
基于知识增强的企业技能智能问答应用研究
2022-07-25 09:42冯强中
现代计算机 2022年9期
冯强中
(科大国创云网科技有限公司,合肥 230088)
0 引言
科技的迅猛发展以及网络信息的爆炸式增长,致使传统的信息获取方式变得越来越不适合人们的日常需要。为了适应信息的快速增长,满足人们的日常查询,能够和人们进行互动的自动问答技术逐渐走进研究者的视野。传统的信息获取方法主要是以人工为主(如人工客服、商业导购等),但由于当前网络信息比较繁杂以及人们查询信息的方式也不标准化,因此面对各式各样的用户查询,人工方式会耗费大量的时间和精力去获取用户想要答案,特别是咨询的问题大多数为重复的时候,资源浪费特别严重。因此,基于深度学习技术实现的自动问答模型变得十分符合现在人们对查询问题的迫切需求。
大数据、机器学习、模式识别以及神经网络等人工智能技术的飞速发展和成熟落地使得机器替代人工来进行沉重和繁琐的作业成为可能。继计算机视觉领域取得巨大进展之后,深度学习技术在自然语言处理领域也迎来了它的光辉时刻。作为自然语言处理领域重要的应用场景——智能问答机器人,是机器替代人工进行工作来提高工作效率、降低人工成本的典型代表。根据用户问题的所属数据领域,本文所研究的问答系统属于面向常用问题集(frequently-asked questions, FAQ)的 问 答 系统。针对公司专业领域的知识数据,本文提出了一种基于知识增强的智能问答模型。通过相关实验,证明了本文所提出的模型不仅能够克服之前静态FAQ 方式的缺点,而且在面对用户的重复性问题时,该模型能够精确地定位用户提问的知识,再及时、准确地给出用户解答。该模型能够以一问一答的交互形式及时为用户提供服务,避免回复不及时等降低用户体验的情况出现,降低了相关的人工成本以及资源。
1 相关研究
基于自然语言处理等深度学习技术实现的智能问答系统有很多,比如Bordes等对问句中实体准确定位,将问句中的实体抽取出来,再将实体连接到知识库,以该实体为起点,查找与其关系相连的实体作为候选答案。其次计算这些实体关系的组合与问句之间的相似度,通过打分排序,选择相似度最大的候选项返回答案,取得很好效果。Dong 等设计了一种多列卷积神经网络,根据知识图谱特点,定义答案路径、上下文路径、答案类型,作为参考特征,并且每个特征对应一个已经训练的卷积神经网络,用于捕获问句中语义信息,再通过计算问句与答案之间的相似度,对结果打分排序,排名第一的作为最终答案。Dong 等提出用两级encoder-decoder 改进机器翻译端到端模型,有效解决自然语言与语义表示之间跨度大的问题,通过问题分解来提升性能。Qu 等提出了一种基于相似矩阵的递归神经网络(AR-SMCNN)模型,利用RNN 顺序建模特性捕获语义及相关性,使用注意机制跟踪实体和关系重要部分,并制定了一种准确确定问句中主实体的方法。史梦飞设计了一种分布式的问答系统,将问题句进行分类,提高下游任务的准确性,通过构建基于深度学习的End2End 问答模型,同时考虑中文问句的复杂性,提出结合语义依存分析的剪枝算法及自动化模板的方法。付燕等用LSTM+CNN 提取问题和答案的特征,利用构造负样本的方法,完成了一种基于混合神经网络的问答算法。曹明宇等基于当前主流的BILSTM-CRF 神经网络模型,对问题中的药物、疾病等实体进行识别;然后结合TF-IDF 与预训练的词向量,得到问题向量,将其与预先定义的问题模板进行相似度匹配,得到最相似的问题模板;该系统可以有效地回答原发性肝癌相关的药物、疾病及表征等问题。Qu 等在传统的基于向量模型的基础上,提出一种AR -SMCNN 模型,利用CNN 与RNN 神经网络优化提取信息的精度,解决了之前忽视自然语言原始信息的问题,取得了Simple Question 测评上的最优效果。Hamilton 等认为知识图谱是一张由关系和实体组成的图,通过学习实体低纬度嵌入表示,可以预测潜在或者缺失的边。目前知识图谱查询的难点在于处理更为复杂的逻辑查询,因为这涉及多个未发现的边、实体和属性。针对这一问题,Hamilton 等设计了一种框架,实现在不完整知识图谱上有效地对连接逻辑查询进行预测,在低维空间中对图谱节点embedding 操作,并在这个embedding space 中将逻辑运算符表示为学习过的几何运算(例如平移、旋转)。通过在低维embedding space 中执行逻辑运算,可以预测图谱中的关系。
由以上方法可知,神经网络和知识图谱在知识问答领域的表现都十分良好。但在实际应用中,尤其面对公司特定领域知识的业务场景时,很难获取如上述方法那样充足的数据。因此面对这种情况,大多数面向公司专业领域知识问答模型都是基于字符匹配的。但是这样的模型准确率却不高。考虑到神经网络进行特征提取的效果往往是最优越的,而知识图谱表达数据中的相关实体以它们之间的关系最有效、最直观。因此本文针对较少的公司专业领域的数据,通过数据增强,然后以双向LSTM 结合知识图谱为基础进行知识增强,构建出了一种基于知识增强的智能问答模型。
2 数据处理
数据来源于公司特定领域的专业知识,具体内容如表1所示。其中“问题”表示企业知识库中用来查询的标准查询语句,“回复”是左侧每个“标准问题”对应的标准答案,“相似问题”是“问题”列中每个问题的相似查询语句。例如:输入查询语句“人才政策”,回复的答案就是“1、合肥市……”;同样,考虑到用户在进行查询时所输入的自然语言不一定标准,可能会输入“人才补贴”、“住房补贴”等相对接近标准问题“人才政策”的相似查询语句,也应该返回问题“人才政策”的答案。

