
基于聚类分析算法的思政课程实效性量化评估建模分析
2022-07-21 02:57:54张哲
自动化技术与应用 2022年6期
张哲
(肇庆医学高等专科学校 思政部,广东 肇庆 526020)
1 引言
当前,现有的教学课程评估方法的内存量不足,导致其在面对巨大的任务量时无法进行实效性量化分析[1],因此,在大数据分析及信息处理等技术的完善下,各类自动化评估模型被广泛应用到教学以及其他资源评估领域中[2],在一定程度上提高了各类评估的效率[3]。针对教学课程评估方面已有相关研究。
徐青等人结合MOOC 课程特点,运用网络分析法和矩阵实验室法设计了MOOC 课程自动化评估模型,评价指标有:教学设计,课程内容,教学服务,视频质量,学习效果与教学考评。最后通过实例分析验证了模型的有效性与可行性[4]。周凯等人提出了基于多元化的课程自动化评估模型。根据课程的创新度,实践度等指标构建课程评估模型,获取每位学生从各个方面进行评估的原始数据,对其进行预处理后,建立修正理想点数学模型,获得课程的综合评估数据。实例分析了该方法构建的可行性与合理性[5]。Kelley等人通过Kotter变更模型实现了对教学系统的自动化评估,描述了大学学生的教学自动化评估系统中如何使用Kotter模型作为指导。该模型涉及了仪器和技术的转变,并且在复杂且不断变化的环境中可涉及数十个指标变量[6]。案例实验说明了Kotter 模型有助于在高等教育机构中对各种计划进行变革。但以上模型针对分类类型数据的自动化评估效果不佳,导致其实用性不足。
为此,提出了基于聚类分析法的思政课程自动评估模型,通过聚类分析中的直接法标准化处理评价指标,将标准化评价指标数据进行聚类融合分析,通过公因子分析方法,得出最优自动化评估模型,从而提高思政课程自动化模型的评估能力。
2 思政课程自动化评估模型
2.1 指标数据标准化处理
在约束性指标体系中,主要一级指标有五个,二级指标在三级指标项目中进一步得到改进和完善。思政课程自动化评估约束指标的详细构成如表1所示。
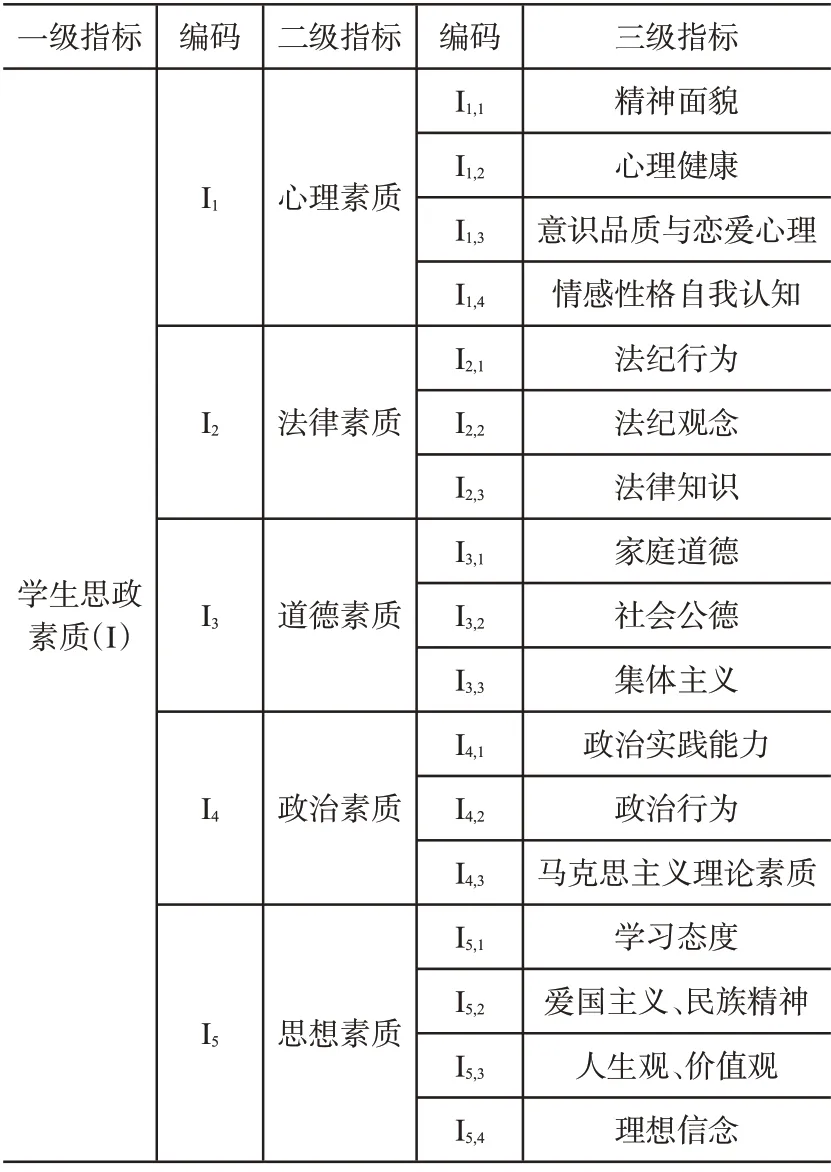
表1 思政课程自动化评估约束性指标
为构建课程自动评估模型,实现课程自动化评估,将表1中所得的评价指标进行分类并量化为约束指标数据,进行约束指标数据分析。指标量化的过程为:设第一级的约束指标数据设定为思政课程的时效性I,该级别约束指标数据共有i个,即Ii,由该i个指标分别生成n个二级约束指标数据。表示为:

对约束性指标数据进行相关性检验分析,得出指标数据间相关系数表示为:

式(2)中,cov(i,n)代表两个指标数据间的协方差。若r大于显著性水平(r>p),则对其进行偏方差检验,考虑指标中是否存在其他干扰因素,对两个数据间的净相关性进行检验。偏方差系数表示为:

系数的正负号可反映指标值与目标值之间方向的变化,表明其变化趋势是否呈一致性。相关系数的绝对性则反映了相关性的强度。符合两项标准化检验的指标数据被用于聚类算法中,进行预处理。
2.2 课程评估指标的实效性聚类融合处理
由于评估问题的观点不同,不同类别的人在确定指标权重时会有不同的想法。给定的索引权重通常差别较大[8]。因此,采用模糊C均值聚类法算法[7],对量化后的指标数据进行动态聚类融合预处理,以构建具有实效性的课程自动化评价模型。
在决策过程中,聚类分析算法具有操作方便,简单直观,易于理解的优点,被广泛应用于不确定性多属性策略和类别型指标评估领域的模型构建中[8]。因此,根据动态聚类分析,对思政课自动评价指标数据进行标准化处理,具体表达式:

式(4)中,Ki,n为自动评价指标聚核数目,c为自动评价指标初始凝聚点。根据组重心分析法得出思政课自动评价目标模糊动态方程,具体的表达式为:

式(5)中,k为聚类中心值。通过计算评估数据与聚类中心之间的距离确定目标函数:

式(6)中,η为课程自动化模糊综合评值。对所得数据信息进行聚类和整合后,得到自动化评估数据融合聚类表达式为:
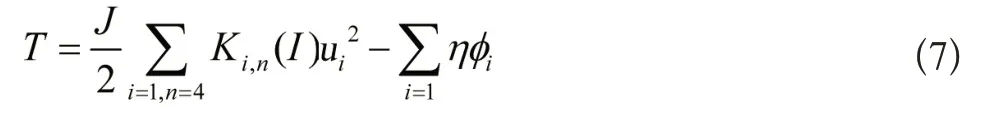
式(7)中,φi为第i个最优方案模糊综合评判值。根据自动化评估数据融合方法,输出融合数据信息表达为:

至此,完成了指标数据聚类和整合,在此基础上进行课程自动评估模型构建,从而实现思政课程自动化评估模型的优化,提高评估的准确性和效率。
2.3 课程自动化评估模型构建
为实现思政课程的自动评估,基于最优方案模糊综合评判值得到的聚类分析结果构建思政课程时效性的自动评估模型[14]。该评估模型可有助于教学自动化评估过程中定量数据管理和规划能力的提高,由于思政课自动化评估过程中,对其产生影响的指标较多,需将课程自动化评价指标转化为约束指标估计式,在此基础上可完成约束课程水平的参量模型的构建,进而获得课程自动化分析模型。课程自动化评估的估计式转化为求最小二乘解如式(9)。

由f(t)表示评估大数据分布时间点。利用公式(10)计算思政课程自动化评估的综合模糊幅度:

其中,w为自动化评估动态模糊权重值。评价指标分布的相似度的求解则通过使用模糊贴近度填充方法,具体表达式如式(11):


式(12)中,为评估的先验分布概率,通过线性特征融合方法实现对思政课评估指标分布概率均值的融合,获取具体表达式如式(13):

