
基于属性分类建模的电子产品价值评估技术
2022-07-21 04:12:10王陆霖杜永萍韩红桂
计算机工程与设计 2022年7期
王陆霖,刘 杨,彭 治,杜永萍,韩红桂
(北京工业大学 信息学部,北京 100124)
0 引 言
电子产品的估价阶段是电子产品回收过程的关键阶段,能否合理高效并准确地估价会影响电子产品的回收效率和买卖双方的交易意愿[1,2]。
目前对于电子产品的价值评估技术的研究大多通过人工设定各个属性的权重,形成算法模型来进行产品价值的评估[3]。电子产品相较于其它产品,其价值波动较大,上述方法需耗费较多人力。因此,研究者们开始研究基于数据驱动的价值评估方法。Zhang等[4]和Yan等[5]使用遗传算法对BP神经网络进行优化,得到了较高的预测精度。Yu等[6]使用极限学习机构建预测模型,有效降低了数据噪音的影响。Han等[7]提出了一种混合构建神经网络的方法,能够适应价格变动。Wang等[8]引入奇异谱分析(SSA)并建立神经网络来进行商品价值的评估。NTAKARIS等[9]使用深度神经网络模型来进行价格预测,实现了特征的自动提取。Han等[10]使用模糊神经网络进行废旧手机的价值评估,提高了评估精度。Wang等[11]和Peng等[12]采用序列建模的思想,模型能够随时间自适应调整评估结果。
数据驱动的方法较为依赖历史数据,而电子产品的更新换代较快,模型会产生因缺乏历史数据而导致的对新产品的冷启动问题,然而已有的工作中都缺乏相应的缓解方法。因此,本文提出了基于属性分类建模的价值评估模型(attribute classification modeling based value evaluation mo-del,ACMVE),设计了基于属性分类的价值评估系统架构。
1 基于属性分类的价值评估架构
我们在对主流的在线电子产品回收平台的调研中发现,电子产品回收平台对产品进行价值评估的结果主要受到3个因素的影响,如图1所示。第一个因素是产品的标准价值,产品标准价值用于确定产品价值所处的大致区间,代表了产品价值受到市场行情或时间变化影响的结果。第二个因素是产品基础属性,基础属性是未经使用的全新产品包含的属性,基于产品基本价值可以计算产品的基本价值。第三个因素是产品折损属性,折损属性是使用过程中产品的损伤折旧情况,通过考虑产品受损情况在产品基本价值上进行减价得到当前产品的评估价值。
