
基于深度学习的RGBD图像协同显著目标检测
2022-07-22 13:36周晓飞郭舒瑶温洪发刘炳涛李世锋张继勇颜成钢
信号处理 2022年6期
周晓飞 郭舒瑶 温洪发 刘炳涛 李世锋 张继勇 颜成钢
(1.杭州电子科技大学自动化学院,浙江杭州 310018;2.杭州电子科技大学计算机学院,浙江杭州 310018;3.中电数据服务有限公司,北京 100088)
1 引言
对于视野中出现的所有物体,人类视觉往往会更加关注吸引人眼注意的物体,依据这种视觉信息处理机制捕捉的物体被定义为显著目标。显著目标检测(Salient Object Detection,SOD)作为计算机视觉领域的基础性任务,旨在模拟人类的视觉系统,从图像/视频所包含的场景中快速地定位感兴趣的目标,而忽略区域中的其他信息。Itti 等人[1]基于一般计算框架和心理学理论,提出了最早的显著性模型,其能够凸显场景中的显著物体。Liu等人[2]和Achanta 等人[3]将显著目标检测定义为一个二值分割问题,致力于定位分割显著区域。显著目标检测方法的使用可以减少数据处理量、加快信息处理速度,被广泛运用于分割[4]、识别[5]、压缩[6]、图像编码[7]、图片质量评价[8]等相关视觉任务中。
与此同时,人们发现随着深度相机相关技术的迅速发展,获取深度(Depth)信息的方式变得更为便捷。相关研究表明,相比于RGB 图像凸显场景表观信息,Depth 图像能够有效凸显场景中物体的几何边界。因此,研究人员尝试利用RGBD 图像来提高显著目标检测的准确性。例如,Qu 等人[9]采用早融合策略,将手工设计的RGB 特征和Depth 特征串接起来,并以此作为卷积神经网络(Convolutional Neural Networks,CNN)的输入。Fan 等人[10]在通道维度上将RGB 图像和Depth 图像进行连接,以此作为卷积神经网络的输入。Wang 等人[11]采用后期融合策略,并学习一个开关映射函数来自适应地融合RGB 分支和Depth 分支的显著性预测结果。Liu 等人[12]采用中期融合策略,提出了一种基于相互注意力的多模态融合结构来有效融合RGB 分支和Depth分支的卷积特征。
相较于以往对RGBD图像进行的显著目标检测研究,本文将研究拓展到多幅RGBD图像。这里,多幅RGBD 图像之间存在极强的相关性,有着类似的目标。为此,本文尝试利用相关图像间的信息,对一组RGBD 图像中的协同显著目标进行检测。由此可以看出,协同对象应同时具有两个主要属性:1)对象在单个图像中是显著的;2)对象在相关图像组中普遍存在。同时,注意到现有的RGBD 图像协同显著目标检测方法主要有两类,包括基于传统图像处理算法的模型和基于手工提取特征的机器学习模型。例如,Song 等人[13]利用基于聚类的方法检测协同显著目标,这其中涉及的特征包括平均深度值、深度范围和方向梯度直方图。Cong等人[14]设计了一种迭代检测框架,该框架主要包含添加、删除和迭代方案。
上述方法主要利用传统图像处理算法和机器学习方法来获取RGBD图像间的共同显著区域。同时,随着深度学习技术的快速发展,深度学习技术也开始广泛应用于显著目标检测领域,检测性能得到极大地提升。但现有的基于深度学习的各种显著性检测模型主要针对单幅图像或者单个视频序列,针对多幅RGBD 图像的基于深度学习技术的协同显著目标检测模型尚未被提出。
为此,本文提出一种基于深度学习的RGBD 图像协同显著目标检测模型。该模型的输入为目标RGBD 图像和两幅协同图像(仅是RGB 图像)。模型充分提取与融合多幅图像之间的共有特征,以此凸显共同对象,由此得到目标图像的协同显著性图。特别地,与已有的基于深度学习的显著性检测模型不同,本文首先设计了“单体图像特征提取模块”,通过四条并行的单体图像特征编码器分支满足本任务中多模态信息输入的要求,以此充分挖掘单幅图像丰富的特征。此外,在已有的针对多模态任务的卷积神经网络结构设计中,如何选择特征融合策略是一个挑战性问题。为此,本文基于UNet网络[15]架构设计了以ConvGRU 单元为核心的多模态特征融合模块,对多模态深层语义信息进行了有效融合,极大地提高了协同显著性模型性能。
