
融合暗通道先验损失的生成对抗网络用于单幅图像去雾
2022-07-22 05:58:50程德强尤杨杨寇旗旗徐进洋
光电工程 2022年7期
程德强,尤杨杨,寇旗旗,徐进洋
1 地下空间智能控制教育部工程研究中心,江苏 徐州 221000;2 中国矿业大学信息与控制工程学院,江苏 徐州 221000;3 中国矿业大学计算机科学与技术学院,江苏 徐州 221000
1 引 言
在大气环境中,空气中聚集了许多细小颗粒物,这些细小颗粒物会导致光产生吸收或折射现象,影响光的正常辐射,改变物体呈现的颜色、对比度、饱和度、细节,导致设备采集到的图像受到严重影响。然而,基于计算机视觉的目标跟踪[1]、目标分类[2]、图像检索[3]等诸多高级任务,对图像质量有较高的需求。因此在执行高级任务之前,进行单幅图像去雾以获得更高质量的图像具有十分重要的意义。
针对单幅图像去雾,国内外许多学者做了大量研究。在单幅图像去雾研究的初级阶段,传统的图像增强方法被用来实现去雾,例如利用直方图均衡化去雾[4]、利用Retinex 理论去雾[5]等,但这些方法缺乏物理模型指导,去雾效果往往收效甚微。1999 年,Narasimhan[6]根据成像规律提出了清晰图像退化的物理模型,具体可被描述为
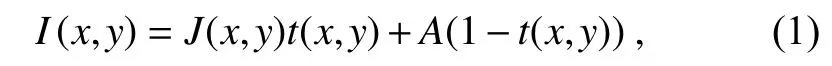
其中:I(x,y),J(x,y),t(x,y),A分别为退化后的存雾图像、清晰图像、退化传输图和全局大气光。在具体的数学推导中,退化传输图t(x,y) 被 定义为:t(x,y)=e−βd(x,y),其中d(x,y)为 场景深度,而 β为介质传输系数。可以注意到,在单幅图像去雾中,上述模型中仅仅已知退化图像I(x,y)。在这样的情况下利用该模型去雾是一个多未知量、少约束的病态问题,需要附加额外的先验信息来实现。
2011 年,He[7]等人发现在没有天空的清晰图像中总会有一个通道的有些像素值特别低,甚至接近于0。基于这一发现,他们提出暗通道先验(dark channel prior,DCP)并利用大气散射模型实现了去雾。为了进一步降低算法复杂度,减少运行时间,He 等人于2013 年设计了引导滤波器[8]并将其嵌入到之前设计的算法中,取得了良好的效果。同年,Meng[9]等人探索了退化传输图的固有边界约束,将其总结为边界约束及上下文正则化先验(boundary constraint and contextual regularization,BCCR),他们利用这一先验规律结合大气散射模型实现了去雾。2015 年,Zhu[10]等人发现在一幅存雾图像中,雾的浓度与亮度和饱和度之差成正相关,他们将这一先验规律总结为颜色衰减先验(color attenuation prior,CAP),并据此有监督地学习了估计透射传输率的线性模型,最终实现了去雾。2020 年,Wang[11]等人结合光场多线索和大气散射模型实现了图像去雾。
在上述基于先验信息的去雾算法中,暗通道先验算法开创了利用大气散射模型进行单幅图像去雾的先河,但这种简单有效的去雾算法尚且存在一系列问题:第一,退化传输图空间连续性差导致最终的去雾图像存在边缘伪影;第二,图像存在天空区域或亮域等不符合暗通道先验规律的区域,最终的去雾图像色彩失真。为了解决传输图空间连续性差的问题,Zhao[12]等人于2019 年提出一种多尺度融合最优模型来增强退化传输图的空间连续性;2020 年,Yan[13]等人重写了最小化滤波器函数,使得在提取暗通道特征图的过程中尽可能少地引入边缘信息跳跃。为了解决天空域或亮域的问题,Wang[14]等人提出计算暗通道置信度来加权补偿退化传输图。总的来说,基于先验信息的去雾算法经过长年的发展,取得了瞩目的成就。但是,这类算法通常存在在特殊场景下不稳定的情况,因此具有一定的局限性。
近几年,深度神经网络的出现给计算机视觉底层处理任务提供了强大工具,也促进了单幅图像去雾算法的快速发展。Ren[15]等人提出利用两层(convolutional neural network,CNN)网络从存雾图像中初步估计以及细化传输图。Cai[16]等人设计了一种新型网络用于提取特征来模拟一些先验信息的实现,同时加入了多尺度映射来估计传输图。Li[17]等人通过重构大气散射模型来联合估计传输图与大气光,实现了“端到端”的去雾。上述的这些去雾算法利用合成数据集学习存雾图像与传输图或者联合估计图之间的潜在映射关系,最终去雾步骤仍然利用大气散射模型来实现,如果传输图估计不准确则会引入失真与伪影。为了实现真正的端到端的去雾,Ren[18]等人设计了一种门控网络来融合一些相关的特征图像,最终实现了去雾。2014年,Goodfellow[19]提出生成对抗网络(generative adversarial network,GAN)思想。基于这一思想,Li[20]等人训练了一种条件GAN 网络,引入了对抗损失、L1损失、感知损失[21]来从存雾图像中恢复清晰图像。Deniz[22]等人使用循环对抗网络CycleGAN[23]进行训练,避免对成对数据集的依赖。
上述基于生成对抗网络的去雾算法依赖于训练数据集,非常容易造成模型的预测结果对于样本真值过度拟合。基于这样的问题,Li[24]等人引入暗通道先验损失,训练了一种条件GAN 网络,一定程度上解决了过度拟合的问题,但是在设计暗通道先验损失的过程中,暗通道特征图的提取过程仍然是一个包含最小值滤波的非凸函数,无法充分保证取得最优解[24-25]。Alona[26]等人提出了一种无监督的去雾方法,根据软抠图的模型设计了损失函数,但是需要在适当阶段停止训练以获得更好的图像质量。
与上述算法不同,本文首先利用最小值滤波等效像素压缩理论[8],将求取暗通道特征图的最小值滤波步骤等效为对像素强度值进行非线性或线性压缩。一方面从根本上解决了暗通道求解函数非凸的问题,使得将暗通道先验损失嵌入网络训练成为可能。另一方面,该方法不需要设置固定尺度提取暗通道特征图,提高了算法的尺度鲁棒性。其次,本文算法不仅利用对抗损失、L1损失、感知损失组合来指导网络模型训练,提高去雾效果,还基于图像暗通道特征图的稀疏性以及偏度性质,构建了一个包含两个约束项的损失函数,用于纠正预测图像的暗通道特性。这种针对暗通道特性设计的损失函数使用暗通道特性监督网络训练,对预测结果产生影响,避免了网络模型对样本真值过度拟合。
总结来说,本文主要做了以下三方面的工作来提升最终的去雾效果:
1) 引入了最小值滤波等效像素压缩理论,不仅使得将暗通道先验损失嵌入网络训练成为可能,也提高了算法对不同尺寸图像的适应性。
2) 通过约束暗通道特征图的稀疏性以及偏度性质构建了新的暗通道先验损失函数。
3) 在传统的GAN 网络去雾框架中嵌入了暗通道先验损失,避免了模型对样本真值的过度拟合,同时提升了去雾效果。
2 相关理论
2.1 生成对抗网络
近一段时间,生成对抗网络被普遍应用于图像恢复领域,在图像去噪、去模糊、高分辨率重建等方面取得了不俗的效果。生成对抗网络的框架主要包含一个生成器网络G以及一个判别器网络D,生成器网络尽量学习样本A至 样本B的映射关系以最大限度地欺骗判别器网络,而判别器网络则尽量区分生成器网络预测的假样本与真样本的区别,从而达到对生成器网络的指导作用,其具体的网络框架示意图如图1所示。
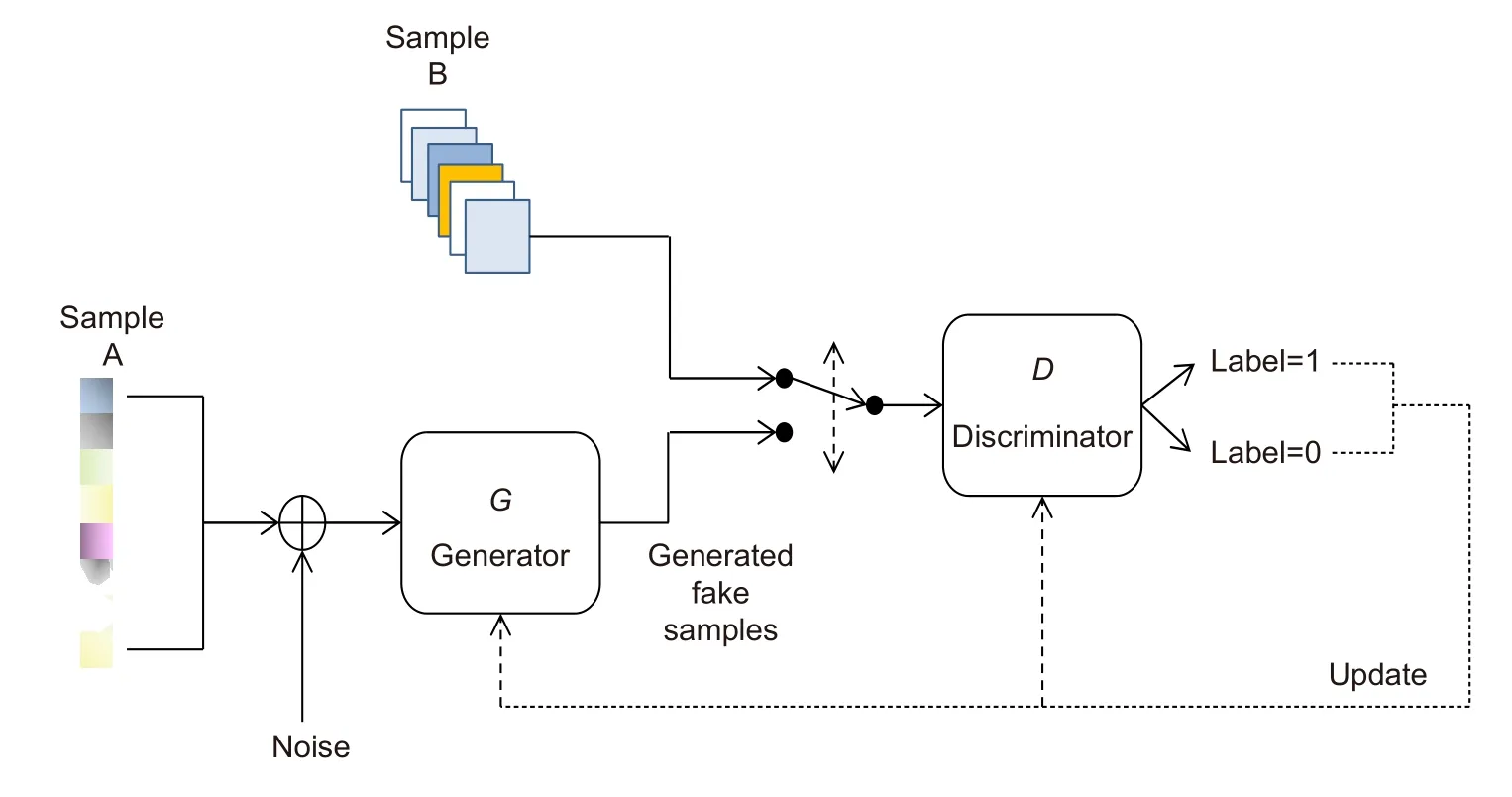
图1 对抗生成网络框架Fig.1 Framework of adversarial generation network
其中的生成器网络G在判别器网络D的指导下更新其网络参数,使其生成的样本尽量接近真实样本的数据分布,其目标函数可以被描述为
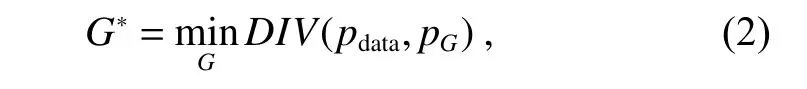
其中:G∗代表最小化真实数据分布pdata与生成的数据分布pG之间的距离。为了衡量真实数据分布与生成数据分布之间的距离,判别器网络的目标函数定义为

