
基于核心专利技术主题识别与演化分析的技术预测*
2022-07-18 06:28王曰芬
情报杂志 2022年7期
杨 恒 王曰芬 张 露
(1.南京理工大学知识产权学院 南京 210094;2.天津师范大学管理学院 天津 300387 )
0 引 言
随着新一轮科技革命的到来,世界各国都在加紧通过技术预测把握先发优势,抢占科技创新制高点。科学高效的技术预测工作能够帮助国家和企业准确了解技术研究热点与技术发展脉络,跟踪世界主要国家及企业技术发展动态、预测技术未来发展趋势、尽快发现技术发展机会[1]。目前技术预测的方法主要分为基于专家智慧的定性预测法和基于数据驱动的定量预测法[2],两种方法的结合使用正在成为研究关注的方向。
专利文献作为技术创新能力的重要表现形式,蕴含着极大的经济价值及技术价值,是理想的技术挖掘的数据来源[3],然而随着专利文献数量的急剧增长,需要找到快速准确挖掘和分析技术的方法,而对大规模的专利文献进行数据集的有效缩减以及进行技术主题的识别与演化分析[4]将是有效且可行的方法。核心专利是一个产业/技术领域中具有重要技术价值及经济价值的专利,能够反映出相关领域研究的核心技术,从研究内容看,核心技术又是由一个个技术主题构成的。因此,识别出核心专利并进行技术主题分析,不仅可以对海量专利文献进行有效缩减,而且能够突出重点地跟踪与预测技术发展态势,提高技术跟踪与预测的效果和效率。
1 国内外研究现状
国内外已有研究中,对技术主题识别的研究方法主要分为两大种类:基于引用关系的技术主题识别方法、基于文本内容的技术主题识别方法[5]。基于文本内容的技术主题识别主要采用主题模型法,伴随着自然语言处理技术发展而出现的如 Word2Vec、LDA 等高效处理文本的模型,提高了文本语义处理的效果。目前的研究一般将核心专利识别与技术主题识别分开进行,从核心专利数据集中识别出技术主题并进行主题演化分析的相关研究还比较有限。相关研究已经表明:基于核心专利数据集对专利文献的文本数据进行相关术语抽取工作,与基于全数据集进行比较,其能够提高术语抽取的效率[6];同时,面对海量数据,在技术主题的识别上,基于核心专利数据集进行识别的结果能够覆盖基于全数据集进行识别的结果的绝大部分,且技术主题之间的区分度较高,有助于提高识别过程的效率和识别结果的准确性[7]。
因此,本文的创新点有两点:一是引入核心专利的概念,从行为效果和动机目的两个角度入手,考虑专利的影响和价值,全面选取核心专利识别指标和识别流程,采用客观赋权法对指标赋予权重,然后结合灰色关联分析法进行打分,确定核心专利。二是基于核心专利数据集而不是全数据集进行技术主题的识别与演化,并将定量分析结果与专家定性评价相结合对技术进行预测。
2 研究方案设计
2.1 研究框架
针对研究目的,本文以数据驱动思想为指导,遵循数据挖掘与分析的基本流程,提出面向技术预测的核心专利技术主题识别与演化分析的研究框架设计如图 1 所示(其中,虚线部分表示的是前期所做的研究,具体内容见文献[8],实线部分表示的是本文所做的研究及内容)。

图1 研究框架设计
