
基于注意力机制的多样性图像风格迁移
2022-08-03 05:23安徽理工大学计算机科学与工程学院张世程
数字技术与应用 2022年7期
安徽理工大学计算机科学与工程学院 张世程
基于注意力机制的风格迁移模型是目前该领域研究的重点。这类模型可以保证风格化后的结果图能保留良好的语义信息,同时优秀地实现纹理、色彩以及形状等风格样式的迁移。但是目前这类模型还没有考虑过多样性生成,所有生成的结果都是唯一的。为了弥补这个不足,本文研究如何实现多样性风格迁移。具体来说,通过在模型的注意力机制中注入一种噪声矩阵——作为一种风格扰动来提升结果的多样性。本文的方法不仅可以完美嵌入目前主流的基于注意力机制的风格迁移模型,而且不需要训练,只需在模型测试阶段操作即可。通过理论和实验两个方面验证了提出的方法确实可以提高生成结果的多样性,在满足高效性的同时方便代码实现。
随着以深度学习为代表的AI技术快速发展,越来越多的领域开始交叉融合,风格迁移就是将艺术与深度学习技术融合的典型实践。具体来讲,给定一张内容图和一张目标风格图,风格迁移的目的就是将原始内容图的风格转化为目标图的风格,同时保证原始内容的语义信息不丢失。目前,以手机美颜为代表的各类修图软件大量使用了相关技术,为人们提供休闲娱乐功能。
最近,自注意力机制在各种计算机视觉应用领域中大放异彩,如:目标检测、语义分割等。在风格迁移中也出现了许多使用自注意力机制的研究工作,这类算法往往具有良好的迁移效果。但是目前这类算法普遍存在一个问题:只能生成唯一的结果。众所周知艺术不是单调唯一的,应该是多样的。多样性是普遍存在于这个世界上的,这就像世界上没有两片相同的叶子一样。因此,解决风格迁移的多样性问题不仅是艺术所追求的,也是促进风格迁移实际落地应用的必要保证。
1 多样性风格迁移
1.1 风格注意力机制
风格注意力机制[1]是自注意力机制(Self-attention)的一种应用。对于给定的内容特征和风格特征,风格注意力机制通过计算内容特征和风格特征之间的特征相似性获得一个加权矩阵,之后通过加权矩阵来重组内容图的风格,即完成了风格迁移。如图1所示为加噪的后的风格注意力机制,与原始的风格注意力相比,多了一个噪声。
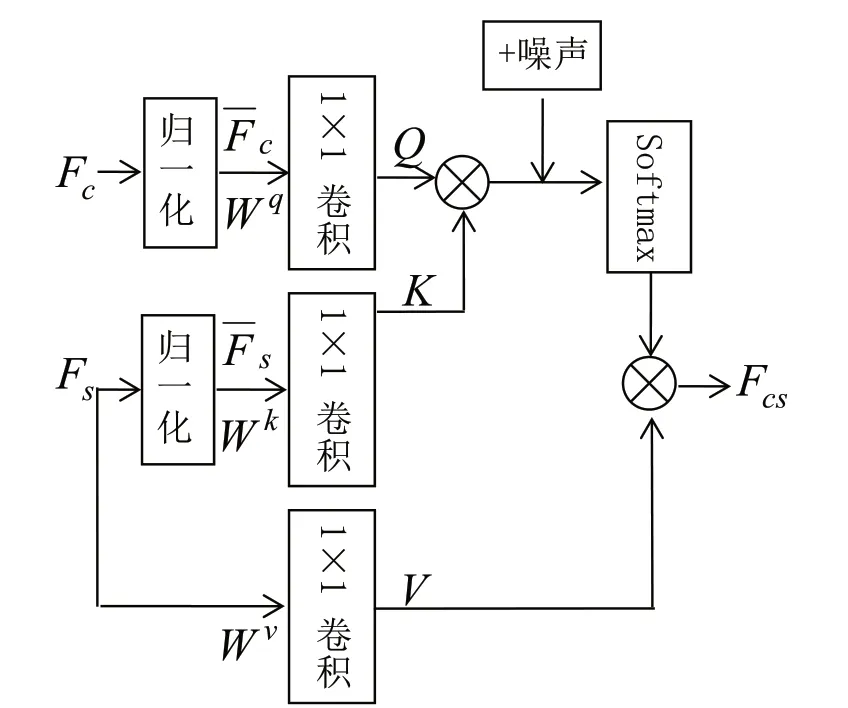
图1 加噪后的风格注意力机制Fig.1 The style-attentional mechanism after adding noise
1.2 风格扰动
为了提升生成图片的多样性,目前视觉领域中最常用的手段就是噪声注入。本文提出两种加噪方案,下面通过形式化语言来描述并且证明两种方法的可行性。
方案1:扰动加噪
根据图1所示,输入内容特征图Fc,风格特征图Fs,使用一个实例归一化操作,减去各自通道特征的均值并除以方差变为和Fs。Wq,Wk,Wv是 三 个1×1卷 积,主要提供非线性映射:

