
基于车辆尾部特征的前车识别算法
2022-07-22 14:08杨传江曹景胜袁增千范博文
重庆理工大学学报(自然科学) 2022年6期
杨传江,曹景胜,袁增千,范博文
(辽宁工业大学 汽车与交通工程学院, 辽宁 锦州 121001)
0 引言
近年来,迅猛发展的汽车工业给人们生活增添了诸多便捷,但随之而来的道路交通问题也日渐凸显,传统机动车行驶过程中出现超速、酒驾等问题屡见不鲜,给人们出行安全带来巨大隐患[1-3]。随着人工智能领域的快速发展,解决汽车驾驶主动安全问题、有效减少交通事故的无人驾驶和智能网联汽车成为了该领域内最有可能落地化和产业化的分支。在智能网联汽车众多关键技术中,道路前方车辆识别与跟踪技术是其中研究热点之一[4-6]。传统的车辆检测和识别方法主要有:基于毫米波雷达、超声波雷达的声波测距技术;基于车载激光雷达扫描的光传感定位技术;将雷达数据融合进行环境感知和精确测距的方法等,但是激光雷达成本极高,实际应用困难;毫米波雷达对行人识别率低,并且开发周期长;超声波雷达作用范围有限,易受外界环境影响。
随着图像识别算法的深入发展和计算机数据处理速度提高,机器视觉开始在车辆检测和识别方面表现出优势。随着硬件水平的提高和计算机算力的支持,越来越多的人探讨深度学习算法的应用,主要包括一阶段的YOLO系列和SSD算法,以及两阶段的R-CNN算法,程泊静等[7]使用单目摄像头基于YOLOv3实现前车实时检测跟踪。但是,深度学习算法需要极高的硬件成本和大量数据集进行训练,对于部分研究者来说较为困难,因此,基于特征提取的统计学习方法依然有其优势。曹景胜等[8]对类Haar特征提取并基于AdaBoost算法进行训练和级联,满足多场景、多工况下的前车识别;徐鹏等[9]基于支持向量机(SVM)进行样本分类,实现低能见度下车辆样本分类。
正常行驶在道路上的汽车,其尾部与周围环境相比,具有明显的视觉形态,因此本文使用局部二值模式(local binary pattern,LBP)特征提取方法,改进算子提取方式,对提取到的特征值化、区域分块、排序处理,然后结合支持向量机(support vector machine,SVM)分类方法,实现对前方车辆的识别与跟踪。
