
基于蚁群-遗传算法的光谱选择方法与应用
2022-07-06 05:41薛河儒刘江平刘美辰胡鹏伟孙德刚
光谱学与光谱分析 2022年7期
黄 清,薛河儒*, 刘江平*,刘美辰,胡鹏伟 ,孙德刚
1. 内蒙古农业大学计算机与信息工程学院,内蒙古 呼和浩特 010000 2. 山东华宇工学院信息工程学院,山东 德州 253000
引 言
1 实验部分
1.1 材料
在天猫、 京东等平台购买了6种不同品牌的牛奶,其中,特仑苏脂肪含量为4.4 g·(100 mL)-1,QQ星和蒙牛高钙脂肪含量为3.7 g·(100 mL)-1,The land脂肪含量为3.3 g·(100 mL)-1,伊利甄浓脂肪含量为4.6 g·(100 mL)-1,伊利脱脂脂肪含量为0 g·(100 mL)-1。
1.2 样本反射光谱数据采集
高光谱采集系统由高光谱成像仪、 高精度扫描云台、 石英卤钨灯照明电源、 等部件组成。 高光谱测量仪为美国Headwall公司2010年生产的型号为1003B—10141的高光谱成像仪,光谱范围400~1 000 nm,共125个波段,采集到的光谱图像分辨率为777×1 004像素。
在实验的过程中,尽量保持牛奶样本与摄像头的距离约20 cm,为保证不受其他反射光源的影响,在牛奶样本盛器下垫一块黑色绒布。 在光谱采集过程中,光谱摄像头中的传感器中会产生暗电流,每次采集到的光谱数据会伴随着一定的噪声,影响高光谱图像的质量,为了避免客观因素影响,在每次采集光谱图像之前,需要对该系统进行黑白校正处理,在一定程度上提高图像的质量[5]。 实验中,首先盖上相机盖,点击暗电流,采集全黑的光谱校正图像IB; 然后取下相机盖,用白板采集全白校正图像IW; 最后,采集牛奶样本的光谱图像,每个样本平行采集三次,最后根据公式IC=(IR-IB)/(IW-IB)对采集到的牛奶光谱图像进行黑白校正。 其中,IC为校正后的牛奶光谱图像,IR为实验过程中采集到的牛奶光谱图像。 利用ENVI软件从三张图片中选取效果最好的光谱图像,从中选取40个光线清晰均匀的感兴趣区域,导出每个区域的光谱反射率数据作为该品牌牛奶的40个样本进行实验。 