
一种融合Bert预训练和BiLSTM的场景迁移情感分析研究*
2022-08-09 06:16杨秀璋宋籍文廖文婧任天舒刘建义
计算机时代 2022年8期
杨秀璋,宋籍文,武 帅,3,廖文婧,任天舒,刘建义
(1.贵州财经大学信息学院,贵州 贵阳 550025;2.贵州高速公路集团有限公司;3.涟水县财政局)
0 引言
随着微博、博客、网页新闻等领域的出现,网络舆情已成当下研究热点。现阶段表现较好的机器学习方法大都依赖于标注大量原始文本数据,再对测试数据进行处理,通常训练集和测试集均需来源于相同领域、平台或场景的数据。然而,这些方法较难对场景迁移或跨平台、跨领域的舆情事件进行情感分析研究,且迁移场景的舆情态势感知越来越重要。因此,如何高效地检测场景迁移和跨平台舆情事件的情感倾向和走势,将是未来研究重点,且能减少数据标注花费的精力,让模型具有更强的鲁棒性和准确性。
针对上述问题,本文提出一种融合Bert (Bidirectional Encoder Representations from Transformers)预训 练和BiLSTM(Bi-directional Long Short-Term Memory)的场景迁移情感分析模型,该模型能在少量数据标注的情况下,对未知类型进行预测并有效解决数据漂移问题。该模型将对微博舆情事件数据集进行训练,然后迁移预测知乎舆情事件的情感倾向,最终体现模型对迁移场景具有较好的鲁棒性和准确性。此外,本文通过详细的对比实验有效评估Bert-BiLSTM 模型的性能,这优于团队之前的相关工作,即对“巴黎圣母院火灾”舆情事件和“新冠肺炎疫情”舆情事件进行情感分析,并且该模型能应用于跨目标、跨领域、跨事件的舆情监测和情感分析。
1 相关研究现状
二十一世纪以来,情感分析作为自然语言处理领域的重要研究热点,在网络舆情、文本挖掘领域均有较为广泛的研究范畴。对网络舆情事件进行广义分析可分为两类,分别是基于统计机器学习的情感分析和基于深度学习的情感分析。
1.1 基于统计机器学习的情感分析
基于机器学习的情感分析主要通过对训练集数据选取特征进行词性标注训练,对测试集数据进行分类预测。根据机器学习方法的监督程度可分为监督学习、半监督学习和无监督学习。
