
基于二分类模型的电子档案管理技术研究
2022-07-12 04:53许秀霓
微型电脑应用 2022年5期
许秀霓
(广东电网有限责任公司, 广东,广州 510030)
0 引言
档案是指单位及个人在进行相关业务的处理时,所产生的一级来源文件[1]。在计算机诞生以前,档案主要以实体形式存在,不仅档案难以管理,利用率也非常低[2]。随着电子信息化的发展,如今的档案大多以电子信息形式存在。电子档案提升了档案管理的效率,增加了档案的流通性[3]。但是在电子档案实际应用过程中,系统每天都会存入大量的数据,对于档案内容的检索就显得非常关键[4]。文本摘要技术是近些年较为流行的一种技术检索技术,可以将大量的文本信息快速地生成精准的文本摘要。为了能够使档案管理的效率有效提升,并能方便档案管理工作者能够有效地检索到目标档案,本次研究应用了二分类算法对关键词分类模型进行构建,并与平滑方法相结合,旨在为管理工作人员提供通顺可读的电子档案文摘。
1 基于二分类模型的电子档案管理优化设计
1.1 训练数据的清洗与词向量的构建
在选用训练语料时,需要确保语料主题是否与关键词保持一致。本次研究在进行模型构建时的语料全部来源于csdn博客原文,并将博客中抽取的词语标记成关键词。在清洗训练语料时,首先要清洗掉如字符乱码之类的噪音数据,再对语料进行统计词频、分词等[5]。为了能够保证后面运算的准确性,还应进行去停用词处理,因此便能得到可用的词粒度训练语料,增加了词向量构建的准确性。训练数据具体的清洗步骤,如图1所示。

图1 训练数据具体的清洗步骤
