
基于目标感知增强的无人机航拍目标检测
2022-07-21 04:12:18王鼎山贾世杰
计算机工程与设计 2022年7期
王鼎山,贾世杰
(大连交通大学 电气信息工程学院,辽宁 大连 116028)
0 引 言
智能无人机近几年在能源巡检[1]、海上救援[2]、交通监管[3]等领域内获得了越来越广泛的应用,而目标检测是实现无人机智能感知的关键技术之一,凭借着深度学习的优势,当前目标检测发展日渐成熟,并建立了以Faster R-CNN[4]、R-FCN[5]、Cascade R-CNN[6]等为代表算法的两阶段检测框架和以SSD[7,8]系列、YOLO[9-12]系列、RetinaNet[13]等算法为主的单阶段检测框架,在常规图像数据集上,此类检测算法取得了巨大的成功。然而,在航拍图像中由于目标物体尺寸偏小、特征不明显和分布不均匀的特性,使得这些通用目标检测器无法充分发挥其潜能,导致航拍图像中的目标检测效果并不理想。
为了使目标检测在无人机航拍图像处理中获得良好的性能,众多研究者提出了不同的方法和策略来弥补检测器的不足。Liang X等[14]提出的FS-SSD改进算法,从多类目标之间的相互作用考虑来进行空间上下文分析,充分利用了目标特征的邻域信息,弥补了SSD在小目标检测上存在的不足,但该方法依赖于相关权衡参数和距离阈值的设置,不利于模型的自适应学习。高杨等[15]运用多层特征融合的方式对Faster R-CNN进行了改进,提升了小目标的检测精度,但是各层特征的融合并不总是有效,有时一些背景噪声的干扰会影响特征图的激活。Zhang X等[16]基于Cascade R-CNN级联检测的思想,提出一种多模型融合的航拍目标检测器DSOD,有效提升了密集小目标的检测性能。
上述检测算法从不同的角度考虑,给出了针对航拍图像目标检测效果不佳的相应解决方案,但是很少通过优化预测阶段的特征来进一步提高检测器的性能。在特征预测阶段,检测头部作为最终结果的输出端,尤其对小目标特征的推理预测影响着整体模型的鲁棒性。因此,本文以YOLOv4为基线模型提出了一种具有目标感知增强的航拍检测算法。