
基于深度学习的颅脑损伤机制自动化鉴别
2022-07-31 14:14杨琦帆孙雪阳王彦斌田志岭董贺文万雷邹冬华于笑天张广政刘宁国
法医学杂志 2022年2期
杨琦帆,孙雪阳,王彦斌,田志岭,董贺文,万雷,邹冬华,于笑天,张广政,刘宁国
1.郑州大学基础医学院法医学系,河南 郑州 450000;2.司法鉴定科学研究院 上海市法医学重点实验室 司法部司法鉴定重点实验室 上海市司法鉴定专业技术服务平台,上海 200063;3.中国合格评定国家认可中心,北京100062
致伤方式推断是法医学鉴定的难点之一,准确的致伤方式判断可以为案件侦查提供线索,还可以为司法审判提供证据[1]。头部致伤方式通常分为直接暴力和间接暴力,直接暴力导致的颅脑损伤有多种,其中,直线运动引起的加速性损伤和减速性损伤最常见。由于加、减速性脑损伤涉及头部打击伤或摔跌伤两种形式,故对其准确鉴别在法医学实践中具有重要意义[2]。传统的加、减速性脑损伤推断主要通过观察损伤的形态学特征。然而,鉴定实践中往往由于某些条件的限制致使尸体解剖无法进行,例如某些排除他杀后的死亡案件或死因明确的交通事故案件,其家属通常会拒绝进行尸体解剖,还有一些民族因宗教信仰等不能进行死后解剖,在无法准确获得颅脑损伤形态的情况下,往往导致案件侦查及司法审判难以进行[3]。针对这一问题,法医学工作者自20 世纪90 年代便开始尝试将现代医学影像技术应用于尸体检验,并由此出现了虚拟解剖技术[4-6]。近年来,虚拟解剖的开展使得加速性颅脑损伤与减速性颅脑损伤的鉴别更为方便、直观。然而,鉴于鉴定人员大多并非擅长影像学专业,实际读片时难免存在主观性和经验性,导致判断结果存在差异,而虚拟解剖中的大量影像学数据无形中也加重了鉴定人员的工作负担。如果能够建立一种快速、准确的加、减速性颅脑损伤分类方法,则可迅速解决法医工作者面临的实际难题。
目前,深度学习技术快速发展,其在图像分析领域取得的巨大成功为解决上述问题提供了一种可能途径。深度学习的概念最早由HINTON 等[7]于2006 年提出,其核心是特征提取,即通过设计卷积神经网络(convolutional neural network,CNN)模型从大量数据中提取客观特征并利用提取到的特征对未知数据进行预测和分类。CNN 模型可以自动学习这些标注过类别的训练数据,并总结出可以表征所标注数据特征的函数,之后根据这个函数测试新的未标注过的数据可以得到一个可靠的预测结果[8]。经过十几年的发展,CNN 的算法不断优化、结构不断加深,在图像分类中的准确率得到显著提升。目前,已有多种CNN 模型被提出并广泛用于医学图像分析领域,如皮肤癌的分类[9]、糖尿病视网膜眼底病变的检测[10-11]以及骨龄评估[12-16]等。
Inception_v3 模型是近几年图像分类研究中比较常用且表现良好的一种经典CNN 模型,因此,本研究拟选用Inception_v3 模型对颅脑损伤的CT 图像进行加、减速性损伤的自动化鉴别研究,探讨CNN 模型用于辅助头部致伤方式推断的可行性。
1 材料与方法
1.1 样本收集