在本次研究中,主要会考虑到主题与频率的影响,同时应用有监督的学习方法进行模型构建和关键词提取,构建该模式首先需要对词语向量模式进行构建。本次研究在进行词向量构建时,综合了主体模型与词频的词向量输出,将4个算法word2vec、LSA、Textrank、tf-idf的输出作为词向量,同时对创建后的原始特征进行降维处理,以避免发生特征间的共线性情况,使运算复杂度有效降低。其中,word2vec、LSA为主题词向量的表现,Textrank、tf-idf为词频词向量的表现,将主题与词频进行有效结合,形成训练所用词向量,能够有效提升模型的表现能力。为了能够得到用于进行二分类模型的训练词向量,需要采用分类算法对模型进行优化,在当前词向量特征表现中,选取模型能够体现表现力的特征,剔除相对于模型而言不重要的特征,以使特征维度有效降低。
Filter方法为有效的过滤法,该方法通过具体指标对阈值进行设定,从而进行阈值特征的过滤。该方法可以用来检验因变量目标值与自变量特征之间的特征值关系。设x为自变量,y为因变量,构建统计量如式(1),
(1)
式中,统计量X2用于衡量x=i且y=j的样本频数的期望和观察值之间的差距,同时也是用来衡量目标函数和特征函数之间的相关性。再应用Embedded方法有效结合特征选取与模型训练工作,通过降维处理降低训练特征维度,这里主要应用了LDA降维方法,其优化方式如式(2),
(2)

(3)
应用拉格朗日乘子法解决优化中的凸优化问题,具体函数如式(4),
ξ(w,λ)=wTSbw-λ(wTSww-c)
(4)
再对w求偏导,设极值为0,如式(5)、式(6),
(4)
(5)
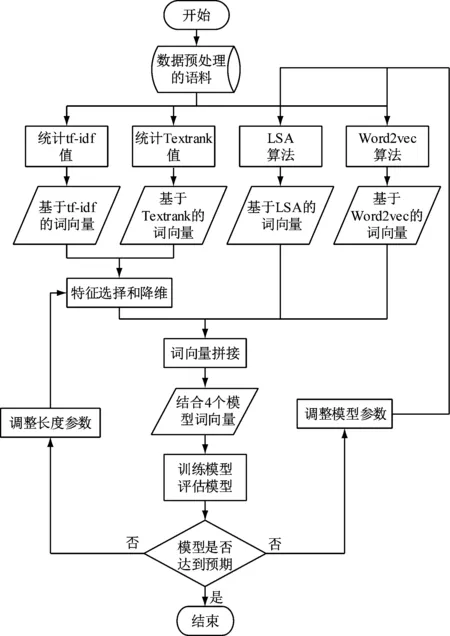
图2 词向量构建过程
1.2 二分类模型构建及模型调参
