
基于LSTM的Linux系统下APT攻击检测研究
2022-08-08 01:35时绍森文伟平
信息安全研究 2022年8期
时 林 时绍森 文伟平
(北京大学软件与微电子学院 北京 102600)
随着网络逐渐渗透到人们生活的方方面面,网络空间的安全问题也逐渐被重视起来.网络中的攻击手段多种多样,高级持续威胁(advanced persistent threat, APT)攻击为其中较为复杂并且危害性较高的一种.APT攻击过程贯穿系统外部与系统内部,且持续性很强,因此难以进行检测与彻底防御,需要得到更多的关注.近年来,全球APT组织持续增多,攻击涉及金融、政府、教育、科研等重点行业[1-2].到2021年上半年[3],APT攻击整体形势严峻,发现和披露的APT攻击活动较2020年同期大幅增加.
APT攻击周期一般较长,在长期且持续的攻击下,攻击者会将多种攻击方式进行组合并调整,导致防护系统无法对经过精心处理的攻击特征完成规则匹配,最终导致目标机器遭到入侵.目前,大多数IDS系统仅具有单步攻击的检测能力,并没有将持续性的攻击联系起来,且检测内容往往局限于网络流量,如鱼叉攻击、XSS、SQL注入等.一些APT攻击监控系统使用IDS的告警日志进行攻击判定.报警日志往往具有一定比例的误报,判定的攻击行为并不准确.更重要的是,仅检测流量往往会忽略完整的APT攻击过程,APT攻击攻入系统后,会进一步释放控制机器的恶意代码,导致主机系统发生大量攻击.因此,将主机内的攻击行为与网络流量中的攻击行为相结合,共同作为APT攻击的判断条件是十分必要的,并且对于APT攻击检测而言,主机内的恶意行为非常重要.
目前,针对Windows系统的入侵检测系统与沙箱系统较多,而针对Linux系统攻击的分析与防御措施较为薄弱.很多恶意代码检测分析工具与防火墙都是针对Windows系统的,侧重于Linux系统的恶意文件检测手段较少.例如,开源的Cuckoo沙箱、商用的腾讯微步沙箱、奇安信文件分析平台等对Windows恶意文件的检测较为成熟,但是对于Linux平台上的恶意文件缺乏检测能力.因此针对Linux系统的APT攻击检测亟待解决.此外,目前业内普遍用于研究的攻击数据也只局限于网络流量数据或某些APT攻击释放的恶意文件,并不具有很强的关联性.APT攻击持续时间长、攻击步骤繁多的特点导致APT攻击样本并不丰富,目前还没有形成一套科学的数据集供广大安全从业人员进行研究.
针对以上问题和研究现状,本文提出并实现了一种基于LSTM(long short-term memory)的Linux系统下APT攻击检测方案.该方案综合了主机侧与网络侧的双侧行为特征,将特征数据集依据APT攻击的生命周期进行建模重构,进而使用LSTM进行训练,得到了检测效果良好的APT攻击检测模型.
本文主要贡献如下:
1) 捕获恶意Linux ELF文件行为的LAnalysis沙箱.
构建了一款能力较强的分析Linux ELF文件的LAnalysis沙箱,通过对相关内核函数以及系统调用函数的针对性内核插桩,LAnalysis可以获取恶意代码的持久化、隐藏与伪装、权限提升、进程注入等10类共16种不同的恶意行为.
2) 符合APT攻击生命周期的数据集.
使用LAnalyise沙箱分析了500个恶意家族的共4 101个恶意样本.获取了恶意样本的主机侧攻击行为特征,构建了Linux主机侧的攻击数据集,并结合网络侧数据集NSL-KDD按照APT攻击生命周期,构建了一套兼具主机行为和网络行为特征的APT攻击数据集.
3) 基于LSTM的APT攻击检测模型.
将符合APT生命周期的数据集放入注重时序性特征的LSTM进行训练,其中包含网络与主机双侧特征,得到了可以检测APT攻击的深度学习模型,并取得了良好的应用效果.
1 相关工作
APT攻击生命周期较长,各种攻击行为之间具有一定的关联性,这给检测带来很大挑战.目前的检测手段主要分为侧重于主机侧APT攻击部署的恶意代码的检测、侧重于网络侧恶意流量分析的检测以及将多步攻击相结合的注重攻击关联性分析的检测等.
主机侧恶意代码检测主要是对APT攻击释放的木马[4]或后门等文件进行检测.当前针对可疑恶意程序的分析方法主要为动态分析与静态分析[5].冯学伟等人[6]利用恶意代码中使用的IP地址之间的联系进行聚类;霍彦宇[7]将分析恶意代码时产生的行为警报信息处理为特征,使用聚类的方法进行分类识别;Sharma等人[8]提出一种入侵检测框架,使用6个监视器监视系统中的行为,统计4天中各个文件的更改情况以及进程数据作为正常情况后续进行状态检测,若文件与进程数据出现异常就会发出威胁告警;Moon等人[9]提出一种基于主机中发生行为的攻击检测方法,通过捕获主机中39种特定行为的发生作为特征对APT攻击进行检测;孙增等人[10]提出基于沙箱回避对抗的相关检测方法,统计了常见沙箱中使用系统的各种特征,在代码运行前查找所运行系统的相关特征,进而判别当前软件是否在沙箱中运行.
网络侧恶意流量分析检测是对流量中的信息进行特征提取[11],利用这些特征通过规则匹配或机器学习与深度学习训练模型等方式判定是否为异常流量.攻击者通过系统中运行的Web服务进行入侵,或从已经完成入侵的系统中横向移动至其他系统,在此期间都会产生大量的异常流量.因此检测相关攻击可以从异常流量入手.戴震等人[12]通过流量分析发现恶意软件的远端控制服务器对其进行指令发送的过程具有一致性,进而通过解析报文的通信特征对攻击进行判定;Chuan等人[13]通过结合机器学习模型形成了一种集成学习器对URL中的特征进行分析与提取,对具有恶意风险的网站进行识别;Liu等人[14]通过对数据集NSL-KDD进行处理形成了一套新的网络攻击数据集,使用DBN网络降维后通过SVD模型对可疑数据进行识别与分类.APT攻击流量检测中还有一部分是通过域名检测来判定恶意流量的.Vinayakumar等人[15]收集了网上公开的恶意域名数据集,并在系统中收集了DNS日志,在合并处理后采用LSTM进行检测;Niu等人[16]针对移动端的DNS日志进行C2域名检测.
攻击关联性分析检测更加注重对APT攻击之间关联性的分析与建模.Bahrami等人[17]利用杀伤链模型对APT攻击场景进行建模,该模型将APT攻击分解为40多项子活动,并确定了APT攻击中的行为特征,进而进行攻击检测;Kim等人[18]对杀伤链模型进行了改进与细化,主要用于对IOT网络的APT攻击进行检测;Zhou等人[19]通过对移动目标进行防护来处理APT攻击中的路径突变问题;Jasiul等人[20]和杜镇宇等人[21]设计了不同的基于Petri网的攻击检测模型,文献[20]使用主机内的系统特征与文件特征生成了有色Petri网,利用其对恶意软件中的恶意行为进行建模,文献[21]中的模型通过匹配攻击路径,并根据收集到的报警信息对攻击行为进行预测;Ghafir等人[22]将属于一个完整APT攻击的不同子攻击活动的检测结果进行关联,通过HMM对其解码,确定最有可能的攻击序列;Niu等人[23]使用动态步骤图对APT攻击进行映射,建立网络攻击模型捕获APT攻击因素;孙文新[24]提出了因果场景生成算法,将相关流量以及对应的攻击步骤匹配至杀伤链模型中,发掘流量数据之间的相关性.
通过对以上APT攻击检测方法的研究发现,目前的检测方法存在若干问题,包括对APT攻击中单个攻击之间的时序性结合关注度不高;针对Linux系统中恶意软件的检测与行为捕获工具较少,且已有工具效果较差;由于APT攻击周期过长导致业内对于APT攻击的高质量数据集较少等.
2 Linux系统下APT攻击原始数据集的构建
高质量的APT攻击数据集是构建APT攻击检测模型的关键.本文构建的原始数据集融合了APT攻击的主机侧与网络侧双侧特征,为后续生成APT攻击数据集提供了良好基础.构建Linux主机攻击行为捕获沙箱LAnalysis,利用其分析Linux ELF恶意文件生成主机侧初始数据集,对网络公开数据集NSL-KDD进行处理,生成网络侧初始数据集.
2.1 沙箱LAnalysis
目前常用的开源沙箱以及众多商用和在线文件分析平台针对Linux ELF文件的恶意代码样本分析能力较弱,以致无法获取恶意样本的全部恶意行为.本文构建了一款能力较强的分析Linux ELF文件的沙箱LAnalysis,针对APT攻击中使用的恶意代码进行分析,进而构建APT攻击中的主机行为数据集.
LAnalysis为C/S架构,分为服务端(监控端)与客户端(被监控端)2部分.检测方式为服务端将样本发送至客户端,对目标样本进行检测,检测完后将检测报告进行回传,服务端将检测报告进行分类处理,形成不同类恶意行为的特征文件.系统结构如图1所示:

