
基于NVIDIA TX2的喷码字符检测算法
2022-07-13 01:51:50胡维平刘北北刘雨戈
计算机工程与应用 2022年13期
李 帆,胡维平,刘北北,2,刘雨戈
1.广西师范大学 电子工程学院,广西 桂林 541000
2.中国科学院 自动化研究所 苏州研究院,江苏 苏州 215000
随着人民生活水平的提高,人们对食品药品安全的把控越来越严格,生产日期、产品批号等信息作为消费者唯一判断的标准,其作用尤为重要。大部分生产厂家都是通过字符喷印技术将信息打印到产品的外包装上,由于喷印机机械震动、喷头堵塞、缺墨等因素,喷印字符时不可避免的会出现字符漏喷、缺失或重叠等现象,严重影响产品的质量问题。近年来,一些公司尝试采用机器视觉检测方案,极大地提高了商品生产的质检速率。但由于商品背景颜色各异、喷码信息复杂多样、形态大小不一,且常含有相似的干扰字体,极大地增加了喷码字符的检测难度。
喷码质检行业中厂家需求各不相同,有的厂商只要求检测喷码的有无,这类任务可采用目标检测算法,将喷码字符区域看作一个待检的整体。此方法准确率高,检测速度快,但是无法满足高质量的字符级质检要求,因此基于字符识别的检测算法逐渐被应用于喷码质检行业中[1]。
传统的字符检测算法主要过程是:图像预处理,提取目标区域,字符区域二值化,水平投影行分割,垂直投影字符分割,最后使用SVM、AdaBoost等分类器进行字符分类[2]。传统算法存在理论性强、训练及推理速度快等特点,但是需要手工设计特征,无法应对复杂的背景环境,鲁棒性不强。随着深度学习技术在视觉检测方向的普遍应用,基于深度学习的字符识别算法也相继被提出[3]。
目前,基于深度学习的字符识别技术普遍采用字符检测加字符识别的方法。其中字符检测算法主要有连接文本提议网络CTPN[4]和目标检测网络(如YOLO、SSD、R-CNN 系列等)。CTPN 算法将检测区域拆分成细窄的检测框,引入RNN提取序列特征,同时设计Siderefinement 来提升预测边界框的精确度,但对于倾斜文本的检测效果不好,且网络推理速度较慢,无法满足嵌入式端实时检测的需求。两阶段目标检测算法先生成候选区域再进行目标检测,准确率很高但网络推理速度较慢。单阶段的目标检测算法虽然精度略低,但检测速度快,其中YOLO[5]系列的v5版本不仅在速度上优势明显,而且模型体积小,部署方便,但应用于喷码字符定位时,其目标边界框回归精度仍不能完全满足字符识别的要求,同时为了在嵌入式端完成实时检测效果,模型推理速度也有待提高。
