
生鲜产品的多变量SVR需求预测
——基于在线评论的顾客感知因素提取
2022-07-25 06:39张炎亮代沛沛
中国农业大学学报 2022年7期
张炎亮 代沛沛
(郑州大学 管理工程学院,郑州 450001)
电子商务背景下,网络零售迅速发展,越来越多的电商巨头进入生鲜领域,拓展了生鲜产品线上销售渠道,推动了生鲜行业的加速发展。2020年我国生鲜产品电商行业规模达4 584.9亿元,预计到2023年,生鲜产品电商行业规模将超万亿。在广阔的市场需求下,生鲜产品电商行业却仍面临着货损率高、盈利少等诸多问题,究其原因,部分生鲜产品电商企业通过资金投入、扩大宣传盲目拓展市场,但若缺乏准确的市场需求信息,生鲜产品极易造成积压,导致货损率增大,企业成本增加。基于此,生鲜产品电商企业须对产品需求做出迅速响应,此外相比线下销售,线上销售能为顾客提供表达购买体验、情感态度的在线评论平台,顾客在平台上可主动分享自身对产品的全方位评价,从而让潜在顾客更多了解产品信息,帮助其执行购买决策,因此在线评论在一定程度上影响了产品需求量。
在线评论是开放式表达渠道,评论内容是顾客对产品及服务的感知性评价,此评价无意中会形成一种口碑效应,影响后续产品销售。目前国内对在线评论数据与产品销量之间的关系进行了较多探讨:纪雪等量化从评论文本数据中提取出的产品属性,计算产品属性的用户满意度来确定下一代产品的开发需求。张梦莹等基于有用性排序的方法,探究出评论总数、评论时效性、情感倾向对产品销量都存在着不同程度的显著性影响。沈超等提取出产品的关键属性和非关键属性,利用决策树模型分析出了客户偏好趋势。王英等考虑品牌效应因素,基于采纳信息模型,验证了品牌强度、评论效价及评论时效度对产品销量会存在显著相关关系。胡雅淇等以农产品为研究对象,运用逐步回归的方法分析出在线评论数量、可视化评论、差评数量及评论长度均会正向或负向的影响产品销量。
国外对在线评论数据与产品销量关系的研究较多: Lau等基于情感分析方法,挖掘出评论数据中消费者情绪,并以此进行销售预测,提高了销售预测的准确度。Chen等基于实验研究认为正面或负面的补充评论的顺序会影响消费者的购买意愿,而产品的涉入程度会调整它们之间的关系。Hu以京东商城在线评论数据为例,以问卷调查和访谈的方式,探讨出经济相关评论和服务相关评论对网购行为有显著影响。Gopinath等运用动态分层线性模型,发现口碑数量能够影响口碑极性进而影响品牌绩效。Ruiz-Mafe等发现评论顺序对销量有着不同影响,当在线评论以正面评论开始时对企业销量的提升更有益处。