其中:D∗代表最大化准确判别的概率,E为数学期望,Ex∼pdata(x)[logD(x)]表示判别为真实数据(label=1)的概率,Ex∼pG(x)[log(1−D(x))]表示判别为假数据(label=0)的概率。于是,生成器网络的目标函数可被重新定义为
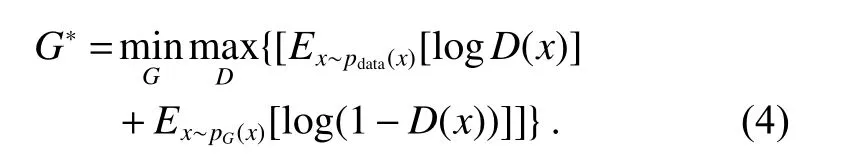
最后,根据上述的目标函数在训练中交替更新生成器网络与判别器网络的参数,使得两者在博弈中达到动态平衡。
2.2 暗通道先验
He[6]等人分析了不含天空的5000 张彩色图像的潜在特征,提出了意义重大的暗通道先验规律:对于没有天空的清晰图像,总有一个通道的有些像素强度特别低,甚至接近于0。如果以一个固定尺度将这些像素对应的通道强度值提取出来,就可以形成一张暗通道特征图像:
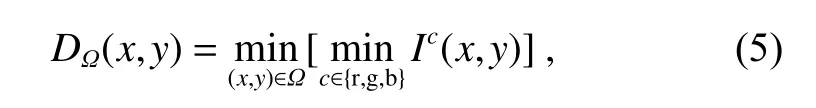
其中:DΩ(x,y)为以 Ω 为尺度的暗通道特征图,Ic为图像的RGB 三个通道强度,x,y是图像的坐标,图2 为一组清晰图像与存雾图像的暗通道特征图对照。