Q,K,V表示为三个嵌入向量。之后通过Q,K计算相似度矩阵S并使用Softmax函数归一化矩阵的值。因为Softmax函数的功能只是将值放缩到(0,1)之间,不影响模型的整体功能,因此可以忽略这一项简化表示为:

那么最后可得到风格化的特征向量Fcs为:

上面介绍的是一个简单的未加噪声的风格注意力机制计算过程。根据图1所示,噪声加入的位置为Q,K计算相似度矩阵后。记加噪以后的相似度矩阵为S*=S+Z,其中Z为噪声,那么此时风格化的特征向量表示为:

根据Gatys[1]关于Gram矩阵的定义,得到加噪前后的两个Gram矩阵和, 则:
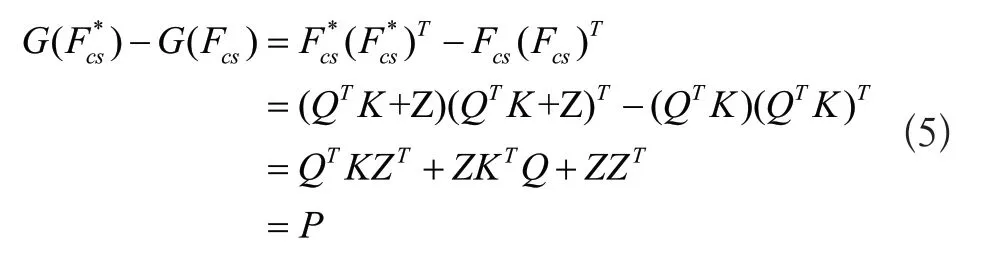
我们将P矩阵定义为多样性矩阵,表示加噪前后两个特征图之间的差异,那么这种差异性可以随着加入的噪声Z改变。由于不同的Gram矩阵可以表示不同的风格,两个有差异的Gram矩阵可以看做是两种风格。即加噪前后得到的风格化特征Fcs和有不同的风格。但是这种差异性整体并不大,这种细小的风格差异就可以看作是同种风格的多样性体现。
方案2:稀疏化
除了在相似度矩阵中直接加入噪声,对于S也可以使用稀疏化方法来实现多样性。所谓的稀疏化指的是让相似度矩阵中部分区域的值变为0,整个矩阵因为有许多为0的值而成为一个稀疏矩阵。虽然实现手段不同,通过下面等式可以证明稀疏化是上述方案1的一种特例。
我们记相似度矩阵S为n×m的矩阵,表示为:

记稀疏化后的矩阵为R,表示为:
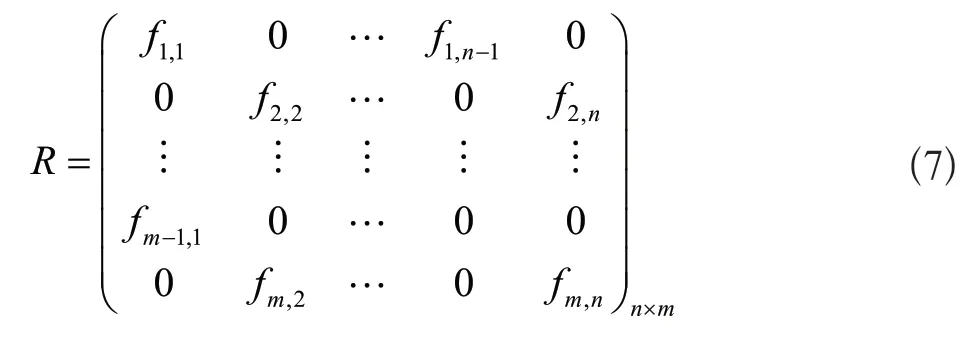
那么R即可表示为:

