
基于ResNet网络与离散变分自编码器的精细轮廓检测方法
2022-07-08 10:05王衢林川陈永亮
广西科技大学学报 2022年3期
王衢 林川 陈永亮











摘 要:传统的基于卷积神经网络的轮廓检测方法多为由编码网络和解码网络构成的编解码结构,存在轮廓定位不准确、输出轮廓模糊的问题。为解决这一问题,提出一种基于离散变分自编码器的轮廓检测方法。该方法舍弃了解码网络,利用离散变分自编码器的编码器和解码器分别配合编码网络进行训练和轮廓输出,并设计了带有动态权重的损失函数,用于解决本文方法在训练过程中遇到的类别分布极不均衡的问题。基于BIPED数据集,本文的轮廓精细度实验表明本文方法在更严格的评估标准下优于最新方法DexiNed。在一般的评估标准下,本文方法的ODS F-measure能够达到0.889,比最新方法DexiNed提高了3.0%。研究结果表明,对离散变分自编码器的利用不仅能帮助模型提高轮廓精细度,也能显著提高模型的轮廓检测性能。
关键词:轮廓检测;深度学习;离散变分自编码器;计算机视觉;交叉熵损失函数
中图分类号:TP391.41 DOI:10.16375/j.cnki.cn45-1395/t.2022.03.002
0 引言
在计算机视觉领域中,轮廓检测作为一项基础视觉任务,旨在检测自然图像中具有视觉显著性的轮廓。对于一些高级的视觉任务,如目标检测[1]、目标跟踪[2]、光流检测[3]以及图像分割[4-5]等,轮廓检测通常是其基础或作为其辅助,轮廓信息的质量直接影响了这些任务的性能。为了更好地服务于这些高级视觉任务,研究者们一直致力于探索性能更加优良的轮廓检测方法。
近年来,基于卷积神经网络的轮廓检测方法[6]将轮廓检测性能提升到了一个新的台阶。Xie等[7]受FCN[8]与DSN[9]的启发,搭建了第一个端到端的、可训练的深度学习轮廓检测模型,即整体嵌套边缘检测(holistically-nested edge detection,HED)模型。得益于全卷积神经网络结构,HED能够对任意尺寸的图像进行处理,从真正意义上实现了对轮廓检测神经网络的端到端训练。Liu等[10]分析了HED网络存在的缺陷,提出了更丰富的卷积特征(richer convolutional features,RCF)模型。与HED不同的是RCF对编码网络的所有卷积层都进行了特征提取,这使得RCF所能够利用的多尺度信息相比于HED 更加丰富。Wang等[3]以提取精细轮廓为目的提出了清晰边缘检测(crisp edge detection,CED)模型,为了提升模型提取细致轮廓的能力,在模型中使用亚像素卷积对特征图进行缓慢的上采样,以保证轮廓的位置准确性。He等[11]专注于研究对多尺度信息的利用方式,提出了一种双向级联的解码网络结构(bi-directional cascade network,BDCN),以从浅到深、从深到浅两条路径对不同的侧端输出进行整合,合理地体现了主干网络不同层级之间的互补关系。乔亚坤等[12]以充分利用多尺度信息为目的,设计了IPD网络,所提出的交互式解码网络拥有较强的特征提取和利用能力。Huan等[13]针对特征混合(feature mixing)以及侧端混合(side mixing)的问题进行了研究,提出了上下文感知跟踪策略(context-aware tracing strategy,CATS),设计了新的损失函数用于提升监督信号对轮廓像素附近区域的重视程度,并利用空域掩膜对多尺度输出进行空间上的加权求和。其实验结果表明,CATS策略能够指导神经网络输出位置准确性更强的轮廓。
