
基于Deeplab v3+的高分辨率遥感影像地物分类研究
2022-07-04 01:54:54陆妍如毛辉辉宋现锋
地理空间信息 2022年6期
陆妍如,毛辉辉,贺 琰,宋现锋,2*
(1. 中国科学院大学资源与环境学院,北京 100049;2. 中国科学院地理科学与资源研究所,北京 100101)
传统的面向对象方法和机器学习方法在高分辨率遥感影像信息提取方面发挥了重要作用[1-9]。近年来,卷积神经网络(CNN)发展迅速[10-19]。当前这些方法均在一定程度上提升了图像分类精度,但是仍然存在着一些不足之处。Deeplab v3+[20]是Deeplab系列的最新改进模型版本,具有多尺度捕捉对象信息、获取目标清晰边界的优点,是目前最新的语义分割网络之一。为了实现自动化程度更高、结果更精确的高分辨率遥感影像特征信息提取,本文深入分析Deeplab v3+模型结构,基于GF-2 米级与无人机亚米级遥感影像与其他网络模型开展地物分类对比实验,探究了该模型在高分影像几何结构特征提取方面的优势和有效性。
1 Deeplab v3+网络模型
1.1 模型结构
DeepLab v3+网络由两部分组成:编码和解码模块,编码模块由改进的Xception 网络[20]和ASPP[21]模块组成。如图1 所示,训练样本经由Xception 网络提取特征,然后经ASPP 获取多尺度信息并聚合全局特征,最后经1×1卷积输出具有深层特征的特征图。将该特征图做双线性上采样,同时把对Xception 网络对应的同分辨率浅层特征做1×1卷积。最后将浅层特征和深层特征做卷积融合连接,对该多尺度特征做双线性上采样并实现分类预测。

图1 Deeplab v3+网络结构
1.2 Xception改进模块
如图2所示,Xception网络框架分为三部分:入口流、中间流和出口流。入口流用于对输入图像下采样以减小空间尺寸,而中间流则用于连续学习关联关系和优化特征,出口流对特征进行排序以获得粗略的得分图。结构图中的红色部分为改进部分:①中间流层数变多,深度可分离卷积层的线性堆叠由重复8 次改为16 次;②将原来简单的池化层改成了stride 为2 的深度可分离卷积;③额外的RELU 层和归一化操作添加在每个3×3 深度卷积之后。
