
基于机器学习的航空异常着陆事件检测
2022-07-21 04:12:14苏志刚杨金锋张海刚
计算机工程与设计 2022年7期
杨 雄,苏志刚,杨金锋,张海刚
(1.中国民航大学 电子信息与自动化学院,天津 300300;2.中国民航大学 中欧航空工程师学院, 天津 300300;3.深圳职业技术学院 粤港澳大湾区人工智能应用技术研究院,广东 深圳 518055)
0 引 言
快速存取记录器(quick access recorder,QAR)即是一种常见的飞行数据记录设备[1]。目前,QAR数据越来越被民航安全专家所重视,这标志着民航界从事故寻因这种预防航空危险的被动思维到日常监控提升航空安全水平的主动出击思维的转变。但目前实际应用的阈值方法面临着机型多样性、地理多样性和气候多样性的挑战,很难兼顾每种条件设定阈值[2],因此亟需一种有效的方法从航空高维数据中准确地检测出异常事件。
目前国内外学术界对QAR数据应用于航空异常事件的研究可分为基于拟合回归的方法、基于聚类的方法和基于分类的方法。基于拟合回归的方法是无监督方法,不需要标签。拟合的方法使用多个自变量参数来拟合一个因变量,从而找出自变量和因变量之间的关系[3,4]。基于聚类的方法也属于无监督方法,与回归方法不同的是基于聚类的方法首先会找一个聚类中心,计算其余点与中心点的相对距离,检测出相对距离较大的点即为异常点[5,6]。基于分类的方法是有监督方法,使用分类器通过异常标签来检测异常[7,8]。基于拟合和聚类的方法根据不同的规则来分析航空数据,侧重挖掘和利用数据间关系[9],但因为没有标签信息,无法统一比较这些算法的性能,因此很难评估这些算法在大规模数据应用上的有效性。在另一方面,基于分类的方法优势在于可以充分利用标签属性和有监督模型学习到数据类别的判别边界,但在航空领域标签信息很难获取。
为了比较每一种算法的性能,本文克服标签获取的困难,以飞机最常发生事故的着陆进近阶段为检测目标[10],通过数据源匹配得到异常标签。针对航空高维数据的特点,提出了一种基于斯皮尔曼等级相关系数(spearman rank correlation coefficient,SRCC)特征处理、梯度提升树(gradient boosting decision tree,GBDT)和递归特征消除(recursive feature elimination,RFE)经过交叉验证(cross validation,CV)特征处理的混合特征选取方法,最后使用贝叶斯优化改进目标函数的极限梯度提升树(extreme gradient boosting,XGBoost)的异常检测模型。
