,未能充分利用网络感受野实现伪影去除。(2)现研究MR图像重建算法更多关注PSNR指标的提升,缺少对重建图像视觉感受的重视。
针对以上问题,将生成对抗网络(generative adversarial network,GAN)[13]作为重建算法原型,利用较少的K空间数据即可得到较高质量的MR图像,极大缩短了扫描时间。本文主要贡献为:(1)将U-net结构作为GAN网络的生成器原型,在其编码层部分使用残差结构,通过残差映射等方式缓解网络梯度消失的问题,提高特征利用率。(2)提出空洞金字塔结构并将其连接于解码层之前,通过使用不同扩张率的空洞卷积[14]来捕获不同尺度的上下文信息,提高模型对伪影和细节的判别能力。(3)生成器的损失函数除了使用原始均方误差和对抗损失外,还添加感知损失,利用生成图像和目标图像在特征空间的欧式距离,提高两者之间的语义相似度,改善视觉感受。(4)为进一步提升MR图像重建质量,在保留原始模型优势的基础上引入集成学习,对多个学习器进行组合以实现网络总体性能的提升。
1 数据处理与重建方法
1.1 数据下采样
本文数据集选用open access series of imaging studies(OASIS)大型开源数据集。为了证明模型能适应各种采样率下的MR图像重建,使用四种不同的采样因子分别为10、5、3、2来获取欠采样MR图像,即分别获取10%、20%、30%、50%的K空间数据,并进行逆傅里叶变换,实现空间域到图像域的映射。
基于Hyun等人的理论[8],在采样时添加低频信息,能有效解决位置不确定的问题,并且可以保留更多的细节信息。在保持上述采样因子不变的情况下,额外添加4%的低频信息段,采样结果如图1所示。
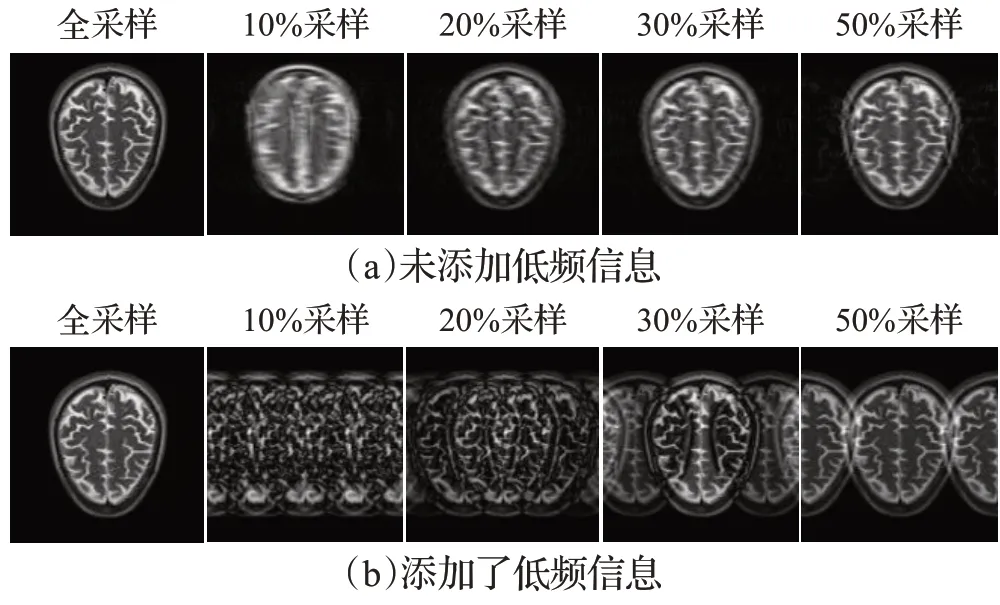
图1 不同采样操作的MR图像Fig.1 MR images of different sampling rate
1.2 数据增强
一般情况下,深度学习中拥有的数据样本越多,模型的性能越好。由于医疗图像数量的稀缺性,将采用数据增强的方式扩充数据量,使模型更加稳健。本文使用在线随机增强的方式来提高模型的鲁棒性,在线随机增强的方法是每次只获取一个批量(batch)的数据并对其进行随机增强,相比离线数据增强,这极大缓解了硬盘的存储压力。