目前针对在线评论数据与销量关系的研究仍在继续发展,现有文献主要针对评论数据中的信息与产品销量之间的关系进行探讨,但从时间维度上看,评论信息反映了随着时间的变化顾客对产品需求的变化,如何利用挖掘出的评论信息把握产品未来需求变化、预测产品未来需求量,鲜少有研究对其进行更加深入的讨论,所以利用在线评论中顾客感知信息预测产品需求量的研究仍然较为缺乏。在此过程中,评论数据中顾客感知因素的提取是对产品需求量进行准确预测的前提。由于在线评论中数据量巨大且评论内容多是由不同词语组成,传统方法很难准确提取出顾客感知因素,因此,出现了许多用于处理大量非结构化文本数据的方法,如隐狄利克雷分布(LDA)、Word2vec模型、K-means聚类等。在众多评论文本提取方法中,相对于其他数据处理方法,Word2vec模型能够基于深度学习中的循环神经网络,结合词语上下文关系,理解文本中的语义和语法信息,在大量语料库中进行无监督学习,通过计算词向量确定两个词语之间关系远近,因此更加贴合评论文本特征,能够更全面获取产品的特征词语。此外在需求预测方面,由于提取出的产品特征数据具有多元化、非线性的特点,而SVR作为SVM的一种,在处理非线性数据上具有很强的处理能力,其能根据预测对象与其他影响因素的关系解决冗余属性问题,并且在小样本需求预测上具有较高的准确度,在处理复杂的产品特征数据上具有较大优势,因此本研究选取多变量SVR预测生鲜产品需求量。
本研究旨在以生鲜产品为研究对象,基于Word2vec模型挖掘评论文本中顾客感知的产品特征因素,并对特征因素量化处理,建立包含多个特征因素的多变量SVR需求预测模型,以期对产品需求量进行准确预测,从而使企业准确了解顾客需求,及时调整产品决策。
1 研究方法与模型
为利用在线评论中顾客感知因素对生鲜产品需求量进行准确预测,本研究构建了2个模型,分别是Word2vec模型和多变量SVR需求预测模型。
1.1 Word2vec核心思想
Word2vec是用于高效训练词向量的工具,其基本思想是一篇文章中上下文相似的2个词语,它们的词向量也应该相似。该模型主要包含2种训练方式:CBOW(Continuous Bag-of-Word)模型以及Skip-Gram模型(图1),两者均是通过单层神经网络为每个词语分配一个恒定的向量,该向量并不代表词语特征,而只是显示一个数字,构建句子或文本中每个词对应的数值向量后,将单个词的向量进行组合,可显示整个句子的数值向量。其中CBOW模型是根据句子中目标词语的相邻词(-1,-2,+1,+2)信息对目标词语进行预测,训练词向量速度较快;Skip-Gram模型是根据目标词语所在的语境推测出上下文中与它相似的词语,训练速度相对较慢,但其训练效果比CBOW模型训练效果好。鉴于本研究需要提取产品主题,对结果准确要求较高,因此采用Skip-Gram模型,将所爬取的网站评论数据作为该模型的训练集。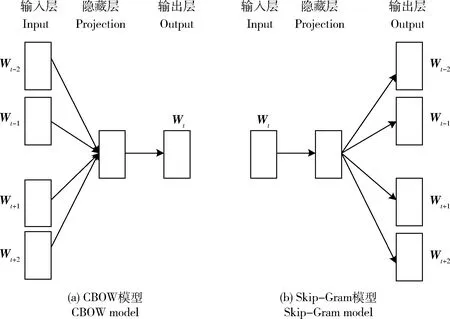