一共分别采集了6种不同品牌的牛奶样品,合计240个样本。 图1(a—f)是六个不同品牌牛奶的原始光谱数据反射曲线。 受采集环境和仪器设备的影响,虽然原始高光谱图像经过了黑白校正处理,但是数据中仍然存在一些无用的信息和噪声,通过图1可以看出,伊利甄浓和QQ星的光谱反射图像在采集的过程中受到的干扰较大。 为了降低散射光和噪声的干扰,需要对采集到的光谱数据进行数据预处理。
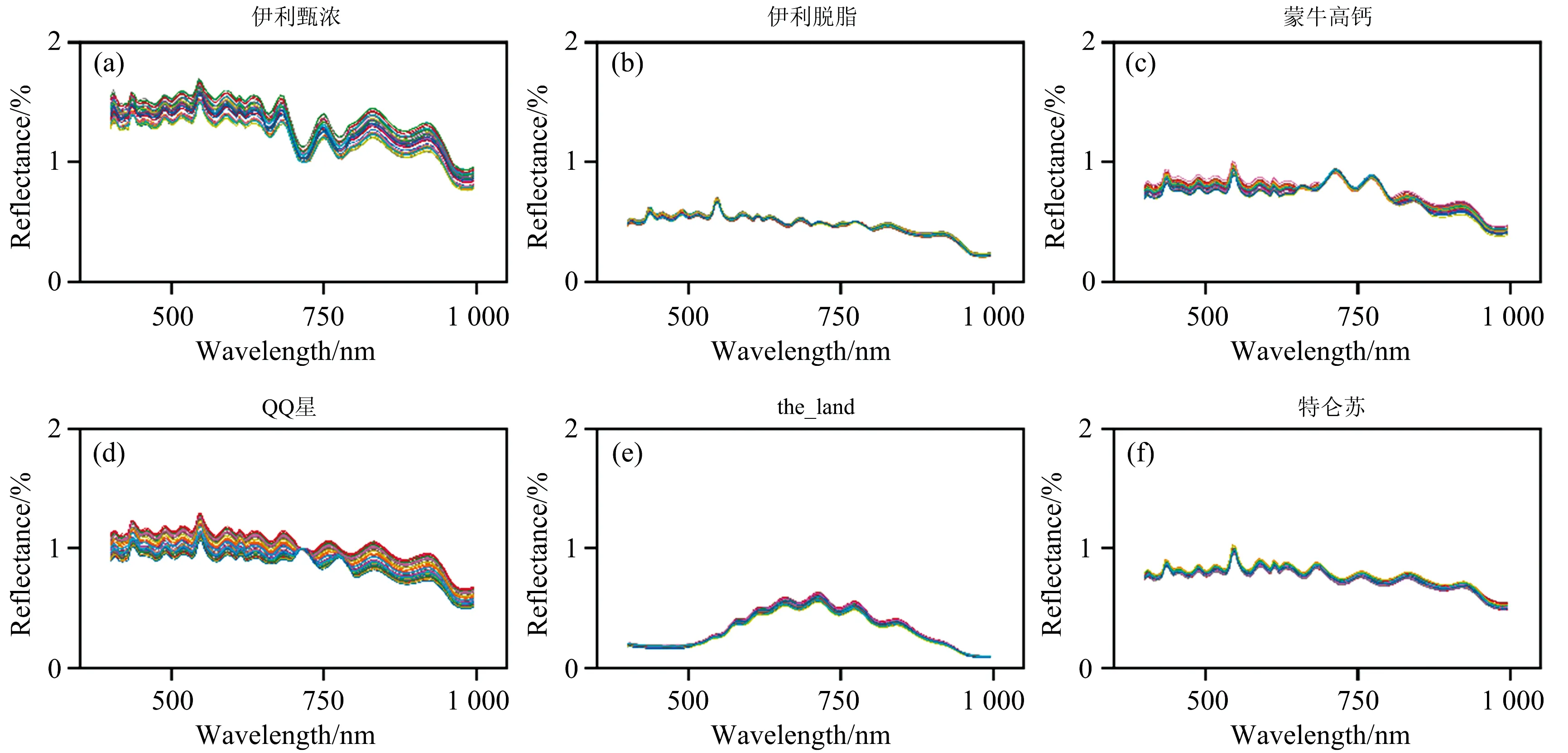
图1 六种不同品牌样本原始光谱图(a): 伊利甄浓; (b): 伊利脱脂; (c): 蒙牛高钙; (d): QQ星; (e): The land; (f): 特仑苏Fig.1 Original spectra of samples of six different brands(a): Yilizhennong; (b): Yiliskim milk; (c): Mengniu high calcium milk; (d): QQ star; (e): The land; (f): Telunsu
2 结果与讨论
2.1 光谱数据预处理
光谱分析中常用的预处理方法包括导数校正法(其中包括一阶导数 (first derivative, 1stDer),二阶导数(second derivative, 2stDer),和多阶导数等),多元散射校正(multiplicative scatter correction, MSC),标准正态变换(standard normoal variate transformation, SNV),卷积平滑(savitzky-golay, S-G)等。 其中导数校正法和S-G平滑可以有效消除基线平滑和平移引起的噪声,MSC和SNV则可以减少因光的散射等现象造成的噪声。

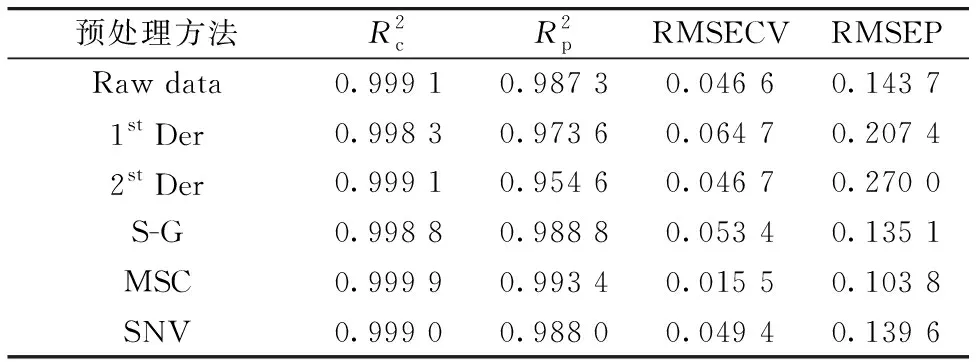
表1 不同预处理方法的牛奶脂肪含量PLS回归模型预测结果
2.2 特征波段提取