本文用四种不同的方式以相同的概率值进行随机增强,以确保数据的重复性保持在较低的水平。以0.25的概率使用上下翻转的增强方式,0.25的概率采用水平镜像,0.25的概率使用90°倍数旋转方式,0.25的概率采用平移增强方式。通过在线随机增强降低了模型对目标位置的敏感性,使原本较难收敛的模型快速收敛,提高模型性能。
1.3 重建网络
重建网络由两部分组成:生成器网络(简称生成器)和判别器网络(简称判别器)。生成器主要学习如何将欠采样MR图像映射到全采样图像的过程,判别器则主要完成判断生成器图像是否“真实自然”的过程。
本文以生成对抗网络为原型,生成器部分采用U-net结构,考虑到重建任务本身需要极强的上下文信息提出了空洞金字塔结构并将其连接于U-net解码层之前,以此实现上下文信息融合。在判别器中连续使用8个卷积层,卷积核个数随着网络层数加深不断增加。遵循Radford等人[15]总结的体系结构准则,在判别器网络中避免使用最大池化层,转而采用改变卷积步长的方式来实现特征下采样,最后通过两个全连接层和sigmoid激活函数对图像进行分类,生成对抗网络结构如图2所示。
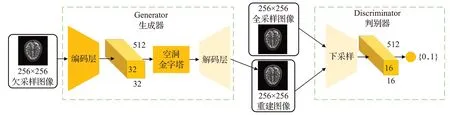
图2 生成对抗网络结构Fig.2 Structure of generative adversarial network
重建网络的具体流程为:首先对原始数据进行傅里叶变换获取K空间数据,然后对K空间数据以不同采样因子进行欠采样操作且对其进行逆傅里叶变换,以获取欠采样图像作为生成器的输入。将欠采样图像喂入生成器,利用卷积神经网络的特征学习能力实现输入图像与全采样MR图像之间的映射,并将重建后的MR图像和全采样图像送入判别器判断图像来源。最后,生成器和判别器通过反向传播不断交替训练和优化,使两者达到平衡[16],实现低质量MR图像到高质量图像的重建。
1.3.1 生成器网络
本文的生成器结构如图3所示,主要功能是通过神经网络实现去除欠采样MR图像伪影的功能。其中U-net结构由两部分组成,左边为编码层用于特征提取,右边为解码层通过插值方式将特征放大并使用跳跃连接将编码层对应的尺度特征进行拼接。
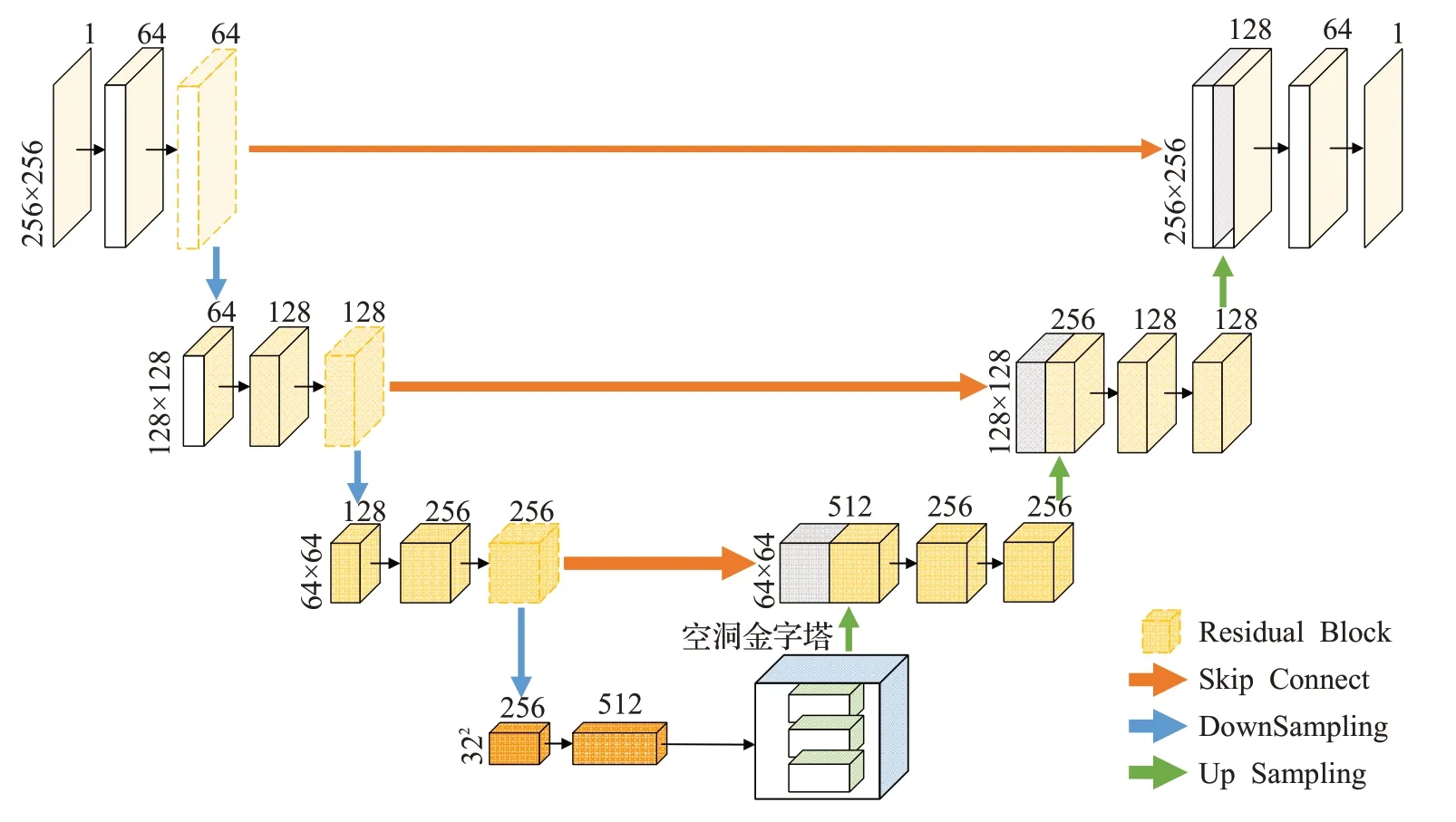
