
基于课程式双重DQN的水下无人航行器路径规划
2022-08-04 09:28王莹莹周佳加管凤旭
实验室研究与探索 2022年3期
王莹莹, 周佳加, 高 峰, 管凤旭
(哈尔滨工程大学 智能科学与工程学院, 哈尔滨 150001)
0 引 言
水下无人航行器(Unmanned Underwater Vehicle, UUV)的工作环境中存在着大量的干扰因素,如海岸、大小岛屿、海上漂浮物、暗礁、来往船只、风浪流等[1]。为了保证UUV在复杂工作环境下的安全性,自主路径规划能力就显得非常重要。但是,受到路径规划智能技术的发展限制,自主路径规划难以适应于动态、复杂的环境[2]。这导致UUV的避碰系统无法满足实际环境下的工作需要。
对于UUV来说,路径规划是最重要的自主航海技术之一,路径规划的目的是避免与静态或运动障碍物相撞以确保安全。典型的运动规划方法包括:智能优化方法[3]、启发式搜索方法[4]、模糊逻辑方法[5]、神经网络方法[6]、人工势场法等。智能优化算法适合解决类似路径规划的复杂优化问题。遗传算法[7],模拟退火算法是具有代表性的智能优化算法。Singh等[8]提出了一种A*方法,设计了圆形边界包围无人水面艇(Unmanned Surface Vehicle, USV),以此生成最佳航路点的安全距离约束,从而解决了USV在海上环境中的运动规划问题。Oral等[9]提出了一种新的增量搜索算法,该算法扩展了D*算法,提出的增量搜索算法可以在多个目标的条件下优化路径质量。Sun等[10]针对模糊边界选择的主观性,所产生的路径不能保证是最优的问题,比较了两种优化方法来进行模糊集的优化,在水下三维环境下生成了最优的3D路径。Solari等[11]基于扫描声呐的声特征,研究了人工势场方法在水下无人航行器避障中的应用。在不同环境下进行了模拟测试,证明了该方法在水下无人航行器的避障系统中的可行性。Li等[12]针对特征值较小区域的地形匹配精度低的问题,提出了一种自主水下航行器最优路径规划方法。该方法引入了由反向传播神经网络计算的联合判据和模糊判据,并通过仿真实验证明了可行性。
随着UUV所担负的科研、军事任务日益复杂,从而对UUV的运动规划能力也提出更高的要求[13],多层级决策融合、提升智能水平成为UUV运动规划技术的重要发展趋势和研究方向[14]。近年来,强化学习算法常常与深度神经网络相结合来解决序列决策问题。深度强化学习算法[15]已被用于解决复杂和不确定环境中的许多任务。深度强化学习在解决路径规划和实时避障问题上具有很强的潜力。