车思琪等人在机器学习算法基础上整合情感词典对中美企业英文版致股东信进行分析,研究结果表明该模型准确率有效提升。杨立等人在传统机器学习模型基础上融合MLS需求概念模型,使得机器学习模型更好的适用于实际场景。戚天梅等人在传统机器学习算法基础上融合情感倾向计算方法,有效提升模型在情感倾向和强度计算方面的有效性。热西旦木·吐尔洪太等人针对维吾尔文网络信息不健全的问题,结合机器学习和词典方法的优缺点,构建LCUSCM 分类器模型,有效提升维吾尔文情感分析准确率。
虽然众多学者对传统机器学习方法进行不断优化,通过增加情感特征词典、情感特征提取与分类器组合等方法提升了机器学习方法的情感分析效果。但是,传统机器学习方法在对文本数据进行情感分析时,不能做到有效关联上下文语义信息,一定程度上还会造成歧义。
1.2 基于深度学习的情感分析
基于深度学习的情感分析一定程度弥补传统机器学习忽略上下文本关联性造成的缺陷。深度学习模型通过主动学习文本数据特征,在保留原文本词语关联性的前提下,结合上下文语境,有效地降低语义歧义,提升文本信息情感分析效果。
杨秀璋等人针对微博舆情事件情感分析缺乏深层次语义支持的现象,在深度学习TextCNN 模型基础上融入Attention 注意力机制,一定程度提升了对微博舆情事件的情感分析效果。孙嘉琪等人针对传统方法无法预测情感走势变化的现象,在现有深度学习模型基础上构建时间序列模型,提出ARIMA-GARCH模型,实验结果表明该模型能够有效预测投资者的情感走势,且误差较小。袁勋等人融合多层注意力机制开展方面级情感分析研究,构建的BMLA 模型能增强句子与方面词之间的长依赖关系,一定程度提升了传统模型的准确性。
虽然众多学者对深度学习模型进行不同程度上的优化,一定程度提高深度学习模型在进行情感分析时结果的准确性。但是,深度学习模型和监督学习的机器学习模型都必须建立在拥有准确的训练集数据的前提下。网络舆情分析的难题重点在于如何在不花费大量人力、时间的前提下,有效运用人工智能的方法实现对网络舆情信息的精准预测,尤其是对少样本标注的迁移场景进行情感分析。