
基于稀疏度自适应的压缩感知重构算法研究
2022-07-02 02:49:48吕冠男刘海鹏卢建宏
陕西理工大学学报(自然科学版) 2022年3期
吕冠男, 刘海鹏, 王 蒙, 卢建宏
(昆明理工大学 信息工程与自动化学院, 云南 昆明 650500)
压缩感知(Compressed Sensing,CS)[1-3]是近年来新兴的信号获取理论,它表明当一个信号是稀疏信号,或者说这个信号具有稀疏性,就可以用一个与原信号不相关的测量矩阵,以远低于奈奎斯特(Nyquist)采样率采集到的信号测量值进行压缩采样,用重构算法将压缩采样后的信号实现对原信号的高概率重建。压缩感知具有所需采样点少、数据储存量低等特点,在信号采集[4]、雷达探测、数据通信[5]等领域被广泛研究。
目前对压缩感知理论所做的研究主要集中在信号重构算法上,而贪婪算法由于其计算结果的有效性和稳定性得到广泛研究。例如,前向搜索正交匹配追踪(Look Ahead Orthogonal Matching Pursuit,LAOMP)算法[6]。
虽然LAOMP算法目前已经得到了较为广泛的应用,但是LAOMP算法是在稀疏度k已知的条件下进行的,同时选择的L个最大内积值未必是最佳值,所对应的原子索引也未必是最佳的索引值。因而通过LAR得到最小残差也未必是最小的,这就意味着可以在提升LAOMP的重构精度上做工作。因此,本文在继承LAOMP算法优点的同时,对其不足之处加以改正,提出了一种基于稀疏度自适应的回溯前向搜索正交匹配追踪(Sparsity Adaptive Backtracking Look Ahead Orthogonal Matching Pursuit,SABLAOMP)算法。SABLAOMP算法首先通过回溯策略选择能量组最大的原子集,然后将这些能量最大的原子加入到LAR中,根据残差性能选择加入支撑集的原子的个数,更新支撑集,更新残差,自适应地更新步长,使得支撑集中的原子构造更加合理,提升了重构效果。
1 算法描述
1.1 LAOMP算法
正交匹配追踪(Orthogonal Matching Pursuit,OMP)算法发展较早[6],为后面的各种同类型算法的提出奠定了基础,它继承了匹配追踪(Matching Pursuit,MP)算法在传感矩阵中挑选原子的方式,由于MP算法在进行投影时,所选用的列向量之间不具备正交性,故而任意一次迭代都可能达不到理想的结果。针对MP算法的缺点,OMP算法作出了改进,在投影之前通过正交化方法对筛选的原子进行正交处理,这样就能使反复挑选到同一个原子的概率几乎为0,从而保证了每次迭代的最优性,不仅能加快算法的收敛速度,同时还提高了重构精度。但是Saikat Chatterjee[7-9]等反复试验发现OMP算法每次进行原子选择时不一定选择了最优原子,于是在OMP算法的基础上提出了LAOMP算法。
