
基于卷积神经网络的锚链闪光焊接质量检测方法
2022-07-12 14:03王真心苏世杰
计算机应用与软件 2022年6期
王真心 苏世杰
(江苏科技大学机械工程学院 江苏 镇江 212003)
0 引 言
锚链由许多个链环连接而成,是一种用来抵消与缓冲船舶和海洋工程平台所受外力的专用产品,其质量的优劣直接关系到相关人员的生命与财产安全。在锚链的生产过程中,闪光焊接是最重要的环节,直接决定了锚链的力学性能。对于锚链而言,即使只有一个链环因质量问题而产生断裂,整条锚链便会失效,其带来的损失将是巨大的[1]。
目前,主要通过出厂前的破断试验和拉力试验来检测锚链的质量。破断试验是指从锚链中抽取一定数量的试样,对其施加相应的破断载荷,若试样出现断裂的现象,则判定该锚链的质量不合格。拉力试验是指对锚链施加相应的拉力载荷,并测量其试验前后的长度,若永久伸长的长度超过原始长度的5%,则判定该锚链的质量不合格[2]。这种质量检测方法虽然直接、可靠,但使得替换不合格链环的成本异常高昂,且新替换链环的力学性能很难与其他链环保持一致。
由于锚链闪光焊接的焊口被封闭在链环内部,很难在焊接过程中对气孔、裂纹、夹渣等缺陷进行检测。另外,锚链闪光焊接时会发生变形、烧化、氧化等一系列复杂的物理化学反应,具有高度非线性,很难建立一个精确的模型对其焊接质量进行检测。对此,卢伟[3]基于模糊分类的理论,依靠经验设置了焊接数据的波动范围,当焊接数据超过合理范围时则判定为不合格,该方法只能粗略地对焊接质量进行检测,且具有很强的主观性和不确定性。
近年来,深度学习的优势逐渐体现,不仅突破了传统机器学习的瓶颈,还进一步推动了人工智能的发展[4]。如今,深度学习在图像识别、数据挖掘、计算机视觉、自然语言处理等领域都有着非常出色的表现,在质量检测领域,深度学习同样也得到了很好的应用。Moustapha等[5]利用循环神经网络建立了一种动态模型,实现了对无线传感器质量的检测。刘辉海等[6]为了对风机齿轮箱的质量进行检测,提出了一个基于深度自编码网络的模型,并利用玻尔兹曼机对参数进行预训练。Shao等[7]通过深度置信网络,准确地从复杂多样的振动信号中识别出滚动轴承的缺陷。对于锚链闪光焊接的质量检测,李俏[8]采用卷积神经网络的方法进行判断,虽在实验中取得了较高的准确率,但忽略了实际生产中不合格样本与合格样本在数量上的不平衡问题,且不能持续地对新样本进行学习。