表1 企业技能知识库原始数据
为了方便模型构建,我们需要把表1的数据进行处理。
(1)表1所示的数据量太少,并且没有相关的负样本,因此需要把表1 的数据进行数据增强,处理成<问题,相似问题,非相似问题>格式的数据,详细如表2所示。

表2 标准问题匹配数据集
通过对原有数据进行清洗、筛选、扩展等数据处理操作,将“问题”列中的每个问题和“相似问题”列中的每个相似问题进行匹配扩展,同时对“问题”列中非当前问题的其他问题,包括与之对应的相似语句都可以是当前问题的非相似问题,最终数据从300 多条增强为95336条。
(2)为快速查询相关问题,本文构建了知识图谱,为此将表1 的数据处理成三元组,见表3。

表3 企业知识库三元组数据
为构建知识图谱,表1中“问题”列中的每个问题,“回复”列中的每个答案,“相似问题”列中的每个相似问题都被定义为实体,并且考虑到表1中的数据比较少,知识比较分散,本文为知识图谱添加了一个主实体:机器人(robot),并且定义主实体和“问题”实体之间的关系是‘相关’(related)。通过相关数据处理,本文一共定义“问题”和“答案”实体各126 个,“相似问题”实体315 个。实体之间的关系3 个,分别是相关、答案以及相似。比如实体“人才政策”和实体“机器人”的关系为‘相关’,和“1、合肥市公共租赁住房申请指南…”的关系为‘答案’,和“住房补贴”的关系是‘相似’。
3 模型构建
模型的总体架构思路如图1所示,问题查询语句输入模型后,由训练数据训练完成的双向LSTM 模型可以对输入的查询语句进行‘标准化’,得到标准问题。将标准问题输入构建的知识图谱,利用知识图谱可以对标准问题进行查询,返回用户所需答案。下面将具体说明双向LSTM模型和相应的知识图谱。
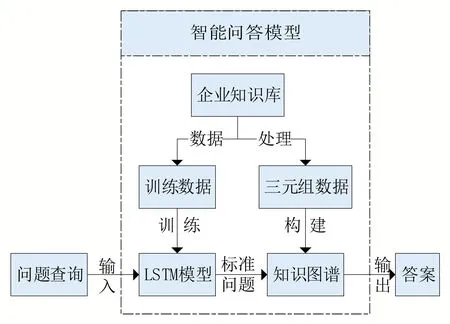
图1 模型总体架构示意图
3.1 双向LSTM模型示意图
将数据处理成<问题q,相似问题q+,非相似问题q->格式之后,首先建立词典和随机初始化词向量矩阵,然后索引得到每一个问题的语义矩阵表示,带入双向LSTM 模型中对问题的语义向量表示进行微调训练,最后迭代缩小损失函数,使得<问题,相似问题>的cosine 的值变大,而<问题,非相似问题>的cosine 值变小。具体框架示意图如图2所示。

较远的词与词之间的联系选取出更好的特征。最后损失函数的计算采用如下公式:
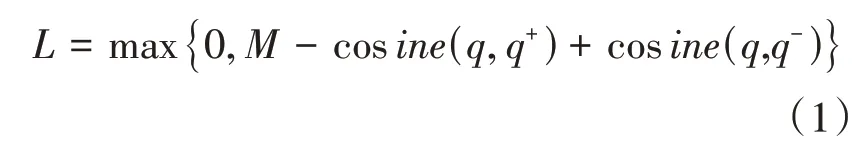
其中,是需要设定的参数,可以改变,实验中设置为1,、、分别是问题、相似问题、非相似问题的语义表示向量。通过迭代缩小损失函数,使得<问题,相似问题>的cosine的值变大,而<问题,非相似问题>的cosine 值变小。
3.2 知识图谱示例图
根据表3企业知识三元组数据生成的知识图谱总体如图3 所示。它以主实体robot 为中心向外发散,robot 用‘相关’关系连接着每个“问题”和“相似问题”的实体,其中每个实体都通过各自的‘关系’连接着其他实体。