词向量构建成功后,就能够构建二分类模型进行词向量分类处理。本次研究设计主要采用了GBDT、随机森林、SVM、logistic regression四类学习算法,对二分类模型进行构建,根据模型参数分类效果进行词向量参数反馈,以确定最优分类算法。首先,构建出四类学习算法的模型,并进行模型参数优化,确保每种算法均在最优环境之下;其次,在相同数据环境、不同特征维度下对比各类算法的训练效果,包括学习预测、AUC值、n值、查全率、预测查准率、存储空间、时间消耗。综合分析后选取最佳分类模型用于系统模块的实现。分类算法在学习过程中的步骤,如图3所示。
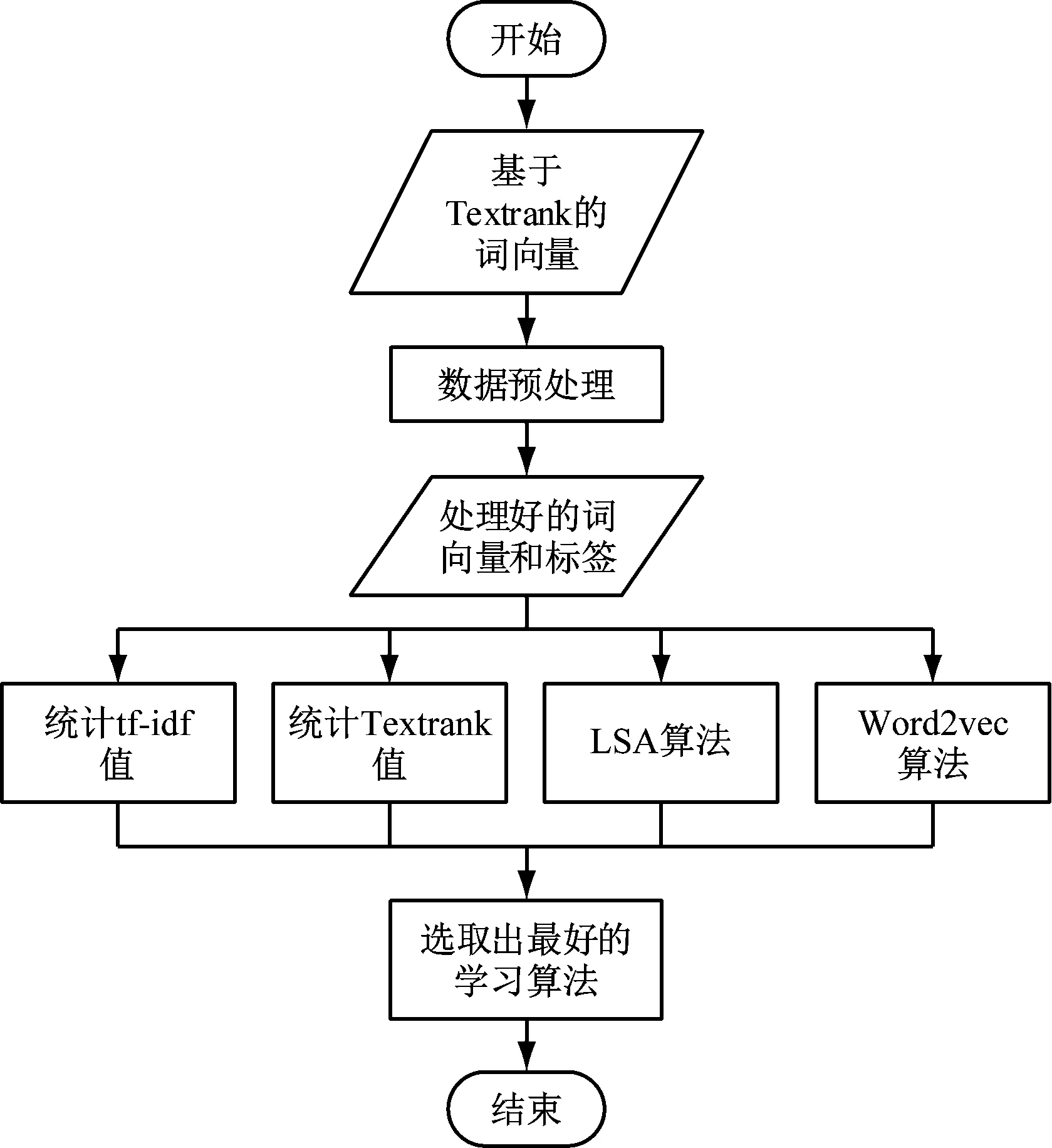
图3 分类算法在学习过程中的步骤
接着评价模型分类结果,将指标好坏程度反馈到词向量的构建过程中,以便构建时能够及时调整特征维度,判断各个算法中词向量的分类准确程度、时间与空间的占用率,最后找出最优分类模式。本次研究采用多指标评价模式评价模型,以便对后面的数据、业务需求提供依据。评价具体表示方法包括将正例预测成正例(TT)、将正例预测成负例(TF)、将负例预测成正例(FT)、将负例预测成负例(FF)。
查准率也就是准确率,主要是衡量模型预测结果的准确程度,表示预测结果中的正例样本中的真正正例数量,表示方式如式(6):
(6)
查全率也就是召回率,主要是表示预测样本中正例被正确预测的比例,表示方式如式(7):
(7)
查全率与查准率的调和平均值表示为F1,F1值是一种模型预测相对均衡的评价方式,如式(8):
(8)
