
随机森林结合CatBoost的近红外光谱药品鉴别
2022-07-06 05:36路皓翔刘振丙
光谱学与光谱分析 2022年7期
蒋 萍,路皓翔, 刘振丙*
1. 广西警察学院信息技术学院,广西 南宁 530028 2. 桂林电子科技大学计算机与信息安全学院,广西 桂林 541004
引 言
近红外光谱分析技术具有对检测样品零污染、 检测速度快等突出优点,其结合化学计量学和机器学习广泛应用在石油化工[1]、 疾病诊断[2-3]、 农副产品质量检测[4]等领域。 药品质量的有效监督对于维系国计民生至关重要,引起了全球各国政府的关注,我国也专门成立了国家食品药品监督管理总局对药品质量进行监督[5]。 然而传统的药品鉴别模型较为复杂、 精度较低且运行时间较长不能满足实际的需要,因此构建快捷、 准确的药品鉴别模型是一项极为重要的工作。
近红外光谱分析技术依据构成样品的不同成分对于近红外光谱的吸收性不同实现样品属性及质量的检测,机器学习可对高维数据进行处理挖掘出最能表征样本属性的特征[6-8],国内外学者尝试将机器学习和近红外光谱分析技术相结合起来应用于药品质量检测[9,11]。 有研究采用小波变换对药品光谱数据进行处理,通过稀疏降噪自编码提取药品光谱数据深层特征并由持向量机(support vector machine,SVM)进行药品类比鉴别。 周颖[12]等通过构建女贞子的近红外光谱快速检测模型,实现了真假女贞子及其产地的准确鉴别。 Rodionova[13]等建立了一种数据收集、 模型构建和模型校验的研究过程,能够有效区分假冒药品和真实药品。 Sampaio[14]等利用偏最小二乘判别分析(partial least squares discriminant analysis, PLS-DA)和SVM对米粉的光谱数据进行分析,有效解决了米粉制造商的准确区分。 然而,由于样品的近红外光谱维度较高且存在严重的谱区重叠问题,无疑会对模型的鉴别性能产生较大的影响[15-16],因此筛选出有效的、 最能表征样品特征属性的波长或波长范围对于构建有效且可靠的近红外光谱分析模型具有重要意义。 陈文丽[17]等采用最小角回归算法筛选柑橘叶片的近红外光谱有效波长,并利用极限学习机(extreme learning machine,ELM)对筛选的有效波长进行分析实现柑橘叶片是否带有黄龙病的检测。 沈东旭[18]等通过在神经网络的约束损失函数进行光谱数据中有效数据的筛选,提高了血液鉴别模型的性能。 Chen[19]等研究了基于卷积神经网络(convolutional neural networks, CNN)的特征波长选择方法,研究发现CNN的参数对其性能产生较大的影响。 虽然利用筛选出来的样品特征波长用于构建近红外光谱分析模型可以有效改善其性能,但是在药品鉴别领域的报道仍较少。