1 航空异常着陆事件检测方案
航空异常着陆事件检测方案主要包括以下过程:首先将QAR数据和参数监控标准数据匹配,得到异常标签;再对数据进行预处理,处理数据匹配和数据重抽样;然后使用混合特征选取的方法选择合适的特征;随后使用贝叶斯优化的加权XGBoost算法训练出模型;最后在未做任何改变的测试集上模型评估。整个检测方案的流程如图1所示。
1.1 数据匹配
本文选用同一天气状况下一个月份的波音737-800和737-900ER的QAR数据作为实验基础,总共861个航班。借助航空公司的译码软件AirFase得到译码后的QAR数据和超限事件参数库,超限事件参数库是AirFase软件根据民航法规设定的参数阈值[11]得到的航班超限异常,部分超限参数阈值见表1。

图1 模型流程

表1 部分参数阈值及触发条件
QAR数据中有航班注册号、机型号、航班执行日期、飞行时间和各参数记录,超限事件参数库里面有航班注册号、机型号、异常阶段、异常事件发生事件及异常程度等。通过匹配两个数据源中的航班注册号和航空公司注册号,搜索超限异常参数数据源中的异常事件发生的时间在QAR数据中的航班执行日期和时间,通过这些参数可以唯一确定哪个航班在哪个时间点发生了何种异常。最终通过正则化过滤、航班号匹配、异常时间定位等手段实现了QAR译码数据和标准超限参数库的匹配从而得到异常标签。整个过程如图2所示。

图2 数据源匹配得到异常标签
将监控参数标准库与每个航班的QAR数据匹配,得到每个异常发生的时间点。再将一个航班中第一秒发生异常的时间点和最后一秒发生异常的时间点中间的时间段全部打上异常标签,即得到QAR异常参数数据集。
1.2 数据重抽样
为了确保不同航班有相同的输入长度,对每个航班的数据样本进行重抽样。对于每个航班f来说,样本数据可以表示为式(1)
(1)
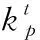
对每个航班按相同的规则进行重抽样。飞机在刚着陆时,刹车会拉到最大以降低速度。将飞机刹车值突变的点设为着陆点,每个航班取着陆点前29点,着陆后取10点,每个航班总计40个时间戳,取值的范围涵盖了飞机在500英尺至在滑行跑道上的高度,因此总共有34 440行样本。