其中,YOLOv4对网络的梯度信息和目标定位信息进行了优化,并探究了与多种实用检测策略的最优组合,有效地实现了检测器速度与精度之间的最佳平衡。鉴于此,本文首先对其主干网络引入了注意力机制,以在基础特征之上构建更有效的特征分量,从而提升目标在各层级的表征效果。其次借助上下文信息的优势,将特征金字塔结构中的多尺度信息进行上下文汇总和筛选,从而细化中间特征。最后在特征预测阶段,通过复用原始检测信息和跨阶段聚合主干网络特征,重构了检测头子网络,以增强模型对目标的定位感知能力。最终在相应数据集上的评估,验证了本文所提方法在无人机航拍目标检测任务上的有效性。
1 网络结构与算法原理
如图1所示为网络模型的框架,主要包括3部分,第一部分为BCA-CSPDarknet53特征提取网络,是在主干网络的各中间层融合瓶颈连接注意力(bottleneck connection attention,BCA)来引导其特征输出,以有效和自适应地处理每个阶段之间特征区域的变化,形成分层映射的表征空间。第二部分是上下文细化模块(context refinement module,CRM),通过聚合上下文信息并对其筛选细化,以充分利用有效的目标上下文来提高检测小目标的性能。第三部分是针对预测端的目标感知增强检测头(object-aware enhancement head,OAE-Head),这一改进旨在突出主动响应目标位置特征,同时抑制背景信息。
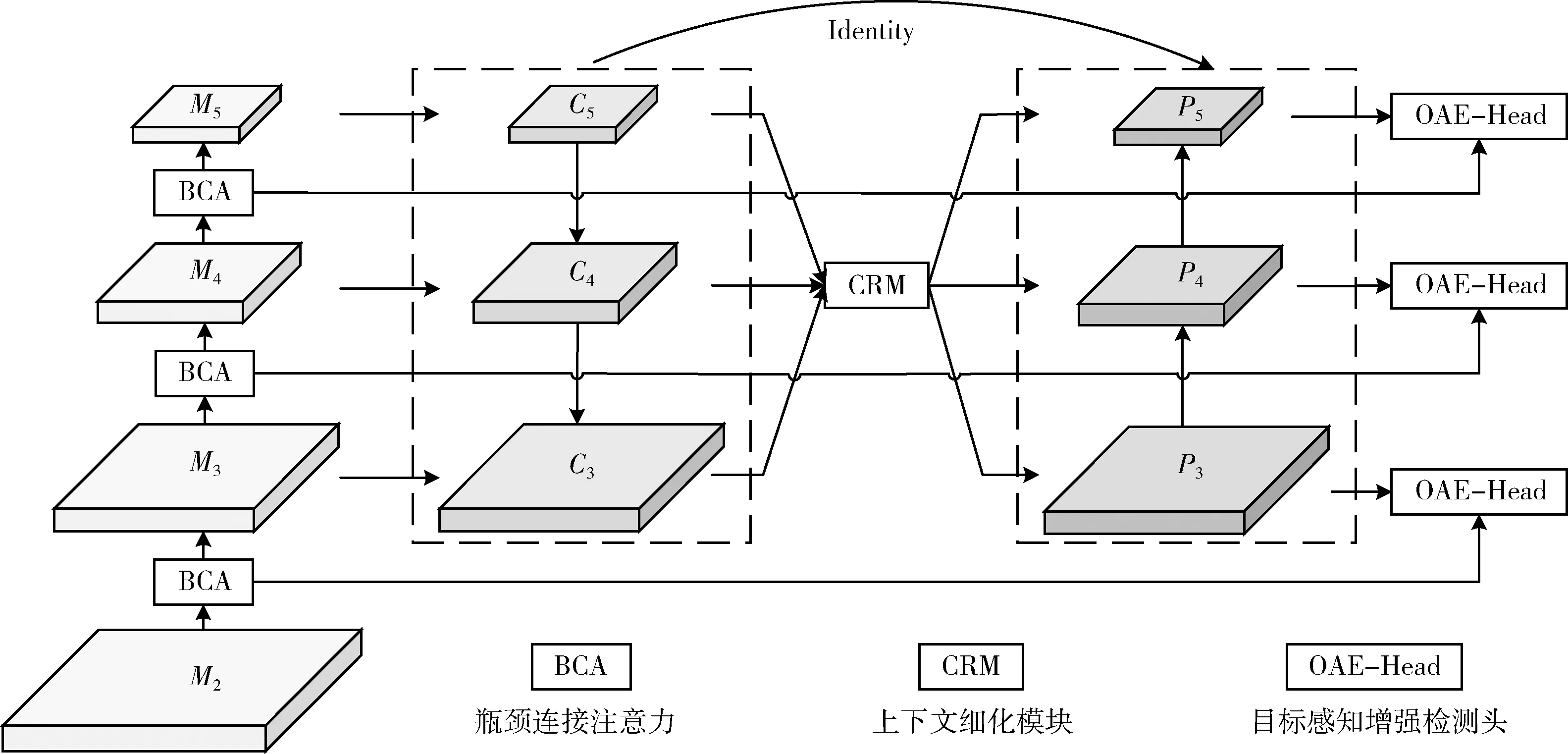
图1 网络模型框架
1.1 BCA-CSPDarknet53特征提取网络
BCA-CSPDarknet特征提取网络的组成如图2所示。本文在YOLOv4主干网络中的每个CSPDarknet结构层添加了BCA模块(如图2右侧所示),该模块的设计结合了ECA[17]网络,本文进而对该注意力网络进行了级联交互,以实现对中间特征的深度注意力编码,通过短连接的方式来增强注意力特征之间的信息流通,充分利用注意力机制的优势。
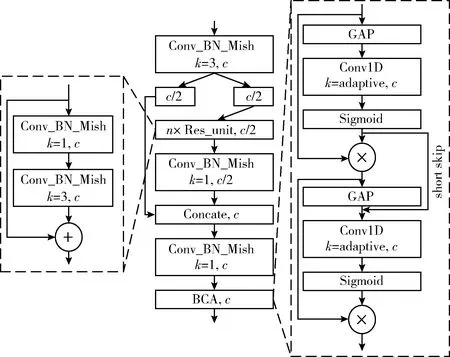