蚂蚁在寻找食物的过程中,会根据路径的长短,判断该路径的好坏,留下不同浓度的信息,方便自己的同伴判断觅食的路径,随着时间的延长,较优的路径上积累的信息元素比例越来越高,越来越多的蚂蚁选择此路径,慢慢的形成了一种正反馈机制。 蚁群算法就是模拟蚂蚁觅食这一行为,来寻找最优特征波段组合。 在基本蚁群算法中,初始信息素浓度都是人为设定的(大多数都设定为1),初始信息素的匮乏,使得算法收敛时间过长,执行效率低下[7]。 受到CARS算法的启发,将PLS回归模型系数的绝对值作为评价波段好坏的标准,首先在全波段数据下建立PLS回归模型,每个波段对应的回归系数绝对值作为信息素的初始值。 避免了在第一次迭代中,蚂蚁随机寻找特征波段的缺点,加快了算法的收敛速度。 将蚁群算法与PLS回归系数相结合,虽然解决了传统蚁群算法收敛速度慢,模型复杂的缺点,但是仍然无法解决蚁群算法由于正反馈机制容易陷入局部最优的缺点,因此将PLS-ACO算法与遗传算法相结合,经过遗传算法迭代产生更多优秀的个体,为计算波段的贡献率,提供更多的样本,以提高算法的稳定性和通用性。 研究提出了全局阈值(threshol)的概念,传统的遗传算法和蚁群算法,都是选取某一次迭代最好的个体或几个个体来进入贡献矩阵中,但是在前几次的迭代中的最优个体,很有可能不及最后几代里的最差个体。 通过全局阈值,对产生的所有个体来进行筛选。 大于全局阈值的个体将进入到贡献矩阵中,计算每个波段的贡献率,也就是贡献矩阵里每个波段组合中每个波段出现的次数,依次剔除贡献率最小的波段,对筛选后的波段组合建立PLS回归预测模型,选择适应度值最大的波段组合作为最终的最优波段组合。
2.2.1 PLS-ACO
(1) 初始化算法的参数: 用全光谱波段数据建立PLS回归模型,得到对应波段的回归系数(β)的绝对值作为蚁群的初始信息素矩阵(init-pheromone)。 最大迭代次数(max-iters),蚂蚁个数(max-ants),每只蚂蚁选取最大特征个数(max-features), 以及信息素启发因子(Q),信息素挥发因子(ρ),入选特征路径矩阵(has), 未选路径矩阵(have), 全局阈值, 贡献矩阵(contribution)。