字符识别的算法主要包括分割的单字符识别和不分割的文本识别等方法。其中分割的单字符分类识别将字符串切割成单个字符,再使用图像分类网络对其进行分类识别[6],但每个字符的切割效果会直接影响字符识别的准确率,喷码字符点状不连续的特征,无疑是字符分割的最大障碍,另外背景复杂,字符较小,喷印不清晰等因素都会影响分割效果。不分割的文本识别一般用Seq2Seq[7]+Attention[8]和CRNN+CTC[9-10]两种方法,Seq2Seq+Attention 的算法包括encoder 和decoder 两部分,encoder 网络通过CNN 提取图片特征,BLSTM 得到横向序列,decoder解码部分采用LSTM和注意力机制。CRNN 算法将序列标注算法嵌套在深度卷积神经网络中,支持端到端的梯度反向传播,在IIIT5K、SVT 以及ICDAR系列标准数据集中取得了优于现有算法的结果。
在分析研究现有算法的基础上,本文提出采用基于YOLOv5+CRNN的字符识别技术,免去字符分割步骤,直接实现对定位后的整行喷码字符识别,提高整体系统的喷码识别准确率。文字检测网络采用改进的YOLOv5网络,字符识别网络采用CRNN 网络,其主要创新和贡献包含以下内容:对YOLOv5文字检测网络增加注意力机制[11],改进损失函数,进行模型剪枝压缩[12-13],以提高字符定位精度和检测速度;针对喷码字符区域背景复杂且字符存在倾斜的问题,进行背景擦除和透视变换等预处理任务后再送入CRNN字符识别网络。此外,为了提高深度学习算法的推理速度,方便嵌入式等边缘设备的算法部署,本系统还对训练后的模型进行了模型量化和裁剪。实验表明,本文所采用的方法具有高精度、高速度和良好的鲁棒性,对喷码字符的检测有着重要的意义和应用价值,并且可实际应用于工业生产线部署。
1 喷码字符检测系统
喷码字符检测系统由硬件和软件两部分组成。硬件系统主要包括工业相机及支架、环形光源、嵌入式设备、显示器等。针对喷码识别需求,选择海康MV-CA003-21UC 工业相机,最高帧率可达814.5 frame/s,最短曝光时间40 μs,可满足喷码图像的采集。嵌入式平台采用NVIDIA TX2,共2 块CPU 和1 块有256 个CUDA 核心的GPU,8 GB 的运行内存,32 GB Flash 存储器。工作在最大性能时功耗不超过15 W,可在有限的条件下实现高性能的并行计算。
软件系统采用Ubuntu18.04 操作系统,为了加快模型推理速度,更好地适配嵌入式底层硬件,选取Tengine嵌入式轻量级AI 推理框架。该框架将程序体积压缩至3 MB 左右,并且支持嵌入式端NPU、GPU(CUDA/TensorRT)等加速。