图2 BCA-CSPDarknet结构
具体来说,假设输入张量为X∈C×H×W, 经逐通道全局平均池化(global average pooling,GAP)操作可表示为
(1)
式中:H,W分别为特征图X的高和宽,G表示1×1×C的全局信息表征图。然后,采用一维卷积对G进行自适应通道映射变换,捕获跨通道信息交互的相关性,以确定每个通道特征图的权重,该操作可描述
V=σ(Fk(G))
(2)
式中: Fk(·) 表示卷积核大小k的一维卷积操作,σ为Sigmoid函数,V是生成的各通道权重激活值,其中k的取值由输入特征图的通道数自适应确定。公式如下
(3)
式中:γ和b是超参数,默认取值为2和1, |·|odd表示取最邻近的奇数值。在得到各通道的权重分布后,与原始输入特征进行信息交互,即
X′=V⊗X
(4)
式中:X′为第一注意力图,⊗表示元素对应相乘。
在short skip的前馈过程中,将之前的注意力权重V和后一模块中的全局信息表征G′合并,再经过一维卷积进行特征变换和激活映射,确保从先前的注意力信息中继续学习,避免其特征在每一步学习中产生较大的变化。随后,与第一注意力图相乘融合。此过程可表示为
X″=σ(Fk(V⊕G′))⊗X′
(5)
式中:X″为第二注意力图,⊕表示元素对应相加。
最终堆叠BCA-CSPDarknet作为特征提取网络,对每个阶段目标信息的选择和表征过程进行分层注意力映射,形成不同感知层次上相对准确且有效的视觉空间表征,以挖掘不同大小目标最有用的信息。
1.2 上下文细化模块
CRM由信息聚合块(information aggregation block,IAB)和信息校准块(information calibration block,ICB)组成,如图3所示。

图3 CRM结构
许多研究结果表明上下文信息对小目的推理识别具有积极作用,故IAB将不同尺度下隐含语义信息的特征图,映射到共同的抽象空间进行合并,得到局部和全局上下文信息。将C3和C5特征图分别进行平均池化下采样和插值上采样操作,使其与C4特征图的尺度大小和空间维数相等,之后对统一映射的特征图进行简单的平均,即