图3 生成器网络结构Fig.3 Structure of generator network
在编码层部分,使用了残差结构来进行特征提取,此结构由残差映射和恒等映射两部分组成,使用此模块能较好地缓解网络随着深度的加深而产生梯度消失或者网络退化等问题。
如图4(a)与(b)所示,H(x)为卷积神经网络中若干非线性网络层的目标映射,其中x为网络的输入,而残差网络则需要去拟合残差映射F(x)。
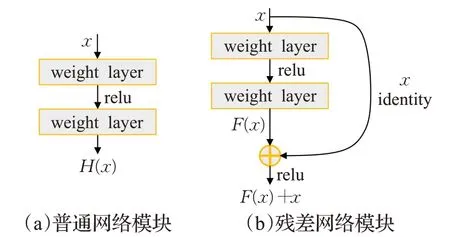
图4 普通网络模块与残差网络模块结构Fig.4 Structure of convolutional unit and residual unit
其数学表达式为:

结合上述公式及图4可知残差学习比直接对原始特征进行学习更为容易。当F(x)=0时,卷积堆叠层可实现恒等映射,保证了网络性能的不受影响,事实上F(x)并不会一直为0,这样卷积堆叠层可在输入的基础上学习到新特征提升性能。
K空间欠采样过程因打破奎奈斯特-香农采样定理产生了大量伪影,而网络感受野的增大能有效帮助模型区分伪影和真实的细节信息[17]。因此在进入解码层之前,将编码层的输出特征送入提出的空洞金字塔结构,来增大网络的感受野。该结构如图5所示,其相较于标准卷积的不同之处是引入了新的参数——扩张率d,该参数定义了卷积核处理数据时各值的间距,即在连续的滤波器值之间引入d-1个0,如灰色部分。在不增加参数量和计算量的前提下,将原本感受野为k的标准卷积扩大到了k+(k-1)×(d-1),如绿色部分。本文使用了三种不同扩张率(分别为1、2、4)的空洞卷积,利用空洞卷积代替最大池化等增加网络感受野的操作,能在分辨率恢复时对特征图进行更密集的计算,更为重要的是,将不同扩张率的多个空洞卷积进行并行操作,再利用1×1卷积将特征融合,可实现对目标的多尺度捕获,从而提升重建质量。
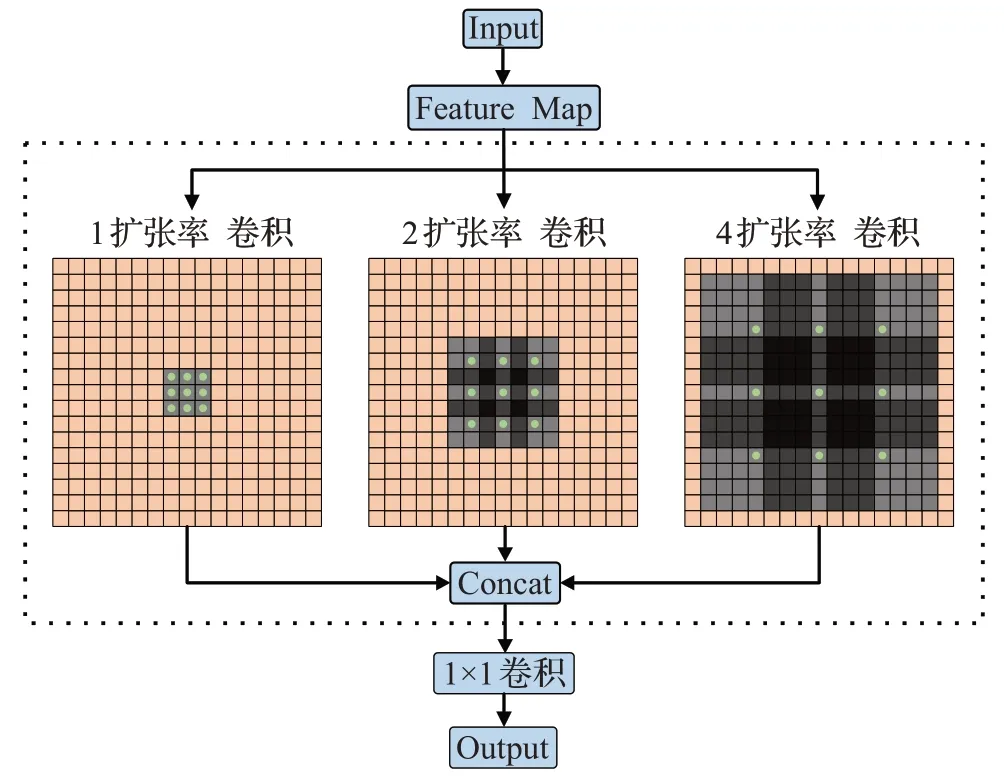
图5 空洞金字塔结构Fig.5 Structure of atrous pyramid
在解码层中,通过跳跃连接将编码层同层信息与前一层上采样信息进行拼接,实现不同层次特征融合,不仅为重建提供了抽象的语义信息,同时也提供了浅层信息的细节特征,从而进一步提高了MR图像重建质量。
1.3.2 判别器网络