本文所设计的喷码字符检测系统主要应用于喷码生产线喷码机后端,是一种在线实时检测系统,其工作流程是流水线商品触发工业相机采集单张图片信息,系统完成喷码字符质检任务并剔除喷码有缺陷的商品,整体工作流程如图1所示。
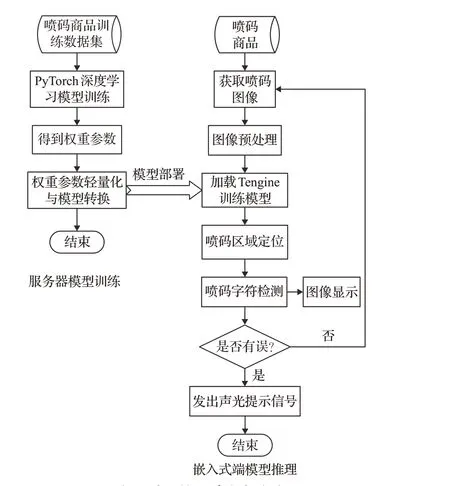
图1 喷码检测系统流程图Fig.1 Flow chart of coding inspection system
2 喷码字符检测算法
对于喷码字符的识别,首先要定位商品图像中喷码字符的位置,因此识别任务需要包括两个步骤,即字符检测(字符定位)和字符识别,并将输出字符与欲喷印字符进行对比。喷码检测任务如图2所示。
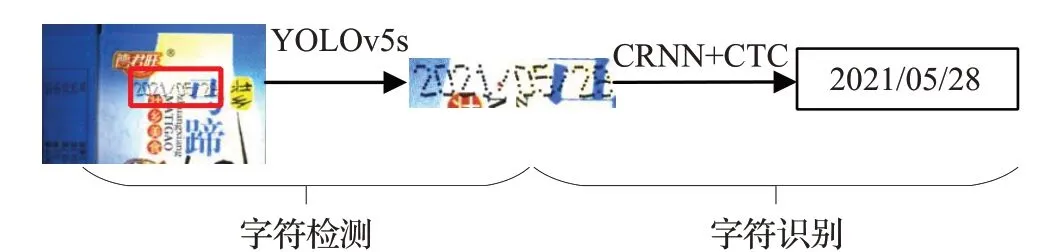
图2 喷码检测任务图Fig.2 Inkjet inspection task map
2.1 YOLOv5定位算法原理与改进
2.1.1 YOLOv5算法原理
YOLOv5结合了大量计算机视觉相关技术,网络模型小、推理速度快。网络结构主要改进了Backbone 与Neck部分,同时对输入端的数据预处理也做了大量细节的改进。网络采用了Mosaic数据增强的方法,随机选取4张图像缩放其比例并重新组合成一张图像,提高了小目标的识别效果,还有助于减少对显卡内存的需求,提高模型训练效率。YOLOv5使用CSP-Darknet作为特征提取网络,在很大程度上避免了网络中梯度重复的问题,在特征图中融合梯度信息,既提高了检测速度,又保证了准确率。Neck特征金字塔结构,增强了不同大小目标的检测效果。YOLOv5网络结构主要包含以下三部分:
(1)Backbone主干网络提取图像的高维特征信息;(2)Neck融合图像不同维度的特征信息;
(3)Head是预测层,生成边界框并预测类别。
本文选择YOLOv5 网络宽度最小、复杂度最低、检测速度最快的YOLOv5s 版本并加以改进,YOLOv5s 网络检测流程如图3所示。
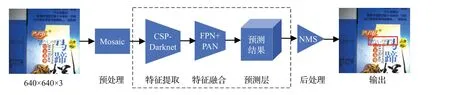
图3 YOLOv5s网络结构Fig.3 YOLOv5s network structure
2.1.2 结合注意力机制的YOLOv5s模型
注意力机制(attention mechanism)是一种资源分配机制,其思想是在原始数据中找到内在的相关性,突出关联性强而忽略掉一些关联性弱的特征信息。本文希望网络只关注点状的喷码区域特征,因此在特征提取网络中加入注意力机制,可有效提高字符检测算法的准确率。