数据不平衡的现象存在于人类生活的方方面面,而有用的往往是少数类。例如,在医学疾病的诊断中,患病的数量远小于正常的数量[9];在电信通信中,只有少数存在诈骗行为[10];在信用卡交易中,非法交易只占少部分[11]。在一些极端情况下,即使将所有的少数类都错分,模型总体的准确率也会非常高,但这样的分类结果是毫无意义的[12]。目前,针对数据不平衡问题,最简单的方法有两种:随机欠采样和随机过采样。随机欠采样通过减少多数类的样本来消除不平衡,但容易忽略样本中有用的信息。随机过采样通过复制少数类来增加样本数量,模型容易产生过拟合。SMOTE(Synthetic Minority Over-sampling Technique)是一种使用较广的采样方法,通过合成样本的方式使数据平衡[13]。
对于锚链闪光焊接来说,每天都有大量的新样本产生,若使用传统的批量学习来训练模型,对时间和空间的需求也会逐渐增长。但是当样本的数量非常庞大时,批量学习将无法完成模型的训练,而增量学习的出现为此提供了一种新的解决思路。增量学习和人类自身的学习模式非常类似,在已有模型的基础上,能够不断地学习新知识,并保留大部分已经学习到的旧知识[14]。
针对传统的破断试验和拉力试验不能及时准确地检测锚链闪光焊接质量的问题,本文提出一种基于卷积神经网络的检测方法。将反映锚链闪光焊接过程变化的电极位置曲线和电流曲线作为研究对象,结合锚链闪光焊接的特点,提出一种新的采样方法:最近邻拼接采样,使不合格样本与合格样本的数量相同。另外,对于新样本采用增量学习的方式进行学习。为了验证本文方法的有效性,对数据不平衡程度不同的样本进行对比实验,并比较批量学习和增量学习的分类效果。
1 锚链闪光焊接原理
闪光焊接是锚链生产中最为核心的工序,焊接过程中电极位置和电流的变化曲线如图1所示。在预热阶段,电极位置和电流都是呈周期性变化。在连续闪光阶段,电极位置的变化较为平稳,而电流上下波动。在顶锻阶段,电极位置先减小,并在一段时间内基本不变,最后变大,而电流在突然增大后骤减为零。锚链闪光焊接的流程如图2所示,包含预热、连续闪光和顶锻3个阶段[15]。
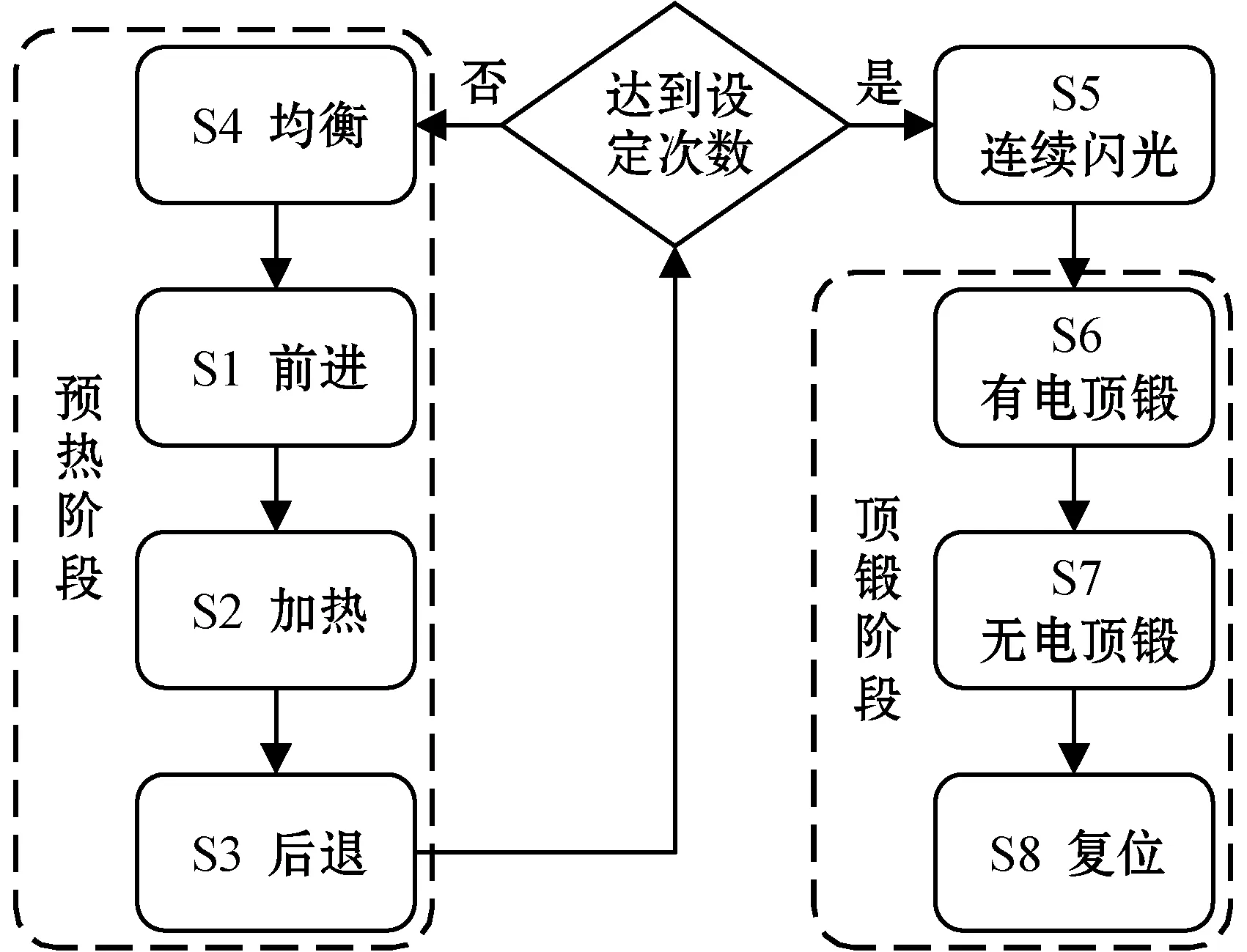
图2 锚链闪光焊接的流程
