
一种低开销自适应SD-UANET流表下发机制*
2022-08-01 02:18付泽亮朱其政张本俊
电讯技术 2022年7期
任 智,付泽亮,朱其政,周 杨,张本俊
(重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引 言
无人机自组网(UAV Ad Hoc Network,UANET)是移动自组网的一个特例[1],具有功能多样性、灵活性[2]、易于安装部署和相对较小的运营费用等优势,在军事和民用领域得到了广泛应用[3-5]。而软件定义网络(Software Defined Network,SDN)是一种新型的网络体系结构,其通过OpenFlow技术来实现网络控制面与数据面的分离,从而达到对网络流量的灵活控制,目前已成为下一代互联网的研究热点,其应用有效弥补了传统网络结构过于扁平化、安全防护手段单一的弊端,在提升网络安全等级、降低运维管理难度方面优势突出。因此利用SDN中集中控制的思想,将SDN新架构思想引入无人机自组网,以便解决随着无人机技术的发展,无人机所担负的任务的复杂化和多元化时,能更好更快地掌控无人机群网络状态,并同时根据无人机自组网的特性对SDN中流表下发机制进行改进,使其网络性能更加优异。
文献[6]针对UANET 高动态、不稳定的空中无线链路和无人机碰撞的特性提出了SD-UANET 架构。文献[7]提出了一种面向SD-MANET的拓扑发现方法,利用连通支配集算法生成骨干网络,由骨干节点将局部拓扑信息通过上行通路上报给SDN控制器,其通过限制向控制器上报局部拓扑信息的节点数量来降低拓扑信息收集过程中产生的额外开销。文献[8]尝试在智能手机的无线自组织网络上实现软件定义网络,使其模块化的自组织网络管理结构易于修改和扩展。文献[9]提出在网络规模较大且网络拓扑变化剧烈的情况下,引用多控制器的SDWM组网架构,将数据平面分割成多个域且每个域都有网络转发设备,然后每个控制器掌控一个域,实现域与域之间的联通;同时提出了一种具有启发性的信道分配算法,通过周期性的利用AP的频带利用率为其分配不同带宽的信道,成功提高了信道利用率,提升了网络的系统吞吐量。文献[10]在此背景下,提出了一种基于软件定义网络的fanet拓扑管理(简称STFANET)。它是一种协调协议,包含了一种高效的基于SDN的无人机通信和一组拓扑管理算法,目标是建立和维护一个FANET拓扑结构,以便通过中继单元在执行个人或协作任务的独立节点之间提供稳定可靠的通信链接。
通过研究以上发现,现有文献针对OpenFlow v1.5协议在无人机自组网环境下的多跳流表下发机制与flow_mod包结构的兼容性问题的研究较少且存在如下问题:原协议流表下发机制针对拓扑变换平缓的有线网络,主动流表下发只是网络刚建立时触发,在运行过程中主要采用向控制器问路的被动流表下发方式进行寻路,而无人机自组网场景中网络拓扑复杂多变,被动流表下发方式增加了流表获取的时间同时增大了开销;无人机自组网环境中节点繁多,相应的流表项条目也随之增多,原协议采用flow_mod消息进行单播下发,导致冗余的头部开销与源、目的元组开销过多,单播也会导致无线资源利用率下降,从而使网络吞吐量下降。