(2) 蚂蚁选择路径: 在每一次迭代中,每只蚂蚁随机选择一个特征波段作为路径起始点,并将其储存在has矩阵,have矩阵择则删除该特征波段,init-pheromone矩阵删除对应特征波段的信息素。 由init-pheromone矩阵,计算每一个特征波段的被选概率,用轮盘赌算法选择下一个特征波段,直到所选特征波段达到max-features。
(4) 信息素更新: 仿造生物界蚂蚁觅食行为更新信息素,选取每一次迭代中,适应度值最高的蚂蚁进行信息素的更新。 将最优蚂蚁所选择的特征波段对应的回归系数绝对值,以及适应度值作为信息素更新的依据,对应波段的信息素按照信息素更新公式得到加强。 没有被选择的特征波段,信息素会因为挥发,浓度慢慢变小。 具体信息素更新公式如式(1)所示。
τn=(1-ρ)xτn-1+dela
(1)
重复步骤2—步骤4,直至达到设置的最大迭代次数,通过设置threshol,得到最终contribution矩阵。 剔除contribution矩阵中,选取的特征波段完全相同的特征波段组合。 计算每个波段的贡献率,依次剔除贡献率最小的波段,对选择的特征波段组合建立PLS回归模型,选择适应度值最大的波段组合作为最终所选择的最优特征波段组合。
2.2.2 PLS-ACO-GA
具体步骤:
在PLS-ACO的基础下,结合遗传算法[8],进行如下步骤: (1) 初始化算法的参数: 遗传算法交叉概率(pc), 变异概率(pm)。
(2) 初始种群生成: 在PLS-ACO算法中,将每一次迭代中,每一只蚂蚁所选择的特征波段组合作为遗传算法中的个体,所有蚂蚁选择的特征波段组合构成了遗传算法中的初始种群。
(3) 选择运算: 用轮盘赌算法淘汰那些适应度值低的个体。 为避免最优个体的遗失,每一次轮盘赌选择过后,如果最优个体被过滤了,则将最优个体代替适应度值最低的个体,重新保留在种群中,以便于通过交叉产生更多优秀的个体。