AUC(Area Under Cover)指标主要是用于ROC函数下方面积的衡量。其中,ROC函数是将模型进行不断变化,并将数据预测为正值的阈值,再将预测结果绘制成一条曲线。通过以上着重考察的评价指标,可以得出一个分类模型最好的评价,最终确定适合于本次研究的分类算法。
由于二分类算法最终生成的关键词需要对关键句进行提取,本次研究采用的方法为遍历文章中的所有句子,记录包含关键词的句子与关键词数量,最后根据关键词数量进行排序。设摘要颗粒度为k,关键句子为topk,对抽取后的关键句进行平滑化处理,以生成连续可读的关键句。同时在文摘中加入关键句前后的n个句子,其中n值受到摘要规模的影响,属于可变参数。摘要的生成需要通过人工判断,在判断过程中调整n值,直到最终生成最优摘要效果。
2 基于二分类模型的电子档案管理设计测试分析
2.1 文本摘要模块功能测试
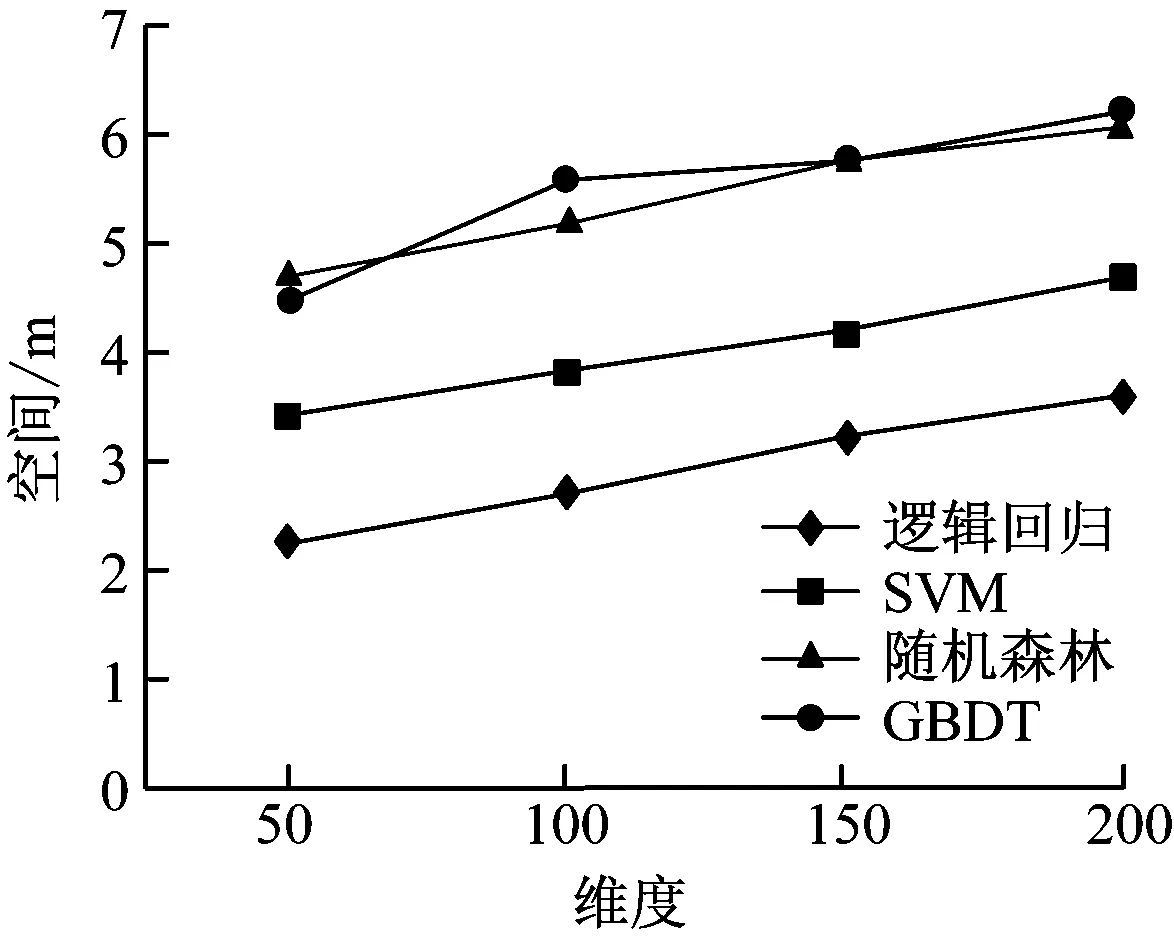
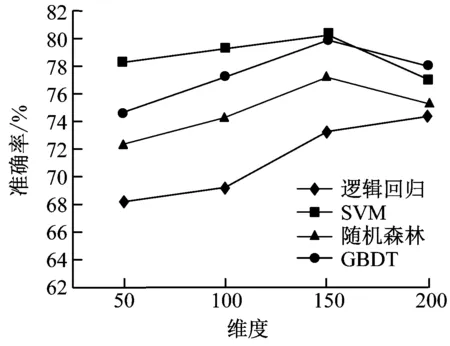
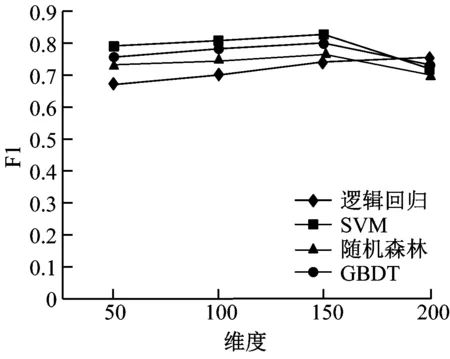
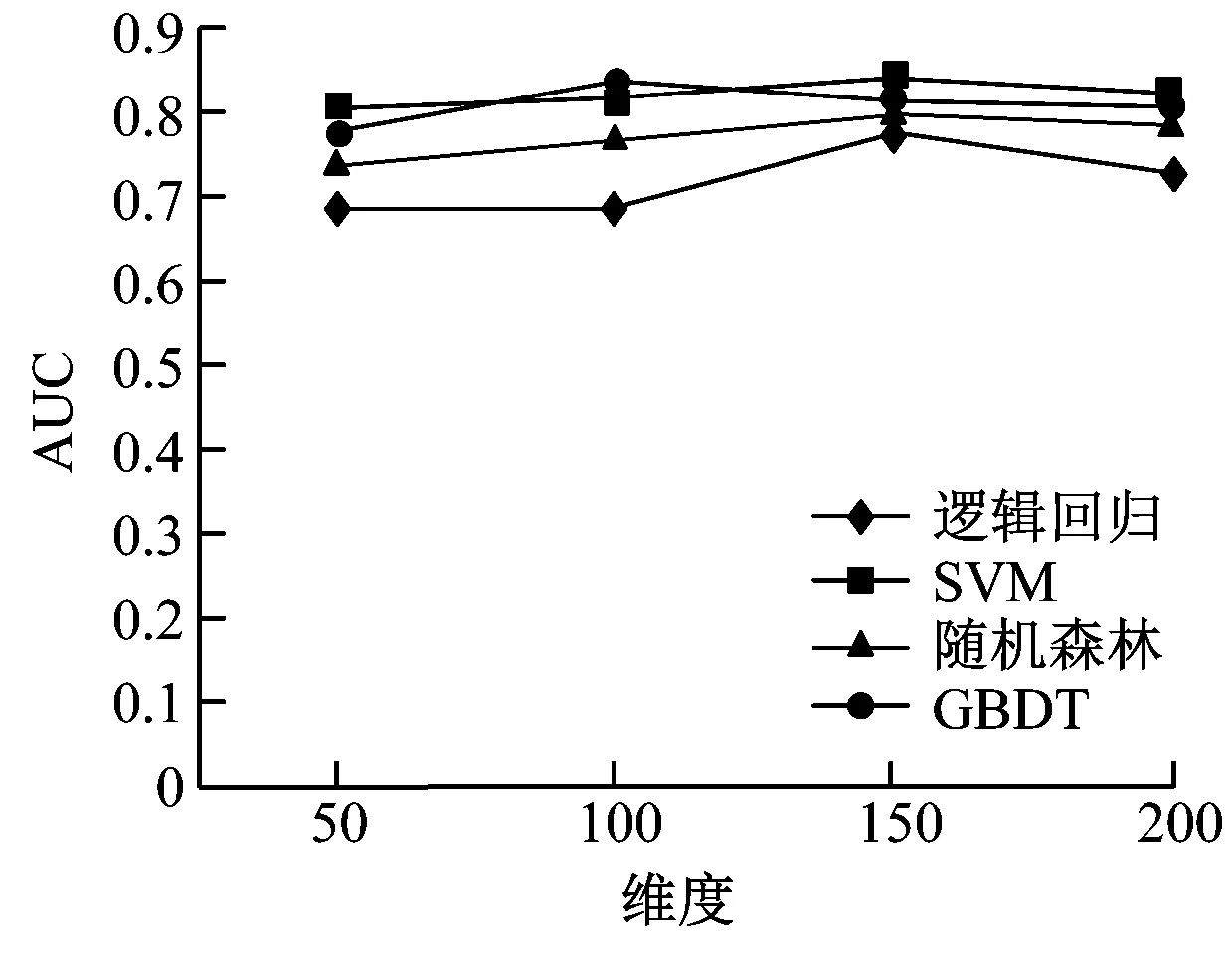
本次研究的训练数据来源于CSDN训练集,其中包括1.5万篇语料,数据集大小为4.4G。分别构建了50、100、150、200维度作为特征长度的选取,固定word2vec特征长度为50,LSA特征长度为10,再应用分类算法分类词语。在每一次训练测试中均采用同一台计算机以及相同的数据集。训练测试结果如图4所示。
(b) 空间随维度的变化图
(c) 准确率随维度的变化图
(d) F1值随维度的变化图
(e) AUC值随维度的变化图