1 课程式强化学习理论基础
1.1 强化学习
强化学习是基于“行为”的学习过程,它是通过学习系统与环境的直接交互进行的。强化学习系统的响应采用标量奖励或回报来评估,以表明其对环境的响应是否适当,然后系统根据这个标量进行自我调整,从而提高未来的性能。
如图1所示,强化学习问题常用智能体—环境来研究,在本文中,智能体就是UUV。

图1 智能体—环境系统示意图
在时刻t,从状态St=s和动作At=a跳转到下一状态St+1=s′和奖励Rt+1=r的过程中,奖励Rt+1和下一状态St+1仅仅依赖于当前的状态St和动作At,而不依赖于更早的状态和动作。这样的性质称之为马尔可夫性。这意味着当前状态包含了可能对未来产生影响的所有信息。强化学习的核心概念是奖励,强化学习的目标是最大化长期的奖励。回报Gt可以定义为未来奖励的和:Gt=Rt+1+Rt+2+…+RT。
1.2 课程式学习
课程式学习主要思想是模仿人类学习的特点,主张让模型先从容易的样本开始学习,并逐渐进阶到复杂的样本和任务。在训练过程中,对样本进行权重动态分配,课程初始阶段简易样本居多,课程末尾阶段样本难度增加。课程式学习对于机器学习有如下两个层面的帮助:① 在达到相同的模型性能条件下,课程式学习可以有效加速机器学习模型的训练,减少训练迭代步数。② 可以使模型获得更好的泛化性能,即能让模型训练到更好的局部最优值状态。先用简单的知识训练对模型的提高会有帮助,并且简单的知识学得越好,则对模型最终的泛化性能越有利。
1.3 目标网络与经验回放
目标网络是在原有的神经网络之外再搭建一份结构完全相同的网络,原神经网络称为评估网络。具有双网络结构的Q学习算法称为双重深度Q学习网络(Double Deep Q Network, Double DQN)算法。

经验回放是一种让经验的概率分布变得稳定的技术,它能提高训练的稳定性。经验回放主要有“存储”和“采样回放”两大关键步骤。存储是指将轨迹以(St,At,Rt+1,St+1)等形式储存起来;采样回放是指使用某种规则从存储的(St,At,Rt+1,St+1)中随机取出一条或多条经验。经验回放有以下好处:在训练Q网络时,可以消除数据的关联,使得数据更像是独立同分布的。这样可以减少参数更新的方差,加快收敛。
2 UUV路径规划模型设计
2.1 环境状态模型

(1)
