
OpenVX特征抽取函数在可编程并行架构的实现
2022-07-21 03:23张好聪邢立冬潘风蕊
计算机与生活 2022年7期
张好聪,李 涛,邢立冬,潘风蕊
1.西安邮电大学 电子工程学院,西安710121
2.西安邮电大学 计算机学院,西安710121
Khronos Groups 2019 年发布的“The OpenVXSpecification 1.3”,是计算机视觉算法和机器智能加速跨平台规范的最新版本,支持各种现代硬件体系结构,如移动系统、嵌入式SOC 系统和桌面系统。视觉系统内层次结构通常是复杂并且不一致的,OpenVX 旨在最大程度地跨不同的硬件平台实现功能和性能的可移植性,从而提供一种标准化的、对应用程序影响最小的计算机视觉框架,便于硬件厂商选择不同的方式实现硬件加速。这使得高性能处理器和显卡制造商AMD、GPU的发明者和人工智能计算的引领者NVIDIA、全球最大的CPU制造商Intel等越来越多的公司采用OpenVX开源规范。
在信息时代,计算机视觉扮演着非常重要的角色,将越来越广泛地进入各个领域,均需要对图像进行高速处理,并行计算相比串行计算有更快的求解问题的速度,可以缩短计算时间。并行性主要通过三种方式应用于计算机视觉处理:(1)数据并行;(2)任务并行;(3)流水线并行。
结合以上两方面,本文提出了一种具有并行处理能力的专用指令集处理器(application specific instruction set processor,ASIP),对OpenVX 规范1.3中58 个核函数分别构建图执行模型,并映射到该架构上,通过微程序优化其计算流程,实现最终的硬件加速。结果表明,该架构可以随着处理元件的数量实现线性加速。
1 OpenVX并行处理器架构介绍
1.1 互联网络结构的提出
PE(processing element)间的互联网络拓扑结构是并行处理系统的重要组成部分,由文献[6]得出,如图1 所示的分层交叉连接网络(hierarchically crossconnected mesh,HCCM)在各方面性能均优于经典的2DMesh拓扑结构和以2DMesh为基础扩展的Xmesh。
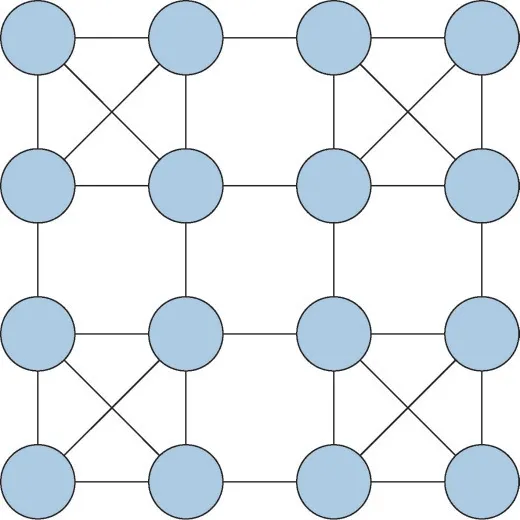
图1 HCCM拓扑结构Fig. 1 HCCM topology
因此本文基于HCCM 结构,提出了HCCM-和HCCM+结构,如图2 所示。对比表1 中这三种结构的参数,其中直径(diameter)指任意两结点之间最短路径中路径长度的最大值,直径越短,通信时间越短,速度越快,对分宽度(bisection bandwidth)指将拓扑结构中所有结点分成数量相等的两部分需要的最小链路数量,为拓扑结构的级数。HCCM-虽比HCCM 的直径短,但其等分宽度仅为4,这限制了整个系统的通信容量,同时HCCM-的边也比HCCM少,意味着其承载数据流量的能力更小。而HCCM+结构结合了HCCM 与HCCM-的优点,其直径小于HCCM,对分宽度和边数也大于HCCM 和HCCM-,在通信速度、容量和承载数据能力等方面都有更多的优势,因此选择HCCM+结构作为处理器的框架。