a.数据获取与预处理。以德温特专利数据库为数据源,德温特专利数据库收录了全球50家专利机构的超过3 000万条专利信息,与Web of Science双向连接,从而将基础研究成果和技术应用成果联系起来,确保了数据的全面和可靠[9]。数据预处理工作主要包括去除重复项、数据筛选、分词、去除无关词语(包括3种类型:一是停用词,主要为一些没有明确含义的词,如数词、介词、冠词等;二是专利中出现的与技术无关的常用词如“where”“include”等;三是专利中独特的学术词汇如“analyze”“propose”等)、词性标注(抽取名词、动词以及形容词3种专利文本中的实词)等步骤。b.核心专利识别。构建核心专利识别指标体系,利用熵权法、灰色关联分析法等识别出核心专利,并进行分类。c.技术主题识别与演化分析。依据全局和局部结合的原则,利用LDA主题模型、Word2vec词向量模型两种模型进行技术主题的识别,并结合技术生命周期理论,从技术主题强度演化和技术主题内容演化两个方面进行技术主题的演化分析。d.技术预测。在得到基于定量分析方法的技术研究热点及发展趋势后,咨询该领域相关专家,借助专家智慧调整定量分析的结果,从而实现较为准确的技术预测。
2.2 研究方法
本文是在前期研究基础上进行的,因此,有关数据获取与预处理、核心专利识别的方法不再赘述,下面主要对技术主题识别与技术主题演化分析方法加以论述。
2.2.1技术主题识别方法
由于LDA主题模型未考虑词语与词语之间的关系,而Word2vec词向量模型关注词语之间的上下文顺序和关系,从语义方面对文本内容进行进一步理解。因此,本文在LDA主题模型的基础上,将词语之间的关系考虑进去。具体做法如下:首先利用Word2vec词向量对经过预处理后的专利文献的摘要、标题等文本内容进行训练,以此得到所有词语的词向量表示,并输出与特征词(经过预处理后的原始语料库)相似度较大的值(具体输出多少个根据实验需求设置),将其扩充至原始语料库中,这样就可得到新的特征词集合 {W1,W2,W3…Wi,Wi+1,…,Wi+n},其中,W1到Wi为经过预处理后的原始语料库中的词语,Wi+1到Wi+n为扩充的词语,两者结合构成新的语料库;然后利用LDA主题模型对新的语料库进行训练,以此获取技术主题。将Word2vec词向量模型以文本扩展的形式引入,可以更深层次地挖掘文本语义知识,提高技术主题识别的质量。主要思路流程如图2所示:

图2 技术主题识别的思路流程
2.2.2技术主题演化分析方法
本研究设计的技术主题演化分析方法包括技术主题强度演化和技术主题内容演化两种。
a.技术主题强度演化。
技术主题强度表达的是技术主题受关注的程度,某一时间段下相关技术的技术主题强度越大,则表示在该时间段中对于这些技术主题研究的热度越高,专利文献申请数量越多。对于技术主题强度演化的计算过程,首先需要识别出总数据集的技术主题,然后计算这些技术主题在技术生命周期中每一阶段的强度,最后分析其演化趋势。技术主题强度一般利用主题支持的文档数量来表征,表示技术主题对于当前时间段上文档的贡献程度,计算公式如公式(1)所示:
(1)
其中,St,k表示时间段t上第k个主题的主题强度,Pd,k为第d篇专利文献中第k个主题的概率,Dt为时间段t上的文档数量。
b.技术主题内容演化。