上述模型在训练过程中主要以像素为单位计算损失函数,未能较好考虑像素间的关系,在检测过程中存在因轮廓像素定位不准确而导致输出轮廓模糊的问题。如图1所示,上述模型的神经网络输出的轮廓相较于Ground truth更加模糊粗糙,因而需要利用非极大值抑制算法进行细化,增加了时间和计算成本。针对该问题,本文提出一种基于离散变分自编码器的轮廓检测方法,利用离散变分自编码器强大的编码能力对轮廓检测任务进行图像到图像建模。此外,还设计了一种拥有类别均衡能力的损失函数,以克服在使用离散变分自编码器训练模型时产生的类别分布极度不均匀的问题。
1 本文方法
1.1 离散变分自编码器
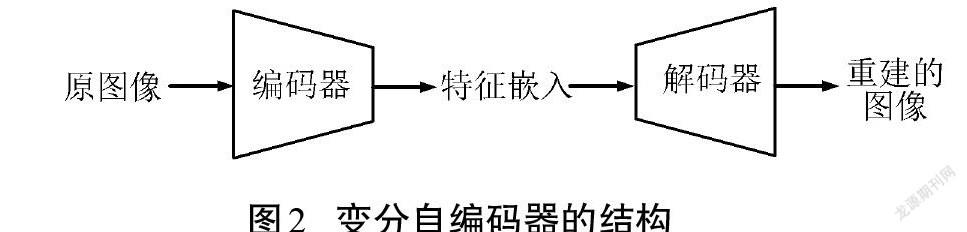
变分自编码器是一类重要的生成模型,结构如图2所示,主要通过编码器将图像压缩为特征嵌入,再通过解码器根据特征嵌入对图像进行重建。训练时,假设输入数据的潜在空间是连续的,其编码器将输入数据编码为一组均值[μ=μ1, μ2,…]和一组方差[σ=σ1, σ2, …],这样的均值和方差规定了一组正态分布:
[Z=Z1~N(μ1, σ1), Z2~N(μ2, σ2), …] . (1)
从这组正态分布中采样获得编码器所编码的特征嵌入[Z=z1, z2, …],随后[z]作为解码器的输入用于重建输入数据。
離散变分自编码器是一种特殊的变分自编码器,其特征嵌入[Z]是离散的,其离散化和采样可以通过Gumbel-softmax[14]实现。本文对于一幅形状为[1×H×W]的[Y](其中[H]和[W]分别为图像的高和宽),编码器将其编码为[1×H'×W']的特征嵌入:
[Z=Encoder(Y)]. (2)
其中:[H'=H/8],[W'=W/8],而[Z]中的元素皆为 [0]~[8 191]的整数,可以视为[8 192]个离散的类别。随后解码器又能对图像[Y]进行重建:
[Y=Decoder(Z)]. (3)
其中:[Y]为重建的图像,与[Y]具有相同的形状和近似的内容。一个好的离散变分自编码器能够令[Y]与[Y]无比接近。
离散变分自编码器对图像中的高频成分拥有较好的编码能力,本文主要将其编码器和解码器应用于ResNet网络,以期提取高频的轮廓细节。
1.2 轮廓检测模型
对于一幅形状为[3×H×W]的自然图像[X],其对应的Ground truth形状为[1×H×W]的[Y]。轮廓检测的目的在于寻找一个轮廓检测器[Detector∙],使[Y=DetectorX]尽可能地接近[Y]。
传统的基于编解码结构的轮廓检测网络直接使用神经网络对[Detector∙]进行建模,其训练方式如图3(a)所示,其编码网络与解码网络构成了一个完整的轮廓检测器。训练时,通过缩小输出轮廓[Y]与Ground truth [Y]之间的误差对网络进行训练,其损失函数利用交叉熵进行计算:
[L(Y, Y)=]
[−βi∈L+logyi−(1−β)i∈L−log(1−yi)] . (4)
其中:[L+]和[L−]分别表示Ground truth [Y]中轮廓像素和非轮廓像素组成的集合;[yi]为输出轮廓[Y]中的元素([i=0, 1, …, (H×W−1)]);[β=L−/(L++L−)]为平衡系数,用于解决样本分布不均衡的问题。但是,这种交叉熵在计算[ya]的损失时,没有考虑任何其他位置([i≠a])对[ya]的影响。
不同于图3(a)所示的传统编解码训练方式,本文仅训练编码网络,如图3(b)所示。训练时,利用离散变分自编码器中的编码器对Ground truth进行编码,得到特征嵌入[Z](式(2)),通过缩小编码网络输出的预测特征嵌入[Z]与特征嵌入[Z]之间的误差对编码网络进行训练。但由于离散的[Z]不可导,无法直接设计[Z]与[Z]之间的损失函数用于训练,因此,通过抽象特征[V]间接表示[Z],进而通过最小化[V]与[Z]之间的损失函数来减小[Z]与[Z]之间的误差。对于自然图像[X],编码网络输出形状为[C×H'×W']的抽象特征[V],其中[H'=H/8],[W'=W/8],[C=8 192]。而[Z]可以使用以下方式从[V]计算获得:
[Z=arg maxc{V(c)}] . (5)
编码器输出的特征嵌入[Z]皆为[0]~[8 191]的整数,因此,编码网络任务可以视为对[H'×W']的二维网格内每个元素进行总类别为[8 192]的分类。由于Ground truth是风格单调的图片,其大部分区域都为背景,因此,由其编码得到的特征嵌入[Z]具有类别分布极不平衡的特点,有些类别所占比重很高,而有些类别的数量为[0]。图4为Ground truth及其离散特征嵌入统计图。此种情况下,使用常规的交叉熵作为损失函数会使模型难以收敛。为了解决这种问题,根据每种类别所占比例来动态地为各个类别增加权重系数,以平衡不同类别对损失计算的贡献度。本文设计的损失函数如下:
[L(V, Z)=]
[−i=0H'×W'−1ω(zi)log(softmax(V(zi, i)))] . (6)
[ω(z)=0, ℎ(z)=0 ,1ℎ(z), ℎ(z)≠0 .] (7)
[softmax(V(c, i))=exp (V(c, i))jexp (V(j, i))] . ; (8)
其中:[zi]是特征嵌入[Z]中的元素[(] [i=0, 1, …, (H'×W'−1 ])) ; [ω(z)]为权重函数,用以计算类别[z]在损失计算时的权重;[ℎ(z)]是统计函数,用于统计类别[z]在特征嵌入[Z]中的个数。可以看出,由于存在权重系数,当[z]的数量[ℎ(z)]非常大时,[ω(z)]会很小并产生很强的抑制效果,从而削弱[z]的比重。
图5为本文与传统轮廓检测方式对比图。本文方法使用离散变分自编码器的解码器完成了类似传统编解码方法中解码网络的任务,不同之处在于本文方法通过arg max(式(5))将抽象特征转化为离散的预测特征嵌入,这种离散的预测特征嵌入能被解码器转化为包含高频细节的轮廓图像。
2 实验结果与分析
2.1 模型训练细节