收集190例司法鉴定科学研究院法医临床学研究室2007—2018 年关于颅脑损伤被鉴定人的颅脑影像学资料,包括109 例加速性脑损伤和81 例减速性脑损伤,由影像学专家完成影像学诊断。同时选取130 例正常颅脑的影像学资料作为对照。本研究已获得被鉴定人或其家属的同意,并经过司法鉴定科学研究院伦理委员会批准。
纳入标准:(1)筛选典型的加速性脑损伤案例和减速性脑损伤案例,其中加速性损伤包括徒手伤和工具伤,减速性损伤包括高坠、平地摔跌和交通事故;(2)造成颅脑直接损伤;(3)头颅为单一受力部位;(4)伤后24 h 内进行头颅CT 扫描。
排除标准:(1)头颅受伤位置无法明确;(2)除颅脑外,身体其他部位为首次受力部位;(3)穿透性脑损伤。
采取随机抽样的方式从上述320 例颅脑影像学资料中抽取70%作为训练验证集,用于模型训练和参数优化,其余30%作为测试集,用于评估模型分类性能。
本研究中训练验证集、测试集的基本信息见表1,训练验证集、测试集被鉴定人在性别、年龄、损伤类型方面差异无统计学意义(P>0.05)。

表1 训练验证集、测试集样本分布情况Tab.1 Distribution of training validation dataset and testing dataset(例)
1.2 图像预处理
为了更好地训练模型,需要对原始颅脑CT 图像统一进行预处理:
(1)颅脑CT图像为Inception_v3模型的样本来源,使用Python 3.9 软件(美国Google 公司)对图像进行预处理。人工截取影像数据集中所有阳性所见断层的图像,并裁剪掉图像上的无关内容,如片号、姓名、拍摄日期等。
(2)将图像调整为同一大小,均为512 像素×512 像素。
(3)图像增强。为了扩大样本量,本研究通过随机旋转(范围-30°~+30°)、随机翻转(增加了概率是0.5的随机翻转)及随机亮度、对比度、色度及饱和度等方式对图像进行增强。
(4)合成RGB 图像。本研究选取CT 序列中连续的三帧分别作为R、G、B 通道合成一张彩色图片。如果三帧中至少存在一张加速性损伤就标记为加速性损伤,至少存在一张为减速性损伤就标记为减速性损伤,其余标记为正常。
最终,共合成1 239 张RGB 图像,其中:1 122 张为训练验证样本,用于Inception_v3 模型训练和参数优化,包括470 张加速性脑损伤图像、390 张减速性脑损伤图像及262 张正常颅脑图像;117 张为测试样本,对已训练好的Inception_v3 模型的分类性能进行检测,包括30 张加速性脑损伤图像、18 张减速性脑损伤图像及69 张正常颅脑图像。
1.3 模型构建与训练
1.3.1 模型构建
本研究构建了Inception_v3 模型框架用于鉴别加速性脑损伤与减速性脑损伤,Inception_v3模型的整体结构如图1所示。Inception_v3模型主要由包含不同数量卷积层和池化层的Inception 模块和Reduction 模块构成。其中Inception 模块增加了模型架构的宽度,有利于从输入图像中提取不同层次的特征,而Reduction模块则有效降低了计算量,使模型便于训练。图的下方展示了模型各个模块的详细结构。两个模块的排列顺序不同,模块中的卷积层主要用于提取图像信息,而池化层主要用于提取图像最明显的特征,并将所获得的特征数据和参数进行压缩从而减少模型过拟合。

