
考虑奖惩的闭环供应链策略分析
2022-08-09 08:21司凤山戴道明孙玉涛
武汉理工大学学报(信息与管理工程版) 2022年3期
王 晶,司凤山,戴道明,孙玉涛
(安徽财经大学 管理科学与工程学院,安徽 蚌埠 233030)
为了减少环境污染和资源浪费,政府往往采取奖惩措施促进废品的回收和循环利用。当前,关于供应链中的奖惩机制研究,王道平等[1]研究了政府对制造商碳排放的奖惩机制,分析了差异定价闭环供应链的协调问题,探究了政府的奖惩力度和碳排放约束政策对供应链利润的影响。周蕊等[2]研究了闭环供应链中政府补贴和奖惩机制对供应链的影响,对比分析了无政府参与、政府补贴机制、政府奖惩机制下的供应链模型。李潇芮等[3]在考虑技术溢出效应和回收竞争的基础上,建立了有无奖惩机制、回收商有无独立研发的决策模型,分析了奖惩机制与回收商决策间的关系。易余胤等[4]研究了集中和分散决策下考虑奖惩机制闭环供应链的最优策略问题,分析了奖惩力度和最低回收率对策略和利润的影响,并设计了协调机制实现供应链的协调。WANG等[5-7]研究了由制造商和回收商构成的闭环供应链中,关于废旧产品回收过程中的责任分担、政府奖惩、信息不对称、多周期等问题,探究了有无政府奖惩机制对博弈策略的影响,针对不同权利结构的回收渠道设计了多种奖惩机制来提高废品的回收率,对比分析了单周期模型和双周期模型的异同。上述研究从政府对制造商碳减排的奖惩机制、政府补贴与奖惩并举机制、技术研发奖惩机制等方面分析了供应链博弈的最优策略,为政府依据回收率对零售商进行奖惩研究奠定了基础。
关于供应链中动力学行为的研究,于淼等[8]在考虑新产品和再制造产品定价差异的基础上,运用演化博弈理论和系统复杂性理论分析了闭环供应链中的产品销售行为,并对混沌系统实现了有效控制。谢磊等[9]研究了多种因素对消费者效用最大化博弈模型稳定性的影响,分析了废品回收的认可度对系统利润的影响,给出了系统利润演化趋势变化的原因。MA等[10]针对闭环供应链构建了非合作模式下的权利不对等和权利对等两种博弈模型,分析了离散博弈系统的分岔、混沌等动力学特性,探究了决策参数对两种模型博弈策略的影响。LOU等[11]在供应链中考虑销售努力和碳减排努力等因素,构建了有无碳减排努力两种情形下的博弈模型,分析了Nash博弈、Stackelberg博弈和低碳Stackelberg博弈中的最优博弈策略和博弈行为。ZHANG等[12]通过构建政府与制造商之间的演化博弈模型,研究政府政策对制造商决策的影响,分析静、动态碳交易价格影响下政府政策对碳交易市场的影响,给出了博弈模型的演化均衡策略。FAN等[13]在考虑消费者低碳偏好的基础上分析了供应链中的静态博弈和动态博弈模型,给出了最优博弈策略的解析式,探究了多种因素对博弈模型复杂动力学行为的影响。CHEN等[14]研究了具有供应链融资风险规避的报童博弈模型,给出了博弈系统局部渐近稳定性的条件,分析了博弈系统Hopf分岔的方向,并对博弈系统的复杂特性进行了探讨。MA等[15]针对供应链系统的稳定性,讨论了制造商和零售商的损失敏感性、决策调整速度等因素对系统稳定性的影响,进而分析了系统的稳定性对决策者利润的影响。上述研究从产品的销售行为、消费者效用、非对称博弈、销售努力、碳减排努力、风险规避等方面分析了离散博弈系统的稳定性和复杂性,为研究连续博弈系统的动力学行为提供了重要参考。
综上所述,国内外学者在供应链奖惩和系统动力学行为研究方面取得了丰富的研究成果,笔者在此基础上从系统稳定性的角度进一步探究奖惩闭环供应链博弈策略的动态调整轨迹,不仅关注博弈的最优策略,而且更关注博弈双方从博弈的初始状态是如何经过不断地、反复地策略调整最终收敛于均衡态(最优策略)的过程。不但能使企业明确将要达到的最优策略,还使他们知道走向最优策略将要经历的策略调整趋势和轨迹,在一定程度上起到策略预测的作用。
1 问题描述
笔者研究的闭环供应链由一个制造商和一个零售商组成,制造商一方面利用原材料生产新产品,单位生产成本为c1(原材料成本和加工成本之和),另一方面利用废品进行再制造,单位再制造产品的生产成本为c2(不含废品原材料成本)。新产品和再制造产品在市场中并存销售,制造商以价格w把产品批发给零售商销售,单位产品零售价为p,且w