(1) 预热阶段由前进S1、加热S2、后退S3和均衡S4组成。当两个电极夹紧焊件的两端后,可动电极时进时退,前进时施加一定的力,使焊件的两个端面接触,形成短路并进行加热,后退时使焊件的两个端面远离。在均衡阶段,电极温度向纵深方向进行扩散,形成一定深度的塑性变形温度。重复这四个子阶段,当达到设定的次数后,便进入连续闪光阶段。
(2) 在连续闪光阶段S5,焊件的两个端面在可动电极的作用下靠近,形成许多细小的接触点,接触点在熔化的瞬间会激发电弧。随着可动电极的持续前进,焊件的温度升高,两个端面之间不断地有液态金属颗粒喷射出来,从而形成闪光现象。为了得到连续稳定的闪光,需要控制好可动电极的速度。
(3) 顶锻阶段由有电顶锻S6、无电顶锻S7和复位S8组成。顶锻刚开始时,可动电极会加速前进,并产生一个足够大的顶锻力,使两个端面间的距离迅速缩小,闪光现象也会突然停止。在闪光过程中产生的氧化物杂质和液态金属会被挤出,从而得到牢固的焊接接头。最后,将可动电极复位,一个完整的锚链闪光焊接流程便完成了。
有经验的焊接工程师往往能够根据曲线中出现的各种异常特征主观地判断锚链闪光焊接的质量是否合格,其中可能发生故障的信号特征主要有:预热阶段的曲线变化不均匀;连续闪光时发生多次中断;连续闪光的时间过长或过短;电极位置曲线不光滑等。
2 不平衡数据的预处理
如果将一般的分类方法直接应用在锚链闪光焊接质量的检测上,模型会更倾向于合格样本,而使不合格样本得不到很好的分类效果。因此,为了提高模型的整体性能,对不平衡数据进行一些适当的预处理就显得十分重要。本文通过最近邻拼接采样的方法来增加不合格样本的数量,同时为了使不同样本的数据长度一致,对样本进行分段线性插值。
2.1 最近邻拼接采样
最近邻拼接采样主要分为以下几个步骤:首先对不合格样本进行归一化处理,其次采用动态时间规整的方法计算不合格样本之间的距离,最后将距离较近的不合格样本拼接成新样本。
2.1.1归一化
归一化是一种无量纲的处理方法,消除了电极位置和电流之间的量纲影响,同时是简化计算的有效途径。本文采用min-max标准化的方法对样本进行归一化处理,公式如下:
(1)
式中:min表示样本中的最小值;max表示样本中的最大值;x′表示样本中x归一化后的值。
2.1.2动态时间规整