2 本文方法
如图1 所示,本文提出的RGBD 图像协同显著性模型由三个子模块组成,包括“单体图像特征提取模块”(图1中蓝色区域)、“多模态特征融合模块”(图1 中浅绿色区域)和“高-低特征集成模块”(图1中橘红色区域)。本文提出的卷积神经网络模型基于UNet 架构设计,以端到端的方式进行联合训练。首先,为了满足多模态信息输入的要求,并且为了有效地从输入图像(即图1 中的目标图像I、协同图像CI1、协同图像CI2和Depth 图像D)中提取单体特征,本文在广泛使用的VGG-16 网络结构[16]的基础上设计了单体图像特征提取模块,如图1所示,即具有相同网络结构的四个并行编码器分支。由此可以得到了四个编码器分支的初始特征映射,并将它们作为多模态特征融合模块的输入,进行多模态特征的融合。最后,模型采用高-低特征集成模块将编码器的原始特征传输到并行解码器的不同层级中,为解码器补充低层语义中有价值的信息。最终可以得到对应于目标图像的协同显著性图,如图1所示。
在下面的小节中,首先在第2.1 节介绍单体图像特征提取模块,接着在第2.2 节介绍多模态特征融合模块。最后,高-低特性集成模块的设计将在第2.3节中讨论。
2.1 单体图像特征提取模块
为满足多模态信息输入的任务要求,本文采用以下图像数据预处理方法:首先,由于不同数据集之间深度信息的存储差异性,将每个目标图像对应的Depth 图像像素标准化为[0,255],然后将每个单通道Depth 图像简单复制扩展为三个通道,以简化网络训练;其次,考虑到网络复杂度和硬件承载力,本文选择从同一类别中为每张目标图像I随机选择两张协同图像{CI1,CI2},并且穷举所有排列组合方式;最后,将目标图像及其对应的标准化的三通道Depth 图像和两幅协同图像组合成一个“RGBD 协同显著性检测序列”{I,CI1,CI2,D},作为模型的输入。
然后,为了有效地提取图像的深层特征,本文构建了单体图像特征提取模块,主要是图1 中蓝色区域所示的四个并行编码器分支部分,分别对应目标图像I、协同图像CI1、协同图像CI2和Depth图像D。这四个并行编码器采用相同的层级结构,并在对应目标图像I、协同图像CI1和协同图像CI2的三个编码器分支进行了参数共享[17]。具体地,受VGG-16 网络结构和其他改进的编码器结构的启发[18],本文将两个全连接层转换成1024 通道数的卷积层(fc6 层替换为3×3 的卷积层,并将膨胀率[19]设置为12,fc7 替换为1×1 的卷积层)。此外,将卷积块Conv5 的膨胀率改为2,并将卷积块Conv5 和全连接层间的池化层步长由2 调整为1。
其中,fi(⋅)表示第i个编码器分支,SFi表示第i个编码器分支输出的特征映射图,pI、pCI1、pCI2、pD分别表示目标图像编码器分支、两个协同图像编码器分支和Depth图像编码器分支的模型参数。
最后,单体图像特征提取模块输出32×32 的初始特征映射图序列{SF1,…,SF4}。
2.2 多模态特征融合模块
在单体图像特征提取模块之后,从四个编码器分支中得到了多模态特征。如何选择有效的融合方案来融合目标图像特征、协同图像特征和Depth图像特征是一个挑战。为此,本文设计了多模态特征融合模块,如图中绿色区域所示。对于每个编码器分支,添加一个卷积层将特征映射图压缩到512个通道,卷积层的数学表示如下:
其中,Conv(⋅)表示卷积层,卷积核为1×1,SF′i表示SFi经过卷积层后的特征映射图。