判别器主要功能是对输入的MR图像来源进行判断区分,具体结构如图6所示。判别网络由一系列卷积组成,通过卷积步长的改变实现特征下采样。在每一个卷积后加上一个批量标准化(batch normalization)[18],以标准正态分布作为输入标准化的方式,避免产生梯度消失的问题。对数据进行批量标准化后,使用leakyReLU激活函数[19]来增强网络非线性能力。leakyReLU不同于ReLU[20],其对负值输入有较小的梯度,使负值的导数不为零,解决ReLU进入负区间后神经元不学习的问题。最后使用sigmoid激活函数来进行二分类(判断属于完全采样还是欠采样),sigmoid函数公式如下:
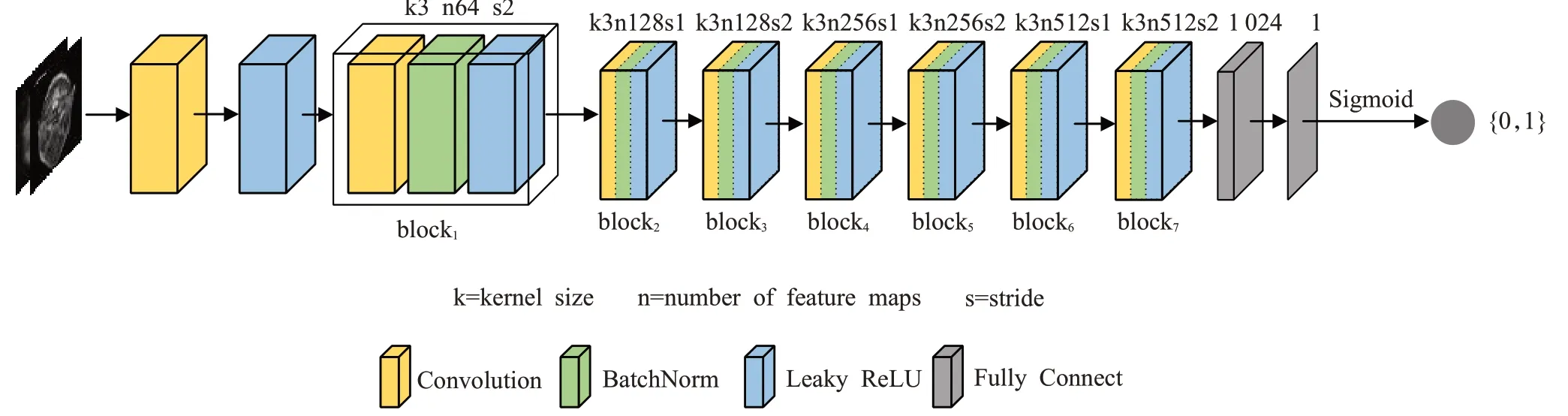
图6 判别器网络Fig.6 Structure of discriminator network

由于sigmoid激活函数把输出范围定于0~1之间,因此在二分类任务中,其输出可被视为概率输出。
1.4 损失函数
1.4.1 生成器损失函数
整个生成器的损失函数l RS包括内容损失和对抗损失,具体表达式如下:

内容损失由两部分组成,其一为基于像素点的均方误差而另一个则为感知损失),并通过系数r来实现对两者的平衡,在文本中设置r=6×10-3。
具体表达如公式(4)所示:
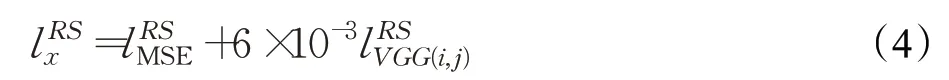
除了利用像素间的损失,借鉴Gatys等人[22]的思想,引入感知损失来解决上文提到的人眼观察感受下降的问题。该方法是通过将重建图像和原始全采样图像同时输入VGG16[23]预训练的网络中,并进行特征提取,然后计算两者之间的均方误差。因为卷积网络的输出特征含有较多的纹理信息,不断优化感知损失可以获得较高的纹理相似度,弥补了MSE缺少纹理特征的不足。具体表达式如公式(5)所示:
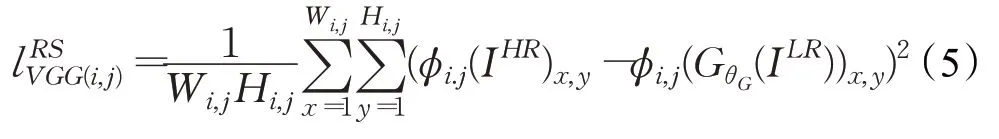
其中,Wi,j和Hi,j为被提取特征的维度,φ是经ImageNet数据集预训练的网络,φi,j为第i个最大池化层前的第j个卷积层特征。感知损失函数通过测量图像之间内容和样式的感知差异,让图像显得更加真实[24]。
关于对抗损失,若判别器对生成器产生样本的判断结果越接近1,则说明其生成的数据越接近于真实分布,具体表达式如下所示:
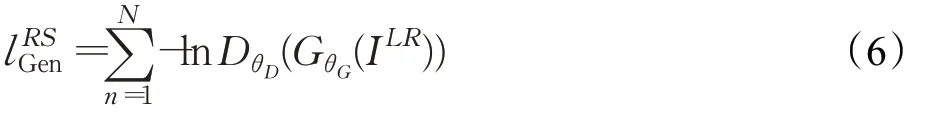
其中,DθD(GθG(I LR))代表重建后图像属于原始全采样图像的概率值。
1.4.2 判别器损失函数
判别器主要区分输入的MR图像来源,其优化的目标在于提高判别准确率,具体表达式如下:
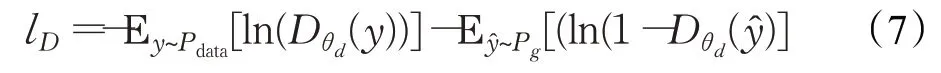
其中,Pdata为全采样MR图像的数据分布,P g为生成器学习到的数据分布,Εy~Pdata[ln(Dθd(y))]表示判别器对全采样MR图像的期望值,Εŷ~P g[(ln(1-Dθd(̂)]表示判别器对网络重建MR图像的期望值。对于判别器D而言,最小化损失函数l D即为最大化全采样图像y和网络重建图像ŷ的判断正确率。
1.5 集成学习
为了进一步提高MR图像的重建质量,采用了集成学习的方式,其思想为通过训练多个学习器并将这些学习器的结果组合起来,从而达到更好的学习性能,基本结构如图7所示。
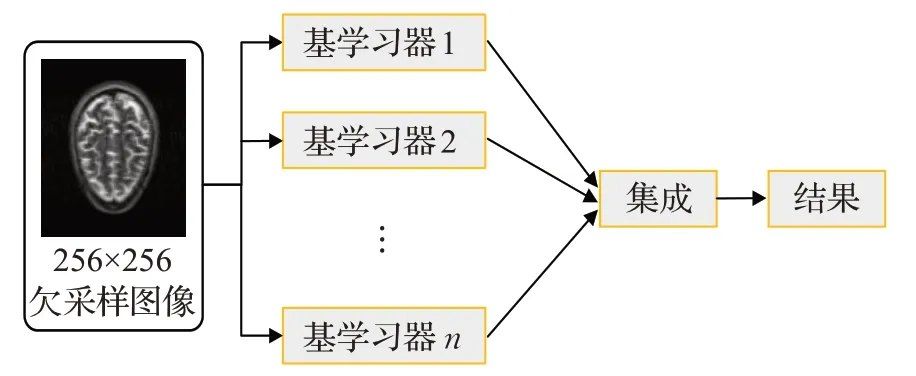
图7 集成学习基本结构Fig.7 Basic structure of ensemble learning
将MR图像重建和集成学习进行结合,构造多个不同的重建模型,根据算法在验证集上的表现选取若干个性能较优的模型(本文选取了5个不同模型),然后将测试数据分别输入被选取的模型获得预测结果,最后对各学习器输出的重建图像加权集成,得到最终重建结果。在MR图像重建任务中使用集成学习不仅能保留本文模型原始优势,而且可进一步提高本文方法的建模精度,改善重建结果。
2 数据集与评价指标
2.1 数据集
从OASIS大型开源数据集中挑选145个MR图像文件,将其随机打乱,其中70%的MR图像文件用于训练,剩余30%用于测试。对训练集中MR图像文件进行切片生成2 475张图像,并从2 475张图像中随机抓取20%作为验证集。训练集通过梯度更新的方式训练模型,使模型尽可能拟合真实数据分布。验证集则用于选择精度较高的模型以及结合训练集的情况判断模型是否过拟合。测试集中的MR图像文件以同样的方式进行切片共生成1 060张图像,用于验证模型的鲁棒性和泛化性。
2.2 评价指标
2.2.1 均方误差(MSE)