针对这一难点,本文提出了一种融合Bert预训练和BiLSTM 的情感分析算法,并从微博舆情事件数据集迁移到知乎舆情事件数据集的预测和分析,最终实现数据漂移和跨平台的舆情感知。整个迁移场景的情感分析任务用图1表示,图的上部分为传统情感分析任务,下部分为迁移场景的情感分析任务。
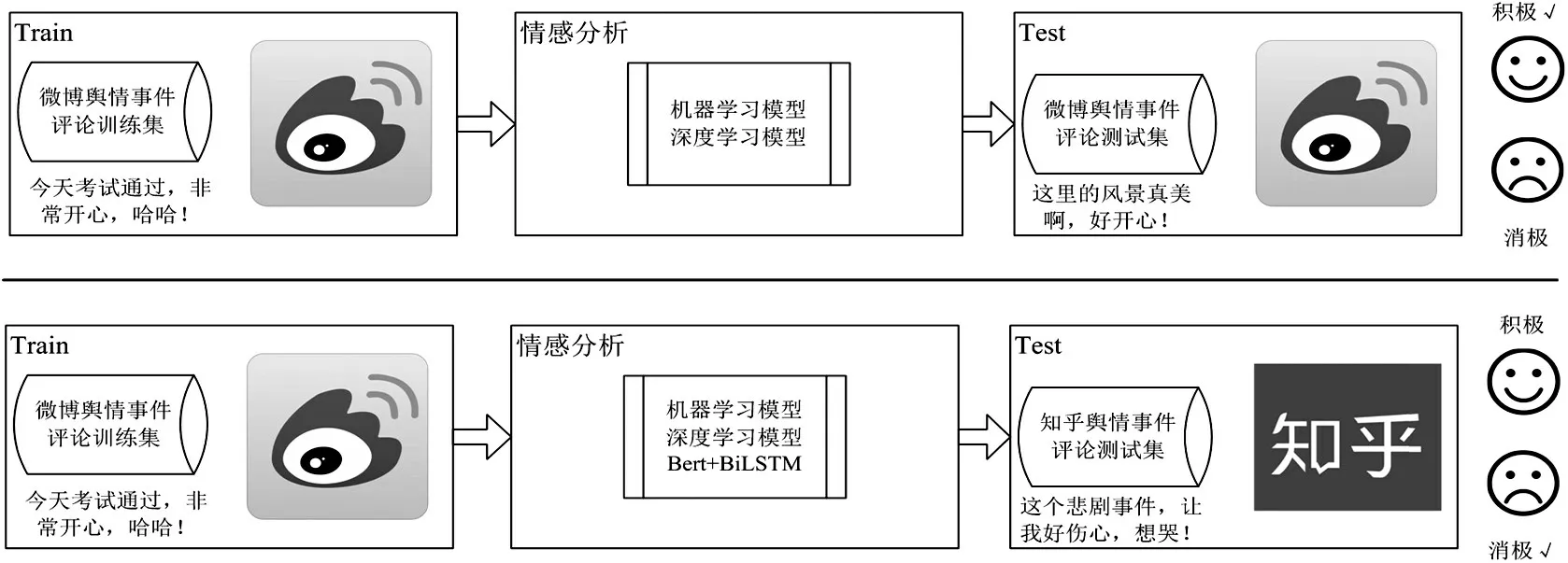
图1 场景迁移的舆情事件情感分析任务对比
2 模型设计
传统方法较难对迁移场景或跨平台、跨领域的舆情事件进行情感分析研究,并且迁移场景的舆情态势感知越来越重要。因此本文提出了一种融合Bert预训练和BiLSTM 的场景迁移情感分析模型,该方法能有效提升模型的鲁棒性,解决海量数据标注问题,并具有更好的适应性和实用性。
2.1 总体框架
本文设计并实现了Bert-BiLSTM-Attention 情感分析模型,整个模型的总体框架如图2 所示。该模型能对迁移场景或跨领域的舆情事件进行情感态势感知,具体实现步骤如下。
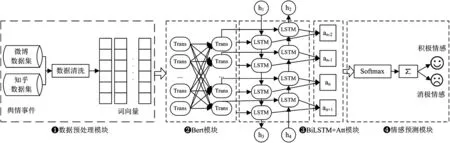
图2 迁移场景下舆情事件情感分析模型的总体框架图
通过Selenium 和Xpath 技术采集微博和知乎舆情事件的评论信息,并按照积极和消极两种情感进行标记,其中微博数据集作为训练,知乎数据集作为预测。接着进行数据清洗,包括中文分词、停用词过滤、特征提取等,并利用Word2Vec转换成词向量。
构建Bert 模型进行预训练,该模型能提取特征词在句子中的关系特征,即在多个不同层次提取关系特征,从而更好地反映情感句子语义知识。本文通过Bert 模型来预训练学习中文情感,为后续情感分析提供支撑。
构建BiLSTM 和注意力机制融合的模型,该模型通过BiLSTM 捕获长距离依赖关系,再通过注意力机制突出情感特征词的权重,从而更好地完成情感分类任务。
经过Bert 和BiLSTM+Att 情感分析模型处理后,接入Softmax 函数实现情感分类,最终实现对不同舆情事件的评论进行积极情感和消极情感的预测,动态感知大众的情感倾向。
2.2 Bert预训练模型
