
流域水文模型不确定性研究进展
2022-07-07 06:51马金锋
人民黄河 2022年7期
张 京,马金锋,马 梅
(1.中国科学院 生态环境研究中心 城市与区域生态国家重点实验室,北京 100085;2.中国科学院大学,北京 100049)
1 研究背景
水是人类社会赖以生存和发展的重要自然资源,然而随着人类活动的加剧,水污染已成为流域管理的重要问题,引起全世界的广泛关注。 水污染主要分为点源与非点源污染,其中点源污染相对易于识别和治理,大部分国家已对其实施了较好的控制。 但是流域非点源污染具有分散、不易识别的特点,目前尚未得到有效的控制和治理,水污染防治工作仍然任重道远[1-2],迫切需要流域尺度的水污染管理技术支持。
流域水文模型是在掌握流域水文规律的基础上实现水量、泥沙以及伴随发生的水质过程模拟的重要手段[3]。 流域水文模型一方面可以用于流域内水量水质预报预警,另一方面还可以为相应的湖库、河流模型提供必要的边界条件,对于支撑流域的水污染预警管理具有重要意义。 流域水文模型经过多年的发展,涌现了许多代表性的模型,如SWAT、MIKE SHE、HSPF、TOPMODEL、HEQM 以及新安江模型[4]等。 采用流域水文模型模拟流域水量水质,进行非点源污染量化以及支撑污染治理决策,已经成为水文和环境等交叉学科的研究重点[5-6]。 然而水污染本身是一个复杂非线性问题,由于人们认知水平有限,因此目前的流域水文模型在实际应用过程中不可避免地存在诸多不确定性。
为了提高流域水文模型模拟结果的精度,减小不确定性对水文模型模拟的影响,国内外学者对流域水文模型不确定性进行了大量研究[7],主要包括模型的输入数据、参数以及结构3 个方面[8-9]。 模型输入数据来源众多且异构,不同的输入数据,不同的参数选择与组合,以及不同模型的结构对模拟结果都具有显著影响。 笔者针对流域水文模型的不确定性,着重就近年来流域水文模型在输入数据、参数以及结构方面的研究进行了分析总结。
2 模型输入数据不确定性
模型输入数据(Input data)的不确定性是导致流域水文模型不确定性的主要来源,包括空间数据(地形、土地利用和土壤)和气象数据。 模型输入数据总的特点是来源众多、空间异构、时间动态。
2.1 地形数据
地形DEM 数据关系到河网生成(即河流的长、宽与深度)、地形坡度以及水流流向的判断,进而影响流域的产汇流过程,因此是众多流域水文模型最重要的基础数据。 地形数据不确定性主要由DEM 数据的分辨率、来源以及重采样方法(Resampling methods)造成。 DEM 数据的分辨率具有尺度效应,分辨率决定DEM 栅格的大小。 如图1 所示,DEM 数据分辨率越低,栅格越大,研究区域的最大坡度越小,导致地形坡度被平坦化而无法反映真实的地形特征,从而导致图2 中河道的提取结果,增加反映真实产汇流过程的难度;而分辨率越高,栅格越小,越能反映流域的地形特征,但栅格太小会给大尺度的流域带来计算量过大的问题。
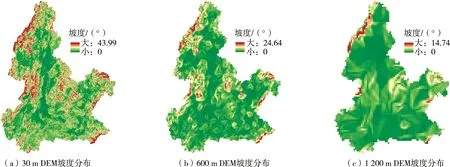
图1 DEM 分辨率对坡度的影响
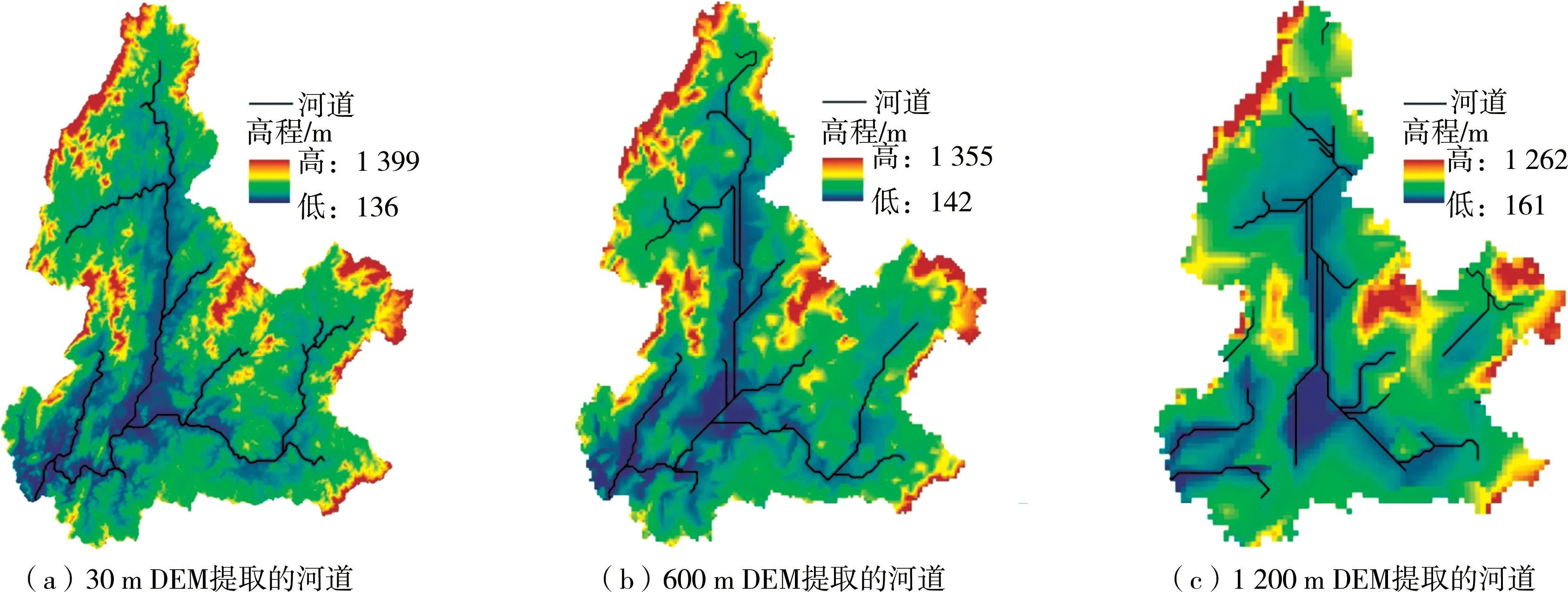
图2 坡度平坦化对河道提取的影响