本文采用轻量级的注意力模块ECA-Net[14],它只涉及少量的参数,在降低复杂度的同时能保持较高的检测性能,既避免了特征维度的缩减,又增加了通道间信息的交互。ECA-Net的注意力权重计算过程分为两步:首先通过对特征图进行全局平均池化产生向量,再通过一维卷积来完成跨通道间的信息交互,得到每个通道的权重。在计算通道特征yi的权重wi时,只需考虑和它相邻的k个值之间的信息,计算公式如下:
本文采用的注意力模块参数确定为k=5,C=8,其结构如图4所示。
注意力模块的作用在于对信息进行细化分配和处理,所以本文在YOLOv5s 的特征提取网络Backbone 之后、Head之前添加ECA-attention模块,让网络更加关注点状字符特征的提取。改进后的网络结构如5所示。
2.1.3 损失函数的改进
Yolov5s 作为字符定位算法,其边界框回归区域的正确率直接影响到字符识别的正确率。YOLOv5s的回归损失采用GIoU 损失函数,虽然考虑到了预测框和真实框的非重合区域,但如果标注的真实框完全包围预测框时,此时损失函数无法回归,使得网络收敛速度变慢。因此,本文采用CIoU 损失函数[15]计算边界框回归损失,不仅考虑了中心点之间的距离,还添加了宽高比因子,能够更准确地回归预测框。CIoU 损失函数的值用LCIoU表示,计算公式如式(6)所示:

原始的YOLOv5s 模型权重大小为21 MB,本文经过稀疏训练、裁剪部分卷积核后模型大小11 MB 左右。模型参数量越少,计算所需的时间越短,因此裁剪后的模型在嵌入式等低算力平台可以有更快的推理速度。
2.2 CRNN字符识别算法原理与改进

CRNN 首先由卷积神经网络(CNN)提取图像卷积特征,再利用长短时记忆网络(LSTM)进一步提取图像卷积特征中的序列特征,最后使用CTC 算法[17]代替Softmax解决样本无法对齐的问题。
CRNN 网络由卷积层、循环层和转录层三部分组成,网络结构框架如图6所示。输入图像分辨率为100×32,网络首先采用CNN 提取图片中喷码字符区域的特征,转换为特征序列后再由循环神经网络(RNN)进行单帧预测,最后由转录层将预测结果翻译为字符序列,输出识别结果。
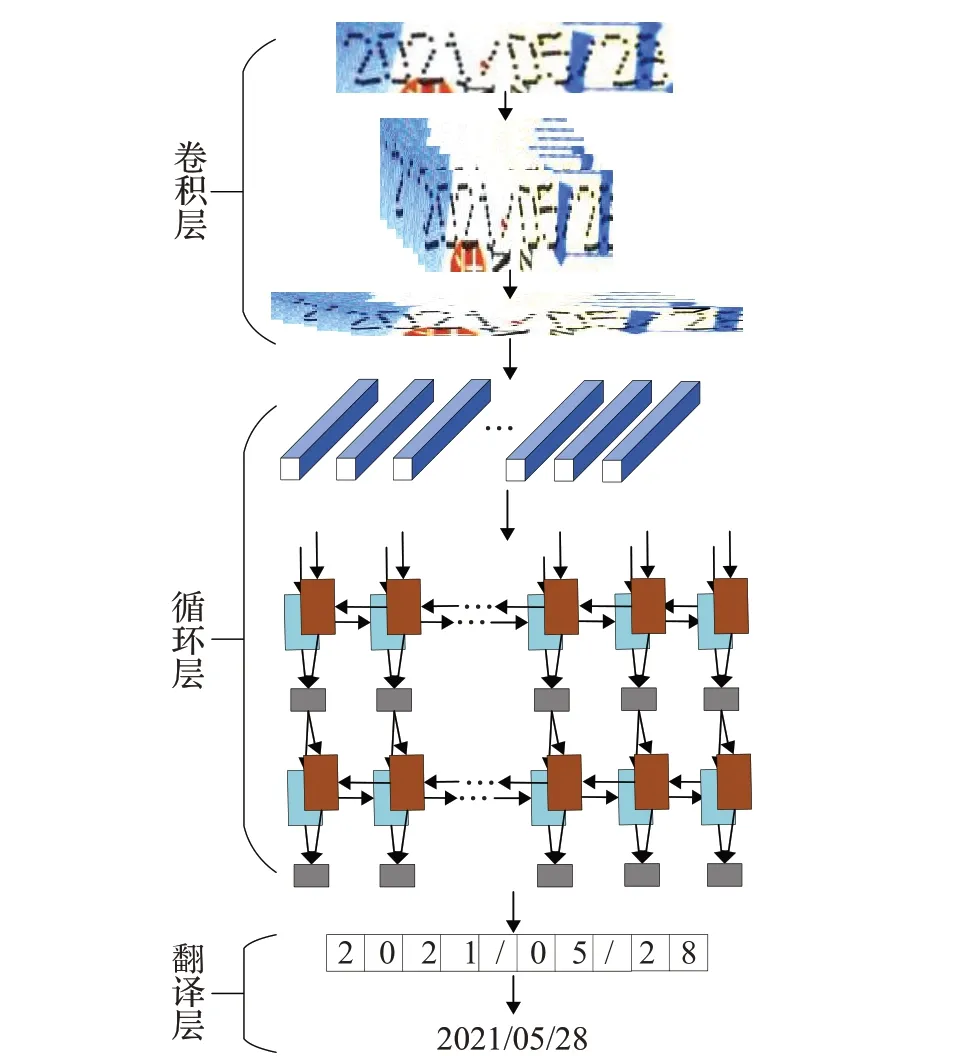
图6 CRNN网络结构图Fig.6 CRNN network structure diagram
2.1.4 稀疏训练
对于一个训练好的模型,通常会存在部分卷积核参数值趋近于零的情况,这部分卷积核的贡献实质上是很小的,倘若裁剪这些卷积核后再进行微调是可以恢复到之前的检测精度[16]。如果对权重参数加以限制,如L1正则化,训练得到的参数结果就会比较稀疏,更加利于裁剪。本文选择BN 层的尺度因子作为裁剪channel 的衡量指标,在训练时,对BN 层的尺度因子添加L1 正则化,达到稀疏化的作用,这样就可以通过BN层的尺度因子是否趋于零来识别不重要的channel。引入一个尺度因子γ,与每一个channel的输出相乘,联合训练权重和尺度因子,对尺度因子稀疏正则化,最后裁剪掉较小的尺度因子及其对应的channel。训练的损失函数如下:
喷码字符识别相较于其他文本识别任务,不同之处在于喷码定位区域背景复杂,且由于喷码机喷头的震动,传送带的运动导致部分待检字符存在倾斜现象。针对此问题,本文在对定位后的喷码区域进行背景擦除和透视变换处理后,再送入CRNN字符识别网络。
透视变换(perspective transformation)是指将透视面绕透视轴旋转某一角度,即将原始图片按照指定的坐标规则变换到新的位置,在保证固定区域变换的过程中,可以忽略整幅图像其他位置的形状和坐标信息。变换规则通过标注原图上任意四个坐标点和与之相对应的预设位置坐标计算得到一个变换矩阵,再通过变换矩阵将原图变换成新的图片,通用的变换公式为:

本文将送入喷码识别的照片进行坐标信息的判断,当坐标相差一定的阈值(旋转超过3°),则视为字符倾斜过度,采用透视变换,将定位到的倾斜字符区域拉升回正确位置,图7是透视变换的结果。
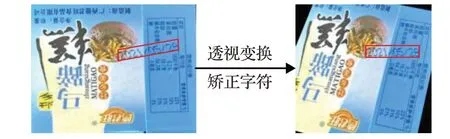
图7 透视变换矫正字符Fig.7 Perspective transformation to correct characters
3 实验及结果分析
3.1 数据集介绍
实验采用的数据集为桂林金鸡岭德君旺食品有限公司生产的12类糕点盒子,其中每类200张,共2 400张包含点状生产日期信息的.jpg格式图片,均为MV-CA003-21UC工业相机在生产流水线并且环形补光灯环境下拍摄,并进行手工标注。本文将2 000张作为训练集,字符定位数据集通过随机裁剪、色彩空间调整和马赛克增强等方式扩充得到4 000张。字符识别数据集通过批量提取喷码字符区域,对其增加Alpha 透明通道,然后设定区域范围后随机粘贴组合产生不同生产日期字符,最终扩充得到6 000张训练集。
3.2 实验环境
为了在短时间内得到好的训练效果,本实验训练和测试过程均在电脑端完成。利用GPU加速训练和推理,硬件上搭载GTX1060 MAX GPU,英特尔i7 8700处理器,使用Ubuntu18.04系统,配置PyTorch1.8+python3.8的虚拟环境,最后将训练好的模型部署到NVIDIA TX2上测试,并进行工厂生产线实测。PC 端和NVIDIA TX2的配置对比如表1所示。
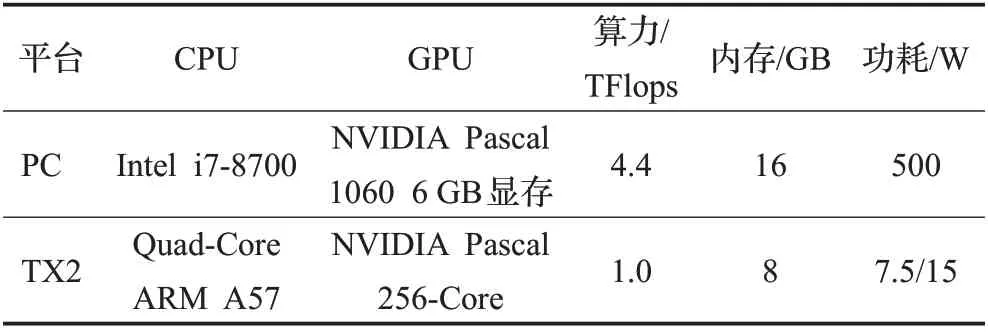
