
基于FPGA的千兆以太网数据通信接口设计与实现
2022-07-12 04:53:46魏晓艳
微型电脑应用 2022年5期
魏晓艳
(陕西国防工业职业技术学院,计算机与软件学院, 陕西, 西安 710300)
0 引言
传统的设备或系统平台之间的数据通信通常由并行总线的方式实现,但随着系统的集成化发展,算法日渐复杂,数据量日益增长,系统功能需要多个芯片协同处理共同支撑。这种情况下并行总线无法满足数据吞吐量要求,对整体性能反而是一种制约。FPGA利用串行并行转换、数据时钟恢复等技术避免了传输过程中的时钟扭曲以及信号衰退等因素的影响,实现了以太网接口的高速传输,为高速以太网接口提供了可靠的解决办法。
1 核心技术简介
1.1 以太网技术
以太网是目前局域网中最常见的通信协议标准,包括10 Mbps、 100 Mbps、1 000 Mbps、10 Gbps等。其中,千兆以太网作为高速以太网技术应用最为广泛,既传承了之前的技术优势,又具备自身独特特性,采用8B/10B编码规则适应光纤传输要求,采用载波扩展技术实现距离覆盖,采用帧突发技术提升效率。
根据OSI标准,基础的七层网络模型包括物理、数据链路、网络、传输、会话、表示及应用层。在以太网的层次架构中,核心技术体现在数据链路层,主要包括接入控制MAC层、逻辑链路控制LLC层。MAC层主要实现将用户自定义格式封装为标准的以太网数据帧以及进行地址过滤实现访问流量管控,是确保数据传输可靠性的关键。
1.2 FPGA技术
FPGA(Field-Programmable Gate Array)也称为可编程门阵列,与传统的微处理器相比,FPGA技术克服了定制电路的缺点,采用逻辑单元阵列的概念利用并行传输实现高速传输及信号处理,在资源复用、嵌入式处理器、微控单元方面应用广泛。
2 需求分析及总体设计框架
2.1 简化的UDP/IP以太网协议栈
目前TCP/IP网络协议应用最广,主要包括TCP、IP、IGMP、UDP等协议。TCP协议需完成3次握手且需要包括数据重传,在硬件实现上难度较高。相对来说,UDP协议占用资源少,逻辑简单,因此传输层选择UDP协议,网络层选择IP协议用于格式封装,同时去掉UDP和IP的首部,只保留数据包以降低硬件开销[1]。基于简化的UDP/IP协议栈的以太网格式如图1所示。其中,传输层、网络IP层、用户层为处理用户逻辑的上层协议,数据链路层为以太网MAC层。

图1 简化的协议栈格式
2.2 接口需求分析
FPGA利用自身硬件加速及并行处理的优势在大规模信号处理方面应用广泛,但对于复杂的数据处理并不擅长,但PC具备这种数据处理能力。基于此背景,设计一种嵌入式的数据通信接口将以太网接入系统平台,通过高速以太网接口将数据传送至PC,由PC完成复杂运算。利用Xilinx的TEMAC核结合自定义简化协议栈,实现系统平台与PC间的高速数据传输。
2.3 基于FPGA的高速以太网接口总体设计框架
为了完成整体的高速以太网数据通信接口,不仅要实现链路层的MAC控制和物理层的收发,还需要实现对用户逻辑部分的上层协议处理。基于简化后的UDP/IP协议栈,设计数据通信接口的总体框架包含3个部分:上层协议的数据包封装与解析、数据链路层的MAC控制器、物理层的GTX收发器,设计框架如图2所示。其中,物理层采用Xilink 7系列的FPGA中GTX收发器内置的串并转换、线路编码、时钟修正以及数据恢复等功能电路实现物理层传输[2],因此本研究着重研究上层协议的数据包封装与解析和数据链路层的MAC控制器。
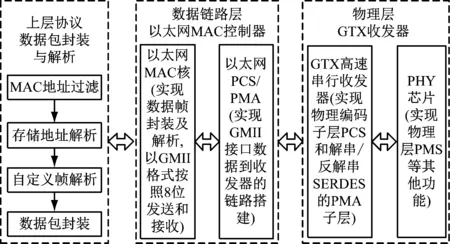
图2 高速以太网接口总体设计框架