图1 Inception_v3 模型整体结构图Fig.1 The integral structure diagram of Inception_v3 model
1.3.2 参数设置及算法优化
本研究使用迁移学习,即模型在训练前已经在ImageNet 上进行了训练,并将训练好的权重作为初始权重,然后再在本研究收集的数据集中进行训练。Inception_v3模型在1 122个训练验证样本中进行学习训练,最大训练周期设为1 000,学习率设为0.000 1,最小批量尺寸设为16,共计迭代100 轮,使用Adam 优化算法以降低交叉熵损失函数;激活函数设置为线性整流函数(rectified linear unit,ReLU),最后使用Softmax分类函数进行图像分类,以样本图像作为输入,以图像的损伤类别作为模型训练的目标结果。每一轮训练过程(训练集)结束后进行结果验证(验证集),并保存表现最好的模型参数。在模型分类准确率没有进一步提高时停止训练,保留该模型用于测试集117 个测试样本的检测,评估模型的分类性能。
本研究基于i9-11900K+RTX 2080Ti 硬件平台的Windows 10.0 操作系统。算法开发过程借助PyCharm软件(捷克JetBrains 公司),使用Anaconda 进行开发环境管理。语言环境基于Keras-GPU 以及Python 3.9软件。
1.4 模型评估
本研究选取准确率(accuracy rate)、精确率(precision rate)、召回率(recall rate)、F1 值及受试者操作特征(receiver operating characteristic,ROC)曲线下面积(area under the curve,AUC)值对Inception_v3 模型的分类表现进行评价。准确率表示模型预测正确的样本在所有测试集样本中所占的比例;精确率表示真正的正样本在预测为正的样本中所占的比例;召回率表示预测为正的样本在测试集所有正样本中所占的比例;F1 值是一个综合评价指标,综合了精确率和召回率的结果,模型F1 值越高表示其性能越好。计算公式如下:

模型在测试集中的真阳性率、假阳性率、真阴性率及假阴性率通过绘制混淆矩阵获取。混淆矩阵作为人工智能的一种可视化工具,将CNN 模型预测情况与实际情况的所有结果进行组合,从而形成真阳、假阳、真阴及假阴4 种情形,并用于计算模型三分类的准确率、精确率、召回率及F1 值。
以FP 为横轴、TP 为纵轴绘制的曲线图即为ROC曲线,AUC 是绘制ROC 曲线时另一种评估模型分类准确率的指标,取值范围为0~1,取值越接近1,说明模型分类性能越好。
此外,梯度加权类激活映射(gradient-weighted class activation mapping,Grad-CAM)是一种为CNN模型输出结果生成“可视化解释”的技术,从而使CNN模型分析图像的过程更透明以及使预测结果更容易解释。因此,为了更好地理解模型是如何根据输入图像做出最终的分类决策,本研究将模型生成的Grad-CAM 图像与原始颅脑CT 图像进行对比,可视化探讨模型在识别并提取图像特征进行预测时聚焦的像素区域是否与颅脑CT 图像中的出血区域相符合。
