
基于支持向量机的农田水利灌溉分流机械运行异常检测
2022-08-02 09:25孙兆光
机械与电子 2022年7期
孙兆光
(莒县青峰岭水库管理服务中心,山东 莒县 276500)
0 引言
农田水利灌溉分流机械是提升农田灌溉的关键设备。该设备可提高灌区排灌的整体水平,以满足农业的发展需求,通过合理布置和调整灌溉系统可以提高节水率[1]。考虑到灌区的灌排需求和饮水需求,优化灌溉设施能够降低设施养护费用、缩短灌溉周期,提高灌溉效率[2]。在上述方式中,需要借助灌溉分流机械完成。当灌溉分流机械出现异常时,将影响整个灌区的灌溉效果,因此,研究农田水利灌溉分流机械运行异常检测方法具有重要意义。
张聪等[3]针对机械变量之间存在的耦合关系,通过趋势互相关分析方法,构建变量耦合关系网络。采用无监督学习方法,根据变量耦合关系网络构建变分图自编码模型,获取机械运行特征,将提取的特征输入图卷积网络中,完成机械运行异常检测,该方法ROC曲线检测结果不理想,存在检测性能差的问题。王昱栋等[4]通过感知哈希算法获取机械图像,利用直方图均衡化方法增强机械图像,结合Canny边缘检测算法和双边滤波算法获取机械运行特征,实现异常检测。该方法在异常检测过程中容易出现漏检现象,存在检测率低问题。张西宁等[5]将边界软化率引入格雷厄姆扫描法中,通过射线法构成数据集,将其输入随机森林模型中,完成异常检测,该方法检测异常所用的时间较长,存在检测效率低的问题。
为了解决上述方法中存在的问题,提出基于支持向量机的农田水利灌溉分流机械运行异常检测方法。
1 农田水利灌溉分流机械数据处理
为实现农田水利灌溉分流机械运行异常检测,采用自组织映射算法聚类灌溉分流机械运行数据,作为研究的基础数据,为后续的检测实现奠定基础。
自组织映射算法由输入层和竞争层构成,属于层次性神经网络结构[6-7]。其中,输入层主要作用是将接收的输入信息传递到下一层中,竞争层主要目的是比较神经网络细胞元和输入信息,根据比较结果分类信息。采用自组织映射算法处理水利灌溉分流机械运行数据的具体过程如下所述。
a.用C表示灌溉分流机械运行数据,用ξj表示神经元在自组织映射网络竞争层中的加权向量,归一化处理C、ξj的表达式为
(1)

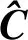
(2)
c.根据竞争学习法可知,在自组织映射网络中获胜神经元的输出为
(3)
ui为输出的神经元结果;t为输出的当前时刻;j为神经元的加权向量;j*为神经元的一般向量。
获胜的神经元在自组织映射网络中可以根据下述规则对加权向量ξj调整:
(4)
β为在区间[0,1]内取值的学习效率,在不断的迭代过程中学习效率不断减小。
采用自组织映射算法聚类处理水利灌溉分流机械运行数据的具体流程如图1所示。

图1 农田水利灌溉分流机械数据聚类流程
2 农田水利灌溉分流机械运行异常检测
2.1 灌溉分流机械运行特征数据提取
在上述灌溉分流机械运行数据聚类基础上,采用尺度不变特征变换SIFT方法[8-9]提取水利灌溉分流机械数据的运行特征。该方法可获取水利灌溉分流机械的局部信息,提取的运行特征点可反映农田水利灌溉分流机械的运行状态。
在固定尺寸中水利灌溉分流机械运行的局部特征信息具有不变特点,用Q(x,y,ζ)表示分流机械运行图像O(x,y)中存在的空间信息,其计算式为
Q(x,y,ζ)=O(x,y)*H(x,y,ζ)
(5)
ζ为幅度可变因子;*为卷积;(x,y)为特征点位置;H(x,y,ζ)为高斯函数,其表达式为
(6)
构建高斯平方差函数F(x,y,ζ),在不同幅度状态下提取农田水利灌溉分流机械运行的特征点,即
F(x,y,ζ)=[G(x,y,μζ)2-G(x,y,ζ)2]*g(x,y)
(7)
μ为检测阈值参数。
2.2 灌溉分流机械运行异常检测
在提取灌溉分流机械运行特征的基础上,本文借助支持向量机完成农田水利灌溉分流机械运行异常检测。在支持向量机中引入免疫算法[10-11]实现农田水利灌溉分流机械运行的异常检测。
设g(u)为支持向量机的误差上限值,通过免疫算法优化g(u),使其最小,具体步骤如下所述。
a.抗体二进制编码通常情况下由3个部分构成,分别为支持向量机的样本特征、误差惩罚因子V和核函数参数η[12-13]。A=[a1,a2,…,al],A为参数集合,其中,l为参数编码对应长度,编码通常情况下由0或1构成。
农田水利灌溉分流机械运行异常检测方法将核函数参数η设定在[0.000 1,20 000]内,将误差惩罚因子V设定在[1,200]内。用G=[g1,g2,…,gd]表示水利灌溉分流机械运行数据的特征集,d表示该集合的大小,通过二进制编码表示机械运行数据的特征选择,D=[d1,d2,…,dd],D为机械运行数据特征选择的总集合。通过上述分析可知,可通过参数和特征的组合表示抗体的二进制编码S=[A,D]。
b.通过匹配灌溉分流机械运行异常检测问题的特征和记忆细胞库中存在的结构信息构成初始抗体群。
c.将支持向量机的误差上限值g(u)作为标准,获得抗体与抗原之间的亲和力Sv,即
(8)
k为抗体v选择的特征总数;f为特征数量。
d.更新群体后,在抗体记忆细胞库中引入与抗原存在最大亲和力的抗体,下次在遇到相同问题时,直接在记忆细胞库中获得答案,缩短寻找答案所用的时间。
e.抗体之间的相似度可通过抗体浓度描述,抗体产生的抑制与刺激可通过相似度度量得以控制,进而实现抗体多样性的控制,设Nvw为抗体之间存在的相似度,其计算式为
(9)
R(2)为抗体v、w之间存在的平均信息熵。
根据相似度计算结果获得抗体v的浓度cv,其表达式为
(10)
f.抗体进入下一代的过程具有随机性,亲和力会影响克隆的概率,即当抗体与其他抗体亲和力低、与抗原亲和力高时,克隆的几率较大。用av表示抗体选择的概率,即
(11)
β、χ均为加权系数;M为抗原数量;vv为浓度抑制概率。
g.新抗体是原始抗体做变异和交叉操作生成,抗体交换信息可描述新抗体生成过程。农田水利灌溉分流机械运行异常检测方法通过高斯变异[14-15]和单点交叉生成新个体。
h.为避免算法出现局部最优解问题,需要对抗体集合做更新处理,记忆细胞集中存在的记忆细胞通过不断迭代构成抗体群。
i.将提取的特征输入支持向量机中,设置终止条件,满足条件的个体即为最佳个体,获得农田水利灌溉分流机械运行的异常检测结果。
结合支持向量机和免疫算法实现农田水利灌溉分流机械运行异常检测的具体流程如图2所示。