(4) 交叉运算: 随机生成一个0到1之间的数,如果该数大于pc,随机选择一个个体作为母代,进行交叉操作。 本研究使用单点交叉操作,即随机生成一个交叉点,交换该点前后的特征波段。 结果生成两个新的个体,将其建立PLS回归模型,计算其适应度值,并与父代母代进行比较,若子代比父代母代更加优秀,则进行替换,对应的父代或者母代淘汰。
(5) 变异运算: 本工作使用单点随机变异,随机生成一个0~1之间的数,若该数大于变异概率pm,随机选择一个特征,改变其是否被选择的状态。
(6) 个体选取: 如果该个体的适应度值大于全局阈值,则将该个体的路径存入贡献矩阵中。
重复步骤(1)—步骤(6),直至达到设置的遗传最大迭代次数,将通过全局阈值的特征波段组合存入贡献矩阵中,进入下一次PLS-ACO算法迭代中。
PLS-ACO-GA算法流程如图2所示。
2.2.3 特征波段选择方法结果与比较

图2 PLS-ACO-GA算法流程图Fig.2 PLS-ACO-GA algorithm flowchart

图3 PLS-ACO波段贡献率Fig.3 PLS-ACO band contributionrate

图4 PLS-ACO-GA波段贡献率Fig.4 PLS-ACO-GA band contributionrate
表2和表3分别是指设置不同max-features时,PLS-ACO和PLS-ACO-GA所选特征波段组合建立PLS回归模型时得到的结果。
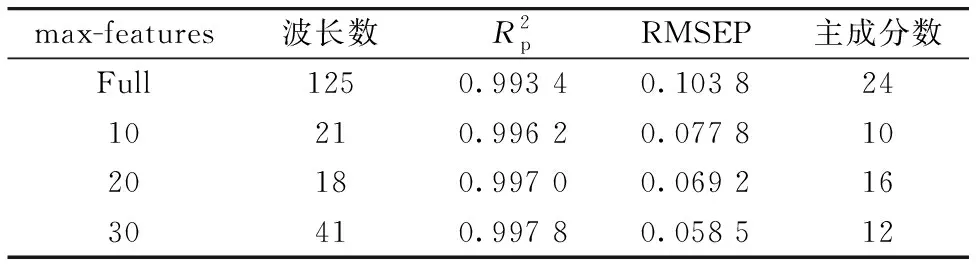
表2 PLS-ACO,max-features分别设置为 10,20,30的PLS回归模型结果Table 2 PLS regression model results with PLS-ACO andmax-features set to 10,20 and 30 respectively
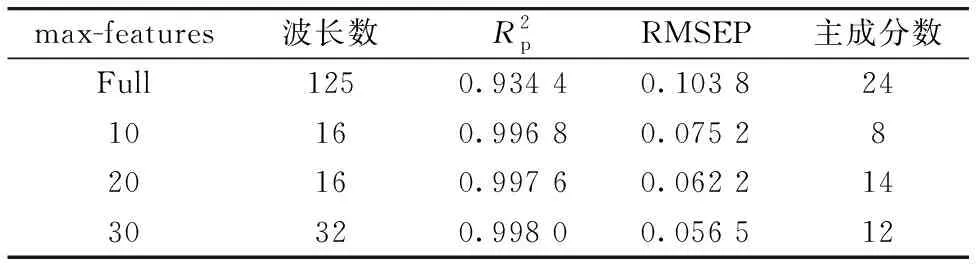
表3 PLS-ACO-GA,max-features分别设置为10,20,30的PLS回归模型结果