图2 HCCM-和HCCM+拓扑网络Fig. 2 HCCM-and HCCM+topology
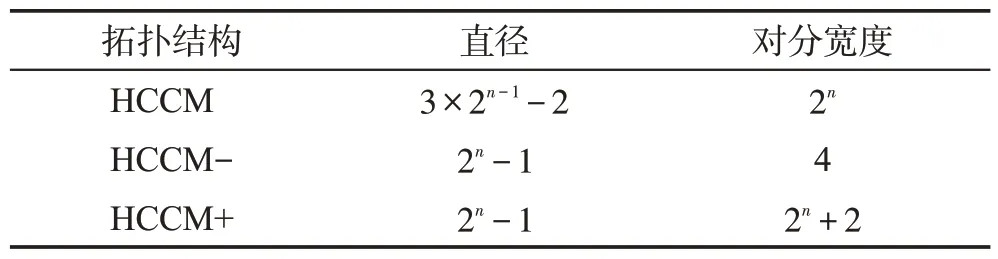
表1 HCCM、HCCM-与HCCM+的参数Table 1 Parameters of HCCM,HCCM-and HCCM+
1.2 OpenVX并行处理器架构
图3为自主设计的16个PE互联构成的OpenVX可编程并行处理器,主要由微程序控制器(micro controller)、PE、路由交叉开关(route)、共享存储及访存控制电路(memory access control)构成。

图3 OpenVX可编程并行处理器Fig. 3 OpenVX programmable parallel processor
微程序控制器是各种操作的底层支撑部件,通过PE对应的寄存器向每个PE发送操作控制、取址控制、条件控制、转移类型、下地址等指令,控制PE内部寄存器堆(register file)的取数地址、数据类型选择模块(data type selection)的取数方式、交叉电路(cross circuit)的走向以及PE内部运算单元的运算模式。也通过Route 控制PE 间数据的多通道传输。Route 是在XY 路由只有两个方向通讯的基础上,增加了PE之间对角线上的数据通路,支持一对一和一对多的传输方式,可以满足OpenVX核函数多种类型的数据传输。
PE 间的缓冲由位宽32 bit、深度64 的存储实现,具体通信方式由路由交叉开关根据OpenVX 核函数的需要控制。PE 结构如图4,包括寄存器堆、译码电路(decode)、数据类型选择电路、若干个ALU(arithmetic and logic unit)、除法器(DIV)、乘法器(MUL)、内部交叉电路、输出选择电路等。ALU 可以实现ADD(加)、SUB(减)、AND(与)、OR(或)、XOR(异或)、SLL(逻辑左移)、SRL(逻辑右移)和SRA(算术右移),内部包括多路选择器和操作控制码。乘法器和除法器均支持定浮点数据的运算。
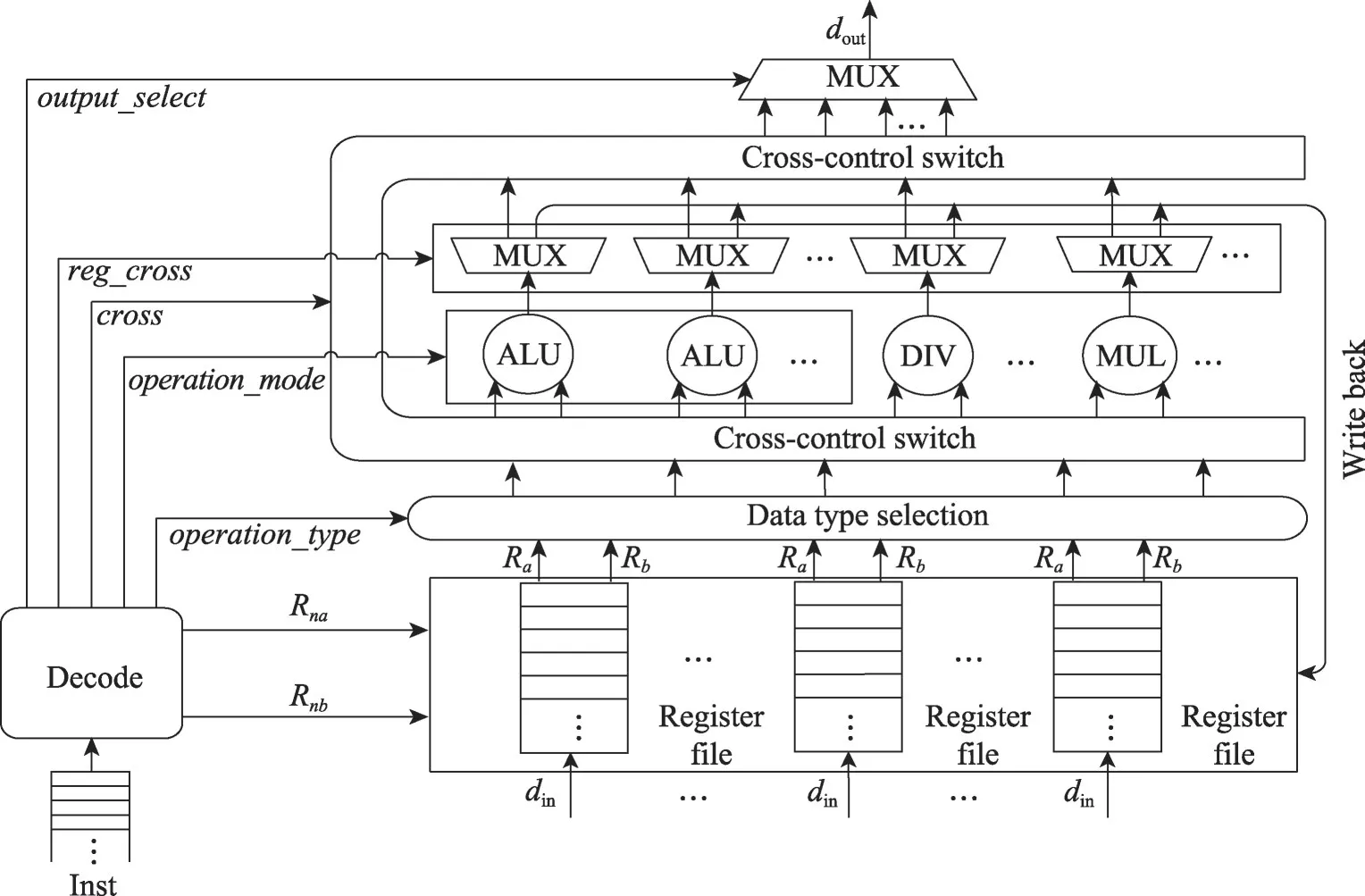
图4 PE结构Fig. 4 Structure of PE
PE内部交叉电路主要由多个57选1的选择器构成,根据微程序控制器发送的指令控制多个数据的走向。其输入包括数据类型选择模块和各个运算单元的输出,即每个处理器既可以对图像原始数据进行计算,其计算结果也可以返回处理器继续执行后续操作。