接着,本文在卷积层后应用改进的DenseASPP模块[20],从而更好地提取和整合单体图像的高级特征。在DenseASPP 模块中,有一个池化分支和三个卷积分支。其中,池化分支由一个平均池化层、一个1×1 卷积层和上采样层组成。在三个卷积分支中,卷积层通道数统一设置为176,卷积核的膨胀率分别设置为2、4 和8。最后,将输入特征图与四个分支的输出特征图在通道维度上进行级联(con⁃cat),并设置一个输出通道数为512 的卷积层进行压缩。四个分支的数学表示如下:
其中,AP(⋅)表示平均池化层,UP1(⋅)表示上采样层,Cat(⋅)表示级联,分别表示第i个编码器分支DenseASPP 模块中池化分支和三个卷积分支的输出特征映射图,DAi表示第i个编码器分支DenseASPP模块的最终输出特征映射图。
接下来,为了获取对应于目标图像的高层语义特征,即协同特征,本文以级联方式,采用3 个门控循环单元(ConvGRU)[21]来提取协同卷积特征。如图1 所示,本文共设置了三个ConvGRU 单元,分别对应于目标图像编码器分支和两个协同图像编码器分支。与卷积长短时存储器(ConvLSTM)[22]相比,ConvGRU 仅由一个复位门和一个更新门组成,在计算快速的同时可以获得相当的效果。具体来说,本文在所有ConvGRU 单元中都采用3×3 的卷积核。ConvGRU单元的数学表示如下:
其中,ConvGRU(⋅)表示ConvGRU 单元,CF1、CF2和CF3分别表示三个ConvGRU 单元输出的特征映射图。由此,三个并行RGB 图像分支的高层语义信息经过级联ConvGRU 模块之后,得到了32×32 的特征映射图,通道数为512。
最后,为了进一步充分融合由RGB 图像得到的协同特征和由Depth 图像得到的深度信息,本文引入Selective Self-Mutual Attention(S2MA)模块[12]来充分融合协同特征图与Depth 特征图。在这过程中,实现了目标图像的深度特征对协同特征的引导,为后续解码工作奠定了基础。
2.3 高-低特征集成模块
在解码器部分,本文构建了高-低特征集成模块,该模块采用残差连接的双解码器分支结构,包括作用于目标RGB 图像的解码器分支和作用于目标Depth 图像的解码器分支。在多模态特征融合模块之后,每个分支都设置一个卷积核为3×3、通道数为512 的卷积层。对于Depth 图像的解码分支,本文使用表示为“”的残差卷积块,其表达式如下:
其中,EFj表示Depth 图像解码器分支第j层级生成的特征映射图,IFj表示Depth 图像编码器分支输入到Depth 图像解码器分支第j层级的特征映射图,RFj表示Depth图像解码器分支第j层级传输到相应RGB图像解码器分支的特征映射图。
其中,HFj表示RGB图像解码器分支第j层级生成的初步特征映射图,PFj表示RGB 图像解码器分支第j层级生成的特征映射图,MFj表示RGB 图像编码器分支输入到RGB 图像解码器分支第j层级的特征映射图。
如图中黑色箭头所示,本文在每个解码器分支中构建了六个深度监督通道。如图1 所示,在不同解码器层级的特征映射(EFj或PFj)上,本文添加一个3×3 的卷积层和Sigmoid 激活函数来生成显著性映射图。然后,计算显著性图和真值图(Ground Truth,GT)之间的交叉熵损失值,以此进行网络的训练。本文模型在训练时的总损失由RGB 解码器分支和Depth 解码器分支不同层级的损失加权求和所得:
其中,LRGB和LDepth分别表示RGB解码器分支的总损失和Depth解码器分支的总损失,Lb表示{LRGB,LDepth}中的某一解码器分支,ln和αn分别表示Lb解码器分支第n层级的损失值和对应权值,N表示解码器总层级数(本文中N=6)。这里仿照已有工作[18],本文将各层级权值分别为0.5、0.5、0.5、0.8、0.8和1。
3 实验
3.1 数据集