图1 LAnalysis架构
服务端分为通信层、分析层、控制层共3层.控制层依据用户传递过来的指令启动沙箱工作,并且通过命令执行的方式对沙箱进行控制;通信层负责收集和处理另一端发来的消息并进行下一步流程的推进;分析层对客户端发来的分析样本的行为报告以及流量进行处理与分析,进一步提取出该样本的恶意行为特征.
客户端由一个沙箱虚拟机组成,沙箱分为通信层、检测层与对抗层共3层.检测层负责部署沙箱检测模块,对目标样本进行行为分析;通信层负责与服务端的沟通并将分析结果回传给服务端;对抗层负责部署沙箱自我保护模块与规避行为检测模块,对恶意样本进行检测并与破坏沙箱的行为进行对抗.
LAnalyisis获取恶意代码的10类共16种不同的恶意行为,在检测与分析APT攻击中部署的恶意Linux ELF文件的恶意行为上表现更为出色.
2.2 Linux ELF恶意文件行为捕获与检测
LAnalysis对恶意代码的10类恶意行为进行捕获,用于构建主机行为数据集.具体为反调试行为、迟滞代码行为、持久化行为、文件隐藏行为、网络隐藏行为、进程隐藏行为、网络行为、权限提升行为、进程注入行为、对系统的窥探行为.捕获行为的选择来自攻击框架ATT&CK中常用的攻击行为.
恶意行为的捕获与检测主要依赖于LAnalysis的检测层,它运行在沙箱内部,部署沙箱监控的各个模块以检测目标样本的各类恶意行为,是整个沙箱系统的核心检测层,由SystemTap编写的8个恶意行为检测模块构成,分别为文件主动探测模块、迟滞代码检测模块、反调试检测模块、隐藏行为检测模块、进程注入检测模块、持久化检测模块、窥探行为检测模块、进程追踪模块. 除此之外还有为了防止沙箱被破坏所构建的沙箱自我保护模块.另外,还有一些恶意行为的检测不是通过SystemTap部署内核探针完成的,而是通过恶意代码运行前后系统发生的变化进行检测.
2.3 APT攻击数据集构建
在APT攻击中,主机攻击指攻击者通过各种方式入侵受害者的主机系统,在主机系统中植入恶意代码,进而产生对受害者主机的控制与破坏行为.网络侧攻击指在进入主机前在网络空间中进行的流量攻击或建立C2通道远程操控进行攻击的手段.
2.3.1 APT攻击主机行为数据集的构建
通过对大量不同恶意家族中恶意样本的分析,获取其在Linux主机上产生的恶意行为,将其构建为APT攻击的主机行为数据集.通过对无害良性样本进行分析,提取与恶意样本同样的特征,作为正常主机行为特征,为构建非APT攻击数据集提供原数据基础.另外,为了方便生成APT攻击样本数据,需要将主机行为数据集进行标签化处理.
2.3.2 APT攻击流量数据集的处理
本文选用的流量数据集为NSL-KDD. NSL-KDD是入侵检测领域的一个经典数据集,其每条数据均由41种特征组合而成,每个网络连接被标记为normal或attack.本文使用NSL-KDD作为APT攻击网络攻击数据集的原始数据集,其中attack表示攻击数据,共有4大类,这4大类又被细分为22种不同的攻击,共有125 973条数据.为了适应深度学习模型的训练,通过one_hot对数据进行编码.对数据集进行维度处理后,还需要将数据和标签进行分离,同时将同一类标签的数据进行归类,以生成APT攻击流量数据集.
3 基于LSTM的APT攻击检测方案
3.1 总体设计
APT攻击检测方案分为3个部分,分别为原始数据集生成模块、APT攻击数据集生成模块、模型构建模块.总体设计图如图2所示.
1) 原始数据集生成模块.
在原始数据集生成模块中,构建了沙箱LAnalysis并对采集的恶意样本与良性样本进行分析,形成APT攻击的主机行为数据集;同时使用NSL-KDD作为APT攻击的网络流量初始数据集.
2) APT攻击数据集生成模块.
APT攻击数据集生成模块用于将网络行为数据集与主机行为数据集根据APT攻击的攻击流程进行合并重构,将各种单独的攻击方式组合成具有前后上下文关联的APT攻击,生成APT攻击数据集.同时,还需要生成非APT攻击数据集作为深度学习模型训练的负样本.
3) LSTM模型构建模块.
利用生成的APT攻击数据集与非APT攻击数据集构建基于LSTM的APT攻击检测模型.

