
基于热点访问的分布式数据库HBase负载均衡算法研究
2022-07-12 04:53李峻屹
微型电脑应用 2022年5期
李峻屹
(陕西警官职业学院,信息技术系, 陕西,西安 710021)
0 引言
随着信息技术的普及,日常生活中的各个领域都离不开信息化系统,系统运行需要进行海量数据的存储及读取操作,单一计算机无法实现高效处理,在这种背景下分布式数据库应运而生。分布式数据库将物理上集中的数据库分散为多个数据存储单元存储于多个存储节点之中,利用网络将存储节点连接起来组成分布式数据库。这种方式具有更高的处理性能,但由于每个节点的访问频率不同容易导致部分节点负载过重、性能下降甚至崩溃。因此,需要设计良好的负载均衡策略,利用均衡分配提升分布式数据库的稳定性。本研究以HBase开源分布式数据库为例,研究一种改进的负载均衡算法,以此规避节点崩溃风险、提升分布式数据库的安全性。
1 核心理论及技术简介
1.1 HBase简介
HBase是利用BigTable思想实现分布式面向列的数据库,在Hadoop上实现了类似于BigTable的存储功能,具有多维、稀疏、持久化映射等特性,在非结构化数据的存储方面具有高可靠性、高性能以及高伸缩性,在大规模集群中应用广泛[1]。
1.2 HBase数据格式
某种意义上来讲HBase可以看作巨大的表,通过行键Rowkey、列族ColumnFamily、时间戳Timestamp等实现信息检索,在缺失时间戳的情况下默认返回最新数据。利用JSON数据格式可直观展示HBase数据模型,JSON格式可表示为[2-3]
RowKey{
ColumnFamilyA{
ColumnX:
t2 value2