式中,(xob0,yob0)为障碍物初始位置;(xobt,yobt)为t时刻障碍物位置;mod(t,tback)是取余函数,得到的是t整除tback之后的余数。用上述方法可以表示环境中的障碍物信息,然而这些信息UUV是不知道的,它只能凭借声呐的返回值来确定某个方向上障碍物和船体的距离来做实时避障规划。
水下环境信息感知手段采用多波束前视声呐,由换能器阵列经过相控发射与信号接收,同一层的 91 条波束与UUV保持相同的相对纵倾,对应于 91个相对航向。前视声呐探测信息表现为极坐标形式,包括障碍物与 UUV 的相对航向、相对纵倾和相对距离。为了适用于路径规划和提高计算效率,将声呐探测数据简化为:前向100°的扇形区域每隔10°划分一个区域,一共发射11条波束,离散化处理后声呐探测的返回值d={d0,d1,…,d10},其中di表示探测范围内障碍物和UUV的相对距离。
除了考虑障碍物信息以外,全局规划需要考虑UUV与目标点的相对关系,在实际操作中,关于目标点的位置是提前已知的,而UUV的布放位置也是已知的,因此,可以在初始化阶段就算出目标点和UUV的相对位置关系:
(2)
式中:(xo,yo)为目标点位置;(xt,yt)为t时刻UUV的位置;α是在以UUV当前位置为原点的坐标系中,目标点所在的角度。UUV当前偏航角为ψ,则可以推出UUV航行方向和当前位置与目标点位置连线的角度差αe=α-ψ。由图2可见,在UUV航行速度为定值的情况下,αe越接近于0,航行速度在目标点相对连线上分量越大,速度越快。
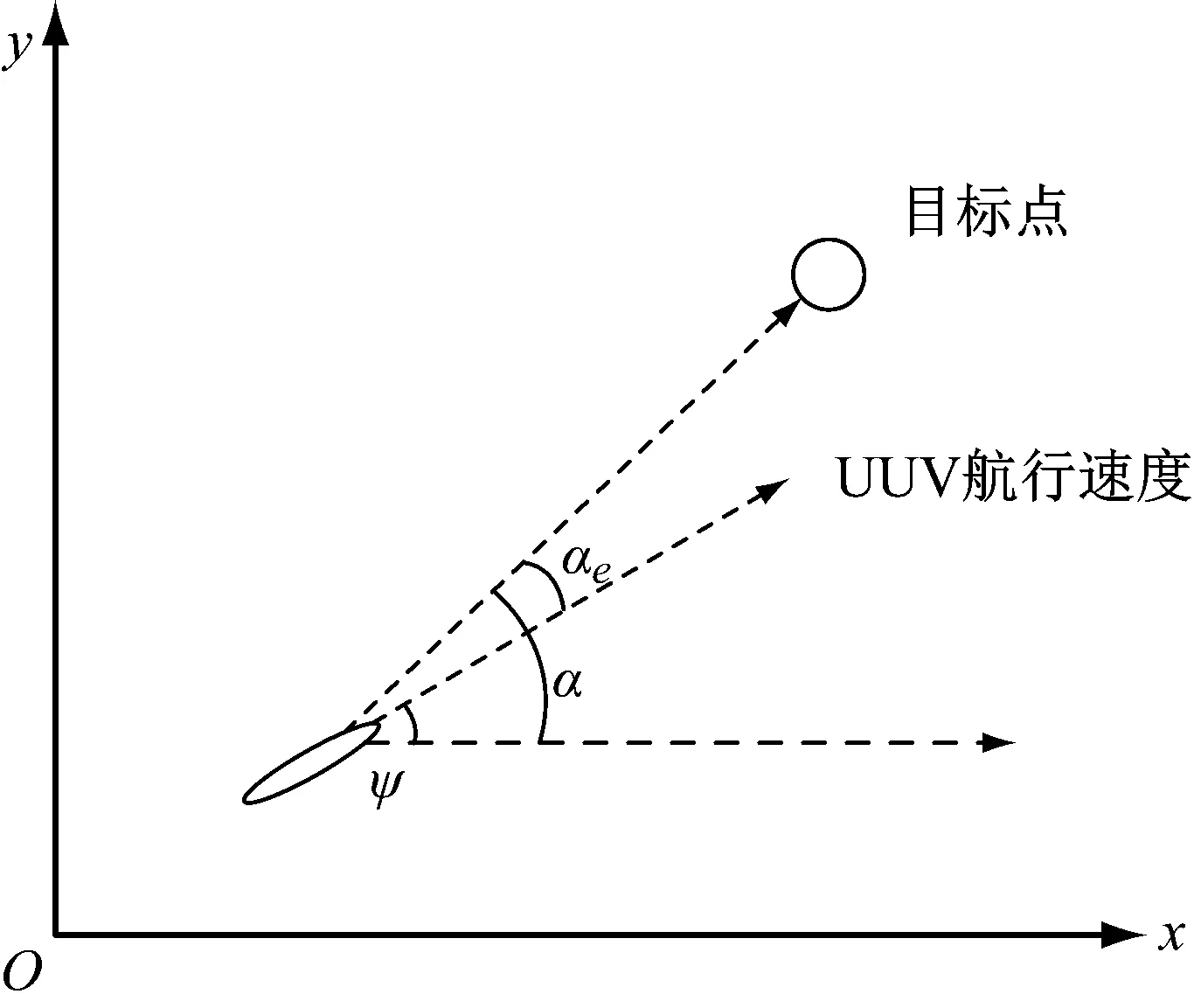
图2 UUV与目标点的相对关系
αe可以很好地体现在全局规划中的环境信息,且在UUV采取行为之后,可以根据上一时刻的状态和采取的行动计算下一时刻的αe并更新,然后作为下一时刻环境状态的一部分输入到神经网络。把αe和声呐信息d={d0,d1,…,d10}结合起来,可以作为双重Q网络中路径规划的输入信息。环境状态可以表示为一组12维的向量:s=[d0,d1,…,d10,αe]。
2.2 行为动作和奖励函数模型
考虑到航行器操纵机构对于运动控制的限制,结合实时规划的快速性,将行为动作设计为:左转(15°,30°),前行,右转(15°,30°)这5种情况。仿真过程中每秒交互一次,选取的角度变化量在(-30°,30°)的区间内,符合航行器的可实现操纵效果。这5个行为动作是双重深度Q网络的输出,决定了UUV接下来的航行方向和速度。