(6)
式中:Ci表示第i层特征,L表示多尺度特征层数,fFA为聚合后的输出特征。
由于上下文信息并不总是对网络模型有用,需要对其进行筛选才能有效地利用[18]。因此,ICB负责对上下文信息进行细化处理,它能够为每个空间位置的邻域信息建立空间和通道间依赖关系,避免上下文当中无效信息的干扰,从而生成更具鉴别性的特征。该结构有两个并行分支,其中一支路径保留原始空间信息,另一支用于压缩全局信息以形成潜在的低维空间,其过程可描述为
(7)
式中: F1(·) 表示在原始尺度空间下对特征的卷积操作,所对应特征映射与输入共享相同的分辨率; D(·) 为平均池化操作,对fFA进行低维空间映射, F2(·) 为小尺度空间下的卷积操作,进而通过双线性插值上采样U(·) 将低维表征映射至原始特征空间。
最后以f2作为参考特征信息,来指导原始特征空间内的特征变换过程,即
fSC=F3(f2⊗f1)+(f2⊗f1)
(8)
式中: F3(·) 为过渡卷积操作,fSC为生成的校准特征。
1.3 目标感知增强模块
航拍目标检测中,小目标的感知识别往往很容易受到复杂背景的影响,而用于预测阶段的特征图可能仍存在背景干扰信息,而导致最终检测结果是次优的。为此,本文设计了OAE-Head检测头子网路,如图4所示。
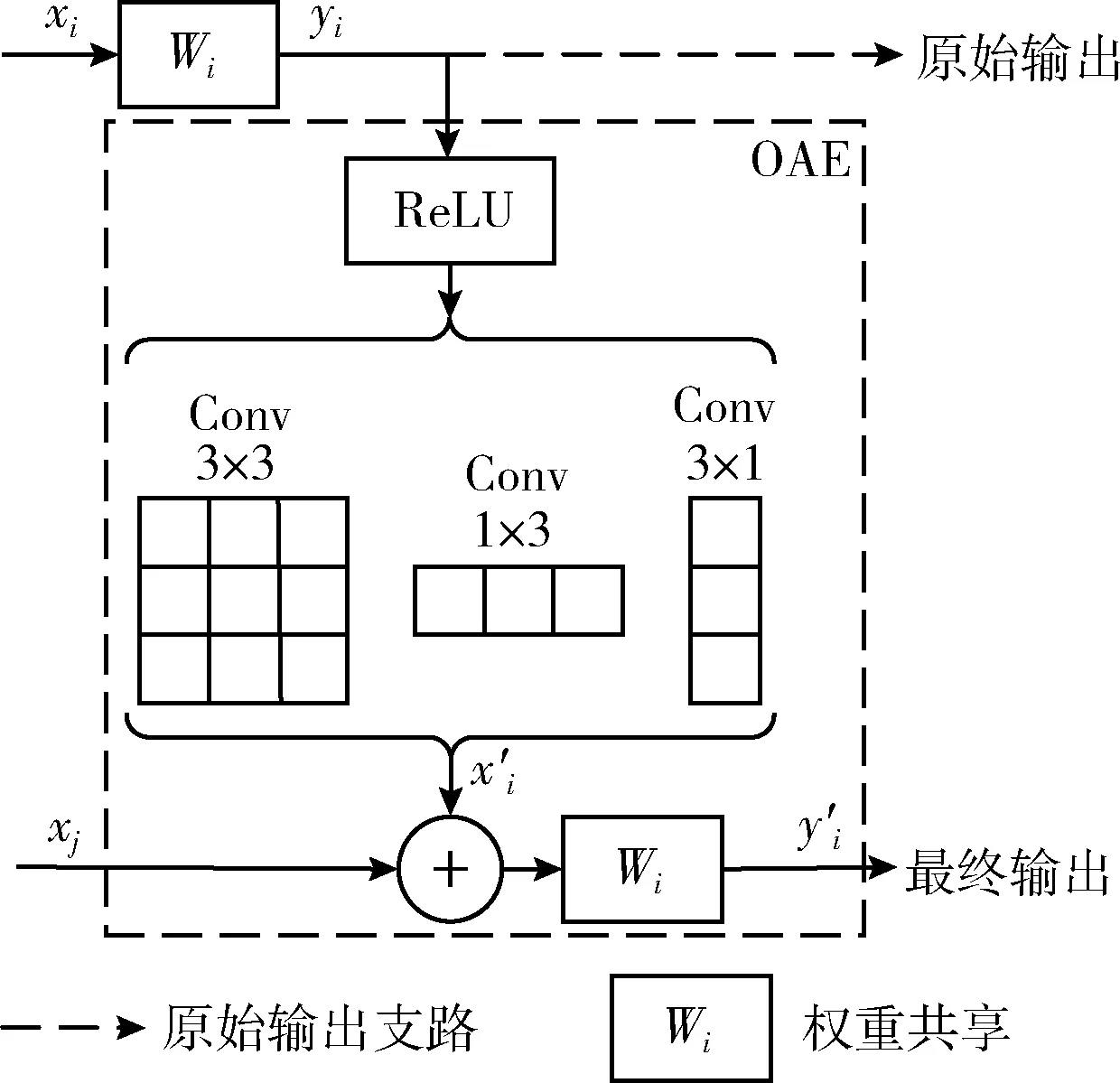
图4 OAE-Head结构
该结构基于原始检测头部的输出信息和主干网络各阶段的特征信息,通过一组非对称卷积核与共享权重的原始检测头部卷积核来进一步优化预测过程中的信息输出。此过程复用了原始预测中的启发式信息,对推理预测阶段的开环特征计算更新为闭环特征优化,以此来增强正确激活的特征区域,同时抑制背景信息[19]。
原始输出支路上的推理实现过程为
yi=Wi*xi
(9)
式中:xi和yi分别表示第i层原始输出分支的特征映射和输出,Wi为对应检测头部的卷积滤波器,*表示卷积操作。
引入非对称卷积后的OEM因其包含不同形式的卷积操作,在一定程度上能够产生差异化的梯度,得到更细粒度的特征表示。此过程可描述为
(10)