本研究将无损、 检测快速的近红外光谱分析技术与机器学习方法相结合用于药品的准确鉴别。 为减少光谱数据谱区重叠及无关变量对药品鉴别模型性能的影响,结合随机森林(random forest, RF)和CatBoost提出了一种新的近红外光谱药品鉴别方法。 首先采用随机森林筛选出药品近红外光谱数据中最能表征样品特征的波长,再利用CatBoost对筛选出来的样品特征波长进行分析实现不同厂商药品的分类鉴别; 以药品的近红外光谱数据为实例评价该方法的有效性,并与同类方法进行实验对比。 本研究主要特点:
(1)将随机森林算法用于筛选最能表征样品属性的特征波长点,可有效剔除样品近红外光谱中无关变量对模型性能的影响;
(2)为确保模型具有较高的预测精度,采用决策树作为CatBoost中的弱分类器保证模型的预测精度更高、 鲁棒性更强。
1 RF-CatBoost模型
RF是一种结合决策树和特征选择的集成学习方法,解决了传统决策树分类规则复杂易陷入局部最优解的问题,常用于特征变量选择、 分类及异常点检测等[20]。 CatBoost[21-22]以对称决策树为弱分类器,将样本特征组合在一起便于充分利用样本特征间的信息且丰富了样本的特征; 此外,为了降低样品数据中噪声对模型性能的影响,采用排序提升的方法对数据进行处理,能够解决模型过拟合的问题,提升其准确性及泛化能力。 结合随机森林较优的特征选择能力和CatBoost较强的分类能力提出了一种新的药品鉴别模型——RF-CatBoost,其模型结构如图1所示。
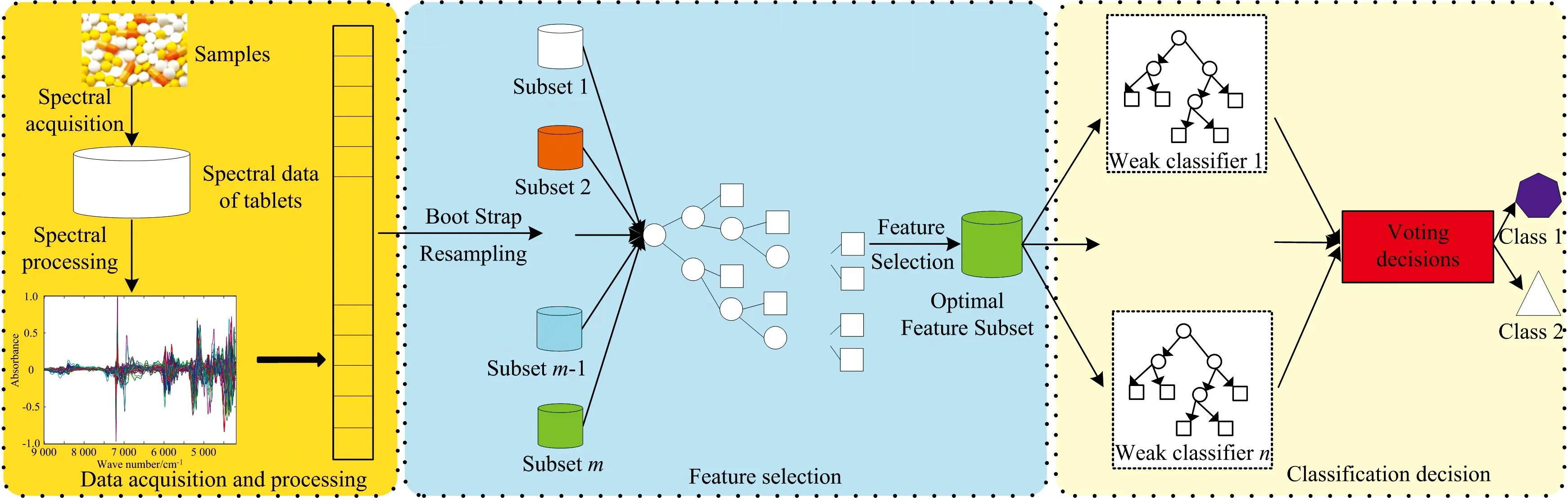
图1 RF-CatBoost的结构Fig.1 The structure of RF-CatBoost
鉴别模型主要分为两个部分: RF特征波长选择和CatBoost分类决策,即首先采用RF对经过预处理后药品近红外光谱数据的特征波长进行筛选,然后将筛选出来的样品波长送入CatBoost中对样品类别进行决策。 若样品的原始集合为D,其中N为样品总数,Xi表示第i个样品的特征波长集合,yi表示第i个样品的类别属性,则RF-CatBoost实现类别确定的详细过程如下:
Stage Ⅰ: 波长选择
袋外误差是袋外数据真实值与预测值之差,袋外误差总和是所有袋外总据误差总和。