为了解决原协议在无人机自组网中不兼容以及开销较大的问题,本文提出了一种低开销自适应软件定义无人机自组网流表下发机制,通过流表周期性主动下发、组播切包去尾与流表项源、目的元组自适应压缩,在无人机自组网场景下极大减小了流表下发的开销,提高了网络吞吐量。
1 网络模型与流表结构
1.1 网络模型
基于无人机自组网的特点,在软件定义无人机自组网中,使任一节点为控制器节点,其中含有控制器软件,计算并掌握全局网络拓扑并周期下发流表;而无人机自组网中其他所有的任意节点均为交换机节点,如图1所示,使得自组网中每个节点都有到整个网络的流表。

图1 软件定义无人机自组网网络模型
1.2 流表结构
在OpenFlow v1.5中,flow_mod包中的匹配域ofp_match部分共涵盖了从物理层到运输层等45个元组,但是比起OpenFlow v1.0中的匹配域ofp_match部分来说,采用的OXM TLV(type-lenth-value)变长形式,可以自适应地使用所需的元组,减少了不必要的开销,如图2所示。
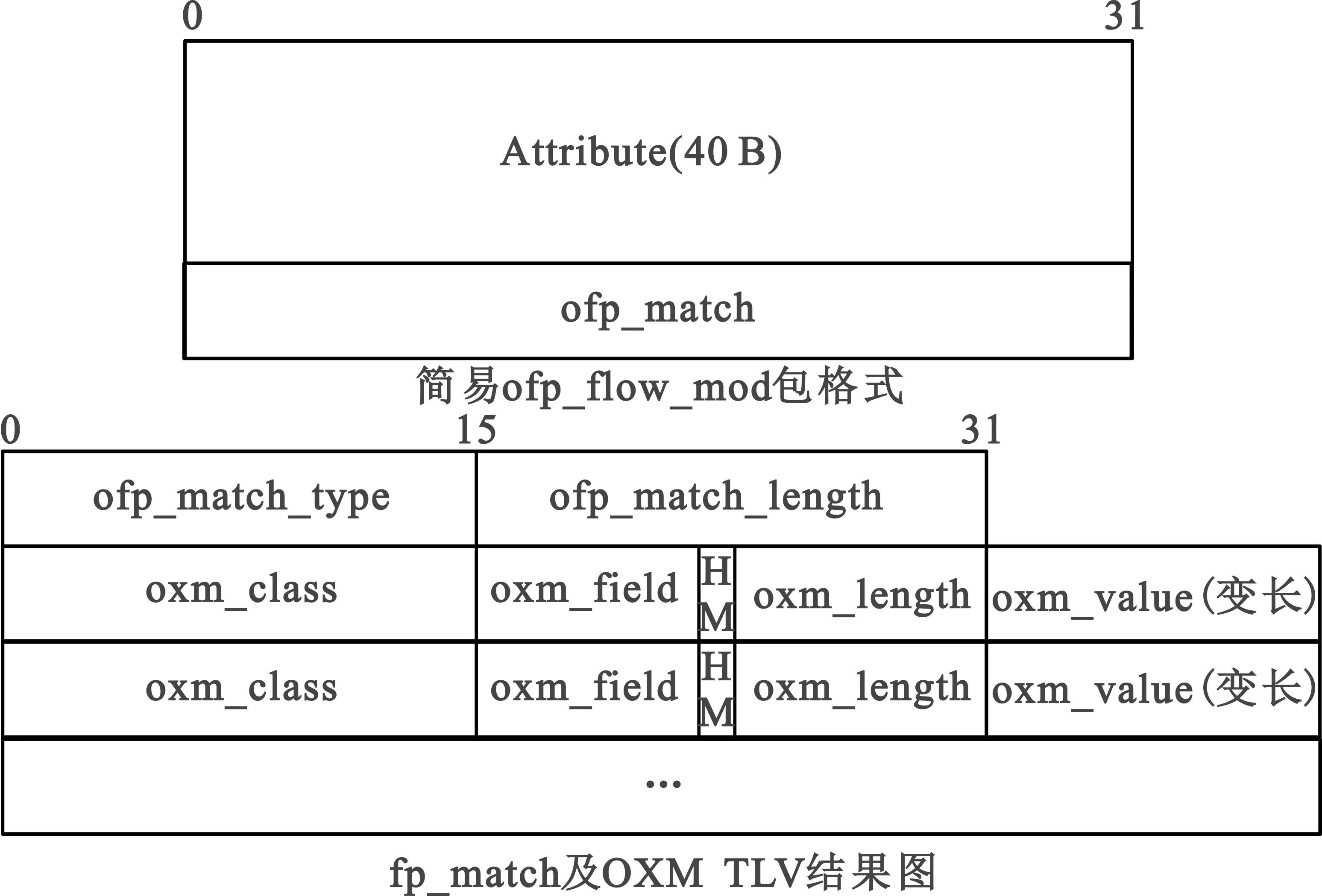
图2 ofp_flow_mod及ofp_match包格式图
由于在无人机自组网的场景下没有类似传统SDN有线网络中的物理端口,因此将flow_mod包中的出端口out_port改为out_ip,指导flow_mod包的流向;在匹配域ofp_match中,主要使用ETH_DST、ETH_SRC、IPV4_SRC、IPV4_DST这4个元组,而由于无线链路条件的限制,应尽量减少开销,因此舍弃以太网的源、目的元组,同时增设IP地址的下一跳地址来弥补以太网地址的功能。
2 问题描述
在控制器节点到某交换机节点存在多跳的情况中,若采取传统的流表下发模式,控制器无人机节点会采用单播的方式,将每个交换机的流表分发给每一个交换机无人机节点,这样会多出许多头部开销并使问路消息(Packet-in消息)增多,且各类消息较多会造成无线链路环境不稳定。因此考虑采取组播切包的策略,在此种链路情况下进行流表下发。
在组播切包的策略的基础上,可以发现组播发包会导致flow_mod包过大,特别是在一条链路上节点多的情况下会导致切包次数变多,从而增加了头部的开销,也为切包组包增加了困难。可以发现,流表下发时,每条ofp_match流表匹配域都包含源地址、目的地址等相关信息,然而对于同一交换机节点来说源地址部分就会产生浪费,同时对于网内每一个交换机节点来说它们到网中的其他节点的目的元组也重复了一部分。