奖励函数包括实时奖励函数和延时奖励函数。在全局路径规划中,实时奖励分为正奖励和负奖励:当αe具有一个相对小的角度时给予正奖励,期望UUV能够快速地沿着起始点和目标点直线最短距离行驶,设置一个正奖励用来鼓励航行器不要偏航。实时负奖励是关于时间的,UUV航行时间越长,代表绕了远路,负奖励会对这种行为给予惩罚。延时奖励函数为到达目标点,到达目标点是全局路径规划的核心任务,所以设置了较大的奖励值。为了避免程序无穷尽的运行下去,设置了999作为一个回合内交互的最大步数,超过这个次数之后,环境自动初始化进行下一回合的训练。奖励函数的设计决定了UUV对目标任务的理解和学习能力,在UUV局部路径规划中设计了如下的奖励函数:

(3)
式中,d为船体和障碍物的距离。
图3所示为根据当前的环境状态信息判断UUV行为价值的流程图,其中,导致回合结束的状态有交互次数>999,到达目标点,发生碰撞3种。其他3种状态不会导致回合结束,所以在给出当前交互奖励值后进入下一时刻交互。

图3 交互结果判断流程图
3 路径规划仿真实验及结果
UUV的路径规划学习课程如下:
步骤1全局路径规划:不设置障碍物,仅考虑趋向目标体运动。
步骤2在全局规划的路径中加入单个静态障碍物,UUV探索其他行为以期避开障碍物到达目标点。
步骤3增加静态障碍物的个数到5,设置复杂地图环境对决策网络进行训练。
步骤4设置2个不同移动方向、速度的动态障碍物,3个静态障碍物,训练UUV的障碍物特征提取能力和综合避障能力。
3.1 全局路径规划训练过程及结果
使用的仿真平台是Gym,实现了UUV与环境接口中的环境部分。使用Keras库来搭建双重DQN。深度强化学习中,环境状态维数等于输入神经元个数,设置为12;行为动作个数等于输出神经元个数,设置为5。激活函数为ReLU,优化器为Adam。
全局路径规划中,环境的初始化信息包括:UUV初始位置(xt,yt)、UUV初始偏航角ψ、进而求出UUV起始航行方向与目标点的相对夹角αe、声呐探测值d={d0,d1,…,d10}。为了训练结果的泛化,UUV初始位置和UUV初始偏航角会设置一个合理的区间,每次初始化会在区间内随机选取值。水下训练环境的大小:长300 m,宽200 m;航行器的大小:长10 m,宽4 m;可被判定为到达目标点的范围:设置半径为8 m;仿真过程中每秒交互一次,UUV恒定速度为2 m/s。