Wt为目标词语;Wt-1,Wt-2,Wt+1,Wt+2分别为目标词语的相邻词。Wt is the target word; Wt-1, Wt-2, Wt+1 and Wt+2 are the adjacent words of the target word, respectively.图1 CBOW模型和Skip-Gram模型Fig.1 CBOW model and Skip-Gram model
1.2 影响因素特征集构建
从在线评论数据中提取出顾客感知的产品特征因素,可使企业了解消费者所关注的产品特性,是对需求进行预测的前提。在线评论数据中顾客对产品特征的描述多是以词语形式呈现,因此本研究通过Word2vec模型词向量聚类的方法从大量评论数据中提取用户所关注的多个产品特征集,作为需求预测模型的输入变量。提取步骤如下:
1)中心特征词提取。提取过程中,一方面通过查阅相关文献,分析影响顾客感知、顾客满意度的相关要素,进而初步预判影响需求的主要特征;另一方面对在线评论的文本数据进行词频以及词性统计,结合所分析的顾客感知要素选取高频词语作为影响因素特征集的中心特征词。
2)Word2vec模型训练。运用python中的“jieba”分词工具对评论文本进行分词和停用词处理,并设置模型中的上下文窗口参数和词向量空间维度对模型进行训练,在设置不同参数对模型进行多次训练后,本研究将上下文窗口参数和词向量空间维度分别设为5和100。
3)特征集构建。依据中心特征词,通过Word2vec模型对词语进行多次聚类,选取相似度较高的词语作为特征词库,形成需求预测影响因素的特征集,将其作为预测变量输入到SVR模型中。
1.3 SVR预测模型构建
1
.3
.1
数据预处理Word2vec模型训练出来的结果是由一个个词语所组成的特征词库,为更好的将其输入到预测模型中,需将文本因素转化为数值因素。因每条评论中都包含着顾客所感知的产品特征,因此本研究运用经Word2vec模型聚类出来的各个特征词来表达顾客观点,实现文本因素的数值化转换。假设在线评论数据经过聚类之后形成的影响因素共(i
=1,2,…,n
)类,当某条评论文本中包含与因素相似的词语时可将该条评论文本归为类,从而得到各个因素所包含的评论文本数量,实现文本因素的量化,在(t
=1,2,…,T
)时刻第i
类因素可表示为(t
),为消除量纲对预测结果的影响,需要对数据进行归一化处理,利用Z-score标准化的方法将数据限制在一定范围之内,计算公式如下:(1)
式中:为原始数据的均值;σ
为原始数据的方差。1
.3
.2
支持向量回归模型原理SVR作为SVM的一种,引入了不敏感损失函数ε
,在解决非线性回归问题方面具有很强的处理能力,它的优化目标函数可表示为:(2)
式中:C
表示惩罚因子,C
值越大对误差分类的惩罚越大,越小对误差分类的惩罚越小;x
为模型需要输入的变量值;y
为相应的预测值;w
为函数f
(x
)中自变量x
的系数;l
表示损失函数,即允许超平面外存在样本点,但需要使损失函数尽可能小;(f