其中矩阵U可以看作是部分位置取相反值的噪声矩阵,而R=S+U形式与方案1的形式一致,因此证明了方案2也是方案1的一种特殊形式。对于稀疏化,可以直接使用PyTorch提供的Dropout函数,因此该方案实现也十分简单。
2 实验与结果
2.1 实验环境和数据集选择
实验所选的操作系统为Ubuntu 20.04,处理器为Intel i5 10400,显卡为一张RTX3060,内存为16g,运行环境为PyTorch1.8.1。为了评估生成结果的多样性,本文使用Wang[2]发布的数据集并按照他们测试方法进行多样性比较。数据集共有6张内容图和6张风格图,实验前对图片进行预处理,将图片大小统一调整为512×512大小。该数据集可以同时生成36种风格化组合,对于每种风格化组合随机生成20张图片,并两两计算这20张图之间的多样性,最终对36种风格化组合的计算结果取平均。
2.2 结果
本文实验同时验证上述两种方案的可行性。对使用了风格注意力机制的模型SANet[3],MAST[4],AdaAttN[5],IEContraAST[6]进行实验,以此来验证提出方案的普适性。对于方案1,本文选择加入的噪声Z服从N(0,α2) 的正态分布,其中α为超参数可以控制加入噪声的大小,实验设置中为15。对于方案2,使用PyTorch提供的Dropout函数,参数设置为0.7,表示将相似度矩阵中约70%的值设为0。
2.2.1 视觉效果
风格迁移中视觉感受尤为重要,本节从生成图片视觉差异上进行对比,验证生成的结果是否能让人从肉眼上分辨出多样性。如图2所示是生成的结果图。其中最左边的是内容图和风格图,右边上半部分是方案1生成的结果,下半部分是方案2生成的结果。通过观察,方案1生成的三张长颈鹿图片的脖子斑点存在明显的差异,而方案2中长颈鹿的脸颊斑点明显也存在差异。细致对比,可以发现这种差异有很多。但是无论差异再大,这几张图之间整体的风格是一致的。因此可以断定从视觉上确实可以观察到生成结果的多样性。