式(13)中,为思政课自动化评估的决策阈值,bi为第i个评估指标的自适应初始步长,t为评估时刻,m为特征分布的关联系数。根据公因子分析方法,得出最优自动化评估模型为:
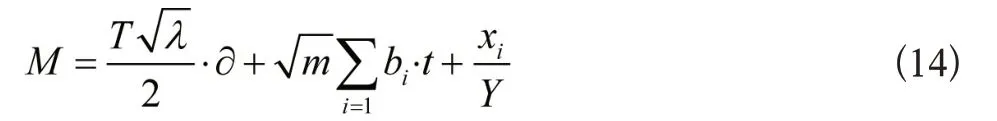
综上所述,基于思政课自动化评估数据,通过聚合思政课程自动化评估数值,实现了思政课程自动评估数据融合聚类,通过公因子分析法计算子序列的因子得分系数,得出最优模型,完成了思政课程自动化评估数据模型的构建,实现了思政课自动化评估。
3 仿真实验及结果
为了验证基于聚类分析算法的思政课程实效性量化评估建模分析的有效性,以某一个高校的思政课程为例,在学校各个专业和年级的所有学生中,随机选取200 名学生,利用思政课程自动化评估模型,评估该学校思政课程时效性,并与基于DEMATEL-ANP方法、多元化方法的评估结果进行对比,从而验证基于聚类分析算法的思政课程实效性量化评估建模分析是否有效,经过统计分析处理之后,得到思政课程自动化评估模型准确度测试结果,如图1所示。
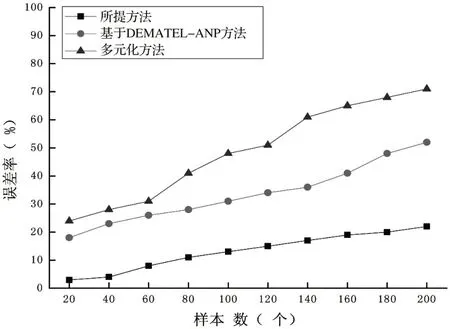
图1 思政课程自动化评估准确度测试结果
图1 中的数据显示,三种方法中,所提方法的误差率最低,控制在30%以下,其次是基于DEMATEL-ANP方法,误差率在60%以下,准确度最差的为多元化方法,其误差率在60%以上。
通过比较所提方法与基于DEMATEL-ANP方法、多元化方法的评估结果得到思政课程自动化评估效率测试结果如图2所示。
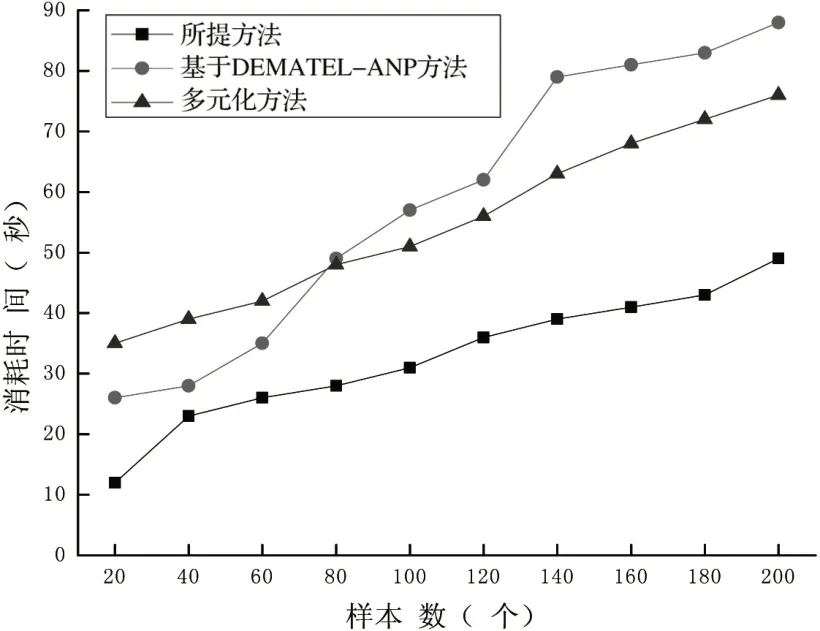
图2 思政课程自动化评估耗时测试结果
图2中的数据显示,在三种方法中,与基于DEMATELANP、多元化方法相比,所提方法进行课程的自动化评估时所消耗的时间最低,根据以上结果可以看出,基于聚类分析算法的思政课程自动化评估模型中进行课程评估时准确度较高,耗时较低,因此在思政课程的日常教学评估过程中,应注重使用该方法。
4 结束语
本文提出了基于聚类分析算法的思政课程实效性量化评估建模分析,基于思政课程时效性量化评估理论内涵,构建了思政课程时效性评估指标体系,并将评估指标体系进行标准化处理,通过聚类分析方法对数据进行融合分析,确定了思政课程自动化评估指标的融合信息,最后结合思政课程自动化评估模型设计,实现了思政课程时效性的量化评估。实例分析显示,提出的量化评估方法具有一定的科学性,与学生给出的语言评估相一致。但该研究中还存在一定不足,后续研究可以通过对指标体系量化方法进行创新研究,提高数据的准确性。
猜你喜欢
当代陕西(2022年4期)2022-04-19 12:08:52
甘肃教育(2021年12期)2021-11-02 06:29:38
活力(2021年6期)2021-08-05 07:24:10
人大建设(2019年8期)2019-12-27 09:05:28
当代陕西(2019年15期)2019-09-02 01:51:54
当代陕西(2019年9期)2019-05-20 09:47:22
电子测试(2017年15期)2017-12-18 07:19:27
文学教育(2016年33期)2016-08-22 12:59:02
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