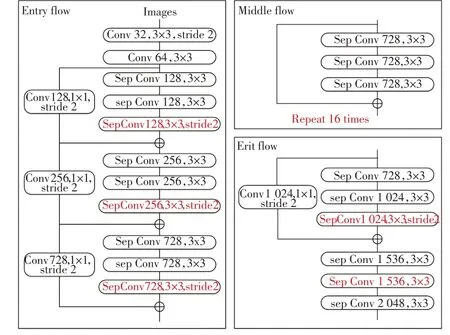
图2 Xception改进网络结构图
1.3 ASPP和编解码模块
ASPP 模块包含两部分:一是使用多个不同大小的空洞卷积核并行地对输入特征图进行特征提取,获取不同感受野大小的特征图;二是将输入特征图做全局平均池化来取得图像上下文信息,然后将这些不同尺度特征融合以获取更精准的深层语义特征。
在编码阶段,网络通过卷积等操作减小图片尺寸并学习输入图像的特征图;在解码阶段,通过卷积、上采样等方法逐渐恢复目标细节和空间信息。编解码器能够极大提升神经网络前向、后向传播效率,减少内存资源的使用。
1.4 扩张卷积和深度可分离卷积
扩张卷积[22]是在标准卷积的核中注入空洞,使其不通过池化层也能有较大的感受野,在不降低分辨率的情况下聚合范围更广的特征信息。如图3 所示,以3×3的卷积核为例说明感受野的增加情况。空洞率为2的3×3 卷积核的感受野已经增大为7×7。同理,空洞率为4的3×3卷积能达到15×15。

图3 扩张卷积
深度可分离卷积[20]把标准卷积分解为深度卷积和逐点卷积(图4),其中深度卷积独立对每个输入通道做空间卷积,逐点卷积用于结合深度卷积输出。深度可分离卷积极大地抑制模型参数的增加。Deeplab v3+网络将扩张分离卷积,应用于ASPP和解码器模块。
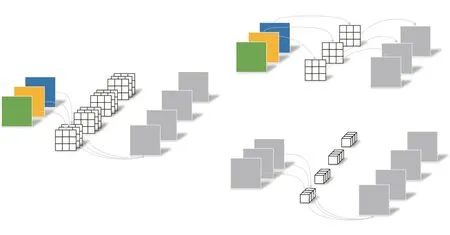
图4 深度可分离卷积
2 实验设计
本文利用高分辨率遥感影像为实验数据集,开展Deeplab v3+和UNet、SegNet、FCN8s 的地物分类对比实验,比较分类精度和分析地物识别存在差异的原因,探查Deeplab v3+模型在富含纹理特征的高空间分辨率遥感影像分类上的有效性与适用性。
2.1 数据集选择
