
基于随机森林回归算法的山洪灾害临界雨量预估模型
2022-07-05 08:21:34桑国庆刘昌军王君诺
济南大学学报(自然科学版) 2022年4期
赵 龙, 桑国庆, 武 玮, 刘昌军, 王君诺
(1. 济南大学水利与环境学院, 山东济南 250022; 2. 中国水利水电科学研究院, 北京 100038; 3. 水发规划设计有限公司, 山东济南 250100)
临界雨量是山洪灾害重要的预警预报指标[1]。 当某个区域在一段时间内降雨量达到某一量级时, 该区域会发生山洪灾害, 这时的降雨量即称为该区域的临界雨量[2]。 随着山洪灾害防御精细化发展, 临界雨量的研究对象逐渐从较大区域发展为沿河村落等居民聚居区[3]。 按照计算原理的不同, 可以将临界雨量的计算方法分为两大类, 一类是基于灾变物理机制的水文水力学法, 另一类是基于数据驱动的统计归纳法[4]。 许多学者对临界雨量采用水文水力学法进行了研究。 叶勇等[5]对临界雨量进行研究, 提出了水位反推法, 此方法简单实用且便于推广。 原文林等[6]利用流域数字水系与美国陆军工程兵团水文中心水文模型系统(HEC-HMS)建立模型, 获得了精确的降雨径流关系并计算了临界雨量, 结果表明该模型预警精度较高。 彭万兵等[7]采用降雨驱动指标法建立了山洪灾害预警模型, 模型适用性较好。 另外, 许多学者对临界雨量采用统计归纳法进行了研究。 张玉龙等[8]以云南省山洪灾害典型区为例, 采用径向基函数插值法、 反距离加权插值法、 克里金空间插值法研究了区域临界雨量的变化规律, 结果表明克里金空间插值法表现较好。 樊建勇等[9]提出与临界雨量有较大相关性的参数有主沟道比降、 流域面积和主沟道长度等小流域参数, 同时构建了统计模型推算山洪灾害临界雨量, 但该统计模型考虑参数较少。
综上,在理论上水文水力学法较为严谨,但对降雨、下垫面条件、灾害频次、河道特性等资料有一定要求,且计算过程较为复杂,应用水文水力学法计算资料匮乏地区的临界雨量存在一定困难。相对而言,统计归纳法理论较为简单,不涉及山洪物理过程机制,多在于数理统计与规律总结,但较少对已有的临界雨量成果数据深入挖掘。机器学习在数据的挖掘与处理方面具有较大优势,但目前在临界雨量预估方面应用较少。随着全国山洪灾害防治项目的推进,有关部门积累了大量采用水文水力学法计算的临界雨量数据,在此基础上利用机器学习算法对临界雨量预估是可行的。
本文中以山东省临朐县山丘区237个受山洪灾害威胁的沿河村落作为研究对象,将水文水力学法与统计归纳法紧密结合,基于随机森林回归算法构建临界雨量预估模型。以190个沿河村落的临界雨量成果数据作为训练集训练模型,其余47个沿河村落的临界雨量成果数据作为测试集,对模型效果进行验证,并分析所选参数对模型的重要度,以期为临界雨量计算提供参考。
1 基本方法
本文中综合水文水力学法与统计归纳法,将沿河村落作为研究对象,首先选取资料充足,计算条件好的沿河村落,采用水文水力学法计算临界雨量,成果数据经验证合格后作为原始数据集;其次,综合考虑降雨特征、流域特征、沿河村落及河道特征等参数,利用随机森林回归算法建立山洪灾害临界雨量预估模型,计算无实测资料沿河村落的临界雨量,计算流程如图1所示。