图2 APT攻击检测方案总体设计图
3.2 APT攻击数据的生成
在APT攻击数据生成前首先要针对APT攻击过程进行攻击步骤拆分与建模,之后使用网络行为数据集与主机行为数据集中的子攻击标签组成APT攻击标签序列,形成符合APT攻击生命周期的攻击数据.
3.2.1 攻击过程建模
根据Hutchins等人[25]提出的网络攻击杀伤链分析模型(Cyber Kill Chain)可知,1次APT攻击分多个具体的攻击步骤.因此将网络侧行为数据与主机侧行为数据依据APT攻击过程进行建模是生成APT攻击数据的关键.由于APT攻击方式多种多样,每次攻击都可能有不同的战术变化,本文只选用最经典的3种APT攻击方式进行模拟.
这3种最经典的APT攻击方式是:钓鱼攻击、利用Web漏洞与操作系统漏洞入侵、利用线下移动设备入侵.3种攻击方式都包含相似的必要攻击步骤,但是在感染主机和感染后的行为上略有不同.例如,钓鱼攻击通常没有针对Web的攻击行为,但会有可疑的网络流量出现,若被攻击者成功执行钓鱼程序,则其可以直接以被攻击者的权限运行,有时不需要进一步提升权限.利用Web漏洞与操作系统漏洞的攻击方式往往有较多的网络攻击流量,且攻入系统后有权限提升行为.利用线下移动设备入侵没有任何网络攻击流量,直接利用U盘、移动硬盘等通过植入恶意代码进行攻击,但是在入侵后具有与控制服务器交互的行为,会产生网络流量.
1) 通过网页或邮件等进行钓鱼攻击.
由于被攻击者安全意识不强,误执行了攻击者发送的邮件或网页链接的不可信内容,以致主机被感染后遭受到一系列攻击行为.该种攻击方式的攻击过程如表1所示.