Chaplot[10]最早探究了DEM 分辨率(20 ~500 m)在SWAT 模型中的尺度效应,研究发现50 m 的分辨率是一个重要的阈值,当分辨率小于50 m 时DEM 分辨率的变化对径流模拟的影响不大,当分辨率超过50 m时会给泥沙和氮营养物的模拟带来误差。 Lin 等[11]进一步探究高分辨率(5 ~140 m)DEM 的尺度效应,发现SWAT 模型对低分辨率DEM 数据更为敏感,分辨率越低总磷总氮的模拟精度越低。 同样的尺度效应在HSPF[12]和TOPMODEL[13]模型中也被研究发现,但对于DEM 分辨率的选取没有一个固定的标准,要根据所研究流域的实际情况选择合理的分辨率,这在一定程度上增加了DEM 数据的不确定性。
以往DEM 数据主要来源于人为量测,大尺度的优质DEM 数据缺乏是造成难以建立可靠流域水文模型的主要原因。 但是,随着遥感(RS)与地理信息系统(GIS)的发展,出现了众多DEM 数据产品,比如2009年日本经济产业部和美国宇航局联合发布的ASTER DEM,美、意、德三国宇航局联合发布的SRTM DEM,以及2010年美国地理空间情报局发布的GMTED 2010 等。 我国为了共享统一的DEM 数据,建立了地理空间数据云(http://www.gscloud.cn/),发布了一系列DEM 数据。 不同来源的DEM 数据产品影响着流域水文模型的水量水质结果,如何选择合适的DEM 数据产品一度成为建立可靠的流域水文模型前需要思考的重要问题。 Tan 等[14]探究了不同来源的DEM 数据对模型不确定性的影响,结果发现SRTM DEM 的不确定性小于ASTER DEM 的,SRTM DEM 数据对于建立流域水文模型更可取。 虽然地形数据来源问题得到了解决,但是从DEM 数据中获取高程数据的重采样方法给模型带来的不确定性问题近年来引起了许多学者的关注[15-16]。 Tan 等[17]发现多次样条法和最邻近插值法处理得到的DEM 数据给模型带来的相对误差(RE=6.0%)小于双线性法的(RE=7.2%)和三次卷积法的(RE=7.5%),多次样条法和最邻近插值法对于减小DEM 数据处理造成的不确定性更为可取。
2.2 土地利用和土壤数据
土地利用数据主要包括流域的植被覆盖类型、植被指数。 土壤数据主要包括土壤饱和度、有机碳含量、密度、厚度等。 流域水文模型对不同精度的土地利用数据和土壤数据非常敏感,尤其体现在对流域径流的模拟上[18],进而影响泥沙和污染物的模拟。 学者们针对土地利用和土壤数据的分辨率对模型输出的影响进行了大量研究[19],认为当土地利用和土壤数据分辨率高时模型模拟值较为准确。 但事实上,当流域面积达到一定尺度或数据达到一定的精度之后,分辨率对于模拟结果的影响并不大,并且在一定范围内均可达到目标效果[20-21]。 相反,高分辨率的数据输入到模型中会得到数量更多的土地利用和土壤类型、HRU 和子流域,增加了模型率定的难度。 因此,需要选择恰当分辨率的数据以平衡好精度和计算量之间的矛盾。
除了数据的分辨率对模型输出影响显著外,数据的时间变化也会使模型产生不确定性。 受气候变化和人类活动影响,流域内土地利用和土壤类型在5 a 内会发生显著变化[22-23]。 当对研究区进行较长时间尺度水文和水质模拟时,多数研究只考虑了气象条件的时间序列,而土地利用类型、土壤、地形等数据在模拟过程中设定为不变,这就会使模型模拟的结果存在偏差,尤其是对于非点源污染物的模拟,由于氮磷主要来源于耕地[24],因此会随着土地利用方式的转变而转变。 Wang 等[25]通过对模型分别输入静态和动态土地利用数据,发现采用动态土地利用数据后,率定期总氮模拟的纳什系数(NS)由0.50 增大到0.70,验证期总氮模拟的NS由0.30增大到0.50。 因此,对于流域水文模型长时间尺度模拟而言,采用多期土地利用和土壤数据可使模拟值更加接近真实情况。