2 结果
2.1 模型训练和参数优化
模型在训练过程(训练集)和验证过程(验证集)中的损失函数与准确率变化情况如图2 所示。
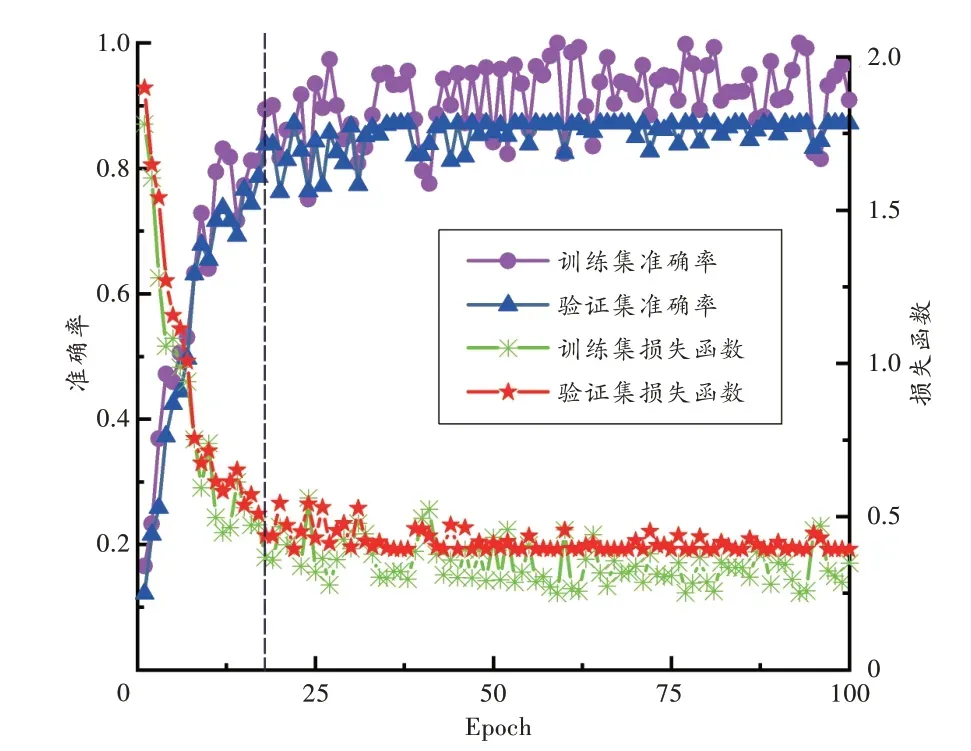
图2 模型损失函数与准确率变化示意图Fig.2 Schematic diagram of model loss function and accuracy rate change
由图2 可知:模型在分类准确率没有得到进一步提高时已得到了充分的训练;约于第18 次Epoch(黑色虚线处)后逐渐平稳,分类准确率在训练过程中最高可达到99.00%,在验证过程中最高可达到87.21%。
2.2 模型在测试集中的分类表现
2.2.1 分类检测及识别效果评价
首先,将训练和参数优化后的Inception_v3模型在117 个样本的测试集中进行分类检测。然后,将模型分类预测的结果与真实情况进行对比分析。最后,再通过计算模型在测试集中的准确率、精确率、召回率及F1 值等参数,分别评价模型在加速性脑损伤、减速性脑损伤和正常颅脑图像三分类中的识别效果。
识别预测结果表明:(1)在加速性损伤的30 张图像中,被识别为加速性损伤(结果正确)的有27 张,被误识别为正常颅脑(识别错误)的有3 张,没有被误识别为减速性损伤的情况;(2)在减速性损伤的18 张图像中,被识别为减速性损伤(结果正确)的有13 张,被误识别为正常颅脑(识别错误)的有5 张,没有被误识别为加速性损伤的情况;(3)在正常颅脑的69 张图像中,被识别为正常颅脑(结果正确)的有62 张,被误识别为加速性损伤(识别错误)的有5 张,被误识别为减速性损伤(识别错误)的有2 张。计算出模型在测试集中的三分类准确率为87.18%。上述识别结果以混淆矩阵的形式表示,详见图3。
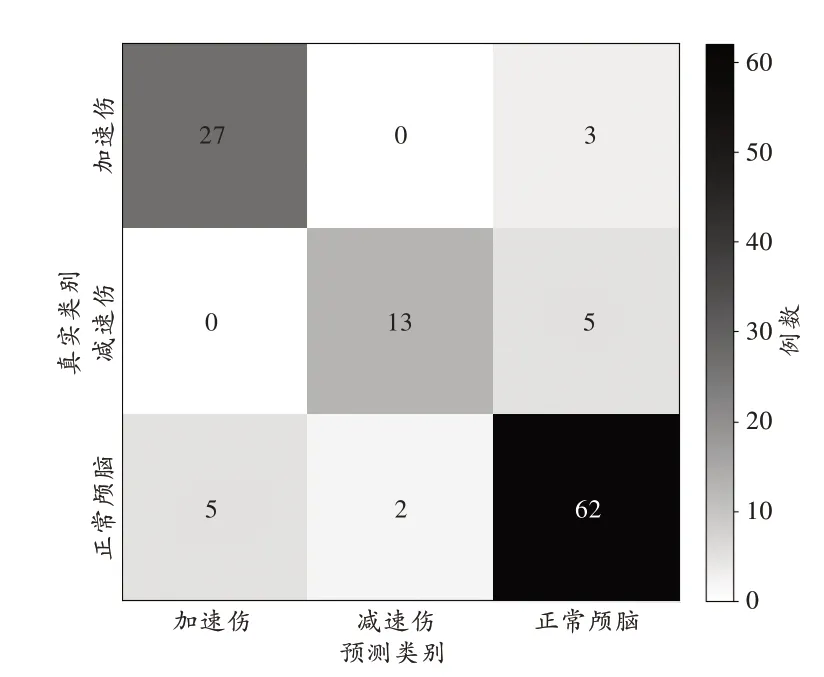
图3 模型在117 个测试样本中的混淆矩阵Fig.3 The confusion matrices of the model using 117 testing samples
基于混淆矩阵,进一步计算评估参数,分别评价模型在3 种图像(加速性损伤、减速性损伤及正常颅脑)中的识别效果,结果见表2。由于F1 值是一个较为综合的评价指标,故一般以F1 值判断模型的性能。由表2 可知,该模型识别加速性损伤(87.10%)和正常颅脑(89.21%)的性能优于减速性损伤(78.79%)。

表2 Inception_v3 模型在测试集中的分类结果Tab.2 The classification results of Inception_v3 in the testing dataset(%)
2.2.2 模型分类性能的ROC 曲线评估
图4 为模型在测试过程中的ROC 曲线,绿色曲线代表加速性损伤,橙色曲线代表减速性损伤,蓝色曲线代表正常颅脑。曲线越靠近左上角,AUC 值越大,模型识别性能越好。由图4 可明显看出,3 种图像的AUC 值均达到了0.90 以上。

