
一种针对坦克速度控制的深度强化学习算法
2022-07-25 03:58崔新悦阳周明赵彦东范玲瑜
火力与指挥控制 2022年4期
崔新悦,阳周明,赵彦东,杨 霄,范玲瑜
(北方自动控制技术研究所,太原 030006)
0 引言
坦克是现代陆上作战中非常重要的武器,在火力、越野能力以及防护力方面有着绝对的优势。坦克的躲避能力较差,很容易被敌方火力袭击。在日益多变的战场环境下,驾驶员需要及时控制坦克以应对突发状况,通过无人驾驶技术实现坦克无人化,能够有效降低人员的伤亡,并且更高效地完成作战任务。在无人驾驶领域,针对速度控制问题的解决方法有动态编程、最大原理或者这两种方法的结合,以上方法都是基于确定性模型,受到维度灾难的影响。2008 年麻省理工大学使用传统行为决策方法,借助本地信息进行导航,缺乏对动态变化环境的适应能力;2013 年,国防科技大学建立了无人驾驶汽车的14 自由度动力学模型,并使用最小二乘迭代算法(LSPI)构建了基于仿真的自动驾驶决策系统;2019 年,高振海等使用Q-learning算法为求解车辆跟随驾驶场景下的最优策略。
本文针对深度强化学习在训练阶段,以等概率从经验池中采样,忽略了经验的时间重要性,导致过早的经验被采样造成收敛时间的浪费这一问题,提出最近经验回放的采样策略对软行动者- 评论家算法进行改进,通过赋予最近经验更大的权重值,增大其被采样的概率,可以加快网络收敛速度。将其应用于坦克速度控制上,可以提高坦克无人驾驶行为决策实时性。
1 坦克行为决策
无人驾驶行为决策的目标是对可能出现的驾驶道路环境给出一个合理的、实时的行为策略,核心任务是消化上层规划模块的输出轨迹点,通过一系列结合自身属性和外界物理因素的动力学计算,转换成对汽车控制的油门、刹车、方向盘等动作信号。坦克行为决策是通过对战场环境及自身状态的分析,并结合作战任务(包括压制、摧毁或防护等)生成驾驶策略以最大程度发挥作战效能,相较于传统无人驾驶,需要具有更高的实时性以及鲁棒性。坦克的动作信号主要包含速度控制以及朝向控制两种动作,通过对坦克速度控制的研究,可以提高坦克的机动性、战场生存能力以及作战效能。
1.1 设计原则
坦克行为决策的设计应该满足能够充分发挥自身机动优势、提高作战效能并保证战场生存概率的需求。因此,其设计原则主要为:1)为延长作战时间,需考虑坦克行驶中的耗油问题;2)行进过程中为规避敌方射击时应采取变速、“S”形路线等;3)行进速度过高也会使瞄准难度变大,影响己方的命中率,因此,射击时需遵守一定的速度限制;4)速度的突然变化会引起车体震动进而引起炮口扰动,影响射击精度,因此,加速、减速不能过猛,要尽量保持平稳行驶。
1.2 仿真环境
强化学习是智能体利用与环境不断交互产生的反馈信号调整自身动作,因此,环境对策略起到决定性作用。本文借助OpenAI Gym 来构建实验环境,它是一个广泛使用的开源框架,可以用来进行改进算法与传统SAC 算法的性能比较。构建坦克对抗环境如图1 所示(忽略道路坡度影响)。

图1 坦克对抗环境
道路总距离不限,敌方目标包括坦克和装甲车随机出现在道路上,模拟坦克对战场环境的不完全信息性。坦克提前150 m 收到关于两个即将到来的目标信息及其与当前位置的距离信息,从而调整自身运动状态。
2 深度强化学习
深度强化学习是将深度神经网络的高容量函数的逼近能力与强化学习的决策能力相结合,可以解决高维状态空间问题,实现对复杂问题的智能决策。目前,深度强化学习在医疗保健、机器人、智能电网、金融等领域开辟了许多新应用。
强化学习是智能体与环境进行交互,在奖励信号的指导下进行试错探索,智能体在随机环境中进行探索,其采取的动作同时影响着当前的立即奖赏以及后续的状态和动作。强化学习的交互过程可以由马尔可夫决策过程(markov decision process,MDP)来表示,MDP 描述为五元组(S,A,P,R,γ),五元组定义如下:1)S 是状态空间;2)A 是动作空间;3)P是状态转移概率:S×A×S→[0,1];4)R 是奖励函数:S×A×S→R;5)γ 是折扣因子:γ∈[0,1]。
强化学习的目标是找到最优策略使得累计奖励最大化,Q(s,a)为状态动作函数:

求解Q 函数对于解决离散动作空间内的强化学习任务具有很好的效果,但是,对于连续动作空间强化学习任务,策略梯度方法是最佳选择。
2.1 行动者评论家算法
Actor-Critic 算法由Actor 策略生成网络与Critic 价值网络组成。其中,Actor 负责与环境交互并生成策略,而Critic 负责评估Actor 的表现,并指导Actor 下一阶段的动作。Actor-Critic 算法结合了二者的优势,可以解决连续动作空间问题,同时收敛速度也大大提升。
优势动作评论算法(advantage actor critic,A2C)在传统的Actor-Critic 算法上进行改进,使用优势函数代替Critic 网络中的原始回报,作为衡量选取动作值和所有动作平均值好坏的指标。
其中,优势函数为:

2.2 软行动者评论家算法
软行动者评论家算法(soft actor-critic,SAC)是加州伯克利提出的一种基于最大熵的离线策略深度强化学习算法,其目标是最大化期望回报的同时最大化策略的期望熵。熵是策略随机性的度量,通过引入最大熵,SAC 具备以下优点:1)鼓励更广泛的探索,同时放弃多余的样本;2)该策略可以得到多个近似最优动作,提高对突发状况的应对能力;3)有效地提高训练速度,是优化传统RL 目标函数的一种新方法。

这样的策略概率分布考虑到了所有的动作,体现了随机性。策略更新通过最小化KL 散度达到:
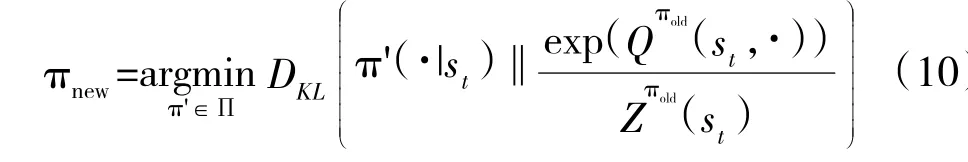
在具体的实现中,SAC 算法用神经网络来表示Q 值和策略,并引入双Q 网络,即同时单独训练两个Q 值网络,选取输出值较小的进行策略网络参数更新,避免过高估计。
3 基于最近经验回放的软行动者评论家算法
3.1 最近经验回放
为了提高SAC 算法在无人坦克速度控制上的收敛速度,使用最近经验回放的采样策略对其进行改进。SAC 算法使用经验池来存储过去的经验,神经网络参数更新时,从经验池随机采样数据。这种采样方案隐式地假设经验池中的数据同等重要。然而,在坦克行驶过程中,当前的状态- 动作与相近时刻更为相关,因此,在靠近当前时刻的区域建立函数逼近器更为准确。
最近经验回放在训练时更加强调最近的经验,通过赋予最近经验更大的权重值,使得在采样时能够被更高的概率抽到。具体来说,假设在当前的回合,一共要进行K 次更新,对于第k 次更新,1≤k≤K,经验i 的采样概率为:

其中,η 是一个超参数,它表示过去数据的重要程度。当η=1 时,相当于均匀采样,当η<1 时,更新的数据的采样概率越大,并且p随着更新而减小,意味着随时间的推进,古老的经验点重要性不断减弱,但是也有机会被采样到,保证了样本的多样性。当η 较小时,对过去经验的遗忘更快,可以实现快速学习;当η 较大时,增强了对过去经验的探索,智能体学习缓慢。
最近经验回放实现了强调最近经验的同时不遗忘过去经验,但是由于改变了样本的采样概率,网络容易过度拟合,因此,引入重要性采样以校正误差:

其中,N 为经验池容量,β 为校正程度。
SAC 算法的结构如下页图2 所示。首先,智能体与环境进行交互,得到“奖励”,将经验(s,a,r,s)存储至经验池中;训练时从经验池中依据最近经验回放原则采样,对价值网络进行参数更新;选取两个价值网络输出中较小的Q 值对策略网络参数进行更新;针对当前状态,策略网络输出动作继续与环境交互。
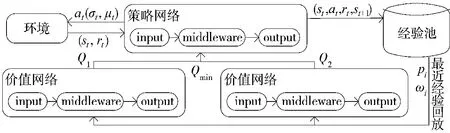
图2 最近经验回放的SAC 算法网络结构图
3.2 深度神经网络设计
SAC 算法的策略和价值函数通过深度神经网络逼近,以实现对高维连续空间的求解,本文算法的价值网络和策略网络采用不同的结构,具体网络结构如表1、表2 所示。
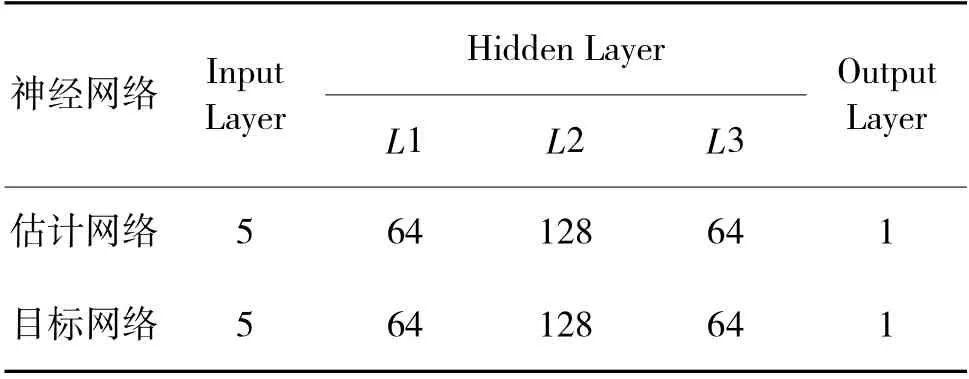
表1 价值网络结构
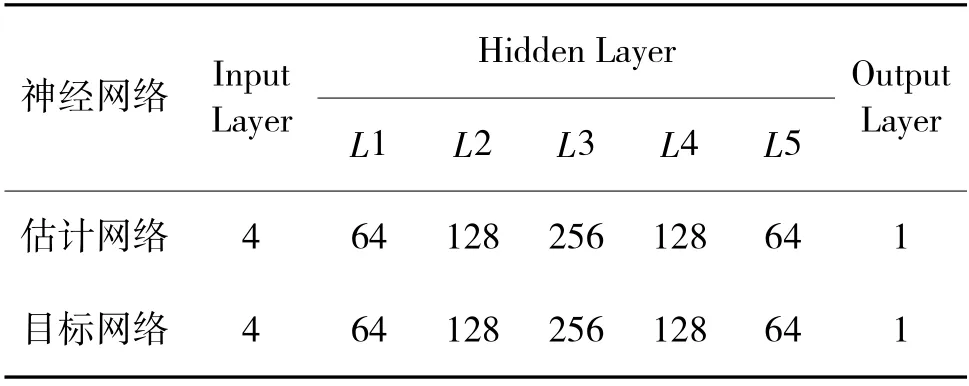
表2 策略网络结构
3.3 奖励函数设计
强化学习是智能体通过与环境的交互得到的反馈,不断调整自身动作以到奖励最大化的过程,奖励函数定义了智能体每个动作所收到的反馈,是控制行为的唯一方法,奖励函数的设计是强化学习环境中最重要和最具有挑战性的步骤之一。
本文针对行进、射击、躲避3 种不同的任务场景设计奖励函数。坦克大多处于行进状态,需要考虑能耗因素;坦克在检测到目标时对目标进行识别,本文设置坦克和装甲车两种目标,根据不同目标调整行进速度,奖励函数需要考虑的因素为减小速度以及平稳驾驶;坦克在检测到敌方炮火时采取躲避策略,此时奖励函数需要考虑的因素为提高速度以及行驶“S”形路线。综上,坦克的奖励函数为:种场景下的奖励函数。r(t)表示对能量消耗的惩罚,等于消耗能量值E。r(t)为车辆静止的惩罚,如果只有能量消耗得到惩罚,那么不开车是最有效的动作,车辆就会一直静止不动,所以需要设置一个奖励让驾驶更有吸引力:


3.4 算法流程
首先需要为智能体定义状态以及动作,状态需要满足能够为agent 提供所有必要的信息,以实现面向目标的学习过程,定义为:



4 仿真实验及分析
实验借助OpenAI Gym 来构建实验环境,通过控制速度以及朝向使坦克完成相应的作战任务,以进行改进算法与传统SAC 算法的性能比较。
4.1 实验参数
实验中两种算法采用相同的的参数设置,如表3 所示。
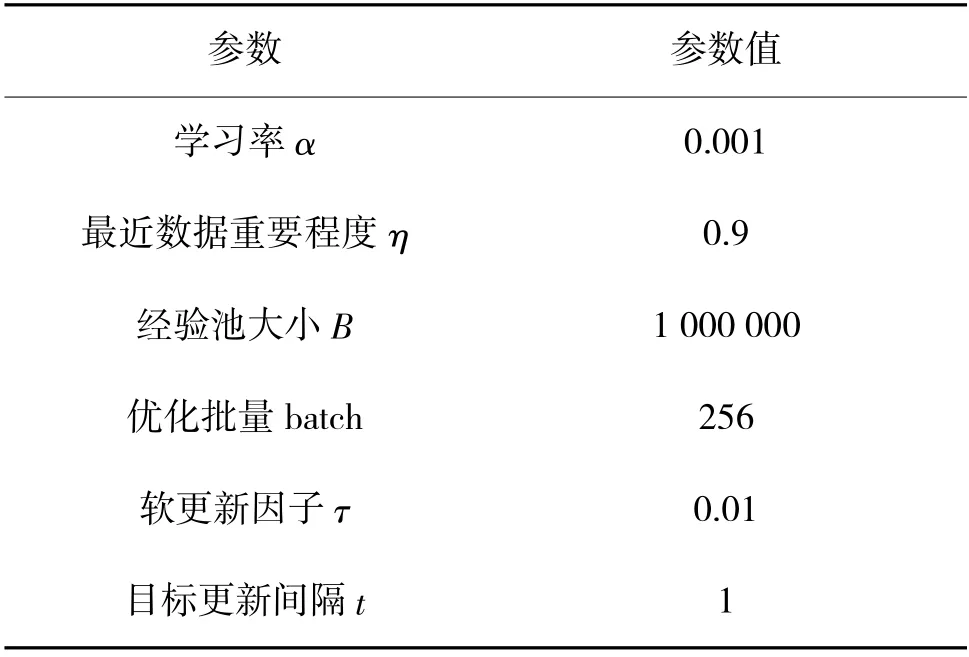
表3 参数表
实验设计了行进、射击、躲避3 种不同的任务场景,通过误差、平均奖励以及3 种任务的成功率对算法进行评价。
4.2 实验结果
分别从Critic 误差、Actor 误差以及平均奖励等角度,对原始的SAC 算法与改进算法的性能进行比较,如图3 所示。
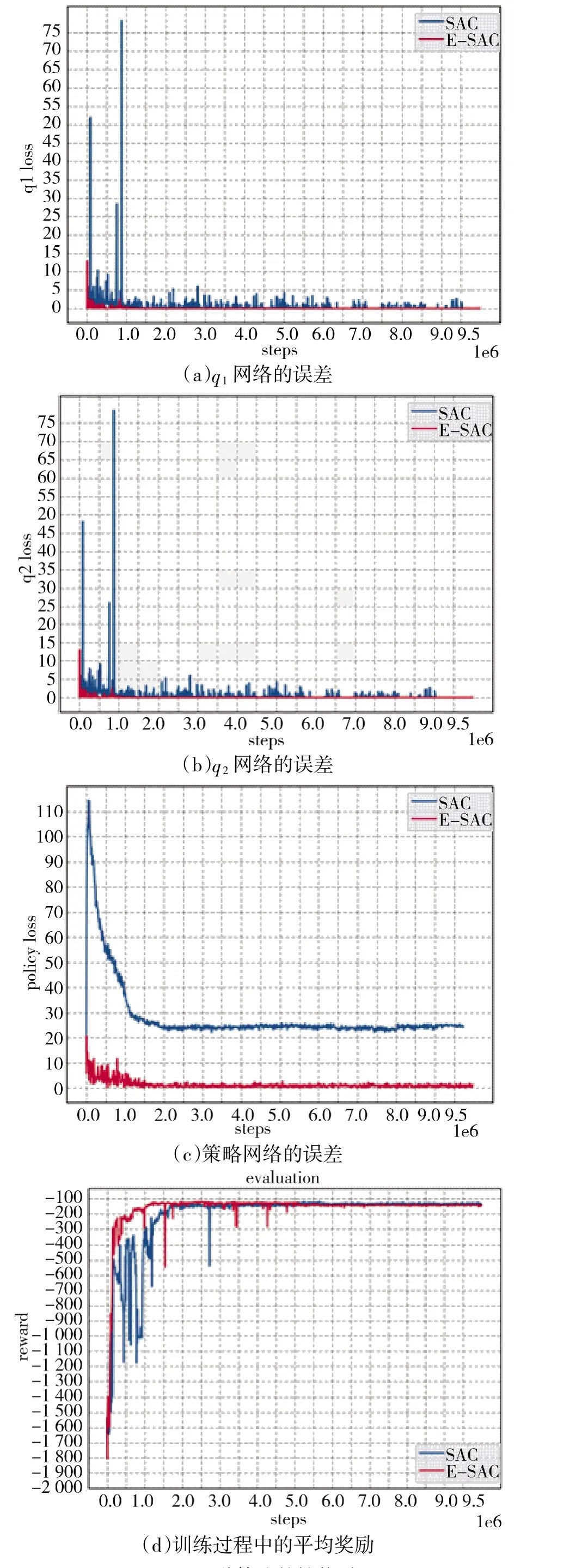
图3 两种算法的性能对比
由图3(a)可以看出,在整个训练过程中,改进算法的Q网络误差收敛速度比SAC 算法更快,更稳定,在训练至800 回合时改进算法的Q误差为3,并且此后向0 收敛,而SAC 算法的Q误差曲线更为震荡且紊乱,在训练至900 回合时误差已经突变至77。图3(b)中两种算法的Q网络误差的表现与Q类似,改进算法的训练效率以及稳定性都大大优于SAC 网络。图3(c)表示的是策略网络误差情况,改进算法最初误差仅为20,并逐渐收敛到0,SAC 算法的策略误差收敛后为22,说明最近经验回放的采样方法使策略网络修正误差更加迅速,能够有效减弱无关经验对网络的影响,减少策略网络无意义的更新次数。图3(d)是算法的平均回报曲线,改进算法增长更加稳定。以上说明改进在坦克速度控制上表现的性能优于SAC 算法。
下面从行进、射击、躲避3 种不同的任务成功率角度对改进算法与传统SAC 算法进行比较。图4为3 种不同的任务场景。
图4 行进、射击、躲避3 种任务场景
3 种任务每种测试100 次,结果如表4 所示。