2.3 气象数据
在气象数据中,降水数据是模型的主要驱动条件,直接影响径流过程的模拟,进而影响水体中的泥沙和水质过程模拟。 降水数据的不确定性主要来源于降水数据的准确性、完整度、降水站点的数量以及空间分布。
高分辨率的监测数值对模型造成的误差较小,并且经过地面站点矫正的卫星数据更为准确。 Alnahit等[26]选取了基于观测站点的PRISM 降水数据、卫星(3B42RT、PERSIANN)的降水数据以及与地面站点进行过偏差校正的卫星降水数据(3B42、PERSIANNCDR 和GPCP-1DD)输入SWAT 模型进行水文模拟,结果表明:与没有进行偏差校正的卫星降水数据相比,进行过偏差校正的卫星降水数据在捕捉降水的季节特点方面表现更好,准确度更高,PRISM 具有较高的空间分辨率,因此效果最佳。 同时,降水数据的完整度也是决定降水数据不确定性的重要原因。 Chen 等[27]在进行气象数据载入时,依次剔除降水时间序列中10%~60%的数据,结果表明当降水数据的完整度低于80%时,NS会低于0.60 并持续下降。 后续的研究中Chen 等[28]还对比了不同完整度的降水数据对模型不确定性的影响,认为枯水期降水数据的缺失将会大大增加模型的不确定性。
除了降水数据的准确性和完整度以外,降水站点的数量以及空间分布也影响着降水数据的质量。 传统稀疏单一的气象站点不能很好地描述整个流域空间的气象要素,降水站点数量直接影响模拟的精度。 Chen等[27]依据降水站点的位置移除11%~67%的站点,从而量化了空间站点数量的影响,结果显示随着降水站点的缺失,模拟结果逐渐恶化,径流模拟的NS从0.75降到0.60,总磷模拟的NS从0.99 降到0.74。 此外,降水站点的空间分布位置也影响模型的模拟结果,不一定要均匀分布,越靠近径流测量断面的降水站点越有使用价值。 Tan 等[29]通过对研究区域内7 个降水站点(S1~S7)进行不同的组合输入SWAT 模型,发现当组合内有靠近水文站的降水站点(S6)时模拟结果较好。 因此,对于未来雨量站优化设计,应综合考虑水文站位置和子流域位置来设定降水站点的位置和数量。
为减少降水数据不确定性给模型工作者带来的复杂工作量,Meng 等[30]采用2421 个国家级自动气象站和业务考核的近40000 个区域自动气象站的气象数据,制作了中国大气同化驱动数据集(CMADS)。 各系列数据集(V1.0、V1.1、V1.2、V1.3)的空间分辨率分别为(1/3)°、(1/4)°、(1/6)°、(1/8)°,有效减少了气象站数量、位置和数据缺失带来的不确定性。 图3 是对比采用CMADS 数据和中国气象数据网数据对梅川江流域汾坑站径流和泥沙过程的模拟,可以明显看出采用CMADS 数据后,径流和泥沙的峰值模拟得到了改善,NS分别提高了0.07 和0.23。
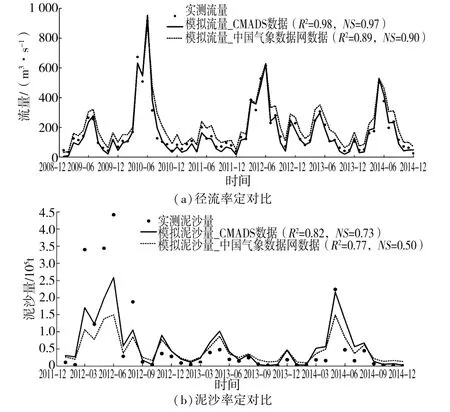
图3 CMADS 气象数据对径流和泥沙模拟的改进
3 模型参数不确定性
流域水文模型在不断改进和优化的过程中,虽然越来越接近真实情况,但随着模型参数越来越多,参数选择、参数相关性以及时空尺度都会给模型参数带来不确定性[31]