寄存器堆通过识别微程序控制器发送的取址指令,取出运算单元需要的原始数据。数据类型选择模块接收到数据和取数类型指令后执行相应截位操作,向交叉电路对应的端口写入数据,每次执行操作前,交叉电路会根据条件控制信号选择两个操作数送入运算单元。除了操作数,每个ALU 还有一个指令输入端口,用来接收经过微程序控制器优化后的一系列操作控制指令,快速完成OpenVX 核函数的并行计算。根据核函数的不同,每个运算单元的输出有写入寄存器堆或送入交叉电路两种选择。整个PE 计算任务完成后由选择输出电路选择当前PE 的输出。
访存控制电路采用突发读写的方式,通过AXI总线访问DDR,根据图像的处理方式,输出对应的数据格式。图像处理通常在以下级别完成:
(1)低级图像处理:像素级操作。
(2)中级图像处理:对图像像素导出的抽象进行操作。
(3)高级图像处理:从中级图像处理操作中提取抽象内容,目的是生成更高层次的抽象。
OpenVX核函数均属于低级图像处理,可分为点处理、局部邻域处理、递归邻域处理和全局处理。访存控制电路通过指令判断图像处理类别,选择最优取数方式送入寄存器堆。
该并行处理器是为OpenVX 核函数设计的通用处理器,适用于所有OpenVX 核函数,支持单指令多数据(single instruction multiple data,SIMD)和多指令多数据(multiple instructions stream multiple data stream,MIMD)两种编程模式,可以实现数据并行、任务并行、流水线的计算模式。SIMD模式下,16个PE执行微程序控制器发出的同一条操作指令,节省了代码存储;MIMD模式下,微程序控制器发送指令序列,多个PE可以同时完成不同核函数的操作。
2 OpenVX的图执行模型及函数简介
2.1 OpenVX的图执行模型
OpenVX 主要由一个预先定义的包含58 个视觉函数的计算机视觉核函数库、基于图的执行模型和一组物理内存的抽象内存对象组成。其中的视觉函数既可以对两幅图像做算数和逻辑运算,如将两幅图像对应位置的像素加、减、与、或等,也可以对一幅图像进行卷积、颜色转换、仿射变换、滤波、缩放、通道提取/合并、形态学操作、直方图均衡化和特征抽取等,满足多样化的计算机视觉需求。根据不同的计算机视觉应用,选择一个核函数或将多个核函数组合,抽象为不同的有向无环图(directed acyclic graph),也称图执行模型(graph execution model),进而将输入图像转换为具有预期特性的另一幅图像。图5为一个对图像进行缩放(scale image)的图执行模型示例,这些有向无环图的结点(node)即为OpenVX核函数,相邻结点间存在数据依赖关系。图5 中,输入的彩色图像数据经过Node1(颜色转换)转换为灰度图像,此结果经Node2(双边滤波)对图像进行平滑处理,得到的平滑图像最终通过Node3(图像缩放)得到结果图像输出。OpenVX 通过对其预定义的核函数加速,实现整个硬件算法的加速。