技术主题内容演化反映的是技术主题中主题词的变化,主要有技术主题新生、技术主题消亡、技术主题继承、技术主题分裂和技术主题融合5种演化类型。技术主题内容演化分析首先需要识别出技术生命周期上各时间段的技术主题,然后衡量相邻时间段上技术主题之间的关联关系。目前相似度计算方法中,余弦相似度算法应用较为广泛。余弦相似度用两个技术主题向量夹角的余弦值来衡量技术主题之间的关系,值越趋近于1,则表示两个技术主题越相似,值越趋近于0,则表示两个技术主题几乎没有相似性,计算方法如公式(2)所示。另外,还需根据实际设置相似度的阈值,若两个技术主题的相似度大于阈值,则技术主题之间存在关联关系;若两个技术主题的相似度小于阈值,则技术主题之间不存在关联关系。
(2)
其中,Tt、Tt+1为相邻时间段上的主题向量,即该主题中所有词语的概率分布所形成的主题向量。
3 实证分析
本文以人工智能领域为例,在前期数据获取与预处理、核心专利识别及技术生命周期划分的基础上,识别出201条核心专利[8],但201条核心专利的数据量过小,不适合进行技术主题的演化分析,因此本文进一步调整核心专利划分的阈值,将大于等于78%maxBi的专利划分为准核心专利(有较大可能性成为核心专利),最终获得3 262条准核心专利。根据技术生命周期理论,结合专利申请量变化、申请人数量变化、专利申请量增长率变化,可以将1985—2019年人工智能领域的技术发展划分为四个时间段[8],其中萌芽期(1985—1999年)有558条准核心专利,缓慢发展期(2000—2009年)有1 342条准核心专利,快速发展期阶段(2010—2014年)有922条准核心专利,腾飞期(2015—2019年)有440条准核心专利。另外,本文使用Python中的Ntlk工具包完成分词、去除无关词语、词性标注预处理工作。
3.1 技术主题识别
对准核心专利数据进行实际训练,对LDA主题模型和Word2vec词向量模型的一些参数设置如表1所示,其他相关参数保持默认值。
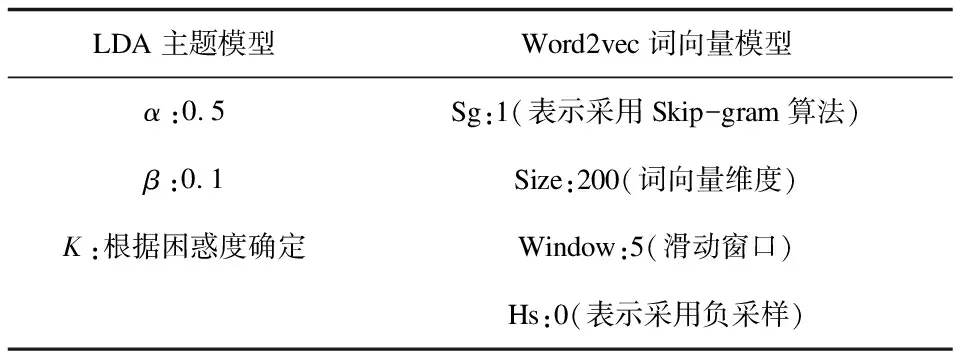
表1 LDA主题模型及Word2vec词向量模型的主要参数设置
首先利用Word2vec词向量模型对经过预处理后的原始语料进行训练,训练完成后,本文选择模型输出的与原始语料库中词语最相关的10个词语,并且词语之间的相似度大于0.7的词语,将其扩充至原始语料库中,以此得到新的语料库,然后基于LDA主题模型对新的语料库进行训练处理。LDA主题模型的训练需要确定主题个数K的值,这将直接影响对技术主题识别的效果,本文通过计算困惑度来获取K的值,一般来说,困惑度值越低,对应的技术主题个数最优,但困惑度值只能作为一个参考,具体情况还需考虑实验运行情况及主观需求。图3为主题个数在1~100时困惑度的变化曲线,曲线的跨度设置为5,从图中可以看到,在主题个数为0~10时,困惑度曲线呈现急速下降趋势;主题个数为10~26时,困惑度曲线呈现缓慢下降趋势;主题个数为26~100时,困惑度曲线呈现平稳、轻微波动状态。因此,本文综合考虑困惑度值和本研究的实际需求,将主题个数设置为26。

图3 不同主题个数下的困惑度曲线图
