
基于指针级联标注的中文实体关系联合抽取模型
2022-07-09 11:12:48王泽儒柳先辉
武汉大学学报(理学版) 2022年3期
王泽儒,柳先辉
同济大学电子与信息工程学院,上海201800
0 引言
知识图谱[1(]knowledge graph,KG)是由Google公司在2012年提出的一个新概念。知识图谱能够更好地组织、管理和理解海量信息[2],并以“实体-关系-实体”的方式表达客观世界中的概念、实体及其相互间的语义关系,从而构成庞大的知识库,有助于知识的共享和重用。知识图谱通常是由许多实体关系构成的关系图,因此在构建知识图谱的过程中,如何从非结构化文本中抽取实体关系成为一项至关重要的任务。
实体关系抽取通常包含命名实体识别(named entity recognition,NER)和关系抽取(relation extraction,RE)两项子任务。早期实体关系抽取方法主要是通过人工构造语法和语义规则,基于规则模板的方式抽取实体关系,之后发展为以传统机器学习方法为主的实体关系抽取算法,包括无监督[3,4]、半监督[5]与有监督[6]的算法。近年来,为避免繁琐的人工特征抽取,基于深度学习的实体关系抽取算法已成为目前实体关系抽取领域的主要研究方向。基于深度学习的实体关系抽取算法主要分为流水线学习(pipeline)[7~10]和联合学习(joint)[11~13]两种。流水线学习是指在已完成实体识别的基础上对每个实体对进行关系分类的学习方式。联合学习是指在进行命名实体识别和关系抽取两个子任务时共享编码层的参数,经过优化后得到全局最佳参数。相较而言,联合学习有效地改善了流水线方法中存在的错误累积传播问题以及忽视实体识别与关系抽取这两个子任务间联系的问题,提高了模型的鲁棒性。
然而现阶段的联合实体关系抽取算法难以解决如下问题:关系重叠、实体嵌套以及抽取三元组的同时判别实体类型。关系重叠是指句子中包含多个相互重叠的三元组,具体表现为一个实体同另一个实体之间存在多种关系(entity pair overlap,EPO)及一个实体与其他不同实体之间存在多种关系(single entity overlap,SEO)这两种关系重叠类型。