使用均方误差作为衡量重建图像和原始图像相似性的指标之一,公式如下所示:

其中,N代表测试集总数,2562代表单张图像长为256像素,宽为256像素,是经过网络重建后的图像像素值,是真实图像像素值,当MSE的值越小就表明重建后的图像数据分布越接近原始全采样图像的数据分布。
2.2.2 峰值信噪比(PSNR)
峰值信噪比(peak signal to noise ratio,PSNR),常用于图像压缩领域中信号重建质量的测量,通过MSE进行定义:
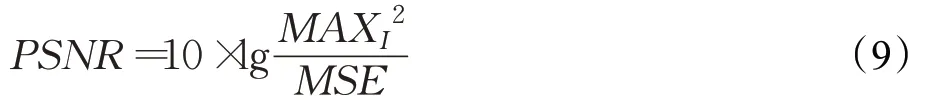
其中,MAX I为图片I可能的最大像素值,如果像素由B位二进制表示,那么MAX I=2B-1,本文每个像素都由8位二进制来表示,所以最大MAX I=255。PSNR越高则表示失真越少。其作为最普遍的图像评价指标之一,未考虑到人眼的视觉特性,因而常出现评价指标和主观感受不一致的情况,为此引入了结构相似性作为另一评价指标[25]。
2.2.3 结构相似性(SSIM)
结构相似性(structural similarity index,SSIM),是一种衡量两幅图像相似度的指标。给定两个图像x和y,两张图像的SSIM可按照以下方式求出:
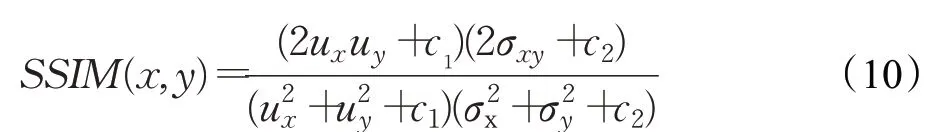
其中,u x、u y是x和y的平均值,σ2x、σ2y是x和y的方差,σxy是x和y的协方差,c1、c2为常数,避免分母为零的现象出现。SSIM值越大则表示两幅图像的相似度越高。结构相似性用均值估计亮度,标准差估计对比度,协方差度量结构相似性,从三个不同的角度对两幅图像进行衡量,更好地适应了人类视觉系统,更加客观地衡量了视觉感受[26]。
3 实验结果
本模型训练主要基于Pytorch框架工具,使用的操作系统为Ubuntu 16.04.2 LTS,CPU采用Xeon®E5-2630 v4,训练显卡为NVIDIA GeForce GTX TITAN X其显存为12 GB。本文实验将batch设置为10,使用Adam为优化器并将学习率设置为1E-4,迭代200个epoch完成训练(1个epoch等于训练集的全部数据对模型进行一次完整训练)。
通过上述方法和训练参数设置,本文实现了高质量MR图像重建,重建结果如图8所示。