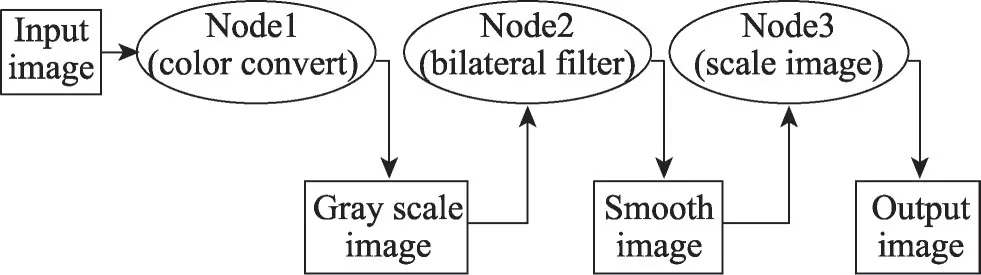
图5 图执行模型示例Fig. 5 Example of graph execution model
2.2 OpenVX核函数简介
通过对OpenVX 规范1.3 的研究,对规范中提到的58 个核函数构建各自的图执行模型,并映射在OpenVX 并行处理器上完成硬件结构上的并行加速。选取其中Harris Corners 和Canny Edge Detector两个底层特征抽取函数详细介绍其并行实现过程,因算法比较复杂,通过将其优化为几个简单结点进行加速。以下为构成其图执行模型的核函数。
(1)Color Convert。将图像从一种颜色空间转换为另一种颜色空间,如彩色转灰度的公式为:

(2)Control Flow。可以完成图像多种数据格式的逻辑运算(与、或、异或、与非)、比较大小(等于、小于、小于等于、大于、大于等于)和算术运算(加、减、乘、除、取余、最大/最小值)。
此函数几乎包含所有基本操作,这使其成为图执行模型中利用率最高的结点。如Canny 边缘检测中通过比较、两个方向的梯度值与给定值的大小判断梯度方向,计算Sobel 算子结果的乘积等,均可用Control Flow实现。
(3)Gaussian Filter。对整幅图像进行加权平均的过程。用一个掩膜扫描图像中的每一个像素,用掩膜确定的邻域内像素的加权平均灰度值去替代模板中心像素点的值。用到的掩膜为:
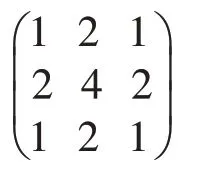
(4)Median Filter。一种线性滤波算法,目标像素本身与其周围的8个像素构成一个3×3的滤波模板,求取模板内9个像素的均值代替目标像素。
(5)Non-Maxima Suppression。一种边缘稀疏技术,在局部区域内保留最大值的像素,抑制非最大值的像素。如3×3区域的抑制条件为:
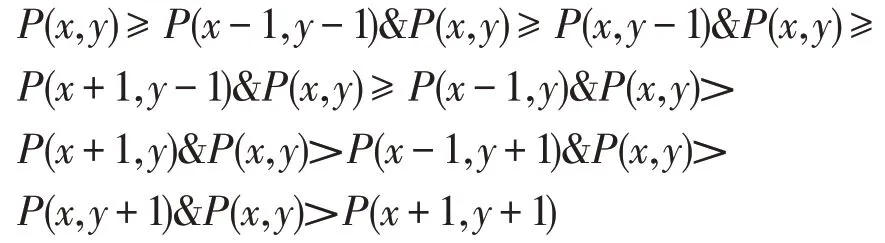
(6)Sobel 3×3。用不同的卷积核与原灰度图像进行卷积,求取像素、方向的梯度幅值。、方向卷积核分别为:

(7)Thresholding:将输入图像与阈值相比,产生一幅二值图像。
2.3 部分核函数在硬件平台的改进和具体实现
上述函数中的Gaussian Filter、Median Filter、Non-Maxima Suppression、Sobel 3×3都是对图像像素级的局部处理,即输出像素值由输入像素及其邻域像素值决定。以3×3模板为例,处理过程中需要同时得到图像窗口内的9 个像素,文献[13]中调用了2 个FIFO 行缓存(与Xilinx 的Shift IP 核,即行缓存IP 核同义)完成2 个行缓存,加上当前行得到3 行图像数据,将这3 行数据分别打2 拍得到一个窗口9 个像素数据,其原理如图6所示。这也是大多数FPGA进行图像处理使用的典型方法。若待处理图像大小为×,得到第一个×的矩阵需要(+1)×(-1)个时钟,则此方法在640×480 的图像中得到第一个3×3矩阵需要1 280个时钟。