1.3 航空着陆异常特征提取
在飞机飞行时,会有多个传感器来记录同一参数,以保证当一个传感器发生故障时其它传感器还能继续工作。这种冗余机制一方面保障飞机的安全,但另一方面在数据分析时却会带来不必要的麻烦。因此本文结合3种特征选取方式:过滤法(Filter)、包裹法(Wrapper)和嵌入法(Embedding)[12],设计出一种针对航空高维数据的混合特征提取算法。混合特征选取算法首先对航空参数采取斯皮尔曼等级相关系数消除冗余特征,之后采用梯度提升算法选取与异常事件最相关的特征,其中使用递归特征消除。
1.3.1 斯皮尔曼冗余特征处理
斯皮尔曼等级相关系数特征处理是一种过滤的方法,它值的范围从-1到1。值1表示强正相关,值-1表示强负相关,当相关系数接近于0时,表示特征之间不存在相关关系。在当前数据集种负相关和正相关都是相关,所以取相关矩阵的绝对值。斯皮尔曼等级相关系数表示为式(2)
(2)
其中,d为A、B两个变量中元素对应相减得到一个排行差分集合,其中di=Ai-Bi,N为单个元素总个数,在这为QAR数据的行数。如果两个变量的相关系数越接近1,说明两个变量具有很强的相关性,可以认为是冗余的,本文经过实验将相关阈值设为0.95。经过冗余值列处理后,着陆阶段QAR数据的特征由152维降至78维。
图3为原始数据和数据预处理后的热力图对比,右侧从浅至深的渐变色表示相关系数从小到大的变化,颜色越深,说明两个变量之间的相关系数越大,这两个变量更有可能互为冗余列。通过图3(a)、图3(b)可以看出经过数据预处理之后,深色区域明显变少,深色程度明显变弱。
1.3.2 GBDT-RFE-CV关键特征选取
GBDT是集成学习Boosting的一种,Boosting方法以连续的方式训练一堆单独的模型,每个单独的模型都从前一个模型的误差中学习。而GBDT每个模型采用基于分类与回归树(classification and regression trees,CART),通过每个模型在上一轮模型的残差基础上进行学习,学习的方向是前一个模型损失函数的梯度下降方向[13]。GBDT特征选取是一种基于模型的方法,设有K个CART树的决策空间F,通过训练数据集,GBDT的每颗CART树fk在不同特征上分裂节点(node)的次数之和为不同特征的重要度,之后通过设定特征数目阈值或者选取性能指标选取合适的特征子集。