t1 value1
ColumnY:
t1 value4
}
ColumnFamilyB{
t2 value3
}
}
HBase分布式数据库在结构上包括客户端Client、分布式服务组件ZooKeeper、主服务器Master、Region Server服务器以及文件系统hdfs 5个部分组成。总体架构如图1所示。其中,Client负责与Master、Region Server进行通信,ZooKeeper负责节点监控状况感知、同步及配置管理等服务,Master负责集群负载均衡管理,Region Server Cluster负责Region的读写,实现数据处理。Region是HBase中的基本单元,由Store组成,分布于集群的各个节点之中,每个Region扩大到一定大小之后会进行自动拆分。Store作为Region的存储单元主要包括MemStore和StoreFile。接收到写入请求时,数据线写入MemStore,达到阈值后再存入HFile[4-5]。
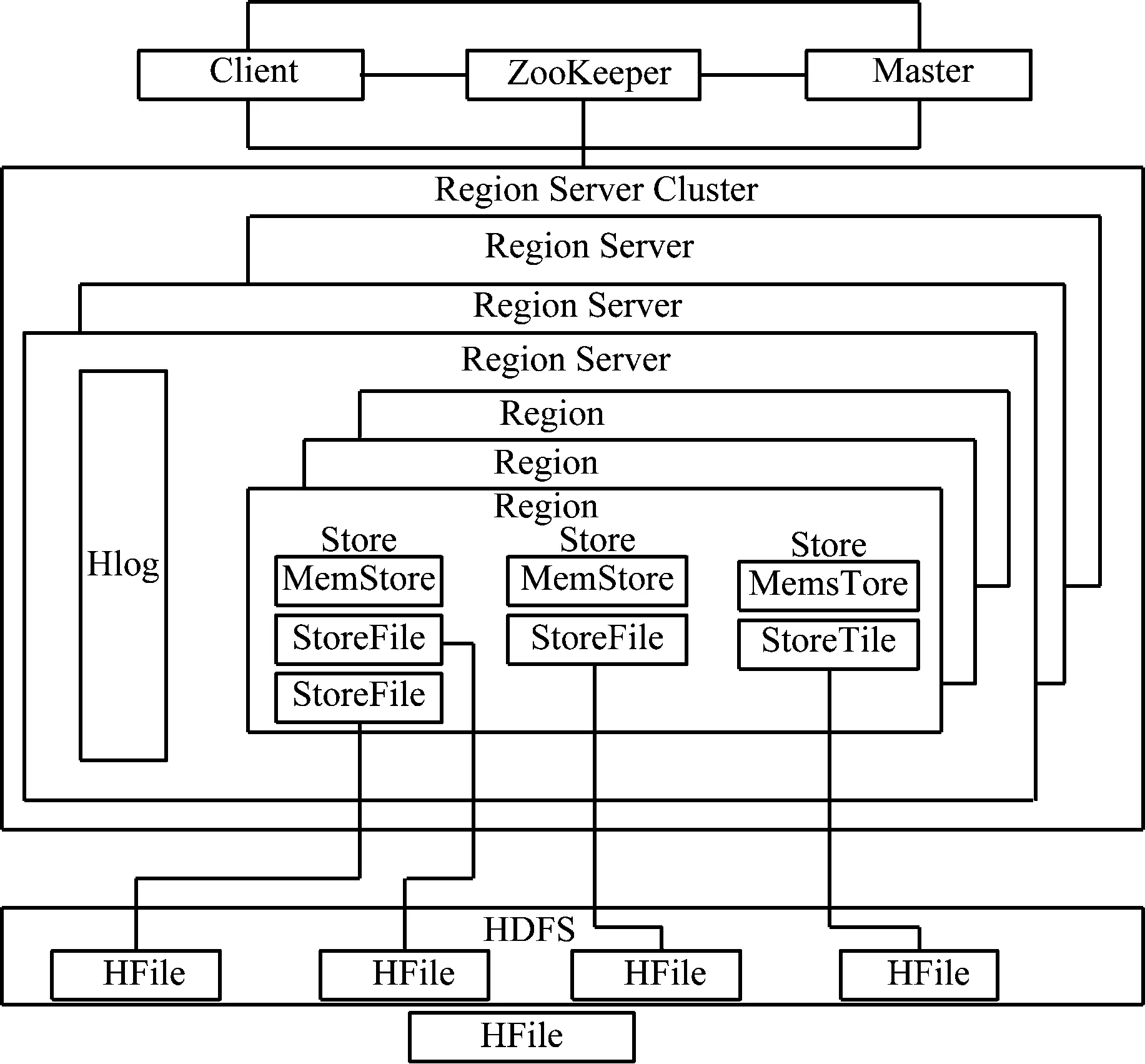
图1 HBase架构
1.3 负载均衡分类
目前市面上存在多种负载均衡产品,从不同的侧重点实现不同场景下的均衡算法,常用的负载均衡技术包括以下几类。
(1) 软件和硬件。硬件方式主要是增加节点数量,一方面增加了成本,另一方面也造成资源浪费;软件方式主要是利用均衡算法进行负载分配,成本低且易实现。
(2) 本地和全局。本地方式是节点均在本地,通过设备搭建排除节点故障;全局方式则是节点处于不同位置,适用于各地均存在设备的大型公司。
(3) 网络。网络层是OSI的7层网络模型根据不同层面制定不同的负载策略。