3 低开销自适应流表下发机制
3.1 流表组播下发切包重组去尾策略
针对控制器节点到某交换机节点存在多跳的情况下,原OpenFlow v1.5协议中flow_mod通过单播逐一为每个交换机下发流表,会导致无线链路的不稳定、多余的头部开销与无线资源利用率不高的问题,采用组播下发流表切包重组策略。本策略基本思路为:控制器节点在将流表主动分发到网络中各个交换机的过程中,如果能够使用组播方式,通过一个控制包向多个交换机发送流表,则采用组播方式替代原来的单播方式进行流表分发;在组播分发的过程中,根据节点的梯度(即节点距离控制器的跳数),采用由近及远的分发原则以便保障在需要时有流表可用,且每经过一个节点都进行去尾工作,尽量减少下一次转发的开销;当无线链路条件只能装载部分组播流表时,流表和流表项可以分拆;但分拆后总的控制包的开销相比于流表单播情况下的控制包的开销不能增加,如果通过计算发现总开销增加则不进行组播下发,而采取单播下发的方式。
在组播过程中,由于无线链路资源有限,选择对组播包进行分片切包发送。为了便于分片后的组播包完整无错的合成,需要对OpenFlow包头结构进行适当的改进优化。首先OpenFlow包头结构所有字段全部保留,不作删减,但是缩减xid字段的大小由原先的4 B的长度缩为2 B,空余出的2 B用来进行切包组包工作,这样既不增加头部开销同时也具有了切包组包的能力。OpenFlow新旧包头对比如图3所示。
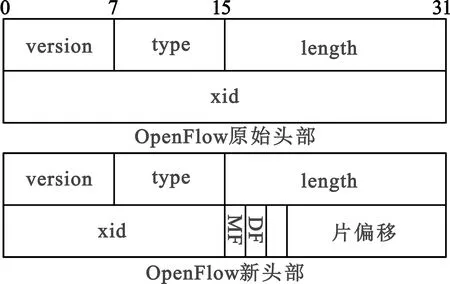
图3 OpenFlow新旧头部对比图
OpenFlow包头结构最后2个字节16位为cut-package,其中前三位是标志,标志的最低位记为MF,MF为1,表示后面“还有分片”,MF为0则表示这是若干分片的最后一个;标志字段中间一位记为DF,DF为1代表“不能分片”,DF为0时才允许分片;标志的最后一位暂时不做安排;后13位是片偏移,代表某分片在原包的什么位置。
本策略基本步骤如下:
Step1 控制器获取全局拓扑并计算全局路由后,生成相关匹配域,若满足组播下发条件,则给一条链路最远端(即最大梯度节点)交换机节点发送flow_mod包,将out_ip填充去最远端节点的下一跳地址,同时携带这条链路上其他交换机节点的ofp_match匹配域和匹配域对应的属性,形成flow_mod组播包,然后根据无线链路的资源进行切包发出,每个分片都带有相同的OpenFlow新包头、 xid、标志位和不同的片偏移,以便到达第一个交换机时进行正确的组包。