(f) 准确率随维度的变化图-以10为步长
(g) F1值随维度的变化图-以10为步长

(h) AUC值随维度的变化图-以10为步长图4 训练测试结果
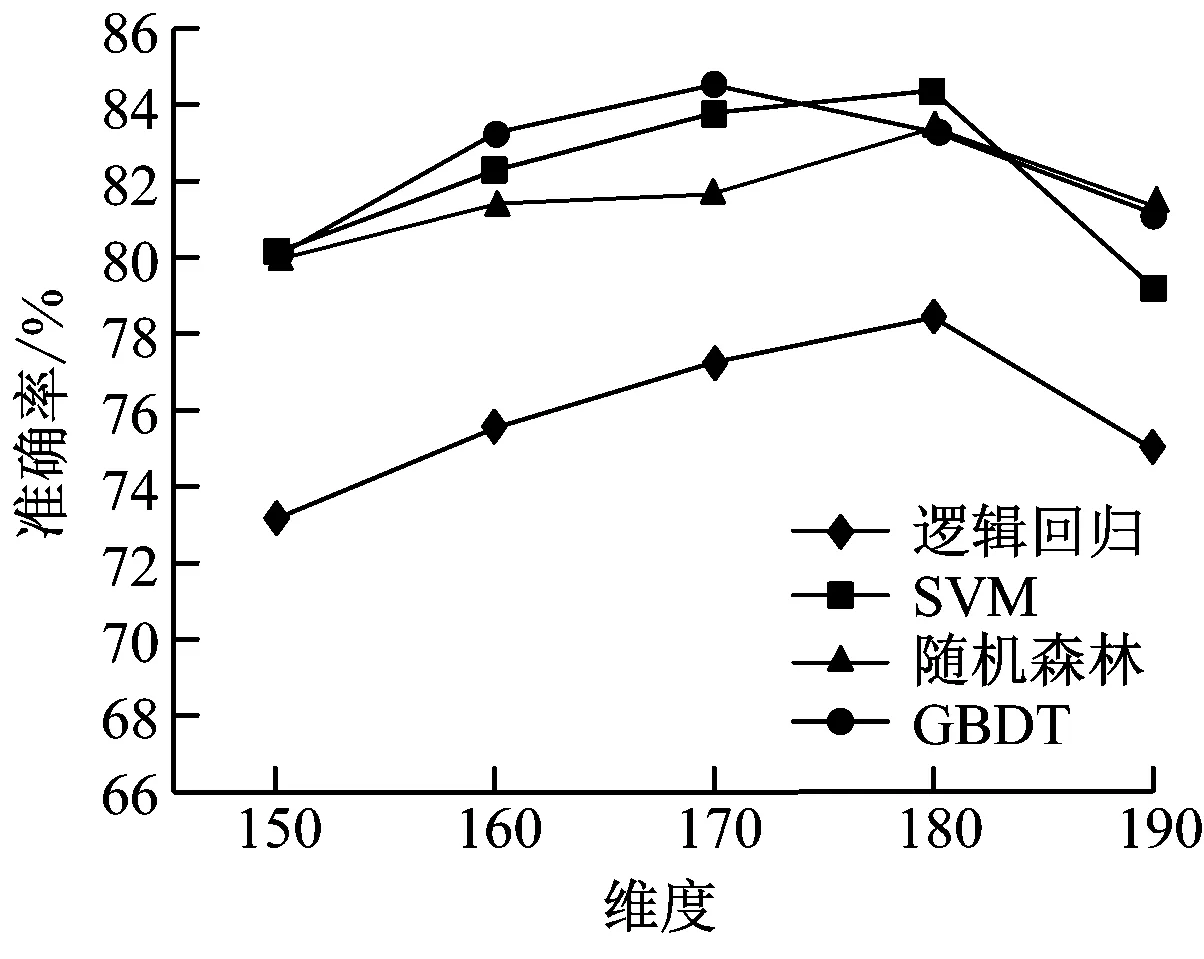
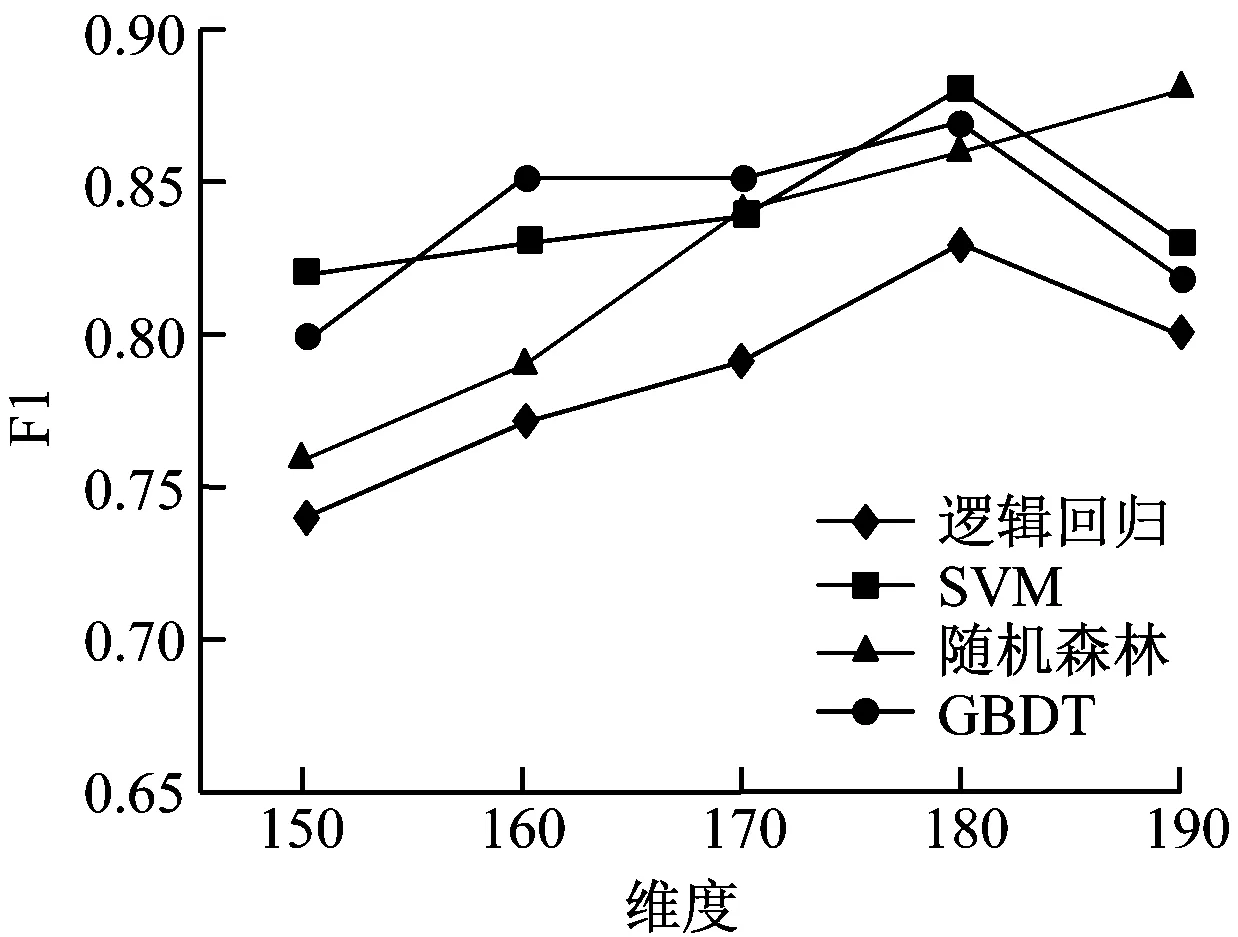
由图4(a)~图4(e)可知,各个算法在50、100、150维度时,AUC值、F1值与分类准确率均呈现上升趋势。但是在200维度时,各测试值均呈现下降趋势,主要是维度提升后造成了模型的过度拟合。所以可以判断出Textrank与tf-idf算法的最优特征维度在150~200之间。本次测试将维度间隔调整至10进行迭代计算,结果如图4(f)~图4(e)所示。由图4可知SVM算法最为稳健,AUC值、F1值与分类准确率均保持相对较高,其他算法则相对较差,表现不如SVM,且具有较高的运算复杂度。因此,本次研究基于二分类模型选择的组合特征长度为180维度,应用SVM作为模型分类算。
在前文中构建的二分类模型在被调整到参数最优时,能够准确地提取关键词。所以本次研究将重点测试基于关键词的关键句提取能力,并将测试结果与传统算法进行比较。测试语料采用LCSTS集合中的数据源,LCSTS数据集中含有约200万个中短文本,同时提供了人为标准的摘要,该数据集很符合本次研究的测试工作。为了测试所设计的摘要算法的优越性,本次研究引入传统的Textrank、tf-idf算法,将这两类算法使用同样的评判标准与设计算法进行对比。