3.1 参数选择
参数的敏感性是参数选择的重要依据,敏感性分析也是参数不确定性分析的重要方面。 参数敏感性分析的目的主要包括:确定敏感性高的参数和参数组合、确定不同参数组合对模型输出的贡献以及模型间的相互作用并剔除低贡献率和无效参数,降低模型计算量[32-33]。 模型参数的敏感性分析方法主要包括Morris分析法[34-35]、回归分析法[36]、FAST 分析法[37]和Sobol分析法[38]等。 国内外学者对各类敏感性分析方法进行了深入研究[39],各敏感性分析方法均有优势和弊端,陈卫平等[40]对几种典型方法的优缺点也进行了详细的分析。 因此,需要运用优化算法(遗传算法、贝叶斯优化算法等)来弥补单一算法的缺陷。 任婷玉等[41]通过Sobol 分析法对模型进行敏感性分析并筛选出敏感参数后,以高斯过程为概率代理模型,采用贝叶斯优化算法对筛选出的参数进行估值,结果显示,当贝叶斯优化算法的采集函数为期望提升量(EI)时,仅需要141次迭代就可以达到较好的优化效果。
3.2 参数相关性
复杂多变的水文过程可通过各种各样的参数进行表征,参数之间的相关性直接决定参数的组合。 在进行模型率定时,多数研究将参数假设为相互独立,忽略了参数的相关性。 然而,两个敏感性强的参数之间也会呈现出显著正负相关,这就会增加模型参数的不确定性[42],甚至难以找到最优参数。 庞树江等[43]通过构建潮河流域HSPF 模型,对识别出的5 个敏感参数进行相关性分析,结果表明,下层土壤含水量(LZSN)与上层土壤含水量(UZSN)和入渗能力(INFILT)分别呈极显著正相关和负相关关系,INFILT与地下水蒸散发能力(AGWRC)和UZSN也分别呈极显著正相关和负相关关系。 另外,当敏感参数多于两个时,在进行参数组合时会出现异参同效现象,原因是进行模型率定时采用的最优算法出现了多于敏感参数个数的方程而产生多个解,即敏感参数之间的相互补偿效应。 在不同条件下异参同效的强度也不相同。 王欣[44]通过研究发现,在理想资料背景下的异参同效明显程度弱于实测资料背景下的,消除异参同效现象是流域水文模型参数率定面临的重要问题。 张质明等[45]提出通过设置约束条件剔除部分不符合污染物转化规律的参数组合。 芮孝芳[46]认为可将流域模型分解为子模型,为每个子模型选择特定的目标函数,多目标优化[47]减少待率定参数数量,同时选择合适的算法和目标函数识别不敏感参数,来减少异参同效现象的产生。
3.3 参数动态变化和空间异质性
对于已经确定的参数和参数组合,在模拟不同时间和空间的流域时参数也会呈现出动态变化和空间异质性。 对于同一个流域,有时将率定期的最优参数组合用于验证期时模拟结果并不理想,原因是忽略了参数的动态变化性。 Guse 等[48]通过探究参数的动态变化发现,模型的关键参数在丰水期为深蓄水层渗透系数(RCHRG_DP)、地下水滞后系数(GW_DELAY)和基流消退系数(ALPHA_BF),而在枯水期则为土壤蒸发补偿系数(ESCO)。 对于不同空间尺度的流域,参数适用性也不相同,上游率定好的参数并不完全适用于下游。 Chen 等[49]利用嵌套式流域思想将流域划分为8 个尺度等级(依次为66、349、778、825、1485、2013、2378、2422 km2)探究参数的空间异质性,在特定时期进行水文模拟,会出现土壤湿容重(SOL_BD)和土壤饱和导水率(SOL_K)在空间规模为66 km2时为关键参数,而在349 ~2422 km2范围内作用并不明显。 因此,以流域模拟的时间、空间为依据选择最合适的参数和参数组合,区分参数在时间和空间上的变化并对已经率定好的参数进行后期维护,对于提高模型精度和降低参数的不确定性尤为重要。