为了衡量不合格样本之间的相似性,采用动态时间规整(Dynamic Time Warping,DTW)的方法计算它们之间的距离[16]。对于序列p=(p(1),p(2),…,p(m))和q=(q(1),q(2),…,q(n))来说,需要构造一个m×n的距离矩阵D,其中的元素d(i,j)表示序列p中第i个点和序列q中第j个点之间的距离,计算公式如下:
d(i,j)=(p(i)-q(j))2
(2)
在距离矩阵D中,可以搜索到一条规整路径W={w1,w2,…,wK},其中wk=(wp(k),wq(k)),wp(k)和wq(k)分别表示序列p和q中元素的位置。规整路径W需要满足以下约束条件:
(1) 起始点为w1=(1,1),结束点为wK=(m,n)。
(2) 规整路径中任意相邻的两个元素wk=(a,b)和wk-1=(a′,b′),必须满足a-a′≤1和b-b′≤1,保证规整路径的连续性。
(3) 规整路径中任意相邻的两个元素wk=(a,b)和wk-1=(a′,b′),必须满足a-a′≥0和b-b′≥0,保证规整路径的单调性。
满足上述三个条件的规整路径有很多,但其中累加距离最小的才能代表序列p和q之间的距离,用DTW(p,q)来表示,最优路径的求解需满足以下公式:
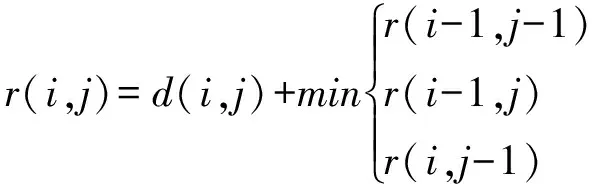
(3)
式中:r(i,j)表示在距离矩阵D中从起始点到点(i,j)的累加距离。规整路径的求解过程如图3所示。

图3 规整路径的求解过程
例如两个序列分别有4个和6个数据点,小方格左下角的数表示两个点之间的距离,右上角的数表示累加距离,虚线箭头表示最小值的累加方向。在计算时从最底下的一行开始,从左往右逐行往上,最终得到这两个序列之间的距离为12。通过对虚线箭头的方向反推,可以找到最短距离的规整路径,如图3中实线箭头所示。
2.1.3合成新样本
最近邻拼接采样合成的电极位置和电流如图4、图5所示,从不合格样本中随机选取样本X1,并找出与其距离最近的两个样本X2和X3。根据锚链闪光焊接的特点,将样本X1、X2和X3分别按照预热、连续闪光和顶锻3个阶段分成3段曲线,从中随机抽取3个不同阶段的曲线拼接成新样本Xnew,重复以上步骤,使不合格样本的数量得到扩充。
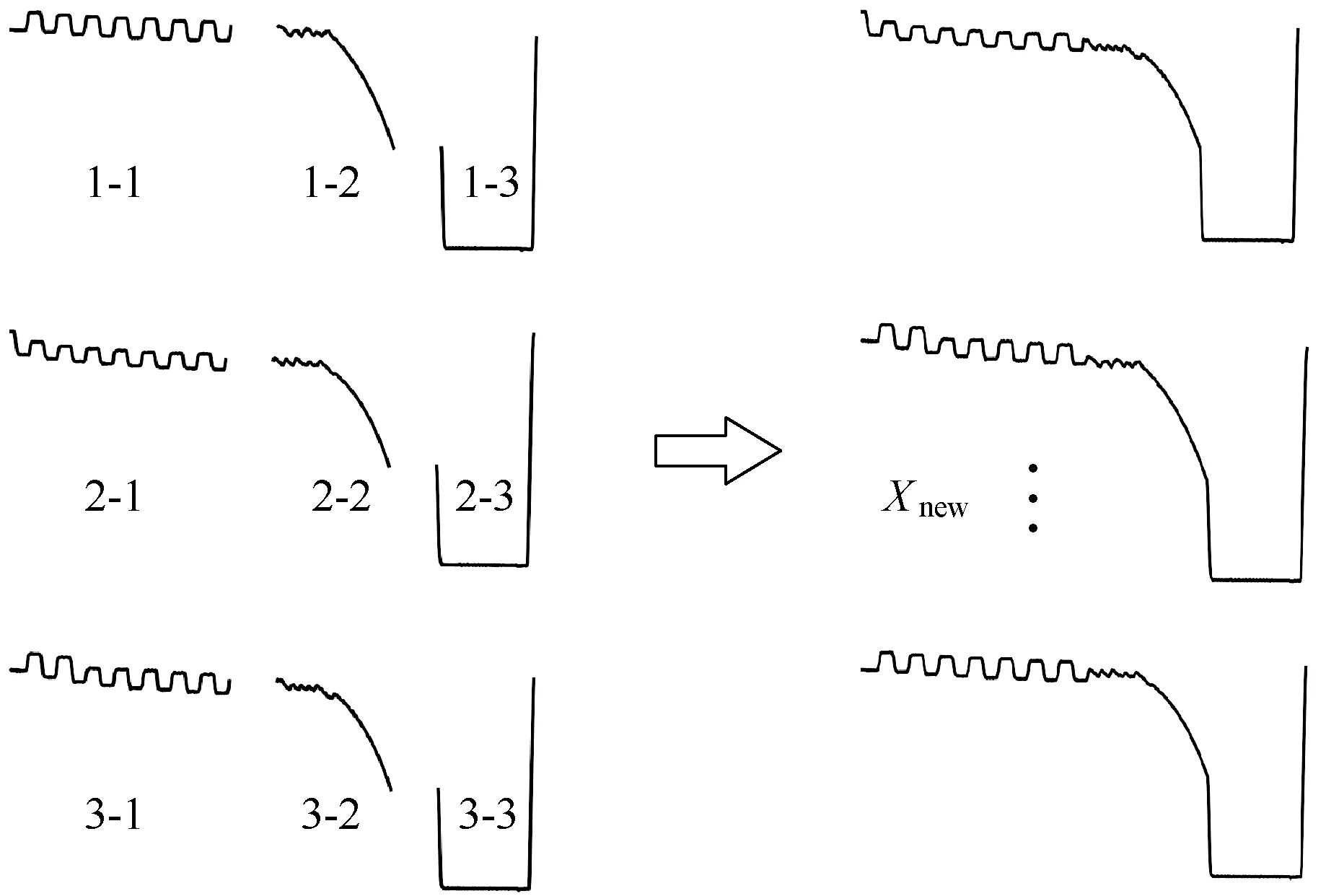
图4 最近邻拼接采样合成的电极位置

图5 最近邻拼接采样合成的电流
2.2 分段线性插值