3 上层协议的数据包封装与解析
上层协议的用户逻辑处理主要包括MAC地址过滤、存储地址解析、自定义协议解析以及数据包封装4个部分。MAC地址过滤只接收与FPGA端的MAC地址匹配的数据包以实现地址过滤;存储地址解析实现PC端MAC的提取和储存;自定义协议解析实现数据字节拆解,结合PC端MAC地址作为数据发送的目标地址;数据包封装在创建初始数据帧的基础上完成增加目标地址、帧类型等处理动作后进行数据传输。
3.1 MAC地址过滤
在数据帧rx_axis_mac_tdata中利用字段Address Field存储接收数据目标主机的物理地址。rx_axis_mac_tvalid代表MAC输出是否有效,FPGA端接收之后检查目标地址pkt_mac_reg,判断与自身地址my_mac相同则作为接收数据包去掉14个字节的帧头接收之后的有效数据。不相同则进行复位[3]。整体过滤流程如图3所示。

图3 地址过滤流程
3.2 存储地址解析
去掉14字节帧头之后的有效数据存储于64位寄存器out_cmd_i[63:0]之中,预先定义好存储方式dest_mac_redister[47:0],比较out_cmd_i[63:0]中地址字节out_cmd_i[59:32]和预先地址字节ADD_DEST_MAC_L/H。如果与ADD_DEST_MAC_L相同,则FPGA端的数据包发送目标地址的低32位,如果与ADD_DEST_MAC_H相同,则FPGA端的数据包发送目标地址的高16位,最终解析出PC端的MAC地址,存储在dest_mac_redister[47:0]之中。
3.3 自定义帧解析
去掉帧头后的有效数据包括1个字节的操作类型OPCODE、1个字节的信道编码Channel Num、4个字节的数据块大小Block Size、4个字节的帧起始位置Start Address,34个字节的填充Zero Padding[4]。在接收到存储地址解析模块的PC端MAC地址,将其作为发送FPGA端的目标地址之后,读取数据库的帧字段里的Channel Num、Start Address、Block Size字段,将这3个字段加在数据包前端作为控制信息后发送响应包至PC端。
3.4 数据包封装
由于以太网的数据链路层最终输出是8位的GMII数据,因此需将64位数据进行拆分,每个时钟周期传输8位,以tx_axis_mac_tdata代表封装好的标准数据帧,op_code代表操作类型,out_data_reg代表待发送数据包[5]。整体封装过程如图4所示。

图4 数据包封装过程
4 数据链路层高速以太网MAC控制器
数据链路层的高速以太网MAC控制器采用GTX串行收发器与外部PHY芯片进行连接,基于TEMAC嵌入式三态以太网MAC硬核实现,控制器整体实现过程如图5所示。
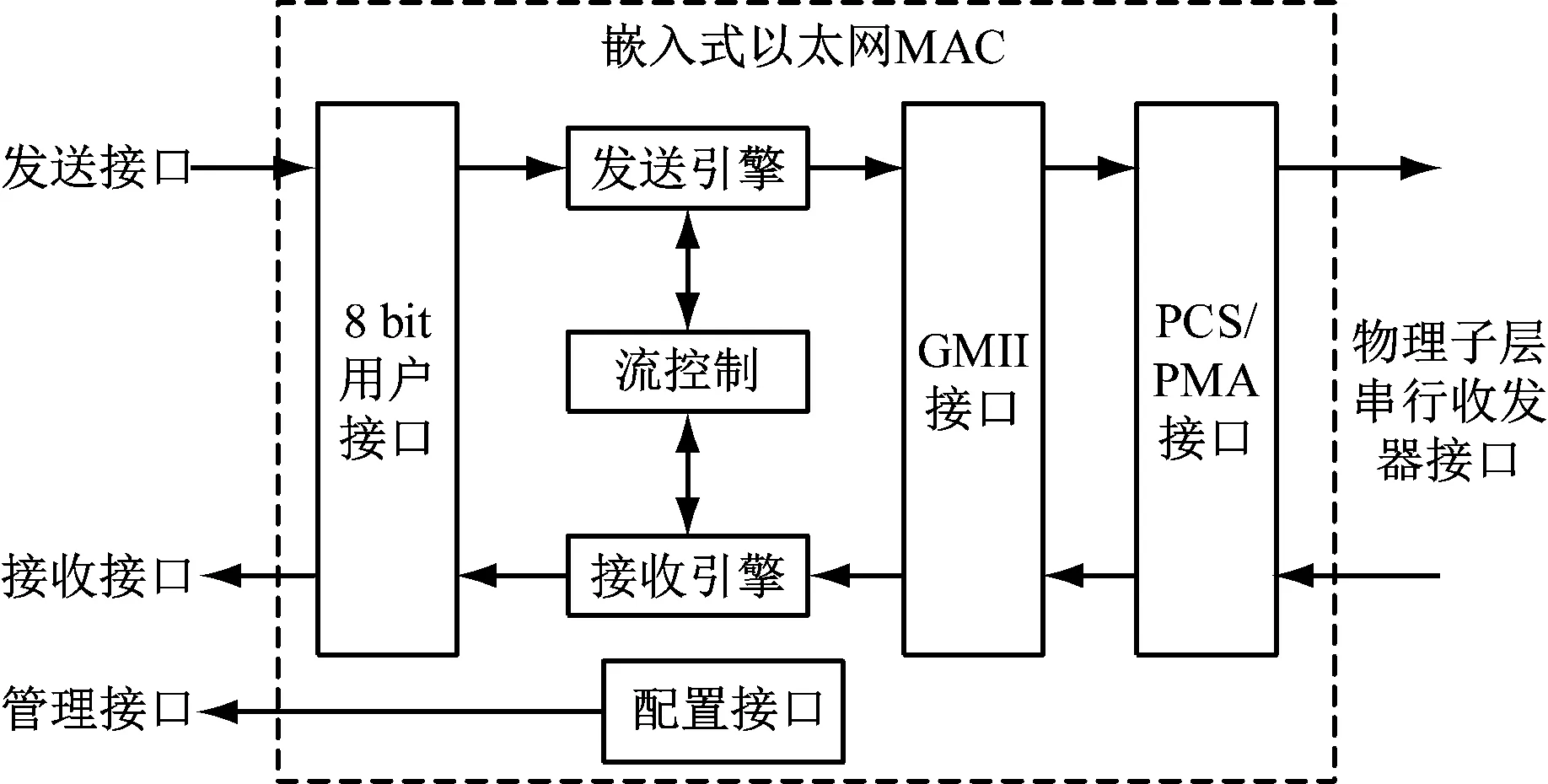
图5 以太网MAC控制器
(1) 接收接口:接收数据后判断是否符合协议标准,去除添加区域,提供接收结果信号。
(2) 发送接口:在待发送数据前增加前导编码Preamble、起始符SFD、校验序列FCS以及填充字段Pad使数据满足以太网帧的长度规范。
(3) 8 bit用户接口:为了支持GMII接口协议,用户接口采用8 bit接口。
(4) GMII接口:将数据转换为GMII格式,简化外部处理逻辑。
(5) PCS/PMA接口:与GTX收发器相连,将内部并行接口GMII转换为串行接口SGMII,利用串行收发器与物理层芯片通信[6]。
(6) 管理接口:采用AXI4-Lite总线实现寄存器配置。
5 通信接口测试