根据各个技术主题所包含的主题词对所识别出的26个技术主题进行命名,分别为智能搜索(Topic#1)、通信(Topic#2)、人机交互(Topic#3)、智能医疗(Topic#4)、智能汽车(Topic#5)、语音识别(Topic#6)、问答系统(Topic#7)、图像视频识别(Topic#8)、机器翻译(Topic#9)、数据存储(Topic#10)、知识表示(Topic#11)、图像处理(Topic#12)、神经网络(Topic#13)、虚拟现实(Topic#14)、自然语言处理(Topic#15)、信号处理(Topic#16)、算法模型(Topic#17)、计算机系统(Topic#18)、机器学习(Topic#19)、目标检测(Topic#20)、移动设备(Topic#21)、模式识别(Topic#22)、分析与挖掘(Topic#23)、过程控制(Topic#24)、生物特征识别(Topic#25)、智能金融(Topic#26),表2展示了所识别出的26个技术主题中的10个技术主题及主题词。

表2 技术主题识别结果(其中10个)
3.2 技术主题演化
3.2.1技术主题强度演化
由上已经得到基于准核心专利数据所识别出的26个技术主题,再根据技术主题强度计算公式(1),计算技术主题在技术生命周期中各个阶段的主题强度值,如表3所示。
根据表3可以绘制技术主题强度变化图谱,据此可以看出大部分技术主题的主题强度都呈现轻微波动的变化趋势,说明人工智能领域绝大多数的技术主题不是保持一成不变的状态,而是随着时间的发展,对相关技术的研究热度有所调整,从而顺应时代的发展趋势。另外,通信(T1)、语音识别(T15)、机器学习(T20)这三个技术主题的主题强度可以明显看出其上升的变化趋势,且技术主题强度都维持在较高的水平上,说明这三个技术主题作为人工智能领域重点关注的对象,相关技术的发展较为迅猛,由此产生了大量的相关专利;机器翻译(T7)技术主题的主题强度在前三个阶段中呈现较为平稳的变化趋势,在腾飞期主题强度迅速下降,说明该技术主题现阶段的研究热度在逐渐降低。
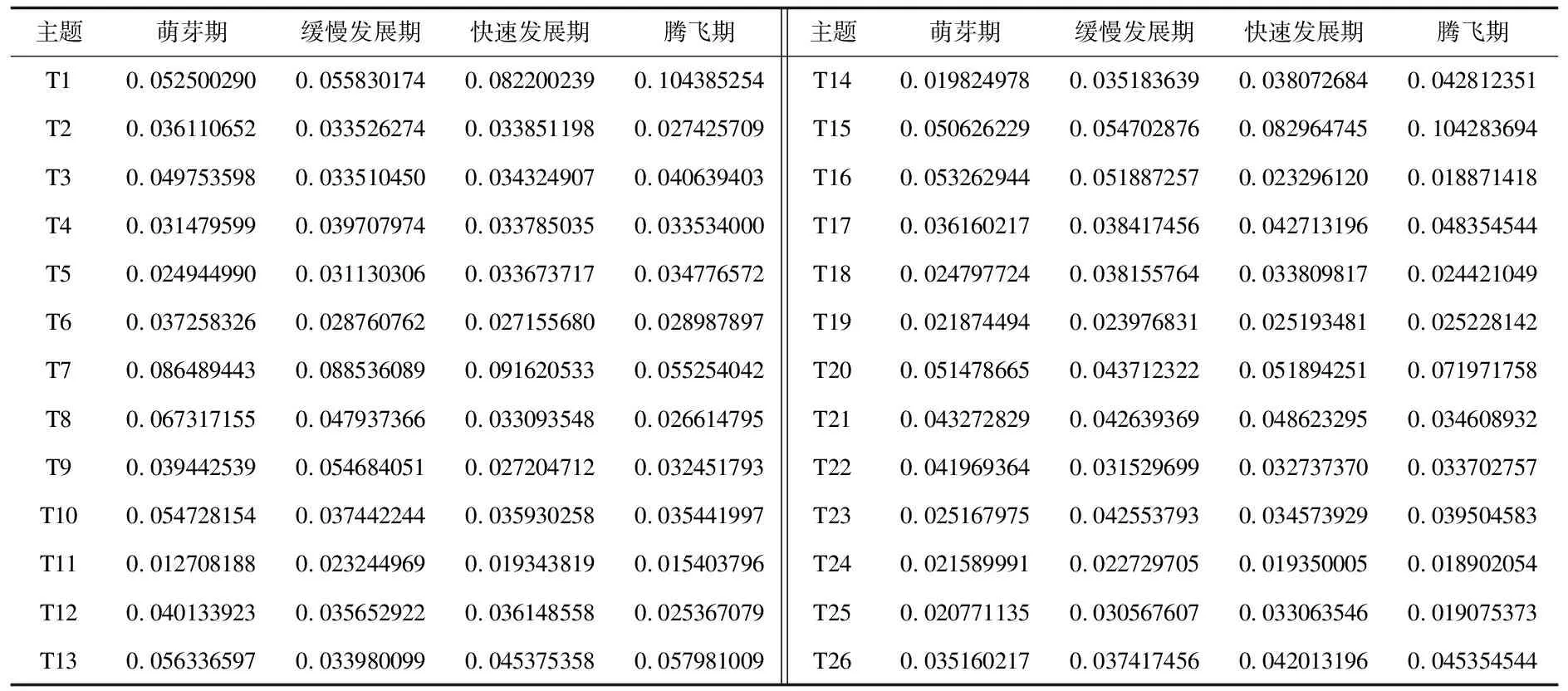
表3 技术主题各个阶段的主题强度值
3.2.2技术主题内容演化
首先,根据技术生命周期的划分,识别每一阶段的技术主题,结果如表4所示。

表4 技术生命周期各阶段的技术主题识别结果
然后,计算技术生命周期相邻时间段上技术主题之间的余弦相似度,根据人工智能领域技术主题之间相似度的计算结果,本研究设置相似度阈值为0.7,即技术主题之间的相似度大于0.7,则存在技术主题关联关系。将所得结果可视化展示,如图4所示。
从图4可以看出,大部分技术主题在技术生命周期多个阶段中都有出现,呈现继承、分裂或融合演化关系,如信号处理、传感器、自然语言处理、目标检测、语音识别、图像识别及处理、音视频处理、通信、机器学习、数据存储、问答系统等技术主题,这些技术主题一直是人工智能领域研究的重点内容,人工智能的快速发展离不开这些技术主题的有效研究。另外,有少部分技术主题仅在技术生命周期一个阶段或两个阶段中出现,如萌芽期的过程控制及文件系统两个技术主题在缓慢发展期阶段消亡;缓慢发展期新增了分析与挖掘、机器翻译、IT+金融及人机交互四个技术主题,同时分析与挖掘、专家系统这两个技术主题在快速发展期阶段消亡;快速发展期新增了大数据、智能汽车、云及机器人四个技术主题,同时机器翻译技术主题在腾飞期阶段消亡;腾飞期新增了生物特征识别技术主题。这表示随着人工智能的发展,各个阶段的技术主题基本保持不变,仅有少数技术主题会根据时代需要发生一定的变化,如目前智能汽车、机器人、生物特征识别等技术主题成为新兴热点,这也符合人工智能的发展现状。