传统的关系抽取模型通常将识别出的实体与原始文本组合为实体元组向量作为输入,模型难以从单一实体元组向量识别出多种关系,因此无法解决关系重叠问题。实体嵌套(nested entity,NE)是指一个实体包含或部分包含另一个实体,例如句子“[[[上海]中芯国际]芯片晶圆生产线]”是三层嵌套实体,其中地名被嵌入到企业名中。实体嵌套问题同样为联合实体关系抽取算法带来挑战,原因在于现有的方法通常将命名实体识别子任务看作一个序列标注问题,假定每个字符只能属于一种实体类型。目前知识图谱主要的存储媒介从早期的RDF三元组逐渐转变为图数据库如Neo4j[14],图数据库在存储知识时不但要求实体的名称,还必须指定实体的类型。然而现阶段的联合实体关系抽取算法通常以识别实体在句子中的位置为目标,而不对实体的具体类型做出判断,无法顺利地将抽取出的实体关系导入图数据库。因此,需要一种可以解决上述问题的联合实体关系抽取算法。
CasRel(cascade binary tagging framework)[11]模型的出现为解决关系重叠问题提供了一个思路。传统的实体关系抽取算法可以抽象为主体和客体映射为关系的函数f(s,o)→r,Wei等[11]改变了这一传统思想,将问题抽象为以关系作为条件通过主体映射客体的函数fr(s)→o,避免了主体、客体只能映射为单一关系的局限性,并通过一种级联二进制标记框架加以实现。本文采用CasRel模型的思想,提出了一个新型的指针级联标注策略,与BERT(bidirectional encoder representation from transformers)[15]预训练模型结合,可以有效解决实体嵌套与关系重叠问题,并且可以在抽取三元组的同时判别实体类型。
1 本文模型
模型主要由文本预处理、BERT编码器、头实体解码器、字向量融合、尾实体解码器5个模块构成,如图1所示。对于数据集中的文本,只需要根据预先定义的句子最大字符长度做[PAD]填充即可,并转化为矩阵向量;其次利用预训练的BERT编码器对文本矩阵向量处理,获取包含语义信息的字向量;接着将字向量输入头实体解码器预测头实体类型与位置索引;再根据头实体预测的结果与字向量融合;最后将融合字向量输入尾实体解码器预测尾实体类型、关系类型与位置索引。