1 前车识别总体研究
在汽车上安装摄像头,用以替代驾驶员的视觉效果,是较早提出的一种驾驶辅助方案[10-12]。计算机视觉技术利用视频采集设备(如CMOS或CDD摄像机)代替人的眼睛,将获取到的信息传递给计算机,计算机代替人的大脑对“看到”的图像进行分析处理,然后做出相应的反应。将计算机视觉技术应用到汽车安全系统中,能够大大提高行驶的安全性[13-15]。
本文研究LBP特征提取算法应用于前车识别,进行图像局部特征提取。LBP算法在人脸识别中应用广泛、识别率高、成熟可靠。而一般汽车尾部设计与人脸类似,尾灯想象为人的眼睛,车牌类似于人的鼻子,后保险杠凹凸不平,看作人的嘴。因此采用LBP算法来识别前方车辆的车尾[16]。主要步骤为:
1) 由车载图像获取设备(摄像头)进行前方道路车辆图像采集,将原始图像预处理后,提取图像上划分点的LBP特征值,将特征值统计为直方图,进而归一化为特征向量;
2) 将正负汽车样本,经过以上步骤转化,对SVM分类器进行训练,将步骤1)中的结果导入训练后的分类器,从而识别出前方车辆。前车识别原理如图1所示。
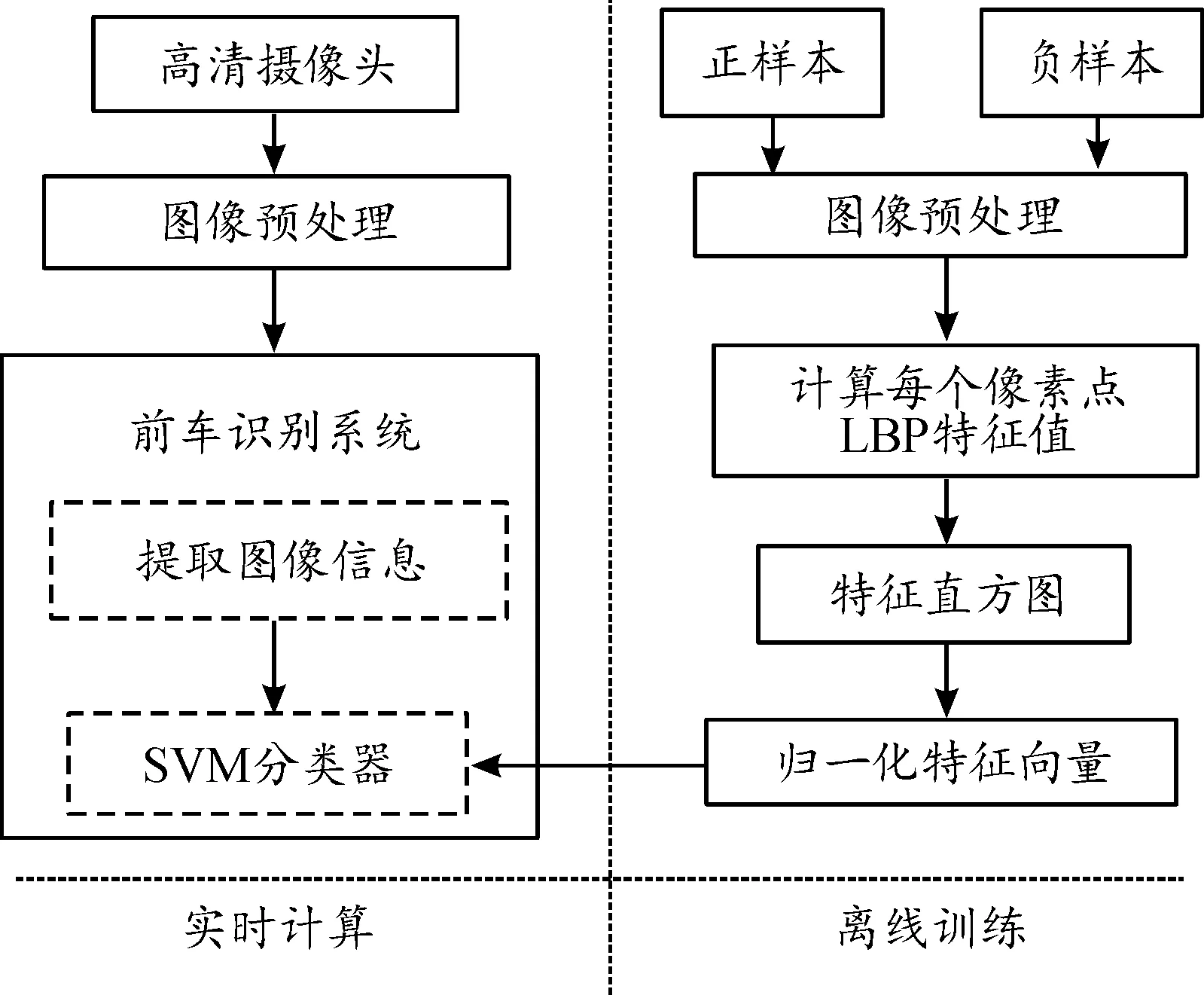
图1 前车识别原理框图
2 LBP特征提取
2.1 图像预处理
一般拍摄设备获取图像时,周围环境因素会对其产生影响,尤其是多云、傍晚、雨雪天气等光照变化剧烈的情况。为了提高特征提取准确率,降低光照影响,将图像感光区域进行修正(归一化处理),为:
(1)
式中:IMGn(i,j)为图像经过修正后的(i,j)处的像素值;IMG(i,j)为录入图像在(i,j)处的像素值;Vave为图片区域内像素的平均值;M为像素点数目;xk为图片区域内第k个点的像素值。
特征提取是基于灰度化的图像,将彩色图像进行灰度化处理,基于了红、绿、蓝三原色的加权平均值法,为:
Gray=R×0.299+G×0.587+B×0.144
(2)
这种方法处理后的图像能基本体现原图像特征,更符合人眼成像。