为了使得价值评估算法能够适应市场行情的变化,现有价值评估方法中的约束关系和权重需要频繁进行人工的调整和更新,耗费大量人力。对于电子产品来说,新产品的上市是非常频繁的,但现有方法为新产品的价值评估进行建模非常依赖专业人员的经验,这导致了更为严重的人力消耗。为了缓解此问题,本文提出了基于属性分类建模的价值评估模型(ACMVE),模型通过将产品属性进行分类并分别建模的方式,能够更好学习产品各属性对产品价值的影响。本文使用独立的模块拟合时间因素对产品价值的影响,在获得有时效性的评估结果的同时提高了数据利用率并且能够有效缓解冷启动问题。基于此模型设计了电子产品价值评估系统架构,能够利用历史订单信息不断优化价值评估模型,使得价值评估架构能够始终保持精度较高的价值评估结果,减少定价过程中的人工干预。
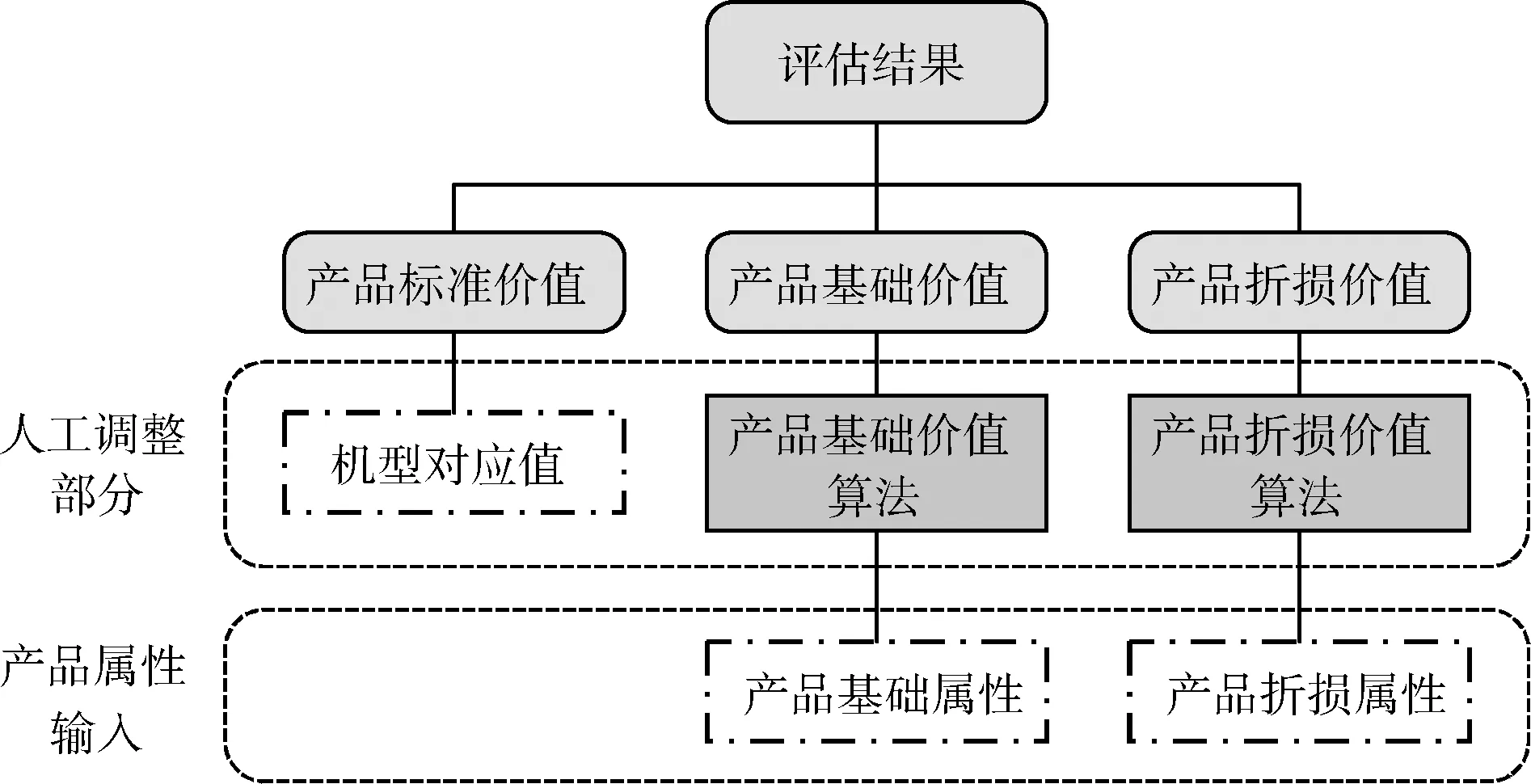
图1 传统估价方法
基于属性分类的电子产品价值评估架构通过利用其自动更新模型参数的特性来代替人工进行估价算法修正的工作,利用卖方与平台交易产生的订单数据,将历史订单信息作为价值评估模型的训练数据,通过定期训练进行价值评估模型的自动优化。本文提出的价值评估系统架构如图2所示。
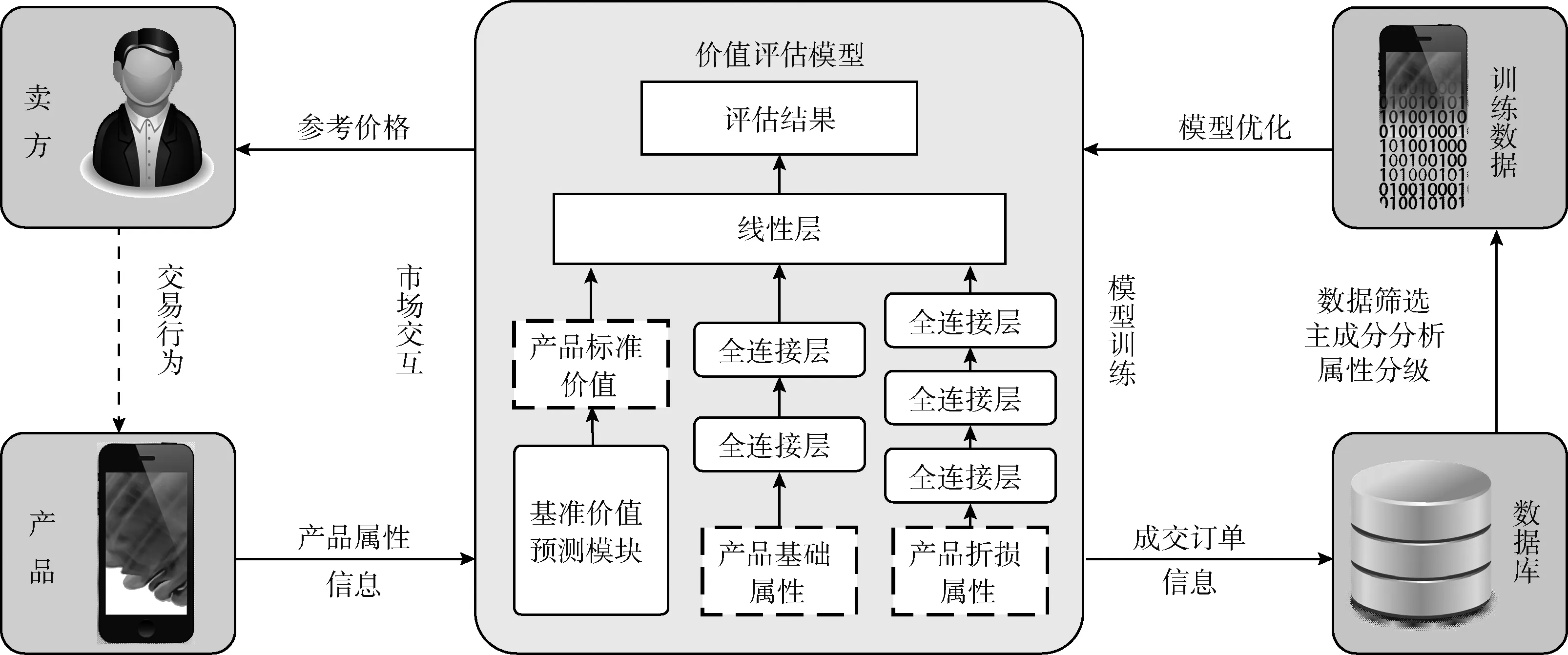
图2 基于属性分类建模的价值评估系统架构
价值评估系统分为市场交互阶段和模型训练阶段。在市场交互阶段,卖方会为价值评估模型提供待评估产品的产品属性信息,价值评估系统会将产品属性信息分类为产品基础属性和产品折损属性并输入价值评估模型,价值评估模型对卖方的电子产品进行估价,为卖方提供产品的参考价格,卖方会依据参考价格决定是否产生交易行为。
在模型训练阶段,成交的订单信息会被存入数据库,在进行训练数据预处理的过程中,价值评估系统会从数据库中筛选出成交的订单的数据并进行属性分类和数据量化,形成模型的训练数据并生成标准价值预测模块所需的数据,之后使用训练数据对模型进行训练。价值评估系统两个阶段的运行是独立的,市场交互阶段会在卖方进行价值评估请求时执行,模型训练阶段可以根据模型更新的需要调整模型训练的频率。
2 基于属性分类建模的价值评估方法
2.1 数据预处理
电子产品的属性会通过属性分类、属性指标量化和数据降维3个数据预处理步骤,形成便于模型计算的模型输入数据,其中属性分类过程将电子产品的属性分类为产品基础属性和产品折损属性,属性指标量化步骤将定性指标量化为可计算的数据,数据降维步骤可以减少数据中的噪声对模型的影响。