(4) 链路。将网络中多条链路看做一条,根据IP匹配运营商接口进行分流。
因此,综合对比之下,本研究采用软件方式利用算法实现HBase分布式数据库的负载均衡。
2 HBase原有负载策略及缺陷
2.1 HBase原有负载策略
HBase原有负载策略主要调整集群节点的Region数量来实现。首先,筛选出负载过重或空闲的节点。然后,利用迭代的方式调整节点Region进行交换或者迁移,根据判定因素保留有效调整,在调整后各节点的数值近似时完成负载均衡。通过使用空间总和、节点数量计算单个节点在均衡后的目标空间使用率如式(1)[6-7],
(1)
式中,avgcnt为空间利用率,regioncount为区域空间,servercount为节点数量,利用配置项slop计算阈值的上限ceil与下限floor:
floor=Math.fioor(avg_cnt×(1-slop))
(2)
ceil=Math.ceil(avg_cnt×(1+slop))
(3)
以此上下限阈值进行筛选,将筛选出的节点作为一个逻辑新集群,利用迁移计划表记录Region的迁移及交换情况。设目前集群状态值为cost,cost值的计算包括3个影响因素:
(4)
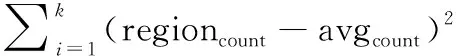
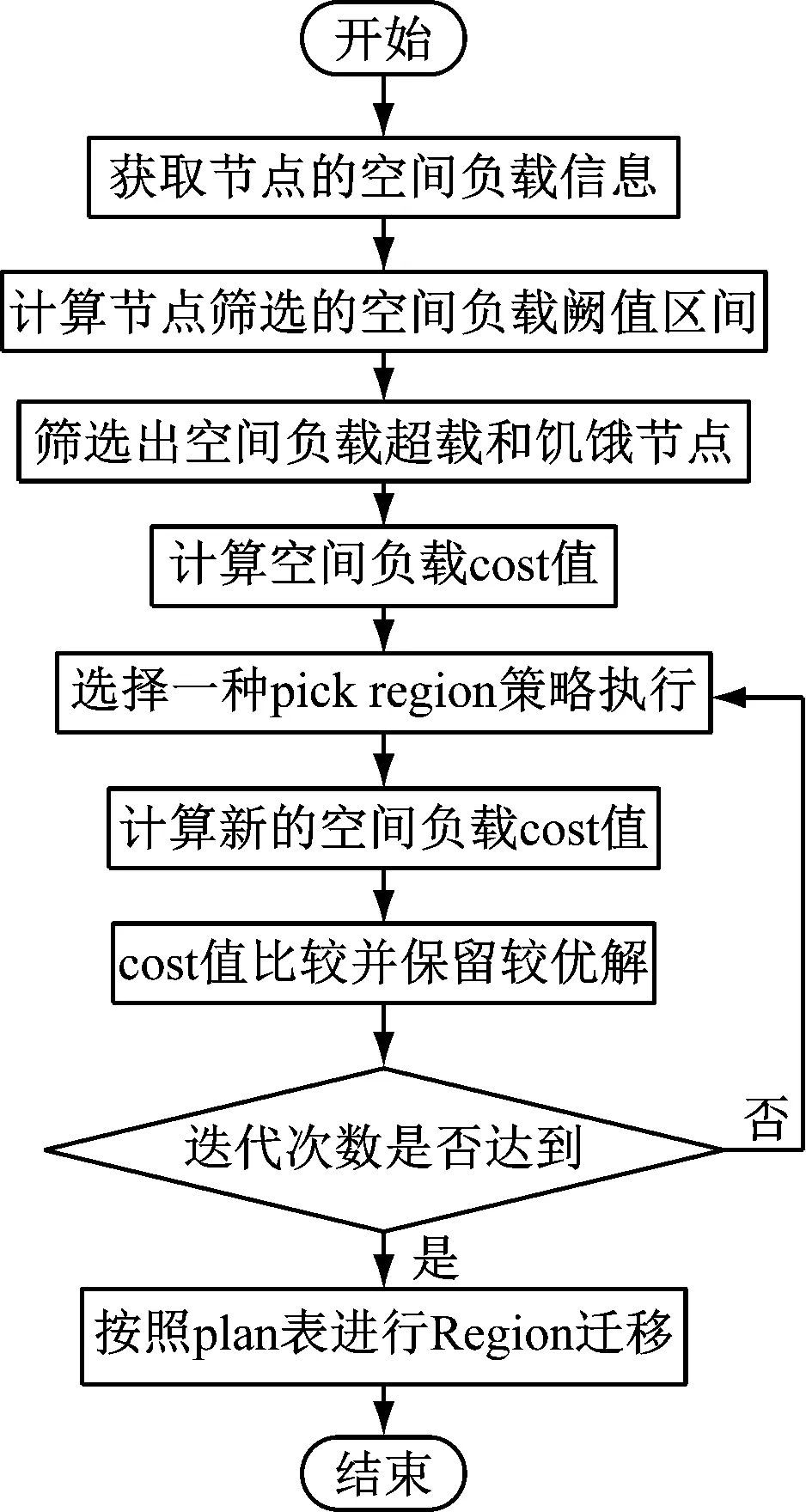
图2 原有策略算法流程
2.2 原有策略缺陷
HBase的原负载策略必须是3个重要环节都不出差错才能实现均衡,在策略上存在缺陷:首先,节点筛选过程必须找出全部的空闲及过载节点;其次,需要根据当前准确负载情况才能确定判定因素;最后,迭代方式的选择需考虑计算过程中的潜在问题,但它只考虑分布式数据库集群节点的空间负载情况,未考虑节点存在热点访问的情况。