(x
),y
)表示超平面中的样本点;ζ
为松弛变量,当样本点位于超平面以内或其边缘上时ζ
=0,当样本点位于超平面上方时ζ
>0,当样本点位于超平面下方时ζ
<0。为求解式(2),一般采用拉格朗日对偶变换,公式为:(3)
式中:α
和为拉格朗日系数。对于单变量SVR预测模型,通常仅将时间序列的p
个数据作为预测模型的输入变量,对未来某个时刻的值进行预测,此情况下,y
与其前几个时刻的值之间存在着如下函数关系:y
(t
+T
+1)=F
(y
(t
),y
(t
+1),…,y
(t
+m
))(4)
在本研究中除了将时间序列历史数据作为预测模型的输入变量外,还提取了其他相关影响因素,因此需将单变量SVR转换为多变量SVR,即上述函数关系转换为需求量y
与多个输入变量之间的关系,函数关系表示为:y
=F
(x
(t
),x
(t
),…,x
(t
))(5)
引入核函数将非线性回归问题转换为一个近似线性回归问题,仍然采用拉格朗日对偶变换法进行求解,具体公式表示为:
(6)
在核函数选择过程中,可供选择的核函数主要有径向基函数(Radial basis kernel function, RBF)、高斯核函数、多项式核函数、Sigmoid核函数等,其中RBF函数能够将特征空间映射到无穷维,与其他核函数相比参数较少,方便计算,因此本研究引入RBF函数作为SVR模型的核函数。最后将所提取的影响因素特征集输入到此回归函数中可对产品的需求量进行预测。
1
.3
.3
PSO算法优化SVR模型参数在SVR模型中惩罚因子C
以及不敏感损失函数ε
是影响模型预测准确度的重要参数,其中C
值过大曲线容易过拟合,反之容易欠拟合;ε
反映了数据映射到新的特征空间后的分布,ε
值越大支持向量个数越少,反之支持向量个数越多。为较快速确定参数C
和ε
的值,采用粒子群算法对参数进行优化,操作步骤如下:1)种群初始化。设置迭代次数、种群大小、学习因子、惯性权重等基本参数。
2)计算该算法的适应度函数值,并将R
作为算法的适应度函数。3)根据适应度函数计算粒子个体及全局最优解,并与历史值进行比较更新群体中粒子的速度和位置。
4)判断是否满足终止条件,如满足则停止迭代,若不满足则不断更新粒子速度和位置直至满足终止条件。
2 研究数据与结果分析
2.1 数据获取及预处理
为验证评论数据中的产品特征因素对生鲜产品需求量预测准确度的影响,本研究采用京东生鲜网站中产品评论数据进行实证分析。利用谷歌插件web scraper分别获取了苹果、火龙果和小龙虾3种生鲜产品2021-06-25—2021-08-17共54天的评论数据,得到的3种生鲜产品评论数据量分别为10 312条、9 685条和9 064条。根据网站的评论规则,每个顾客在确认收货后均会形成一条文本评论数据,基于此本研究将每天的评论数量作为生鲜产品的日需求量,从而建立以天为周期的历史需求量数据集。