图4所示为UUV在全局规划中的回合奖励变化图,共训练了1 400回合。起始阶段并没有学习到趋向于目标点运动,在训练环境中随机选取行为进行交互,奖励值很低。训练1 000次后,UUV找到了最优路径,奖励值可以稳定在最高点20左右。
3.2 静态障碍物避碰训练过程及结果
如图5所示,增加了障碍物个数后,学习难度明显加大,在前1 000回合奖励值波动明显,并不稳定。在1 500回合后寻找到最优路径,奖励值稳定在20。UUV成功找到最优路径并到达目标点,证明了在复杂障碍物环境下,经过训练的UUV依然能做出快速且有效的避障路径规划。

(a) 训练200次
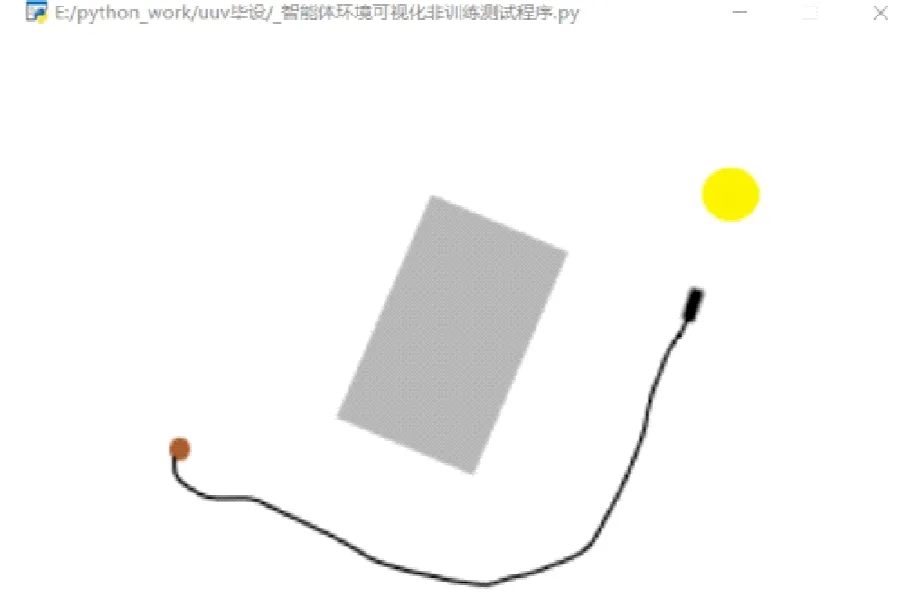
(a) 单静态障碍物训练结果
3.3 动态障碍物避碰训练过程及结果
图6所示是在动态障碍物环境下的训练结果。图7所示是动态障碍物环境下的回合奖励变化图,其最优路径与直接趋向于目标体运动的路径接近,可以长期得到在-10°≤αe≤10°情况下的0.1正奖励。所以虽然环境更复杂,但是奖励值较高,趋近稳定后最优回合奖励大于20。
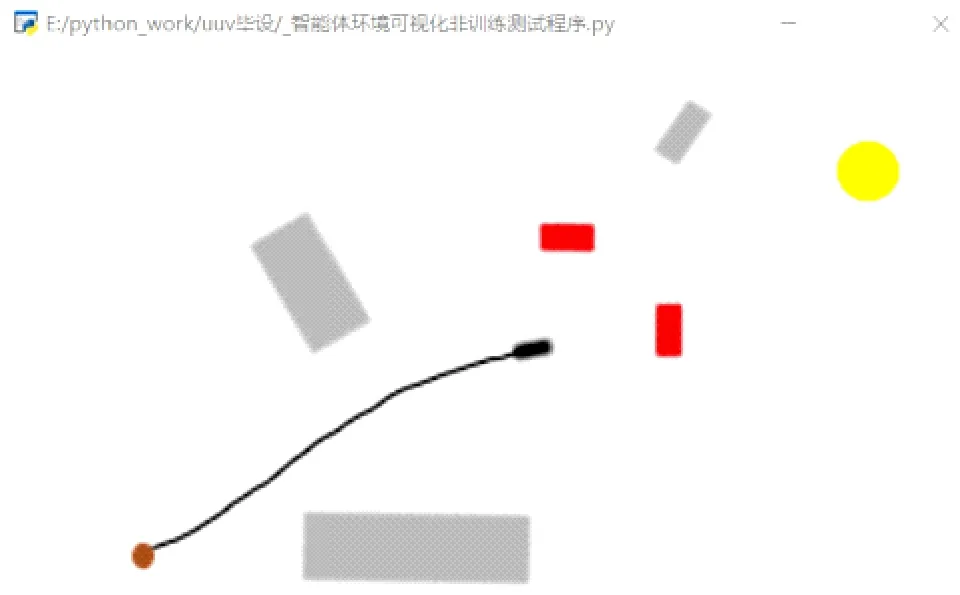
(a) 遭遇动态障碍物
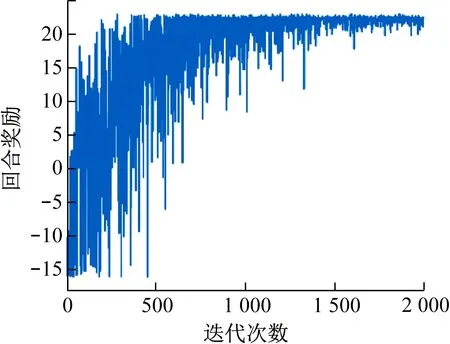
图7 动态障碍物训练回合奖励变化
4 结 语
针对双重DQN算法在复杂规划任务中学习效率低的问题,提出的课程式双重DQN加快了双重DQN在复杂规划任务中的学习速度。在全局路径规划中,对训练样本进行权重动态分配,将路径规划任务由简到繁分解为全局路径规划,静态、动态障碍物的实时避碰。利用神经网络在静态障碍物、动态障碍物环境完成仿真训练。仿真实验结果表明,课程式学习在训练过程中有显著的引导作用,并验证了课程式双重DQN算法的有效性。
猜你喜欢
疯狂英语·新读写(2021年6期)2021-08-05
房地产导刊(2021年6期)2021-07-22
儿童故事画报(2020年7期)2020-08-03
动漫界·幼教365(中班)(2020年3期)2020-04-20
铁道通信信号(2020年9期)2020-02-06
创新作文(1-2年级)(2019年4期)2019-10-15
领导决策信息(2018年50期)2018-02-22
商周刊(2017年5期)2017-08-22
中国卫生(2016年2期)2016-11-12
军事历史(1999年2期)1999-08-21