4 模型结构不确定性
流域水文模型涉及的水文过程繁多,不同模型采用的求解方法也各有不同。 比如,SWAT 模型采用SCS 径流曲线系数法或Green-Ampt 公式模拟下渗,采用线性水库或马斯京根法模拟河道演进。 而HSPF 模型在模拟下渗和河道演进时采用的分别是Philip 公式与动力波法[50]。 不同求解方法导致模型对输入数据的要求不同,比如,SWAT 模型需要输入气象的逐日数据,而HSPF 模型可以是逐时数据,因此HSPF 模型更能反映污染物的日尺度变化特征。 同时,每个流域水文模型都具有自己独特的模型结构,目前流域水文模型的结构主要有分布式和半分布式。
半分布式模型采用的是以水文响应单元(HRU)划分的方式建立各子流域逻辑关系,优点是可以将复杂的水文响应单元化繁为简,使得模型可以适用于大尺度流域的快速计算,代表模型有SWAT、HEQM[51]等。 但对于一些人为活动影响剧烈的城市区域,人为的取用水过程显著地改变自然状态下的河道径流过程,半分布式模型不能很好地表达城市水文水质过程的空间异质性,半分布式的求解方式导致模型结构存在不确定性。 分布式模型采用栅格化的方式,相对于半分布式模型结构更加精细,可以很好地弥补半分布式模型的缺点,充分表达模拟结果的空间异质性,代表模型有HSPF、VIC 等。 由于分布式模型在每个栅格单元都进行流域水文模式计算,因此模型往往对计算能力要求很高,这个问题随着计算机并行和集群计算手段的发展终将得到合理的解决,分布式计算将是未来水文模型的发展方向。
虽然水文模型可以对水文过程进行直观的重现和预测,从而指导水资源的规划和利用,但是在模型率定的过程中,有时会出现如图4 所示的情况,无论怎么调整参数,模拟值和观测值仍然有较大的误差。 当模拟值的波动范围始终不包含真实值时,这种系统误差可以理解为模型结构存在不确定性。 模型结构的不确定性主要来源于人对复杂水文过程的认知不足,对于建模人员而言,熟练掌握各个水文过程的机理并不容易[52]。 事实上,所有的流域水文模型都会对真实的水文过程进行抽象或简化表达,这在一定程度上导致模型结构存在不确定性[53]。 模型结构代表了额外的不确定性,应在水文不确定性评估中予以考虑。

图4 模型结构不确定性示意
为了评估模型结构的不确定性,Mcmillan 等[54]提出了一种使用时变跟踪数据和水龄来理解模型结构不确定性的框架(FUSE),研究认为尽管需要模拟的径流过程很相近,但模型的选择对水龄特征模拟具有显著影响。 Karlsson 等[55]评估了3 个模型(NAM、SWAT、MIKE SHE)的水文过程模拟结果,发现平水年3 个模型的模拟结果差异不大,但由于水文模型结构和过程方程式不同,因此极端降水情况下3 个模型的模拟结果差异很大。 Chen 等[50]运用SWAT 和HSPF 模型模拟了西苕溪流域的径流响应,结果表明虽然两种模型均可以很好地模拟逐日和季节性的流量,但它们不能准确地重建极端流量过程,比如年度最大流量和年度7 d 最小流量。 Zhang 等[51]结合Bootstrap 重采样方法和SCE-UA 自动校准技术探究HEQM 模型水质模块的不确定性源,发现在95%的置信度下,水质参数的不确定性占总水质模拟的12.1%,但是,若考虑水质模块的结构不确定性,则不确定性占比增至92.0%,可见模型结构本身是HEQM 模型(尤其是水质模块)的主要不确定性来源。