本文模型使用一张RTX2080Ti显示卡进行训练和测试,在Python语言环境中通过Pytorch深度學习框架对深度学习模型进行实现。使用Ramesh等[15]训练好的离散变分自编码器生成特征嵌入。编码网络的主干采用ResNet50[16],其参数在ImageNet数据集[17]上进行预训练。在训练过程中,采用随机梯度下降优化算法对模型进行参数更新,初始学习率为[2×10]-4,在整个数据集上迭代训练4次,每次迭代后将学习率变为原来的[0.1]倍。
将本文方法记为DVAE-Contour,使用BIPED数据集[18]进行实验分析和对比。BIPED是最近提出的用于轮廓检测评估的数据集,由[250]张分辨率为[1 280×720]的户外图片组成,每张图片由专家进行精心标注。为了对数据集进行扩充,采用裁剪、旋转、翻转、伽马校正等数据增强手段,扩充后的数据集共有57 600对训练样本。
在进行模型性能评估时,使用AP(平均精度)、ODS(全局最优阈值)以及OIS(图像最优阈值)下的[F]-measure(调和平均数[F]值)对模型进行性能评估。[F]-measure的计算方式为:
[F=2×P×RP+R], (9)
[P=NTPNTP+NFP], (10)
[R=NTPNTP+NFN] . (11)
其中:[P]和[R]分别代表精确度和回归度,NTP表示轮廓像素被正确预测为轮廓像素的个数,NFP表示背景像素被错误预测为轮廓像素的个数,NFN表示轮廓像素被错误预测为背景像素的个数。
2.2 模型输出轮廓精细度分析
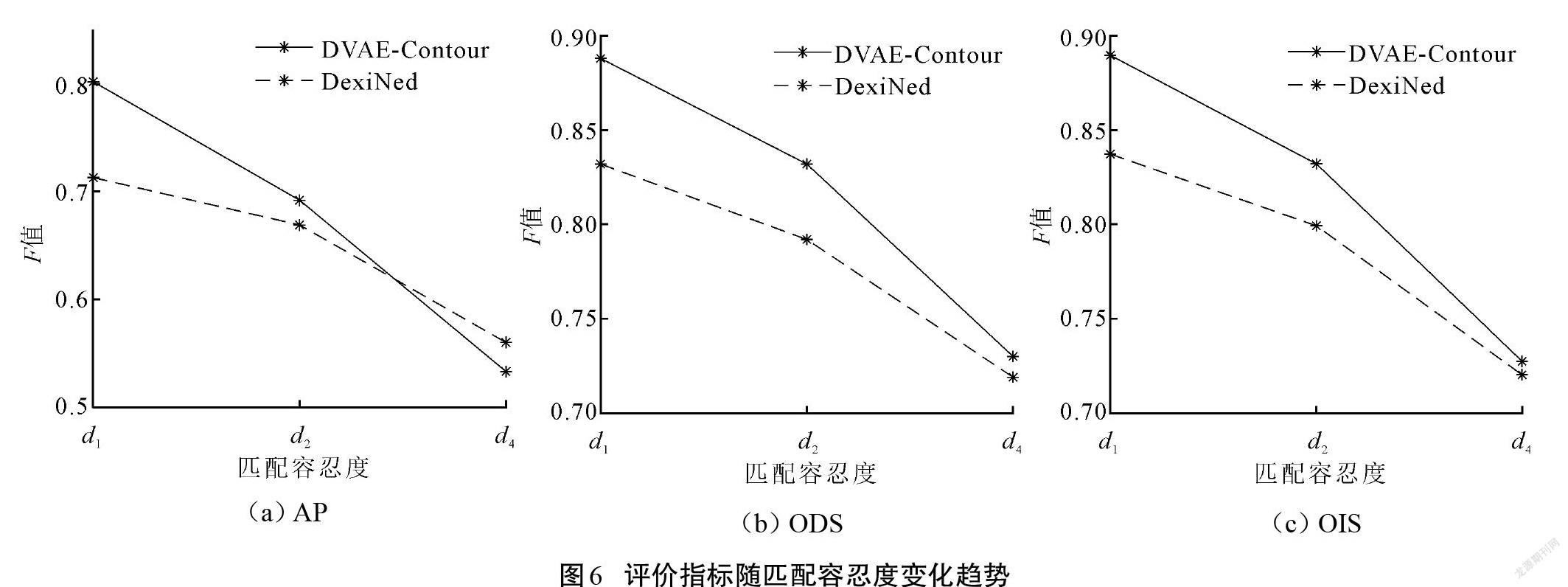
对所提出模型提取轮廓的精细度进行分析。在进行评估时,需要设置轮廓像素匹配容忍度,用来判断一个像素是否能够被判定为正确的轮廓像素,此容忍度越小,对像素的判断越严格。因此,通过设置不同的匹配容忍度来测试模型输出轮廓的精细程度。设置了[d1=0.007 5]、[d2=d1/2]、[d4=d1/4]这3个容忍度对DexiNed[18]以及本文所提出的DVAE-Contour进行了实验。为了使评估结果对精细度分析有意义,所有的轮廓都没有经过非极大值抑制的细化处理。
实验结果如图6所示,当轮廓像素的匹配容忍度变小时,由于对轮廓像素的评判更加严格,图中的2种方法在3个评价指标中都有明显的下降。对于ODS和OIS 2个评价指标,DVAE-Contour的性能在3种匹配容忍度下都优于DexiNed,而AP则在匹配容忍度为[d4]的情况下落后于DexiNed。
2.3 模型性能对比
为了进一步分析模型性能,将本文方法 (DVAE-Contour)与同类轮廓检测方法在精度和模型训练参数量方面进行对比,包括SED[19]、HED[7]、CED[3]、RCF[10]、BDCN[11]、DexiNed[18]。在采用非极大值抑制且轮廓像素匹配容忍度为0.007 5的情况下,各方法的ODS、OIS、AP以及所需要训练的参数量(Parameters(M))结果如表1所示。由表1可以看到,本文提出的DVAE-Contour在ODS和OIS這2项评价指标下都明显优于最新算法DexiNed,分别高出3.0%和2.4%,而在参数量方面略高于DexiNed,这是因为本文方法采用的模型参数量高于VGG16的ResNet50。