前向搜索残差[10](Look Ahead Residual,LAR)是LAOMP筛选原子的主要手段。所谓的LAR就是在算法的迭代中,通过对未来迭代的影响来选择原子。首先,该算法选择L个与传感矩阵内积最大的原子,并将这L个原子的下标存储在一个集合;然后把这L个原子逐个放入LAR中迭代,L个原子通过前向预测会得到L个残差,残差最小的那个原子就是最佳原子;再把最佳原子加入原子集,更新残差,进行下次迭代,迭代结束,输出近似信号,完成重构。
LAOMP算法的核心就是LAR算法,具体描述如下:
输入:感知矩阵A,测量向量Y,稀疏度K,先前支撑集Ipre,新选择的原子索引t。
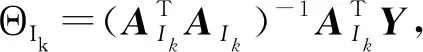
迭代过程:
1)迭代次数k=1:K;
3)更新支撑集Ik=Ipre∪tk;
5)更新残差rk=Y-AIkΘIk;
6)判断是否满足迭代停止条件‖rk‖2>‖rk-1‖2,若满足,则停止迭代,否则,重复步骤1—6。
输出:rk=Y-AIkΘIk。
LAR算法中A={aij},i∈M,j∈N,Y∈RM,t∈{1,2,…,N}。基于LAR算法中LAR的迭代过程定义前向预测残差为
r=LAR(Y,A,K,Ipre,t)。
(1)
1.2 SABLAOMP算法
虽然LAOMP算法选出的迭代原子比OMP算法选出来的质量更高,但是LAOMP算法是在稀疏度K已知的条件下进行的,同时选择的L个最大内积值未必是最佳值,所对应的原子索引也未必是最佳的索引值,因而通过LAR得到最小残差也未必是最小的;其次,当迭代多次后数个残差性能均能小于τ(定义τ作为判决残差性能趋于稳定的门限值,τ一般取10-6),如果每次仍然固定的选择L个最佳原子加入到LAR中,并且每次仍只选择一个残差值,这样就增加了迭代的次数耗费了时间。为了解决这些问题,本文提出了SABLAOMP算法,该算法在保证不失LAOMP算法优良性能的同时克服其不足之处。SABLAOMP算法首先通过回退筛选[11]的思想选择能量组最大的原子集,再通过最小二乘法求得此原子集中每个原子的重构系数θ,选出系数最大的前L个原子,并将这些原子一一加入到前向预测中,根据残差性能选择加入支撑集的原子个数,更新支撑集,更新残差,自适应的更新步长,判断是否满足终止条件,从而输出结果。
SABLAOMP算法的核心由回溯策略和LAR子算法组成。回溯策略具体操作如下:
输入:感知矩阵A,测量值y,稀疏度K。
初始化:矩阵空集A0=∅,索引集合Λ0=∅,初始残差r0=y,迭代次数t=1,索引值集合J0=∅,重构值初始化θ=0。
1)利用u=|Art-1|,求得u中K个较大的值,然后将这K个值对应的序列号j构成集合J0;
2)更新索引集Λt=Λt-1∪J0,At=At-1∪aj(其中所有的j∈J0);
4)更新集合Λt=ΛtK,并更新残差rt=y-Atθt;