在评估各种流域水文模型结构不确定性的同时,如何降低模型结构带来的不确定性成为水文不确定性的研究热点。 目前,多模型耦合模拟是降低流域水文模型结构不确定性的重要手段,使用两个或两个以上的模型并综合各个模型的模拟结果集合为一个确定性结果,避免单一模型改变参数组合而影响模型效果的问题。 将MODFLOW 和SWAT 耦合为SWAT-MODFLOW模型[56-57]可更加系统地解释地表和地下水系统的主要水文过程。 为深入探究硝酸盐在表面径流和地下径流系统中的迁移,Wei 等[58]在SWAT-MODFLOW 模型基础上耦合输运模型RT3D,建立了流域系统中硝酸盐输送与转移的SWAT-MODFLOW-RT3D 模型。 为增强模型适用性,Aliyari 等[59]对SWAT-MODFLOW 模型进行改进,使其可用于世界范围内的农业城市流域。
5 问题与展望
流域水文模型是支撑流域水污染管理的重要手段,模型输入数据、参数和结构的不确定性直接影响模型模拟结果的可靠性。 模型不确定性分析中存在的问题和未来的研究方向如下。
(1)模型输入数据具有多源、动态、异构的特点,其不确定性主要来源于:①DEM 数据的分辨率、来源以及重采样方法;②土地利用和土壤数据的分辨率及长时间尺度下采用单一时期静态数据;③降水数据的准确性、完整度、降水站点的数量以及空间分布。 未来应探究空间输入数据的尺度效应,平衡好模型精度和计算量的矛盾,从而选择合理的空间尺度数据;探究土地利用变化对长时间尺度模拟的影响;采用多源融合数据改善降水数据的完整性和准确度。
(2)流域水文模型参数较多,各种单一的敏感性分析方法均有各自的优缺点,并且一旦忽略参数之间的相关性,很难筛选出最优组合,对于已经率定好的参数,在模拟不同时间和空间的流域时参数也会呈现动态变化和空间异质性。 未来应致力于优化参数敏感性分析方法,降低参数间的异参同效;探究动态改变输入数据对模型参数取值的影响,对于长时间尺度的模拟,模型参数除了本地化以外,还需要进行后期维护。
(3)所有的流域水文模型都会对真实水文过程进行抽象或简化表达,单一流域水文模型受其求解方法的限制直接影响模型结构。 多模型耦合模拟是未来水文模型研究的趋势,但是多模型耦合模拟仍然具有计算强度大的问题,需要花费较长的时间和较高的计算资源进行参数优化和精度验证。 因此,未来应该加强实地水文查勘,并结合模拟目标有选择性地对水文过程进行删减,开发一些水文过程子模块工具,使得建模人员可以自由组合各个水文过程,支持分时段动态模拟,从而建立具有区域特色的最优水文模型。
猜你喜欢
法律方法(2022年2期)2022-10-20
现代经济信息(2021年3期)2021-11-23
成都信息工程大学学报(2021年3期)2021-11-22
陕西档案(2021年2期)2021-05-21
北京航空航天大学学报(2020年10期)2020-11-14
英语文摘(2019年6期)2019-09-18
中国外汇(2019年7期)2019-07-13
人大建设(2017年6期)2017-09-26
黄河黄土黄种人·水与中国(2017年2期)2017-03-16
中国科技术语(2016年4期)2016-11-19