3 基于热点访问改进的负载均衡算法设计与实现
3.1 改进算法流程
针对原有策略的缺陷,基于热点访问对负载均衡算法进行改进。首先根据热点访问负载情况筛选出需要调整的节点,然后再进行region调整。与此同时,判定因素也基于热点访问进行确定,迭代时以不破坏已有环境为前提逐步进行调整与优化。改进的方面主要包括以下几点。
(1) 信息采集时既需要收集region count,也需要收集节点的request数,并且记录region与request的关系。
(2) 针对原算法中最终集群以及初始集群里未筛选到的节点,再次计算request per second值以及floor_req、ceil_req值如式(5)~式(7):
(5)
floorreq=avgreq×(1-reqslop)
(6)
ceilreq=avgreq×(1+reqslop)
(7)
其中,server_count为节点数量,floorreq、ceilreq为是否需要进行负载调整的阈值下限与上限,avg_req为空间利用率负载,reqslop为配置项。
(3) 计算集群状态cost值时,除了region迁移成本和region本地化成本之外还要考虑热点访问的负载情况,采用加权平方和进行计算[8-9],即:
(8)
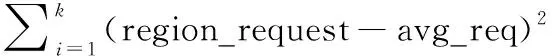
(4) 选择策略时cost值计算依然沿用原有方式:计算新的cost值与前值比较,保留有效调整存于迁移计划表。