RFE[14]是一种Wrapper特征选取的方法,它的目标是通过递归地考虑越来越小的特征集来选择特征。首先,在初始特征集上训练估计器,得到每个特征的重要性。然后,从当前的特征集合中剔除最不重要的特征。这个过程在修剪集上递归地重复,直到最终达到需要选择的特征数。
GBDT特征选取和RFE方法组成了一组嵌入法特征选取方法。首先,GBDT模型在原始特征上训练,每个特征得到一个权重即特征重要度。之后,那些拥有最小绝对值权重的特征被移出特征集空间。如此递归重复,直至剩余的特征数量达到设定的特征数量阈值。为了让算法自动地选取合适的特征,本文采取交叉验证的方法,能够自动调整特征子集空间的特征数量,具体的算法流程如下所示。
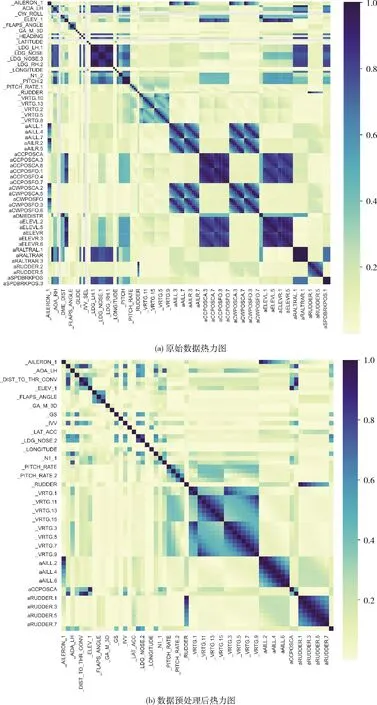
图3 数据预处理前后热力图对比
算法1:GBDT-RFE-CV特征选取
输入:含有M个特征的训练集S,n折交叉验证,特征选取设定的阈值L
输出:最佳特征子集
(1)将训练集分层抽样划分为n轮数据集,每轮n-1份为训练集,1份为测试集
(2)每一份数据集通过GBDT训练得到决策空间F

(4)根据每棵树上特征node数目得到特征重要度
(6)在M特征空间遍历删除最不重要的特征,得到新的子集空间Mi
(7)使用Mi特征子集执行交叉验证,得到验证分数,并丢弃最不重要的特征,得到新的子集空间Mi+1
(8)end for
(9)end for
(10)统计最高的交叉验证分数得到最佳特征子集
1.4 贝叶斯优化的改进XGBoost
1.4.1 改进XGBoost
XGBoost的也是集成学习Boosting的一种,相比于GBDT,XGBoost对代价函数进行二阶泰勒展开,并在代价函数中引入了正则项,用于控制模型的复杂程度。因此从原理上XGBoost的性能更好,更适合用作最终的异常检测器。XGBoost的目标函数[15]是由训练损失和正则化两部分组成,训练损失函数的定义如式(3)所示,正则化即树的复杂度定义如式(4)所示,目标函数的定义如式(5)所示
(3)
(4)
(5)
对于二分类问题,XGBoost的默认损失函数为交叉熵损失(cross entropy loss,CE),定义为
(6)
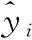
