
基于改进k-means的医院患者流向异常聚类研究
2022-07-12 04:53:50杨婷婷
微型电脑应用 2022年5期
杨婷婷
(如皋市人民医院, 江苏, 如皋 226500)
0 引言
患者流向监测是实现分级诊疗制度的关键。目前,患者流向监测主要依靠统计性指标,但由于医疗信息化水平的提高,采用该方法进行流向监测存在效率低、可靠性差等问题。因此,为提高患者流向监测效率和可靠性,研究以数据产生源头为出发点,通过大数据聚类分析和异常检测,挖掘异常的医院患者流向及其异常流向原因。现今,常用的数据聚类分析方法包括DBScan、Hierarchical Clusterer、k-means算法等,如武炜杰等[1]、张巧等[2]、李玥等[3]分别采用上述算法,完成了各个领域海量数据的分类,更好地实现了目标跟踪等目的;异常检测方法主要为基于偏差法检测,如孙宇豪等[4]、秦婉亭等[5]基于偏差法完成了对微信和飓风轨迹异常的检测。基于上述研究,综合考虑医院患者流向异常数量巨大等特殊因素,本文决定首先采用k-means算法对患者数据分类,然后借助偏差法进行识别,实现患者流向异常检测。
1 k-means 算法及改进
k-means算法是一种常见的划分聚类分析算法,其聚类思想是对给定的样本集,按照样本间的距离大小划分为k个类簇,并尽量使每个类簇间的距离最大。该算法初始k值为随机设置,且通常以所有点平均值作为质心,故其对含有噪声的数据集聚类效果差[6]。本研究中,医疗患者数据复杂且噪声明显,因此为提高聚类效果,提出两个阶段的k-means改进算法。
第一阶段,确定聚类个数k1和初始质心进行聚类。研究采用最大最小距离法确定初始质心,以保证每次选择的质心均远离已经选择的质心。最后,根据确定k1值和质心,进行聚类,得到聚类结果。
第二阶段,根据第一阶段聚类结果划分为常见患者、罕见患者、极罕见患者集合。由于极罕见患者数量较少,因此研究对其进行删除处理,并采用k-means算法分别对常见患者和罕见患者集合进行聚类,并输出结果。
改进的k-means算法流程如图1所示。

图1 改进k-means算法流程
2 基于改进k-means的医院患者流向异常检测
基于改进k-means的医院患者流向异常检测流程主要分为两步,具体如下。