Step2 当flow_mod包所有分片到达第一个交换机时,将所有xid相同的分片通过标志信息和片偏移重新组合成一个完整正确的包。然后,交换机提取匹配域中源地址是本机的ofp_match,并删除flow_mod包中源地址是本机的ofp_match部分,进行去尾,此时flow_mod包比在控制器时少了一个交换机的流表,计算已经去尾的flow_mod包的大小,若无线链路资源仍不够用,置DF为1,表示仍然需要切包转发;反之,若无线链路资源够用,置DF为0,表示不需再切包。而包的流向out_ip则根据flow_mod包中剩余的ofp_match中梯度最大的值的地址作为目的节点,并查找刚刚提取的ofp_match,获得到最大梯度节点的下一跳地址,并存入out_ip,最后将剩余重组的flow_mod组播包进行转发。
Step3 接下来此条链路上的交换机节点皆如第一个交换机节点一样对flow_mod包进行处理,直到flow_mod包中的ofp_match部分删完,且flow_mod包到达最远端交换机节点结束。
通过以上步骤,可以使flow_mod包与OpenFlow包头在不增加额外开销的情况下进行切包组包并将各交换机节点流表下发。
3.2 流表源、目的地址自适应压缩策略
针对组播flow_mod消息中ofp_match匹配域中流表信息的重复冗余的问题,在不影响需要发送的流表完整性的情况下,通过对流表的自适应压缩,自适应地减少多余的源地址与目的地址元组,从而减少组播包的开销与组播包在传输时的切包次数。
流表自适应压缩策略的基本思路为:在组播中,对于一个交换机节点的多个流表而言,源地址重复占用开销,因此使匹配域中每个交换机节点的源地址只有一个,这一个源地址对应其到多个交换机的多个下一跳地址、跳数与流表属性,这样每个交换机节点都可节省多个源地址的开销。对于多个交换机节点的多个流表而言,目的地址也是一致的,因此只需要一份总的目的地址的信息,这样又将减少多个目的地址的开销。
对于一条链路上N个交换机节点、N-1个多跳交换机节点,流表压缩与flow_mod组播包生成步骤如下:
Step1 控制器节点计算全局路由之后,首先存一份所有网络节点的地址作为一份目的地址放入组播包的匹配域。
Step2 控制器节点得知一条多跳链路上最远端节点梯度为N后,首先将此条链路最远端节点的源地址存一份到匹配域中,然后将最远端节点到自组网内其他节点的下一跳地址对应其属性按照Step 1中目的地址的顺序依次存入组播包中。
Step3 控制器节点查找全局路由表,找到从自己到最远端节点的路由,找到目的节点的前一跳节点地址prev_addr,此节点距控制器节点梯度为N-1,与Step 2一样,存一份prev_addr地址到组播包的匹配域中,然后将此节点到网内其他节点的所有流表对应其属性依次存入组播包中。
Step4 重复Step 3的流程,找到梯度为N-2一直到梯度为1的节点,依次存入组播包中。
Step5 组播包生成完成,流表自适应压缩完成。
通过以上的步骤,可以实现流表的自适应压缩,有效地利用有限的无线资源,减少流表下发时的总开销。
4 验证分析
4.1 理论性能分析