图2 异常检测流程
3 实验分析
3.1 实验方案设计
为验证本文方法的整体有效性,将文献[3]方法和文献[4]方法作为对比方法,进行实验测试。
在农田水利灌溉分流机械运行异常检测时,实验中以某地大型农田水利灌溉分流机械为研究对象进行实验分析。本次实验中评价指标选取接收者操作特征曲线ROC下面积,即AUC概率,对本文方法、文献[3]方法和文献[4]方法的有效性进行检测。真阳率和假阳率分别为ROC曲线的纵坐标和横坐标,真阳率越高、假阳率越低,曲线下面积越大,即方法的性能越好,设TP为真阳率,其计算式为
(12)
nT为判定正常状态为正常状态的次数;nF为判定正常状态为异常状态的次数。
设FP为假阳率,其计算式为
(13)
nR为判定异常状态为正常状态的次数;nN为判定异常状态为异常状态的次数。
3.2 实验结果分析
本文方法、文献[3]方法和文献[4]方法的ROC曲线如图3所示。

图3 不同方法的ROC曲线
由图3可知,与其他2种方法相比,本文方法构成的ROC曲线面积较大,表明本文方法的真阳率高于假阳率,在农田水利灌溉分流机械运行异常检测过程中具有较好的性能。
在2种典型实验环境下采用本文方法、文献[3]方法和文献[4]方法检测农田水利灌溉分流机械运行状态,对比不同方法的检测率,测试结果如图4所示。
由图4可知,随着时间和样本数量的增加,本文方法、文献[3]方法和文献[4]方法的检测率均有所下降, 表明样本数量和机械运行时间会影响上述方法的检测率。上述方法在实验环境2中的检测率明显高于实验环境1中的检测率,对比测试结果发现,在相同时间和相同样本数量下,本文方法的检测率在不同实验环境中均高于文献[3]方法和文献[4]方法的检测率,这是由于本文方法对机械运行状态检测之前通过自组织映射算法对机械的运行状态数据进行聚类,提高了方法的检测率。

图4 不同方法的检测率
将检测时间作为指标,采用上述方法检测农田水利灌溉分流机械运行的状态,对比不同方法的检测效率,结果如表1所示。

表1 不同方法的检测效率

表1(续)
由表1中的数据可知,在多次异常检测测试中本文方法的检测时间均控制在0.1 s左右,远低于文献[3]方法和文献[4]方法的检测时间,表明本文方法具有较高的检测效率。
4 结束语
检测农田水利灌溉分流机械的运行状态,可以提高灌溉工程的用水效率、有利于管道的施工和管理。针对异常检测方法存在检测性能差、检测率低和检测效率低等问题,提出基于支持向量机的农田水利灌溉分流机械运行异常检测方法。该方法借助支持向量机完成农田水利灌溉分流机械运行的异常检测,提升了农田水利灌溉分流机械的运行效率,具有一定可行性。
猜你喜欢
江西通信科技(2022年3期)2022-10-11
预防青少年犯罪研究(2022年1期)2022-08-15
云南农业(2021年10期)2021-10-22
云南农业(2021年9期)2021-09-24
云南农业(2021年8期)2021-09-06
建材发展导向(2021年11期)2021-07-28
云南农业(2021年3期)2021-04-24
河南水利年鉴(2020年0期)2020-06-09
电子技术与软件工程(2019年21期)2020-01-16
建材发展导向(2019年11期)2019-08-24