由于多种因素的影响,锚链闪光焊接的时间有长有短,而卷积神经网络又要求输入样本的数据长度一致,为了解决这一问题,对电极位置曲线和电流曲线进行分段线性插值。
分段线性插值的基本思想是:设有一个数据集合{(x0,y0),(x1,y1),…,(xn,yn)},其中插值节点x0,x1,…,xn是n+1个连续递增的整数,y0,y1,…,yn是x0,x1,…,xn对应的函数值,将这n+1个数据点依次相连,可以得到一条由n个线段组成的曲线[17],用分段线性插值函数P(x)表示为:
(4)
式中:li(x)表示分段线性插值的基函数。li(x)如图6所示,具体公式如下:
(5)
(6)
(7)
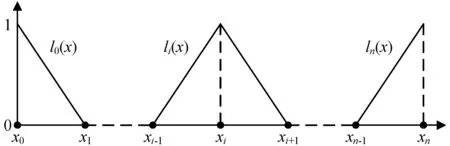
图6 分段线性插值的基函数
当x∈[xi,xi+1]时,分段线性插值函数P(x)可以表示为:
(8)
3 研究方法
传统的分类模型在训练时,需要依赖人的经验进行特征的提取,而本文采用卷积神经网络的方法,能自动地从训练样本中提取有用的特征进行模型的训练。将测试样本代入训练好的模型中,可以得到每个样本分别属于不合格与合格的概率,其中概率较大的作为预测的结果,从而判断样本的质量是否合格。此外,结合增量学习的方法,使模型具有持续学习的能力,其流程如图7所示。
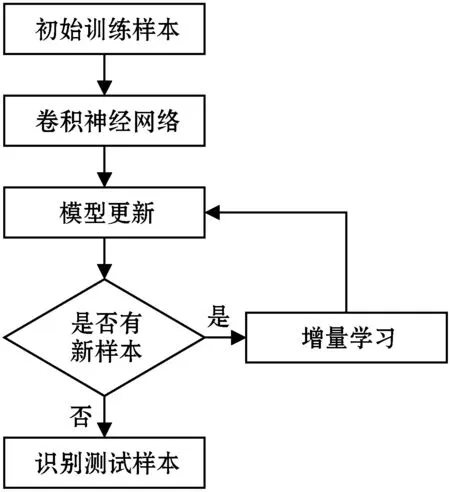
图7 增量学习的流程
3.1 卷积神经网络
卷积神经网络是一种深度学习算法,由输入层、卷积层、池化层、全连接层和输出层组成[18]。由于锚链闪光焊接的电极位置和电流是典型的一维信号,为了适应这一特性,本文搭建了一个一维的卷积神经网络,除了输入层和输出层,包含2个卷积层、2个池化层和1个全连接层,这些层又可以称为隐藏层,具体参数如表1所示。

表1 卷积神经网络隐藏层的参数
卷积层具有权值共享和局部连接的特点,是卷积神经网络的核心,而卷积运算是卷积层的重要步骤,不同的卷积核提取出来的特征是不一样的,卷积层的公式如下:
(9)

池化层也可以称为下采样层,其主要作用是对卷积层输出的特征进行压缩,减少特征的数据量。常用的池化方法有平均池化和最大池化,平均池化输出子区域中的平均值,最大池化输出子区域中的最大值。池化层的公式如下:
(10)
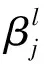