表1 PC和NVIDIA TX2配置对比Table 1 Comparison of PC and NVIDIA TX2 configuration
3.3 实验设置与训练过程
对YOLOv5s字符定位网络和CRNN字符识别网络分别训练,并进行相关测试。部署时利用字符定位网络输出的字符区域坐标在原图上进行裁剪,再将裁剪后只包含字符区域的图片送入CRNN网络进行字符识别。
字符定位网络实验优化算法采用Adam优化器,初始化学习率设置为1E−4,batch size为16,epoch为100;所有权重初始化均值为0,标准差为0.01的高斯分布,训练过程如图8 所示。字符识别网络实验优化算法采用Adam 优化器,初始化学习率设置为1E-4、batch size 为64,epoch为5 000。
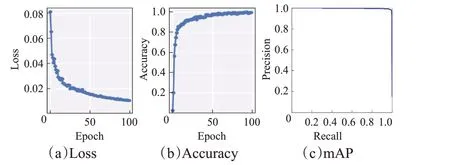
图8 训练参数曲线Fig.8 Training parameter curves
3.4 实验结果及分析
为了验证本文提出的YOLOv5s+CRNN 的喷码字符检测方法,在500 张测试数据集上进行实验,并分别对各网络的字符定位效果和字符识别效果进行性能评价。字符定位准确率表示在信度阈值为0.6 时,正确检测出喷码字符区域的个数除以检测总数。字符识别率的评价指标采用字符准确度(char accuracy)来表示。字符准确度指预测的字符串与真实字符串相比得到的准确率,对于英文单词“g-o-o-d”来说,如果预测序列为“g-o-a-d”,则在评估的时候逐字对照,4个字符预测对了3 个,因此该字符串预测序列的准确率为75%。模型推理时间表示测试一张照片所耗时间,单位为毫秒(ms),实时检测速度采用帧率来表示,即每秒检测图片的张数。实验的检测速度均是各模型在PC端利用1060 GPU设备加速检测得到。
表2 展示了YOLOv5s 定位算法改进部分的消融实验结果。本文对其增加ECA注意力模块和改进损失函数,分别能提升2.8 个百分点和1.2 个百分点的检测精度;再对网络进行稀疏训练和通道剪枝后模型减小了6.7 MB,检测时间缩短了6.5 ms。表3 对比了在CRNN模型前加入透视变换矫正和背景擦除等预处理后,对字符识别精度的影响。
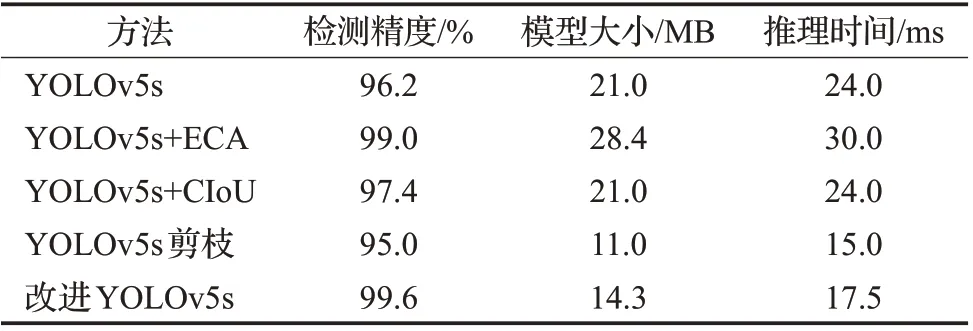
表2 改进定位算法消融实验Table 2 Ablation experiments with improved positioning algorithms

表3 改进识别算法消融实验Table 3 Ablation experiments with improved recognition algorithms