式中:Wkm表示非对称卷积滤波器,m=1,2,3时分别对应3×3,1×3和3×1的卷积核大小, ReLU(·) 为Leaky ReLU激活函数,x′i为该过程输出的特征映射,并将其与xj结合,由共享卷积核输出最终的预测信息
y′i=Wi*(x′i+xj)
(11)
式中:xj为对应主干网络的各阶段特征,y′i为第i层预测分支的最终输出。
通过应用这种反馈策略与聚合方式可以达到去噪和优化高级语义信息的目的,确保了对应尺度空间表征下目标相对位置的敏感性,加强了多尺度预测支路上的细节信息传递,提高了解的性能,从而获得更准确的预测结果。
2 实验及结果分析
本文使用公共的航拍图像数据集VisDrone[20]进行实验评估。此数据集由无人机从14个不同的城市拍摄采集,涵盖了各类视角、多种尺度和不同密度下的目标对象,共有图像10 209张,其中训练集、验证集和测试集分别有6471、548、3190张,标记的类别包括行人、车辆、自行车等10类常见目标。按照COCO数据集将面积小于32×32的物体定义为小目标的依据,VisDrone数据集中包含的小目标占比高达约60%[20],为有效实现检测任务带来极大的挑战。
实验平台采用的操作系统是内存大小为16 GB的Ubuntu16.04,处理器为i7-7800X,GPU型号为NVIDIA RTX2060 8 GB显卡,使用CUDA10.2加速库及Pytorch-1.6.0深度学习框架。实验设定训练图像的大小为608×608,采用Mosaic和CutMix数据增强方式,并进行了label smoothing标签正则化操作。优化器选择SGD和Adam进行参数更新,初始学习率为1×10-4,学习率衰减方式为余弦退火算法,衰减下限为1×10-6,训练批次大小为16,迭代150个epoch。
2.1 对比实验
在VisDrone数据集上,采用COCO数据集的评价指标对所提方法与其它主流目标检测算法和相关航拍目标检测算法进行了对比实验。从表1可知,本文算法的检测精度较其它算法有显著提升,AP值达到了26.26%,比原始YOLOv4算法提升了4.24%的精度,其中小目标的精度涨点约2%,其主要原因是本文利用上下文信息和原始预测信息优化了深层特征,一方面将用于推理小目标特征的上下文信息进行聚合并细化,另一方面在多尺度预测端优化输出信息,从而提高了小目标的检测精度。