图1 山洪灾害临界雨量预估模型计算流程
1.1 水文水力学方法
水文水力学法主要包括水位流量反推法、降雨驱动指标法、降雨径流关系曲线插值法等。本文中在计算临界雨量时采用的是水位流量反推法。
水位流量反推法是假定降雨与径流同频的情况下计算控制断面水位流量关系,确定成灾水位,获得成灾流量,再经过产流、汇流计算获得不同频率的洪水过程,用成灾流量的频率确定降雨频率,最后反推临界雨量。
1.1.1 控制断面水位流量关系计算
基于王维林等[10]对确定山丘区沿河村落成灾水位方法的研究,定位沿河村落防洪能力最薄弱的居民户的位置,确定成灾水位,采用曼宁公式计算控制断面水位流量关系,即
(1)
式中:Q为流量, m3/s;n为河道糙率,无量纲;A为过水断面面积,m2;R为湿周,m;J为河道比降,无量纲。
1.1.2 设计暴雨计算与产汇流计算
根据当地的水文手册与暴雨图集,查得多年得平均雨量值,经产流计算(降雨径流关系曲线法)、汇流计算(推理公式法),获得不同频率洪水过程,并绘制设计暴雨频率p-洪峰流量Qmp(m为汇流参数)曲线图。
Htp=HtKP
,
(2)
(3)
(4)
m=0.061 4θ0.75
,
(5)
(6)
式中:Htp为t时间、 设计暴雨频率为p的点雨量值,mm;Ht为t时间的平均降雨量,mm;KP由皮尔逊Ⅲ型线表查得;τ为汇流时间,h;L为河道长度,m;Qmp为洪峰流量,m3/s;F为流域面积,km2;t为时间,h;H为净雨量,mm;θ为汇流参数。
1.1.3 临界雨量反推计算
成灾流量是成灾水位对应的流量,在p-Qmp曲线图上查出成灾流量的成灾频率。假定降雨与径流同频,利用成灾频率设计出该频率下典型时段的降雨量,此降雨量即为临界雨量。
1.2 随机森林回归算法
1.2.1 分类回归树算法
随机森林回归(RFR)算法作为一种机器学习算法, 已被应用于多个领域[11-13], 它是由分类回归树(CART)算法组合形成的。 CART是一种形成二叉树模型的技术。 根据输出变量类型的不同, 可将CART分为分类树与回归树, 本文中使用的是回归树。
1.2.2 随机森林回归算法原理
多棵回归决策树构成了随机森林回归算法。基于集成学习的思想,取各回归决策树的均值作为预测结果,即
(7)

作为一种基于统计学理论的机器学习算法,随机森林回归算法引入了Bagging方法和随机子空间方法[14],避免了单棵决策树模型容易过拟合且精度不高的问题。
1)Bagging方法[15]又被称为自助聚集(bootstrap aggregating),是基于自举的统计方法。该方法以可重复的随机采样为基础,通过Bootstrap重采样方法形成多个预测器。假定原始样本中共有N个样本,反复抽取N次,组成新训练样本。当N趋向无穷大时,每个样本不被抽中概率为
(8)
在同一棵树的训练样本中将近有36.8%的原始样本不会出现,未被抽中的样本称为袋外数据(OOB)[16]。通过Bagging方法可避免回归决策树局部最优解的产生。
2)随机子空间方法。构建回归决策树时需要选取随机特征。选取随机特征是指从全体属性集合中随机选择部分特征属性,根据最小均方差原则选取节点分裂最优特征,让每棵树不剪枝以实现最大限度的生长。训练样本的随机取样根据特征属性随机选取,能最大程度地保证回归决策树的多样性。
1.2.3 算法流程
1)利用Bagging方法,对原始训练集随机抽取样本,构造出k个样本子集。
2)利用随机子空间方法,随机在所有X个特征属性中抽取部分特征属性,进行节点分裂,构建单棵回归决策树。
3)重复步骤1)、2),建立多棵回归决策树,并使每棵树最大程度地生长,形成森林。
4)最终预测结果是对所有回归决策树的预测结果取平均值。随机森林回归算法计算流程如图2所示。
2 临界雨量预估模型构建
2.1 研究区概况及数据准备
临朐县地处山东省潍坊市西南部,位于弥河上游、沂山北麓,是山洪灾害易发地区,尤其是随着近年来极端天气事件增加,暴雨天气增多,更易形成洪水,历史上曾在1963、 1984、 1986、 1998、 2000、 2001、 2010、 2012、 2019年发生过较大洪水。该县30 m分辨率数字高程数据(DEM)从地理空间数据云平台(http://www.gscloud.cn/)获取。全县237个研究对象分布情况,如图3所示。