从网站爬取出来的评论数据是顾客对产品使用体验的随意性表达,其中会存在着图片、符号等非文本信息,因此需要删除评论文本中的表情符号、数字等无用评论信息,确保评论文本的纯文字性;其次对于一些不包含任何主题信息的超短评论,也需将其删除;最后将处理后的评论数据输入到python软件中,运用“jieba”分词工具对评论数据进行分词、去停用词处理,形成最终的文本语料库。
2.2 在线评论产品特征因素提取
挖掘评论数据中顾客感知的产品及服务信息是提取生鲜产品需求影响因素的关键步骤。对经过预处理后的评论文本进行词频统计分析,选取词频排名前100的词语作为产品特征词库,在该词库中由于会存在着同义词,需要对其进行人工筛选,将同义词合并为一类,从而形成生鲜产品的中心特征词,作为Word2vec模型的输入语料。
经过词频统计分析及人工筛选合并同义词,最终确定生鲜产品的5类中心特征词,分别为“口感”、“包装”、“物流”、“性价比”和“服务”。将此中心特征词分别输入到Word2vec模型中,借助模型中的相似度函数,计算得到与各个中心特征词的相似词语,以火龙果评论数据中的特征词“口感”为例,得到的相似度排名前30的词语集合见表1。按此步骤最终可形成生鲜产品需求预测影响因素特征词集。
表1 “口感”语义相关特征词集及其与中心特征词的相似度
Table 1 Semantic related feature word set of “Taste” and its similarity to the central feature word
词语Word相似度Similarity词语Word相似度Similarity词语Word相似度Similarity词语Word相似度Similarity味道 Smell0.955 7好吃 Good to eat0.812 3挺大 Quite big0.797 2个儿 Size0.778 3很甜 Very sweet0.873 8个个 All0.812 0糖分 Sugar0.795 2超值 Value0.777 0甜美 Sweet0.856 7口味 Taste0.811 9坏果 Bad fruit0.793 9爽口 Tasty0.777 0新鲜 Fresh0.850 8均匀 Evenly0.811 8适中 Moderate0.791 5磕碰 Bump0.776 2不小 Not small0.849 4很大 Very big0.808 3偏小 Too small0.786 5一顿 A meal0.775 4皮薄 Thin skin0.848 0个头 Size0.807 7蛮大 Quite big0.785 0很正 Very positive0.774 6品相 Appearance0.828 0个子 Size0.801 8蛮甜 Quite