5)通过判断满足‖rk‖2>‖rk-1‖2和迭代次数t≥K来输出重构系数θtK和其对应原子索引值ΛtK,否则循环(1—5)。
输出:重构系数θtK、θtK对应原子索引值ΛtK。
匹配追踪(Matching Pursuit)算法、OMP算法、正则化正交匹配追踪[12](Regularization Orthogonal Matching Pursuit,ROMP)算法以及稀疏自适应匹配追踪[13](Sparsity Adapitive Matching Pursuit,SAMP)算法、LAOMP算法等,都是通过每一次的迭代来寻找最佳原子。但是由于数据的随机不确定性,导致选出来的原子不一定是最佳原子。因此SABLAOMP算法在此基础上引入回溯策略,该算法在不需要知道信号稀疏度的情况下,选择出最大内积值所对应的若干个原子,然后在这些原子中选择出能量组最大的原子,将原子的索引值加入到支撑集中,再将这些索引值进行LAR处理。由于迭代初期处理后的残差值相差较大,因此为了得到更好的残差需要在LAR算法中迭代多次判断残差的性能,而随着迭代次数的增多,相邻内积值间的差别逐渐缩小再迭代多次已没必要,因此本论文选择的迭代次数为floor(M/L)次。随着迭代次数的增多,L也会自适应的增大,故而迭代次数就会减少,正合本文要求。如果经过LAR输出的残差值中有f个值小于τ,那么就将这f个值对应的F位置加入到支撑集,否则直接将最小的一个残差所对应的F中的位置加入支撑集,更新近似系数,更新残差,自适应的更新步长,判断是否满足终止条件,输出近似系数。具体描述如下:
输入:感知矩阵AM×N,测量矩阵YM×1,初始步长S。
初始化:近似系数Θ=0,初始残差r0=Y,支撑集I=∅,步长L=S,pos_theat=。
起始阶段:Stage=1,最大循环次数Itermax=M,迭代次数K=floor(M/L)。
迭代过程:
1)外部循环次数k=1:Itermax;
2)A的各列与残差的内积P=ATrk-1;
3)从P中选取L个具有较大能量的原子所对应的索引序号,将它们放入支撑集Jl中;
4)内部循环次数l=1:f,
a)由LAR得到残差值r=(Y,A,K,pos_theta,Jl),
b)存储残差nf=‖r‖2,
c)根据残差值的大小确定更新索引值ik的个数;
5)更新支撑集Ik=Ik-1∪ik;
7)存储支撑集pos_theta=Ik;
8)更新残差rk=Y-ΘIk;
9)若参数满足:‖rk‖2≥‖rk-1‖2或者norm(rk,2)<τ,更新步长Stage=Stage+1,L=Stage×S;
10)判断迭代停止条件k≥Itermax或者L>M。
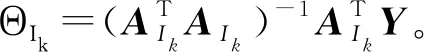
2 实验部分
以下仿真结果均在MATLAB R2017a环境下进行得到,稀疏基矩阵和观测矩阵[14-15]均选择小波变换正交基和高斯随机矩阵[16-17]。