本次研究在进行测试时,主要是给出了人工标注的测试数据集,以便测试二分类模型中的摘要算法,并应用Edmundson评分标准进行标注评判。Edmundson评分标准是将目标文摘与算法生成文摘的共同句子数进行对比,根据对比结果给出评分。Edmundson具体评分的方法是先拆分句子,主要由标点符号来进行拆分。在将句子抽取后,Edmundson可以被定义为式(10),
(10)
式中,|T|表示目标文摘中句子总数,|S|表示匹配上的句子总数。基于Edmundson评分标准,本次研究综合考虑了算法对系统资源的占用情况,对算法进行了客观评价,以判断本次研究能否达到设计要求。
本次研究在LCSTS集合下进行了10次实验,每次实验均随机抽取LCSTS集合中的10 000条数据,用以对二分类模型、Textrank、tf-idf进行评价,最后通过10次实验结果综合评价各个算法的效果。3种不同算法在10次实验中的平均Edmundson值关系,如图5所示。
由图5可以看出,本次研究提出的有监督的二分类模型提取文摘的质量最优,主要的原因是该算法可以应用自身已有的模型进行文摘提取,从而节约了大量的时间。进一步对3种算法的平均模型的时间消耗与空间消耗进行对比,结果如图6所示。
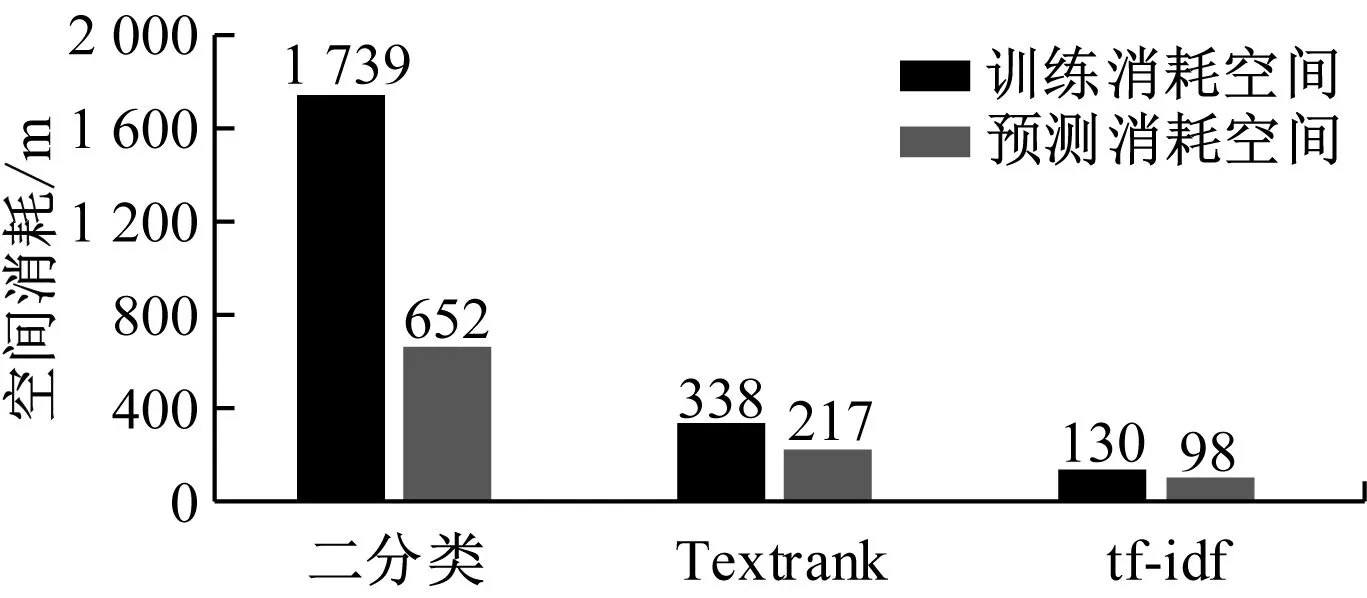
(b) 三种算法平均模型空间消耗对比图6 三种算法的平均模型的时间消耗与空间消耗对比
由图6可知,Textrank和tf-idf算法均为输入无监督型算法,时空消耗大部分为训练数据的切词、预处理和先行词频统计等。而本次研究提出的基于二分类模型为监督型学习算法,在进行模型构建时,会不断地调整模型参数,造成大量时间的耗费。因此模型的时间消耗与空间消耗测试结果显示,2种无监督的学习算法时空消耗均远远小于二分类模型。