图4 技术主题内容演化
3.3 技术预测
3.3.1基于定量的技术预测
通过上述对人工智能专利数据进行技术生命周期划分、核心专利识别、技术主题识别及演化等的定量分析后,可知目前人工智能的发展主要经过了四个阶段,分别为萌芽期(1985—1999年)、缓慢发展期(2000—2009年)、快速发展期(2010—2014年)以及腾飞期(2015—2019年),现在正处于人工智能的火热发展时期。
从技术主题识别结果可知,人工智能领域准核心专利现阶段主要的技术研究热点有语音识别、图像处理/识别、生物特征识别、目标检测、机器学习、神经网络、自然语言处理、数字数据处理/传输/存储、问答系统、通信、信号处理、计算机系统、人机交互、智能医疗/汽车/金融等,从人工智能领域研究的内容角度出发,可以把这些技术研究热点归纳为基础层(包括硬件、算法模型及数据)、技术层(语音识别、图像识别及目标检测等人工智能相关技术的研发)及应用层(人工智能相关技术在各种领域上的应用)三大类别[10]。
从技术主题演化结果可知,人工智能领域主要技术主题的发展呈现出动态变化的趋势,绝大多数技术主题在人工智能技术生命周期各个阶段中都存在且研究热度基本保持稳定,呈现出轻微波动的变化趋势,只有少数技术主题在技术生命周期某个阶段上呈现新生、消亡、快速发展或衰退的变化趋势。从技术主题强度演化结果来看,通信(T1)、语音识别(T15)、机器学习(T20)等技术主题呈现上升的趋势,未来需要大力支持与发展这些技术主题;从技术主题内容演化结果来看,生物特征识别、云、大数据、神经网络、智能医疗/金融/汽车、机器人等技术主题在快速发展期及腾飞期中呈现新生演化状态,表明这些技术主题在该阶段中得到关注,未来这些技术主题的研究方向同样需要引起重视。
3.3.2结合定量与定性的技术预测
在定量分析结果的基础上,本研究举办了专家研讨会,邀请领域相关专家重点讨论人工智能关键技术的发展现状及预测领域技术未来的发展趋势。
首先,对人工智能关键技术的发展现状进行分析,上述对人工智能技术研究热点的定量分析结果被归纳为基础层、技术层及应用层三大层面,根据专家们的意见,对人工智能发展现状也从这三个层面进行考虑。基础层作为支撑人工智能发展的基石,主要包括数据、算法模型及硬件(硬件主要包括芯片、传感器及操作系统等,芯片的主要代表有GPU、FPGA、ASIC等,传感器主要提供数据输入和人机交互等作用)三个方面,这三者也被称为人工智能的数据、算法、算力,三者缺一不可,数据的规模与质量决定了算法模型训练结果的好坏,目前处于大数据时代,产生了海量数据可供使用,但数据还需进一步的清洗、标注等处理工作,以保证数据的质量,硬件基础为算法模型训练数据提供较快的处理速度。技术层为相关技术的研发,主要包括语音识别、机器学习、计算机视觉和自然语言处理,这几项技术为目前人工智能领域最受关注的技术,并衍生出一系列相关技术,如深度学习、增强学习、卷积神经网络、循环神经网络、隐马尔科夫模型、人脸识别、图像识别等。应用层为相关技术在产业上的应用,人工智能领域的相关技术目前正积极和各个行业交叉融合、相互促进,产生了很多应用场景,主要包括智能驾驶、智能医疗、智能金融、智能教育、智能安防、智能家居、机器人、智能推荐、新零售、智能客服等,目前几乎所有行业都在积极向智能化方向发展,期望借助人工智能带来新一轮的发展与变革。