Bert 是一种预训练语义表征模型,由谷歌人工智能团队于2018 年提出。该模型通过融合文本表征能力强大的迁移学习(Transformer)模型实现,预训练能获得更好地向量表达。整个模型由输入层、编码层和输出层构成,其中输入层是{e,e,...,e}向量,编码层由多个Transformer组成,最终输出向量为{T,T,...,T}。
在Bert 模型中,预训练旨在提前训练好下游任务的底层知识,再用下游任务各领域样本数据来训练各种模型,从而加快模型的收敛速度,实现场景迁移。在自然语言处理任务中,为了更好地理解文档中的句子和特征词,更好地将他们转换成词向量,提升模型的泛化能力,因此利用Bert模型来完成语言表征,该方法优于传统的Word Embedding、ELMO、GPT 等。Bert 模型的输入表示包括Token、Segment、Position 三个嵌入层的叠加,分别对应单词、句子和位置信息,最终实现句子级别的表征任务。其中,输入向量E由三种不同向量对应元素叠加而成,每个句子第一个向量标志是[CLS],结束标志位[SEP]。通过该结构能为句子级别的情感分析构建句向量,位置向量P记录特征词所在的位置,计算公式如下:
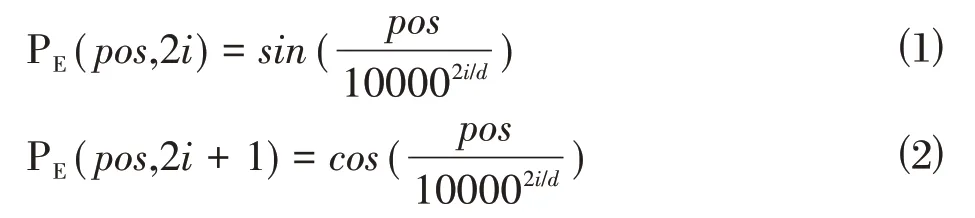
其中,pos 为特征词在句子中的位置,d 表示特征词向量的维度,P为输出位置向量,2i和2i+1表示词向量的偶数维度和奇数维度。
此外,在Bert 模型中,Transformer 编码器是由自注意力机制和前馈神经网络组成,能更好地解决自然语言处理任务中的长依赖问题。其方法是将输入句子中的每一个特征词都和句中的所有词做Attention计算,从而提取特征词之间的依赖关系,整个计算过程用公式⑶表示。
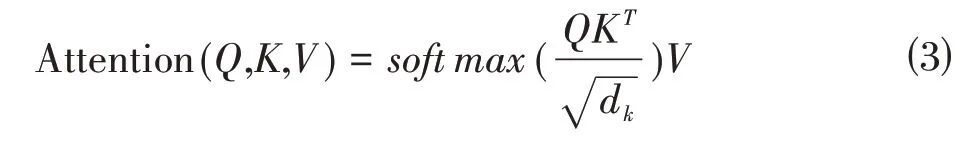
其中,Q、K 和V 分别表示Query 向量、Key 向量和Value 向量,对应编码器的输入字向量矩阵,d为输入向量的维度。最终,通过Bert 模型实现了对舆情事件评论的预训练提取。
2.3 BiLSTM模型