图1 奖惩闭环供应链结构图
根据图1模型做如下假设:
(1)再制造过程满足单位废品能够通过加工处理产生单位的再制造产品,例如对废旧汽车零部件、工程机械、机床等进行专业化修复。
(2)单位再制造产品的成本由单位废品的回收成本p0和单位再制造产品的加工成本c2构成,即为p0+c2。
(3)假定废品回收和再制造过程持续不断且周期足够快,再制造产品与新产品在质量上无明显差异,因此单位产品的平均成本c由单位再制造产品和单位新产品的生产成本按回收率组合而成:c=τ(p0+c2)+(1-τ)c1=c1+τp0-τΔ,Δ=c1-c2>0[18]。
(4)在完全理性决策和有限理性决策下,制造商都是领导者而零售商都是跟随者,并且在这两种决策情形中数量关系不变。例如产品零售价和废品回收率始终都是关于产品批发价的函数。
在产品销售过程中,主要考虑产品价格对需求量的影响,因此产品的需求函数如式(1)所示[11],制造商和零售商的利润函数如式(2)~(3)所示。
q=a-γp
(1)
πm(w)=(w-c1-τp0+τΔ)q
(2)
πr(p,τ)=(p-w)q+p0τq+k(τ-τ0)-ητ2/2
(3)
其中,γ为需求对价格的敏感系数,γ>0;πm和πr分别为制造商和零售商的利润。
闭环供应链中的各博弈主体最理想的决策状态是完全理性的,即彼此之间都掌握全部的市场信息,容易一步到位制定出各自的最优策略。但是现实中由于信息的不对称性,各博弈主体极难掌握决策所需的全部信息,只能依靠历史数据和经验等因素不断地进行策略调整,这种有限理性下制定的策略经过反复的调整将会无限逼近于完全理性下的最优策略。
笔者研究制造商和零售商权利不对等的Stackelberg博弈,制造商作为领导者先确定批发价w,零售商作为跟随者后确定零售价p和回收率τ,进而对比分析完全理性和有限理性决策情形下,闭环供应链博弈主体的最优策略及其演化轨迹。
2 完全理性下的策略分析
制造商和零售商作为完全理性的决策者,能够参照当前市场状况制定出各自的最优策略。以下命题中上标*表示最优策略。
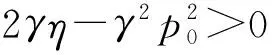
证明根据逆向求解法,πr(p,τ)关于p和τ的海塞矩阵为如式(4)所示[19]。
(4)


(5)
(6)
将式(1)、式(5)、式(6)带入式(2)中,同理得到当2γη(γΔp0-2η)<0时,存在唯一的最优批发价使得制造商利润最大,则有:
w*=
(7)
由式(5)~(7)得到最优零售价和最优回收率分别为:
(8)
(9)
至此,命题1证毕。
此时,制造商和零售商的最优利润分别如式(10)~(11)所示。
(10)
π*r=(p*-w*+p0τ*)(a-γp*)+
k(τ*-τ0)-ητ*2/2
(11)
由命题1可以得到推论1和推论2。