2.2 LBP特征原理
LBP算子在描述图像局部特征方面的主要优点是:受光照影响较小,具有非0即1的局部二值特征,关于灰度变化鲁棒性好;图像信息旋转不变特性,提取图像特征更充分,在描述局部纹理特征方面更为准确。另外,LBP特征为整数特征,计算简单,图像分析速度快。随着技术的进步,原始LBP算子不断被改进,以应用于各种干扰强和情况复杂场景。白灵鸽等[17]介绍了原始LBP算法改进为圆形模式、旋转不变模式过程,李旭辉[18]应用等价模式方法减少运算数据,宋艳萍等[19]应用MB-LBP算法提高特征提取的准确率。本文详细介绍了LBP算法的改进历程,并在最终选择等价模式方法和MB-LBP算法相结合的特征提取方式,提高识别的速度和稳定性。
2.2.1原始LBP算子及公式
原始LBP算子首先选定一个3×3的邻域,计算中心点和周围8个点的灰度值,邻域点分别与中心点比较,若邻域点大记为1;若中心点大,则邻域点记为0。这样周围像素点的值会产生一组8位二进制数,利用这组数表示中心点的像素。这8位数按照一定顺序排列,共有256种可能。图2是一种示例。

图2 原始LBP算子示例
其推导公式为:
(3)
式中:(xc,yc)表示中心像素点位置;p是第p个点的像素;ic是区域中心点(xc,yc)的灰度值;ip为邻域点按一定顺序排列的第p个点的灰度值;s(x)是记录比较结果的符号函数。
2.2.2圆形LBP算子
原始的LBP算子只是获取周围邻域内的像素值,尺寸范围较小,频率也无法满足。随后有学者提出圆形LBP算子,这种算子可以将3×3邻域扩展,不再局限于正方形区域,纹理特征适应性增强,并且带来旋转不变特性。圆形LBP算子半径为R,在以半径画圆的邻域上取N个点,同样判断大小,取值为0或1,采样点数量可变。原理如图3所示。
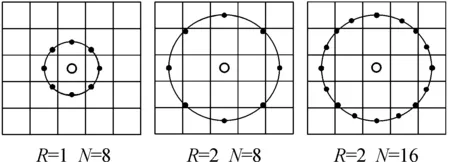
图3 圆形LBP算子示例
给定中心点(xc,yc),可以确定周围邻域内的采样点位置分别为p(xp,yp),计算方法如下:
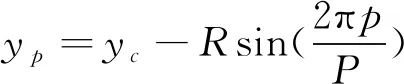
