
复杂场景下抽烟、打电话动作识别算法
2022-07-25 09:42赵绪言
现代计算机 2022年9期
赵绪言
(西南交通大学计算机与人工智能学院,成都 611756)
0 引言
现今,智能安防领域在城市智能化过程中成为越来越不可或缺的一部分,其改变了传统监控功能单一,没有基于视频主动分析功能的缺陷。国内外越来越多的技术性企业正在全力发展基于智能安防的行为分析等核心技术。为了使计算机能够更好地监控和分析视频数据,对于视频中目标行为的检测与识别是一项基本能力。如今在深度学习快速发展的背景下,利用视频数据进行人物行为识别变得越来越容易,但是在很多特定场景下,基于深度学习的行为识别依旧有非常多可以深究的部分。
生活中某些特定的场景常常会对人物的行为做出特定的限制,如加油站禁止抽烟和打电话,驾驶过程中禁止打电话等。近年来在加油站、驾驶过程中抽烟、打电话引发的安全事故屡见不鲜,对社会造成很大的危害。因此,设计一种基于深度学习的抽烟、打电话动作识别算法是十分有必要的。
早期的行为识别算法的输入是图片,输出是行为的类别,然而行为的发生往往伴随着时序的关系,如果网络的输入仅仅是图片那么时序关系将会被忽略。本文选择工程环境下的复杂场景,研究基于时序信息的抽烟、打电话识别算法。
1 相关工作
动作的发生常常伴随着先后顺序,例如人抽烟这个动作会先抬手,然后再吸烟。为了在行为识别网络中加入时序信息,输入单张图片是不够的,而是需要将覆盖整个动作的视频片段输入网络进行训练。因此需要在网络中设计加入时序特征。
Donahue 等提出的LRCN 使用CNN 提取空间特征,使用LSTM 提取时序特征,进行行为识别。但是LSTM 的固有顺序阻碍了训练样本的并行化,导致训练效率很低,并且它可感知的时序性范围也是有限的。而RGB-Based 的方法可以一定程度上解决这些问题。
RGB-Based 行为识别可以分为Two-Stream、3D-based、2D-based、Video Transformer 这几个类别。
其中Two-Stream 将动作识别中的特征提取分为两个分支:一个是RGB分支提取空间特征、另一个是光流分支提取时间上的光流特征,最后结合两种特征进行动作识别,代表性方法如TwoStream及其扩展。
3D-Based 的方法将2D 卷积添加了时间维度,扩展到3D,直接提取包含时间和空间两方面的特征,这一类方法也是目前做的比较多的话题。代表方法如开山之作C3D及其之后的扩展SlowFast等。目前3D-Based 的方法在大规模的Scene-Based 数据集(如Kinetics400)上相对于2D 的方法取得了更好的效果,但是3Dbased 也存在一些明显的问题:其网络参数量大,计算开销大,推理速度明显慢于2D-Based的方法。
2D-Based 的出现是为了解决以上3D-based的缺点,近年来也有比较高效的2D-based 的时序建模方法,包括TSN,TPN等轻量级的时序建模方法。
基于卷积的主干网络长期以来一直主导着计算机视觉中的视觉建模任务,然而目前图像分类的主干网络,最近正在进行从CNN 到Transformer的 转 变。这 一 趋 势 始 于Vision Transformer(ViT)和Swin Transformer的引入,在视觉分类任务上取得了SOTA 的效果。Swin Transformer 不同于ViT 一来就下采样16 倍的策略,提出了具有层次性的特征图,利用SWMSA(shifted-window multi head self attention)进行窗口之间的通讯。Transformer 系列在图像分类上的巨大成功促成了一些基于Transformer 结构的视频识别任务研究的出现。例如本文用到的方法Video Swin Transformer。
另外还有Skeleton-Based 的方法,例如STGCN。这种方法基于骨架的行为识别以关键点检测算法的结果作为网络输入进行行为识别。骨架的信息使得行为识别的准确性得到提升,但对输入的要求比较严格,需要先对视频数据进行预处理得到骨架数据,这使得该类算法的中间步骤较多,不利用工程化应用。
2 算法原理
2.1 抽烟、打电话动作识别