首先,从样品总数N中有放回Bootstrap采样n次构成子集B1,B2,…,Bj,见式(1)
Bj=Bootstrap(D{(Xi,Yi),i=1, …,N})
(1)
采用Bj对随机森林中的决策树进行训练并计算Bj对应的袋外数据OOBj预测结果的误差,
errOOBj=errr{Test[OOBj,model(Bj)]}
(2)
则n个子集的袋外误差总和errOOBjT1为
(3)
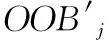
(4)
并计算两个袋外误差的均值errM[见式(5)],差值越大说明特征变量Sm越重要。
(5)
重复以上操作计算出所有特征变量的errM,并按照errM从小到达的顺序排列将最重要的前n个特征变量作为第i个样本Xi的特征集合Xi={s1,s2,…,sn},输入CatBoost进行分类决策。
Stage Ⅱ: 类别决策
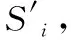
(6)

(7)
为了对训练集样本的类别进行确认,采用RF对其特征波长进行选择,由式(7)对依据其选择的特征波长进行类别的确定。
2 实验部分
为保证RF-CatBoost在进行药品鉴别时具有较高的训练精度,需对模型中的参数进行确定。 首先对实验室数据、 数据预处理及数据集划分进行简要概述,然后对RF-CatBoost中决策树数目做确定,最后给出RF-CatBoost模型建立的过程。
2.1 实验数据
实验以湖南方盛制药、 江苏正大、 山东鲁抗和山东罗欣生产的铝塑和非铝塑两种包装方式的头孢克肟片光谱数据为例。 该光谱数据由中国食品药品检定所提供,采用Bruker Matrix光谱仪采集,光谱仪的采样间隔设定为4 cm-1,采样范围为4 196~9 002 cm-1,每个样本的吸光点为2 074个。 实验中头孢克肟片近红外光谱数据如表1所示。
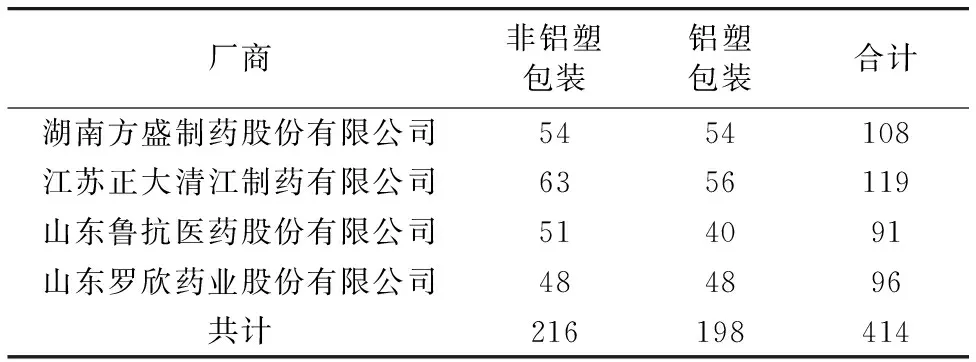
表1 头孢克肟片近红外光谱数据信息Table 1 Near infrared spectral data of cefixime tablets
2.2 数据预处理
四个厂商生产的铝塑和非铝塑包装方式头孢克肟片的光谱共414条,这些光谱间存在明显的重叠且包含噪声,影响了样品光谱信息的解析。 为了消除样品光谱间的重叠、 提高样品光谱间的辨识度,采用对样品的光谱数据依次进行平滑化、 归一化处理消除光谱数据中的背景干扰,消除光程差异带来的光谱变化。 经过预处理后的头孢克肟片光谱信息如图2所示。 多阶段预处理增加了样品光谱数据间的辨识,提高药品鉴别模型的准确度。