其次,对人工智能技术的未来发展趋势进行探讨,综合专家意见及技术主题演化结果,未来十年将会是人工智能发展的关键时期,预计到2030年人工智能相关技术已经发展成熟,将被广泛应用到生活、生产制造、社会治理以及国防建设等,进入大规模产业化阶段。技术的未来发展趋势主要有以下四点:一是新型的硬件基础需要重点关注及研发,尤其是人工智能芯片中的量子芯片,将引领新一轮芯片的发展与变革。现存的计算架构难以支撑大规模数据的并行计算需求,目前人工智能的一些主流企业已在加紧开发新型芯片,以加速对海量数据进行深度学习等复杂算法模型进行训练的计算过程。二是感知智能向认知智能方向迈进,弱人工智能向强人工智能再到超人工智能方向迈进。当前人工智能所具备的只有快速计算、记忆存储的运算能力以及视觉、听觉等感知能力,但缺乏人类大脑所具有的理解与思考等认知能力,也即表示当前处于弱人工智能时期,距离强人工智能及超人工智能时期还有很长的一段路要走,为此,需要积极研发各种深度学习、神经网络等智能算法,这也是未来需要攻克的技术难关。三是新一轮的数据革命已经到来,需加强对数据的管理。当前我们正处于大数据时代,各个领域都产生并记录了大量可用的数据,未来越来越多的事物将被数据化,基于数据挖掘带来的价值将得到进一步的体现,未来需要积极搭建数据收集、处理、存储等的一体化、可视化的平台,另外,数据隐私及信息安全问题需要引起重视。四是人工智能将深度融入到产业的发展中,新一轮产业变革正在到来。目前人工智能已经成功运用到多个领域中,但只能做些较为简单的事情,远远没有到达真正的智能化时代,未来人工智能将与多个产业深度融合,以发挥人工智能的最大价值。同时,根据人工智能专利数据技术主题识别与演化结果,专家进一步预测未来10年的技术研发热点,主要有语音识别、人脸识别、图像识别、模式识别、文本识别、神经认知、机器学习、深度学习、神经网络、自然语言处理、大数据、云计算、5G通信、物联网、区块链、集成电路、芯片、自动化、人机交互、虚拟现实、智能搜索、个性化推荐、智能金融/医疗/驾驶/家居等。将定量分析结果与专家评价相结合,对综合研究结论进行可视化,如图5所示。
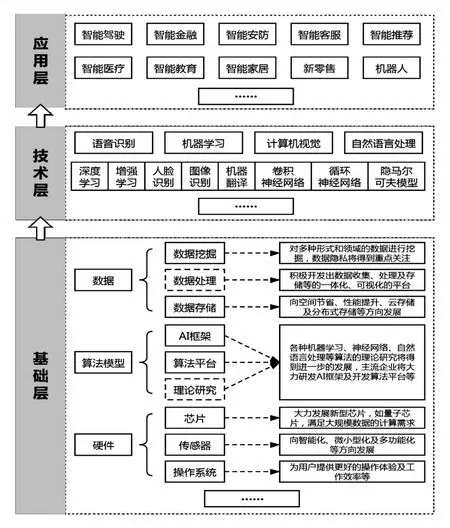
图5 人工智能的未来发展
目前人工智能已经上升为国家战略,国家已经先后制定了一系列政策并投入大量资金来发展人工智能,在行业的应用方面也在积极开展,但是中国人工智能领域核心技术的实力还比较薄弱,在所识别的3 262条准核心专利中,美国拥有准核心专利数量排名第一,中国排名则较为靠后,而在全数据集中,中国专利申请数量排名第一,这说明中国专利的申请数量已经居于前列,但位列核心的专利数量不多。为此,结合专家座谈的意见,本文提出以下几点建议:一是跟踪国际发展态势,大力发展人工智能产业,加快促进产业智能化发展;二是制定相关措施,鼓励企业以核心技术为目标进行科技创新,并加大相关技术研发投入;三是加强高端人才建设,倡导高校积极开设以基础层与技术层相结合的人工智能相关课程;四是制定人工智能相关标准体系,开展核心技术创新应用试点示范,推进人工智能向高端发展;五是积极开展国际合作,弥补我国在核心技术上存在的薄弱环节。