2.1.1 属性分类
电子产品属性对于其价值的影响主要分为产品基础属性和产品折损属性。以手机估价为例,其基础属性是手机制式、机身颜色、购买渠道、剩余保修期、存储容量、内存容量等在产品出厂时就确定的属性。手机的产品折损属性是如机身外观磨损情况、屏幕外观磨损情况、屏幕显示情况、产品维修情况等由于使用过程中产生的外观磨损和器件老化现象对产品造成贬值的属性。我们将电子产品的属性依照上述原则进行分类,分别进行建模。
2.1.2 属性指标量化
产品属性信息通常为定性指标,需要通过量化处理才可以用于计算。通常使用独热编码将产品属性信息转化为数值型数据。独热编码又称为一位有效编码,在对指标进行编码过程中,使用N位状态表示位来对指标中N种可能的状态进行编码,并且同时只有一位有效。如产品属性中颜色属性的取值为黑色或白色,则独热编码将可能把黑色和白色分别编码为01和10。对输入模型的产品基础属性和产品折损属性中的每个属性分别进行独热编码,再将对应的编码结果拼接为一个向量作为待估价产品的特征向量。
2.1.3 数据降维
产品属性中可能包含对价值评估结果影响很小甚至无关的属性,这些属性参与计算不仅增大了计算量还可能对价值评估结果造成干扰,所以本文使用主成分分析法(principal component analysis,PCA)对量化后的指标进行降维。
经过指标量化的训练数据V表示为
V=[v1,…,vi,…,vn]
(1)
vi=[vi1,…,vij,…,vik]
(2)
其中,每个v向量是一个维度为k的样本,n代表样本的个数。
(3)

对标准化阵Z求解相关系数矩阵R, 计算方法如式(4)所示
(4)
求解相关矩阵R的特征方程 |R-λIk|=0中的未知数λ,得k个特征根
{λ1,…,λj,…,λk}
(5)
按照式(6)计算特征的累计贡献率,确定m使得累计贡献率Cum大于0.85
(6)
对每个λj,j=1,2,…,m, 求解方程Rcj=λjcj得对应的单位特征向量cj。
通过式(7),将标准化的指标变量转换为主成分
(7)
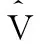
Ui=[ui1,…,uij,…,uik]
(8)
(9)
2.2 基于属性分类建模的价值评估模型