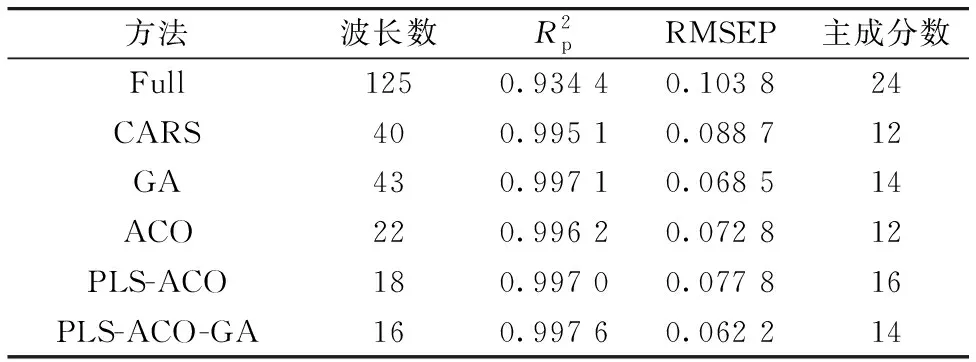
表4 不同特征选择方法下的PLS回归模型结果Table 4 PLS regression model result sunderdifferent feature selection methods

表5 PLS-ACO和PLS-ACO-GA多元线性回归模型结果Table 5 PLS-ACO and PLS-ACO-GA MLR results

表6 PLS-ACO和PLS-ACO-GA随机森林回归模型结果Table 6 PLS-ACO and PLS-ACO-GA RFR results
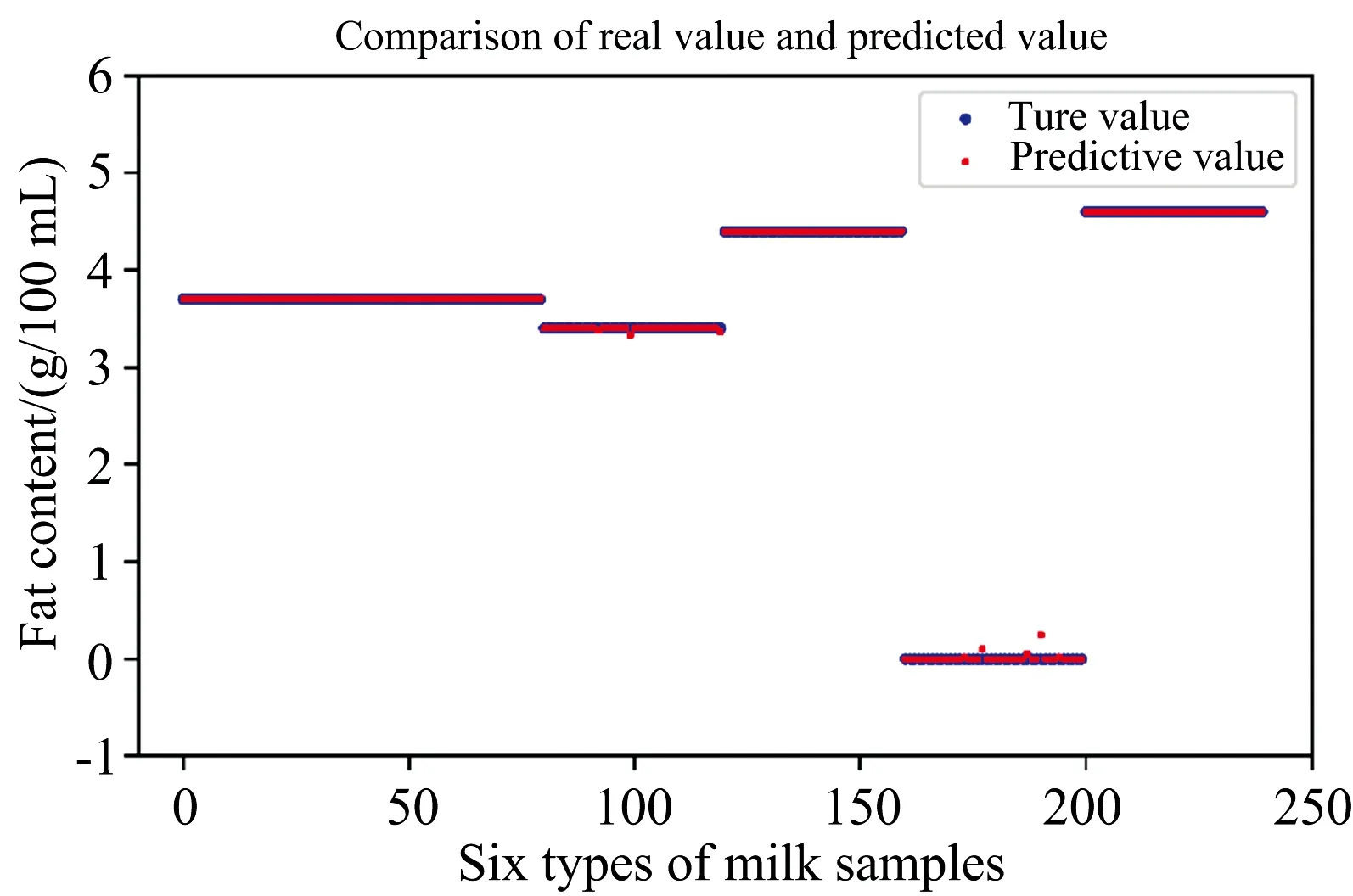
图5 MSC-(PLS-ACO-GA)-RF预测结果Fig.5 MSC-(PLS-ACO-GA)-RF prediction results
通过对比不同的预处理方法,特征波段选择方法,和不同的回归模型,选择MSC作为预处理的方法,用PLS-ACO-GA来进行特征波段选择,最后建立RFR模型得到的牛奶脂肪含量预测最为精准。 将通过MSC-(PLS-ACO-GA)-RFR建模后得到的脂肪含量预测值与真实值做图对比,以便更加直观的感觉到预测效果,结果如图5所示。
从图5中可以看出,只有个别样本真实值和预测值偏差较大,大多数样本真实值和预测值基本重合,预测结果表现优异。
3 结 论
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
航天返回与遥感(2022年2期)2022-05-12
空间科学学报(2021年1期)2021-05-22
电子制作(2018年2期)2018-04-18
制导与引信(2017年3期)2017-11-02
少儿科学周刊·儿童版(2017年5期)2017-06-29
电子制作(2017年8期)2017-06-05
学苑创造·A版(2017年3期)2017-04-27
中国光学(2015年5期)2015-12-09
学苑创造·A版(2014年6期)2014-08-04