4 研究结论
本文以核心专利技术主题识别与演化分析为出发点,以技术预测为落脚点,研究热点技术及技术的未来发展趋势。以德温特专利数据库为数据源、以人工智能领域为研究对象,设计了研究框架与研究方法,并实证研究,以验证本研究所提方法的可行性与可靠性。
本文一方面将核心专利识别、技术主题识别与演化分析相结合,以有效缩减海量专利文献集挖掘与分析的难度及工作量,同时更加突出重点地跟踪与预测技术发展态势。研究结果较为准确、快速,且对于设备环境要求不高,所以对于大规模数据,可以首先识别出核心专利,然后基于核心专利数据集进行技术主题识别与演化分析,这为现有相关研究提供一个新的思路。另一方面,以定性定量两种方法的结合使用进行技术预测,综合考虑了两种方法的优点,能够更为清晰、准确地刻画技术未来的发展方向,研究结论更具可靠性。
然而,在研究过程中仍然存在一定的局限性,未来可进一步开展研究:一是本文在数据的获取上,从具有代表性的专利数据源上收集相关专利数据,技术相关信息不仅存在于专利数据源上,也存在于学术论文、科技舆情、基金及科技报告等数据源上,仅以专利数据进行技术主题识别与演化分析,从而进行技术预测,对于技术的发展状况难以全面掌握,研究结论的准确性有待提高。未来可利用多种数据源多方面、多角度地对技术主题识别与演化进行更全面的研究,如可以使用美国专利商标局专利数据库、中国专利全文数据库等来进行主题识别,或单独分析某一技术主题,以期带来更为准确、可信的研究结论。二是从技术主题识别的结果来看,目前选择的是输出彼此之间相似度大于0.7的10个主题词,主题词包含的信息还比较单一,无法具体显示主题词之间的关联性,在后期研究中可以选择输出短语或者关键词,不断丰富技术主题识别的结果。三是本文在技术主题的识别上,基于LDA主题模型、Word2vec词向量模型两种模型简单的结合识别技术主题,识别结果基本能够反映现实,但目前基于神经网络、深度学习等技术的主题挖掘已经得到大量的研究并取得较好的结果,如LSTM(Long Short Term Memory)模型、K-means聚类算法等的使用,未来可考虑利用这些模型或技术研究技术主题的识别。另外,将时间、机构、IPC分类号等因素与主题模型融合进行研究也是目前关注热点,也可开展对比研究,如将基于技术模型的技术主题识别和基于IPC小类的技术主题识别进行对比分析,将基于技术模型的技术主题演化与基于IPC小类的技术主题演化进行对比分析。
猜你喜欢
军事文摘(2022年14期)2022-08-26
军事文摘(2022年14期)2022-08-26
军事文摘(2022年12期)2022-07-13
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
教书育人·教师新概念(2017年6期)2017-06-15
小康(2017年16期)2017-06-07
南风窗(2016年19期)2016-09-21
中国发明与专利(2007年7期)2007-08-09