通过对电子产品回收平台的估价过程的调研并受到启发,我们设计了基于属性分类建模的价值评估模型(attri-bute classification modeling based value evaluation model,ACMVE),如图3所示。模型的输入数据分为3个部分,分别为产品标准价值和经过上述3个数据预处理步骤得到的产品基础属性与产品折损属性。
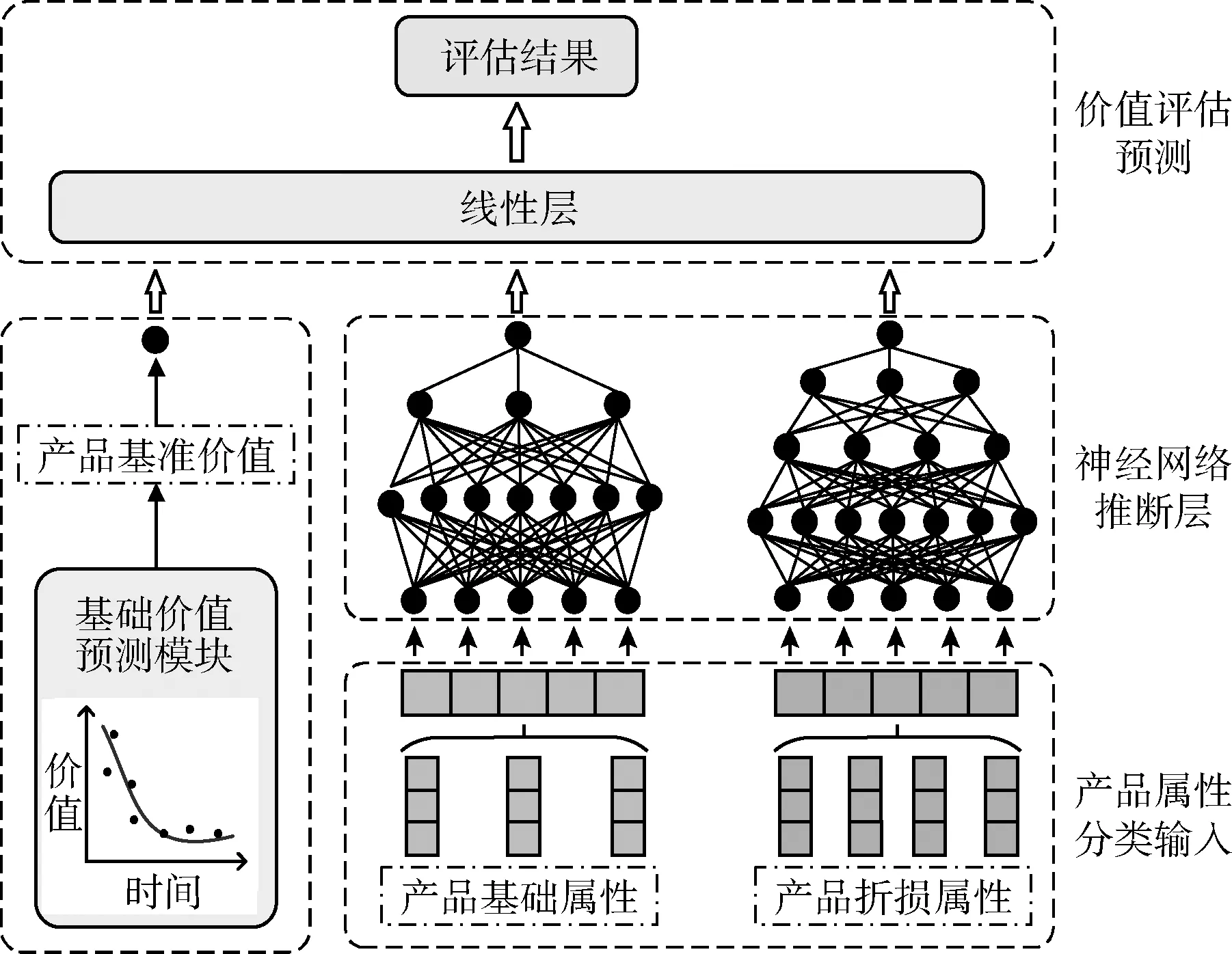
图3 基于属性分类建模的价值评估模型
模型的第一个部分的输入为产品标准价值X0。由于其取值受到市场行情和平台销售能力等众多因素影响,需要输入对应产品的实时价值变化结果。产品的标准价值代表了产品的价值受市场和时间影响的结果,模型中通过标准价值预测模块预测产品标准价值的变化趋势。我们使用标准价值预测模块来预测产品标准价值随时间的变化。其中标准价值预测模块先在历史数据中筛选出产品基础属性和产品折损属性一致的数据子集,我们使用一元多项式回归法拟合此子集中产品价值随时间的变化,将拟合得到的产品价值与时间的映射作为标准价值预测模块的计算方法,在模型进行价值评估时,输入当前时间,通过标准价值预测模块计算得到产品标准价值X0。产品标准价值的计算方法如式(10)所示
X0=b0+b1t+b2t2+…+bmtm
(10)
其中,bm为m次多项式的系数,t为产品交易的时间。
在市场交互阶段可能会发生难以预测的突发情况导致产品标准价值发生无法预测的突变,所以在实际应用场景下可以结合实际情况微调产品标准价值的取值来优化模型价值评估结果。
模型第二个部分的输入为经过数据预处理的产品基础属性X1,为了更好地表示产品基础属性的特征,我们使用嵌入学习(embedding)进行产品基础属性的特征提取。嵌入学习通过将输入的离散向量与嵌入参数矩阵相乘后扁平化为离散向量,通过训练嵌入参数矩阵能够将离散稀疏的独热编码特征转为连续稠密的嵌入向量,可以更好地表示输入特征,有利于神经网络模型学习。嵌入向量的计算方式如式(11)所示
(11)
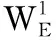
我们使用p层非线性全连接的神经网络进行产品属性与价值映射关系的学习,非线性全连接神经网络通过将输入向量与权重矩阵相乘后与偏置向量相加,再将结果代入非线性激活函数得到本层非线性神经网络的输出,经过训练的非线性神经网络具有学习非线性关系的能力。将p层非线性神经网络相连就得到了p层非线性全连接神经网络,如式(12)~式(14)所示
(12)
(13)
… …
(14)