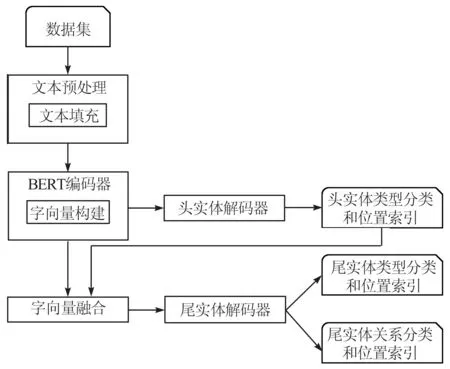
图1 模型框架图Fig.1 Overview of the model
1.1 BERT编码器
在处理自然语言的过程中,构建词库并根据词库将文本分词结果嵌入词向量是必不可少的步骤,相较于英文词语间有间隔作为标记,中文词库在构建时往往受制于分词工具的影响,且文本的分词结果对之后词向量的生成影响颇深。因此,本文不使用分词工具对文本进行处理,选择直接将文本分字后构建字向量。在字向量的生成中,采用BERT模型作为编码器训练字向量,不同于以往的静态字向量,前者能够在不同的语境下表征不同的语义,因此这样的字向量更加体现出强大的语义表征能力。对输入的每个字符进行向量空间的嵌入表示,每个字符向量E计算如下
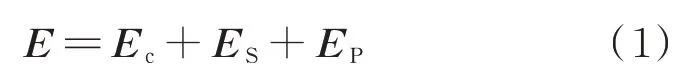
其中,Ec为该字符串的字符向量表示,ES为该字符的句子分类向量,EP为该字符的序列位置向量。
将E经过多层双向Transformer编码器训练得到文本的字向量。第i个字符的向量表示Ti的计算过程如下所示
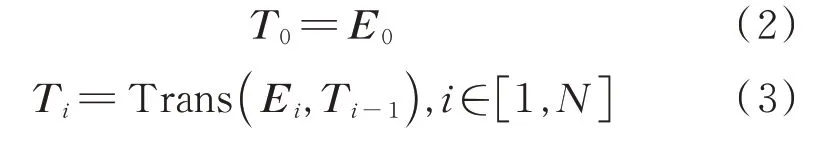
其中,Trans代表每一个Transformer块的运算过程,N为字向量的最大长度,单个字的向量表示的维度为BERT隐藏层输出的维度,默认为768。
1.2 头实体解码器
针对头实体中可能存在的实体嵌套问题以及关系重叠问题,本文提出了一种全新的指针级联标注策略(novel pointer tagging cascade strategy,NPCTS),包含头实体与尾实体标注两部分。在头实体标注部分,如图2所示,采用指针标注的思想,将头实体的标签分为起始标签与终止标签。为了在预测头实体位置的同时,识别出实体的类型,将起始标签与终止标签设计成为矩阵形式,不同行代表在不同实体类型上可能存在实体的位置。由于实体嵌套问题多发生在不同类型的实体间相互嵌套,极少出现同一实体类型嵌套的现象,因此NPCTS按照实体类型作为区分指针级联标注策略可以很好地应对实体嵌套问题。在头实体的起始标签中,“1”代表头实体在句子中的起始位置;同样地,“1”在终止标签中代表头实体在句子中的结束位置。