交叉熵损失明确了误差越大损失越大的准则,但是对于非平衡数据而言,总的交叉熵损失在多数类别样本中更容易降低,对整个分类器性能却没多大提高。为了提高模型对少数类别样本的学习能力,本文通过改变分类器的目标函数,引入代价敏感学习(cost sensitive learning,CS)函数[16]和聚焦损失(focal loss,FL)函数,从而改进分类器的性能。
代价敏感学习函数的定义为
(7)
(8)
式中:w为负例(negative,neg)多数样本比正例(positive,pos)少数样本的比例。代价敏感学习平衡了正负类的重要性,使得模型更加重视正样本。
聚焦损失函数是由Lin等[17]提出,旨在解决one-stage目标检测器样本的类别不平衡问题和不同难易程度的样本学习不平衡问题,聚焦损失函数的定义为
(9)
式中:γ为调节因子,降低容易分类样本的权重,使分类器聚焦于难样本的训练。当γ等于0时,聚焦损失函数为一般的交叉熵函数。
本文将代价敏感度学习函数与聚焦损失函数结合,因此整个模型的损失函数为

(10)
损失函数的一阶导gi和二阶导hi为

(11)
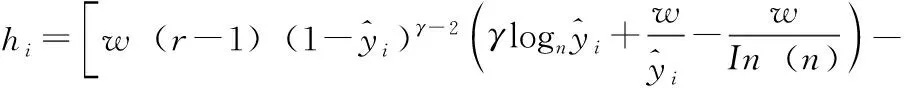
(12)
此时对应近似的目标函数为
(13)
将式(5)代入式(9)进一步简化得到
(14)
式中:Gj和Hj分别是关于近似损失函数一阶偏导数和二阶偏导数的累加之和。
1.4.2 贝叶斯参数优化
对于XGBoost的其它参数,如果单纯靠手工调节参数,不但繁琐复杂,而且算法也无法发挥出最好的性能。本文借助贝叶斯算法自动调节参数使算法达到最好的效果。贝叶斯优化[18]通过建立目标函数的代理概率模型,利用它来选择最优的超参数,以对真实目标函数进行评估。贝叶斯优化在选择超参数集时会考虑到以往的评估,通过以这种有先验信息的方式选择参数组合,模型将关注最有希望的验证分数的参数空间区域。这种方法只需要较少的迭代次数就能获得最佳的超参数值集,因为它忽略了那些不会带来任何影响的参数空间区域。改进目标函数后的XGBoost的流程如图4所示。

图4 贝叶斯优化流程
2 实验结果与分析
2.1 评价指标
本文研究的是航空异常事件的检测与识别,因此真阳性(true positive,TP)即为航空异常事件样本预测为异常的实例数量,假阴性(false negatives,FN)即为航空异常事件样本预测为正常事件的实例数量,真阴性(true negatives,TN)即为航空正常事件样本预测为正常着陆事件的实例数量,假阳性(false positive,FP)即为航空正常事件样本预测为异常事件的实例数量。混淆矩阵说明见表2。