图6 Xilinx Shift IP核原理Fig. 6 Principle of Shift IP core of Xilinx
本结构的访存控制电路在读取3×3 模板的数据时,采用突发读写的方式,通过三条通路分别访问存储的地址端,每条通路对应一行数据在存储中的地址,取出的3 行数据分别发送至PE 内部3 个寄存器堆,微程序控制器根据核函数操作的速度控制访存控制电路何时向寄存器堆送数。此方法可以在3 个时钟内读出9个像素数据,很大程度上为图像的流水线处理节省了时间。
Median Filter需要得到3×3滤波窗口内像素的中值,传统做法是依次比较9 个像素大小,效率较低。本文提出一种优化后的算法:如图7,分别比较窗口内三行数并由大到小排序,则第一列为每行最大值,第二、三列分别为每行的中值和最小值。取第一列的最小值、第二列的中间值、第三列的最大值进行比较,中间值则为当前窗口中值。这种任务并行的算法减少了比较次数,提高了处理速度。
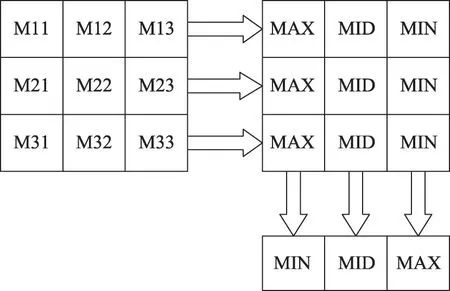
图7 优化后的Median FilterFig. 7 Optimized Median Filter
以函数Gaussian Filter 为例,如图8,将待处理图像当前矩阵内的像素标号。其在PE内部的映射方式如图9 所示,其中A11、A13、A31、A33 对应的掩膜系数为1,因此直接两两相加。A12、A21、A23、A32 和A22对应的系数为2和2,由于对FPGA来说,移位操作是0 开销(不消耗时钟周期),且本设计的ALU 将加法和移位合并,因此在微程序控制器配置此操作指令时,只需考虑将寄存器堆中的图像数据和译码单元的立即数送入第一级ALU,单独的移位操作不再消耗时钟。前一级的结果作为下一级ALU的输入继续完成滤波操作。
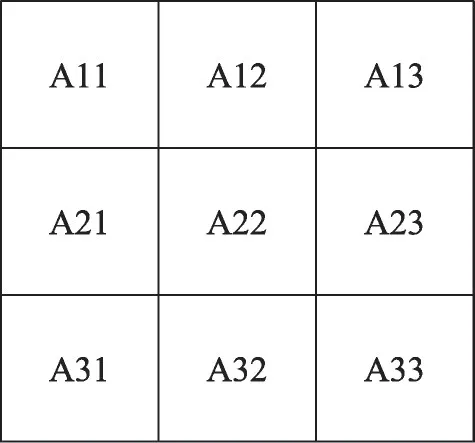
图8 当前矩阵像素标号Fig. 8 Label of current matrix pixel

图9 Gaussian Filter在PE内的映射Fig. 9 Mapping of Gaussian Filter in PE
3 算法的并行设计和映射
在图形硬件系统中,有两种主要的方法来进行快速处理,分别是流水线和并行化,通常需要将两者结合使用才能达到较好的效果。本章介绍两个核函数图执行模型的设计及映射结构。
3.1 Canny Edge Detector的并行设计