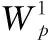
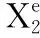
(15)
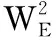
由于产品折损属性通常对于产品价值的影响相比产品基础属性更为复杂,所以我们使用q(通常q>p)层的非线性全连接网络进行处理,如式(16)~式(18)所示
(16)
(17)
… …
(18)
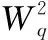
模型的3个部分将通过一个线性层整合在一起,学习3个部分的线性组合,计算方式如式(19)所示

(19)
3 实验与分析
3.1 数据来源
Y公司(因涉及商业机密,Y公司具体名称不便公开。)是专业回购电子产品的互联网科技公司,旨在打造对消费者服务的延伸。本文实验数据来自于Y公司的手机回收业务实际数据,提取2018年全年的iPhone 6s和iPhone 6s Plus两款手机机型的订单回收数据共1380条数据形成实验数据集。数据集的手机选项统计信息见表1。
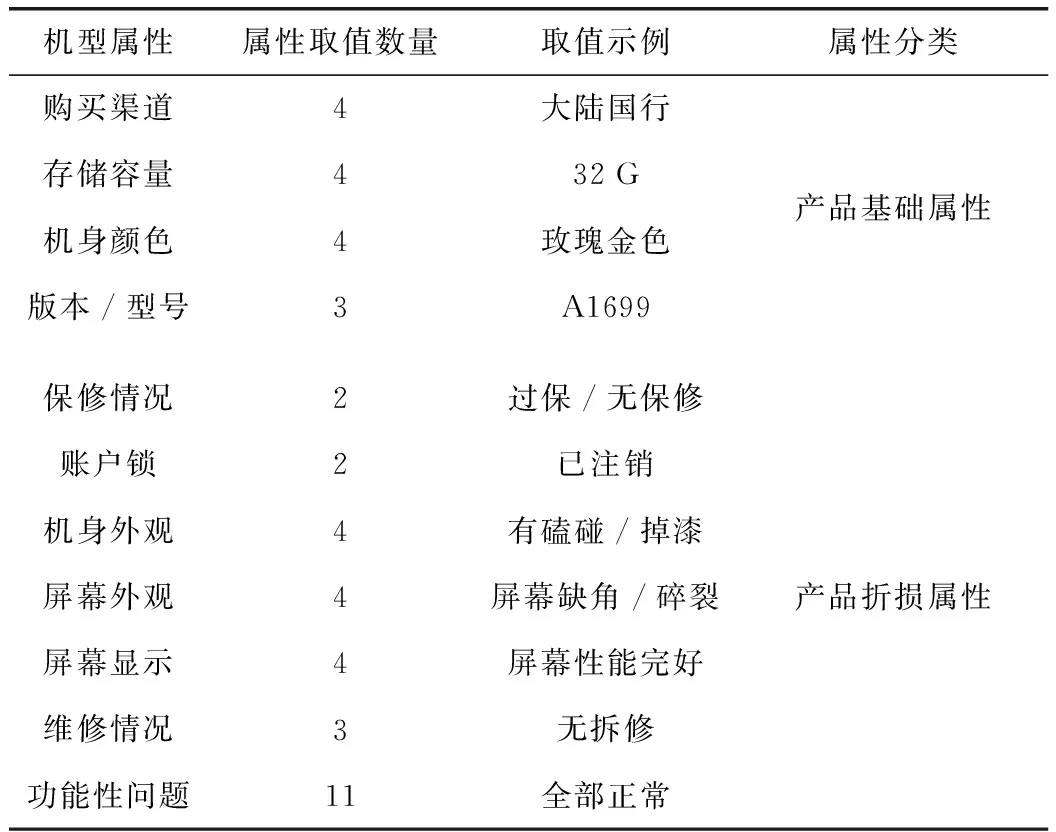
表1 手机回收订单数据集选项统计信息
3.2 实验设置与评价指标
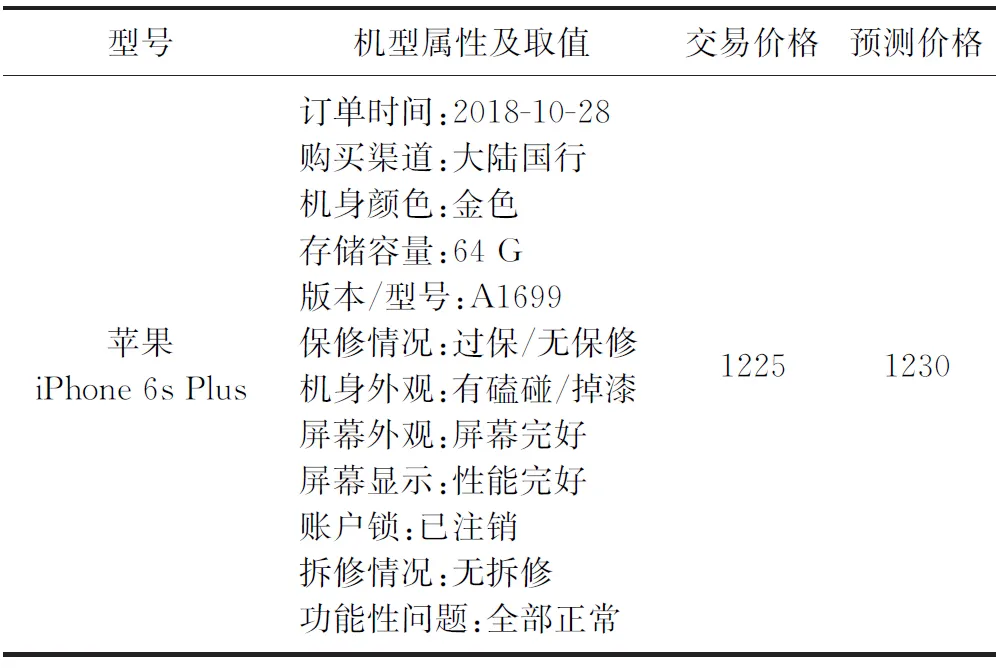
表2 数据集样例展示及模型预测结果
模型的激活函数选择了线性整流函数(rectified linear unit,ReLU),ReLU在训练过程中的计算非常高效,而且因为其在输入小于0时会将输出置为0的特性,能够一定程度上缓解梯度爆炸和梯度消失问题,如式(20)所示
ReLU(x)=max(0,x)
(20)
损失函数使用了均方误差(mean-square error,MSE),其计算方式如式(21)所示,用于优化模型参数的优化器使用了Adam优化器
(21)
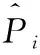
我们在模型上应用了Dropout策略,通过在训练时让每个神经元以一定概率停止工作,在预测时再启用所有神经元,可以使得模型不会太依赖部分神经元,从而起到缓解过拟合问题的作用。