表2 混淆矩阵说明
对于非平衡数据而言,单一的准确率指标不足以反映模型的好坏,需要综合考虑多数样本和少数样本分类的准确性[19]。因此本文采用灵敏性和特异性来分析混淆矩阵,使用ROC曲线和PR曲线围成的面积来评估分类器的性能。所有的指标范围都在[0,1]之间,越靠近1说明算法性能越好,反之则说明算法性能较差。各指标说明见表3。
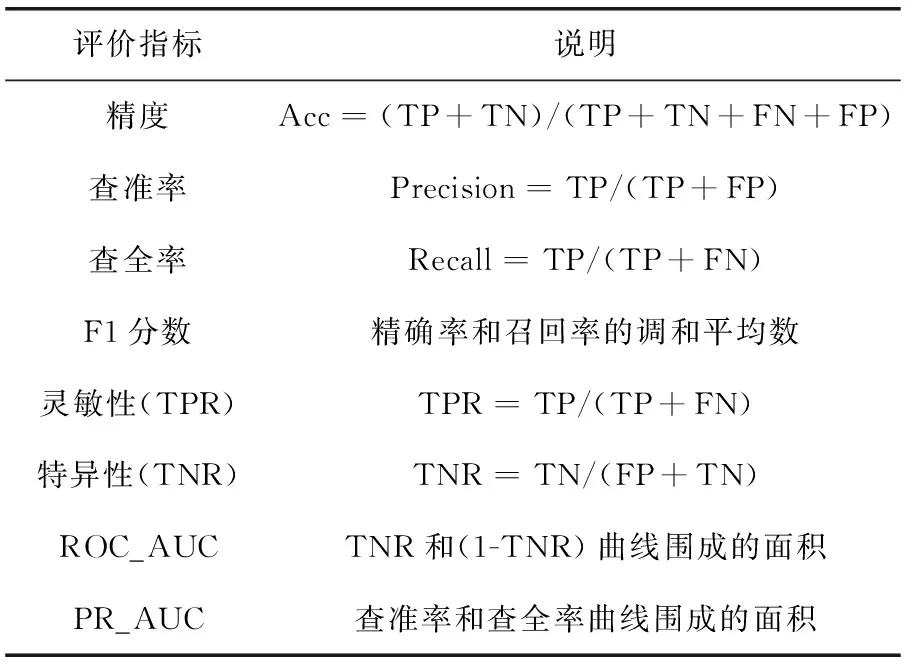
表3 评价指标说明
2.2 实验过程

本文的GBDT-RFE-CV算法在特征选取过程中设置了不同特征数子集,图为不同特征子集的数目和交叉验证分数,图中竖线与曲线交叉的点为交叉分数最大的点,竖线所对应的横坐标为所选取的最佳特征子集,在图5中可以看出算法选取的最佳特征子集数为18,选取的特征参数如图6所示,选取的特征反映了航空器的飞行状态、飞机操纵和发动机状态。飞行状态的参数如垂直下降速率、俯仰角、加速度、雷达高度等,飞机员操作参数如刹车、操纵舵等,飞机发动机参数如低压转子N1、高压转子N2。
本文经过贝叶斯参数调节后的XGBoost超参数见表4。
本文改进XGBoost目标函数是在原始XGBoost的基础上导入由式(11)、式(12)推导出的一阶导数和二阶导数,最终w取5,γ取2实验效果最好。
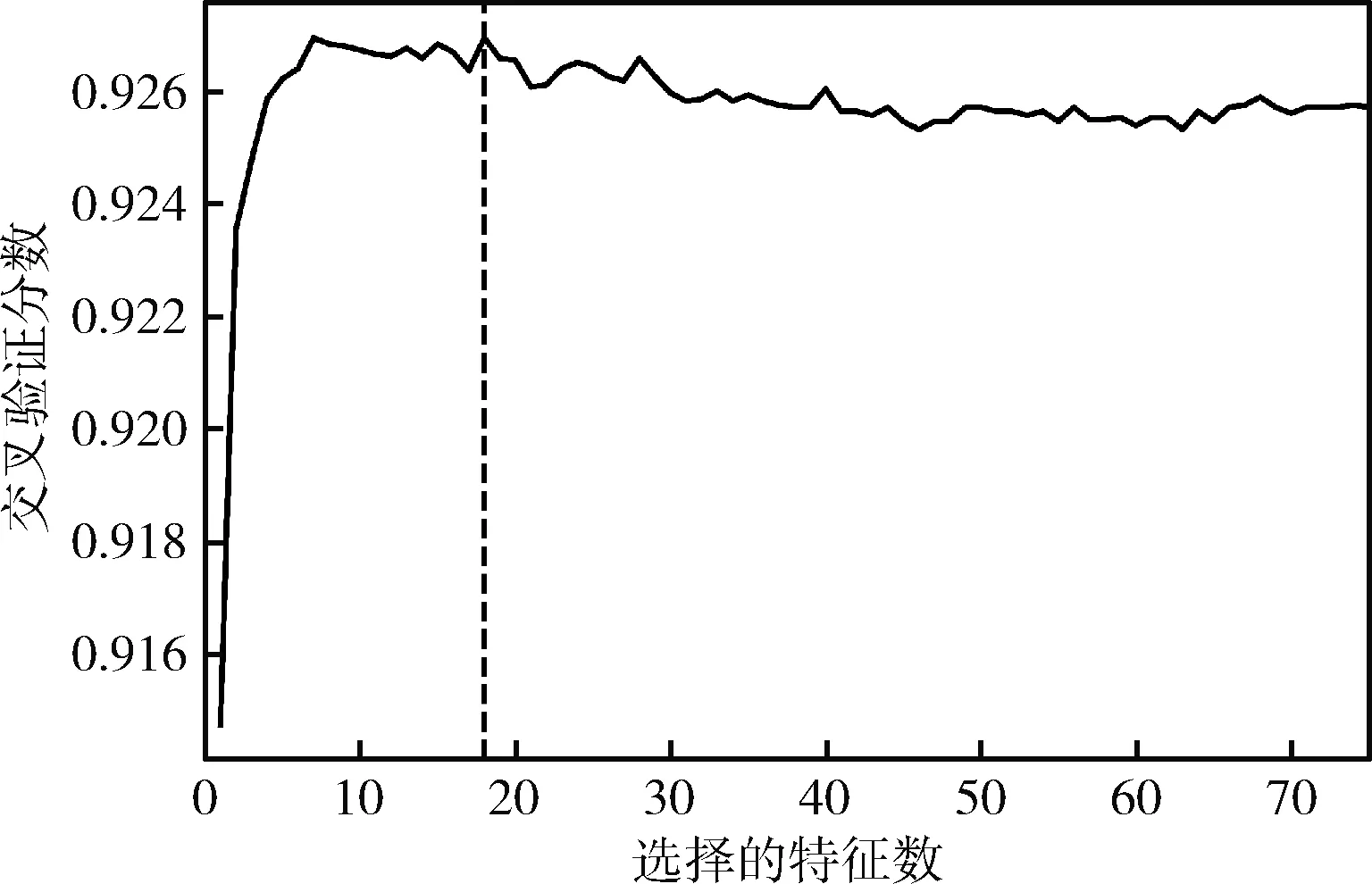
图5 GBDT-RFE-CV特征选取的分数与特征值数量

图6 GBDT-RFE-CV选取的关键特征
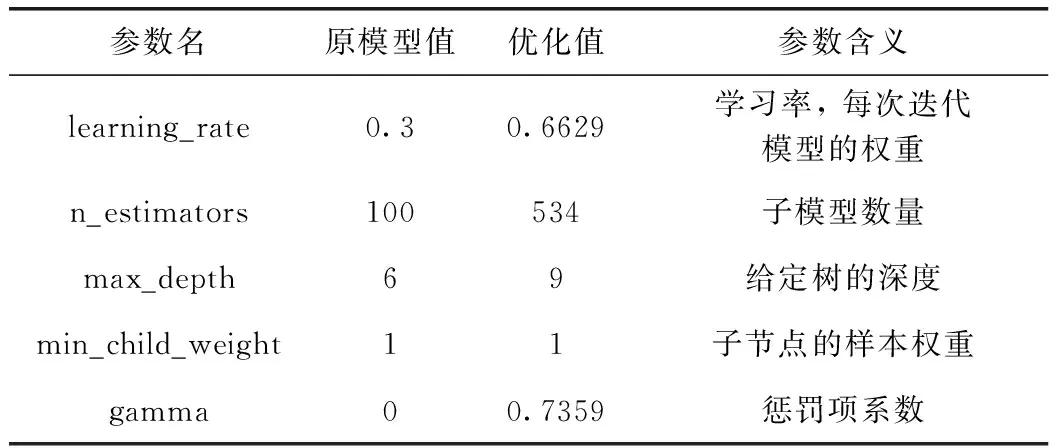
表4 贝叶斯优化后的参数值及含义
2.3 实验结果与分析
为了展示特征选取的必要性和对比经过贝叶斯调参后的改进XGBoost算法在航空异常事件检测中的优越性,本文统计了各算法的精度、查准率、查全率、F1分数、ROC_AUC、PR_AUC、特征选取时间和各模型运行时间,绘制出各模型的ROC曲线和PR曲线。
2.3.1 改进对比
表5和图7展示了算法改进的对比实验,总共分为6组改进对比,分别为了对比混合特征选取、经过目标函数改变后的XGBoost和贝叶斯调参后的效果,其中本文的模型使用的是混合特征选取和贝叶斯优化的改进目标目标函数的XGBoost,整个模型流程首先使用SRCC删除航空数据冗余特征,再结合异常标签使用GBDT-RFE-CV以提取关键特征,然后通过导入由式(11)、式(12)自定义XGBoost的目标函数,最后使用贝叶斯算法来调节XGBoost的超参数。