图8 预测结果可视化图Fig.8 Visualization of prediction results
采用消融实验的方式论证各个模块的有效性,消融对比条件为分别去除残差结构、空洞金字塔结构、感知损失三个模块并在采样率分别为10%、20%、30%、50%上进行实验对比,其中图9和表1为各实验在SSIM、MSE、PSNR三种评价指标下的结果。
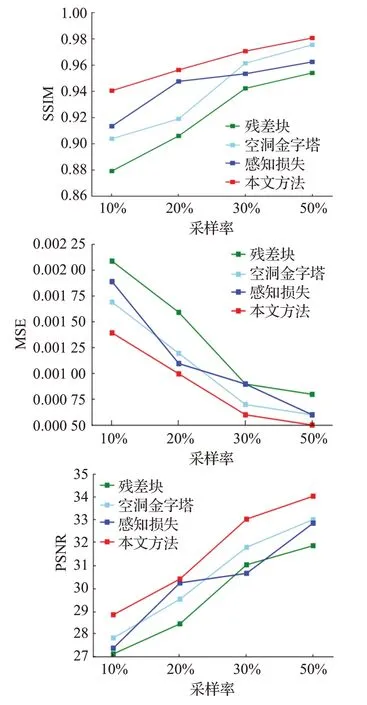
图9 不同采样率下的消融实验结果可视化Fig.9 Visualization of results on ablation studies at different sampling rates
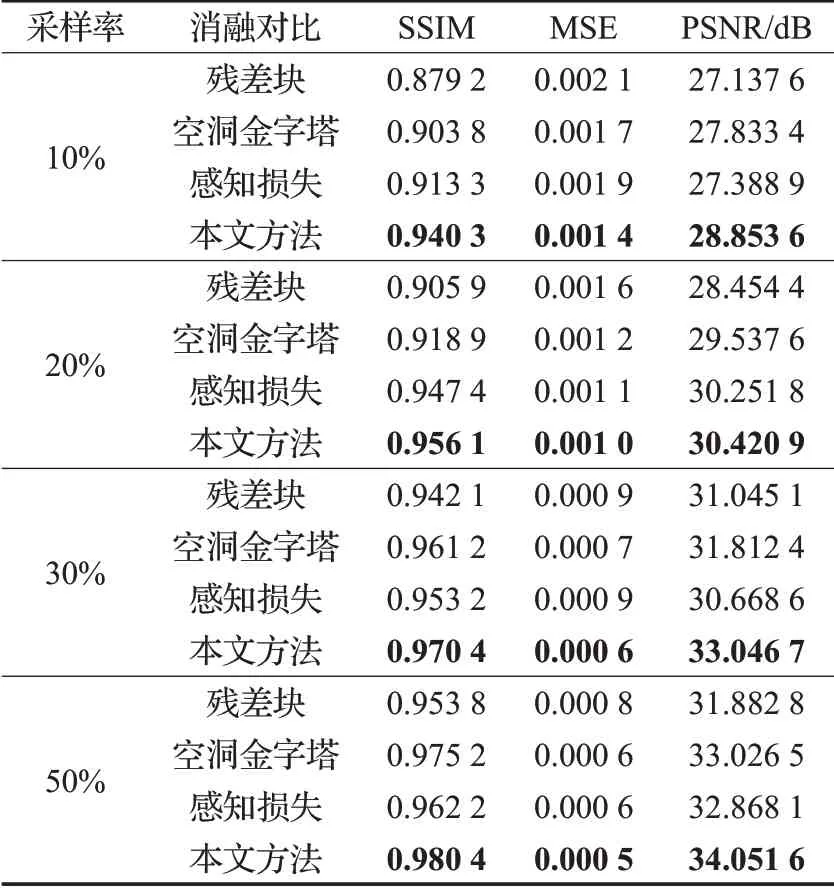
表1 各模块消融结果Table 1 Ablation results of each module
残差结构通过残差映射等方式提高了特征利用率缓解了梯度消失的现象,且从表1可以看出其最多可提升2.17 dB的PSNR,SSIM提升0.006,MSE降低0.000 6,从数据层面进一步证明了其有效性。
空洞金字塔结构通过并行使用不同扩张率的空洞卷积,不仅增加了网络的感受野使其能有效区分伪影和细节信息且利用1×1卷积将特征融合,实现对目标的多尺度捕获,从而提升重建质量。与未添加空洞金字塔结构相比,其最多可提升1.23 dB的PSNR值,0.04的SSIM值,降低0.000 3的MSE值。
感知损失将重建后的MR图像和原始全采样图像分别送入卷积神经网络提取相应特征,并计算两者之间的欧氏距离作为损失函数的一部分,实现从高维感知图像,提高人眼视觉感受,由表1可知感知损失最多能提升2.37 dB的PSNR值,0.027的SSIM值,降低0.000 10的MSE值,对提高MR图像的重建质量具有一定帮助。
以上三组消融实验从不同角度证明了模型的各个模块均能提升MR图像的重建质量。为了进一步评估模型的有效性,分别于已有研究成果和主流重建网络在相同实验环境下,对相同测试集进行对比实验,结果见表2和图10。
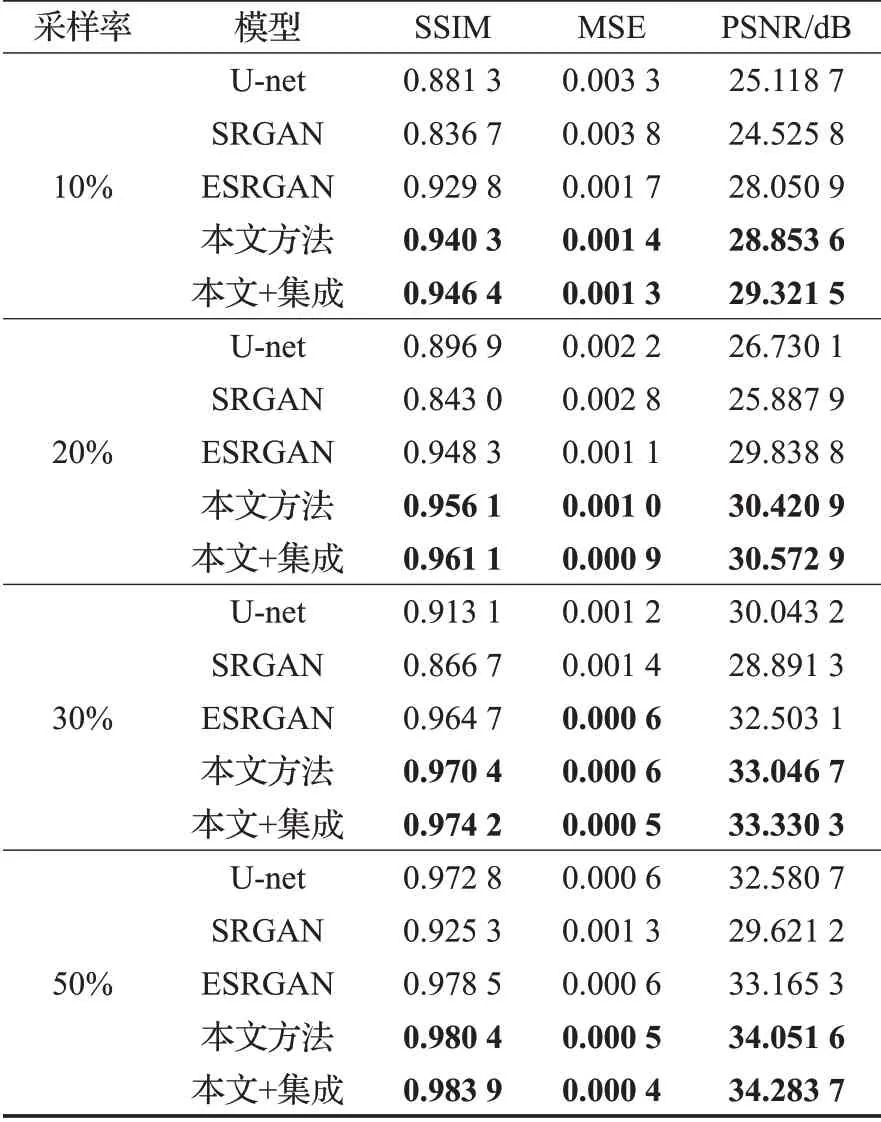
表2 与其他重建网络对比结果Table 2 Compared with other reconstruction networks