图2 随机森林回归算法计算流程

从国家标准地图网站下载,地图审批号为GS(2019)3266号(http://bzdt.ch.mnr.gov.cn/browse.html?picId=%224o28b0625501ad13015501ad2bfc0211%22),结合资源环境科学与数据中心2015年中国县级行政边界数据(http://www.resdc.cn/data.aspx?DATAID=202), 经过ArcGIS 10.2软件数字化处理后得到。图3 山东省临朐县研究对象分布图
根据《山东省水文图集(1975)》查得临朐县土壤最大蓄水量Wmax为60 mm, 本文中将土壤含水量分为较干(0.2Wmax)、 一般(0.5Wmax)、 较湿(0.8Wmax)3种情况, 选取1、 3、 6 h作为典型时间,对全县237个研究对象采用水位流量反推法计算3种土壤含水量下1、 3、 6 h的临界雨量。通过2017、 2018、 2019年实测降雨资料与山洪灾害调查资料对不同时间段临界雨量计算成果检验复核,临界雨量有效预警率为82.3%,数据精度较高,可作为原始数据集输入模型。
2.2 临界雨量影响参数选择与获取
临界雨量受降雨、 土壤含水量、 下垫面情况等因素影响[17], 并借鉴山洪灾害风险评价中的指标[18-19], 考虑数据的易获取性选取临界雨量影响参数。 本文中将临界雨量影响参数分为降雨特征参数、 流域特征参数、 沿河村落及河道特征参数。
2)流域特征参数包括流域面积F、 流域平均坡度Javg、 流域最长汇流路径Lmax、 最长汇流路径比降Jmax、 流域形状系数C。以上流域特征参数可以通过ArcGIS中的统计工具对DEM分析计算获得。
3)沿河村落及河道特征参数。河道糙率n、 控制断面宽度B、 村落河道比降Jr、 河道到居民户水平距离S。河道糙率n为过水断面的综合糙率,可采用实测资料推算或参考《水工建筑物与堰槽测流规范》(SL 537—2011)表K.0.4中的内容;村落河道比降Jr可根据DEM分析计算获得。控制断面河道宽度B、 河岸至居民户水平距离S,以天地图在线影像为底图,利用ArcGIS测量工具提取。
各临界雨量影响参数的范围、平均值及标准差见表1所示。
2.3 模型设置
本文中采用Python语言自带的Scikit-learn机器学习库,以选择的临界雨量影响参数为自变量,临界雨量为因变量,利用随机森林回归算法,构建临界雨量预估模型,实现临界雨量预估。
2.3.1 训练集、测试集
因篇幅所限,本文中以土壤含水量0.5Wmax为例,对1、 3、 6 h典型时间段分别建立模型, 将原始数据集按4∶1的比例划分为训练集和外部独立测试集,使用训练集数据训练模型,外部独立测试集数据仅用于模型效果评估,不用于模型建立。本文中训练集为190组,外部独立测试集为47组。

表1 临界雨量影响参数统计表
2.3.2 模型参数优化
采用网格搜索方法(grid search)对模型参数寻优, 并通过K折交叉验证确定最佳参数。 当K值较大时, 交叉验证结果倾向于更好, 但计算时间也会更长, 综合考虑计算时间和方差, 将K设置为5。交叉验证中的打分器(scorer)可以通过使用评分(scoring)参数指定一个分数衡量指标对训练结果进行评分。 分数衡量指标遵循的原则是较大的返回值比较小的返回值更好。 采用的评分指标为解释方差回归得分。 解释方差回归得分满分为1分, 分值越小说明模型预测能力越差。 计算表达式为
(9)

随机森林回归算法在训练集上的表现是通过5轮训练和验证的表现进行平均得到的。 模型的主要参数有决策树数量(n_estimator)、 决策树最大深度(max_depth)、 最大特征数(max_features)。 其中模型决策树的数量越多, 训练效果越好, 同时训练所需时间也越长。 图4所示为训练集中决策树数量与解释方差回归得分的关系曲线。 由图可知, 决策树数量达到300后, 解释回归方差得分趋向稳定, 因此在不影响计算效率的情况下, 将决策树的数量定为300。 模型其他参数通过网格搜索方法调整, 优化后的模型参数见表2。 由表可知,1、 3、 6 h临界雨量预估模型的得分分别为0.964、 0.960、 0.951, 表明模型训练效果较好。
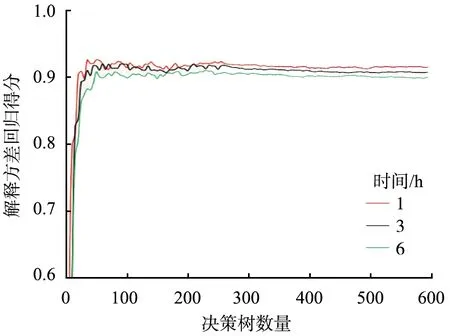
图4 决策树数量与解释方差回归得分关系曲线
3 结果与分析
3.1 模型评价指标
为了对模型进行客观评估,采用均方根误差RRMSE、 平均绝对误差RMAE以及决定系数r2作为模型模拟结果与实际值的拟合程度的衡量标准,其中,当RRMSE、RMAE越小,r2越大时,模型拟合效果越好,精度越高。
(10)
(11)
(12)


表2 临界雨量预估模型参数表
3.2 临界雨量预估结果分析
将测试集的临界雨量影响参数输入到训练好的临界雨量预估模型中,对测试集中沿河村落的临界雨量进行预估。以水文水力学法计算的临界雨量作为实际值,模型计算的临界雨量作为预估值,分别对1、 3、 6 h临界雨量预估模型训练集、测试集的实际值与预估值绘制散点图,如图5—7所示。对1、 3、 6 h临界雨量预估模型的训练集拟合效果分析,预估值与实际值接近,模型拟合效果较好。同时,3组模型的训练结果显示,当临界雨量实际值偏大时,训练样本数量较少,模型的拟合效果相对较差。1、 3、 6 h临界雨量预估模型的测试集均显示临界雨量预估值与实际值分布在对角线附近,说明模型预估效果较好。表3列出了测试集中部分沿河村落的临界雨量预估结果。
为进一步比较随机森林回归算法在临界雨量预估问题上的优劣,分别采用随机森林回归算法与误差逆传播(BP)神经网络算法预估临界雨量。BP神经网络算法使用3层结构,经交叉验证优化后,选择tansig函数作为输入层到隐含层传递函数,purelin函数作为隐含层到输出层传递函数,采用levenberg-marquardt算法进行训练,迭代次数为3 000。