本文采用2 种遥感影像实验数据集(图5),GID数据集[23]空间分辨率为4 m,光谱为可见光波段(RGB)和近红外波段(NIR),地物类型6 类(耕地、植被、建筑用地、道路、水系以及其他)。CCF数据集空间分辨率为0.3 m,光谱为可见光波段(RGB),地物类型5 类(植被、建筑、水体、道路以及其他用地)。
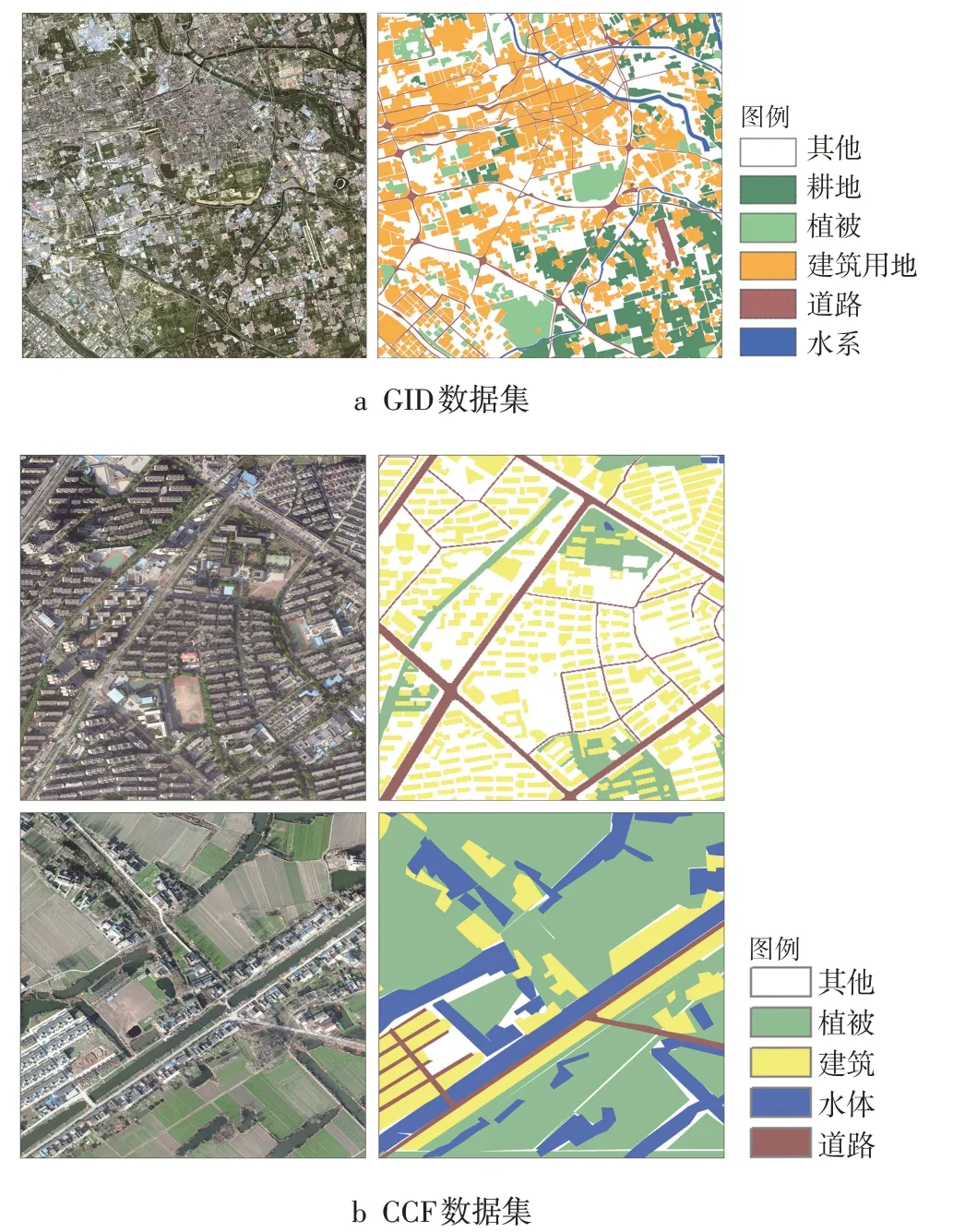
图5 数据集示例
2.2 训练样本构建
两组图像覆盖范围都比较大,空间分辨率高,图像尺寸大且不统一,直接输入整幅图像训练模型会造成内存溢出。本文以128 像素为步长、以256×256 像素为裁剪尺寸,对影像进行从左到右、从上到下的滑动窗口裁剪以获取训练样本切片数据。此外,原始数据存在类别分布不均衡问题(表1),本文去除0值像元占面积70%以上的训练切片,以平衡正负样本量。

表1 两个数据集地物分布占比
数据增强可以在数据集有限的情况下达到扩充训练数据的效果,即数据增多使得模型过拟合概率降低,增强了模型泛化能力。本文采用旋转、翻转等方法,获得GID有效样本82 264个,训练集和验证集按4∶1比例进行划分,CCF有效样本54 304个,训练集和验证集按3∶1比例进行划分。
2.3 分类精度评价
混淆矩阵是比较遥感影像分类结果与参考结果的常见统计方法,其分类精度评价指标包括总体精度(overall accuracy,OA)、精确度(Precision)、召回率(Recall)、F1值、交并比(IoU)和Kappa 系数。其中,总体精度表示正确分类的像素占总像素的比例;精确度表示在预测该类别像素中被预测正确的比例;召回率表示该类别在真实像素中被预测正确的比例;F1值为召回率和准确率的调和均值;交并比反映了实际类别样本和预测类别样本的交集和并集之比。

式中,TP是分类准确的正类;FP是被错分为正类的负类;TN是分类准确的负类;FN是被错分为负类的正类。


2.4 实验平台及参数设置