图2 暗通道特征图对照。(a) 原始图像;(b) 暗通道特征Fig.2 Dark channel feature comparison.(a) Original images;(b) Dark channel feature
为了进一步验证暗通道先验规律的正确性,分析5000 张清晰图像的暗通道特征图,发现其强度分布有着如下特点:86%的像素点的强度分布在0 附近,90%的像素点的强度低于25;另外,大多数的暗通道特征图均有着非常低的平均强度。然而,雾霾图像的暗通道特征图强度分布则有不同表现:超过50%的像素点的强度高于50,平均强度也不再趋近于0,具体结果如图3 所示,上半部分为清晰图像的分布结果,下半部分为存雾图像的分布结果。
从图2,图3 中可以看出,相较于存雾图像,清晰图像的暗通道特征更为稀疏且强度分布有着非常强的右偏特性。因此,本文利用暗通道特征的稀疏特性以及偏度特性构建损失函数,避免训练模型对样本真值过度拟合,进一步增强去雾效果。

图3 暗通道特征图强度分布。(a) 强度分布;(b) 5000 张图像的平均强度分布Fig.3 Dark channel feature intensity distribution.(a) Intensity distribution;(b) Average intensity distribution of 5000 images
3 本文算法
3.1 网络结构
本文依托生成对抗网络框架,并利用现有的网络结构设计生成器与判别器来实现单幅图像去雾,算法框架如图4 所示,具体网络结构将在3.1.1 及3.1.2 章节中阐述。
3.1.1 生成器网络
生成器网络G被用于从存雾图像中恢复出最终的清晰图像。由于带有跳跃连接的“编码解码”网络结构[27-28]对于处理视觉底层任务具有良好的效果,本文使用一种类似的网络结构来构建生成器。在编码阶段,包含了三个尺度的堆叠残差块,根据文献[29]的推荐,本文在每一个残差块内不使用归一化层。在解码阶段,同样的包含三个尺度的堆叠残差块。网络通过下采样卷积层得有效特征并将尺度缩小为原来的1 /2,通过上采样卷积层将图像恢复至原来的解空间内,每一层卷积层后跟随非线性ReLU 层,同时将各跳跃连接特征相加得到最终特征。如图4 所示,其中绿色模块代表普通卷积层,紫色模块代表下采样卷积层,蓝色模块代表上采样卷积层,灰蓝色模块代表残差块,橙色模块代表Tanh 函数层,具体的网络参数以及每一个残差块的输入输出通道数如表1 所示。