图4 模型在测试集中的ROC 曲线图Fig.4 The ROC curves of the model in the testing dataset
2.3 Grad-CAM 图像
图5 为原始颅脑CT 图像及模型正确分类时生成的Grad-CAM 图,其中图5A、5B 为原始图像,图5C、5D 分别为图5A、5B 对应的Grad-CAM 图像。Grad-CAM 图中,红色区域表示计算机高概率区,是为模型判定图像类别贡献较多的区域;蓝色区域则表示计算机低概率区,是为模型判定图像类别贡献较少的区域。显而易见,模型高概率区的分布与颅脑CT 图像中出血区域的分布基本一致,由此可推测模型判定图像类别是根据出血区域分布进行的,这与人类根据颅脑CT 图像中的损伤分布特点鉴别加、减速性脑损伤的思路基本一致,可见模型能够较好地模拟人类阅片过程。

图5 原始颅脑CT 图像及其对应的Grad-CAM 图像Fig.5 Original CT image and the corresponding Grad-CAM image
3 讨论
图像识别是计算机视觉领域的一个重要研究方向,始于20 世纪40 年代[17]。图像识别领域的研究发展至今出现过多种识别方法,其中CNN 是目前完成图像识别任务的最佳方法之一[18]。CNN 不需要人工提取特征点,可以通过建立多层次的网络联系,自动从海量数据中学习知识,预测效率及准确性更高,多次在ImageNet 大规模视觉识别挑战大赛中取得优异的成绩[19-21]。目前,国内外已发表文献中关于CNN 分割颅内出血及预测颅内出血亚类型的研究较多[22-27]。
本研究以Inception_v3 模型为例探讨了CNN 模型在通过颅脑CT 图像分类加、减速性脑损伤中的应用价值。结果显示,模型在训练验证集、测试集中对3 种图像(加速性脑损伤、减速性脑损伤及正常颅脑)的分类准确率高达99.00%、87.18%。鉴于本项分类研究的操作流程及设计思路与其他应用CNN 模型对病变颅脑和正常颅脑或损伤颅脑和正常颅脑进行分类的研究[28-30]没有太大差别,故将本研究结果与其他分类研究结果进行对比。AOE 等[28]开发了一种基于静息状态脑磁图(magnetoencephalography,MGE)信号对患有神经疾病的大脑和正常大脑进行分类的深度学习算法,实验结果显示,该算法的分类准确率为(70.7±10.6)%,表明这种深度学习算法有望发展为一个用于提高神经系统疾病诊断的分类器。SARRAF等[29]运用CNN 分类患有阿尔茨海默病(Alzheimer’s disease,AD)的大脑和正常大脑,结果显示,该模型分类准确率高达96.85%。GARLAND 等[30]利用CNN 区分致命损伤大脑和正常大脑,结果显示,该模型的分类准确率为70%~92.5%,表明CNN 有望在未来成为一种计算机辅助诊断方法或筛查工具。将本研究结果与上述研究结果进行对比,发现本研究结果总体上是有意义且比较理想的,证实了基于CNN 模型通过颅脑CT 图像辅助鉴别加、减速性损伤是可行的,便于法医鉴定人在此基础上进一步分析致伤方式,从而有利于降低鉴定人阅片工作量并提高工作效率。