(5) 重复改进策略直至迭代次数,按照迁移计划表执行即可[10-11]。
整体改进后基于热点访问的负载均衡算法流程如图3所示。
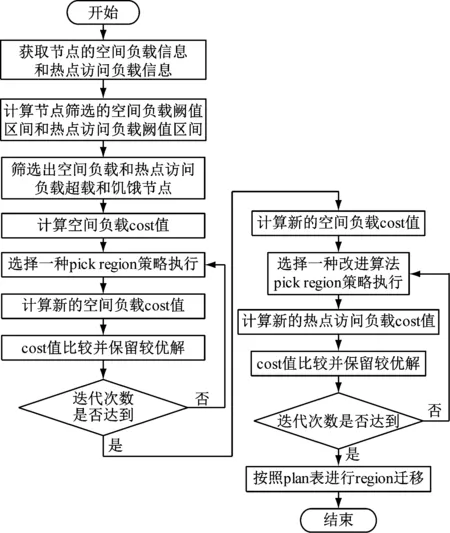
图3 基于热点访问改进的算法流程
3.2 算法实现
在算法实现上基于热点访问的负载均衡算法主要包括采集模块、处理模块及迭代模块3个部分。首先,采集模块负责收集节点的count数、request数并与region对应;其次,处理模块负责计算阈值对节点进行筛选并将request值进行记录,request表结构如表1所示。其中,第一横行为region_id,regionx_x代表节点,第二行为region在上一时段的request数量,最后一行为region在当前时段的request计数器,随读写次数而增加。在一个采集时段结束之后,利用request cnt数据更新request值并将request cnt置为0。最后,迭代模块计算cost值并实现数值对比后选择策略进行迭代[12-13]。

表1 request表结构
4 改进算法效果验证
4.1 验证环境准备
为了验证改进负载均衡算法的有效性及算法的均衡效果,通过虚拟机VMware搭建Hadoop集群环境进行测试,版本采用HBase1.2.6,各个节点Master、S1、S2、S3分别分配置20G空间、1G内存。
采用原负载策略与基于热点访问改进的算法进行对比分析,利用同样的shell读写数据,确保2种算法的初始数据一致[6]。
4.2 验证结果对比分析
对3个节点分别写入数据,采集region与request值,得到在负载均衡前后2种算法各个节点的region count数量与request数量对比结果如图4和图5所示。