(1) 异常聚类。根据基层患者特征,采用改进k-means算法进行聚类。首先,对不同k取值进行反复实验,确定最优k值,并将其作为最终聚类簇个数;然后,采用最大最小距离法选择初始质心;最后,选取最优的指标进行聚类并存储聚类结果。
(2) 异常识别。假设患者跨级就诊均为合理,则患者靠近特殊簇,远离基层患者簇。采用欧氏距离d量化“靠近”和“远离”的关系;采用向量表示跨级患者x的11维特征[x1,x2,…,x11],标记每个类簇的质心c为向量[c1,c2,…,c11],则通过式(4)可计算x到每个类簇质心c的距离,标记距离最近的类簇i到质心c的欧式距离为dxi,
(1)
上述患者流向异常检测流程如图2所示。
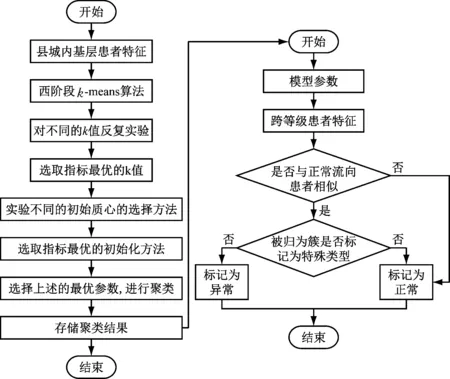
图2 异常识别流程
3 仿真实验
3.1 数据来源及处理
研究以2020年住院病案首页及人口信息库650多万条记录为原始数据集,并从中任意抽取连续10天的病案数据约20万条记录作为实验数据集。考虑到数据集中存在无关或冗余或缺失的字段,研究对实验数据集进行了数据清洗、缺失值填补、标准化预处理。
对于格式错误的数据,采用正则表达式进行查找并进行人工修正;对于重复数据,研究采用删除保留一条数据;采用模糊匹配[7]和推理填补[8]的方式对缺失字段进行填补;采用标准差标准化(z-score)[9]对所有数据进行标准化。标准化公式如下:
(2)
式中,μ为均值,σ为标准差。根据上述标准化处理,得到均值为0,标准差为1的标准正态分布数据集。
3.1.1 特征选择
为更好地识别患者流向异常,根据患者健康状况、经济状况、社会因素等关键特征进行筛选,最终确定了跨级流向的患者特征,如表1所示。

表1 跨级流向患者特征
3.2 评价指标
选取误差平方和(SSE)、邓恩指数(DVI)、戴维森堡丁指数(DBI)作为评估基于改进k-means算法的医院患者流向异常检测方法效果,其计算方法如式(3)~式(5)[10]:
(3)
(4)
(5)

3.3 聚类结果分析
3.3.1 算法验证
为验证本研究改进k-means算法的有效性,研究对比传统k-means算法,在相同参数设置下进行了实验,结果如图3、图4所示。
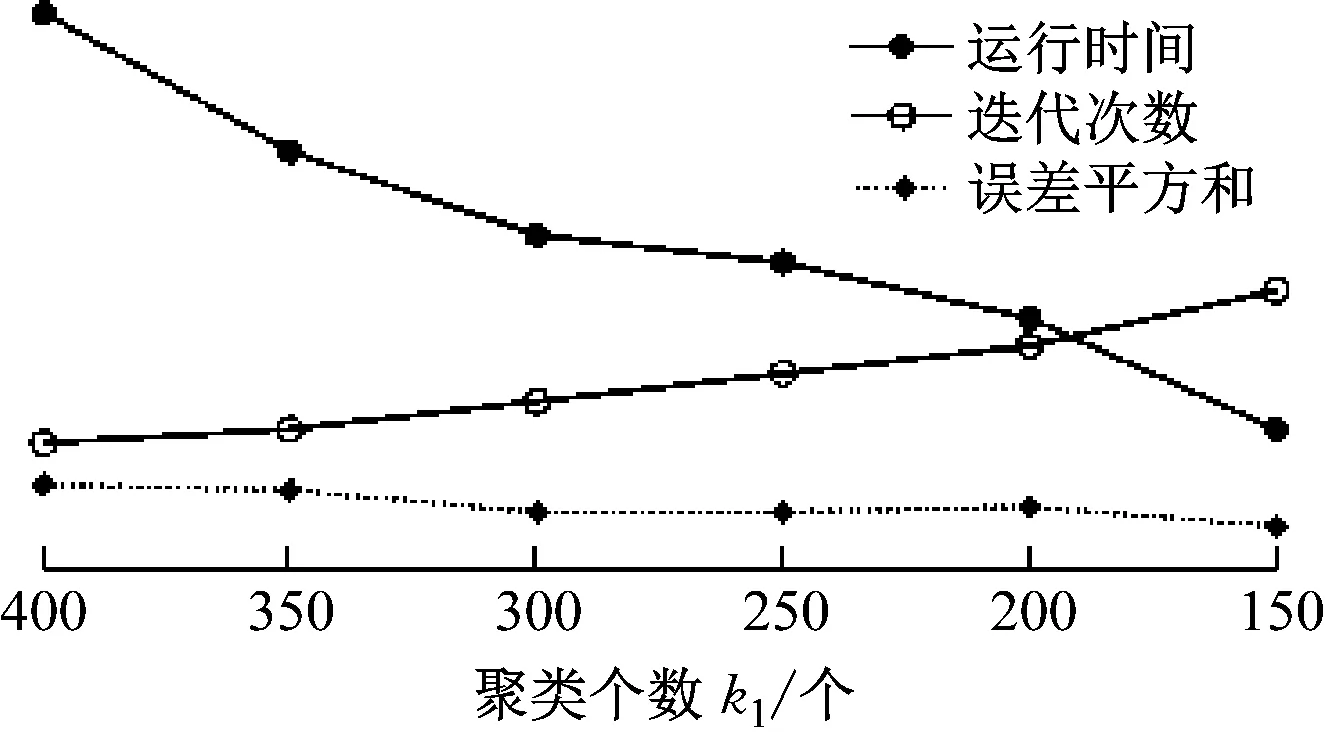
图3 不同k值下算法性能