如表2 所示,本研究中Inception_v3 模型识别正常颅脑的F1 值最高,这与鉴定实践中法医工作者识别正常颅脑组织较容易基本一致。此外,Inception_v3模型在识别加速性损伤时的F1 值较高,考虑可能与训练验证集中加速性损伤图像数量较多有关。然而,本研究中Inception_v3 模型识别减速性损伤的F1 值较低,考虑可能与以下原因有关:(1)不同部位造成的减速性损伤形态可能并不相同,如枕部受力时减速性损伤可能更典型;(2)一些减速性损伤可能并不具有典型的对冲伤特征,从而使判断存在难度;(3)颅骨复杂的解剖生理结构导致部分对冲伤并没有出现在着力点正对侧。由图5 可知,从该模型输出判断为减速性脑损伤的Grad-CAM 图像中可以清晰看出,图中的“兴趣区”与原始CT 图像中的出血区域基本吻合,故推测该模型在对输入图像进行分类时很有可能是依据所提取到的出血区域分布特征,这与人类根据颅脑CT 图像中的损伤分布特点鉴别加、减速性脑损伤基本一致,可见模型能够很好地模拟人类阅片过程。
此外,笔者认为本研究的特色在于:(1)合成RGB图像。由于现代医学影像学图像的储存方式主要是DICOM 格式,故法医鉴定人阅片通常是基于一帧帧连续变化的颅脑CT 图像而并非一张张独立的断层图像。因此,本研究通过将CT 序列中连续的三帧合成一张RGB 图像,一方面便于模型模仿人眼判断受伤类型,另一方面有利于最大程度地还原损伤从而提高识别效率。(2)与相关研究多利用深度学习算法进行二分类不同,本研究还选取了正常颅脑的影像学资料作为对照进行基于深度学习算法的三分类研究。
综上,本研究仅作为一项CNN 模型辅助鉴别颅脑损伤模式的可行性研究,并非代替法医学专家分析并解读颅脑CT 图像。CNN 模型通过提取并分析颅脑CT 图像特征,在辅助加、减速性脑损伤鉴别中具备一定的应用潜力,可以作为虚拟解剖中颅脑损伤鉴定的一种辅助分析方法或筛查工具。但本研究也存在一些局限性:(1)样本量较小;(2)简化了颅脑损伤的复杂性,如未区分具体颅脑损伤的部位、类型,未采用相应方法区分疾病性脑损伤及外伤性脑损伤;(3)模型算法有待优化。因此,在未来的工作中需要进一步扩大样本量,并细化损伤部位(如额部、顶部、枕部、颞部)、损伤类型(如颅骨骨折、硬脑膜外出血、硬脑膜下出血、蛛网膜下腔出血、脑挫伤等),尝试采取相应方法鉴别疾病性脑损伤及外伤性脑损伤,并进一步优化CNN 模型。
本研究基于CNN 模型在图像识别中的显著优势,将CNN 模型用于加、减速性脑损伤的鉴别研究取得了较为理想的实验结果,证实了CNN 在鉴别加、减速性脑损伤中的可行性。尽管本研究中CNN 模型对加、减速性脑损伤及正常颅脑分类准确率有待提高,但总体上仍是一次有意义的尝试。
猜你喜欢
健康护理(2022年3期)2022-05-26
中国药学药品知识仓库(2022年9期)2022-05-23
健康体检与管理(2022年4期)2022-05-13
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
健康体检与管理(2021年10期)2021-01-03
康颐(2020年6期)2020-09-10
右江医学(2014年1期)2014-03-22