为公平比较,采用与DexiNed相同的VGG16作为主干网络,本文方法能够在训练更少的参数情况下获得优于DexiNed的ODS与OIS,分别高出0.6%和0.4%。虽然本文方法的AP低于其他方法,但是通过分析2.2中的数据发现,这些方法的AP较高是由非极大值抑制所带来的,当没有非极大值抑制时,这些方法的AP可能会显著下降。例如DexiNed在不使用非极大值抑制时AP只有0.713,相较于使用了非极大值抑制的AP下降了19.2%。而相比之下,DVAE-Contour对非极大值抑制的依赖则非常小,在不使用非极大值抑制时AP仍然能够达到0.802,只下降了1.0%。
图7为DexiNed与DVAE-Contour的轮廓检测效果图。可以看到,DexiNed在一些轮廓密集的区域无法很好地呈现出轮廓细节,其输出中有些不同的轮廓甚至被错误地融为了一体,而DVAE-Contour则能更好地保留轮廓细节。
3 结论
本文研究了如何利用深度学习模型进行精细轮廓检测。近年来,基于卷积神经网络的轮廓检测方法输出轮廓定位不准确且模糊,分析认为其原因是这些模型没有真正地将轮廓检测建模为一个图像到图像的任务。为了进行真正意义上的图像到图像建模,借助离散变分自编码器训练轮廓检测模型,利用其对图像中高频成分的强大编码能力,帮助轮廓检测模型提取高频的轮廓信息,从而使输出轮廓更加清晰和尖锐。通过不断增大评价指标对轮廓的准确性要求进行了轮廓精细度分析,实验数据表明,随着精确性要求的提高,本文方法的大多数性能指标都优于其他检测模型。
本文方法虽然在一定程度上解决了轮廓定位不准确和模糊的问题,但其良好性能依赖于强大的离散变分自编码器,当离散变分自编码器的特征压缩能力不强时,模型性能将有所下降,因此,有必要进一步研究如何利用小型的特征压缩模型对模型进行训练。
参考文献
[1] ZITNICK C L,DOLLÁR P. Edge boxes:locating object proposals from edges[C]//European Conference on Computer Vision,2014:391-405.
[2] ZHU G,PORIKLI F,LI H D.Tracking randomly moving objects on edge box proposals[J/OL].Computer Science,2015:943-951[2022-03-01]. https://arxiv.org/pdf/1507.08085v2.pdf.
[3] WANG Y P,ZHAO X,HUANG K Q.Deep crisp boundaries[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2017:3892-3900.
[4] BERTASIUS G,SHI J B,TORRESANI L.Semantic segmentation with boundary neural fields[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:3602-3610.