表1 生成器网络参数Table 1 Parameters of generator network
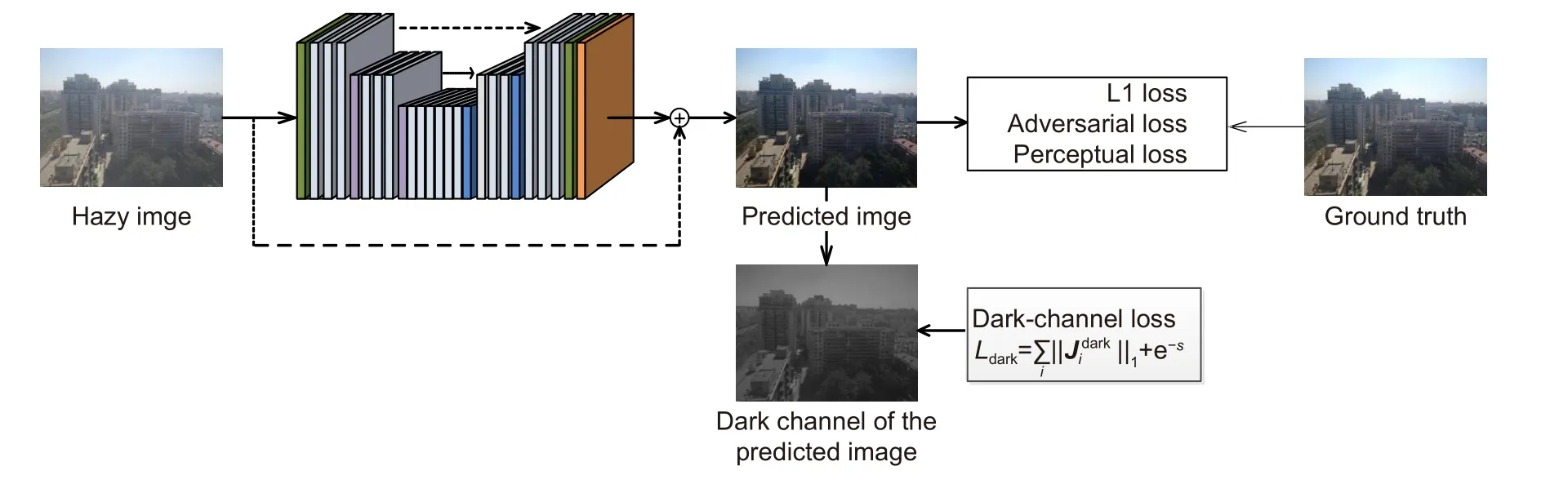
图4 本文算法框架Fig.4 Framework of the proposed algorithm
3.1.2 判别器网络
PatchGANs[30-32]判别器网络相对于传统的判别器网络有着更少的参数,是一种稍轻量级的判别器网络。本文使用类似的PatchGANs 作为判别器网络,conv1-conv4 卷积层后均跟随LeakeyReLU 以及InstanceNorm层,具体的网络参数如表2 所示。

表2 判别器网络参数Table 2 Parameters of the discriminator network
3.2 损失函数
本文算法的损失函数涉及两个部分,一方面是衡量预测图像与样本真值之间距离的L1损失、感知损失Lper、对抗损失Ladv组合;另一方面是根据清晰图像暗通道性质设计的暗通道先验损失Ldark。最终,本文给予所有损失函数以不同的权重来对网络模型进行联合训练。
3.2.1 损失组合
为了使得对抗网络的预测图像与样本真值接近,本文使用L1损失约束预测图像与样本真值之间距离:
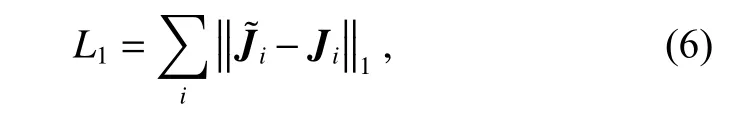
其中:i表示训练数据集的样本编号,以及J表示预测图像以及样本真值的向量形式。另外,Justin 等人[21]证明了高质量图像可以通过定义感知损失来实现,因此本文基于经过预训练的vgg-16 网络生成高层特征并定义了感知损失,用于衡量预测图像与样本真值之间的感知误差:


其中:Dg为判别器,用于判断图像来自于预测图像或者样本真值。
3.2.2 暗通道先验损失
经过He[7]、Li[24]、Pan[25]等人及本文第2.2 章的充分分析,可以得出结论:清晰图像的暗通道特征图相对于存雾图像的暗通道特征图更为稀疏且有着更强的右偏特性,因此本文算法试图将暗通道特征图的稀疏性以及偏度特性作为约束项加入到最终的损失函数中,指导网络训练,避免模型对样本真值的过度拟合,提升去雾效果。
但是由于最小值滤波器的存在,直接由式(5)计算预测图像的暗通道特征图并将其嵌入网络训练,本质上是对一个非凸函数求极值,可能得不到全局最优解。
为了解决上述问题,本文引入了最小值滤波等效像素压缩理论[13],将式(5)中的最小值滤波步骤替换为对每一个像素点进行强度值压缩:

其中:D(x,y)为 此方法得到的新暗通道特征图,lavr为图像强度均值,ε为图像强度标准差,ρ为图像强度分布的偏度。
在进行上述像素强度值压缩的过程中,Yan 等人[13]提出以图像强度均值lavr为阈值,在非亮域内(即l∈(0,lavr)) 执行幂律压缩,在亮域内(即l∈(lavr,1))执行线性压缩,这样有效避免了在天空域或亮域内对像素强度过度压缩的问题。
总的来说,通过对图像的像素强度进行非线性或线性压缩来求取暗通道特征图,其实现函数本身是一个凸函数,这有利于在神经网络中求取最优解;另外此方法对不同尺寸的图像均有着较好的适应性,不需要如式(5)中一样设置固定的最小值滤波尺度 Ω。
在有效解决暗通道求解过程存在非凸问题的基础上,本文以L1正则化约束预测图像的暗通道稀疏性:


其中:s为暗通道特征图的偏度分布,具体可以被表示为

其中:N为预测图像暗通道特征图的总像素数。,分别为均值以及标准差。根据本文第2.2 章节分析可知,清晰图像的暗通道特征图强度分布倾向于向右偏移,而雾霾会影响这种右偏特性。在统计学中,这种分布上的偏移由偏度概念来准确表达,因此采用上述偏度特征来近似雾霾的影响是合理的。
最后,采用同比例加权的方式,最终的暗通道先验损失函数可以被定义为

3.2.3 网络总损失函数
本文算法将3.2.1 章的对抗损失Ladv、L1损失、感知损失Lper以及3.2.2 章的暗通道先验损失Ldark结合起来,用于最终的网络训练:
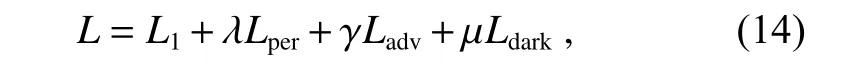
其中:λ,γ,µ分别为感知损失、对抗损失以及暗通道先验损失的加权权重。具体来说,L1损失、感知损失Lper、对抗损失Ladv组合可以提供去雾效果的同时,较好地保持图像的结构、纹理细节。而暗通道先验损失Ldark的加入使得网络模型不再只依靠样本真值更新参数,有利于避免预测图像对样本真值过度拟合。
4 实验结果与分析
4.1 数据集设置
为了更好地训练以及评估模型,本文使用了目前规模较大的单幅图像去雾数据集RESIDE[33]。该数据集早期版本中包含了一个用于模型训练的训练子集ITS、一个综合测试子集SOTS 以及一个混合主观测试子集HSTS。在后续版本中,该数据集扩展了一个训练子集OTS 以及一个任务驱动测试子集RTTS。其中,训练子集ITS 使用了来自于NYU2[34]以及Middlebury Stereo[35]的清晰图像并依据其提供的深度真值合成了13990张室内存雾图像。OTS 使用了来自于文献[36]的真实室外图像并依据文献[37]提供的方法预测了图像深度,最终合成了72135张室外存雾图像。ITS 与OTS 通过随机选择介质传输系数 β与全局大气光A,并通过式(1)的大气散射模型来实现最终的合成步骤。综合测试子集SOTS 包含了室外室内测试集SOTS-outdoor 以及SOTS-indoor 两个部分,每一个测试集各提供了500张测试样本。混合主观测试子集HSTS 包含了 10张来自于互联网的真实存雾图像以及10张已知样本真值的合成图像。为了加强训练数据集的鲁棒性,本文在OTS 以及ITS 数据集中各随机选择了3000张样本。也就是说本文网络模型的训练数据集包含共计6000张样本图像,而且它们来自于室外室内不同场景。
4.2 训练细节与参数
首先,为了进一步加强训练数据集的鲁棒性与健壮性,本文对从OTS 与ITS 数据集采集来的 6000张样本图像进行了以下方式的数据扩充:随机裁剪至256×256或 512×512尺寸;水平翻转或垂直翻转;随机旋转0,45°,90°,135°。最终将所有的扩充样本随机裁剪至256×256尺寸,并将像素强度值归一化至[−1,1]。最终的训练样本数量为:6000×3=18000。
根据文献[24]的建议,感知损失Lper、对抗损失Ladv的损失权重被设置为λ=10−3,γ=10−5。而暗通道先验损失的损失权重被设置为 µ=5×10−6。与文献[16]类似,本文算法的生成器与判别器均基于PyTorch 框架实现,输入网络的batch-size 设置为1,使用Adam 优化器,动量参数设置为β1=0.9,β2=0.999,初始学习率设置为lr=0.0002。共设置 200个epochs 来训练网络,在前 100个epochs 中保持初始学习率,在后 100个 epochs 中学习率线性衰减至10−6。在训练过程中,生成器与判别器交替更新参数,具体设置为生成器每更新5 次判别器更新1 次。
4.3 定量评价
为了定量评价本文算法模型在去雾方面的性能,将本文算法与现有的一些先进去雾算法进行比较,其中包含基于传统先验方法的DCP[7],BCCR[9],CAP[10];基于学习退化传输图方法的MSCNN[15],D-Net[16],AOD-Net[17];基于端到端方法的GFN[18]以及基于无监督方法的DEnegy[26]。
将上述算法与本文算法在综合测试集SOTS 以及混合主观测试集HSTS 的合成图像上进行对比实验,使用峰值信噪比(PSNR)与结构相似度(SSIM)作为最终评价指标,具体结果如表3 所示。从表3 中可以看出,在HSTS 以及SOTS-outdoor 两个测试集上,本文算法在各项指标上都展现了最好的结果;在SOTSindoor 测试集上,PSNR 指标展现了最好的结果。实验结果证明,本文算法不论是与基于先验信息的去雾算法相比,还是与基于深度学习的去雾算法相比,都有一定优越性。具体的定量结果分析说明如下:

表3 各算法在SOTS 测试集以及HSTS 测试集合成图像上的定量结果Table 3 Quantitative results of each algorithm on SOTS test-set &synthetic images of HSTS test-set
首先,基于先验信息的去雾算法[7-10]对于特殊场景下的图像没有良好的适应性,在执行去雾时,先验规律可能会失效,最终反映为评价指标上的失利。举例来说,图像的天空域或亮域不符合暗通道先验规律,这会导致DCP[7]算法预测的退化传输图不准确,直接结果就是出现失真现象;另外,在浓雾场景下,颜色衰减先验的敏感性下降,导致CAP[10]算法在浓雾场景下的去雾效果一般。依此类推,除了上述两种先验信息外,其它先验信息也难以保证对所有场景下的图像都有绝对符合性,所以基于先验信息的去雾算法在进行大规模图像质量评价时,定量结果往往一般。与传统的基于先验信息的去雾算法不同,本文算法使用了生成对抗网络框架,并设置了不同的损失函数用于指导网络训练,生成的图像保留了较好的结构与纹理细节,因此在评价指标上获得了较高的得分。
其次,基于学习退化传输图的去雾算法[15-17]在预估退化传输图时有时缺乏准确性,通过大气散射模型恢复的图像会引入失真或伪影。然而,这种准确性取决于多方面因素,其中最为主要的在于传输图真值的可靠性。目前,传输图真值主要依靠场景深度以及t(x,y)=e−βd(x,y)进行合成,而场景深度通常来自相关数据集提供的仪器结果[34-35]或引入其它深度估计算法[37-38]进行估计。由于仪器始终存在误差,深度估计算法也存在不稳定性,由此得到的传输图真值缺乏准确性,所以该类算法的定量评价结果仍有局限性。与其不同,本文算法不引入预估传输图的中间环节,而是通过生成对抗网络直接从一张存雾图像中恢复出清晰图像,使用端到端的方法提升定量评价指标。
最后,传统的基于端到端[18]的去雾方法,通常只依靠预测图像与样本真值之间的损失来更新网络参数,其训练结果本质上是样本真值的一家之言。即网络模型只考虑预测结果与样本真值是否相近,而忽略了实际的去雾能力。基于无监督[26]的去雾算法在网络训练过程中,需要在合适的阶段停止网络参数更新以保证获得更好的结构与细节。如果停止训练的时机不当,则会造成定量评价结果的大幅降低。与上述两种方法不同,本文算法通过L1损失、感知损失和对抗损失保证生成的图像具有良好的结构与纹理细节,通过暗通道先验损失保证生成的图像在暗通道特征方面更接近清晰图像,有效避免模型对样本真值过度拟合,提升定量评价指标。
近年来,基于不同技术路线的去雾算法不断发展,去雾效果不断提升,为了进一步展现本文算法的优越性,实验对象增加CycleGAN[22],SM-Net[24],RefineDNet[39]三种改进模型并在室内场景测试集DHAZY[40]、高分辨率测试集HazeRD[41]和真实存雾图像测试集BeDDE (包含208 个真实存雾图像和对应的清晰图像)上进行对比实验,引入VSI[42]、VI[43]及RI[43]衡量算法的有效性,具体结果如表4 所示。
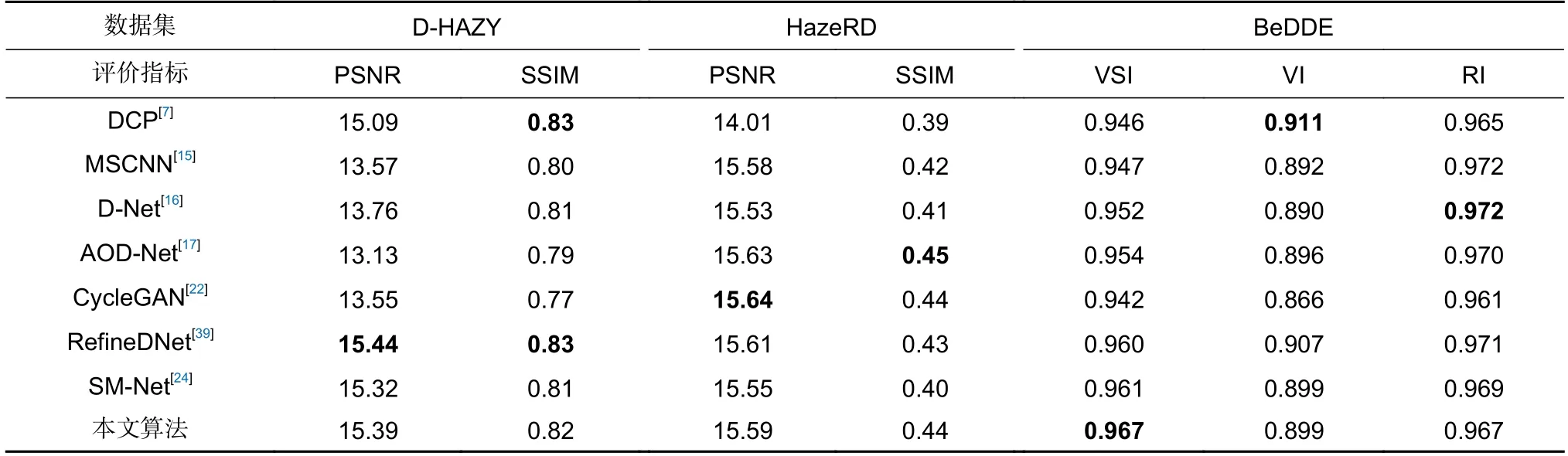
表4 各算法在D-HAZY、HazeRD 以及BeDDE 测试集上的定量结果Table 4 Quantitative results of each algorithm on D-HAZY &HazeRD &BeDDE test-set
首先,从室内场景测试集D-HAZY 上分析,本文算法的PSNR 及SSIM 指标均显著高于CycleGAN[22]和SM-Net[24]两种改进模型,RefineDNet[39]模型取得了更好的PSNR 及SSIM 指标,分别高出本文算法0.05 和0.01。但是这种微弱的差距是符合预期的,因为RefineDNet[39]模型使用室内场景数据集ITS 的全部样本进行训练,一定程度上增强了模型对室内场景图像的有效性。
其次,从高分辨率测试集HazeRD 上分析,本文算法的各项定量评价指标显著高于DCP[7]等基于先验信息的去雾算法,高于MSCNN[15]、D-Net[16]以及GFN[18]三种基于深度学习的去雾算法。AOD-Net[17]以及CycleGAN[22]在高分辨率图像去雾方面取得了更好的定量评价指标,但本文算法与他们的差距不大。
最后,从真实存雾图像测试集BeDDE 上分析,本文算法在各项指标上均取得了突出的结果,特别是VSI 指标,在全部算法中排名第一,这充分说明本文算法不仅在提升去雾性能方面具有优越性,也可以有效避免图像发生失真。
4.4 定性评价
为了更直观地展示本文算法的优越性能,图5 展示了不同去雾算法在SOTS、HSTS、D-HAZY 等合成测试集的定性结果;图6 展示了不同去雾算法在真实存雾图像上的定性结果,其中的对照组为不加入暗通道先验损失时,本文算法模型的处理结果。从中可以看出,DCP[7]与BCCR[9]算法在处理天空区域时造成了比较严重的失真现象;CAP[10]算法较好地处理了天空区域,但是其去雾性能受到雾气浓度影响,去雾结果不彻底。MSCNN[15],D-Net[16],AOD-Net[17]等基于学习退化传输图的去雾算法在处理结果上有雾块残留。GFN[18]算法的处理结果对比度更强,但是造成了一定程度上的色彩偏移。CycleGAN[22]算法的处理整体偏暗并且有伪影失真,SM-Net[24],RefineDNet[39]在图像阴暗处的处理效果不佳,雾块残留较多。对照组模型的恢复结果虽然在结构、细节方面较好,但实际的去雾性能不佳,雾块残留较多。相比之下,加入暗通道先验损失的本文算法模型,其恢复图像不仅在结构、细节方面得到了更好的保证,真实的去雾性能也得到了提高。