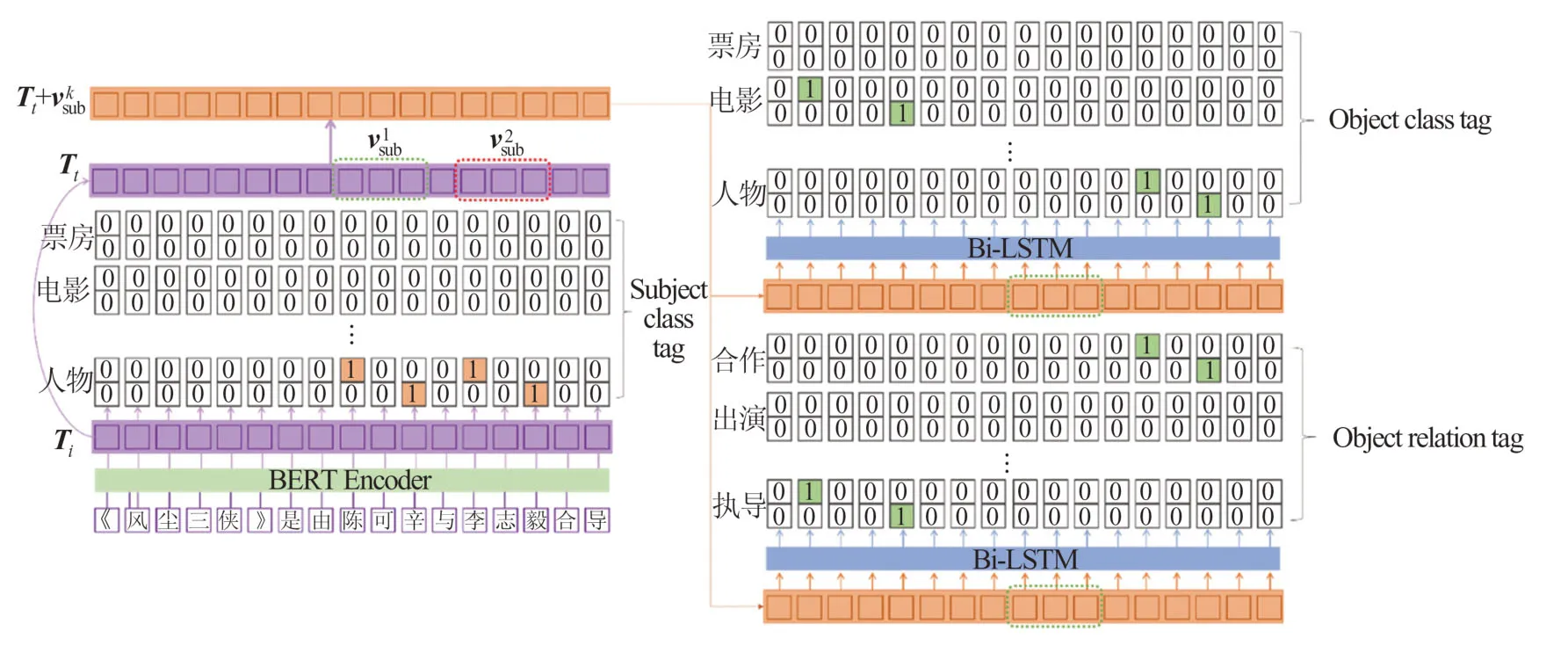
图2 NPCTS实体关系抽取模型Fig.2 NPCTS entity relation extraction model
头实体解码器被用来解析句子中所有可能出现的头实体。将经过BERT编码器编码后的字向量Ti输入全连接层并通过sigmoid函数激活,得到解码后的输出,具体运算过程如下
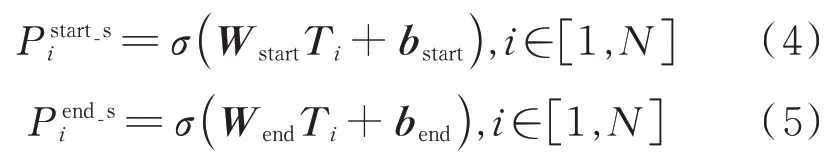
因为头实体采用二值化的标签,所以在训练过程中损失函数采用的是二值交叉熵损失函数,具体可由以下两式表示
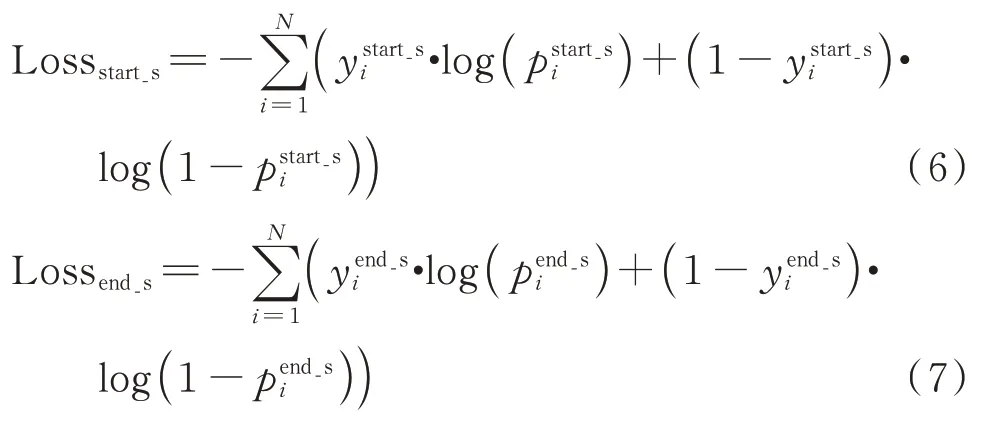
1.3 尾实体解码器
尾实体标注用于标记尾实体的索引位置、实体类型以及头实体与其对应的关系类别。NPCTS采用尾实体关系矩阵与尾实体类型矩阵标记这些信息,这两种矩阵的标注方式与头实体标注方式类似,不同点在于尾实体关系矩阵每行代表不同的关系类型。为了将头实体信息与句子特征相融合,本文采取将字向量中头实体存在范围内的字向量表示取平均,并与字向量相加,以此达到融合头实体信息的目的。具体计算过程如下,
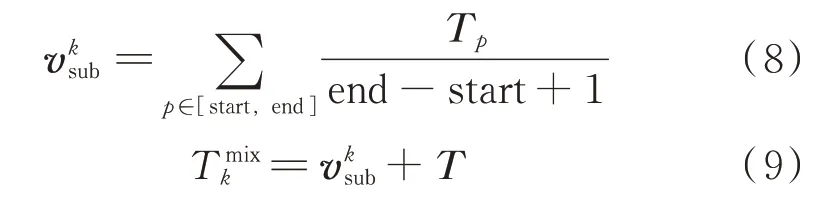
尾实体解码器被用来解析给定头实体后尾实体存在的范围与实体类型。为了从融合后的字向量中更好地获取上下文信息,本文采用双向LSTM(long short-term memory)层对融合后的字向量做进一步特征提取。双向LSTM前向传递层可以获取输入序列的上文信息,后向传递层可以获取输入序列的下文信息。将一个句子的各个字的字向量序列作为双向LSTM各个时间步的输入,再将正LSTM输出的隐状态序列与反向LSTM输出的隐藏层状态序列拼接,得到完整的隐藏层状态序列。本文首先将融合字向量输入两个不同的双向LSTM层,分别进行尾实体的关系预测与类别预测,最后再分别输入全连接层得到解码后的输出。具体运算过程可以由公式(10)~(13)表示