表1 钓鱼攻击流程
2) 利用Web漏洞与操作系统漏洞进行入侵.
利用运行的Web漏洞或开放的高危端口对应的系统漏洞,通过网络入侵进入主机后,进一步部署恶意代码进行针对主机的攻击.该种攻击方式的攻击过程如表2所示.

表2 利用Web漏洞与操作系统漏洞进行入侵
3) 利用线下移动设备入侵.
以便携式的移动设备进行攻击,如移动硬盘、U盘、手机等设备接入主机,可以直接进行植入式攻击.该种攻击方式的攻击过程如表3所示:

表3 利用线下移动设备入侵
3.2.2 攻击序列标签生成
在对APT攻击行为进行建模后,使用网络行为数据标签与主机行为数据标签针对这3类攻击的攻击过程进行对应,形成APT攻击的标签序列可以通过变更标签中的不同样本,生成大量不同的APT攻击样本.表4~6分别为3种APT攻击方式对应的攻击标签.
在生成APT攻击数据时,由于真正的攻击步骤在时间上不可能是完全连续的,各个步骤之间会有不可估计的时间间隔,因此需要在表4~6中的步骤之间穿插一系列的非攻击操作.在实际生成APT攻击数据集时,在表4~6中的各个步骤间,选择在随机位置插入随机数量的标签为normal的数据,表示网络行为中的正常行为与主机行为中的正常行为.同时每个标签都对应较多不同样本,保证了APT攻击数据集中数据的丰富性.