sweet0.784 9中等 Medium0.771 6挺甜 Quite sweet0.822 1浓郁 Rich0.800 8成功 Success0.784 6打算 Intend0.771 5大果 Big fruit0.813 6正好 Just right0.798 0甘甜 Sweet0.781 4保存 Save0.769 7不算 Not count0.812 7太甜 Too sweet0.797 5超甜 Super sweet0.779 2清爽 Refreshing0.765 6
2.3 多变量SVR预测结果分析
经Word2vec模型词语聚类后得到5类影响生鲜产品需求的影响因素,分别为口感()、包装()、物流()、性价比()和服务(),在此基础上利用各个特征词的相似词语对评论文本数据进行归类,得到各影响因素的数据集合,并运用式(1)对各个数据集进行Z-score标准化处理。以火龙果产品为例,将2021-6-25—2021-8-11共48天的产品特征因素及对应的历史需求量数据组成训练样本,用于训练模型,求解模型中的最优参数,建立本研究的需求预测模型;将2021-8-12—2021-8-17共6 d的数据组成测试样本,用于检验模型,预测产品需求量。在训练样本数据中得到的单变量SVR预测值与多变量SVR预测值对比见图2:单变量SVR模型得出的需求量预测数据波动较大,在某些时间段甚至偏离了真实值,而加入在线评论影响因素的多变量SVR模型具有更好的预测效果,预测值与真实值相比波动小,更接近真实市场需求量数据。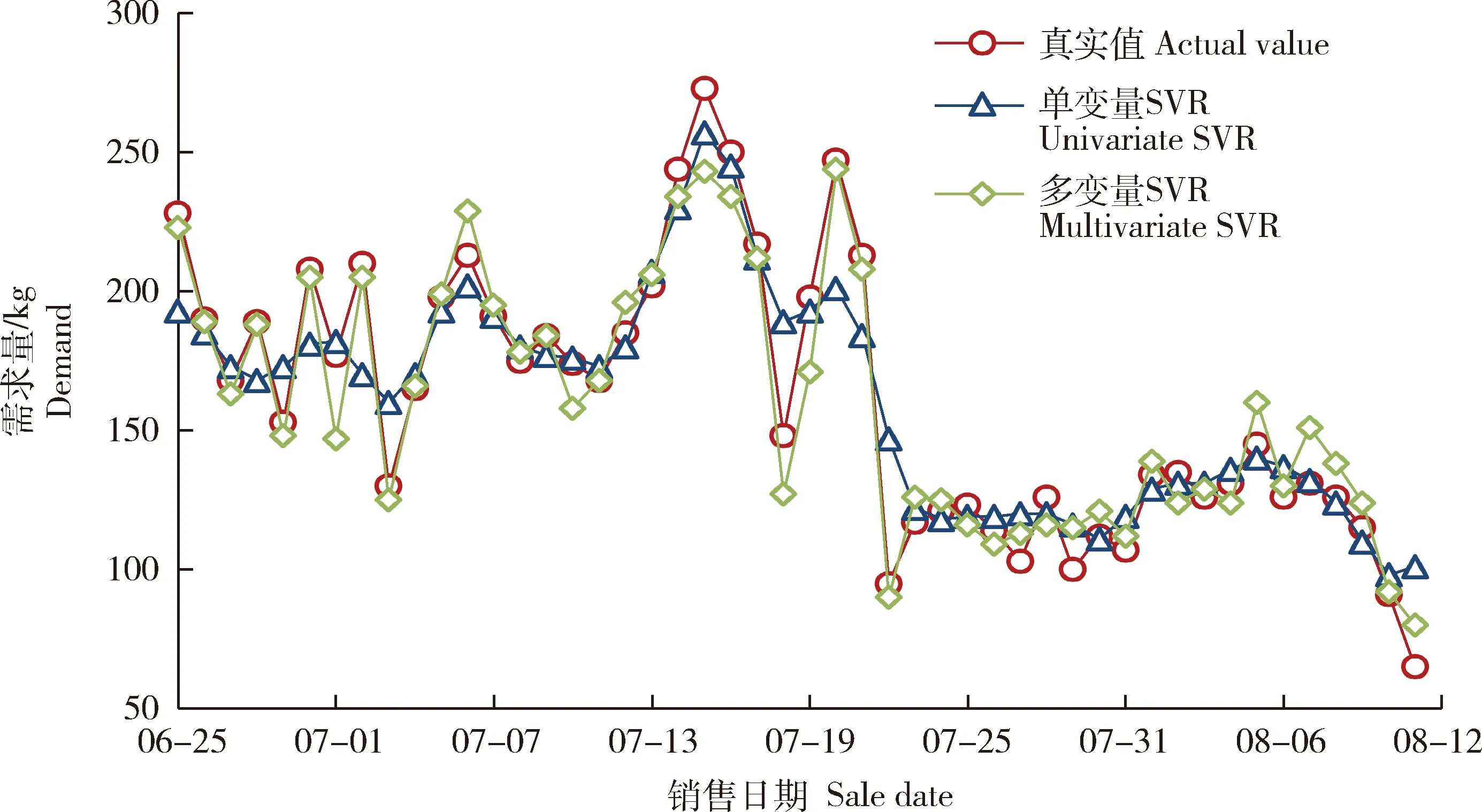
图2 训练样本数据中火龙果需求量真实值与单变量SVR和多变量SVR的预测值Fig.2 The true value and the predicted value of the univariate SVR and multivariate SVR of pitaya demand in the training sample data
利用建立好的多变量SVR模型对测试样本的火龙果需求量数据进行预测,结果见图3。
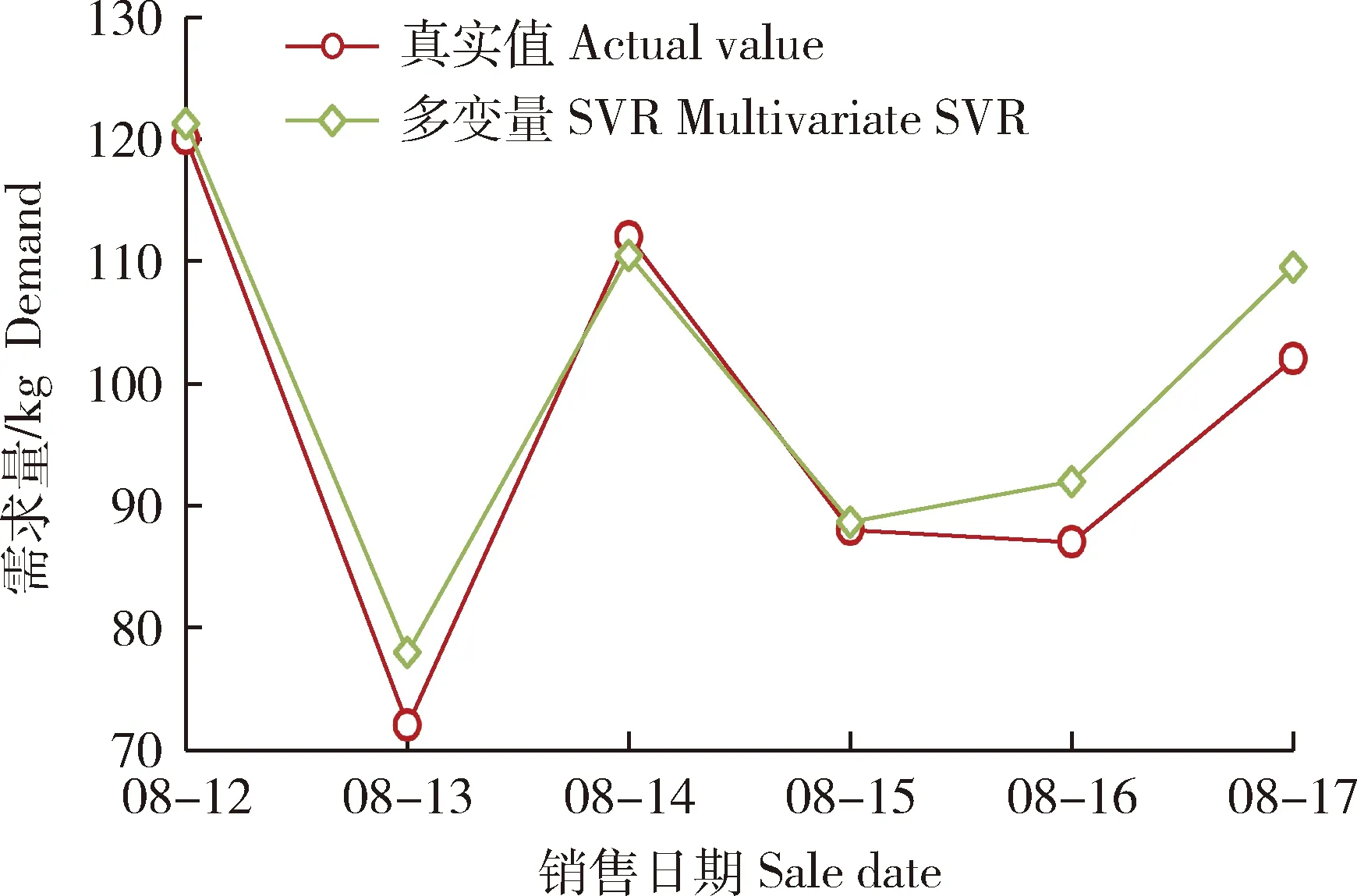
图3 测试样本数据中火龙果需求量真实值与多变量SVR预测值Fig.3 The true value and the forecast value of multivariable SVR of pitaya demand in the test sample data
为更准确验证2种模型需求量预测的准确度,针对3种产品分别计算2种模型需求量预测值的均方误差MSE、平均绝对误差MAE和判定系数R
,其中MSE和MAE数值越小、R