表4 行进、射击、躲避成功率
由表4 可知,改进算法的性能在3 种任务场景下都优于传统SAC 算法。在相对简单的行进任务中奖励函数考虑因素较少,坦克很快可以学会这项任务,成功率可以达到100%;在难度较大的射击和躲避任务中,两种算法的效果都有所下降,尤其是躲避时需要学会“S”形路线,难度较大,需要更多的训练量以达到更好的效果。
5 结论
针对坦克速度的连续控制问题,提出一种基于最近经验回放采样的SAC 算法,大大提高了样本利用率,并针对坦克行进、射击、躲避3 种任务场景给出不同的奖励函数,提高算法的战场适用性。通过实验对比,改进算法在回报、网络误差、成功率各方面的性能都优于传统的SAC 算法,具有更快的收敛速度,满足实时决策,使得未来战场上无人坦克成为可能。未来将进一步探索地形起伏、地面材质等因素对于驾驶策略的影响,提高算法的泛化性。
猜你喜欢
小猕猴智力画刊(2022年4期)2022-05-25
中学生百科·大语文(2021年4期)2021-05-12
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
科技知识动漫(2017年5期)2017-05-11
现代兵器(2016年9期)2016-09-14
智慧少年(2016年2期)2016-06-24
中学生数理化·七年级数学人教版(2016年6期)2016-05-14
海峡科学(2013年3期)2013-10-21
数学大世界·小学低年级辅导版(2010年4期)2010-03-25