表4 钓鱼攻击流程的攻击标签

表5 利用Web漏洞与操作系统漏洞进行入侵的攻击标签

表6 利用线下移动设备入侵的攻击标签

图3 1条APT攻击数据构成
3.2.3 依据标签生成APT攻击数据
在生成的APT攻击数据中每个步骤都会有主机行为和网络行为与之对应,APT攻击的每个时间步的数据由网络行为与主机行为合并而成,表示当前步骤中的网络状态与主机状态.特征处理方面,表示网络状态的特征为122维,即1个NSL-KDD数据标签表示当前的网络情况.主机行为特征由1个或多个当前步骤中的不同主机攻击行为随机组合而成.由于每种不同的主机攻击行为在89维中都有自己固定的位置,因此组合后不会造成互相的覆盖,而是会将各自的特征保留下来,没有融合进来的其余位置都用0进行补齐,表示当前步骤中没有类似的行为.因此1个或多个主机攻击行为标签最终会组合成89维的主机行为特征.1个步骤有网络行为数据集的122维加上主机行为数据集的89维共211维特征.而1条APT攻击数据就是由多个时间步的行为按照攻击方式对应的标签顺序排列而成.
1条APT攻击数据的生成过程如图3所示,每条数据都由若干个时间步构成,表示每次攻击中的攻击步骤,而每个时间步有211维特征,由网络侧特征与主机侧特征组合而成.利用线下移动设备入侵行为中的第7个攻击步骤的1个时间步构成如图4所示,其网络行为数据标签为rootkit,主机侧特征由恶意行为特征集file_hide和process_inject中随机选取1种组合而成.

图4 1个时间步构成示例
3.3 非APT攻击数据的生成
APT攻击数据集在最终模型的数据集中使用标签1进行对应,表示正样本集,还需生成非APT攻击数据作为负样本集,用标签0与之对应.网络特征部分使用NSL-KDD中标签normal的样本,总共为122维特征.主机行为的正常行为样本在创建时就没有按攻击行为进行拆分,整个89维的标签normal的样本就是当前时刻正常的主机行为,因此从中随机选取进行利用即可.将主机行为数据和网络行为数据进行组合形成211维的当前步骤下的单步非APT攻击数据.
使用单步非APT攻击数据生成1条完整的非APT攻击数据的方式共有2种:第1种由标签为normal的网络单步数据与主机单步数据组成,这样得到的数据为完全正常的行为序列;第2种是在APT攻击的3种入侵方式中只生成某步骤之前的攻击序列,代表攻击的中止与失败,该条数据也为非APT攻击数据,为了与攻击数据有一定的区分度,截取的步骤为整体步骤的前2/3处,不会从接近攻击结束的地方进行截取.
3.4 基于LSTM的APT攻击检测模型构建
基于构建出的APT攻击数据集与非APT攻击数据集,使用LSTM进行训练,训练过程分为以下几个步骤:数据集划分与处理、模型初步训练、调参优化.生成参数最优的APT攻击检测模型.整体流程如图5所示:

图5 APT攻击检测模型训练过程
1) 数据集划分与处理.
首先对输入模型的数据进行时序划分处理,使用LSTM进行模型训练时,3个较为关键的可以体现时序特征的参数为单个数据维度、时间步长度与最大数据长度.本文单个数据维度为122+89=211维,表示当前步骤的网络状态与主机状态,最长数据由40个时间步构成,因此最大数据长度为40×211=8 440.为了输入数据的长短一致,将所有数据的长度补齐至8 440.
本文共生成16 000条APT攻击数据与16 000条非APT攻击数据,将训练集与测试集按照3∶1进行划分,则训练集共有12 000条正样本数据与12 000条负样本数据,测试集共有4 000条正样本数据与4 000条负样本数据.
2) 模型的调参优化.
针对LSTM的learn_rate,batch_size以及epoch这3个参数进行优化,比较取何值时模型的表现最好.batch_size是单批次训练数据的大小,影响训练时间与训练速度.epoch为训练的轮数,值越大训练的时间就越长,随着epoch的增大损失函数会逐渐收敛,此时模型趋于稳定,因此需要找到合适的epoch值.learn_rate是1个相对重要的超参数,其取值会影响模型最终的准确率.
3) 模型评价标准.
APT攻击检测是一个二分类问题,模型的预测出的结果只有1和0这2种取值.本文采用准确率、精确率、召回率和F1值这4个深度学习与机器学习中较为常用的指标衡量模型的优劣程度.
4 测试与结果分析
4.1 测试环境
4.1.1 LAnalysis实现环境
LAnalysis分为服务端与客户端,都是基于Python3进行开发,同时还使用了shell脚本、SystemTap脚本进行相关功能的实现.服务端与客户端采用虚拟机嵌套的方式运行,服务端使用主机系统中的VMware创建,客户端使用服务端系统中的VirtualBox创建.具体环境参数如表7所示:

表7 LAnalysis环境参数
4.1.2 LSTM构建环境
LSTM的构建环境为Linux操作系统,主要使用Python进行开发.神经网络模型开发框架使用开源的Keras框架.具体环境参数如表8所示.
4.2 LAnalysis行为检测效果与分析
将本文自主构建的沙箱LAnalysis与开源沙箱Cuckoo、业内较常用的微步云沙箱和腾讯哈勃沙箱以及奇安信文件分析平台进行对比,从Virustotal与VirusShare 2019—2020 ELF样本集中随机选取20个恶意样本,对比统计分析出的恶意行为种类及个数.

表8 LSTM环境参数
20个恶意样本的用例编号如表9所示,根据恶意样本用例编号可以直接在Virustotal和VirusShare中找到该恶意样本,这是每个恶意样本的唯一性标识.

表9 20个恶意样本的用例编号
由于20个恶意样本并不能完全覆盖10类的16种恶意行为,因此将恶意行为概括为对抗行为、隐藏行为、持久化行为、窥探行为以及其他恶意行为5种.由于20个样本一一列举篇幅占用过多,因此只列出其中2个样本的详细对比结果与20个样本的总体分析结果.
1) 0dbcc464a0dc0463bc9969f755e853d8.
该样本为盖茨家族的恶意样本,各沙箱分析结果如表10所示.

表10 0dbcc464a0dc0463bc9969f755e853d8的沙箱分析结果对比
2) 0A9BBC90CAB339F37D5BDD0B906F1A9C.
该样本为Skeeyah家族的恶意样本,各沙箱分析结果如表11所示.

表11 0A9BBC90CAB339F37D5BDD0B906F1A9C的沙箱分析结果对比
3) 20个样本.
各沙箱所检测出来的20个恶意样本的恶意行为总量如表12所示.

表12 20个恶意样本的沙箱分析结果对比 项
由对比结果可知,虽然Cuckoo、腾讯哈勃、奇安信文件分析平台以及微步在Windows文件分析上较为成熟,在业内也较为常用,但是对Linux ELF文件的分析能力十分薄弱.
以上结果证明了本文构建Linux ELF文件分析沙箱的合理性,同时也证明了LAnalysis在分析Linux ELF文件上的功能十分强大.LAnalysis较好地分析了众多恶意家族的恶意样本,因此基于LAnalysis构建的APT攻击主机行为数据集较为全面,利用这些数据构成的APT攻击样本的合理性与丰富性也因此得到了保障.
4.3 模型检测效果实验及对比分析
4.3.1 LSTM模型训练与优化
将3.4节所给出的训练集与测试集的正样本与负样本形成2维数组输入模型,标签为x_train,y_train与x_test,y_test.
首先设置batch_size=32,learn_rate=0.000 1,epoch=10.将初始参数设定为较小的值可以提高调参优化的效率.此时的评价指标如表13所示:

表13 初始状态的评价指标
1) 改变batch_size.
batch_size是训练1次所使用数据量的大小,对训练速度与时间具有较大影响,因此先对batch_size进行调整有利于为后续epoch和learn_rate的调整节省时间.batch_size受总内存值的影响,取值从32开始翻倍增长,当batch_size增大到256时程序会明显变慢,出现卡顿,因此batch_size最合适的大小应设置为128.后续的调参过程中batch_size均设定为128,此时训练速度是最快的.
2) 改变epoch.
epoch为训练的轮数,初始状态epoch=10,此时损失函数的变化曲线如图6所示.通过图6可知损失函数尚未收敛,说明模型仍在优化的过程中,因此应该增大epoch的值进行再次训练.

图6 epoch=10时的损失函数曲线
当epoch=50时,损失函数变化曲线如图7所示,此时可以看到模型随着训练轮数的增多逐渐收敛,当epoch=40时可以看到模型基本收敛,因此后续的调参过程将epoch设定为40.