但是二分类模型所消耗的时间基本上花费在了算法的训练学习中,所以二分类模型只要能够训练出适合的参数,就能够准确地预测到新数据。因此在后续预测过程中,有监督的二分类模型只需根据构建好的词向量步骤进行预测数据,大大减少了测试所耗费的时间。从预测的效果来看,本次研究提出的二分类模型将语义特征与数据统计特征进行了有机融合,可以更优地评价关键词语的权重,使得关键词的获取更加可靠,并且测试过程中受到数据影响波动非常小,这也是本次设计优于其他模型的特点。
2.2 不同算法间的性能对比分析
为了验证本次研究提出的有监督二分类模型的有效性,选取了袁桂霞等[6]提出的有监督词袋模型进行了算法性能对比。并通过平均检索耗时(ART)与平均精确度均值(mAP)两项指标对算法的性能进行评价。本次测试的数据库选取了某新闻平台的数据库,该数据库包括了9项类别,共约17 640个数据,如表1所示。
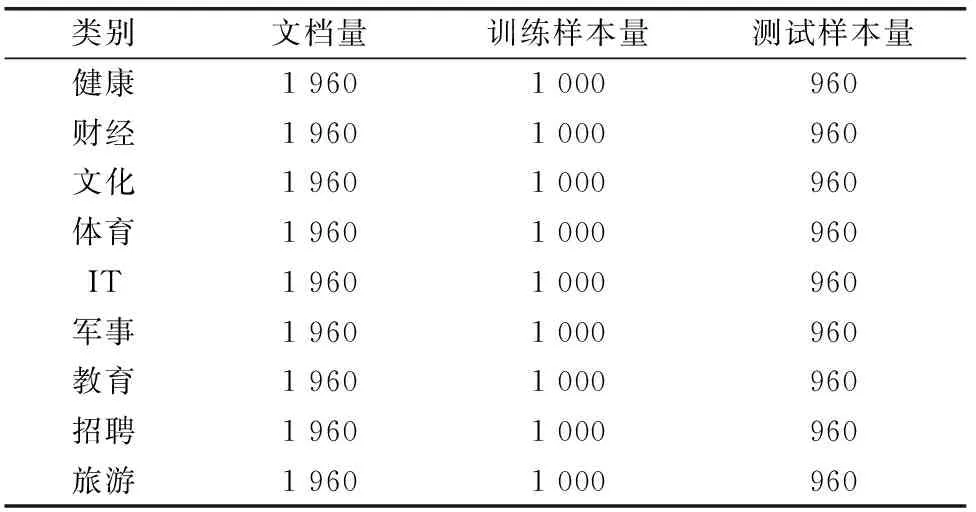
表1 某新闻平台的数据库类别及数量
此次研究选取了文档数据的前1 000个样本作为训练样本数据,剩下的960个样本作为测试样本,并给出了不同码本尺寸下的2种算法模型的ART与mAP指标对比结果。测试结果如图7所示。
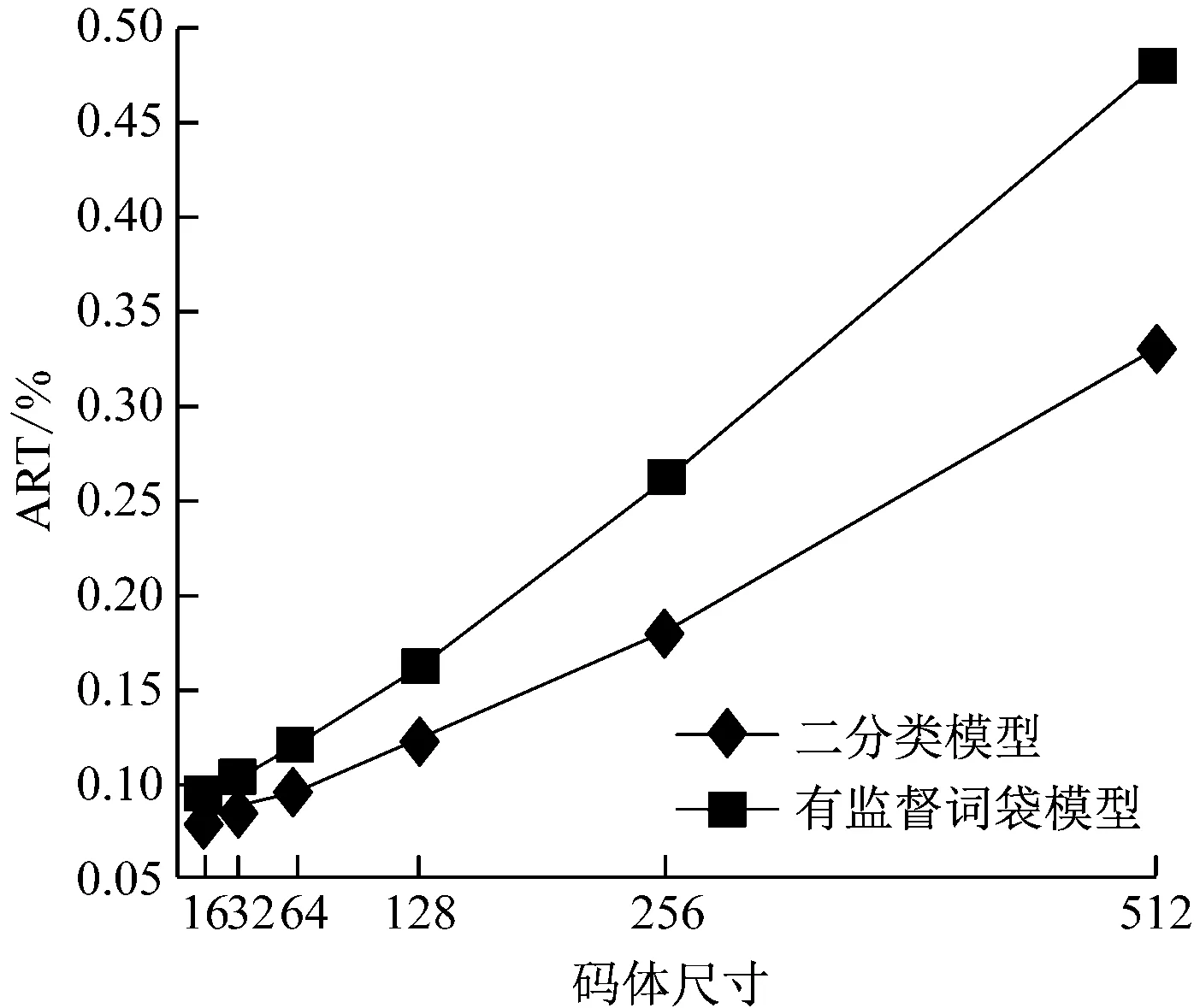
(b) ART指标对比结果图7 两种算法平均检索耗时(ART)与平均精确度均值(mAP)指标对比结果