图5 各算法在合成图像上的定性比较Fig.5 Qualitative comparison on synthetic images

图6 各算法在真实图像上的定性比较Fig.6 Qualitative comparison on real hazy images
4.5 消融实验
为了公平比较本文创新点的有效性,采用了两个对照模型与本文算法作比较:第一个对照模型为第4.4 章训练的基础模型;第二个对照模型在训练时采用了与本文算法相同的损失权重,但在暗通道特征图的计算上使用了文献[22]的“查找表”方法。结果表明,本文算法全面优于两个对照组,具体结果在4.5.1 和4.5.2 小节中详细讨论。
4.5.1 暗通道先验损失
首先,为了充分证明暗通道先验损失的有效性,将本文算法于其它两个对照模型在SOTS 测试集以及HSTS 测试集上做定量评价。为了衡量各模型在真实雾霾图像上的表现,需要采用无参考图像的评价方法[44-45]等。本文最终的定量结果通过PSNR、SSIM和无参考评价方法BCEA[44]来反映。无参考评价方法BCEA 有3 个评价指标:e,r,p。其中,e表示恢复图像中新出现可见边缘的比率;r表示对比度恢复,具体定义为可见边缘的平均归一化梯度;p表示图像恢复后像素变为过饱和像素的概率。在评价时,越高的e,r指标,越低的p指标,代表更好的恢复效果。实验结果如表5 和图7 所示。从图7 中可以看出,本文算法在三个测试集上的PSNR 和SSIM 指标均显著领先于对照组。从表5 中可以看出,加入暗通道损失的对照组2 以及本文算法在e,r指标上明显超出对照组1。上述结果充分说明,暗通道先验损失可以有效避免过度拟合问题,提高模型的实际去雾能力。不过,值得注意的是,对照组2 以及本文算法在p指标上略高于对照组1。这种结果是符合预期的,因为暗通道先验损失通过约束暗通道特征图的稀疏性以及偏度性质提高去雾能力,不可避免地引入了一定的暗像素伪影,增加了过饱和像素的数量。但是这种问题可以通过引入其它损失函数来解决,将暗像素伪影与过饱和被控制在可接受的范围内,图8 的定性结果在一定程度上反映了这种情况。
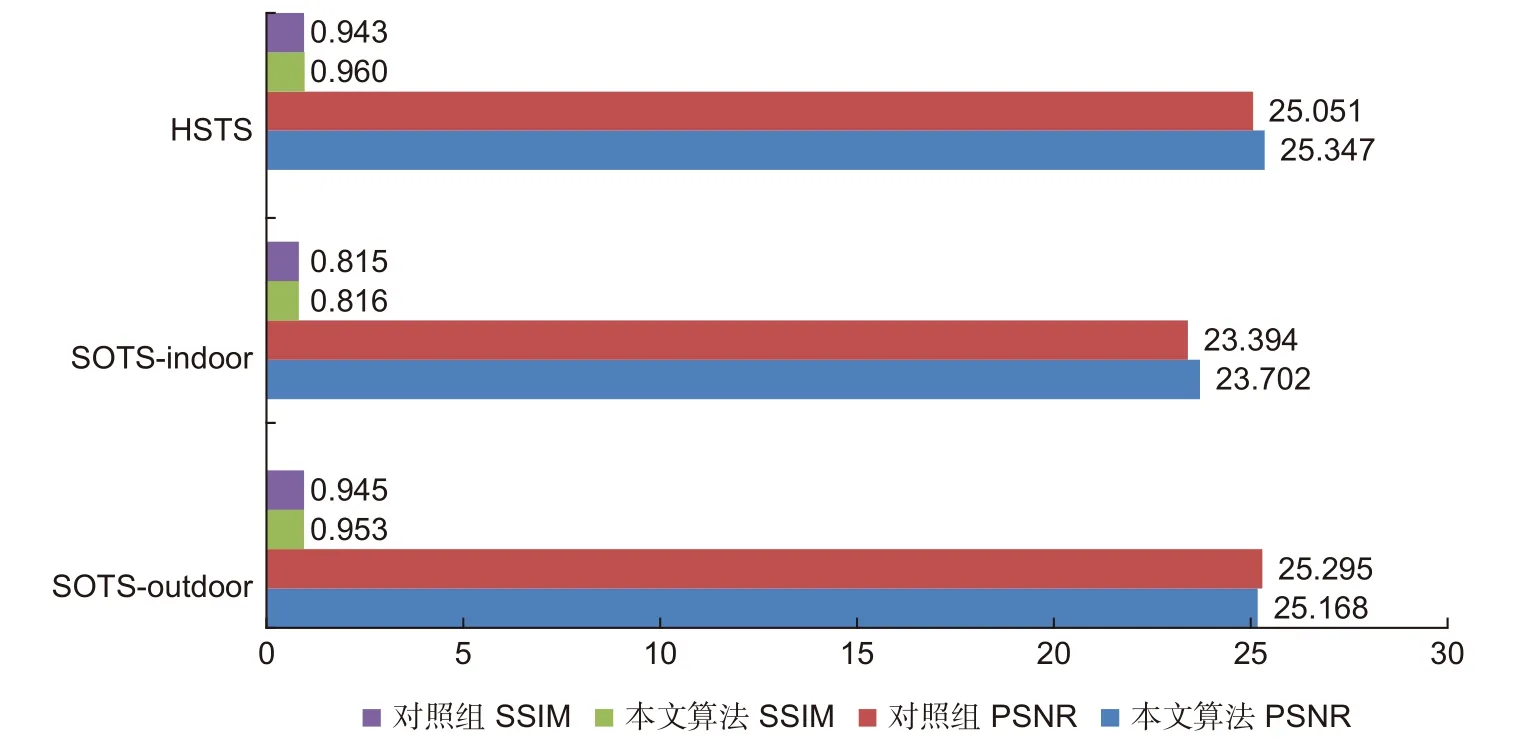
图7 对照组与本文算法在SOTS 测试集以及HSTS 测试集合成图像上的定量比较Fig.7 Quantitative comparison with control group on SOTS test-set &synthetic images of HSTS test-set