在理论性能分析中,主要将OpenFlow v1.5的flow_mod包在无线网络下进行单播下发与本文机制的流表组播下发进行理论上的开销性能比较,后续在仿真中对开销和其他网络性能进行实验验证。
理论性能分析中,MTU为无线信道的单次传输的最大传输单元(假设MTU至少大于单个flow_mod包长,不然单播也要切包,没有意义);N为此条链路上控制器节点到最远端所需的跳数与交换机节点个数,也就是表示每个交换机节点都最少收到N条流表项,包括此交换机节点到控制器节点与到此网络中其他N-1个节点;Lofp_header为OpenFlow包头长度,Lflow_mod为flow_mod包长度,
Lflow_mod=Lattribute+Lofp_match,
(1)
Lattribute为一条流表项的属性,Lofp_match为匹配域,其中包括OXM格式匹配域头部(Lmatch_header)与OXM的源(LOXM_SRC)、目的(LOXM_DST)与下一跳IP地址(LOXM_NEXT)这3个元组。单个交换机节点所接收flow_mod包长如公式(3)所示:
Lofp_match=Lmatch_header+LOXM_SRC+LOXM_DST+LOXM_NEXT,
(2)
L单=N(Lattribute+Lofp_match) 。
(3)
给一条链路最远端节点下发流表需要先将最远端节点链路上的前N-1跳节点全部下发完毕,才能发到最远端,因此流表下发到最远端节点所需的总开销为给这条链路上所有节点下发的所有单个节点的多条流表项的开销之和。
单播下发流表总开销如公式(4)所示:
(4)
流表组播下发时flow_mod包长如公式(5)所示,nrf为已经过的交换机节点个数。
L组播=N2Lflow_mod-nrfNLflow_mod。
(5)
流表组播下发每一跳的切包次数如公式(6)所示:
(6)
(7)
流表组播下发到最远端节点的总开销可通过3.1节策略并考虑切包后的头部推算出来,如公式(8)所示:
(8)
根据3.2节的流表自适应压缩策略,每个节点的所有流表总flow_mod包长度如公式(9)所示,包括N条流表项的属性与下一跳IP地址、1份源IP地址。
L单flow_mod=NLattribute+LOXM_SRC+NLOXM_NEXT。
(9)
自适应流表压缩flow_mod组播下发时包长如公式(10)所示,包括N+1个目的地址与1个匹配域包头,nrf为已经过的交换机节点个数。
L流表压缩组播=(NL单flow_mod+(N+1)LOXM_DST+Lmatch_header)-
nrfL单flow_mod
(10)
自适应流表压缩组播下发每一跳的切包次数如公式(11)所示,ncut_packet取值如公式(7)所示。
(11)
由上述分式可推算出加上流表自适应压缩策略的总开销如公式(12)所示:
(12)
根据以上开销公式,将2.2中流表结构与包结构模型的大小代入其中,可以得出计算结果如下:
C单播=38(N3+N2),
(13)
(14)
(15)
通过单播流表下发与组播流表下发比较可得
(16)
由公式(16)可知,只需比较(MTU-8)(4MTU-304)部分即可。根据图4(a)可得出结论:当MTU小于76 B并大于8 B时原协议单播开销比组播流表下发开销小,但单个flow_mod包加OpenFlow头部开销刚好是76 B,因此,组播流表下发在开销方面比原协议单播下发有一定的提升。
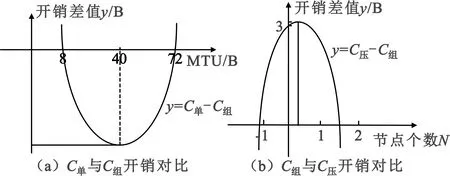
图4 理论开销对比图
在以上分析的前提下,比较组播流表下发与流表自适应压缩的组播下发可得
(17)
由公式(17)可知,只需比较(-5N2+N+8)部分即可。根据图4(b)可得出结论:当节点数(或梯度)N大于等于2个时,流表自适应压缩后的开销比正常组播下发有较大提升。
4.2 仿真验证分析
使用Windows 7系统平台上的OPENET 14.5仿真软件对本文机制进行仿真验证,仿真参数设置如表1所示,设置了5个仿真场景,仿真时间为100 s;节点数分别为5、10、15、20、25个,节点在1 500 m×1 500 m的矩形区域链状分布,节点移动速度为15 m/s,最大传输单元MTU为1 500 B;数据包长为512 B,flow_mod包消息周期为10 s,其中hello消息周期为5 s,tc消息周期为15 s,hello消息与tc消息用来进行无人机自组网场景下的链路发现,类似于SDN中的链路发现协议(Link Layer Discovery Protocol,LLDP)。
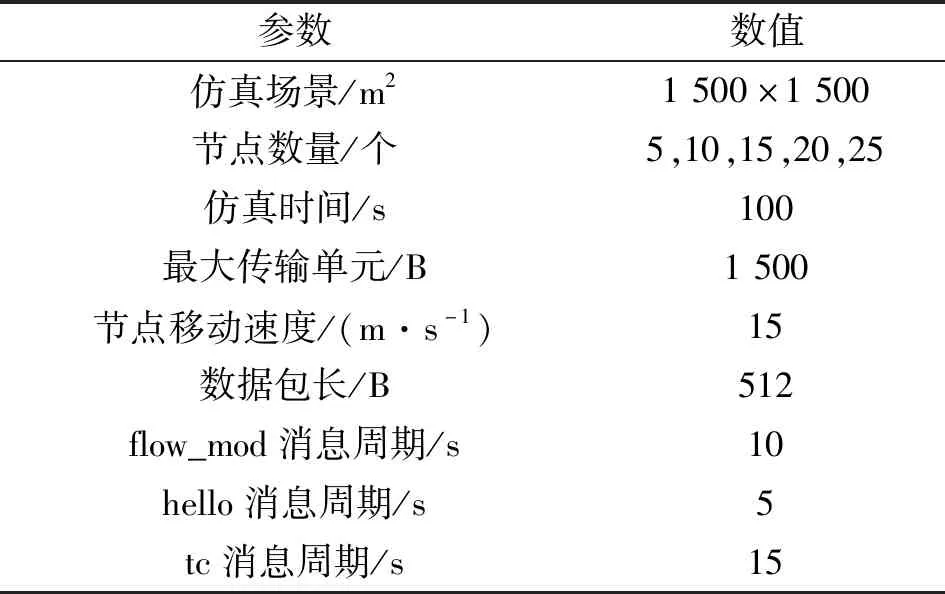
表1 主要仿真参数
4.2.1 网络控制开销
图5表明,使用自适应流表压缩组播下发机制在开销方面比原协议中单播下发流表有着明显改善,在节点数为25个时,流表压缩组播下发相较于原协议节省了33.69%的开销,且节点数越多,节省的开销就越多。原因在于,首先是组播策略节省了部分头部开销,且节点数越多,节省的头部开销就越多;然后便是源、目的地址自适应压缩策略,去除了多余源、目的地址的冗余,同样也是节点数越多,自适应压缩的源、目的地址就越多,节省了大部分的开销。
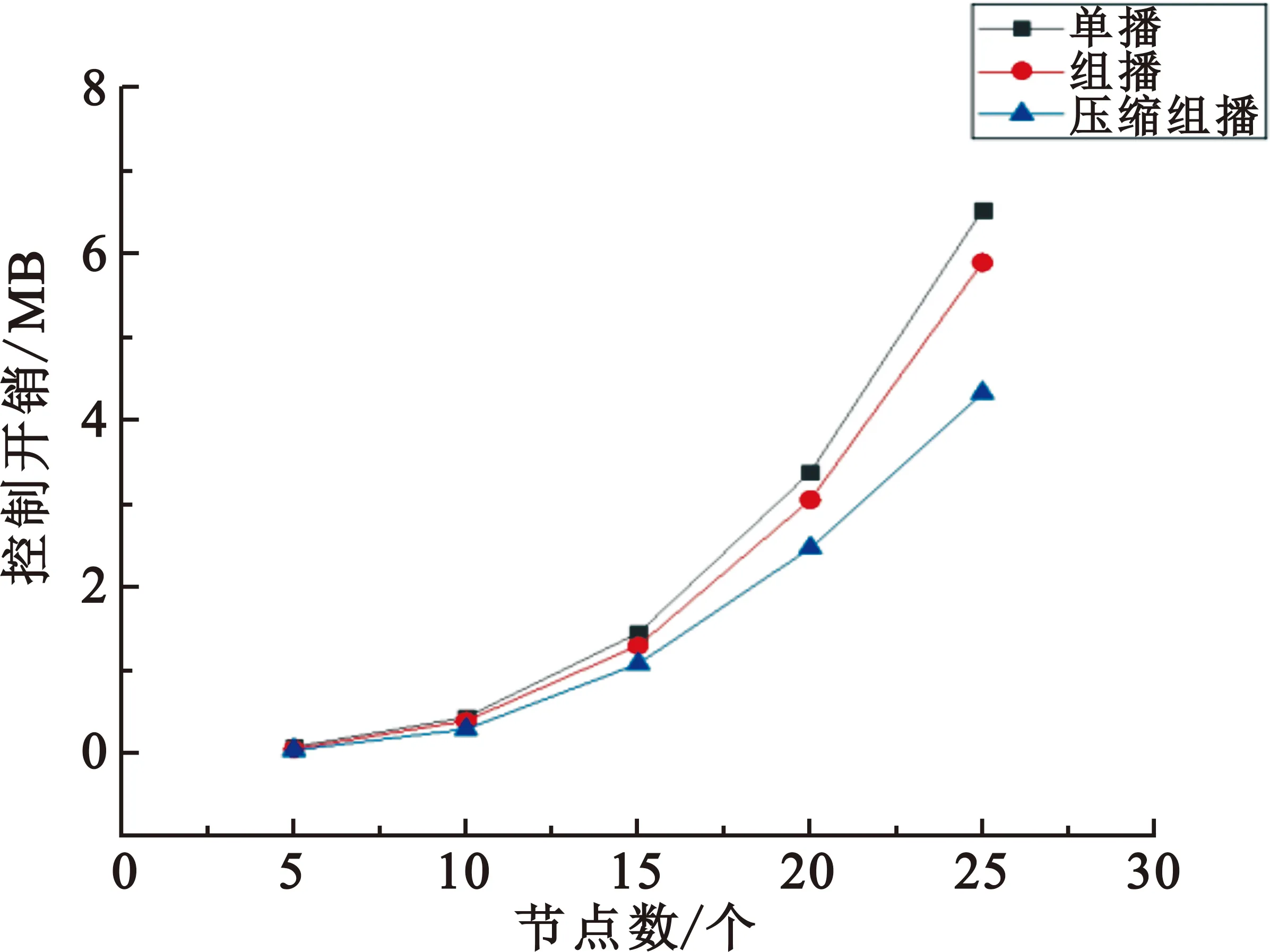
图5 控制开销仿真对比图
4.2.2 平均端到端时延
图6表明,在节点为25个时,使用两种策略的系统相较于原协议数据包平均端到端时延方面降低约12.42%,且节点数越多端到端时延减少的越明显。原因在于,拓扑发生变化,原协议找不到路由时需携带部分数据包或完整数据包向控制器节点问路,但由于拓扑变化,可能找不到去控制器节点的路由,因此时延大大增加;而组播下发流表与压缩流表下发的方式是周期性的,可减少向控制器问路情况,从而降低时延;且随着节点数的增多,原协议会更不好问路,导致端到端时延更长;而组播下发流表与压缩流表下发的方式端到端时延几乎一致,是因为这两种下发流表方式的区别仅在于压缩组播更节省下发流表时的开销,但是这两种方式下发流表的机制是一样的,都是将单播的flow_mod包进行组播切包转发。