2.1 一维试验仿真及分析
首先,为了验证本文提出的改进算法,即SABLAOMP算法,能否实现信号的高精度重构,先对其进行一维点目标重构实验,其中信号的个数设置为256,稀疏度K设定为12,测量值的个数为128,实验结果如图1所示。图中不带点的线表示原始信号,带点的线表示重构信号,在这个图中可以看出带点线和不带点线基本是重合的,且重构误差为5.532 5×10-15,算法收敛时间约为0.17 s。由此可以看出,本文算法可以实现一维信号的高精度重构。
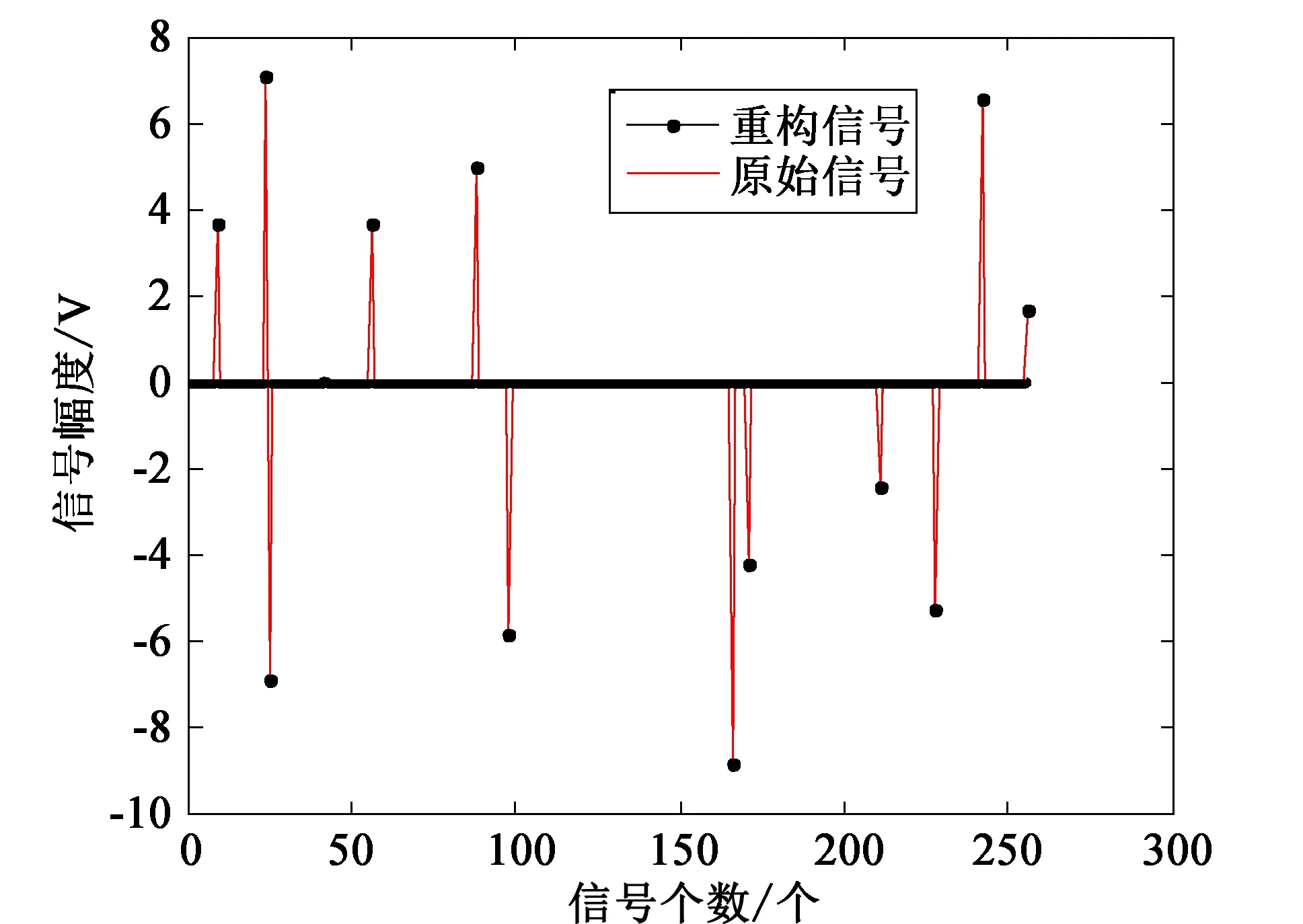
图1 SABLAOMP算法的一维重构实验
然后,在不考虑噪声的情况下,通过精确重构率(ERP)性能指标测试SABLAOMP算法的重构性能,并与OMP算法、LAOMP算法、ALAOMP算法对比。设原始信号X为长度N=700的高斯随机信号和N=500的二值信号,当X为高斯随机信号时采样率区间设为[0.1,0.2]共11个点,测量次数为200次。当X为二值信号时采样率区间设为[0.1,0.3]共11个点,测量次数为200次。由于OMP算法、LAOMP算法、ALAOMP算法需要知道信号的稀疏性,因此设稀疏度K=20,LAOMP算法的前向参数设为L=5,SABLAOMP算法的初始步长设为S≤5,判决门限τ=10-12。对比结果如图2、图3所示。
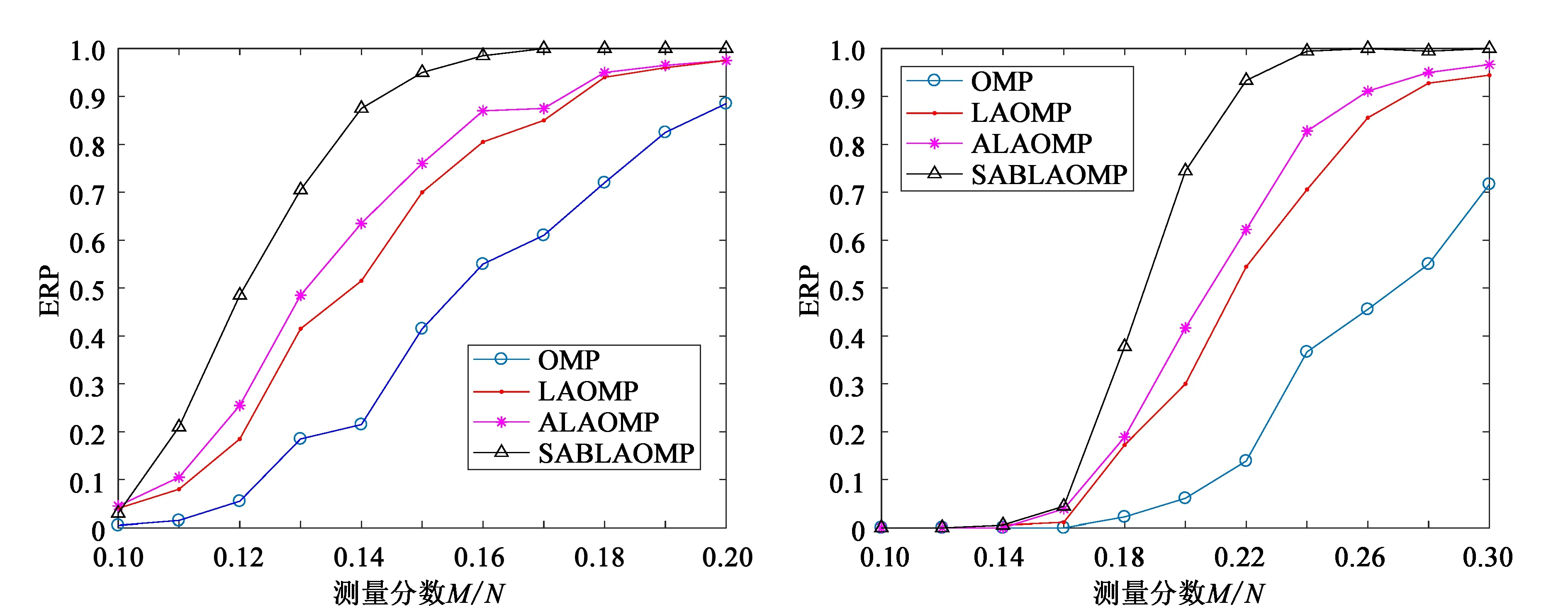
图2 高斯信号下的ERP对比图 图3 二值信号下的ERP对比图
随着压缩率的增大,4种算法的ERP均增大,但本文算法的增大效果更明显。在高斯随机信号下当采样率相同时,本文算法的ERP要比其他4种算法效果好,同时随着压缩率的增大ERP增长的更快,在采样率达到0.15时ERP就已趋近于1(见图2),优于其他3种算法。而在二值信号下,由于二值信号的二值固定性,导致采样率低于0.16时效果不明显(见图3),但当采样率高于0.16时,ERP明显上升,SABLAOMP算法的ERP在0.24时就已趋近于1,其他3种算法均未达到此效果,这充分体现了本文算法的优越性。
2.2 二维图像重构实验比较
为了进一步说明改进后算法的优良性,本文给出了OMP算法、LAOMP算法、ALAOMP算法、SABLAOMP算法在采样率分别为0.3、0.4和0.5时的二维图像重构直观视觉效果对比图。仿真结果如图4—图6所示。可以看出,对于同一张图片,随着采样率的增加图像变得越来越清晰,当采样率为0.3时图像相对来说最模糊,采样率为0.4时图像比采样率为0.3时要清晰许多,而采样率为0.5时图像最为清晰;而不论采样率为何值时,本文提出的SABLAOMP算法重构后的图像均比其他算法重构后的图像清晰。

(a)原始图像 (b)OMP重构图像 (c)LAOMP重构图像
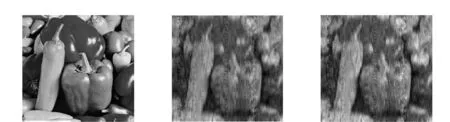