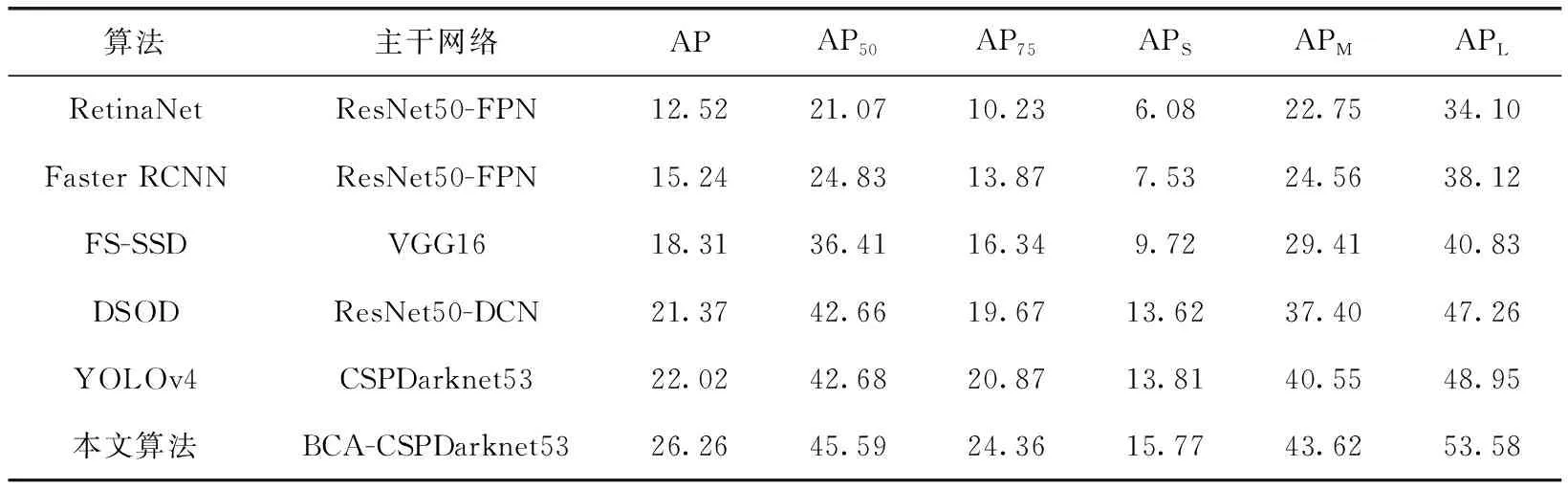
表1 VisDrone测试集上不同算法的检测结果对比/%
表2为VisDrone数据集上每个目标类别的AP。从中可知,在10类目标对象中,原始YOLOv4在无人机航拍图像上的总体检测性能要优于其它算法,而且在众多类别中,例如“tricycle”、“awning”等尺寸较小,且占比也较少的一些目标,其检测精度相比DSOD都有一定的提升。而本文算法,对比原始YOLOv4则进一步提升了此类较难检测目标的精度。
相对于“car”、“van”、“bus”这些占比较高且尺寸略大的目标,检测精度则有约3%~5%的提升。这反映了本文基于YOLOv4的改进算法对增强各类目标对象的表征效果具有明显的优势,从而提高了无人机航拍目标检测的精度。
图5展示了YOLOv4与本文算法在不同航拍场景下的检测效果对比图。从中可以观察到,YOLOv4对离视点较远的物体检测效果差,存在很多漏检目标,相比本文算法则能较好地检测出其中的特定物体类别,即使在暗夜场景下也能有效地检测出混淆在背景中的大部分目标,但对于重叠遮挡较为严重或尺寸极小的物体,仍存在一定的检测难度。总体而言,本文算法能够显著提升无人机航拍图像中小目标的检测效果,且对不同视点和场景变化的泛化能力较强。
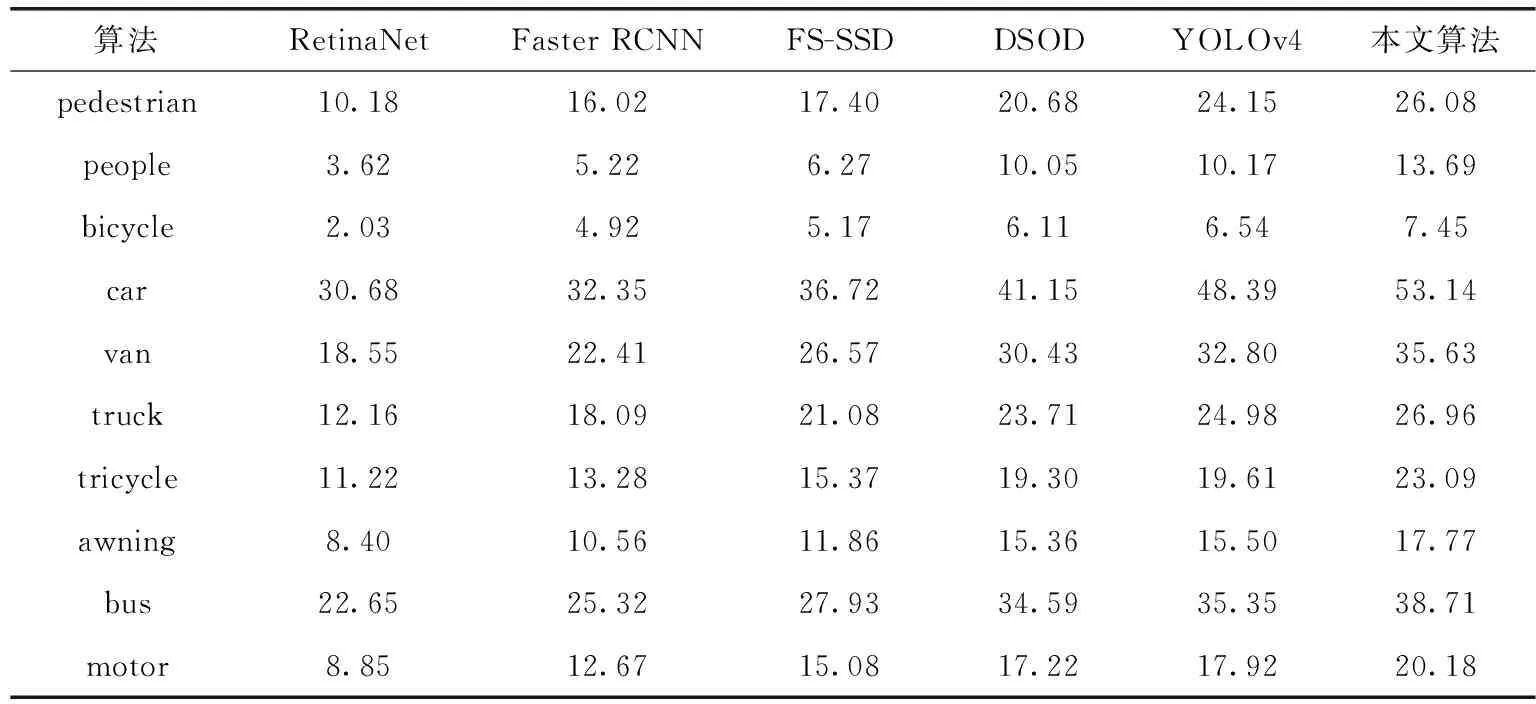
表2 VisDrone测试集上各类别检测结果对比/%

图5 不同航拍场景下的检测效果对比
2.2 消融实验
该实验是对本文网络架构中新设计模块的进一步分析,以验证其有效性和评估在不同模块组合下对算法性能的影响,见表3。从中可以观察到,在原始网络中添加BCA模块后,相比YOLOv4算法,虽然AP75降低了0.33%,但整体的AP值提升了0.49%,且算法推理时间几乎没有增加,说明本文设计的注意力模块轻量且对算法性能提升影响显著。