数据白化是指将数据的协方差矩阵进行单位化处理,保证数据的方差一致且特征间相互独立。 其详细过程如下:
首先,构建预处理后光谱数据x的协方差矩阵,见式(8)
Σ=E(xxT)
(8)
若光谱数据x的变量相关,则其Σ为非对角矩阵。
将协方差矩阵Σ对角化,见式(9)
ΦTΣΦ=Λ
(9)
式(9)中,Λ为对角矩阵,其对角元素由协方差矩阵Σ的特征值组成。Φ为特征值对应的特征向量。 对x进行解相关,见式(10)
y=ΦTx
(10)
y为解除相关后的数据,其协方差矩阵E(yyT)为对角矩阵。
最后,将光谱数据与对角矩阵相乘即可得到白化后的数据w,见式(11)
w=Λ1/2y=Λ1/2ΦTx
(11)
采用单位化处理后的协方差矩阵构建模型有利于提高模型鉴别能力,故而对经过预处理后的药品光谱数据进行白化处理,并将药品光谱数据协方差矩阵的对角元素按照“从大到小”原则排列,其值越小包含的有效信息越少,颜色越接近深蓝色。 白化处理前后药品光谱数据的协方差矩阵如图3所

图2 预处理后头孢克肟片的近红外光谱Fig.2 NIR spectra of pretreated cefixime tablets
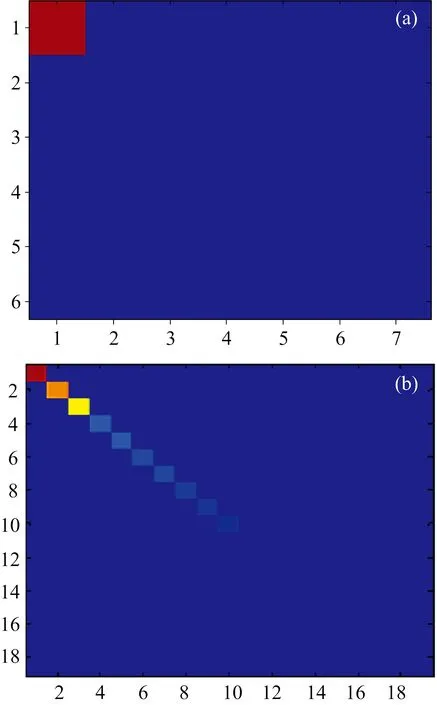
图3 白化处理前(a)和白化处理后(b)药品 近红外光谱数据的协方差矩阵Fig.3 Covariance matrix of drug NIR data before (a)and after (b) pretreatment
示。 从图3(a,b)可看出,预处理前药品光谱协方差矩阵的前三个分量大于其他分量,说明样品等光谱信息主要集中在前三个分量; 预处理后药品光谱协方差矩阵对角线所占面积缩小,说明更多的药品光谱信息显示出来。
2.3 数据集划分
本实验中将非铝塑包装方式的头孢克肟片光谱数据记为A组、 铝塑包装方式的头孢克肟片光谱数据记为B组。 其中A组和B组中均将江苏正大生产的头孢克肟片的光谱数据作为正类样本,其他厂商生产的头孢克肟片的光谱数据作为负类样本,按照表2构建出不同规模的训练集集进行实验,验证各模型在不同规模训练集中的性能。
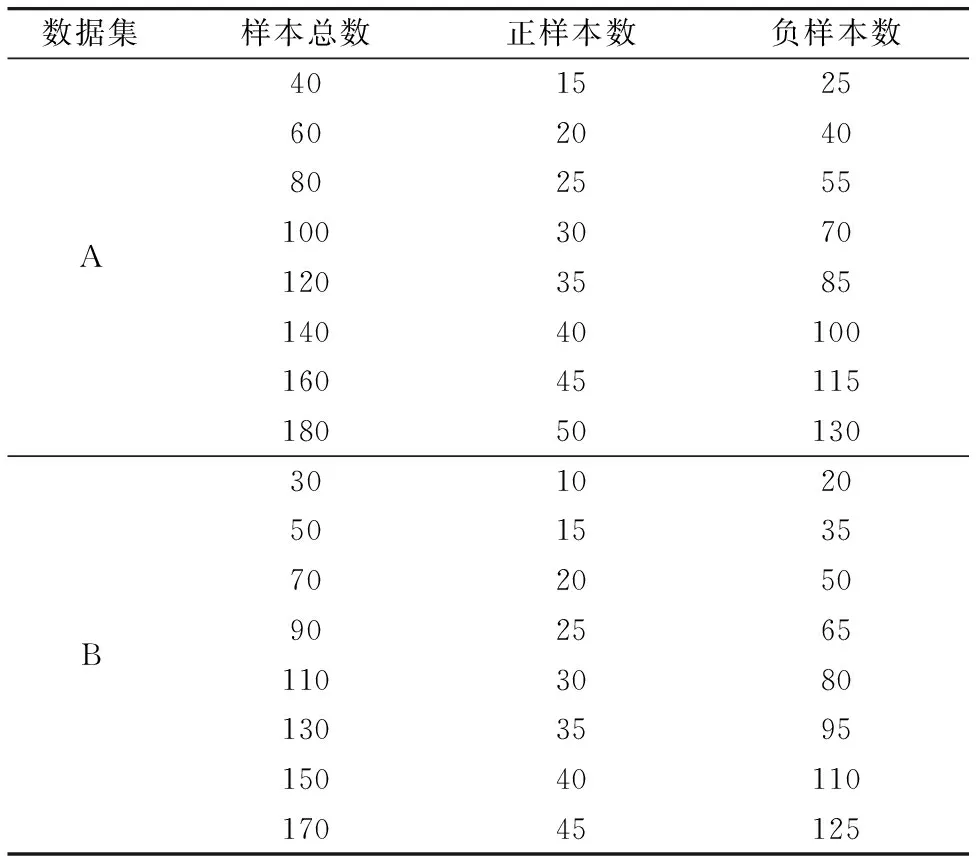
表2 A和B组中不同数量训练集配置表Table 3 Configuration table of different number oftraining sets in group A and B