图6 端到端时延仿真对比
4.2.3 吞吐量
图7表明,在节点为25个时,使用两种策略的系统相较于原协议数据包吞吐量方面提升约9.29%。原因在于,通过组播下发流表机制,各节点拥有到目的节点的匹配域更长,数据包根据匹配域转发的次数也就更多,吞吐量也就越高;且由于网络规模的增大与时间的增加,吞吐量也会随之降低,这就导致单播情况下的吞吐量相对于低时延的无人机场景可能达不到预期,而组播相对于单播有所提升,能更好地适应于无人机场景。

图7 吞吐量仿真对比图
4.2.4 丢包率
图8表明,使用组播下发流表策略相较于原协议单播下发流表丢包更少,且两种组播下发方式丢包率相差不大,在节点数为25个时本机制相较于原协议丢包率降低15.33%。原因在于,组播下发是周期性的,各交换机节点无到指定地址的匹配域的时间段较少且短,而两种组播下发方式丢包率相差不大是因为它们核心机制一样,只是压缩组播下发更加节省了开销,但是这两种方式下发流表的机制是一样的,都属于将单播的flow_mod包进行组合切包转发这种方式,因此两种组播下发方式丢包率相差不大;而原协议单播下发流表,由于拓扑的变化,交换机找不到控制器节点,这样会导致随着节点数的增加丢包率上升越快。
5 结束语
本文通过对OpenFlow v1.5中flow_mod包与其所包含匹配域的基础上,提出了一种低开销自适应的组播流表下发机制,使其更加适应于无线自组网络中多跳复杂的网络情况。该机制给最远端节点下发流表时,通过连带的形式将这条链路上所有节点的流表一同组播下发,并在流表下发的过程中进行去尾,最后对繁多的匹配域的源地址、目的地址进行自适应压缩。理论与仿真实验证明,此机制极大地降低了开销并提升了无人机自组网的稳定性,进一步提升了网络性能。
下一步将继续对无线中OpenFlow协议的控制器寻路算法进行深入研究,使其能更快地寻找全局拓扑并减少寻找全局拓扑时的冗余开销。
猜你喜欢
词学(2022年1期)2022-10-27
计算机系统应用(2022年5期)2022-06-27
网络安全与数据管理(2022年3期)2022-05-23
移动通信(2021年5期)2021-10-25
数码世界(2020年11期)2020-11-23
空间科学学报(2020年3期)2020-07-24
电子制作(2019年20期)2019-12-04
网络安全和信息化(2019年7期)2019-07-10
电子制作(2019年24期)2019-02-23
火控雷达技术(2018年4期)2019-01-15