图2 视觉效果对比Fig.2 Visual effect comparison
2.2.2 指标度量
这一节通过度量指标来验证生成结果的多样性。本文使用三个度量指标:Pixel distance用来比较图像在RGB空间内像素之间的欧氏距离,Lipips distance比较图像在特征空间的相似性,这两个指标越大表明图像之间的差异性越大,即多样性越高。指标Efficiency通过计算单张图片的生成时间来比较方案的效率高低,数值越小越佳。如表1所示展示了实验结果,其中Origin表示原始不加噪的结果,Perturbation表示方案1,Sparsity表示方案2。
通过表1可以发现在不同的模型上,方案1在提升图像多样性上面都优于稀疏化方案,相反在运行效率上方案2优于方案1。对比不同的模型,SANet在实验设定的参数下多样性提升最为巨大,而AdaAttN在多样性提升方面则最少。为什么不同的模型存在这样的差异,这个问题可以留给未来的工作去研究。总之,上述两者方法都达到了预期目的。
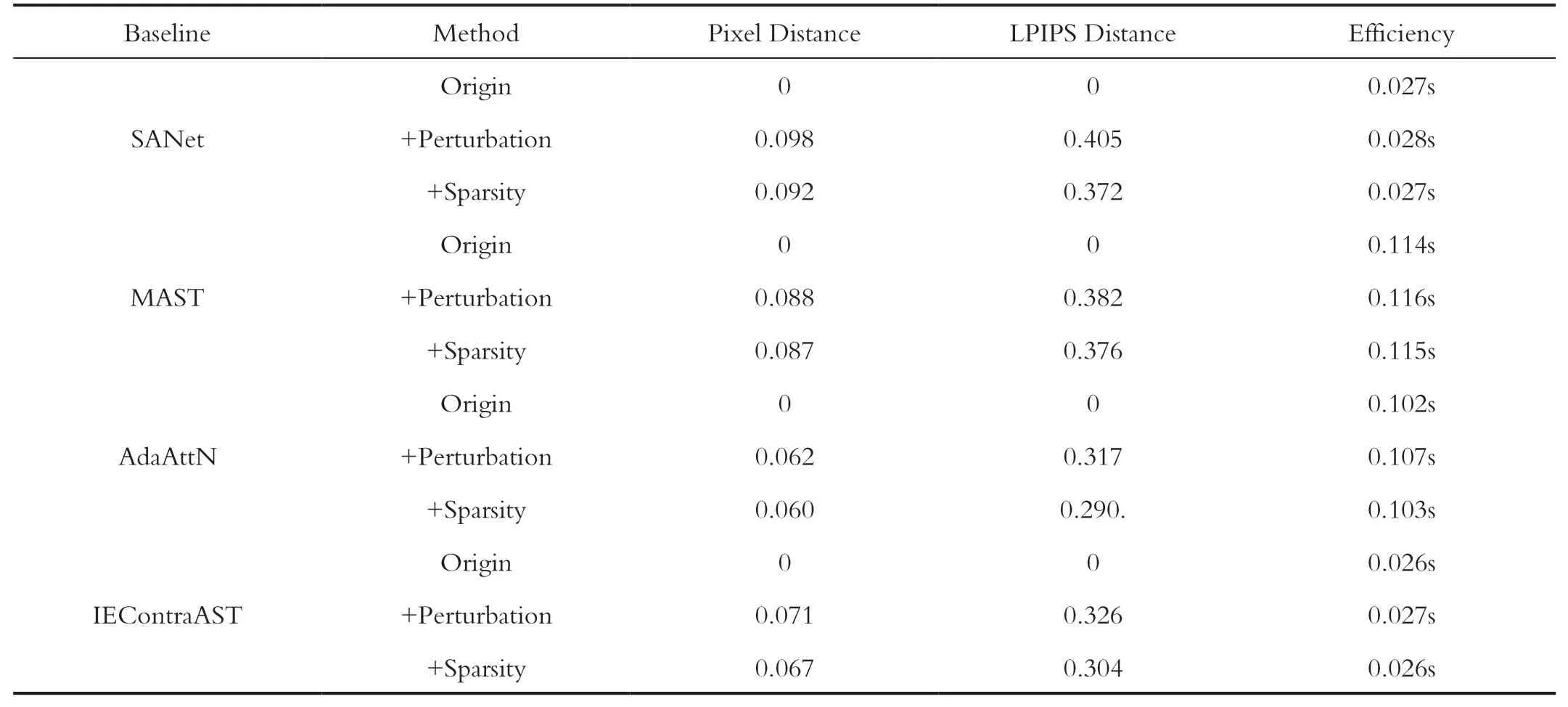
表1 不同模型以及不同加噪方案结果对比Tab.1 Comparison of results under different models and different noise-adding schemes
3 结论
本文提出了一种基于注意力机制的多样性图像风格迁移方法,保证模型能够生成多样性的结果。我们通过在原始的注意力机制中注入扰动矩阵来提升风格化后图像的多样性。理论和实验证明提出的方法对于目前主流的几个基于注意力机制的风格迁移模型都适用,这为实际应用和进一步研究提供了有益思路。
猜你喜欢
模式识别与人工智能(2022年4期)2022-05-07
小雪花·成长指南(2022年1期)2022-04-09
数学年刊A辑(中文版)(2020年3期)2020-10-27
传媒评论(2017年3期)2017-06-13
文艺生活·下旬刊(2017年5期)2017-06-11
东方教育(2016年3期)2016-12-14
戏剧之家(2016年16期)2016-09-28
噪声与振动控制(2015年4期)2015-01-01
振动、测试与诊断(2014年4期)2014-03-01