2.4 CatBoost中决策树个数的确定
CatBoost中决策树数目较多则会增加其运行时间,决策树数目较少则会降低其鉴别精度。 因此在建立RF-CatBoost鉴别模型时需确定CatBoost中决策树数目。 图4(a,b)分别为CatBoost模型在不同规模训练集、 不同决策树数目下两种包装形式的头孢克肟片光谱数据的分类精度。 从图中可看出,CatBoost中决策树的数目在200~300间时,其在两种包装形式的不同规模头孢克肟片光谱训练集的分类精度较高。 当决策树的数目超过300时,随着决策树数目的增加CatBoost模型的分类精度反而降低。 据此分类,本次在构建RF-CatBoost药品鉴别模型时将CatBoost中的决策树数目设定为250。
2.5 模型实现
基于RF-CatBoost的药品鉴别模型编程采用MATLAB 2014A实现,其中RF的源代码使用的是Abhishek Jaiantilal开源的工具箱(https://code.google.com/p/randomforst-matlab/)。 RF-CatBoost模型的性能评估实验运行在Intel(R) Core(TM) i5-2450M CPU的计算机上,系统版本是Windows 10专业版,其详细过程如下:
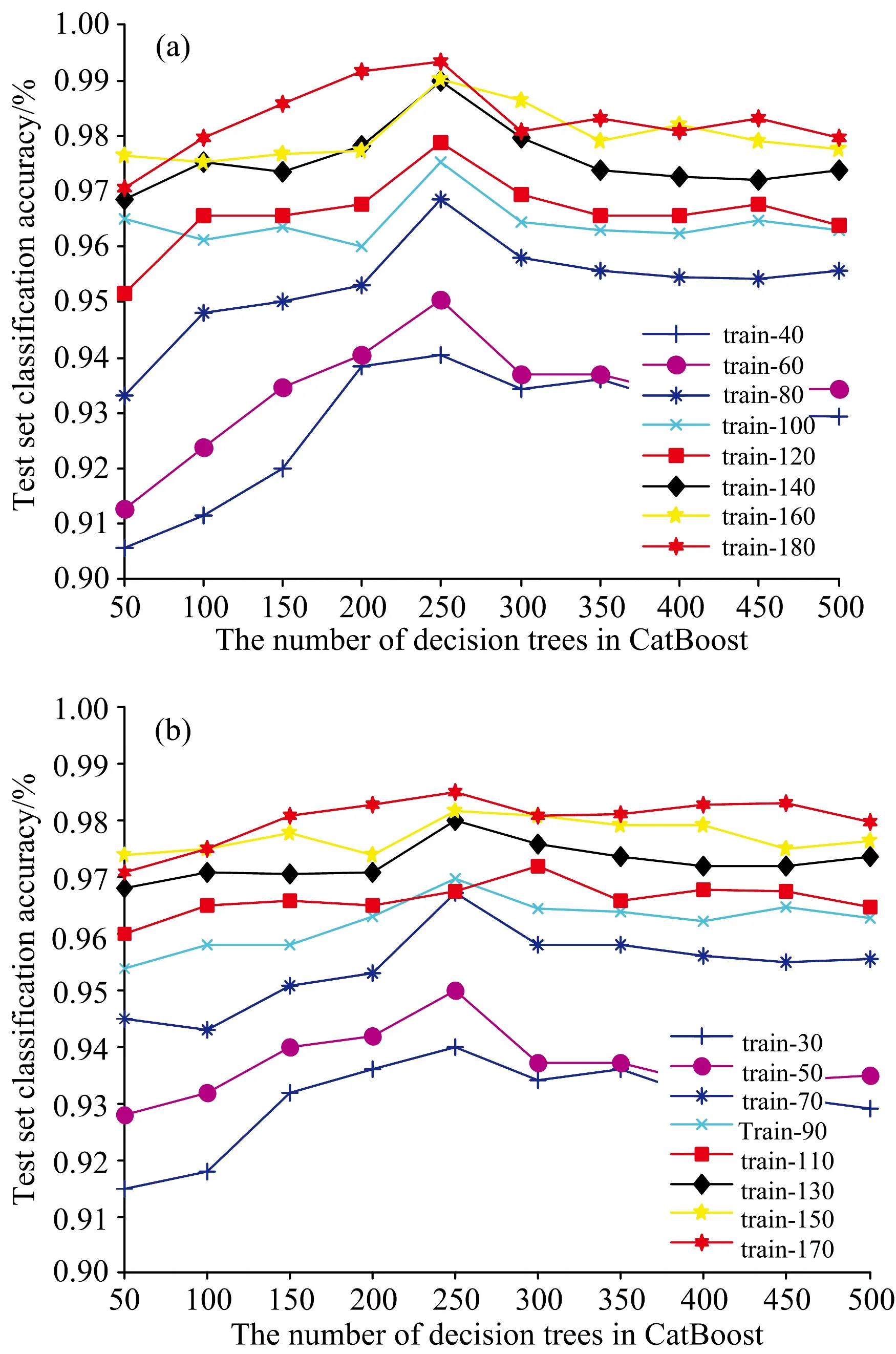
图4 CatBoost中不同决策树数目在A组(a)和B组(b) 不同规模数据集上的分类精度Fig.4 Classification accuracy of different decision tree numbers in Catboost on datasets of different sizes in group A (a) and group B (b)
(1)数据预处理
由于药品的光谱数据中存在重叠且包含噪声,故采用多阶段预处理的方式对药品的光谱数据进行处理。 为了提高模型性能,对经过多阶段预处理后的样品光谱数据协方差矩阵进行白化处理。
(2)特征筛选
采用随机森林筛选出预处理后药品光谱数据中最能表征其属性的特征波长,用于训练CatBoost分类决策模型。
(3)分类决策
按照表2划分出不同规模的训练集,并将筛选出的药品特征波长输入CatBoost中进行模型的训练。 将测试数据输入训练好的CatBoost模型中进行药品类别的确定。
(4)对比分析