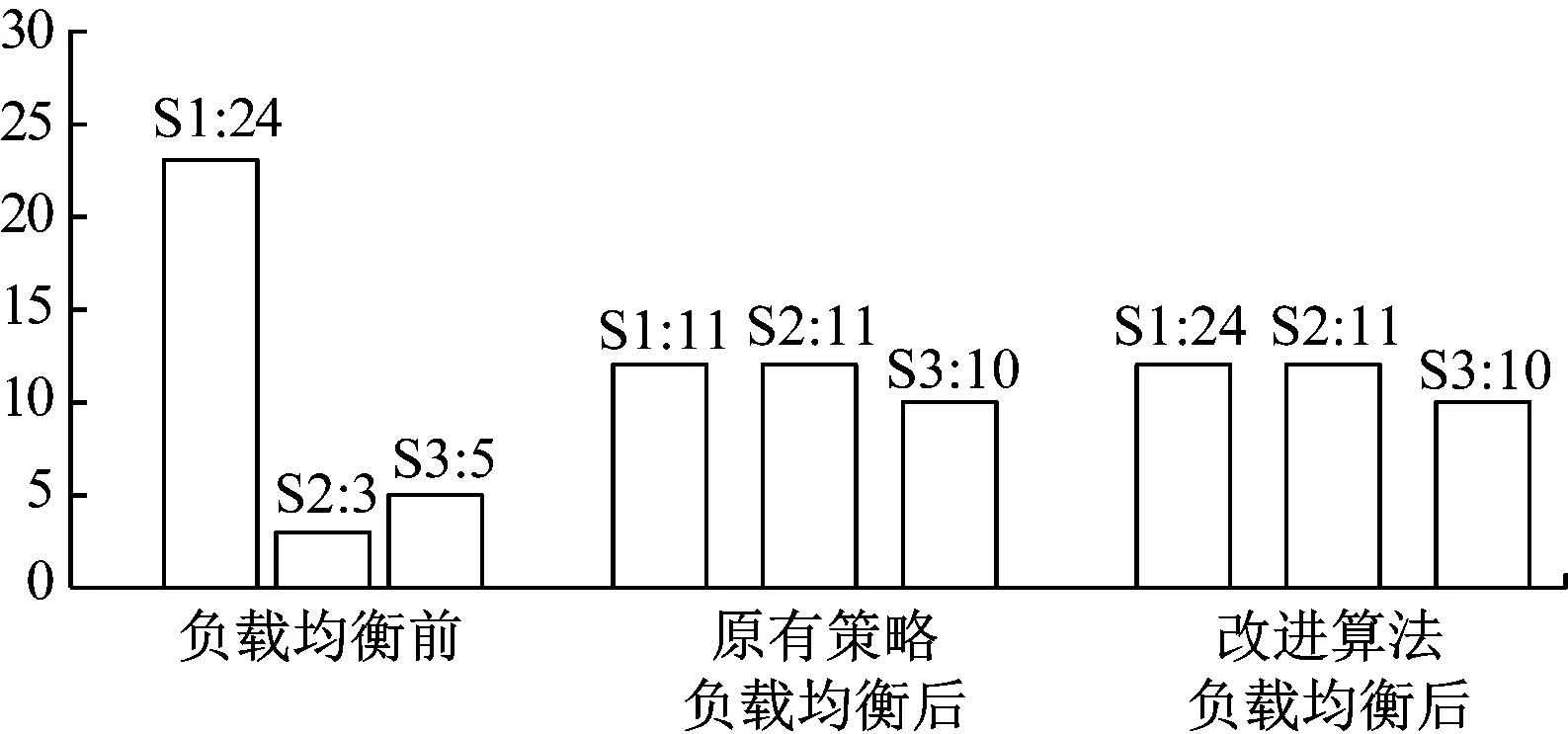
图4 region count值对比结果
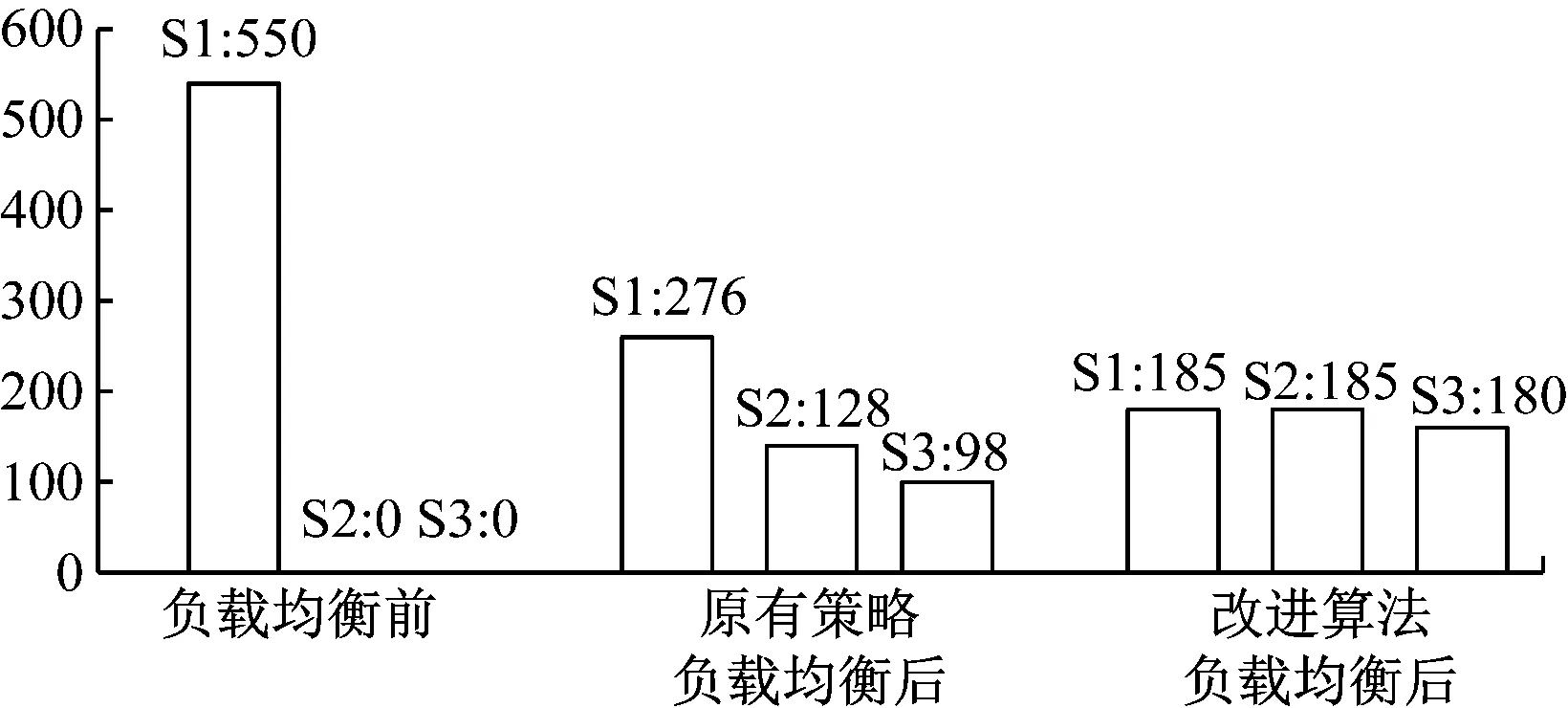
图5 request值对比结果
由图4可知,未执行负载均衡前各节点的region count数量相差较大,进行负载均衡后2种算法都达到了较好的均衡效果。由图5可知,若利用shell脚本只对S1节点读写数据(即S1节点处于热点访问)时,原策略不能达到均衡状态,而改进的算法各节点的request值相差不大,均衡效果更好,性能更为优异[14-15]。
5 总结
本研究分析了HBase数据格式及系统架构,通过比较当前负载产品的优缺点,最终选择软件方式对HBase数据库进行负载均衡,根据原有策略的缺陷提出了基于热点访问的改进算法。经过验证与分析,改进算法负载均衡效果更佳。但也有不足之处,改进算法是以集群中各节点的性能一致为前提,未考虑节点自身性能的差异。后续将继续研究节点性能的评估算法,改进算法在节点自身性能不同情况下的均衡策略。
猜你喜欢
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
煤气与热力(2021年9期)2021-11-06
军民两用技术与产品(2021年5期)2021-07-28
智能计算机与应用(2020年4期)2020-08-31
软件(2020年3期)2020-04-20
电子制作(2019年22期)2020-01-14
车迷(2019年10期)2019-06-24
快乐语文(2018年7期)2018-05-25