表4 对比了几种常见的不分割字符检测方案。其中将字符定位和识别网络合在一起的端到端算法最常见的是ABCNet 和FOTS 检测算法,特点是网络模型复杂,虽然检测精度很高但是推理速度极慢,不适合低算力设备的部署。目前常用的CPTN+CRNN 字符检测方法在定位时采用连接文本提议网络CPTN,将文字沿文本方向切割成更小且宽度固定的Proposal,极大地提高了检测定位的精度,在本文所用数据集上达到了99.8%的定位准确率,但由于其网络模型复杂,导致参数量很大,推理时间极慢,在搭载1060 显卡的PC 端检测速度只有每秒4.5帧左右。
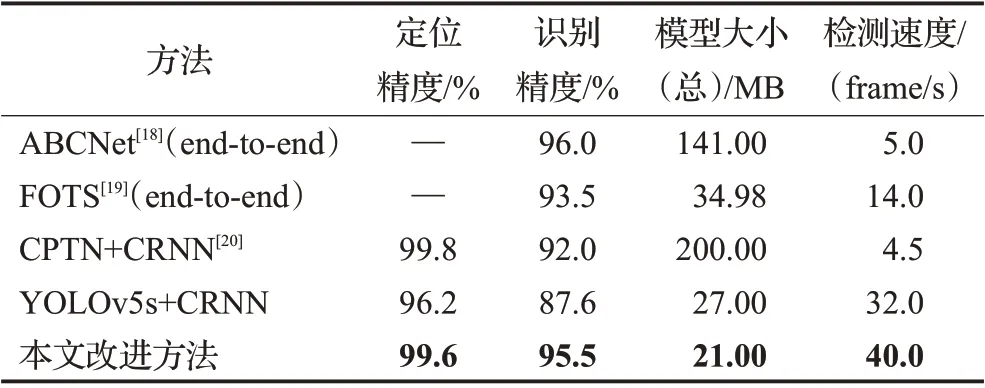
表4 不同方案的效果对比Table 4 Comparison of Effects of different programs
本文提出将YOLOv5s目标检测网络与CRNN网络相结合,在未作任何改进的情况下,验证其检测精度和速度,结果如表4 所示,定位精度与CPTN 相比下降了3.6 个百分点,由于定位区域的偏差不同影响导致了字符识别率下降了4.4 个百分点,但是模型参数量减小了173 MB,检测速度高达每秒32帧。最后,针对喷码字符检测的特定任务,本文从网络结构、特征提取以及模型裁剪等地方加以改进,并对定位后的字符区域做相应的透视变换矫正处理,提高了CRNN字符识别精度。最终在PC 端测试结果,字符定位精度和识别率分别为99.6%和95.5%,总模型大小仅有21 MB,在大大降低了模型参数量的情况下还提高了识别率。
3.5 嵌入式的部署
为了节省硬件成本,加速算法的快速落地,解决工厂生产线的实际检测需求,本系统将改进后的算法进一步量化与裁剪,利用Tengine嵌入式端的深度学习框架,结合QT5 利用C++编写端侧推理代码,部署至NVIDIA TX2嵌入式平台,并利用TensorRT7.1加速推理计算。
在移动设备上计算sigmoid 函数的代价要比ReLU等线性激活函数更大,因此使用线性的激活函数分段近似,使计算更容易,可以大大提高推理效率。YOLOv5s采用Swish激活函数,计算公式如下:
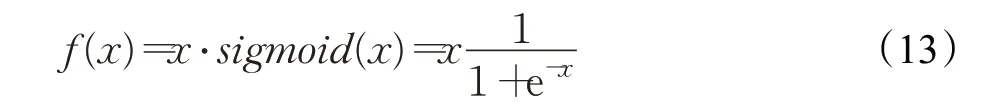
虽然这种非线性激活函数可以提高计算精确度,但是它在低算力的嵌入式环境中耗时严重,因此本文使用hard-Swish代替Swish激活函数,再部署至嵌入式平台,可以大大提高模型推理运算速度。
为了验证改进算法的有效性和可行性,系统采用海康工业相机在桂林某食品加工包装厂实际环境中进行实时测试,并在TX2 平台利用TensorRT 调用GPU 进行推理,检测效果如图9所示。