BiLSTM 模型作为一种经典的循环神经网络,由记忆单元和门(gate)结构组成。该模型从前后两个方向提取特征,从而捕获长距离依赖关系及上下文语义特征。本文将它至于Bert 模型和注意力机制模型之间,从而提取微博和知乎舆情事件评论的情感特征,并实现情感分类任务。
BiLSTM 模型网络结构可以通过公式⑷至公式⑹表示。其中,公式⑷表示t 时刻前向LSTM 层的状态,公式⑸表示t时刻后向LSTM 层的状态,x对应输入向量,w表示对应的权重,f 表示激活函数,最终BiLSTM输出的向量为y。
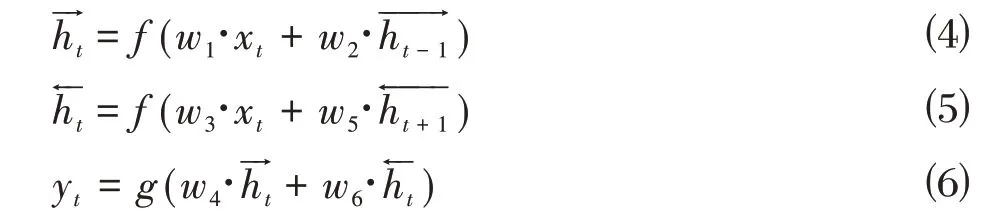
通过BiLSTM 模型能有效捕获评论句子的长距离依赖关系,比如常见的情感特征词“开心”和“真好玩”表示积极情感,“伤心”和“哭泣”表示消级情感,而传统模型无法较好识别这些距离较长的特征词语义关系。最后,将BiLSTM 模型得到的输出向量传递至注意力机制,并接Softmax 实现情感分类,最终预测知乎舆情事件的积极和消极情感。
3 实验与分析
为验证本文模型在迁移场景的情感分析效果,本文构建了包含微博和知乎两类典型社交平台的舆情事件评论数据集,每类数据集包含积极和消极情绪,并进行对比实验。在实验过程中,通过Python3.7构建不同的情感分析模型,利用TensorFlow、Keras 构建深度学习模型,Sklearn 构建机器学习模型。编程环境为Anaconda,处理器为Inter(R) Core i7-8700K,GPU 为GTX 1080Ti。
3.1 数据集和数据预处理
在对舆情事件的情感分析中,社交媒体产生的评论数据将有助于研究者分析大众的情感倾向,感知舆情事件的情感走向。本文通过Selenium 和Xpath 技术采集微博和知乎两种典型社交媒体在2021 年的舆情事件评论信息,包括积极情感和消极情感。例如,舆情事件涉及:庆祝中国共产党成立100周年,神舟十三号成功发射,东京奥运会,EDG 夺冠,孟晚舟归国,云南大象迁徙,河南暴雨灾害,清朗饭圈乱象治理等事件。
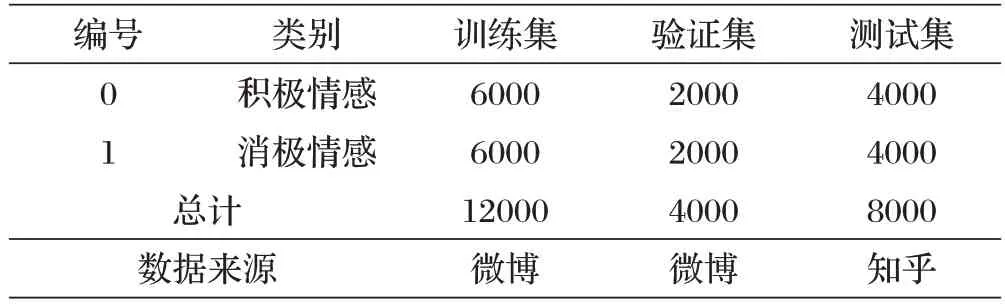