本文提出的RGBD图像协同显著目标检测模型在两个基准数据集上进行了评估:1)RGBD Coseg183 数据集[23]和2)RGBD Cosal150 数据集[14]。其中,RGBD Coseg183 数据集包含183 幅图像,共有16个包含6到17张图像的图像组,同组图像拍摄于具有共同显著目标的室内场景中。RGBD Cosal150数据集是从RGBD 图像显著目标检测数据集RGBD NJU-1985 数据集中收集了21 个图像组,共包含150幅图像。两个数据集都提供了Depth 图像和像素级真值图。
3.2 评价指标
为了更好地评估模型的性能,本文使用了平均绝对误差MAE、F-measure、S-measure[24]和E-measure[25]四个计算机视觉任务常用评价指标。
平均绝对误差(MAE)通过显著性图S和真值图G之间的平均像素级差异计算可得:
其中,W和H分别是图像的宽度和高度。
F-measure是一种整体表现衡量,定义为准确率和召回率的加权平均值:
其中,P和R分别是准确率和召回率,β2设置为0.3以强调准确率[26]。
S-measure 指标可以评估显著性图和真值图G之间的结构相似性:
其中,Sr表示区域相似性,So表示对象相似性,并设置α为0.5[24]。
另外,本文使用E-measure 指标获取显著性图的全局统计信息和局部像素匹配信息:
其中,f(⋅)表示一个凸函数,∘表示哈达玛积。对齐矩阵ζ是在偏差矩阵φGT和φFM上构造的,φGT和φFM两个矩阵可以分别视为GT 和二值显著性映射上的中心操作。
3.3 实验设置
本文使用Pytorch 工具箱[27]实现了所提出的模型,其大小为493MB,并使用RTX 2080 Ti GPU 进行加速计算。对于每个数据集,本文随机划分一半的组别进行训练,另一半的组别用于测试,并在一个数据集上重复三次实验后算得平均值。在数据扩增环节,首先将目标图像、Depth 图像和协同图像都调整为288×288 像素尺寸,然后随机裁剪至256×256像素尺寸,并采用随机水平翻转,最后输入训练网络。此外,对于Depth 图像,像素值标准化至[0,255],并由单通道扩展到三通道。
为了便于网络训练,本文对每个解码器分支进行了深度监督,其中采用了3×3 卷积层和sigmoid 激活函数对不同层级解码器的特征映射生成显著性映射图。采用随机梯度下降算法(SGD)对网络模型进行优化,共迭代50万次。对应的参数如权重衰减参数(weight decay)、动量参数(momentum)和批参数(batchsize)分别设置为0.0005、0.9 和4。初始学习率和衰减系数分别设置为0.01 和0.1,并分别在第10万次和第25万次迭代时衰减学习率。
3.4 指标对比
为了评估本文提出的协同显著目标检测模型的性能,本文同最近发表的其他6 种模型进行了定量和定性比较,包括BSCA[28]、DCLC[29]、RC[30]、RRWR[31]、ICF[14]、HSCS[32]。最后两种方法是目前最先进的RGBD协同显著性模型。
表1 中给出了两个公共数据集上不同RGBD 协同显著目标检测模型在MAE、S-measure、F-measure和E-measure 方面的指标比较结果。这里,本文用红色、绿色和蓝色依次标记排名前三的模型。↑与↓分别表示数值越高性能越好和数值越低性能越好。可以看到,同其他模型相比,本文模型在RGBD Coseg183 和RGBD Cosal150 两个数据集上于所有指标上都取得了最好的性能。如图2 所示,RGBD Cosal150 数据集包含“卡通人物”、“雕塑”和“人物”等图像分组。在“卡通人物”和“雕塑”图像组中,其他模型如ICF只是定位了部分目标区域,而本文模型可以更精确地抑制背景区域并完整地凸显协同显著目标;在“人物”图像组中,本模型可以比其他模型更好地凸显协同显著对象。如图3 所示,RGBD Coseg183数据集包含“白帽子”、“雕像”和“白碗”等图像分组。在“雕像”图像组中,协同显著目标与背景色彩相似度较高,其他模型如RRWR 无法有效地抑制背景区域,但本文模型可以充分利用Depth 信息进行更准确地凸显;在“白帽子”、和“白碗”图像组中,存在多个显著目标的情况,其他模型如HSCS 会错误地凸显非协同显著目标,而本文模型可以更有效地利用协同图像间的相关性找出协同显著目标。