图9 在线识别效果Fig.9 Online recognition effect
本文在工厂流水线自然环境下,固定光源与相机,真实喷印场景下测试1 000 个商品,统计得到的检测性能数据如表5所示。
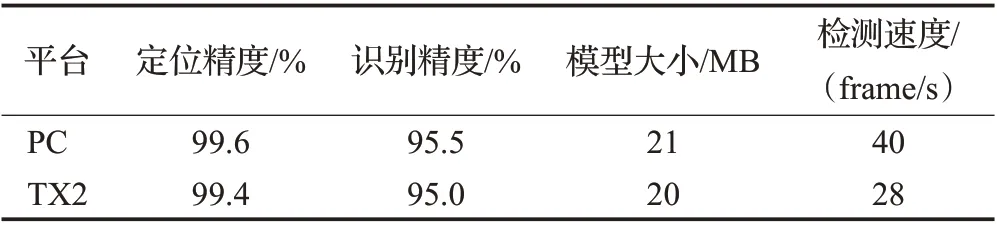
表5 TX2平台测试结果Table 5 TX2 platform test results
测试结果表明,本文所提方法最终可在NVIDIA TX2嵌入式平台实现了每秒28帧的检测速度。对比PC端的检测效果,由于部署前再次裁剪和替换了一些网络结构,但对检测性能影响不大,其定位精度仅下降了0.2个百分点,识别率降低了0.5 个百分点。经在某食品加工厂测试,喷码流水线的速度大约在160 m/min,每秒喷印20 个商品左右,因此在嵌入式设备上的实时检测速度(每秒检测28 个)能够满足工厂的实际检测需求,并且所使用的嵌入式设备在功耗、体积以及成本上与工控机、电脑、显卡等昂贵的设备相比都具有巨大的优势。
4 结论
本文结合深度学习中的字符识别方法,提出了一种基于嵌入式平台的不分割的喷码字符检测算法,提高了字符检测的精准度与速度。将YOLOv5 与注意力机制相结合,有利于点状字符特征的提取,有效地提高了喷码字符区域的定位精度,对定位后的图像区域采用透视变换和擦除背景等处理,提高了字符识别率。最后裁剪掉对嵌入式端不友好的结构后,利用Tengine AI推理框架实现了算法在嵌入式设备NVIDIA TX2 上的部署。算法检测速度可达到28 frame/s,满足了实时性的要求,最终在喷码工厂流水线实测字符识别率可达95%。下一步将继续优化算法,提升喷码字符的识别率,同时尝试训练更多的喷码字符数据集,以满足在更多不同类型字体的喷码字符产品上的应用,使得算法更具有普适性。
猜你喜欢
科技创新与生产力(2022年12期)2023-01-18 10:07:58
电脑爱好者(2022年15期)2022-05-30 01:29:23
锻压装备与制造技术(2021年1期)2021-03-24 01:52:32
重型机械(2020年3期)2020-08-24 08:31:36
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
中国食品工业(2018年5期)2018-11-02 05:18:18
成都信息工程大学学报(2017年3期)2017-11-09 02:56:12
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:06:38