(4)
式中:R表示采样取值的半径范围;p表示采样点所在位置,表示第p个采样点;P表示采样点总的个数。但计算结果不一定为整数,因此选取双线性插值方法,计算公式为:
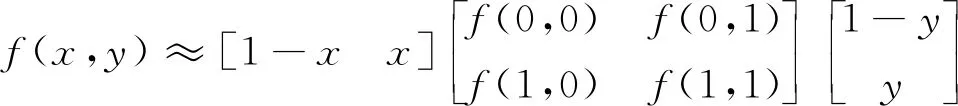
(5)
通过式(3)和式(4)获得采样点坐标,就可以找到该点灰度值,然后代入到式(2),求得基于圆形LBP特征的值。
2.2.3旋转不变LBP特征
原始LBP算子转换为圆形LBP算子后,灰度依然不变,计算精度大大增加,但当旋转图像后,LBP值跟着发生变化,为了避免重复,规定选取所有值中的最小数作为中心点的LBP值,如图4所示。
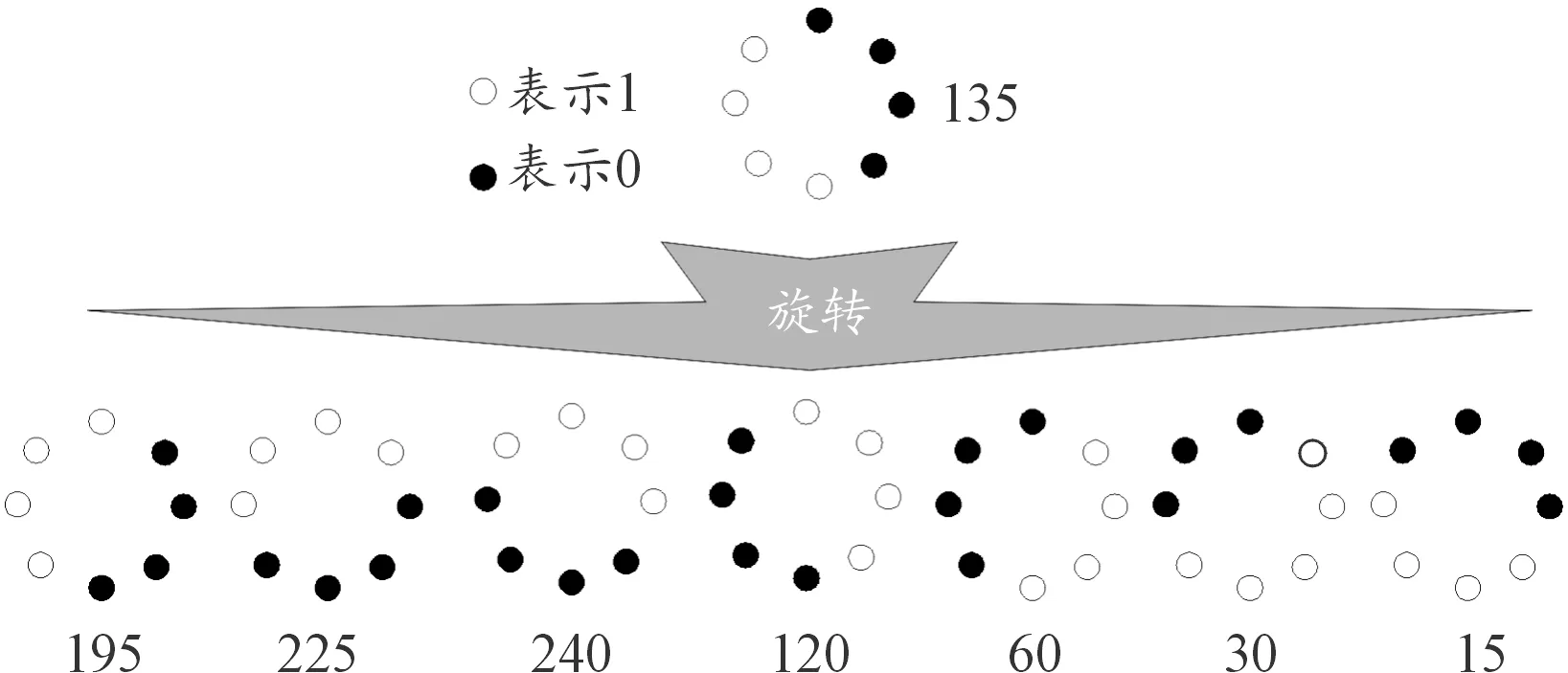
图4 旋转不变LBP算子示例
2.2.4等价模式LBP特征
圆形LBP特征计算像素点值具有随着采样点数目增加,LBP算子模式指数级增加的缺点。将其应用于纹理特征提取、识别、分类时,大量数据不利于运行处理,想到对LBP模式的一种降维方法。
Ojala提出一种“等价模式(Uniform Pattern)”对二进制数组进行处理。规定二进制数组中由0到1或者由1到0视为一次跳变,当LBP特征数组有少于等于2次跳变时,称这种数组为等价模式类。选取具有等价特征的LBP值作为计算值,总数就会减少为P(P-1)+2种,大大降低运算数据量,并且图像信息不会丢失,可以保证识别的准确率。
2.2.5MB-LBP特征
一般情况下,基于等价模式LBP特征可以很好地实现对特征的提取,但对于准确率的更高追求使中国中科院学者提出更进一步的方法——MB-LBP,全称为Multiscale Block LBP。原理如图5所示。
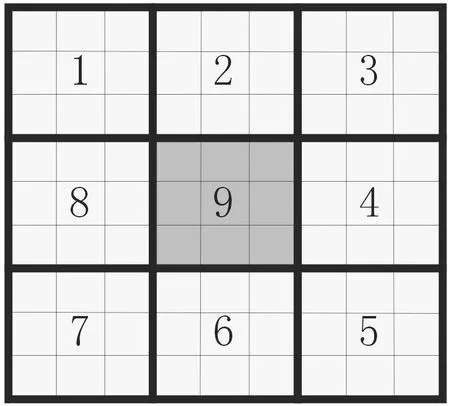
图5 MB-LBP算子示例
类似于HOG特征算法中cell的划分方式,先将正方形大区域划分为9个小区域,每个小区域中划分3×3的区块,取9个小区块的平均灰度值作为一个小区域的灰度值,在整个大区域内使用等价模式LBP算法,就可以提取大区域中心点(小区域9号)的特征值。使用这种方法,在小区域内求平均值而不是直接计算LBP特征灰度值,可以大大减少运算时间。