从表中可以从两个方面看出算法改进后的提升效果。首先是特征选取时间和算法训练时间,提升效果最明显的对比是直接使用GBDT-RFE-CV关键特征选取和先使用SRCC删除冗余再使用GBDT-RFE-CV混合的特征选取,特征选取时间从1 h 20 min降低到23 min 52 s,运行时间降低了71%。且经过特征选取后,对比原始数据模型训练时间和测试时间都有所缩短,原始数据需66.82 s才能训练模型,本文经过特征提取后训练时间仅需24.56 s,训练时间缩短了63%。这些都显示出混合特征算法的必要性。第二从算法性能上对比,可以看出SRCC虽然在性能方面提升不明显,但是特征选取耗费的时间上,SRCC仅需15 s就能删除冗余特征,能很好降低特征选取时间。对比经过混合特征选取、改进XGBoost和贝叶斯调参后F1分数分别较XGBoost在原始数据的模型提升了0.09、0.19和0.22,ROC曲线围成的面积分别提升了0.007、0.011和0.017,PR曲线围成的面积提升了0.034、0.051和0.068,说明这3种改进方式层层递进,显示出这些改进的有效性。

表5 算法改进对比
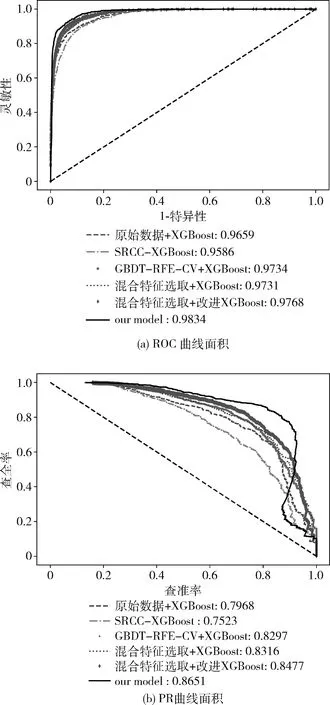
图7 改进对比的ROC曲线和PR曲线
2.3.2 不同模型性能对比
表6展示了改进目标函数后的XGBoost模型和其它机器学习算法的对比。为了对比本文模型的有效性,在航空着陆异常数据集上通过相同的混合特征提取,选用经典的5组机器学习算法作为对比实验,这些算法及改进算法已经在航空数据异常检测中初步应用,分别是K最近邻[20](K-nearest neighbor,KNN)、决策树(decision tree,DT)、随机森林[6](random forest,RF)、多层感知机(multilayer perceptron,MLP)和逻辑回归[3](logistic regression,LR)算法。对比算法都是直接从sklearn库[21]中直接调用,本文的模型是在原始XGBoost库的基础上自定义目标函数后经过贝叶斯超参数调节得到。从中可以看出KNN、MLP、LR这些算法的Recall、F1分数很低,说明这些算法不能很好检测出全部的异常。