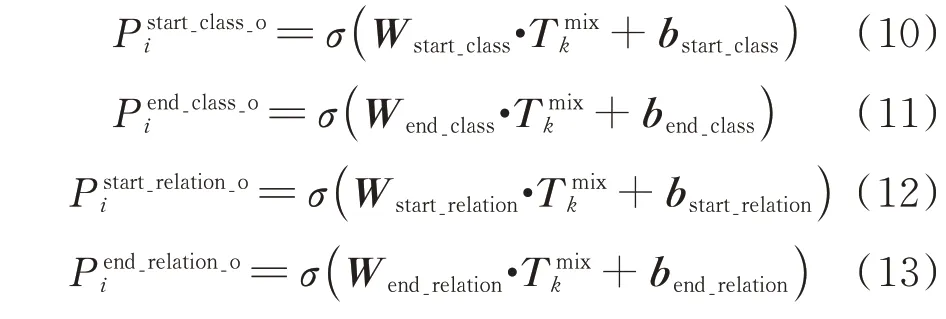
2 实验
2.1 数据集与评价指标
本文选用DuIE1.0和CMeIE(Chinese Medical Information Extraction Dataset)作为实验数据集。DuIE1.0中的句子来自百度百科、百度贴吧和百度信息流文本,是规模较大的基于schema的中文关系抽取数据集,包含超过43万三元组数据、21万中文句子及50个预定义的关系类型。CMeIE是医疗领域的常用数据集,其中儿科语料来源于518种儿科疾病,常见病语料来源于109种常见病。数据集包含近75 000个三元组、28 000个疾病句子和53个图式,将14 339条数据用作训练集,3 585条数据用作测试集,4 482条数据用作验证集。为了验证本模型在应对关系重叠与实体嵌套问题时有更好的表现,本文将数据集划分为三个部分,并分别命名为实体对重叠(EPO)、单实体重叠(SEO)与实体嵌套(nested entity)。两种数据集的划分情况如表1所示(Train为训练集,Dev为测试集)。
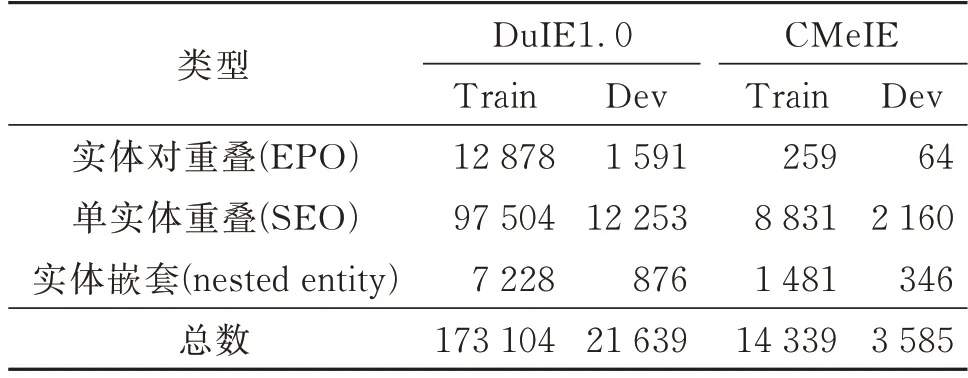
表1 数据集信息Table 1 Information of datasets
本文使用准确率(P),召回率(R)和F1值评估模型效果。其中

F1值是一种较为均衡的评估方法,计算公式如下
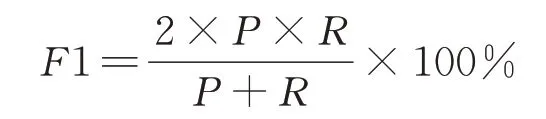
本文分别从字符级别上的SPO(Subject-Predict-Object)三元组抽取与命名实体识别两个任务层面对模型进行评估。
2.2 实验环境及参数设置
算法的实验环境:操作系统是Ubuntu20.04,使用的语言是python3.7,BERT中文预训练语言模型使用Chinese_L-12_H-768_A-12,深度学习框架pytorch1.7.1。句子最大长度设定为180,训练时的Batch_size为8,分类概率阈值为0.5,学习率(Learning rate)为1E-5,多头注意力有12层,多头数量有12个。模型优化器选择Adam,epochs设置为120。
2.3 实验结果评估与分析