以CatBoost、 ELM、 SVM、 反向传播网络(back propagation,BP)、 波形叠加极限学习机(summation wavelet extreme learning machine, SWELM)、 Boosting作为对比方法验证该方法在运行时间、 分类精度以及稳定性方面的表现。 其中CatBoost中决策树的数目选择为250; SWELM和ELM网络结构的构成均为2074-Train_num*0.4-400-2,均选用Sigmoid作为网络的激活函数,迭代次数设定为50次,设定两层的学习率均为0.03; SVM的核函数选择为线性函数,且设定C=1,gamma=0.3; BP的网络结构设置为2074-800-400-2,选用Sigmoid作为网络的激活函数,迭代次数设定为50次,设定网络学习率为3%。
3 结果与讨论
为评估RF-CatBoost在不同规模训练集中的表现,每个规模的训练集按照表2中正样本和负样本的数目随机抽取10次进行实验并与CatBoost、 ELM、 SVM、 BP、 SWELM和Boosting模型对比,将各模型在每个规模训练集上10次运行时间、 分类精度及预测标准偏差的均值作为各模型的最终性能指标值。
(1)分类精度
分类精度是对RF-CatBoost、 CatBoost、 ELM、 SVM、 BP、 SWELM和Boosting模型药品鉴别结果可靠性的衡量,分类精度越高说明药品鉴别模型的可靠性越高。 各药品鉴别模型在不同规模训练集A和B上的分类精度如表3所示。 从表3可看出随着,在A和B两组数据集中各模型的性能随着训练集样本的增加均逐渐增加,当A组中训练集增强到120后RF-CatBoost药品鉴别模型的分类精度均达到100%; 当B组训练集增加到130后,RF-CatBoost药品鉴别模型的分类精度均达到100%。 其中在各组数据集中,与CatBoost、 ELM、 SVM、 BP、 SWELM和Boosting相比,无论训练集规模大小RF-CatBoost的分类精度均最高,CatBoost和Boosting次之。 分析认为集成学习能够将弱分类器集成在一起从而提高各弱分类器模型的非线性分析能力; 与CatBoost相比,RF-CatBoost分类精度较高,主要因RF能够将样品光谱数据中无效特征波长剔除从而筛选出最具样品属性特征的波长。 此外CatBoost较Boosting分类精度更高,主要由于CatBoost利用对称树将类别特征组合在一起,丰富了各类别的特征维度。 BP分类精度最差,说明其非线性建模能力较差。 ELM和SWELM表现出了相当的分类精度且比SVM低,说明核函数几乎对ELM模型鉴别能力没有影响但其非线性建模比SVM差。