[5] WAN J Q,LIU Y,WEI D L,et al. Super-BPD:super boundary-to-pixel direction for fast image segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2020:9253-9262.
[6] 林川,曹以隽.基于深度学习的轮廓检测算法:综述[J].广西科技大学学报,2019,30(2):1-12.
[7] XIE S N,TU Z W.Holistically-nested edge detection[C]//Proceedings of the IEEE International Conference on Computer Vision,2015:1395-1403.
[8] LONG J,SHELHAMER E,DARRELL T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015:3431-3440.
[9] LEE C Y,XIE S N,GALLAGHER P W, et al.Deeply-supervised nets[C]//Conference on Artificial Intelligence and Statistics,2015:562-570.
[10] LIU Y,CHENG M M,HU X W,et al. Richer convolutional features for edge detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2017:3000-3009.
[11] HE J Z,ZHANG S L,YANG M,et al. Bi-directional cascade network for perceptual edge detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2019:3828-3837.
[12] 喬亚坤,林川,张贞光.基于深度学习的轮廓检测模型的交互式解码网络[J].广西科技大学学报,2022,33(1):46-53.
[13] HUAN L X,XUE N,ZHENG X W,et al. Unmixing convolutional features for crisp edge detection[J/OL].IEEE Transactions on Pattern Analysis and Machine Intelligence,2021:1-9[2022-03-01]. https://arxiv.org/pdf/2011.09808v2.pdf.
[14] MADDISON C J,MNIH A,TEH Y W. The concrete distribution:a continuous relaxation of discrete random variables[C]//International Conference on Learning Representations,2017.
[15] RAMESH A,PAVLOV M,GOH G,et al.Zero-shot text-to-image generation[C]//International Conference on Machine Learning,2021:8821-8831.
[16] HE K M,ZHANG X Y,REN S Q,et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:770-778.
[17] DENG J,DONG W,SOCHER R,et al. ImageNet:a large-scale hierarchical image database[C]//IEEE Conference on Computer Vision and Pattern Recognition,2009:248-255.
[18] SORIA X,RIBA E,SAPPA A. Dense extreme inception network:towards a robust CNN model for edge detection[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision,2020: 1923-1932.
[19] AKBARINIA A,PARRAGA C A.Feedback and surround modulated boundary detection[J].International Journal of Computer Vision,2018,126(12):1367-1380.
Crisp contour detection based on ResNet and discrete variational
auto-encoder
WANG Qu,LIN Chuan*,CHEN Yongliang
(School of Electrical, Electronic and Computer Science, Guangxi University of Science and Technology,
Liuzhou 545616, China)
Abstract: Traditional contour detection methods based on convolutional neural network are mostly encode-decode structures composed of encode and decode networks, which exhibit better performance but still suffer from inaccurate contour localization and blurred output contours. To solve this problem, this paper proposes a contour detection method based on the discrete variational auto-encoder. Unlike traditional encode-decode methods, this paper discards the decode network, the encoder and decoder of the discrete variational self-encoder are used to cooperate with the encode network for training and contour detection, respectively. In addition, a loss function with dynamic weights is designed to solve the problem of extremely unbalanced category distribution encountered in the training process of the method in this paper. Based on the BIPED data set, the contour crispness experiment shows that this method can outperform the newest method DexiNed using more strict criteria, while the ODS F-measure of this method can reach 0.889 under general evaluation criteria, which is 3.0% better than DexiNed. This indicates that the utilization of the discrete variational auto-encoder not only helps the model to improve the contour crispness, but also significantly improve the contour detection performance of the model.
Key words: contour detection;deep learning;discrete variational auto-encoder;computer vision; cross-entropy loss function
(責任编辑:黎 娅)
猜你喜欢
计算机应用(2016年12期)2017-01-13
中国新通信(2016年22期)2017-01-13
无线互联科技(2016年13期)2017-01-10
现代电子技术(2016年22期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