在标准价值预测模块的拟合过程中,我们按照控制变量法的思想,先从训练集中筛选出手机购买渠道、颜色、存储容量等产品基础属性和机身外观磨损情况、机身屏幕磨损情况等产品折损属性都一致的数据共50条作为能够表示产品价值受时间因素变化的依据。将其交易时间与成交价格的对应关系使用一元多项式回归法进行拟合,形成产品标准价值预测模块的算法。
我们使用平均绝对误差(mean absolute error,MAE)和平均绝对百分比误差(mean absolute percentage error,MAPE)作为评价模型性能的指标,平均绝对误差能够体现模型预测的结果与真实值的差距,而平均绝对百分比误差是模型误差与真实值的比值,能够体现模型误差的可接受程度,其计算方式分别如式(22)和式(23)所示
(22)
(23)
通过实验,我们发现在手机交易数据集中最优的对应产品基础属性和产品折损属性的神经网络层数应设置为p=3、q=5。
实验在Ubuntu 16.04系统上使用Python语言进行编程,模型使用Tensorflow神经网络框架实现。
3.3 实验结果与分析
我们将基于属性分类建模的价值评估模型(ACMVE)在MAE和MAPE指标上的性能表现与多层感知机模型(multi-layer perceptron,MLP)、基于LSTM的价格预测方法(long short-term memory,LSTM)[12]以及基于模糊神经网络的废旧手机价值评估方法(fuzzy neural network,FNN)[10]的性能表现进行了对比,实验结果见表3。
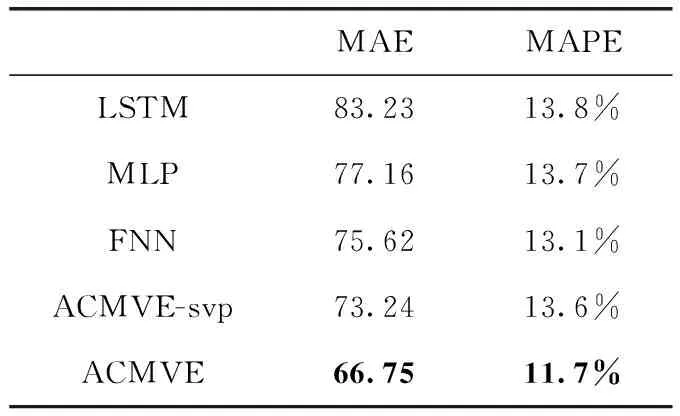
表3 价值评估模型的性能对比
由表3的实验结果可以发现,我们提出的基于属性分类的价值评估模型ACMVE在MAE和MAPE两个指标上的性能优于其它方法。长短期记忆网络(LSTM)对序列数据建模效果优秀,但建模产品属性与产品价值之间潜在关系的能力较差,模型的预测精度较低。得益于非线性激活函数和多层叠加的结构,多层感知机(MLP)在建模产品属性的能力较强,性能有了一定程度的提升。融合了模糊理论的FNN模型取得了相比于上述方法更加优秀的预测精度,但由于缺少了时间信息,其性能提升依然有限。为了验证标准价值预测模块的有效性,我们进行了消融实验,表3中ACMVE-svp是ACMVE模型去除了标准价值预测模块进行训练得到的模型,对比ACMVE的完整模型,ACMVE-svp模型在测试集上的预测精度有了明显下降,特别是在绝对百分比误差(MAPE)上的表现有了明显的性能下降。