(a)训练集(b)测试集图5 1 h临界雨量预估模型预估值与实际值的对比

(a)训练集(b)测试集图6 3 h临界雨量预估模型预估值与实际值的对比

(a)训练集(b)测试集图7 6 h临界雨量预估模型预估值与实际值的对比

表3 不同临界雨量预估模型的测试集预估结果
表4给出了随机森林回归算法与BP神经网络算法在预估临界雨量时训练集﹑测试集的模型评价指标。由表可以看出,采用随机森林回归算法的1、 3、 6 h临界雨量预估模型中, 训练集的r2均大于0.952, 测试集的r2均大于0.946,说明所建立的随机森林回归算法能较好地拟合建模数据;对于训练集与测试集的误差,以实际值的10%为许可误差,训练集与测试集的预估值合格率均大于80%,且RRMSE与RMAE均小于10,误差可接受。此外,测试集与训练集相比,模型评价指标相差不大,说明模型未出现过拟合,泛化性能较好。
通过比较随机森林回归算法与BP神经网络算法的模型评价指标可知, 各时段采用随机森林回归算法的训练集与测试集的r2比BP神经网络算法的至少增大了6%, 拟合效果更好; 各时段随机森林回归算法的RRMAE与RMAE均小于BP神经网络算法的, 且预估值合格率更高。 综上, 基于随机森林回归算法的临界雨量预估模型预估结果与BP神经网络算法相比, 预估精度更高, 能更好地进行临界雨量预估。
3.3 重要度分析
在临界雨量预估模型中,对每个临界雨量影响参数在每棵树上的贡献求平均值,经比较后可度量每个临界雨量影响参数的重要度。在Python语言中使用Scikit-learn机器学习库的feature_importances函数可以直接得到。图8所示为各临界雨量影响参数的重要度。由图可知,临界雨量影响参数中最重要的是流域面积,重要度值为0.320,流域最长汇流路径比降、 24 h降雨均值、流域平均坡度的重要度也相对较高,相比之下,河道糙率、村落河道比降的重要度相对较低。

表4 采用不同算法的模型评价指标

图8 临界雨量影响参数重要度
4 结论
本文中以山东省临朐县山丘区237个沿河村落为例,基于随机森林回归算法构建山洪灾害临界雨量预估模型,并得到以下结论:
1)利用水文水力学法计算沿河村落临界雨量数据与相应的临界雨量影响参数,采用随机森林回归算法构建临界雨量预估模型,将无实测资料的沿河村落临界雨量影响参数输入到模型中,实现了对各村落临界雨量的预估,为预估临界雨量提供一种有效的方法。
2)通过对模型进行训练与测试表明,该模型具有很好的预估能力,在训练集和测试集上的r2均大于0.9,说明该模型拟合情况较好;测试集中临界雨量预估值与水位流量反推法计算的临界雨量实际值接近,且RMAE和RRMSE均小于10,模型预估结果精度较高,能满足实际工作的需要。同时随机森林回归算法结构简单,需要调整的参数较少,能够针对无实测资料的沿河村落进行快速、批量预估临界雨量。
3)模型影响参数中流域面积、流域最长汇流路径比降、降雨均值、流域平均坡度的重要度相对较高,因此应确保这些数据的精度,提高模型的准确性。
4)本文中仅对山东省临朐县沿河村落的临界雨量进行预估,样本数据较少,随着样本数据的增加,模型的性能还需进一步研究。
猜你喜欢
水泵技术(2022年3期)2023-01-15 21:44:59
农业科学研究(2022年2期)2022-08-01 05:25:30
水泵技术(2022年2期)2022-06-16 07:08:44
孩子·小学版(2020年1期)2020-01-19 13:13:12
小雪花·初中高分作文(2019年8期)2019-10-07 08:46:42
成都信息工程大学学报(2019年1期)2019-05-20 09:14:26
西藏科技(2016年5期)2016-09-26 12:16:40
公民与法治(2016年18期)2016-05-17 04:17:48
创新作文(3-4年级)(2015年11期)2015-11-28 10:47:05
中国水利(2015年9期)2015-02-28 15:13:20