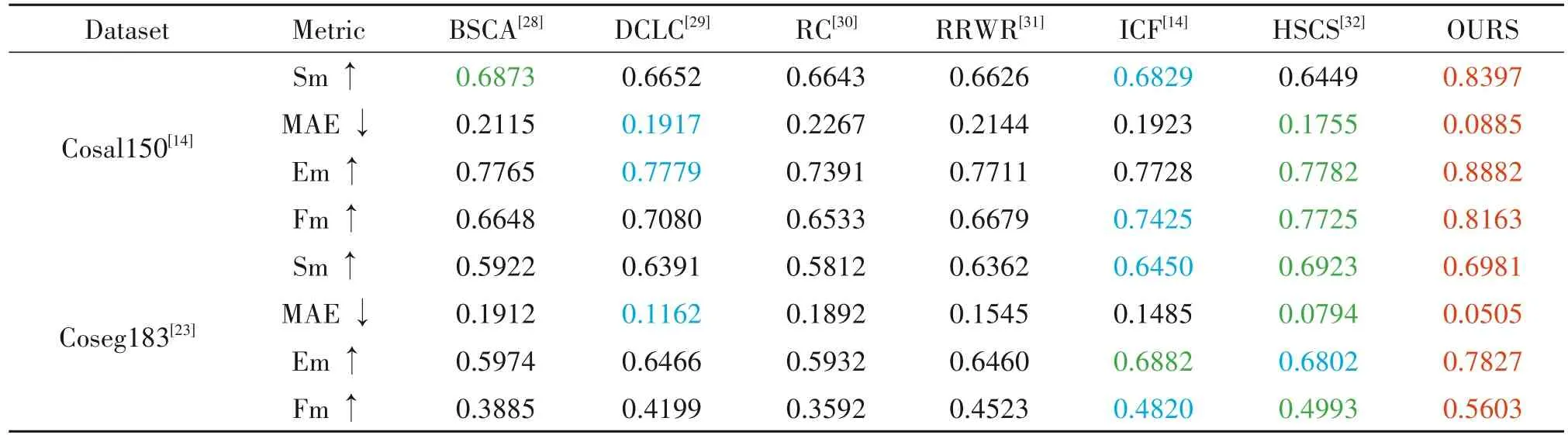
表1 两个公共数据集上不同RGBD协同显著目标检测模型的定量比较实验结果Tab.1 Quantitative comparison of experimental results of different RGBD co-saliency object detection models on two public datasets
3.5 消融实验
为了验证本文所提模型各组件的有效性与合理性,这里对所提出的模型进行了相应的变化,以此来进行对应的消融实验。
1)验证“单体图像特征提取模块”中协同图像编码器分支的有效性。这里,本文舍弃了模型中两个协同图像输入分支,仅保留目标图像分支和Depth 图像分支,在表2 中的“无协同图像编码器分支”列中记录实验的结果。结果表明,单体图像特征提取模块中引入的协同图像编码器分支能够有效提升模型性能,这也证明了单体图像特征提取模块的有效性。
2)验证“多模态特征融合模块”中级联Con⁃vGRU 模块的有效性。这里,为了说明使用Con⁃vGRU 部分可以更有效地集成高层协作信息,本文将其替换为卷积核1×1 的卷积层,并在表2 中的“无ConvGRU 模块”列中记录实验的结果。可以看出,本文所提模型依旧取得最好性能。由此可以证明多模态特征融合模块的有效性。

表2 在RGBD Cosal150数据集上进行消融实验,每行中的最佳结果都用粗体标记Tab.2 Ablation studies are performed on RGBD Cosal150 dataset,and the best result in each row is marked in bold face
此外,图4给出了对应的定性主观评测实验,第3列“ab1”表示无协同图像编码器分支的实验结果,第4列“ab2”表示无ConvGRU 模块的实验结果。以RGBD Cosal150 数据集“鸟类”图像组为例,没有协同图像编码器分支的模型无法有效地抑制背景区域,没有级联ConvGRU 模块无法准确凸显协同显著目标。由此可以看出协同特征提取编码器分支和级联ConvGRU 特征融合的共同作用可以使本文所提模型更有效地实现RGBD图像协同显著目标的准确预测。
4 结论
本文提出了一种基于深度神经网络的RGBD图像协同显著目标检测模型。具体地,本方法首先构建了并行的编码器结构,有效地获取了RGBD 图像的高效表征;接着,使用多模态特征融合模块充分融合来自编码器的深层特征,得到了对应目标图像的协同特征;最后,通过包含残差连接、深度监督的解码器模块进行预测,充分融合目标图像自身的表观和深度信息,由此得到高质量的协同显著性图。在两个公开数据集上的测试结果表明,所提模型在所有评测指标上均优于目前6 种较先进的模型,这也证明了本文模型的有效性和优越性。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
黑龙江大学自然科学学报(2022年1期)2022-03-29
小学生必读(低年级版)(2021年10期)2022-01-18
计算机系统应用(2021年10期)2022-01-06
锻压装备与制造技术(2021年5期)2021-11-13
科学技术创新(2021年5期)2021-03-17
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
——编码器
演艺科技(2020年7期)2020-08-13
家庭影院技术(2019年8期)2019-12-04