通过消融实验的结果可知,ACMVE-svp模型的预测精度相比于其它方法有了一定程度的提高,由于加入了标准价值预测模块,能够学习时间因素对于电子产品价值的影响,对于ACMVE模型的价值评估精度有明显的提升作用,尤其对于MAPE指标上的表现有更大的提升,这使得模型的预测结果更具有实用性。ACMVE模型使用神经网络的结构分别对分类后的属性进行针对性的建模,并且通过标准价值预测模块能够预测产品价值随时间的变化,达到了更好的评估结果。
LSTM、MLP、FNN和ACMVE在测试集上的价值评估绝对误差和绝对百分比误差如图4和图5所示。
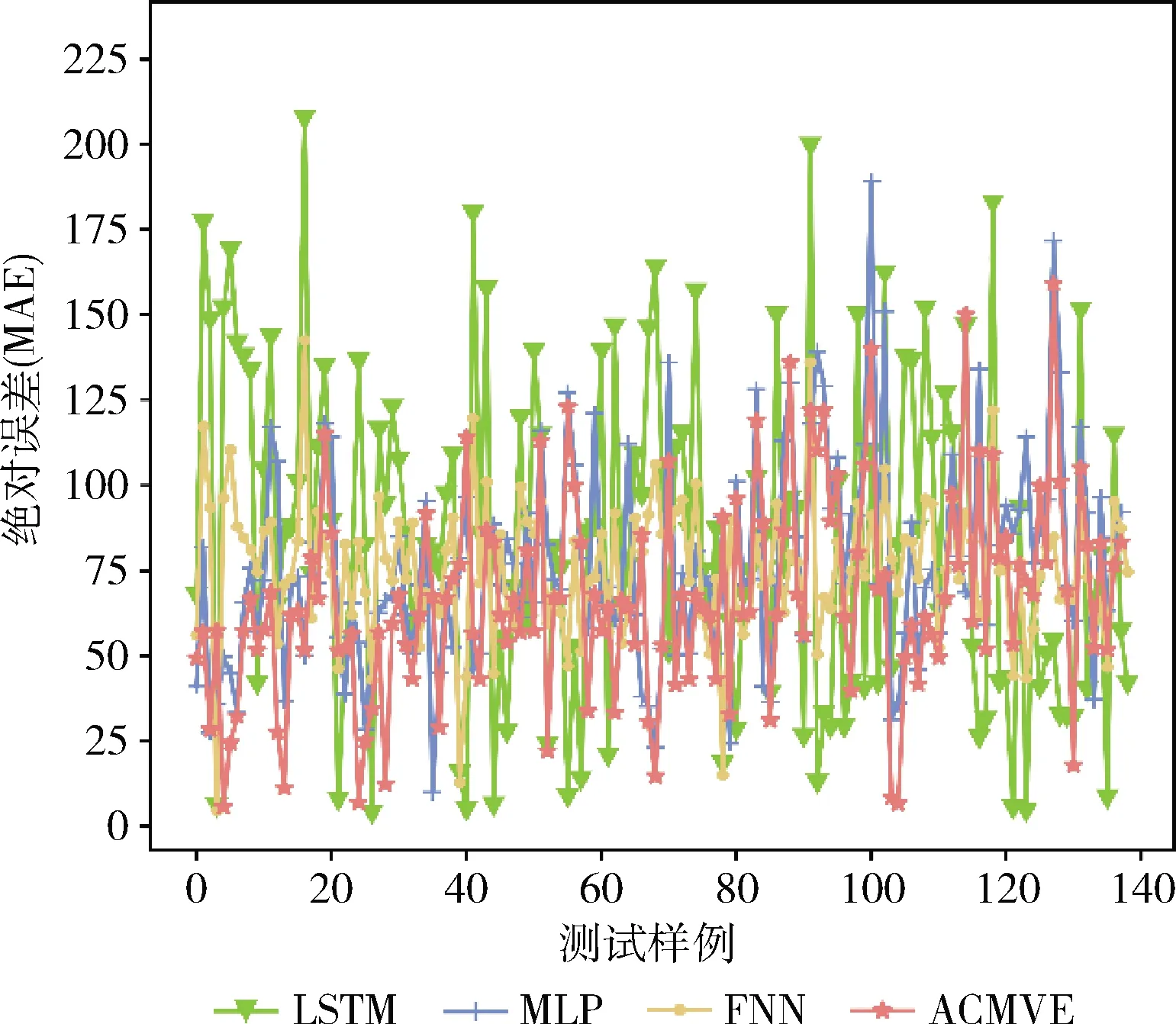
图4 不同模型在测试集上的绝对误差
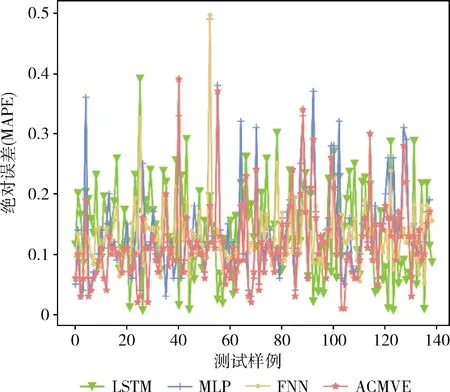
图5 不同模型在测试集上的绝对百分比误差
从实验结果来看,基于LSTM的价值评估模型(LSTM)的价值评估效果不够稳定,在部分测试样例上的绝对误差很低,但在其它样例上的绝对误差较大,导致其整体性能表现较差。同为神经网络模型的多层感知机模型MLP和ACMVE模型中,由于MLP的单线结构,MLP会倾向于融合两种属性,而电子产品属性中基础属性与折损属性对产品价值的影响是相对独立的。基于FNN的价值评估模型因为基于模糊理论的规则推理层的加入,能够更好学习价值与关键特征变量之间的关系从而获得更好的推理能力,但由于缺乏时间信息的加入,模型对于部分数据的价值预测误差依然较大。
ACMVE模型通过两个神经网络分别学习产品基础属性和产品折损属性对产品价值的影响,能够减少产品属性之间的干扰,并且由于产品标准价值预测模块的加入,模型具有了预测产品标准价值变化趋势的能力,模型的预测稳定性更好,并且大部分样例的预测误差更小,从而得到了对比实验中最优的效果。
标准价值预测模块的拟合效果如图6所示。从图中可以看出,标准价值预测模块拟合价值变化趋势的同时,能够一定程度上去除少数干扰数据的影响,为模型整体提供了更好的泛化能力。
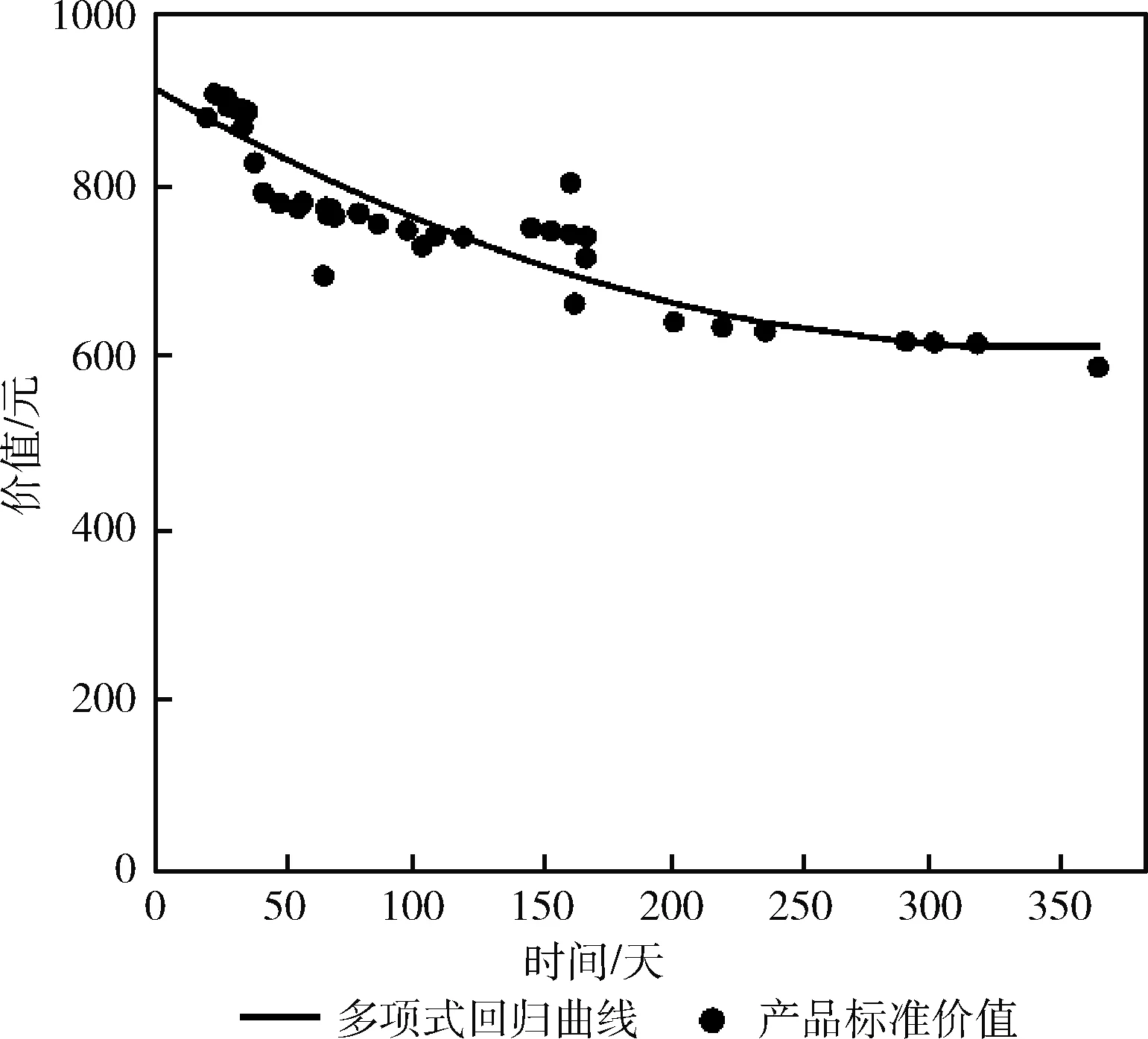
图6 产品标准价值预测模块拟合效果可视化
我们还进一步分析了输入数据通过主成分分析法(PCA)降维前后对模型性能的影响,降维前后的输入数据维度变化和性能表现对比见表4。
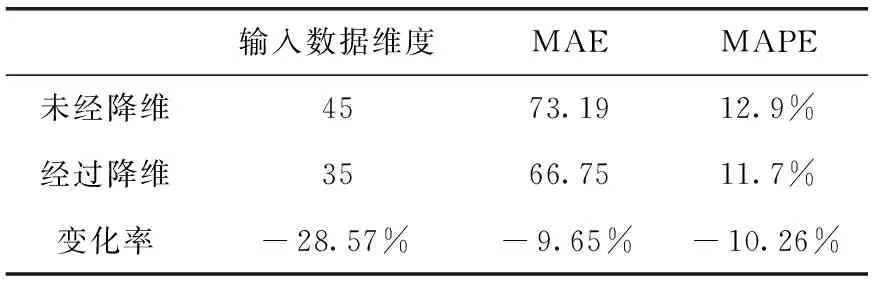
表4 主成分分析前后模型的性能表现对比