图4 改进k-means与传统k-means聚类结果统计
由图3可知,随着算法第一阶段k值增大,算法运行时间逐渐上升,迭代次数逐渐增加,误差平方和逐渐减小。当k<200时,误差平方和下降幅度较大;当k>200时,误差平方和下降幅度逐渐趋于平缓,因此可确定本研究提出的改进k-means算法第一阶段k=200。由图4可知,相同聚类个数条件下,取任意k值,改进k-means算法的误差平方和均低于传统k-means算法的误差平方和,且随着类簇个数的减小,优化效果更明显。
3.3.2 算法比较
为进一步验证本研究算法聚类效果的优越性,研究对比cobweb、DBScan、Hierarchical Clusterer算法进行聚类实验,结果如表2所示。由表2可知,不同算法的聚类时间和聚类结果不同。其中,Hierarchical Clusterer算法因复杂度较高,无法完成建模分类;cobweb、DBScan算法聚类时间较长,且聚类个数较多;传统k-means算法聚类时间最短,但其聚类效果最差;改进k-means算法建模时间略长于传统k-means算法,但其聚类效果优良。因此,综合考虑算法聚类时间与聚类效果,本研究提出的改进k-means算法性能优于cobweb、DBScan、Hierarchical Clusterer和传统k-means算法。

表2 不同算法结果对比
3.4 异常检测结果分析
为验证本医院患者流向异常检测方法的有效性,分别在不同临界值(dxi)下进行实验。不同临界值下患者分布如图5所示。由图5可知,当临界值dxi≤max(i)时,有59%的患者跨级异常但不属于特殊簇,会被判断为异常流向;当dxi≤max(i)/2时,有18%的患者跨级异常但不属于特殊簇,会被判断为异常流向。由此说明,目前就医情况异常跨级的医院患者较多。
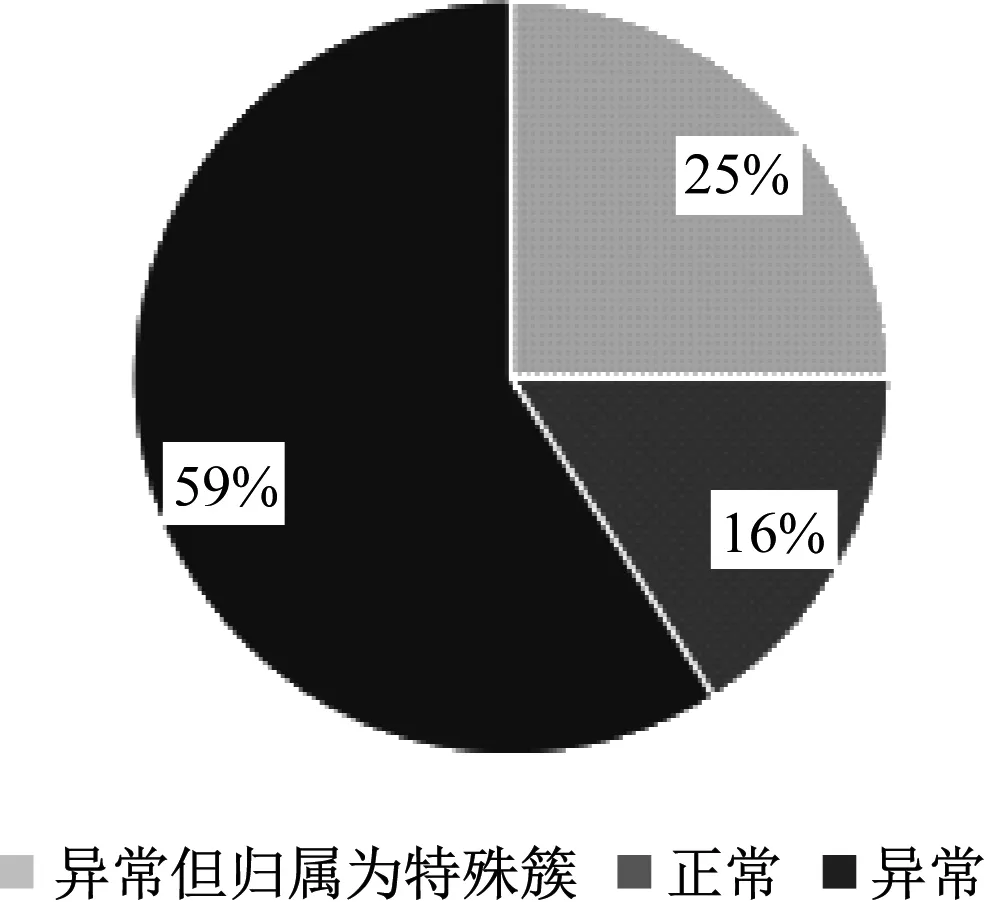
(a) dxi≤max(i)条件下患者分布

(b) dxi≤max(i)/2条件下患者分布图5 不同临界值下患者分布
选取dxi≤max(i)时,被判断为异常跨级的医院患者与正常跨级的医院患者进行疾病难度等多维度对比,结果如表3所示。由表3可知,在年龄、入院病情、疾病难度等多维度特征分布上,本研究检测方法对异常流向的跨级医院患者的判定结果与预期基本相符,说明该检测方法合理。