其中表2内数据为各重建模型在不同采样率下获得的MSE、PSNR和SSIM值,可知本文的方法在重建质量上均高于其他模型,且模型在不同K空间采样率下均能保持较高重建精度,表明模型的泛化性能较好。同时为了更好地提高MR图像的重建质量,在保持原始模型优势的基础上引入集成学习技术,结合多个较优模型,对模型预测的结果进行集成,获得最优MR重建图像,根据表2和图10可以观察到集成学习的加入可实现对各个重建指标的进一步提升。
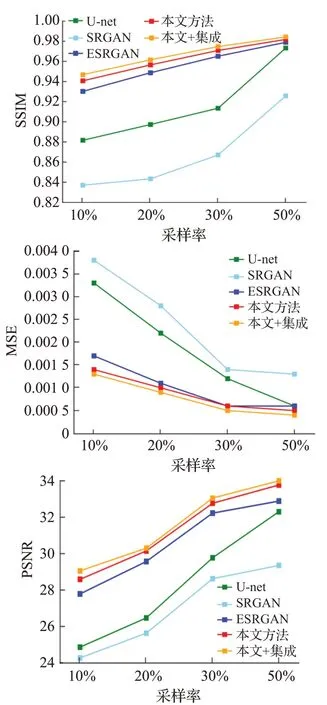
图10 不同采样率下重建网络对比结果可视化Fig.10 Visualization of results on reconstruction networks at different sampling rates
4 总结
本文提出了一种全新的重建算法:以生成对抗网络为原型,在生成器部分使用U-net网络架构,利用残差结构有效提高特征利用率缓解梯度消失现象。提出的空洞金字塔结构不仅提升网络区分伪影和图像细节的能力,并且实现了多尺度信息的融合;在损失函数部分添加感知损失,通过计算重建图像和目标图像在特征空间的欧氏距离,提高两者之间的语义相似度,更好地改善了视觉效果;同时引入了集成学习技术,通过将不同重建器的预测结果进行结合,可实现在保持模型原始优势的基础上进一步提升重建性能。在不同采样率下进行了三组消融实验,即分别去除空洞金字塔、残差结构、感知损失,证明了各模块的有效性。在与目前主流重建网络对比实验中,本文提出的算法表现出一定优势,且该优势能在多个不同采样率下得以保持,进一步说明了本模型的泛化性和鲁棒性。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
今日农业(2021年11期)2021-11-27
数学小灵通·3-4年级(2021年5期)2021-07-16
北京航空航天大学学报(2020年10期)2020-11-14
学生天地(2020年18期)2020-08-25
北京航空航天大学学报(2019年9期)2019-10-26
今日农业(2019年15期)2019-01-03
故事作文·高年级(2017年2期)2017-03-01
共产党员(辽宁)(2015年2期)2015-12-06