表1 舆情事件评论数据集
本文将采集的数据集进行数据预处理,包括中文分词、停用词过滤、特殊字符清洗、情感特征词提取和权重计算等。最后将数据集随机划分为训练集、验证集和测试集,其中训练集和验证集是来自微博的舆情事件评论信息,积极情感和消极情感的训练集各6000条,验证集各2000 条;测试集是来自知乎的舆情事件评论信息,积极情感和消极情感各4000条。
为更好地学习舆情事件的情感态势,需要分别对不同模型进行参数预设,模型超参数设置如表2所示,其中Bert 算法的预训练模型采用中文“Chinese_L-12_H-768_A-12”。此外,为避免某些异常实验结果的影响,本文最终的实验结果为十次结果的平均值。
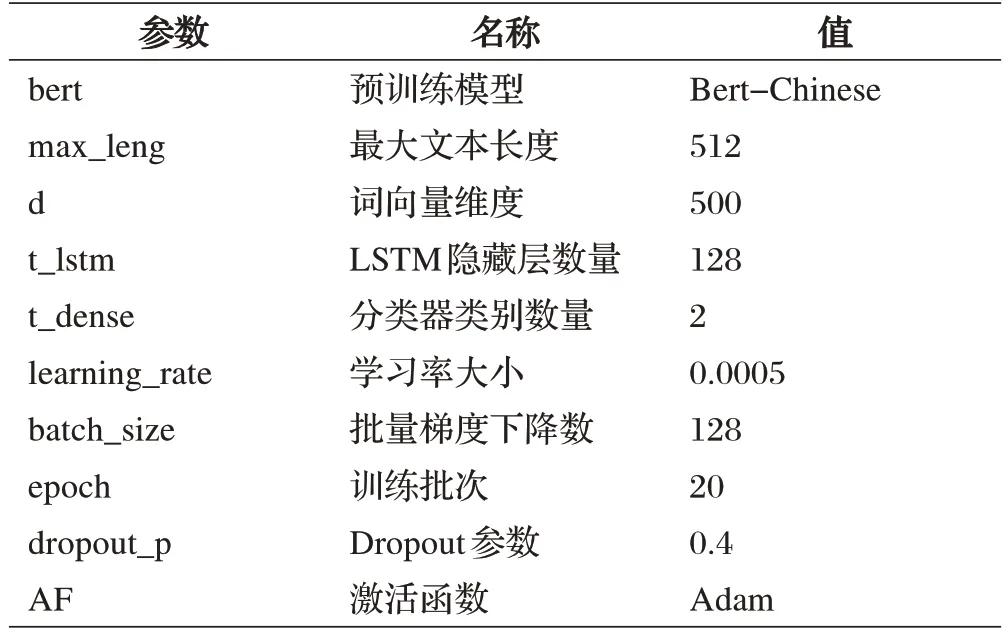
表2 模型超参数
3.2 评价指标
本文将舆情事件评论数据集划分为积极情感(类别为0)和消极情感(类别为1)。其中,真阳性(True Positive,TP)表示评论的预测情感和真实情感都是积极的;真阴性(True Negative,TN)表示评论的预测情感和真实情感都是消极的;假阳性(False Positive,FP)表示将消极情感预测为积极情感;假阴性(False Negative,FN)表示将积极情感预测为消极。接着采用精确率(Precision)、召回率(Recall)、F值(F-score)和准确率(Accuracy)对舆情事件进行情感分析评价,计算过程如公式⑺至⑽所示。

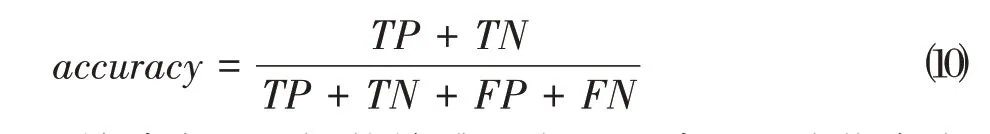
其中,精确率用于评估情感分类被正确预测为指定类别占所预测类别评论数量的百分比,召回率用于评估情感分类被正确预测占该类别情感评论数量的百分比,F值综合了精确率和召回率,是两者的加权调和平均值,常与准确率用于评估模型的质量。
3.3 实验对比