文献[16]提出,对于同一个流水线处理结构,在一定范围内图像分块越多,每块图像的像素总数越少,所需的处理时间则越短。本文综合处理器的资源与文献[16]的结论,将图像分为四块并行处理,每块均进行流水线操作。坎尼边缘检测旨在通过像素梯度方向检测出图像边缘,属于局部邻域处理,分块易导致其分界处出现伪角点。因此对边界采用边界复制法,使分界处存在重叠部分(1 行/1 列像素)。将Canny Edge Detector 算法的每一步映射为一个简单核函数,图10 为优化后Canny Edge Detector 核函数的图执行模型,具体步骤如下(括号内为映射的核函数):
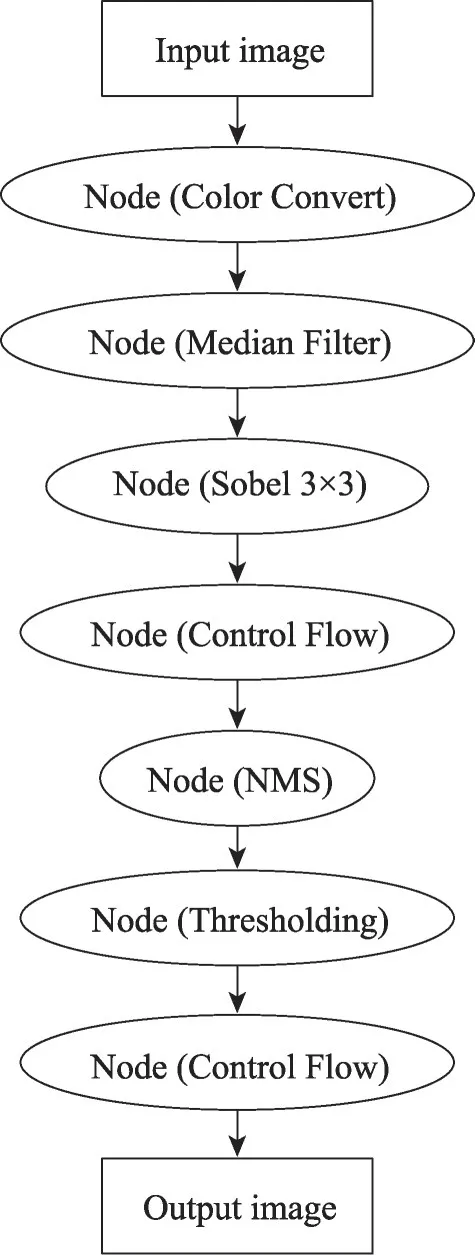
图10 优化的Canny Edge Detector图执行模型Fig. 10 Optimized Canny Edge Detector graph execution model
(1)将彩色图像转换为灰度图像(Color Convert)。
(2)对灰度图像进行滤波处理(Median Filter)。
(3)利用Sobel 算子判断图像像素、方向的梯度正负性,并计算出其绝对值|G|、|G|和对应的梯度幅值=|G|+|G|(Sobel 3×3)。
(4)如图11,将360°的梯度方向划分为四个空间。原算法使用=arctan(G/G) 判断梯度方向,OpenVX中没有直接实现反三角函数的核函数,本文总结出近似方法判断梯度方向(Control Flow):
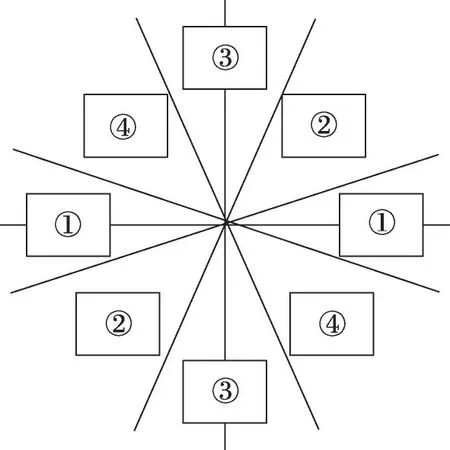
图11 梯度方向划分Fig. 11 Gradient direction division
第①区域:比较G与G绝对值,符合G>G×2.5。
第③区域:比较G与G绝对值,符合G>G×2.5。
第②区域:不在①、③区域,G与G同号。
第④区域:不在①、③区域,G与G异号。
(5)将梯度方向与梯度幅值合成一幅图像信息,以3×3为模板,若中心像素比其梯度方向上两个像素的梯度幅值都大,则标记为真,否则标记为假(nonmaxima suppression)。
(6)用中心像素梯度幅值与设定的双阈值比较:
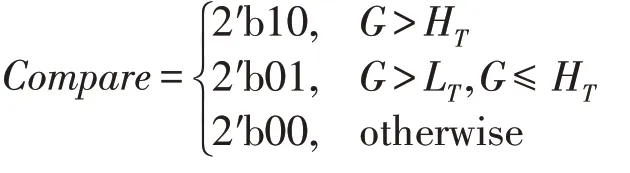
其中,H、L分别为高低阈值(Thresholding)。
(7)将像素真假及变量合成一个新的图像,像素为真时考察变量的值,像素为边缘点应满足为2′b10 或2′b01,同时在其八连通区域中存在像素的=2′b10(Control Flow)。
上述基于图的执行模型中,每一级结点都有各自的任务,并且可以在同一时刻共同操作,构成了连续的流水线操作,如图12所示。
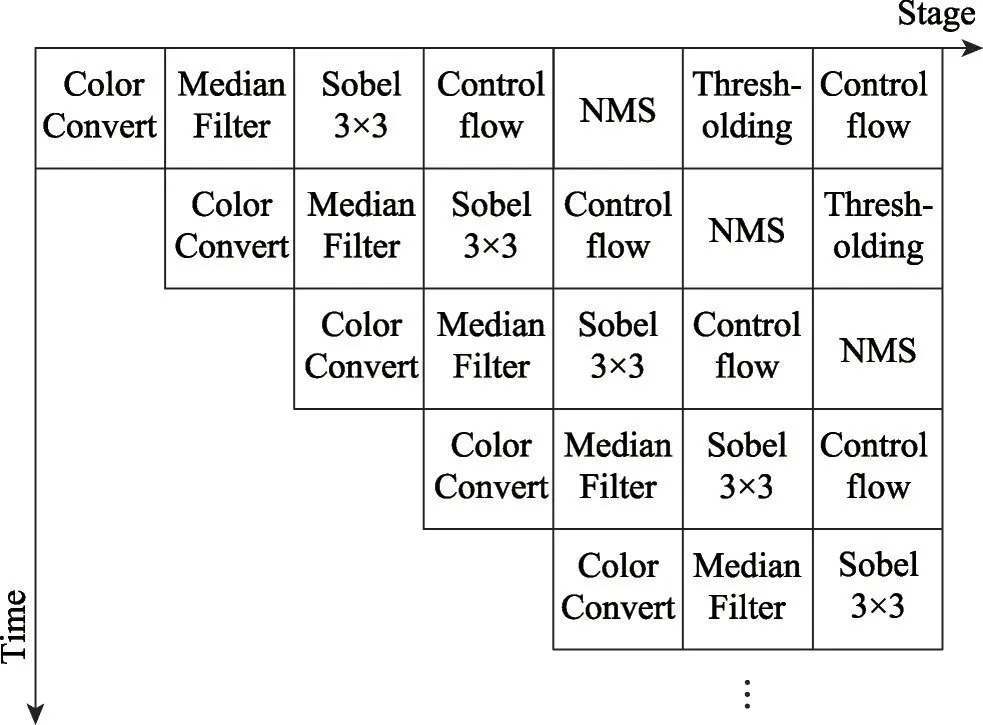
图12 Canny Edge Detector流水线设计Fig. 12 Canny Edge Detector pipeline design