为了评估NPCTS模型与不同结构搭配的效果,本文设计了一系列的消融实验作为对照。NPCTS模型建立在预先训练的BERT模型之上,直接将字向量输入全连接层作为头实体与尾实体解码器。NPCTSembedding表示使用嵌入层生成字向量而非BERT预训练模型。NPCTSBi-LSTM表示在获取字向量后,输入Bi-LSTM层进一步提取特征。消融实验的结果如表2所示,NPCTSembedding模型在两个数据集上表现较差,说明了BERT预训练模型生成的字向量对后续任务的提升作用明显。NPCTSBi-LSTM与NPCTS相比有较小提升,说明Bi-LSTM模型在处理语义特征方面相较于传统神经网络表现更佳,可能是由于Bi-LSTM结构可以更好地提取字向量的上下文信息。
NPCTS模型是针对中文文本的实体关系抽取任务,比较难找到统一对比的数据集与经典的算法。为了进一步验证模型性能,体现本文方法在准确率和稳定性上的优势,将NPCTS模型及其变种与Bert+Bi-LSTM、Bert+Bi-LSTM+CRF、和CalRel[11]四种模型在不同语料库上进行实验对比。Bert+Bi-LSTM为流水线学习的实体关系抽取模型,可以完成命名实体识别任务,并在此基础上判别实体对的关系类型;Bert+Bi-LSTM+CRF(conditional random field)是使用较为普遍的命名实体识别模型,采用CRF分类器识别实体类型。CopyRRL[16]与CasRel[11]模型在英文数据集NYT与WebNLG上都取得了不错的结果,但无法在提取三元组的同时判别头实体与尾实体的类型。本文使用上述模型在中文数据集上复现,实验结果如表2所示,表中“-”代表该模型无法完成该项任务。
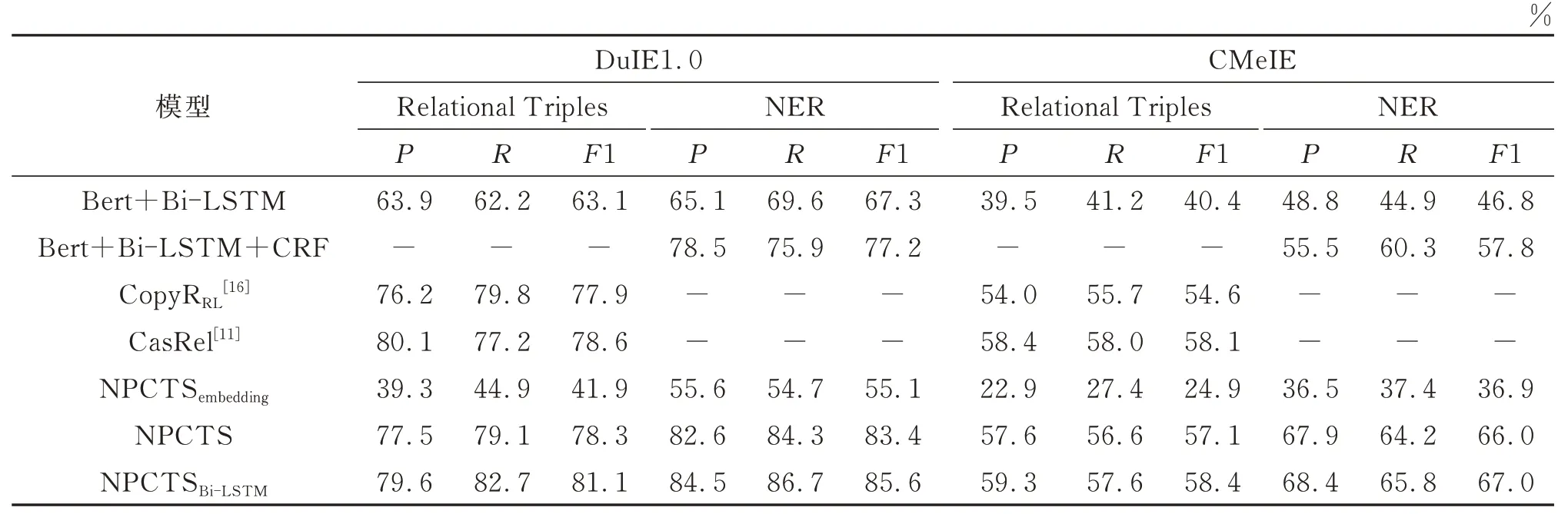
表2 不同模型在Du IE1.0与CMeIE数据集上的实验结果Table 2 Results of different methods on Du IE1.0 and CMeIE datasets