全连接层中的每一个神经元都与前一层的所有神经元相连,提取的是更深层次的特征。为了减少过拟合情况出现的可能,采用丢弃(Dropout)思想,在训练模型的过程中,随机选取一些神经元使其当前的输出为0。Dropout思想可以避免模型对某种局部特征的过拟合,使卷积神经网络具有更好的泛化能力[19],全连接层的公式如下:
xl=f(Wlxl-1)+bl
(11)
式中:xl表示第l层的特征;xl-1表示第l-1层的特征;Wl表示第l层的权重;bl表示第l层的偏置。
3.2 增量学习
增量学习是一种机器学习方法,当训练样本的数量逐渐变多,超出一定范围时,通过增量学习的方法可对持续增加的样本进行知识的更新,直到学习完所有样本。增量学习基于已有的模型,将获得的新样本用于模型参数的修正和优化,不仅保留了模型的基本信息,还提高了模型的识别能力,同时避免了对大量旧样本的重复训练[20]。增量学习按学习的对象主要可以分为三种类型:类别的增量学习,样本的增量学习和属性的增量学习。本文基于卷积神经网络,对锚链闪光焊接的样本进行增量学习。
4 实 验
4.1 实验设计
本文一共采集了1 100个锚链闪光焊接的样本,每个样本都记录了闪光焊接时电极位置和电流的变化过程。其中,不合格样本有100个,通过最近邻拼接采样扩充为1 000个,合格样本有1 000个,本文的实验主要分为两个部分,具体的实验设计如下。
(1) 为了验证最近邻拼接采样在解决数据不平衡问题上的优越性,对不合格样本与合格样本比例为1 ∶10、1 ∶5、1 ∶2和1 ∶1的4组样本,分别采用同样的卷积神经网络进行训练和测试。其中,不合格样本的数量分别为100个、200个、500个和1 000个,合格样本的数量都为1 000个,并选取80%的样本作为训练集,20%的样本作为测试集。
(2) 为了验证增量学习对于新样本持续学习的能力,将传统的批量学习与增量学习进行对比实验。把样本分为5组,每组都包含200个不合格样本和200个合格样本,其中4组作为训练集,1组作为测试集。批量学习在模型训练时,把新样本和所有的旧样本都作为学习对象,而增量学习只对新样本进行学习,并在模型更新后,检测模型在旧样本上的准确率。
对于平衡数据而言,准确率(Accuracy)常用来反映分类模型的整体性能,而在不平衡数据的分类问题中,仅用准确率来衡量是不可靠的,往往忽略了对少数类的识别效果。为了更好地对锚链闪光焊接的样本进行分类,引入了另外的两个评价指标:灵敏度(Sensitivity)和特异度(Precision)[21]。灵敏度反映的是合格样本被正确预测的百分比,特异度反映的是不合格样本被正确预测的百分比,计算公式如下:
(12)
(13)
(14)
式中:TP表示实际合格,被预测为合格的样本数量;FN表示实际合格,被预测为不合格的样本数量;TN表示实际不合格,被预测为不合格的样本数量;FP表示实际不合格,被预测为合格的样本数量。
4.2 实验结果及分析
对于4组不同样本比例的样本集,其训练集的损失值和准确率的变化曲线如图8、图9所示。随着迭代次数的增加,训练集的损失值一开始变化幅度较大,在迭代20次后慢慢变小,最后趋于稳定。

图8 训练集的损失值变化曲线
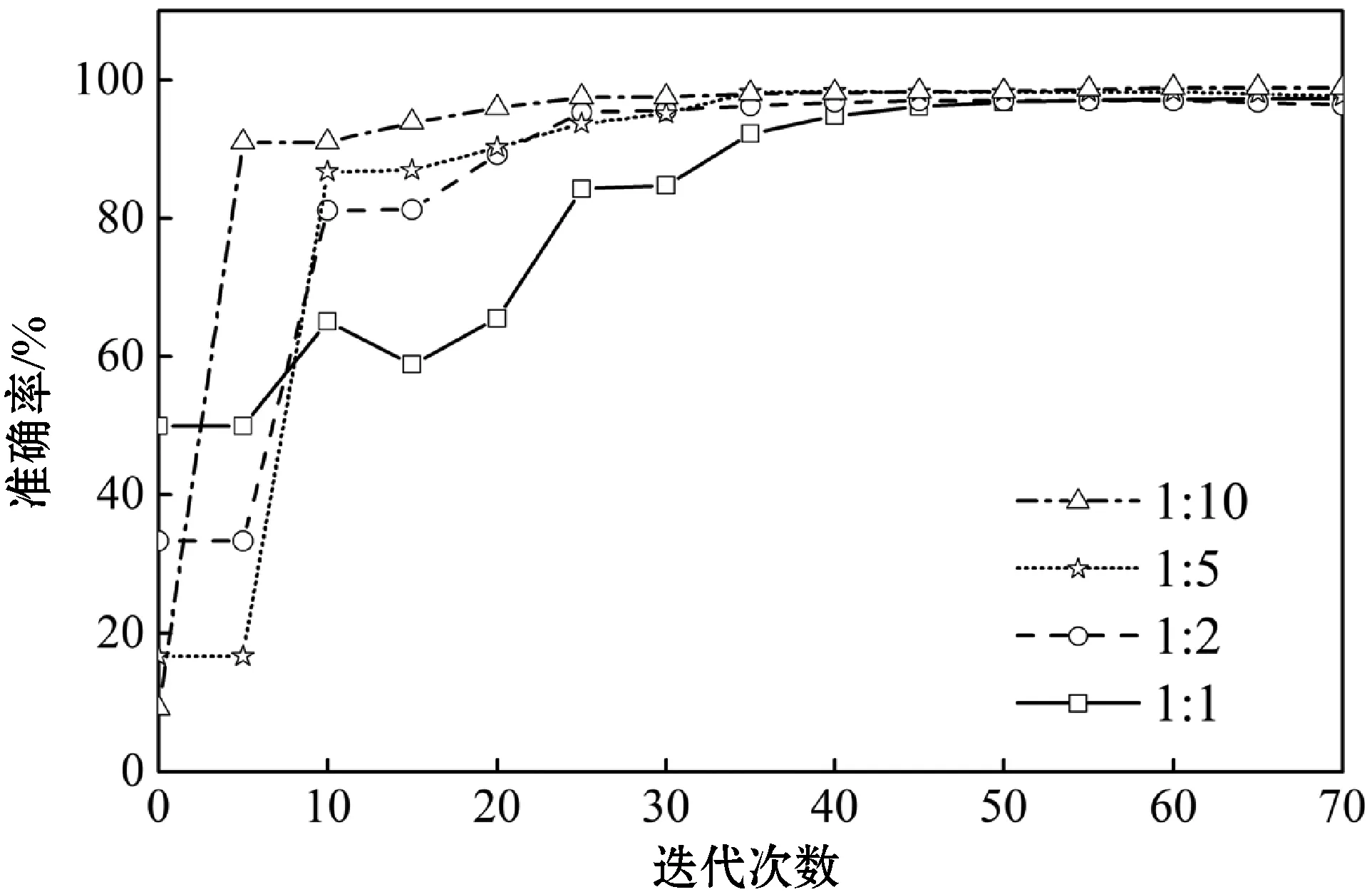
图9 训练集的准确率变化曲线
对于样本比例为1 ∶10、1 ∶5和1 ∶2的样本集来说,其训练集在一开始的准确率分别为9.1%、16.7%和33.3%,这是由于模型将所有的样本都识别为不合格样本。在迭代10次后,模型将大部分的合格样本都识别正确,准确率得到了大幅提升。在迭代30次后,训练集的准确率一直都保持在95%以上,最终的准确率分别为98.9%、97.6%和96.1%。对于样本比例为1 ∶1的样本集来说,其训练集的准确率增长缓慢,在迭代45次后才逐渐稳定,最终的准确率为97.3%。
4组不同样本在测试集上的分类结果如表2所示,当样本比例为1 ∶10时,虽然测试集的灵敏度为100.0%,但是特异度只有25.0%,这是因为不合格样本与合格样本的数量差别过大,模型在训练时为了得到更高的准确率,容易将不合格样本识别为合格样本。当样本比例为1 ∶5和1 ∶2时,测试集的灵敏度有所下降,为99.5%和98.5%,特异度却大幅上升,为87.5%和92.0%,这是因为不合格样本的数量越接近合格样本,模型能学习到越多不合格样本的特征。当样本比例为1 ∶1时,不合格样本与合格样本的数量达到平衡,测试集的灵敏度、特异度和准确率分别为97.0%、96.5%和96.8%。
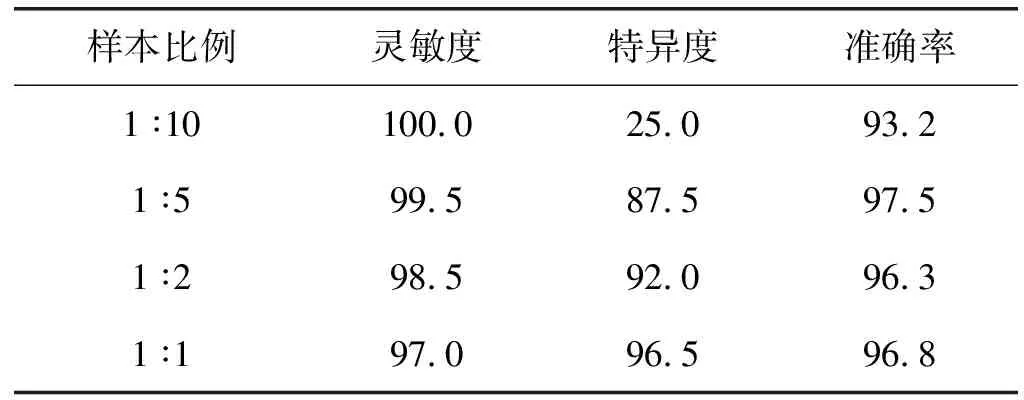
表2 不同样本在测试集上的分类结果(%)