图8 对照组与本文算法在HSTS 测试集真实图像上的定性比较Fig.8 Qualitative comparison with control groups on real images of HSTS test-set
4.5.2 基于像素值压缩的暗通道特征图提取策略
本文引入了一种新的策略来提取图像的暗通道特征,将最小值滤波步骤等效为对像素强度值进行非线性或线性压缩。为了验证该策略的优越性,将本文算法以及上述两个对照模型在HSTS 测试集的真实图像上做了定量评价,结果如表5 和图9 所示。

图9 对照组与本文算法在HSTS 测试集真实图像上的定量比较Fig.9 Quantitative comparison with control group on real hazy images of HSTS test-set

表5 对照组与本文算法在HSTS 测试集真实图像上的定量结果Table 5 Quantitative results of the control groups &proposed algorithm on real images of HSTS test-set
可以看出,本文算法在e,r指标上显著高于对照组2,而p指标略低于对照组2,这意味着本文算法去除了更多的雾块而没有引入更多的过饱和像素。上述结果充分展示了基于像素值压缩的暗通道特征图提取策略在网络训练中的优越性。
4.6 运行时间
为了公平比较,以处理SOTS 测试集(样本尺寸大约为500×500左右)的平均运行时间作为标准,将本文算法与目前较为先进的DCP[7]、CAP[10]、MSCNN[15]、D-Net[16]、AOD-Net[17]、GFN[18]算法作了对比,具体结果如表6 所示。其中,DCP[7]、CAP[10]、D-Net[16]算法在CPU 上完成对SOTS 测试集的处理,而MSCNN[15]、AOD-Net[17]、CycleGAN[22]、GFN[18]以及本文算法在GPU 上完成。硬件具体型号为:

表6 各算法在SOTS 测试集上的运行速度(时间/s)Table 6 Run time of each algorithm on SOTS test-set
1) CPU: Intel(R) Core(TM) i5-8400 CPU@2.80GHz 2.81GHz。
2) GPU:Nvidia GeForce GTX 10606GB CUDA 1280。
CAP[7]得益于算法的低复杂度、AOD-Net[13]得益于其轻量级的网络,在运算速度上取得了较好的结果,但在去雾性能上仍有待提高。本文算法受益于GPU并行处理能力,在运算速度上基本领先于其它先进算法,也取得了较好的去雾性能。
5 结 论
本文提出了一种融合暗通道先验损失的生成对抗网络用于单幅图像去雾。具体来讲,本文首先引入新的暗通道特征图提取策略,通过对像素强度值进行线性或非线性压缩来代替传统的最小值滤波步骤。该提取策略不需要设置固定尺度,在增强尺度鲁棒性的同时,还可以解决非凸函数难以嵌入网络训练的问题。之后,本文通过约束暗通道特征图的稀疏性以及偏度性质设计一种暗通道先验损失函数,并联合通用损失函数共同训练网络模型。暗通道先验损失的加入,一方面可以避免网络模型对样本真值过度拟合,另一方面,可以使得模型预测结果的暗通道特征图更接近清晰图像的暗通道特征图,从而在不依靠样本真值的情况下,提升去雾效果。实验结果表明,本文算法有效解决了传统的GAN 网络去雾算法存在的过度拟合问题,相比于其它先进算法,本文算法取得了更佳的数据指标,提升了实际的去雾性能。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
成都信息工程大学学报(2019年3期)2019-09-25 08:31:14
今日农业(2019年15期)2019-01-03 12:11:33
电子制作(2017年1期)2017-05-17 03:54:35
自动化学报(2017年5期)2017-05-14 06:20:44
探测与控制学报(2015年4期)2015-12-15 15:00:56
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
智能系统学报(2015年5期)2015-12-03 05:18:20
东南法学(2015年2期)2015-06-05 12:21:36