从表2中可以看出所有模型在DuIE1.0数据集上的表现均优于CMeIE,原因在于CMeIE医疗数据集涉及多种医疗领域专有名词且分布不均衡,导致模型学习不充分。Bert+Bi-LSTM作为经典的流水线式实体关系抽取模型可以完成三元组抽取与实体识别两项任务,但在整体效果上差强人意,说明在使用传统序列标注方式以及假定实体间只能存在一种关系的条件下,模型无法应对实体嵌套与关系重叠问题。Bert+Bi-LSTM+CRF模型增加了条件随机场判别实体类型,在两个数据集上均有较大提升。CopyRRL与CasRel模型均试图解决关系重叠问题,并在模型上做出改进,在整体效果上有着不错的表现。在三元组抽取任务上,NPCTSBi-LSTM模型的F1与CasRel模型相比分别有2.5%与0.3%的微提升,表明NPCTSBi-LSTM模型在三元组抽取任务中有不输于领域内效果最好的模型CasRel的表现,而且NPCTSBi-LSTM模型还能够额外完成实体识别任务,并且在实体识别任务上与Bert+Bi-LSTM+CRF模型相比提升了近10%。
针对本文所描述的实体关系抽取领域遇到的实体嵌套和关系重叠等问题,为进一步体现NPCTS模型在应对此问题的有效性,本文使用在完整数据集上训练后的模型在不同类型的测试数据集上做验证,并与Bert+Bi-LSTM、CopyRRL和CasRel模型进行性能对比,实验结果分别如表3和表4所示。在应对数据集中两种关系重叠样式以及实体嵌套的文本时,Bert+Bi-LSTM模型的表现相较于在整体数据集上的表现下降尤为明显,然而其他三种模型由于存在应对关系重叠问题的结构或策略,在SEO与EPO类型的文本上的表现与整体数据集上的表现差距并不大。与CasRel[11]模型在处理实体嵌套文本时与整体表现差距明显,其原因在于这两种模型在进行实体标注时均采用了传统的指针标注策略,没有在实体类型上加以区分,导致其无法解决实体嵌套问题。本文提出的NPCTSBi-LSTM模型则在这三种类型文本上的表现较为一致,这是由于NPCTS模型采用了以实体类型与关系类型作为区分的指针级联标注方式,可以有效应对实体嵌套问题,并识别出实体类型;NPCTS模型将关系模型作为函数,将句子中的头实体映射到尾实体,解决了重叠问题。实验结果也印证了该模型在应对关系重叠和实体嵌套问题上的优越性。