为了验证设计的高速以太网数据通信接口的功能以及性能,针对接口传输准确性以及传输性能2个方面进行了测试。PC端软件采用VS软件,在winpcap驱动的基础上构建数据包。FPGA端采用26 MHz地写时钟,输入数据流为416Mbps。对于传输的任意相邻数据进行差值运算,相差为1则认为连续,没有丢帧[7]。每个数据块由204 800连续数据构成,每个数据为2字节,则数据块大小为409 600bytes,得到输出数据块如下:
Blk Number=336
Prevblk last val=40204
currblk first val=40205
currblk 2nd val=40206
currblk 3rd val=40207
currblk 4 th val=40208
currblk last val=48396
Blk Number=337
Prevblk last val=48396
currblk first val=48397
currblk 2nd val=48398
currblk 3rd val=48399
currblk 4 th val=48400
currblk last val=56588
Blk Number=338
Prevblk last val=56588
currblk first val=56589
currblk 2nd val=56590
currblk 3rd val=56591
currblk 4 th val=56592
接下来将FPGA写时钟频率分别定为30.72和61.44 MHz,利用WireShark抓包工具抓取数据并进行统计分析,根据数据包总数、丢包数、传输速率等信息判断通信接口的性能情况[8]。在写时钟频率为30.72 MHz时,理论上的传输速度应为30.72 MHz×16 bit=491.52 Mbps,实际传输速率为488.82 Mbit/s,丢包率为3.6×10-6。在写时钟频率为61.44 MHz时,理论上的传输速度应为61.44 MHz×16 bit=983.04 Mbps,实际传输速率为942.21 Mbit/s,丢包率为0.23%。
由此可知,本研究设计的高速以太网数据通信接口在写时钟频率为26 Mhz时未出现丢包现象,在30.72 MHz时丢包率很低几乎可以忽略不计,在达到千兆极限的传输速率时,丢包率仅在0.23%,在预期范围之内。
6 总结
本研究基于FPGA技术在简化的UDP/IP协议栈的基础上设计了高速以太网MAC控制器,并对用户逻辑的数据包封装及解析进行了详细设计,经过测试验证接口准确性高、性能优异。但协议栈相对简单,TCP协议相较于UDP协议更为安全,后续将对TCP/IP协议栈进行深入研究,以期在硬件开销允许的情况下实现更安全更复杂的通信接口。
猜你喜欢
销售与市场(营销版)(2021年10期)2021-11-21 20:15:03
宁夏师范学院学报(2021年7期)2021-09-27 12:35:00
装备制造技术(2020年1期)2020-12-25 05:18:20
销售与市场(营销版)(2019年6期)2019-06-21 01:16:38
网络安全技术与应用(2017年9期)2017-09-20 09:54:28
电子制作(2017年24期)2017-02-02 07:14:44
长春工业大学学报(2016年1期)2016-05-07 01:50:03
电源技术(2015年7期)2015-08-22 08:48:48
中国交通信息化(2015年11期)2015-06-06 06:51:33
电子设计工程(2015年6期)2015-02-27 12:05:02