最优策略对奖惩标准τ0求偏导数能够得到推论1。推论1表明,政府调节奖惩标准并不能改变除零售商利润之外的其他最优策略值,在其他条件不变的情形下,政府提高奖惩标准会降低零售商利润,反之增加其利润。
最优策略对奖惩力度k求偏导数能够得到推论2。推论2表明,当政府提高奖惩力度时,零售商为了避免加重惩罚或者为了追求更多的奖励,都会积极主动地提高废品回收率。回收率的提高势必导致参与再制造废品数量的增多,又会引起生产成本的下降,从而导致零售价格的同步降低,此时对消费者有利。
命题1给出了制造商和零售商的最优策略,但是在现实博弈中最优策略一般需要博弈双方经过长期的试探和不断的策略调整才能达到。接下来,假定制造商和零售商都是有限理性的决策者,通过建立微分博弈模型分析博弈双方从初始状态逐渐收敛于均衡状态的过程,探究博弈系统稳定性的条件。
3 有限理性下的策略分析
以制造商为例,由于无法及时获取当前市场的全部决策信息,此处考虑根据自身前期的边际利润制定下一期的策略。当边际利润为正时,制造商会提高批发价格,反之则会降低批发价格。将式(5)和式(6)代入式(2),制造商利润关于批发价w的边际利润如式(12)所示。批发价格的动态调整过程如式(13)所示[20]。
(12)
(13)
其中,Δ″=
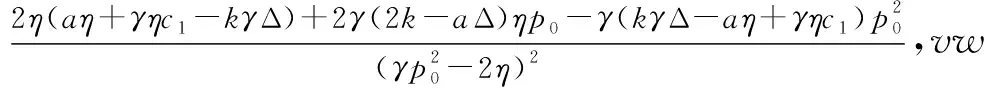
(14)
由式(14)可知,批发价格的变化是一个长期的迭代过程。根据∂πm(w)/∂w=0可以求得均衡批发价格为0或者w*,批发价为0不符合经济常理,所以仅考虑均衡批发价为w*的情况。由式(5)和式(6)能够得到均衡的p*和τ*,显然均衡价格(w*,p*,τ*)与完全理性下的最优策略相同,这也是有限理性下策略反复调整的终极目标。再由式(5)、式(6)和式(14)可以得到零售价p和回收率τ的策略动态调整过程。式(14)在均衡价格(w*,p*,τ*)处可线性化为式(15),特征根如式(16)所示。
(15)
(16)
由命题1中的条件可知λ<0,此时式(14)存在负的特征根,根据赫尔维茨定理可以确定式(14)是稳定的。同理,根据式(5)和式(6)可以得到关于p和τ的微分方程也是稳定的。稳定的博弈系统是分析价格策略调整的基础,只有在稳定的系统中价格博弈才容易达到均衡状态。
4 数值模拟分析
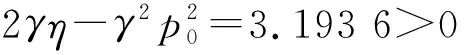
在有限理性下,迭代之后的均衡状态仍为(w*,p*,τ*),即制造商和零售商作为有限理性的决策者,批发价、零售价和废品回收率经过长期策略调整后会收敛于均衡状态(最优策略)。完全理性下的最优策略仅为博弈者提供了决策目标,没有展现决策过程,而有限理性下的决策调整过程将弥补这一不足。
经计算λ=-0.494 5<0,所以系统是稳定的。设初始批发价为w=0.8,从而得到初始零售价为p=1.316 4,初始回收率为τ=0.422 3。制造商和零售商经过201次迭代后,从博弈初态(0.8,1.316 4,0.422 3)收敛于均衡态(1.236 1,1.534 9,0.413 6)的时间序列如图2所示。

图2 有限理性下策略调整的时间序列图
由图2可知,制造商制定的批发价、零售商制定的零售价和废品回收率,尽管最初不是最佳的,但是随着策略的持续调整,最终会趋于均衡状态,即收敛于完全理性下的最优策略,此时制造商和零售商都实现了各自利润最大。
当批发价w取1.6时,其对应的博弈初态为(1.600 0,1.717 2,0.406 3)。此时系统分别从初始态1(0.800 0,1.316 4,0.422 3)和初始态2(1.600 0,1.717 2,0.406 3)开始进行价格博弈,经过长期策略调整后都将收敛于均衡态(1.236 1,1.534 9,0.413 6),如图3所示。

图3 不同博弈初态的策略演化轨迹
由图3可知,虽然制造商和零售商博弈的初始状态不同,但是只要博弈系统是稳定的,他们经过长期策略调整后都会达到策略的均衡状态,彼此不再进行策略的改变。这说明同质产品的初始销售价格虽然存在差异,且在市场博弈过程中价格涨跌不断,但经过长时间的试探和调整,产品价格整体上会达到一个相对稳定的状态。
5 结论
笔者在考虑政府对零售商奖惩的基础上,分析了完全理性下的闭环供应链最优策略,探究了奖惩力度和奖惩标准对最优策略的影响。在此基础上,进一步分析了有限理性下的闭环供应链策略动态调整过程,探讨了系统稳定情形下价格从不同博弈初态到最终收敛于均衡态的过程。对比分析了完全理性和有限理性两种情形下的策略变化关系。得到结论如下:
(1)提高奖惩标准对零售商不利,但制造商不受影响;提高奖惩力度对制造商、零售商和消费者都有利;稳定系统中,价格和回收率经过不断调整,最终都将收敛于均衡态,且与博弈初态无关。
(2)有限理性下,能够展现博弈主体的决策过程,并且在稳定的系统中,策略调整的终态与完全理性下的最优策略无限逼近。这表明,最优价格不能一蹴而就,而是需要综合各方面因素进行不断的价格调整、长期反复的价格试探。在稳定的市场中,波动的价格必定会趋于各方都能接受且相对稳定的结果,从而确保了各方的利润最大。
但是笔者仅考虑了政府对零售商的奖惩而没有涉及制造商,因此通过设计协调机制实现制造商和零售商奖惩的共享是未来的研究方向。
猜你喜欢
军民两用技术与产品(2022年3期)2022-06-05
纺织服装周刊(2022年16期)2022-05-11
物流科技(2022年2期)2022-05-07
数字技术与应用(2022年3期)2022-04-14
家庭教育报·教师论坛(2021年37期)2021-11-15
航天工业管理(2020年9期)2020-12-28
电子制作(2019年15期)2019-08-27
赤峰学院学报·哲学社会科学版(2016年12期)2017-03-20
中国大学教学(2015年7期)2015-09-06
环球时报(2009-12-29)2009-12-29