传统深度学习和机器学习算法较难对跨场景或跨平台的舆情事件进行情感分析,其鲁棒性较差,对此本文提出一种融合Bert预训练和BiLSTM 的微博评论情感分析算法。该算法对微博舆情事件数据集进行训练,然后迁移预测知乎舆情事件的情感倾向。本文详细对比了各种经典模型,其中机器学习模型包括决策树(DT)、SVM、逻辑回归(LR)、随机森林(RF)和AdaBoost,深度学习模型包括卷积神经网络(CNN)、双向长短时记忆网络(BiLSTM)和本文模型。
整个实验结果如表3所示,本文融合Bert和BiLSTM模型的精确率为0.8181,召回率为0.8199,F值为0.8190,准确率为0.8181。通过对比发现,本文方法F值和精确率均高于其他方法,这表明Bert 模型能有效地对跨平台(微博和知乎)的舆情事件进行情感分析,BiLSTM能有效捕获长距离依赖特征。同时,为更好地对比微博和知乎舆情事件情感分析的效果,评估本文融合Bert预训练和BiLSTM的微博评论情感分析算法,我们对积极情感和消极情感进行了详细的对比实验。其中,图3为迁移场景情感分析积极情感的实验结果,机器学习表现较好的逻辑回归算法的F值为0.6402,CNN 的F值为0.7189,BiLSTM 的F1 值为0.7218,本文方法的F1 值为0.8246,均提升10%以上,说明本文方法能迁移到更多场景和平台的舆情分析中,其鲁棒性和准确性均较好。
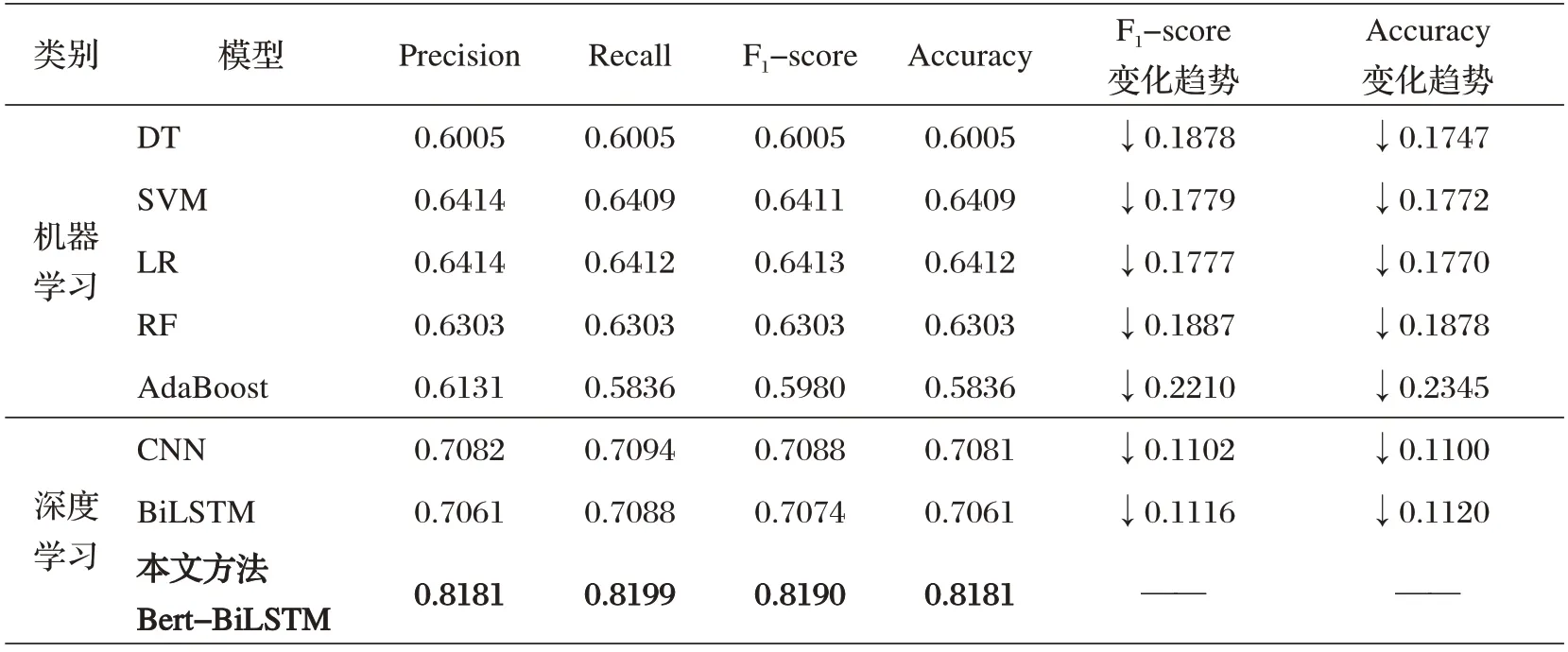
表3 各模型迁移场景的情感分析实验结果对比
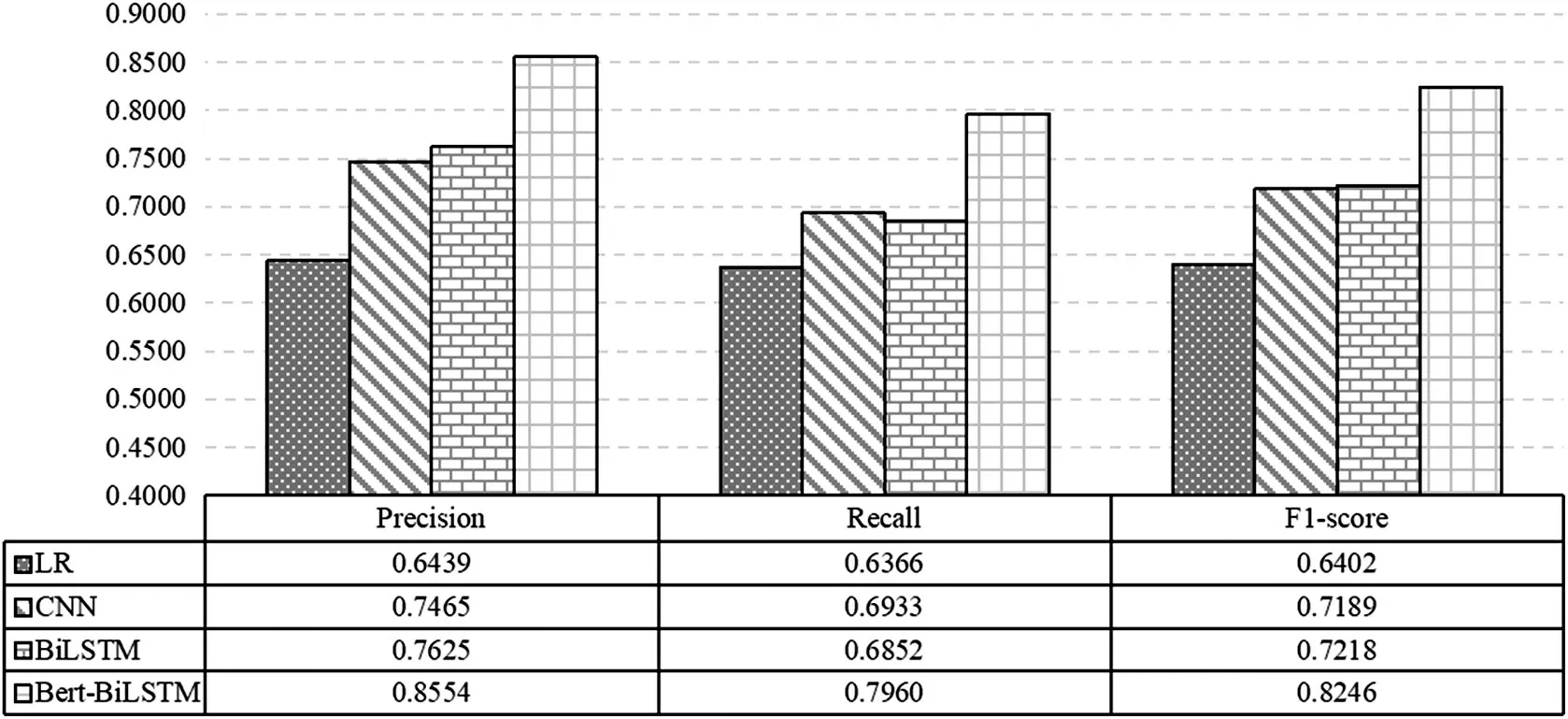
图3 迁移场景情感分析积极情感的实验结果对比
为突出本文融合Bert预训练和BiLSTM 的微博评论情感分析算法,本文对积极情感和消极情感进行了详细的对比实验。对比了深度学习模型对知乎舆情事件评论情感分析的混淆矩阵。其中,图4(a)为CNN模型,正确预测积极情感评论29859条、消极情感评论26791 条;图4(b)为BiLSTM 模型,正确预测积极情感评论30500 条、消极情感评论25985 条;图4(c)为本文模型,正确预测积极情感评论34216条、消极情感评论31230 条。说明本文方法能迁移到更多场景和平台的舆情分析中,其鲁棒性和准确性均较好。
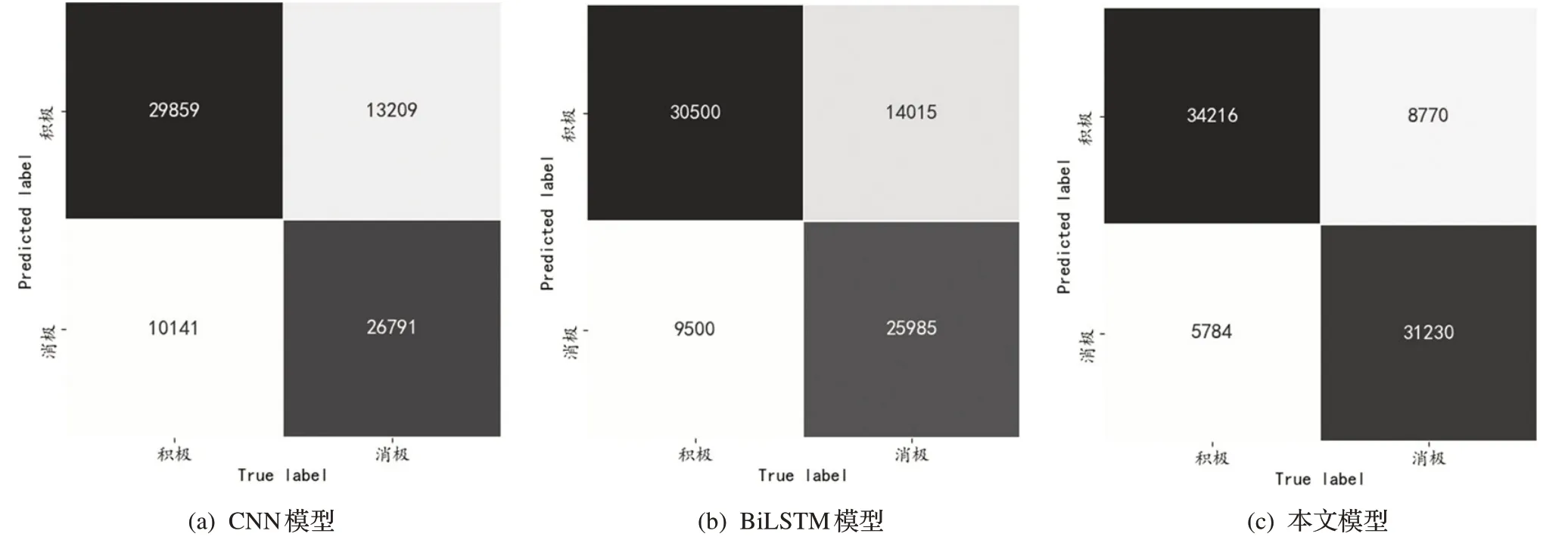