图3 公司技能知识图谱示例图
下面是“问题”实体中的“人才政策”实体对应的子图谱。它用‘相关’关系连接着主实体机器人;用‘相似’关系连接“住房补贴”、“租房补贴”等相似实体;‘答案’关系直指它对应的标准答案。同时,我们从图2也可以看到,每个“相似实体”也都有自己的关系连接着其他实体。

图4 “人才政策”单个实体示例图
4 实验结果分析
本次实验采用95336 条数据和双向2 层的LSTM 预训练模型进行实验,将数据按照7:3 的比例划分成训练集和测试集。然后将训练集的数据按2000 一组进行分组,每一组计算一次损失来迭代更新模型,最后虽不满2000 个仍然将其分为一组,迭代50轮。通过测试集中问题的句子向量以及相似问题的句子向量,得到测试集相似和非相似的准确率。模型的损失变化趋势如图5 所示,双向LSTM 模型训练时间为305 s,精确率达到83.44%。
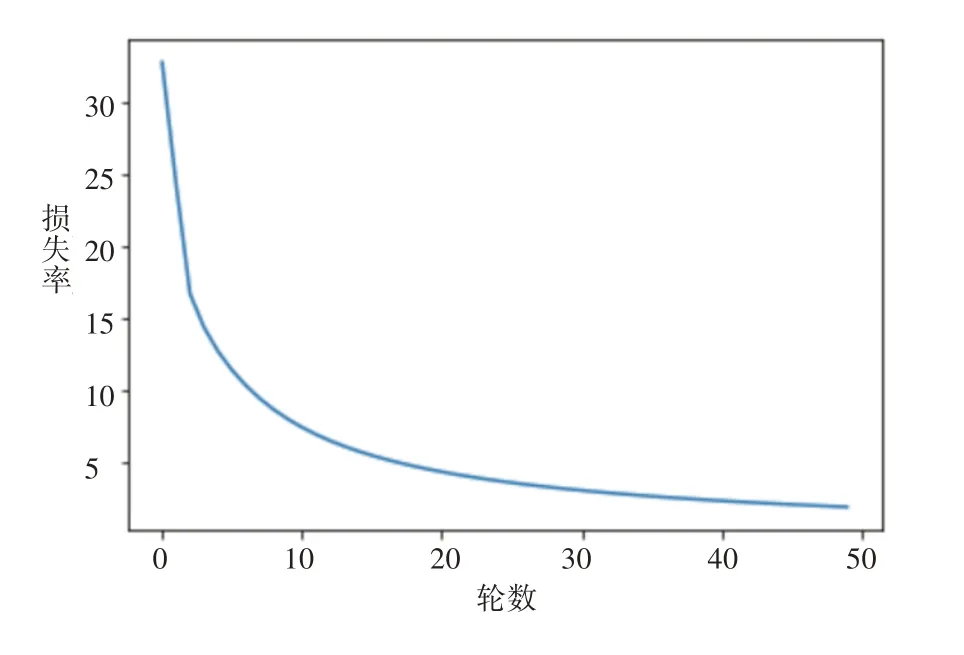
图5 双向LSTM损失函数变化趋势图
模型训练完成之后,输入问题“住房补贴”进行测试,模型的预测结果如图6所示。

图6 测试用例示意图
由测试结果可知,当输入查询语句“住房补贴”后,模型能够将标准问题“人才政策”对应的答案输出出来,说明本文提出的模型能够及时响应并返回准确答案。
5 结语
本文针对公司专业领域的知识数据,以双向LSTM 结合知识图谱为基础进行知识增强,提出了一种基于知识增强的智能问答模型。面对公司数据量比较少的情况,先以数据增强为手段对数据进行扩展,然后利用处理后的数据对双向LSTM 网络进行微调训练,使得微调后的模型能对输入的自然语言语句进行特征提取,然后与公司专业技能知识库中相对应的标准“问题”进行匹配,得到最相似的标准问题。之后将标准问题送入利用问题、相似问题和答案等实体构建的知识图谱中,利用查询语言得到与之相应的标准答案。实验证明,本文提出的模型提升了答案准确率并提升了响应速度,能在节省大量资源的前提下实现对用户查询的自动回复。但由于数据量太少,本文模型能实现自动问答的问题仅仅只支持已有的公司数据,因此后续工作会继续收集数据来对模型进行迭代优化。在数据量充足的情况下,我们还会尝试结合图表征来学习更多的语义知识,进一步提高模型的准确率。
猜你喜欢
军事文摘(2022年16期)2022-08-24
凤凰动漫(军事大王)(2022年3期)2022-06-17
当代陕西(2022年4期)2022-04-19
科学与财富(2021年35期)2021-05-10
新城乡(2018年6期)2018-07-09
世界博览(2016年4期)2016-03-16
数学教学通讯·初中版(2014年6期)2014-08-11
小学生·多元智能大王(2014年6期)2014-07-09
中国信息化·学术版(2013年5期)2013-10-09
小雪花·初中高分作文(2009年8期)2009-11-16