在原始LBP特征提取的基础上,使用MB-LBP方法原理提取到图像特征灰度值,按照等价模式原理最终获取中心点的特征值,这种方法使得特征提取更加准确、清晰。原图和特征提取如图6和图7所示。

图6 拍摄原图
图7 特征提取结果示例
图片处理及特征提取步骤如下:
1) 输入256×256维像素的图像,进行灰度化处理,然后搜索图中每个像素点,得到对应像素点的灰度值;
2) 使用MB-LBP方法和等价模式原理提取每个区域中心点的特征值;
3) 将LBP特征图像划分为8×8共64区域,分别统计每个区域的特征直方图;
4) 将特征直方图归一化,按照上一步分块直方图各自的空间顺序依次排列特征值,组合为整张图片的LBP特征值图谱;
5) 最后,就可以将得到的特征图谱导入SVM分类器进行训练或识别了。
3 SVM分类原理
支持向量机(SVM)[20]是利用监督学习方式,通过计算将数据按特征分为2种类型,是定义在空间上的一种间隔最大特征分类器,是统计学习理论的延伸应用。当给定一个训练样本集:
D={(x1,y1),(x2,y2),…,(xm,ym)},
yi∈{-1,+1}
SVM分类学习的思想是用超平面将样本空间划分,使得样本尽可能被区分开。可以找到许多符合要求的超平面(如图8),但红线距离两侧数据间隔最大,可以尽量避免样本训练集数据的噪声,同时对样本局限性抗干扰能力较强,所以中间那一条红线抗“扰动”性最好。
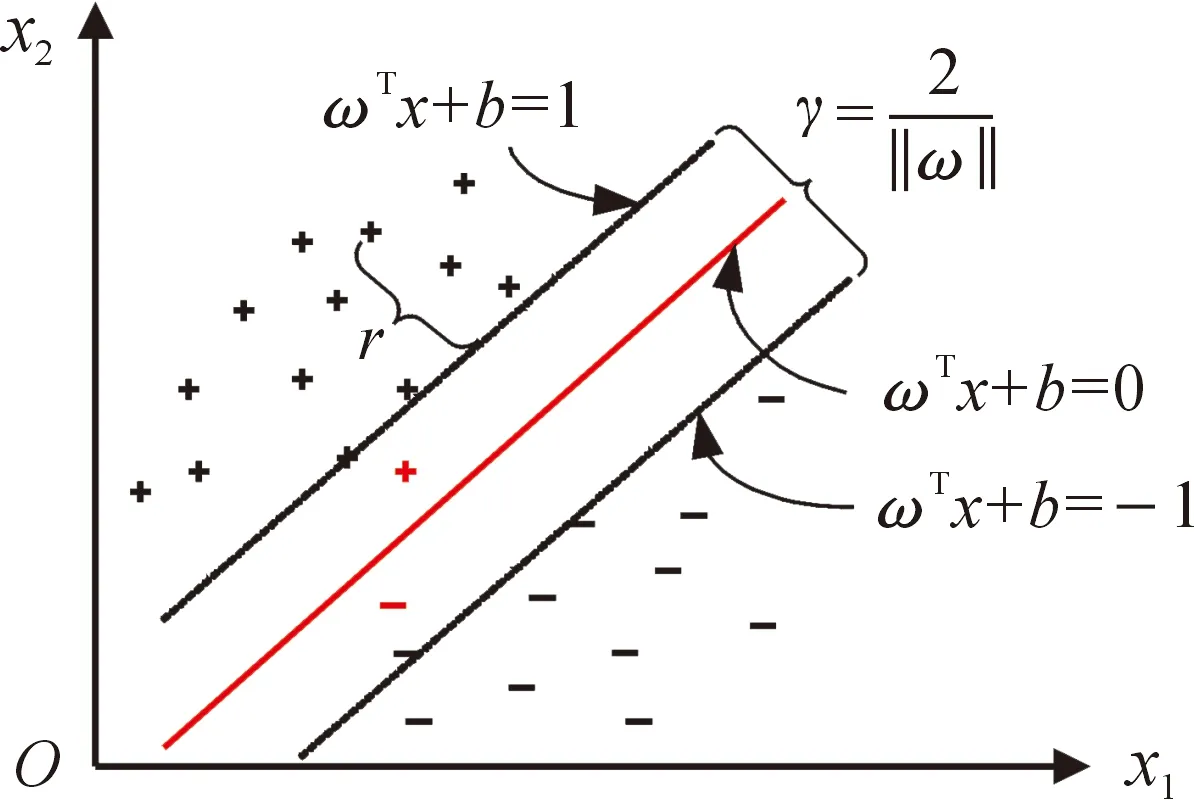
图8 SVM分类原理示意图
将正负样本导入SVM分类器中,分类器会自动识别并且找到一个超平面,使得抗扰动性最好,这决定了识别的成功率。在样本空间中,如下线性方程是划分超平面最好的分界:
ωTx+b=f(x)
(6)
式中:ω=(ω1,ω2,…,ωd)为法向量;b为位移。
由式(6)可得样本所在空间中,任何一点x到超平面(ω,b)的间距为:
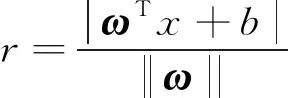
(7)
假设分类器能够正确分类样本,则:
(8)
使式(8)等号成立的采样点称为“支持向量”,若2个采样点分属超平面两侧,被称为“异类支持向量”,2个异类支持向量到超平面距离之和为:
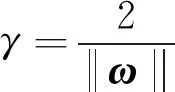
(9)
称为间隔。
找到“最大的间隔”,即式(9)中γ最大值,就能够精确分类,即:
(10)
s.t.yi(ωTxi+b)≥1,i=1,2,…,m表示最大间隔之外的部分。
显然,当间隔最大时||ω||最小,式(10)可以写为:
(11)
这就是支持向量机的基本型。
目标函数的约束条件是不等式,在数学角度变为求解二次规划问题,选用KKT(karush-kuhn-tucker)条件得到原来问题的对偶问题。
将拉格朗日乘子αi≥0加入到每个约束条件中,即得到:
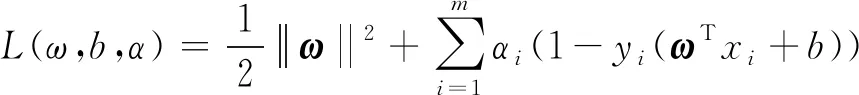
(12)
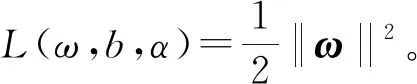
最终目标函数表示为:
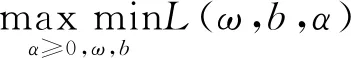
(13)
对式(13)中ω,b求最小值,在对α求最大值,就能求得SVM的最优超平面。
本文中SVM分类器的主要作用是训练汽车图片正负样本,因此其准确率与样本集中的支持向量有关,差异越大,最优超平面的分类越准确。
4 实车测试和对比分析
对研究的内容进行测试和分析,选用的硬件平台为CPU:Intel CORE i7-4790K处理器,内存:16G;软件平台为:在Ubuntu 14.04 操作系统之上运行QT5.5和OpenCV 3.1版本的计算机视觉和机器学习软件库。在训练分类器时,选用5 358张不同种类和外形的汽车后视图片,作为正样本输入;同时选用5 260张非汽车图片,作为负样本输入。
4.1 不同窗口大小下的识别率测试