(a)原始图像 (b)OMP重构图像 (c)LAOMP重构图像

(a)原始图像 (b)OMP重构图像 (c)LAOMP重构图像
以重构图像的峰值信噪比(PSNR)和相对误差(RE)作为图像恢复质量的评判依据,不同的采样率下4种算法的结果见表1。从表中可知,当采样率固定为某个值时,SABLAOMP算法的PSNR最大,RE最小,说明SABLAOMP算法的重建质量优于其他算法;随着压缩比的增大,各算法的PSNR均增大,RE均减小,且SABLAOMP的效果最为明显,其PSNR相比于其他3种算法提高了约25%,而RE相比于其他算法减少量超过了三分之一。进一步说明的本算法的重构效果优于其他3种算法。

表1 压缩比为0.3时二维图像重建质量比较
3 结论
本文就LAOMP的不足之处进行改进,引入了回溯策略,加强了对原子的选择,提出了稀疏度自适应的回溯前向搜索正交匹配追踪算法,即SABLAOMP算法。该算法不需要知道信号的稀疏度,也不需要确定每次筛选的原子个数,只需设定初始的步长,通过回溯策略选出能量最大的若干原子,然后将这些原子加入LAR算法中判断其对最终性能的影响效果,通过判断选择残差性能满足阈值条件的若干原子加入支撑集,然后进行后续迭代,进而判断是否更新迭代步长。经过一维点目标仿真和二维图像仿真对比,发现该算法的重构质量明显优于同类算法。但是,在运行时间上SABLAOMP算法并没有做到最好。比如在一维信号重构实验中,SABLAOMP算法的运行时间约为0.17 s,OMP算法的运行时间只有大概0.06 s,ALAOMP算法的重构时间约为0.15 s,但是相比于LAOMP算法约为0.19 s的运行时间还是有所改进的。所以说,相比于LAOMP算法而言,本文提出的SABLAOMP算法在降低了运算速度的同时还提高了重构精度。但这是在运行多次求取平均值后获得的,复杂度高,速度慢,因此,如何通过在提高重构精度的同时,保证重构速度基本不变,是需要研究的一个方向。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
成都信息工程大学学报(2021年5期)2021-12-30 06:25:30
少儿科学周刊·儿童版(2021年22期)2021-12-11 21:27:59
少儿科学周刊·儿童版(2021年22期)2021-12-11 21:27:59
少儿科学周刊·儿童版(2021年22期)2021-12-11 06:42:32
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
河南科技(2015年8期)2015-03-11 16:23:52
河北科技大学学报(2015年5期)2015-03-11 16:16:37
电测与仪表(2014年2期)2014-04-04 09:04:00