由图7(a)可以看出,在不同的码本尺寸条件下,二分类模型的检索精度明显优于有监督词袋模型,主要原因为二分类模型在进行模型构建时,会不断地调整模型参数,在最优化问题求解过程中不易陷入局部最优,同时二分类模型只要能够训练出适合的参数,就能够准确地预测到新数据,提升模型的区分能力,因此二分类模型的检索精度指标得到提升。由图7(b)可以看出,二分类模型的检索时间同样明显优于有监督词袋模型,主要是由于二分类模型只需根据构建好的词向量步骤进行预测数据,大大减少了测试所耗费的时间。
3 总结
此次研究针对电子档案管理方面的内容,应用了基于二分类模型的优化技术对提出的电子档案管理方法进行了测试研究。研究结果显示,基于二分类模型选择的组合特征长度为180维度,应用SVM作为模型分类算;本文提出的有监督的二分类模型提取文摘的质量最优;无监督的学习算法时空消耗均远远小于二分类模型;二分类模型只要能够训练出适合的参数,就能够准确地预测到新数据;并通过性能测试得出,在不同的码本尺寸条件下,二分类模型的检索精度和检索耗时明显优于有监督词袋模型。本次研究提出的二分类模型将语义特征与数据统计特征进行了有机融合,可以更优地评价关键词语的权重,使得关键词的获取更加可靠,并且测试过程中受到数据影响波动非常小,这也是本次设计优于其他模型的特点。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
当代陕西(2022年4期)2022-04-19
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
当代陕西(2020年22期)2021-01-18
中华诗词(2019年7期)2019-11-25
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