本文实验以Pytorch 为开发框架,OS 为Ubuntu,CUDA版本为11.0,显卡RTX2080TI GPU的显存11 G*8,机器内存为48 G。GID 数据集分类模型的超参数:通道 个 数 为4,类 别 数 为6,batch size 为8,epoch 为20,优化算法Adam,基础学习率0.000 3。CCF 数据集分类模型的超参数:通道个数为3,类别数为5,batch size 为8,epoch 为50,优化算法Adam,基础学习率0.001。此外,训练样本类别不平衡造成的信息失衡会对网络分类的性能产生较大影响。本文在训练过程中采用了Lovasz-Softmax[24],它是一种基于IoU 的损失函数,可有效减弱上述影响。
3 结果分析
3.1 不同语义分割网络对GF-2影像的地物分类结果比较
使用GID数据集对Deeplab v3+、UNet、SegNet和FCN8s网络进行训练并将分类结果与真值比较,得到各语义分割模型的分类结果精度指标(表2)。

表2 语义分割网络分割结果指标对比
在总体精度OA 指标上,Deeplab v3+表现最优,FCN8s 得分较低;在Kappa 系数方面,Deeplab v3+得分在0.9之上,相较UNet、SegNet FCN8s有明显优势。
图6 分别给出了测试影像完整图幅和其局部特征区域的分割结果,其中第一行图像为不同语义分割模型的完整图幅分类结果,可以看出4 个模型对大型水系均有较好的分割效果,但FCN8s模型对建筑用地的识别效果不佳;第二行影像侧重于展示各模型对桥体的提取效果,其中仅Deeplab v3+能够精准识别出细小狭长的桥体目标;第三行影像着重显示各模型对建筑用地与道路的划分效果,相较于其他三类模型,Deeplab v3+能够提取清晰的路网及建筑用地轮廓线;第四行影像侧重于比较各模型对湖泊的提取效果,其中Deeplab v3+表现最佳,能够精确的检测出湖泊边界。从整体视觉上看,相比于Deeplab v3+的优异表现,UNet、SegNet、FCN8s的分割结果不够理想,这是由于它们多次使用池化操作,损失了影像中的高频成分,丢失了位置信息,造成地物分类精度较差,且分割边界较粗糙。