图4 各深度学习模型混淆矩阵对比
4 结束语
针对传统机器学习和深度学习模型较难解决场景迁移和跨领域舆情事件的情感分析问题,无法精准捕获长距离依赖关系和语义特征,以及过度依赖数据标注等问题,本文提出了一种融合Bert 预训练和BiLSTM 的场景迁移情感分析模型,旨在实现对跨社交平台的舆情事件进行情感分析研究。该模型包括四个模块,首先对微博和知乎社交媒体的舆情事件评论进行数据采集及预处理;其次,构建预训练模型Bert来提取及表征文本的词向量;然后构建融合BiLSTM和注意力机制的情感分析模型,捕获长距离依赖关系和语义特征;最后,构建Softmax 实现情感分析,预测知乎舆情事件的积极情感和消极情感。
实验结果表明,本文能有效实现跨场景和平台迁移的情感分析任务,其精确率为0.8181,召回率为0.8199,F值为0.8190,准确率为0.8181。通过对比发现,本文方法的性能均高于其他方法,本文方法的F值比DT、SVM、LR、RF 和AdaBoost 机器学习方法分别提升0.1878、0.1779、0.1777、0.1887 和0.2210,比CNN、BiLSTM 深度学习方法分别提升0.1102 和0.1116。这表明Bert 模型能有效地对跨平台(微博和知乎)的舆情事件进行情感分析,BiLSTM 能有效捕获长距离依赖特征。综上,本文方法能应用于场景迁移和跨社交媒体的情感分析任务,具有较好的鲁棒性和准确率,并能有效感知大众对舆情事件的情感走势,具有一定的应用前景和实用价值。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国生殖健康(2020年5期)2021-01-18
北极光(2019年12期)2020-01-18
小太阳画报(2019年10期)2019-11-04
中国生殖健康(2018年5期)2018-11-06
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
高中生学习·高三版(2016年9期)2016-05-14
中国民政(2016年24期)2016-02-11