图13 为Canny Edge Detector 映 射到OpenVX 并行处理器上的结构。在两个特征抽取函数的映射结构中Line1~Line4各自处理图像的1/4,共同完成底层特征抽取。当第四列结点同时执行完成之后,其结果返回第一列PE,完成完整的图执行模型。映射时用一条线路传输多路数据,将多个结点的工作分成多个时间段,各个工作的各个时间段交叉使用,充分利用了分时复用(time division multiplexing,TDM)的思想,提高了资源利用率。

图13 Canny Edge Detector映射结构Fig. 13 Canny Edge Detector mapping structure
3.2 Harris Corners的并行设计
Harris 角点检测的基本思想是使用一个固定窗口在图像上进行任意方向上的滑动,比较滑动前与滑动后两种情况,窗口中的像素灰度变化程度,如果存在任意方向上的滑动都有较大灰度变化,则认为该窗口中存在角点。图14为优化后的Harris Corners基于图的执行模型,具体步骤如下:

图14 优化的Harris Corners图执行模型Fig. 14 Optimized Harris Corners graph execution model
(1)将彩色图像转换为灰度图像(Color Convert)。
(2)计算出灰度图像每一个像素点方向、方向的梯度值I、I(Sobel 3×3)。
(3)计算I、I、II并缓存(Control Flow)。

(5)计算图像中每一个像素点的响应值(Control Flow):

(6)将值与给定阈值比较,大于阈值的标记为候选点,否则不标记(Thresholding)。
(7)对上述结果进行非极大值抑制,输出最终图像(non-maxima suppression)。
图14 中最左侧的结点Control Flow 得到方向梯度值I后,计算其平方值,经过高斯窗口计算局部累加和,得到得分值所需的系数。中间和右侧路径分别计算系数、,三条路径同时工作。Harris Corners的流水线设计如图15所示。
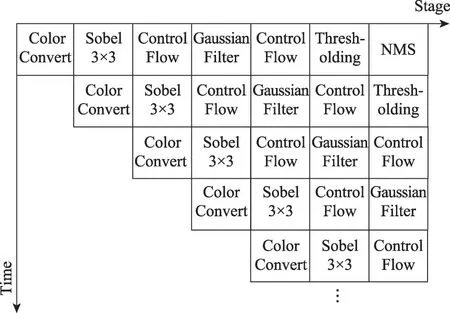
图15 Harris Corners流水线设计Fig. 15 Harris Corners pipeline design
图14 的Harris Corners 图执行模型中,同时计算梯度值乘积的3个结点Control Flow和同时计算得分值系数的3 个结点Gaussian Filter。分别被映射到2 个PE 上,如图16 所示,使得16 个PE 可以同时处理1/4的图像数据,每条处理路径都支持任务并行。

图16 Harris Corners映射结构Fig. 16 Harris Corners mapping structure
4 结果分析