通过表4的实验结果对比可以发现,输入数据通过主成分分析法降维后,输入数据的维度减少了约30%,说明实验数据中存在部分冗余维度。将输入数据的维度降低后,模型在MAE和MAPE两项指标上的表现均提升了10%左右,对比实验结果表明,主成分分析法能够有效地降低输入维度并同时提高价值评估的精度。
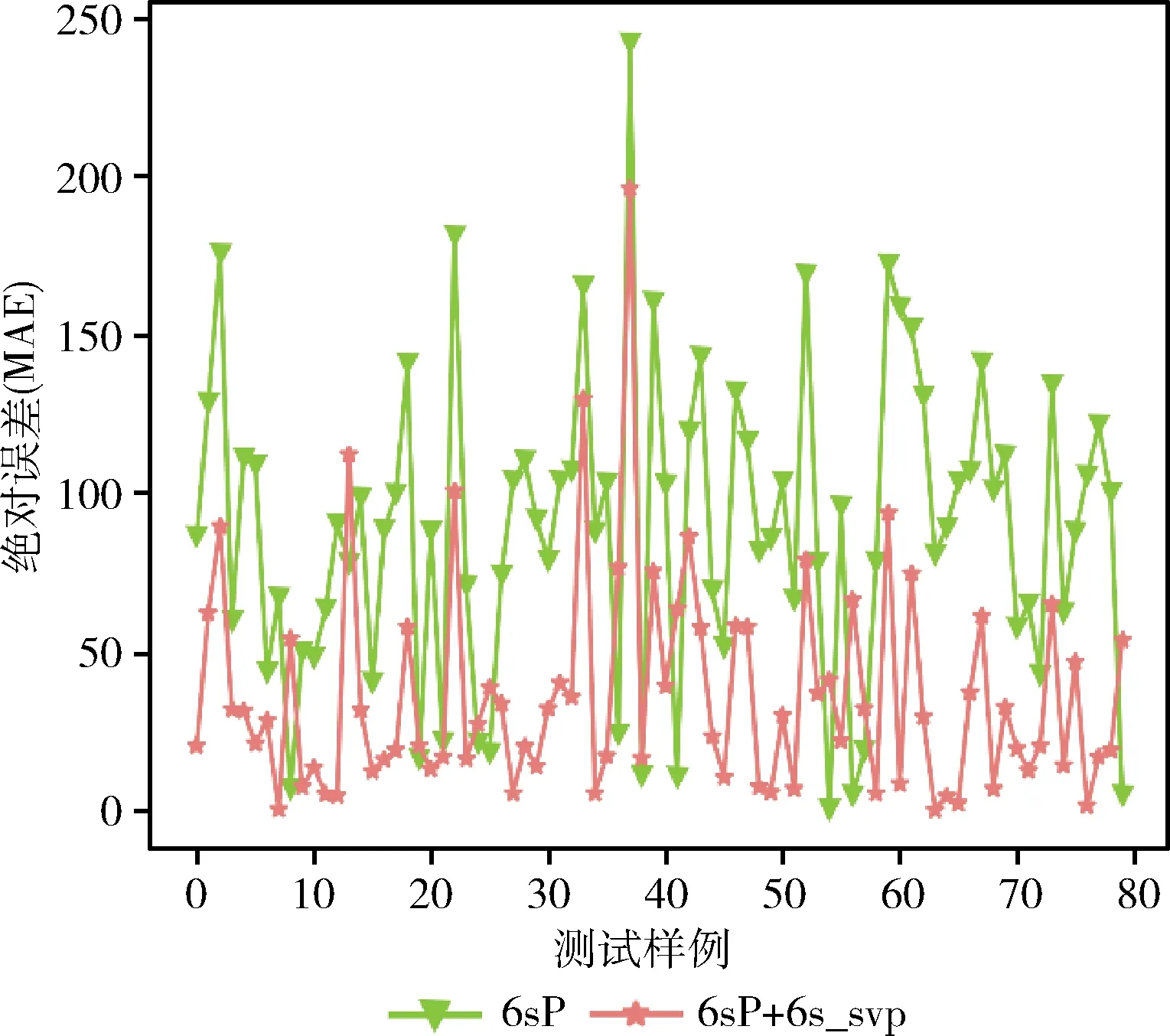
图7 加入6s标准价值预测模块前后的实验结果对比
通过实验结果可知,在6s数据集上训练的标准价值预测模块能够有效提升模型在6sP数据集上的预测精度。这说明手机产品价值受时间因素的影响趋势具有一定的通用性,能够通过在较早进入市场的产品的数据集上进行产品标准价值预测模块的训练,应用在较新进入市场的产品的价值评估模型上可以提高价值评估模型的预测精度。
4 结束语
本文分析了目前回收平台的价值评估过程,针对其过于依赖人工干预的缺点设计了利用历史交易数据优化模型的基于属性分类的价值评估系统架构,提出了基于属性分类建模的价值评估模型(ACMVE),大幅减少了人工干预。通过将产品属性进行分类并分别建模,使用一元多项式回归法预测电子产品标准价值的变化,使得模型的预测结果更具有时效性。独立的产品标准价值预测模块能够缓解对于新产品的冷启动问题,提高了数据利用率,在实际应用中具有更大优势。基于属性分类的电子产品价值评估模型在真实手机回收交易数据集上的测试结果表明,其价值评估结果的误差更小,具有实际应用的价值。后续将研究利用多任务学习方法学习电子产品的通用特征,增加模型的适用性。
猜你喜欢
红蜻蜓·低年级(2021年11期)2022-01-19 01:35:06
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:02
甘肃教育(2020年8期)2020-06-11 06:10:06
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2018年17期)2018-09-28 01:56:44
中华家教(2018年8期)2018-09-25 03:23:06
通信电源技术(2018年5期)2018-08-23 01:15:36
中国资源综合利用(2017年3期)2018-01-22 02:45:44
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