在批量学习和增量学习的对比实验中,模型在测试集和旧样本上的准确率如表3所示。一开始,由于批量学习和增量学习的训练样本一样,因此测试集的准确率都为76.8%。随着训练的进行,批量学习可以从越来越多的样本中学习知识,模型的泛化能力逐渐提高,而增量学习在之前的基础上,每次都能学习到新样本的知识,模型的识别能力也进一步加强。在4次训练后,批量学习和增量学习在测试集上的准确率分别为97.3%和97.5%,都取得了不错的分类效果。增量学习在旧样本上的准确率分别为97.5%、97.1%和97.2%,这说明模型在学习新知识时,不会忘记已经学习到的旧知识,即模型同时具备识别新旧样本的能力,体现了增量学习的优势。
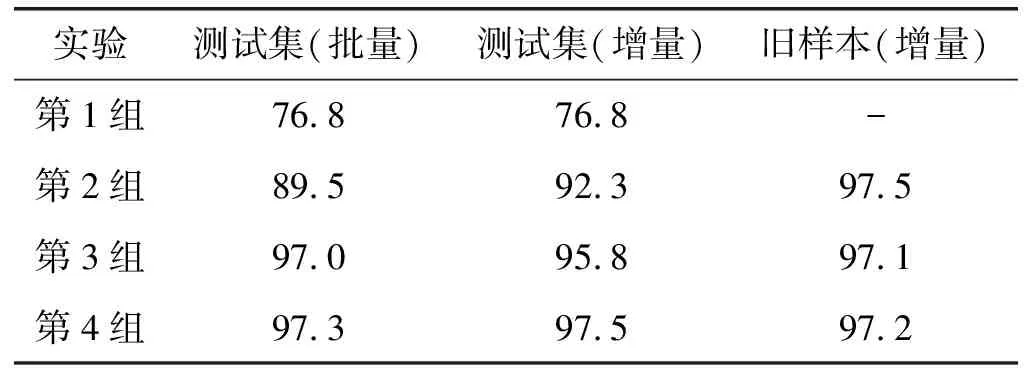
表3 批量学习和增量学习的准确率(%)
5 结 语
本文基于卷积神经网络,建立一个用于检测锚链闪光焊接质量的模型,结合锚链闪光焊接的特点,提出一种新的解决数据不平衡问题的方法:最近邻拼接采样。该方法不仅提高了模型的分类性能,也降低了过拟合现象的发生,并使用分段线性插值的方法使样本满足卷积神经网络对数据长度一致性的要求。模型在不同样本比例下的实验表明,当不合格样本与合格样本在数量上的差距越小时,模型的整体性能越好。尤其是对不合格样本来说,当样本比例为1 ∶10和1 ∶1时,特异度分别为25.0%和96.5%,模型对不合格样本的识别能力有了质的提升。
针对锚链闪光焊接样本数量与日俱增的问题,本文通过增量学习的方式,使模型在充分利用已有知识的前提下,每次只需要训练新样本,而不用像批量学习那样重复训练旧样本。实验表明,增量学习在测试集上的准确率和批量学习相近,随着样本数量的增加,都能使模型的分类效果得到提升。同时增量学习对旧样本具有良好的识别能力,准确率保持在97.1%以上,有效地避免了灾难性遗忘的问题。
猜你喜欢
大江南北(2022年6期)2022-06-16
北京航空航天大学学报(2022年5期)2022-06-06
财会月刊·下半月(2022年4期)2022-04-25
当代陕西(2022年6期)2022-04-19
兵工学报(2022年1期)2022-03-14
汽车工程师(2021年12期)2022-01-18
好日子(2021年8期)2021-11-04
小资CHIC!ELEGANCE(2021年36期)2021-10-15
智慧少年·故事叮当(2020年12期)2020-12-25
高考·中(2019年6期)2019-09-10