在只加入CRM后,AP值达到了22.65%,与添加BCA时相比又有0.14%的增长,但该模块中的聚合操作增加了模型运算量,使得FPS有所下降。而引入OEM后,网络的检测精度提升最明显,相比原始算法从22.02%提升到了24.63%,这也反映了OAE-Head检测头部对多层级特征信息的闭环优化,更有利于增强网络模型对目标的感知效果。另外,将3个模块同时集成到原始框架中,AP最终可以达到26.26%,检测速度减少了6.6 FPS。总体来说,本文所提方法在无人机航拍图像中的目标检测性能具有明显增益。

表3 不同模块的消融对比结果
3 结束语
本文基于YOLOv4提出了一种改进方法来解决无人机航拍目标检测中小目标识别差的问题。利用注意力机制的优点首先对特征提取网络进行改进,以分层引导的方式来实现对阶段级特征的精炼;设计CRM对特征金字塔输出的多尺度特征进行聚合细化,从而平衡语义差异性并强化目标的特征表示;在预测层引入OAE重新利用了对更高阶特征优化后的映射,可有效提升对小目标的定位感知能力。从实验结果可以观察到,所提方法针对不同场景的航拍图像具有一定的鲁棒性和显著的检测优势。之后,本文将针对模型规模进行压缩量化工作,以实现更高效准确的航拍目标检测性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中外文摘(2021年10期)2021-05-31 12:10:40
电子制作(2019年11期)2019-07-04 00:34:38
小学生优秀作文(低年级)(2018年6期)2018-05-19 01:54:27
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
作文通讯·高中版(2017年6期)2017-07-10 03:21:34
传媒评论(2017年3期)2017-06-13 09:18:10
陕西画报(2017年1期)2017-02-11 05:49:48
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