为验证本结构对OpenVX 核函数的并行处理速度有所提升,使用Verilog 硬件描述语言,在Xilinx 公司的FPGA芯片xcvu440-flga-2892-2-e进行综合。用单个基本核函数映射在一个和多个PE 上的加速比、两个底层特征抽取函数串行与并行速度的对比来衡量本并行处理器的处理速度。图17为单个基本核函数映射在1 个和多个PE 上的加速比,计算时统一将映射在1个PE上的速度归一化。图18为底层特征抽取核函数拆分之前分别与拆分后串行和并行的加速比,将拆分之前用一个PE实现的速度归一化,分别计算2个、4个、8个和16个PE并行的加速比。

图17 OpenVX基本核函数并行加速比Fig. 17 Parallel speedup of OpenVX basic kernel functions
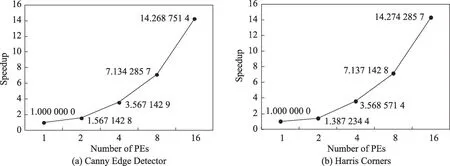
图18 OpenVX底层特征抽取函数加速比Fig. 18 Speedup of OpenVX underlying feature extraction functions
由图中数据可知,将复杂特征抽取核函数拆分为多个结点,并将每个核函数映射到4个PE上,即图像分为四块并行处理可以在OpenVX 并行处理器上获得最大的加速比。整个架构在Vivado 2020.1平台上综合后的资源利用率如图19所示。

图19 资源利用率Fig. 19 Resource utilization
如图20所示,(a)为仿真的原始灰度图像,(b)为Gaussian Filter核函数的运行结果,(c)、(d)为最终的特征抽取结果。

图20 原始灰度图及仿真结果Fig. 20 Original gray image and simulation results
5 结束语
本文介绍了一种用于OpenVX 加速的ASIP,并在硬件平台上实现了部分核函数。硬件最高工作频率可达125 MHz。这些实现以数据并行方法和流水线方法将OpenVX 1.3 核函数映射到ASIP 上。实验证明了本结构具有线性加速比。当图像分辨率为640×480 时,该结构的帧频率约为66 frame/s。本文提出的计算机视觉函数的处理方法,在相关应用领域可以大大节省图像处理时间,提高处理效率。例如,通过显微图像、血管造影图像或超声波图像检测肿瘤;在军事领域检测敌军士兵或车辆等,具有广阔的应用前景。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
集装箱化(2021年1期)2021-04-12
天津医科大学学报(2021年1期)2021-01-26
中国信息技术教育(2020年2期)2020-02-02
汽车零部件(2014年1期)2014-09-21
微型计算机(2009年17期)2009-05-19
电子设计应用(2004年7期)2004-09-02