基于Transformer 系列强大的特征提取能力,本文在Video Swin Transformer的基础上,对视频片段进行抽烟、打电话动作识别。Video Swin Transformer 严格遵循原始Swin Transformer 的层次结构,但将局部注意力计算的范围从空间域扩展到时空域。由于局部注意力是在非重叠窗口上计算的,因此原始Swin Transformer 的滑动窗口机制也被重新定义了,以适应时间和空间两个域的信息。

整体结构中的主要组件是Efficient Video Swin Transformer Block,如图1(b)所示。这个模块是基于Swin Transformer Block,其中Swin Transformer Block 是 将Transformer 中Multi Head Self Attention(MSA)替换成了基于3D 滑动窗口的MSA 模块。具体地说,一个Video Transformer Block 由一个基于3D 滑动窗口的MSA 模块和一个前馈网络(FFN)组成,其中FFN 由两层的MLP 和激活函数GELU 组成。Layer Normalization(LN)被用在每个MSA 和FFN 模块之前,残差连接被用在了每个模块之后。
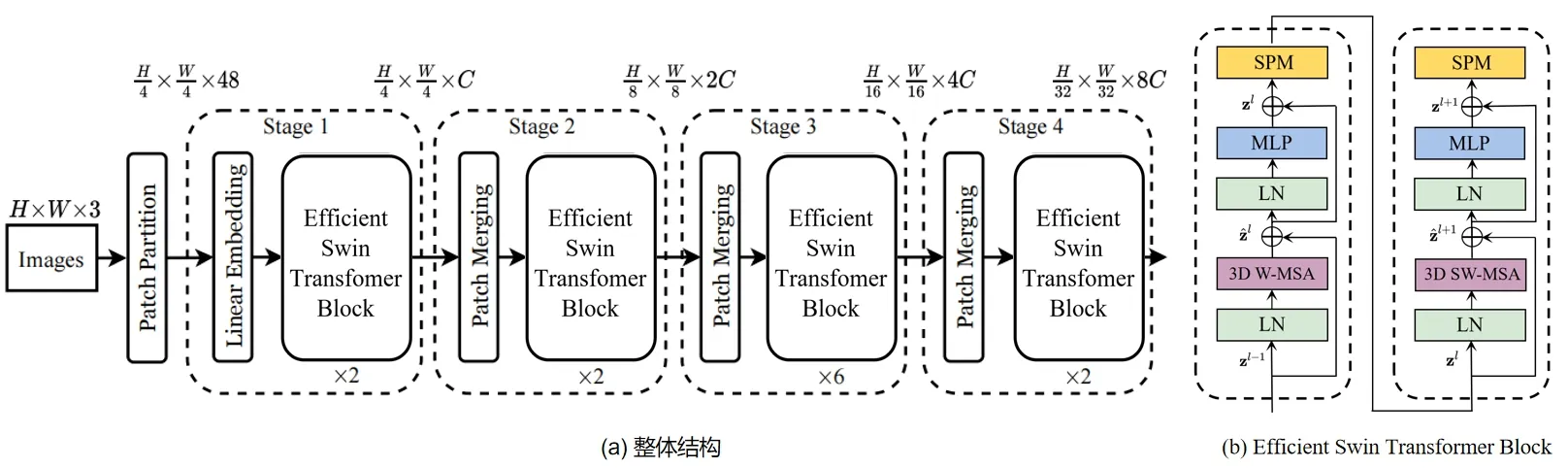
图1 Efficient Video Swin Transformer
本文在Swin Transformer Block 的基础上,参考DynamicViT提 出 了Efficient Swin Transformer Block。即在FFN 之后添加了一层Sparsification Module(SPM)对整个网络进行分层稀疏化,通过消除信息较弱patch 而节省计算开销,加速模型推理速度。patch 的稀疏化是分层执行的,网络在计算的过程中会逐步删除无用信息的patch。两个Efficient Swin Transformer Block 之间的计算如下所示:
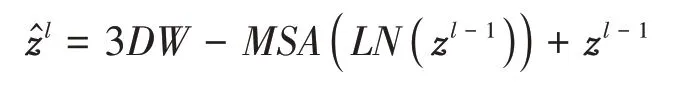

2.2 在线动作识别框架
考虑到目前数据集(3.1 介绍)大部分是以人为中心,视频中人的目标是比较大且清晰的。若实际迁移到工程摄像头角度下,场景信息会更加多样化和复杂,其中“人”的目标可能会较小,如果直接将整个画面传入动作识别网络,网络可能会因为抽烟、打电话的视觉特征不明显,周围无用的视觉信息较多,造成分类效果不理想。因此本文考虑在动作识别模型(Efficient Video Swin Transformer)前,加入一系列前处理操作,尽可能在动作分类前过滤掉周围无用的视觉信息,且保证动作识别模型的在线处理实时性。详细的处理流程如图2所示。
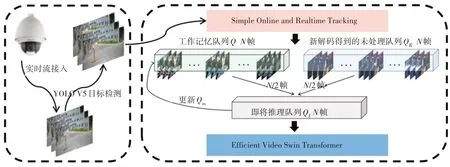
图2 在线动作识别框架
①接入实时流解码得到连续的单帧图片。②通过YOLO V5目标检测算法,检测到“人”这个类。③利用多目标跟踪算法SORT,对多帧之间的目标检测结果进行跟踪,得到带ID 的跟踪序列。④将跟踪后的序列送入Online Video Understanding 算法。维护保证实时性的待检测序列。⑤对上一步中的序列接入Efficient Video Swin Transformer 动作识别模型进行动作分类,得到最终结果。
其中第④步的Online Video Understanding 算法参考ECO。因为动作识别模型在训练时的输入通常都是一段裁剪好的视频。在实际工程中的输入通常是通过解码视频流,形成一帧一帧连续的图片呈现的。那么如何将视频流解码后的多帧图片转换成动作识别模型的输入,且保证识别结果的实时性是一个问题。目前一般的做法是固定一个大小为的滑动窗口,输入连续帧画面,进入动作识别网络判断结果。但是这样做会有两个缺陷:①会造成长期语义信息的缺失;②无法保证动作识别的实时性,可能会造成较长的延迟。因此需要一个在线的处理框架保证网络的实时性。