针对样本集,输入256×256维像素的图像,然后用原始LBP算子、MB-LBP和等价模式算子分别提取特征,并对整张图像进行分块处理,采取3种方案:即划分成32×32的区域,得到8×8像素的样本窗口;划分为16×16的区域,得到16×16像素的样本窗口;划分为8×8的区域,得到32×32像素的样本窗口,然后分别选用8×8、16×16、32×32等不同的样本窗口大小进行测试,测试结果如表1所示。
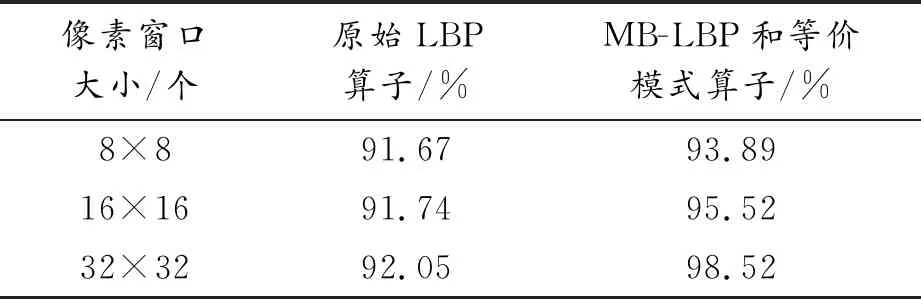
表1 不同样本窗口大小下识别率
通过测试可以分析出,本实验输入原始256×256维像素的图像,选用窗口大小为32×32像素,并且使用MB-LBP和等价模式算子提取特征,得到的识别效果最好。
4.2 实车测试
基于在京沈高速录取的实时行车视频,截取车速为70、90、110 km/h时的原始图像,进行算法测试,得到的结果如图9—11所示。

图9 70 km/h工况下的前车识别图像

图10 90 km/h工况下的前车识别图像

图11 110 km/h工况下的前车识别图像
图9—11为截取的不同车速下前车识别图像,分析实验结果,得知:在右侧车道行驶时,由于车速最低、图像清晰、与前车距离近,因此识别效率高、识别时间短;在中间车道较高速行驶时,识别时间增加,距离较远的车辆图像模糊无法识别;在左侧车道最高速行驶时,识别时间最长,甚至出现识别遗漏现象。
针对上述表现,统计了不同车速下的识别的平均准确率,即:某一大致车速下,前车图像正确识别的帧数之和与整段视频总帧数的比。不同车速下平均准确率如表2所示。

表2 不同车速下平均准确率
通过对比不同车速下算法识别的准确率和识别时间,其结果与理论预测相符合,在不同车速工况下,均可以实现较好的检测结果。
4.3 对比分析
前车识别方法种类繁多,一般情况下,YOLO系列算法识别速度快,传统特征提取算法准确率高。