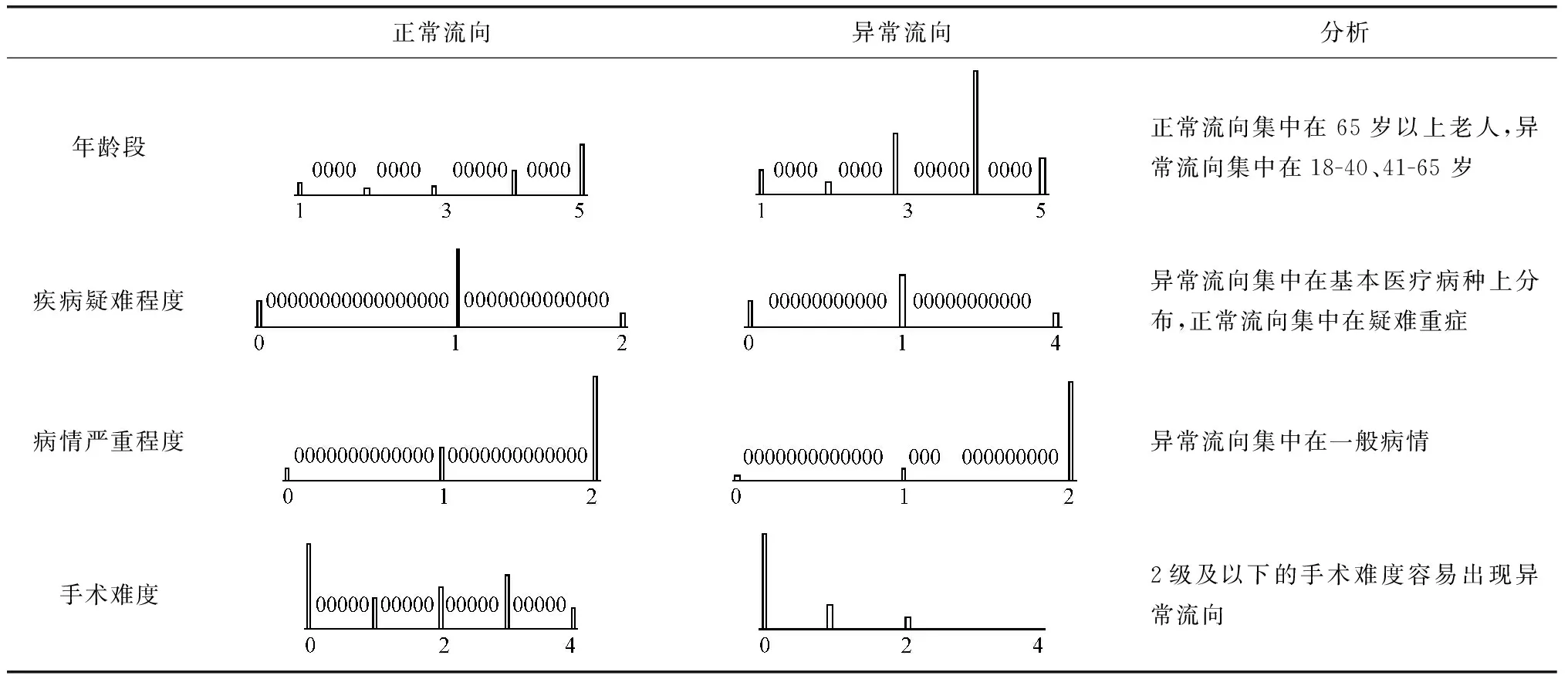
表3 正常跨级与异常跨级患者对比
为进一步评估本研究提出的医院患者流向异常检测模型的准确性,研究抽取400条数据进行专家审核。根据专家评审结果可知,采用本研究提出方法标记的跨级就诊中,被判断为异常流向的患者均被专家评审为异常流向,判断准确率为100%;有31.83%异常流向的医院患者被判断为正常流向,判断准确率为68.17%;有14.73%被判断为异常流向的患者属于合理跨级就诊,判断准确率为85.27%。由此说明,本研究提出的医院患者流向异常检测模型可有效识别出政策难以界定的患者流向。
为分析造成医院患者流向异常的原因,研究将未纳入政策评判的收入水平、住址与医院距离等指标加入模型进行深入分析。根据分析结果可知,85.92%的异常跨级就诊患者收入水平高于该省平均收入水平;64%的异常跨级就诊患者在距离大型医疗机构10 km范围内。由此可知,中高等收入或居住地在大型医疗机构附近的人群很可能选择越过基层医疗机构,直接到大型医疗机构就诊。
4 总结
通过上述分析可知,本研究提出的基于医疗大数据的医院患者流向异常检测模型,可根据正常流向患者聚类结果,有效识别出跨级异常流向的患者,并结合异常流向患者特征找到造成异常流向的原因,提出改善异常流向的对策。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30 06:24:26
北京航空航天大学学报(2021年4期)2021-11-24 01:13:12
井冈教育(2020年6期)2020-12-14 03:04:42
电子测试(2017年15期)2017-12-18 07:19:27
股市动态分析(2016年3期)2016-09-27 16:31:48
智能系统学报(2015年4期)2015-12-27 09:38:39
中国卫生(2015年7期)2015-11-08 11:09:44
电子设计工程(2015年6期)2015-02-27 12:04:53
航天器工程(2014年5期)2014-03-11 16:35:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