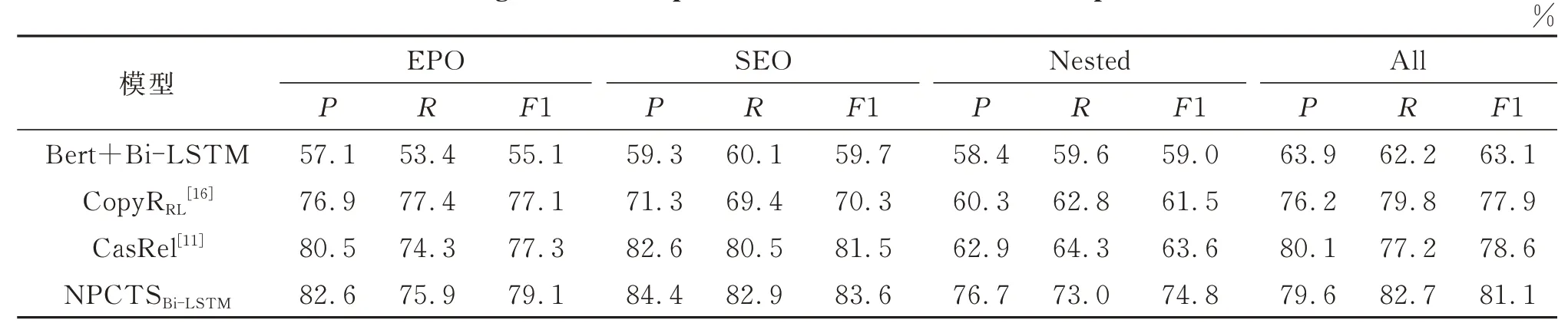
表3 在Du IE1.0数据集上从不同模式的句子中抽取三元组的实验结果Table 3 Results of extracting relational triples fr om sentences with different patterns on Du IE1.0 dataset
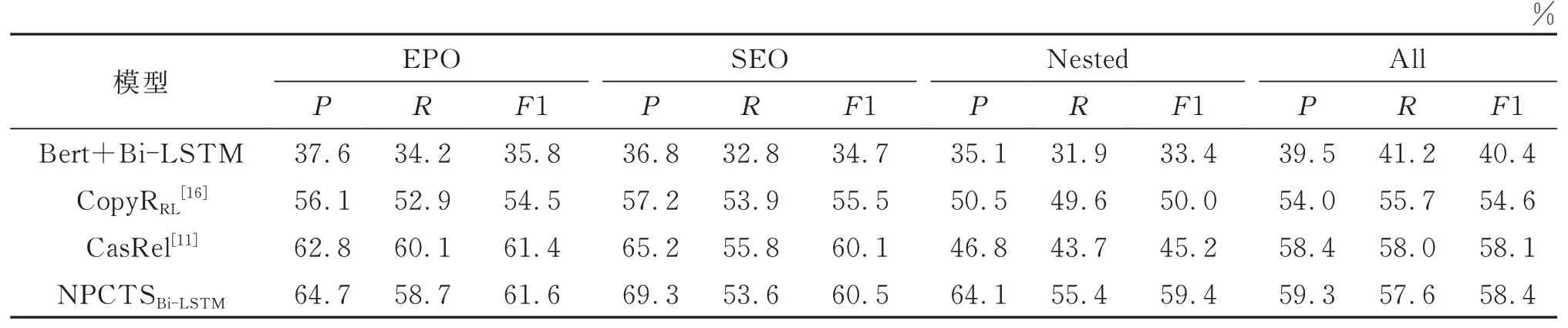
表4 在CMeIE数据集上从不同模式的句子中抽取三元组的实验结果Table 4 Results of extracting relational triples from sentences with different patterns on CMeIE dataset
3 结语
针对实体关系抽取中实体嵌套和关系重叠问题,本文提出了一种基于指针级联标注策略的中文实体关系联合抽取模型。该模型采用联合学习的方式,将实体关系抽取任务抽象为以关系作为条件通过主体映射客体的函数fr(s)→o,可以同时从句子中提取多个实体关系元组,并通过一种新型的级联二进制标记策略加以实现。这种标记策略使得模型可以在识别嵌套主体的同时判断主体的实体类型,在识别客体的同时也能对实体类型和关系类型做出判断。在两个不同领域的中文数据集上的实验结果表明,此模型可以有效提升实体关系抽取的F1值,在应对实体嵌套和关系重叠问题上表现尤为突出。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31 08:40:44
系统工程学报(2021年4期)2021-12-21 06:21:24
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
中国外汇(2019年18期)2019-11-25 01:41:54
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
现代防御技术(2014年6期)2014-02-28 18:26:29
计算机工程(2014年6期)2014-02-28 01:25:29