再对比几种树模型,可以看出单一树来做异常检测的决策树算法在查准率和查全率都比不上基于Bagging模型的随机森林算法和基于Boosting模型的XGBoost算法,说明单一的决策树算法在航空数据异常检测上效果并不好。此外还可以看出基于Bagging方式的随机森林算法能大幅提升检测效果,但是相对比于基于Boosting方式的XGBoost算法,随机算法除了查全率之外其它指标都比XGBoost要差。表6中也可以看出本文提出的模型异常检测性能均优于其它算法。
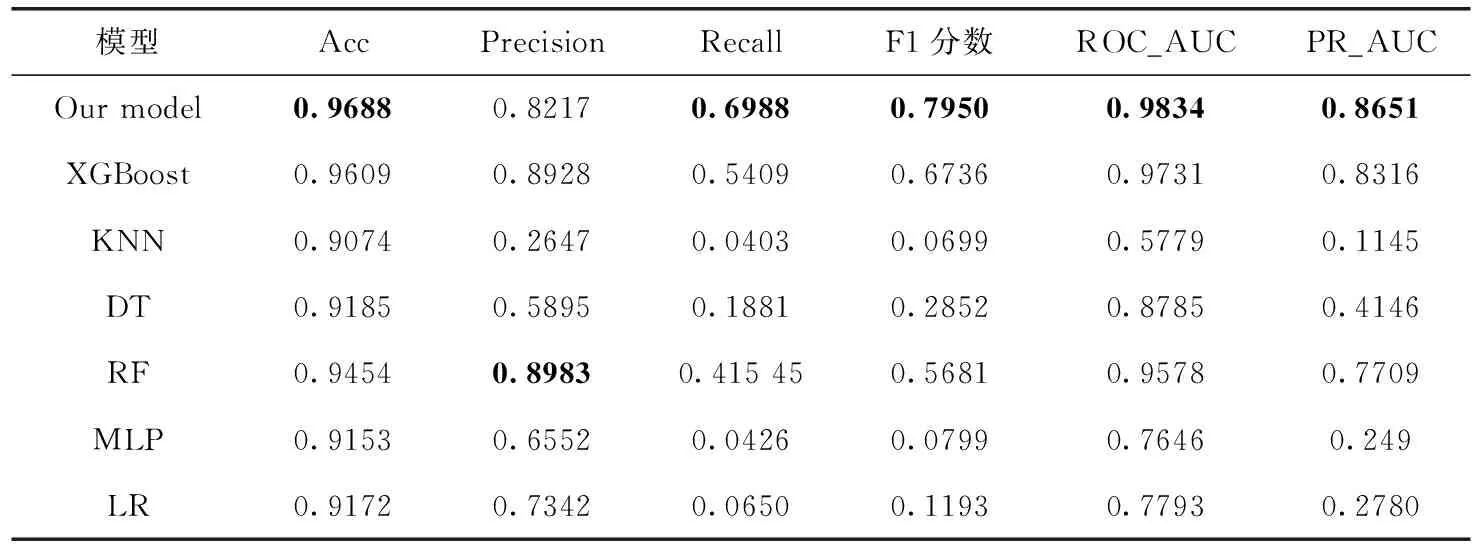
表6 不同模型性能对比
3 结束语
本文提出了一种基于机器学习的航空着陆异常事件检测模型。相比于民航业常用在单维数据中使用阈值分析的方法,本文通过提取多维数据的特征,使用机器学习模型从航空数据中检测异常。本文方法包括数据预处理、删除冗余特征、提取关键特征、改进XGBoost模型的目标函数、超参数优化、建模评估一系列过程。实验使用了数据匹配得到异常标签从而统一的评估各算法模型性能。经过实验对比可以看出,本文提出了混合特征选取的方法对于航空高维数据是有效且必要的,节省了特征提取的时间。在异常检测模型评估中,本文引入代价敏感学习函数和聚焦损失函数来改进XGBoost目标函数,并通过贝叶斯参数优化XGBoost模型,实验结果表明,本文模型能够有效的检测出航空异常着陆事件。然而本文的工作仍存在一些不足,本文的工作仅仅是检测异常,而从数据中发现可能导致异常的因素,从而挖掘出更有价值的信息是下一步的工作。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
趣味(作文与阅读)(2021年11期)2021-03-09 06:37:12
趣味(语文)(2021年11期)2021-03-09 03:11:36
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
数理化解题研究(2017年4期)2017-05-04 04:07:54
数学学习与研究(2017年3期)2017-03-09 18:12:42
铁道通信信号(2016年6期)2016-06-01 12:10:20
中国老区建设(2016年1期)2016-02-28 09:32:00
电子器件(2015年5期)2015-12-29 08:43:15
IT时代周刊(2015年7期)2015-11-11 05:49:55