如图2中右侧中间部分所示,这个框架中主要维护了两个图像的队列,其中Q表示存放较旧图像的工作记忆队列,Q表示存放新解码得到的未处理图像队列。当新的一组序列到来时,需要从上述两个队列中各采样一半得到即将推理队列Q,同时更新工作记忆队列。然后将Q作为动作识别网络的输入得到当前的预测结果。同时将当前的预测结果和平均预测结果进行平均后得到最终的输出。这个框架在以当前画面为主的基础上,通过工作记忆队列和平均输出两个方面维护了较长的时序信息。
3 实验设置与结果分析
3.1 数据集
本文在两大公开数据集的基础上,构建抽烟、打电话的视频数据集。其中Kinetics400 包含抽烟视频,Moments in time包含抽烟和打电话视频。选择Kinetics400 中所有的抽烟视频+网上额外爬取的抽烟视频,Moments in time 中所有的打电话视频,形成视频数据集。每个视频时长大概为10 秒。最后形成的数据集包含三个类别:抽烟、打电话和其他。数据集详细情况如表1所示。

表1 抽烟、打电话数据集
其中抽烟视频870 个,打电话视频1959 个,其他视频800个(“其他”为Kinectics400中除开抽烟的其他类别,随机抽取得到)。按照二八的比例划分为验证集和训练集。
3.2 实验设置
实现上,实验采用Swin Base 的基础结构,使用ImageNet 21K的预训练模型。训练参数patch 设置为224 × 224,学习率采用CosineAnnealing 的策略,初始学习率为3e-4,采用线性warm up 策略,优化器采用AdamW,权重衰减设置为0.05,batch size 设置为16,总迭代次数为30个epoch。
3.3 结果分析
本文将实验结果与动作识别的其他方法在验证集上进行了对比,形成的实验结果如表2所示。其中第四行(已加粗)是本文采用方法的实验结果。可以看出本文提出的Efficient Video Swin Transformer,与传统基于RGB 的方法TSN、TPN 相比,精度有非常大的提升,与Video Swin Transformer 相比,在加入SPM(Keeping Ratio 设置为0.8)后精度只下降0.3%,但是推理速度提升26%,约10 秒的视频片段推理时间可达到3.4秒。
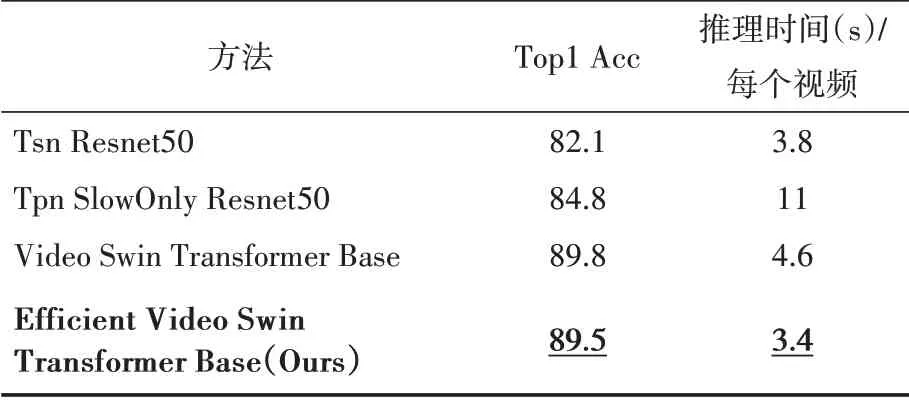
表2 实验结果对比
同时,本文提出的方法通过集成在线动作识别框架,可以将抽烟、打电话的动作识别在真实工程系统环境下做到很高的实时性和准确性。其中YOLO V5 和SORT 能保证检测和跟踪的效率,通过Online Video Understanding 可以实时地平滑出当前的结果,区分出画面中人抽烟、打电话或者其他的行为。
4 结语
本文基于Video Swin Transformer 和Dynamic-ViT,提出了Efficient Video Swin Transformer,在Swin Transformer Block 中加入SPM 模块,在保证一定精度的同时,大幅提升了动作识别网络的推理速度。在Kinetics400 和Moments in time 混合的抽烟、打电话数据集中,与现有方法相比取得了速度与精度最为平衡的结果。同时,本文提出了一套在线动作识别框架,将Efficient Video Swin Transformer 集成在其中。框架从视频流中解码得到单帧图片,到目标检测、跟踪、实时在线平滑队列,最后传入动作识别网络得到分类结果,整个过程可保持结果的实时性和准确性。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
汽车工程(2022年3期)2022-04-07
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
意林·作文素材(2021年23期)2021-01-22
科学导报·学术(2020年26期)2020-10-21
电子技术与软件工程(2016年22期)2016-12-26
青年文学家(2016年32期)2016-12-23
电脑知识与技术(2016年24期)2016-11-14
物联网技术(2015年10期)2015-11-10