(2)运行时间
运行时间是对药品鉴别模型工作效率的重要衡量指标,运行时间越短说明药品鉴别模型的效率越高。 表4给出了RF-CatBoost、 CatBoost、 ELM、 SVM、 BP、 SWELM和Boosting在不同规模的A、 B两组数据集上的运行时间。
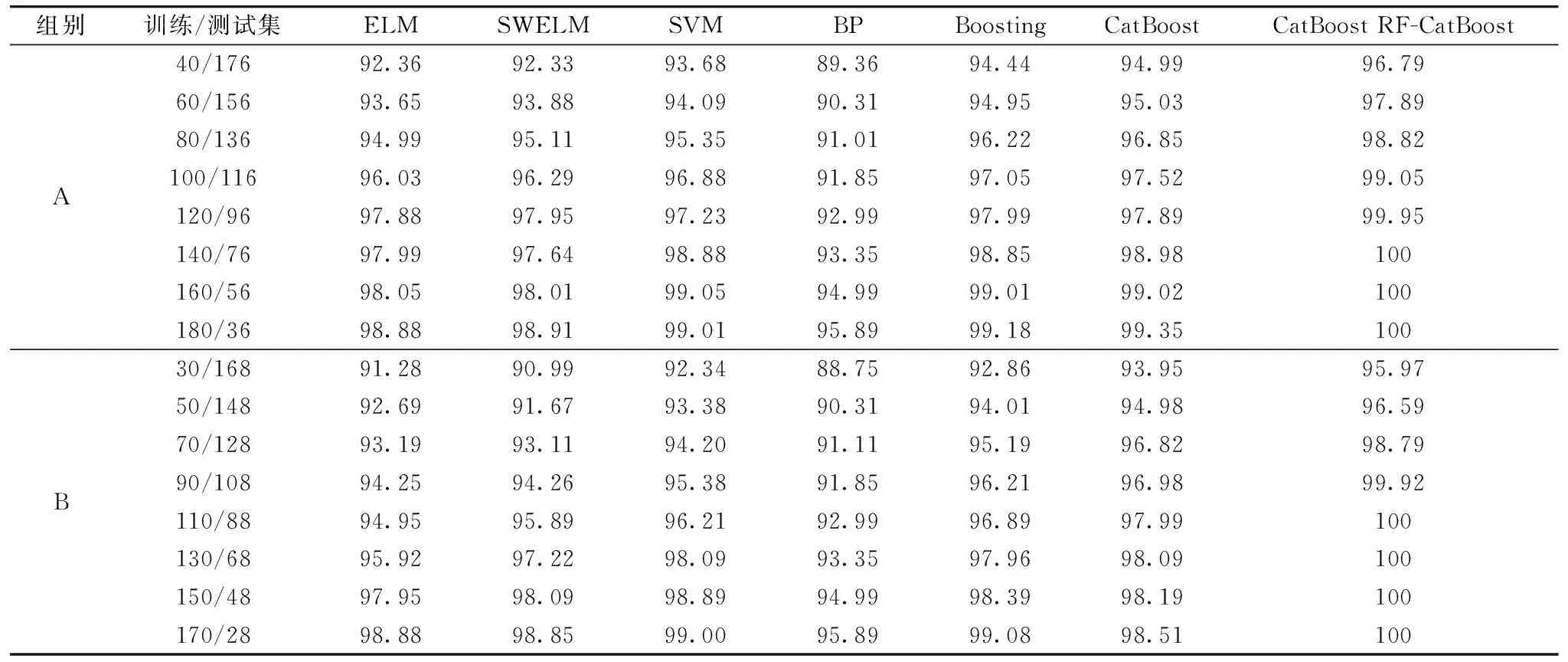
表3 各模型在不同规模的A和B两组数据集上的分类精度(%)Table 3 Classification accuracy of each model on different sizes data sets in group A and B (%)
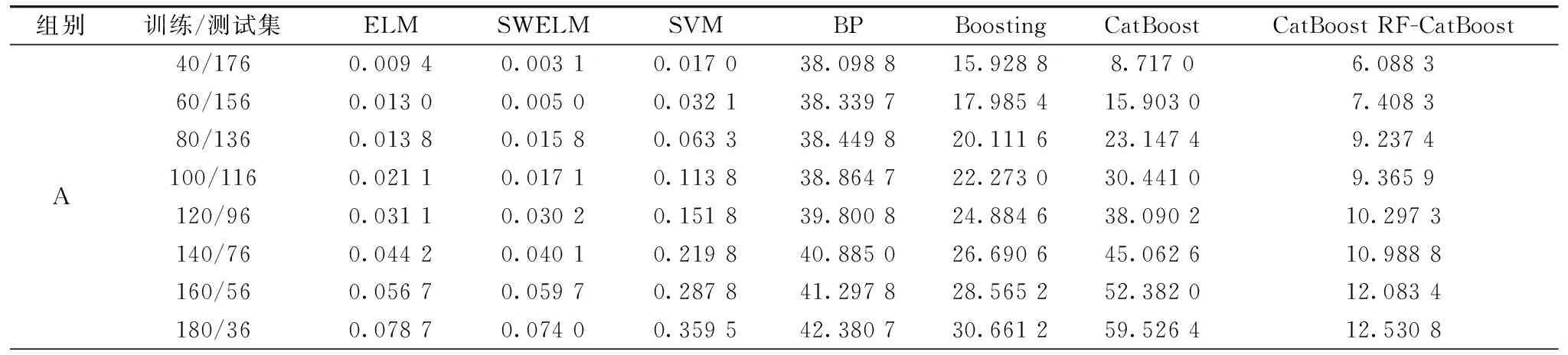
表4 各模型在不同规模的A、 B两组数据集上的运行时间(s)Table 4 Runningtime of each model on different sizes data sets in group A and group B (s)
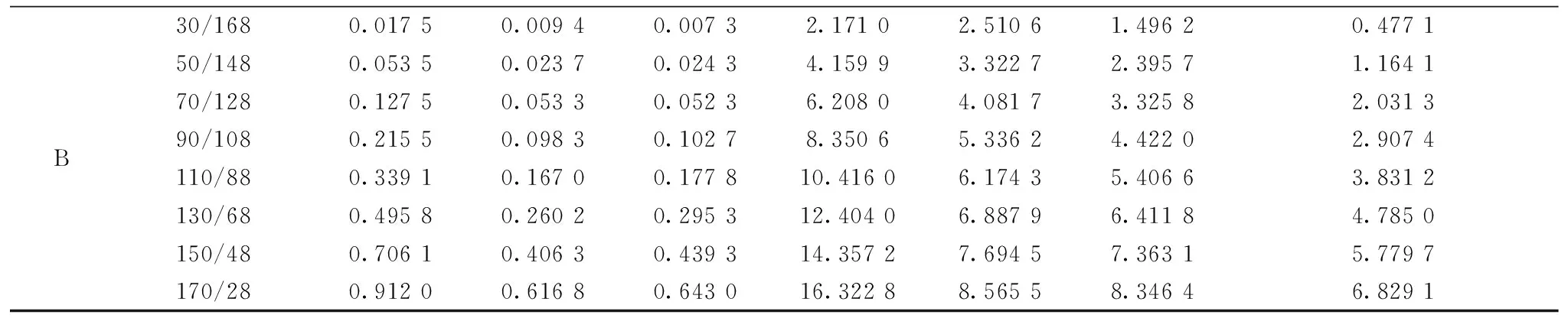
续表4
由表4中可看出,RF-CatBoost、 CatBoost、 ELM、 SVM、 BP、 SWELM和Boosting随着训练样本数目的增加运行时间均逐步增加,且不论训练集样本的大小,BP的运行时间最长,RF-CatBoost、 CatBoost和Boosting的运行时间次之,ELM、 SVM和SWELM的运行时间最短。 分析认为由于BP神经网络采用多次循环迭代求解网络的最优参数实现网络的训练,因此延长了其运行时间; 由于集成学习需要训练多个弱分类器实现最终网络的训练,所以造成RF-CatBoost、 CatBoost和Boosting的运行时间比ELM、 SVM和SWELM的运行时间长。 此外,由于ELM和SWELM为只含有一个隐含层的网络且无需多次迭代寻优,故而缩短了网络的运行时间。
(3)模型稳定性
为了保证药品鉴别模型具有较强的应用稳定性,采用预测标准偏差(standard deviation,STD)对RF-CatBoost、 CatBoost、 ELM、 SVM、 BP、 SWELM和Boosting的稳定性进行评估。 各模型在A、 B两组不同规模训练集上的STD如图5所示。