图7 epoch=50时的损失函数曲线
3) 改变learn_rate.
通常learn_rate的取值范围为[0.000 1,1],但是若直接取值,大概率会选择到[0.1,1]的范围内,此时learn_rate的值难以在较大范围内变化.因此采用对数取值的方式,先选定4个区间,即[0.000 1,0.001],[0.001,0.01],[0.01,0.1],[0.1,1],在这4个区间内再进行平均取值.本文在batch_size=128,epoch=40的情况下不断改变learn_rate进行训练,不同learn_rate下的评价指标对比情况如表14所示.

表14 不同learn_rate下的评价指标对比情况
由表14可知,learn_rate=0.002时模型的F1值是最好的,因此模型的最终指标于batch_size=128,epoch=40,learn_rate=0.002时取得,如表15所示.

表15 模型最终指标
4.3.2 不同检测模型和方案的对比与分析
1) 不同时序处理模型的比较.
本文方案的模型准确率为92.17%,F1值为0.926 7.为确定最优的时序处理模型,训练了RNN模型、GRU模型与LSTM模型进行对比,实验结果如图8所示.从图8可以看出LSTM在处理APT攻击时序数据时效果要好于RNN与GRU模型.
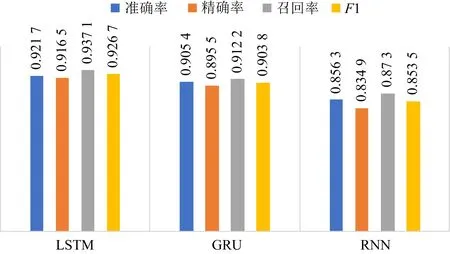
图8 不同时序处理模型的比对情况
2) 不同APT攻击检测方案的比较与分析.
目前业内有众多利用机器学习与深度学习进行APT攻击检测的方法.本文选择了较有代表性的4种[9,14,22,26]与本文构建的模型从模型准确率、特征全面度以及APT攻击建模等方面进行比较,结果如表16所示:

表16 APT攻击检测模型对比
由表16可知,对比的4种方法没有完全兼顾网络侧特征、主机侧特征以及APT攻击的时序性建模这3个APT攻击检测的重要方面,模型都存在不足之处.
文献[22]使用自主构建的网络告警数据进行模型训练,没有在大量网络数据集中进行验证与复现,具有一定的片面性.此外,虽然其考虑到了APT攻击中对子攻击的时序性建模,但是没有将主机侧的行为数据放入模型,对APT攻击的检测具有片面性与不合理性.
文献[9]使用沙箱Cuckoo对恶意代码进行分析,由4.2节可知Cuckoo对恶意代码的分析能力并不出色,因此基于Cuckoo进行恶意样本分析以检测APT攻击具有很大的提升空间.另外文献[9]并没有考虑APT攻击的时序性,仍局限于单种恶意代码的检测,并不能作为有效的APT攻击检测模型.
文献[14]在数据处理时没有使用NSL-KDD中的恶意行为细分标签,而是将攻击行为局限于大类,导致对攻击的刻画不够具体.另外其没有将APT攻击与普通的入侵检测进行区别,仍是针对单种攻击进行检测,没有将APT攻击的时序性特征考虑在内.虽然其准确率为93.7%,但却不能视为较好的APT攻击检测效果.
文献[26]在实验中使用的数据集为KDD99,该数据集相较于NSL-KDD有明显不足,存在大量冗余数据,目前已很少被业内使用.同时文献[26]也没有使用KDD99中更为细分的攻击小类,而是使用大类进行检测,对攻击的刻画不够具体.另外,文献[26]没有使用任何主机数据构建APT攻击数据集,仅用KDD99中包含的网络侧特征数据,而仅依据KDD99构建的APT攻击数据集与APT攻击检测模型是不合理的.
5 总 结
针对业内检测方案对APT攻击中单个攻击之间的时序性结合关注度不高、对于Linux系统中的恶意代码攻击检测工具较少、APT攻击周期过长导致APT攻击研究样本较少等问题,本文提出一种基于LSTM的Linux系统下APT攻击检测方案,并与其他方案进行了对比.实验证明,本文方案能够较好地对APT攻击进行检测,并且能够构建一套兼具主机行为和网络行为特征的APT攻击数据集,较好解决了当前业内缺乏高质量的APT攻击数据集的问题,为后续研究工作打下了良好的基础.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
领导决策信息(2018年16期)2018-09-27
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
数学学习与研究(2017年3期)2017-03-09
中学生数理化·高一版(2016年6期)2016-05-14
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