图6 地物分类结果对比
图7 和表3 揭示了各模型对不同地物类型的识别能力。Deeplab v3+、UNet、SegNet都对水系有着较好的分割效果,F1值均大于0.9,这是由于水体在近红外波段与其他地物的显著差异性所致。对于道路等细小狭长线状目标,所有模型识别效果都有所降低,其原因可能在于:①道路细长的空间形态特性,使得识别不全,导致召回率较低;②道路像元数目在训练集占比很低(1.8%),稀疏样本使得训练不充分;尽管如此,Deeplab v3+提取的路网仍然最为清晰、完整;对于建筑用地、耕地等块状地物分类,Deeplab v3+的F1值分别为0.956和0.938,IoU为0.916和0.888,明显优于其他模型。同其他3种模型相比,Deeplab v3+使用扩张卷积替代连续池化,在不降低特征空间分辨率的情况下增大感受野,使得输出特征更加稠密,有效解决了高分影像地物的“同物异谱”问题。针对物体的多尺度问题,ASPP 模块以不同采样率的扩张卷积采样,多比例捕捉图像信息,提高了特征提取能力。编码-解码模块则逐步重构空间信息精确捕捉了地块边缘。
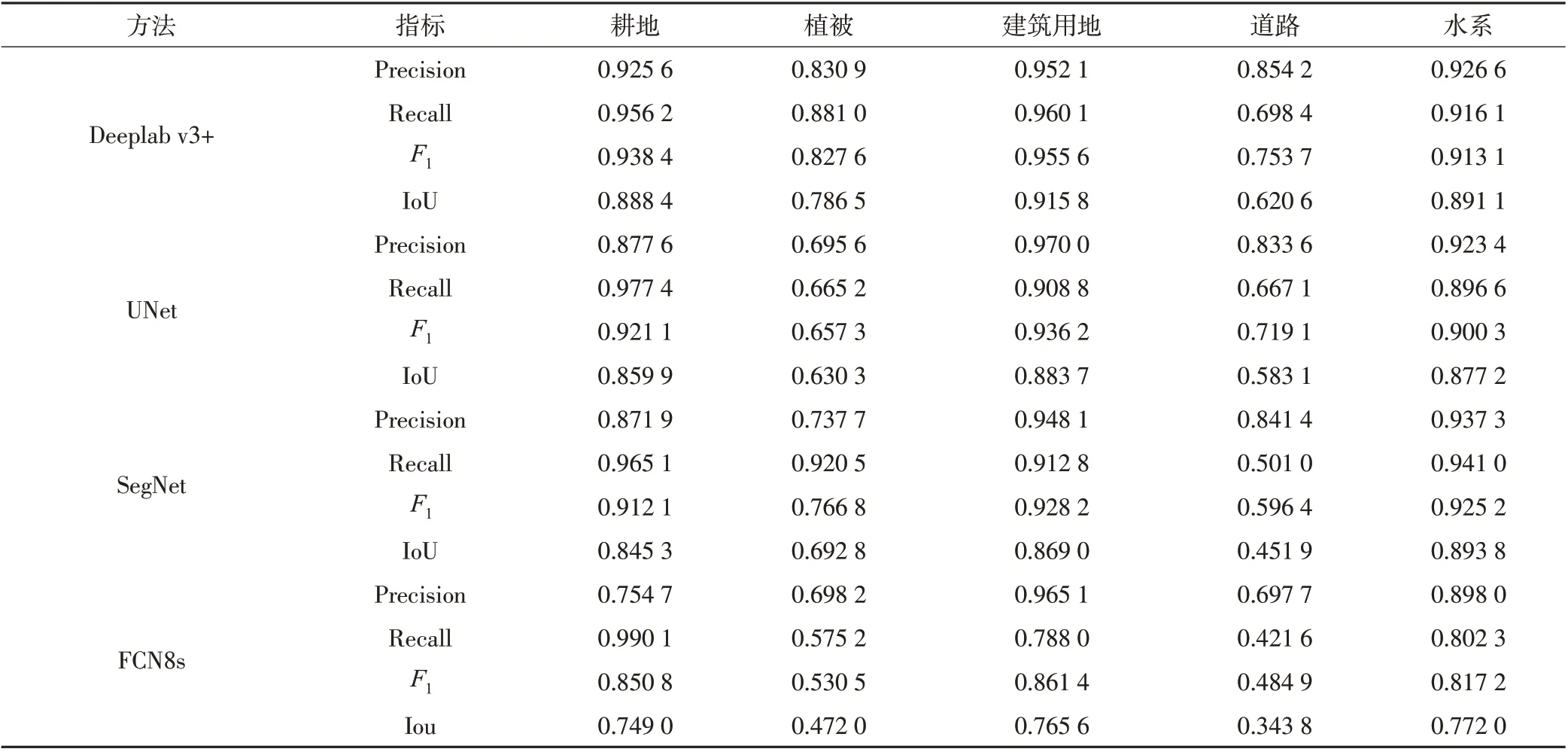
表3 各方法在不同地物类别上的分割效果
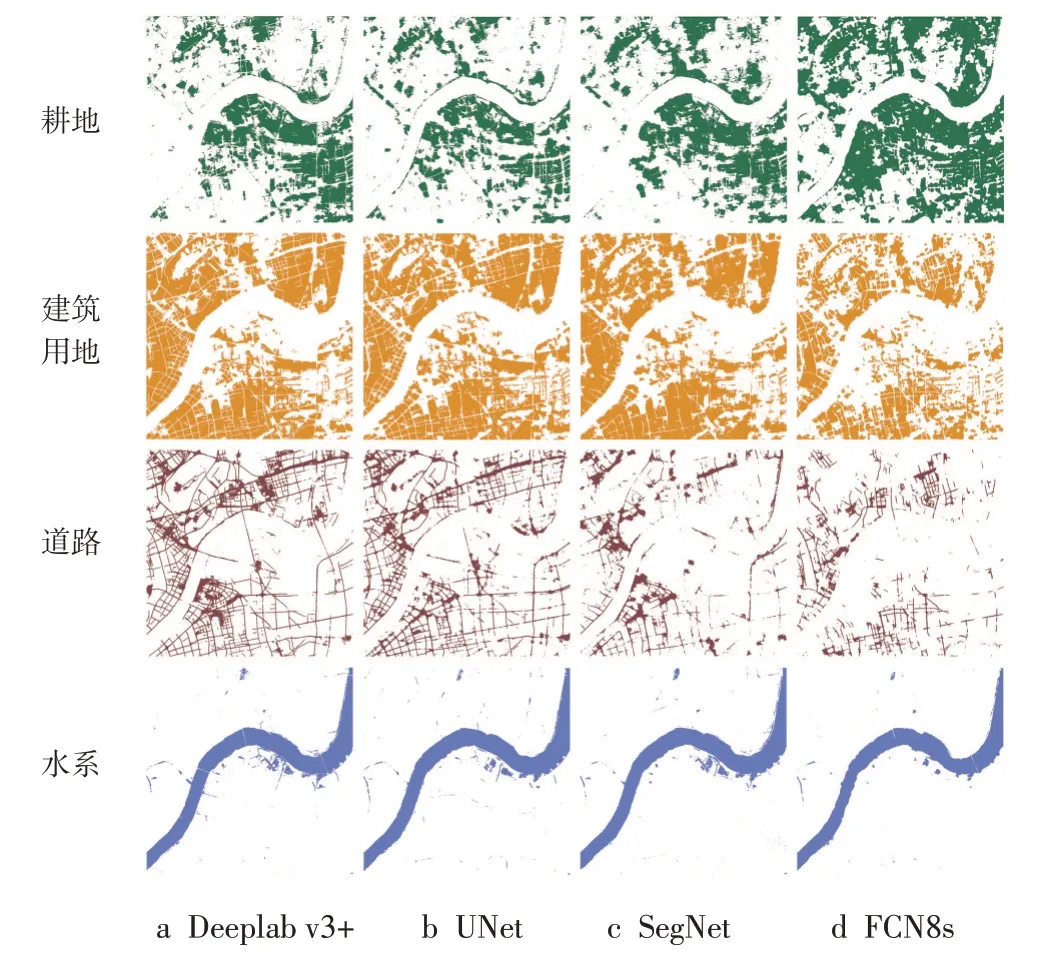
图7 不同类别地物的分类结果对比
3.2 Deeplab v3+对亚米级航拍影像地物识别的有效性分析
使用CCF数据集训练Deeplab v3+网络并进行地物分类,对比分类结果与真值,其OA、Kappa系数分别为0.88、0.82。航拍影像纹理特征突出,同类地物内部的几何结构增加了不同类别地物之间边界的识别难度。由图8 可以看出,Deeplab v3+分割结果和真实值比较接近,整体视觉上分割效果较好。具体而言,在建筑和道路主导的乡镇地区,模型对建筑边界的响应表现优异,房屋阴影影响了小部分路段识别;而对于植被(耕地)主导的农村地区,模型同样能对水体和耕地进行准确的提取,且分割边界较为平滑。