数值越大说明预测结果越好,所得到的计算结果见表2。可见多变量SVR模型的需求量预测误差均优于单变量SVR模型,预测精度更高。因此,在实际生产运作中,加入在线评论顾客感知产品特征因素的多变量SVR需求预测模型能更准确预测产品需求量。表2 单变量SVR与多变量SVR火龙果需求量预测误差比较
Table 2 Comparison of pitaya demand forecast errors between univariate SVR and multivariate SVR
产品Product模型Model均方误差Mean square error平均绝对误差Mean absolute error判定系数R2Coefficient of determination火龙果Pitaya单变量 SVR0.132 90.245 10.877 1多变量 SVR0.052 50.176 10.943 4苹果Apple单变量 SVR0.122 90.196 90.877 1多变量 SVR0.037 00.101 80.963 9
表2(续)
产品Product模型Model均方误差Mean square error平均绝对误差Mean absolute error判定系数R2Coefficient of determination小龙虾Crayfish单变量 SVR0.151 30.219 60.848 7多变量 SVR0.013 20.084 20.986 8
3 结束语
本研究针对社交媒体中在线评论数据信息,以生鲜农产品为研究对象,将文本挖掘技术和需求预测模型相结合,预测了生鲜产品下一阶段的市场需求量。利用谷歌插件web scraper爬取大量在线评论数据,构建Word2vec模型提取评论数据中顾客感知的产品特征因素,最大程度挖掘在线评论中产品特征信息,从而考虑多个因素对需求量预测准确度的影响。在此基础上,将提取出的产品特征因素量化,引入多变量支持向量回归的需求预测方法,实现生鲜产品多变量需求预测。在python软件上进行算例仿真分析,结果表明:在线评论中顾客感知的产品特征因素能有效用于生鲜产品需求量预测中,并且与只根据历史数据进行需求预测的单变量SVR相比,本研究提出的预测模型能提高产品需求量预测的准确度。
猜你喜欢
数学大王·中高年级(2021年6期)2021-09-27
少儿科技(2021年6期)2021-01-02
IT经理世界(2016年20期)2016-11-23
建筑工程技术与设计(2015年21期)2015-10-21
销售与市场·管理版(2015年6期)2015-06-23
新高考·高二数学(2014年7期)2014-09-18
IT经理世界(2014年8期)2014-05-05
福建中学数学(2011年9期)2011-11-03
中学生数理化·七年级数学北师大版(2008年5期)2008-10-14
小学教学参考(数学)(2006年7期)2006-12-31