将本文方法与YOLOv3方法(利用开源代码,自己训练,得到检测识别结果)、类Haar特征+Adaboost[8]方法识别结果进行对比,对比参数主要包括2个方面:每秒帧数(frames per second, FPS)表示计算机每秒处理图像的帧数;平均精度(average precision,AP)表示根据不同车速,以10 km/h为一个区间,分别计算汽车在60~120 km/h车速内,每个区间的图像识别的平均准确率,然后所有区间内的平均准确率加和求均值,称为平均精度。不同检测方法识别结果如表3所示。
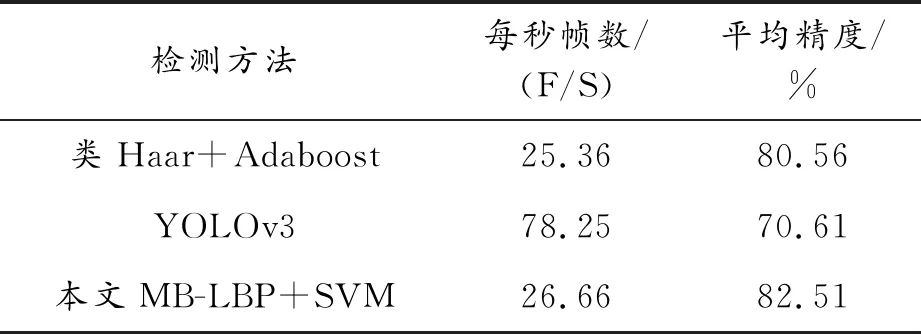
表3 不同检测方法识别结果
通过对比可以看到,YOLOv3算法识别图像用时短,可以实现实时识别,但识别率不高,本文研究的方法每秒运行帧数未达到实时识别标准,但平均精度和效率,较类Haar特征+Adaboost算法都有所提高,基本满足不同速度下的前车识别。
5 结论
汽车智能化是科技进步的高端产物,前车识别技术则是智能汽车实现自动行走的眼睛。当前前车识别主要依赖于机器视觉算法,而基于神经网络的深度学习目标检测方法引起热潮,其检测的速度和精度是建立于大量目标数据集和较高硬件配置的基础之上,应用相对困难,而基于特征的统计分类方法,对软硬件要求低,且能够达到实时检测的目的,实用性强。另外,本文使用的LBP算法对光照有很强的鲁棒性,因此只考虑了不同车速情况的平均识别精度,没有考虑天气、光照的影响。实验测试结果表明,本文提出的方法满足前车识别的基本需求。另外,进一步研究晴天、多云、雨雪、深夜路灯等不同光照环境下的识别结果具有广阔应用前景。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
包装工程(2022年9期)2022-05-13
电子产品世界(2022年4期)2022-04-21
集装箱化(2021年1期)2021-04-12
计算机系统应用(2021年2期)2021-02-23
校园英语·上旬(2020年1期)2020-05-09
中国信息技术教育(2020年2期)2020-02-02
卷宗(2017年16期)2017-08-30
软件导刊(2017年4期)2017-06-20
国外科技新书评介(2014年12期)2015-01-05