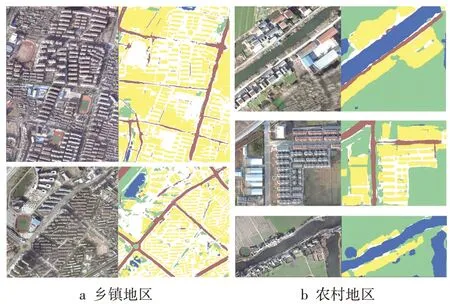
图8 Deeplab v3+在CCF数据集上的分割结果
对比Deeplab v3+模型和文献建议的分割模型[25],CCF 数据集分类的评价指标(图9)表明Deeplab v3+在对水体、道路、植被和建筑这4 种地物类型的识别上表现优异,相对其他语义分割模型取得了较高的F1值和IoU 值。总体而言,Deeplab v3+模型能够满足亚米级航拍影像的特征信息提取和影像分割需求。

图9 各模型在CCF数据集的地物分类精度评价指标
4 结 论
针对传统神经网络模型对高分辨率遥感影像分割精度不足的问题,实施了相应对措:①本文采用Deeplab v3+模型在GID 数据集上开展地物分类研究,其分类总体精度OA 和Kappa 系数分别为0.945 和0.915。与FCN、UNet、SegNet 模型的分类结果相比,Deeplab v3+能实现目标要素的完整提取,尤其是对线状目标的识别,具有较为明显的精度优势。②针对亚米级无人机遥感影像,Deeplab v3+的分类总体精度OA和Kappa 系数分别为0.88、0.82,较之其他模型能实现对遥感影像中建筑物等人工地物更准确的提取,具有较高的可靠性。本文对高分辨率遥感影像要素提取具有一定参考价值,为深度学习在高分辨率遥感影像地物分类中的应用提供了参考方案。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
电子制作(2019年11期)2019-07-04 00:34:38
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
电子制作(2018年11期)2018-08-04 03:25:38
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电子设计工程(2015年3期)2015-02-27 12:03:45