由图5(a,b)中可看出,与ELM、 SVM、 BP、 SWELM相比,在A、 B两组不同规模训练集上无论训练集样本数目如何,RF-CatBoost、 CatBoost和Boosting均表现出了较低的STD且RF-CatBoost最低、 CatBoost次之、 Boosting最差。 结果表明集成学习方法有利于提高决策树的稳定性,且在RF-CatBoost、 CatBoost和Boosting这3个集成学习算法中RF-CatBoost的稳定性最强、 Boosting的稳定性最差。 BP比ELM、 SVM和SWELM的STD较强,说明BP的稳定性较对比方法较差; 与ELM相比,SWELM在不同规模训练集上均表现出了较低的STD,说明核函数对于ELM的稳定性会产生影响。
4 结 论
采用近红外光谱分析技术实现了药品光谱信息的无损采集; 采用多阶段预处理和白化处理消除了药品光谱数据中存在噪声和基线漂移等; 采用随机森林能够准确地筛选出最能表征样品属性的特征波长并采用筛选的特征送入CatBoost
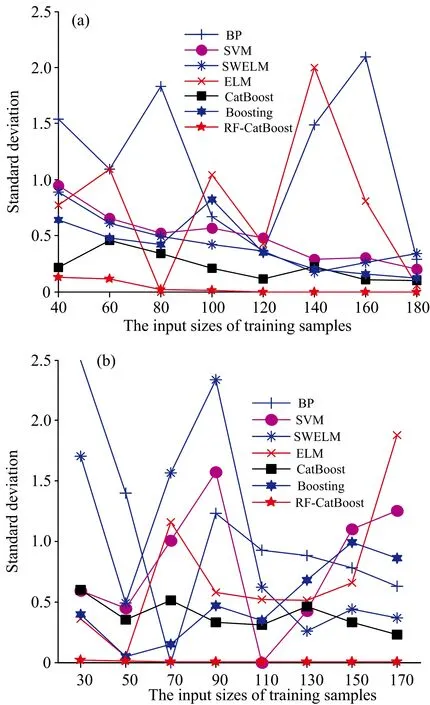
图5 各模型在A组(a)和B组(b)不同规模 训练集上的预测标准偏差Fig.5 Standard deviations of each model on different sizesdata sets in group A (a) and group B (b)
实现了药品生产厂商的准确鉴别。 以不同厂商生产的铝塑和非铝塑包装形式药品的光谱数据为例,构建了不同规模的训练集对RF-CatBoost的性能进行评估,并与CatBoost、 ELM、 SVM、 BP、 SWELM和Boosting模型进行对比,其中RF-CatBoost模型的分类精度最高达100%且预测标准偏差趋于0。 结果表明RF-CatBoost在不同规模训练集上均表现出了最优的鉴别性能,可用于药品生产厂商的鉴别。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
一重技术(2021年5期)2022-01-18
空间科学学报(2021年1期)2021-05-22
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年16期)2018-09-26
电子制作(2018年11期)2018-08-04
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
智能系统学报(2015年4期)2015-12-27
中国光学(2015年5期)2015-12-09
