
基于SMA-LSSVM的径流中长期预测
2022-07-02 09:45田景环李丛鑫
人民珠江 2022年6期
田景环,李丛鑫,李 昂
(华北水利水电大学水利学院,河南 郑州 450046)
准确的径流预测可为防洪减灾、水资源的高效利用提供重要理论基础[1]。受诸多自然和人类活动因素的影响,径流表现出复杂的非线性过程,准确预测未来径流的趋势成为水资源领域的难点[2]。近年来,信息技术的飞速发展,极大地丰富了径流预测的研究方法[3]。以人工神经网络模型(ANN)[4-5]、支持向量机(SVM)[6-7]为代表的非线性方法在径流预测中取得了一定成效。水文时间序列普遍是非线性的小样本数据,相比于神经网络易陷入局部最优、过学习等问题[7],Vapnik[8]提出支持向量机(SVM),将学习问题转化为二次规划问题,得到全局最优解。卢敏等[9]、吴学文等[10]基于SVM建立径流预测模型,证明了SVM在径流预测表现中的优越性。最小二乘支持向量机(LSSVM)建立在SVM基础上,基于最小二乘思想构造目标函数,减少模型参数的同时[11],利用解方程组的方法缩短模型学习时间。LSSVM可以以任意精度逼近非线性系统,是解决非线性预测问题的有效方法。
LSSVM模型中的惩罚系数及核参数直接影响模型的训练结果和适应能力[12],以往对参数的选择大都人为选择确定,导致参数选取的不恰当,从而影响预测精度。随着人工智能的兴起,不断有学者采用智能算法对LSSVM模型的参数进行优化[13-14]。李文莉等[15]针对模型参数选择费时且效果差等问题,利用具有全局搜索能力的粒子群算法(PSO)参数寻优,有效提高径流的预测效率和预测精度。但此算法易陷入局部最优,搜索到局部极小值且寻优能力弱。为弥补现有算法的不足,利用LI等[16]提出的随机优化算法——黏菌算法(SMA),来确保搜索效率和准确性。鉴于黏菌算法收敛速度快、搜索能力强等特点,本文利用SMA对LSSVM模型的参数进行自动搜索获得最优解,建立SMA-LSSVM径流中长期预测模型,并选择漫湾水电站和莺落峡水文站为研究对象进行实例验证,结果表明SMA-LSSVM具有较高的预测精度,对径流预测是可行有效的。
1 研究方法及模型建立
1.1 黏菌优化算法(SMA)
1.1.1SMA描述
黏菌算法(SMA)[16]是一种基于黏菌自然振动模式的元启发式智能算法。此算法通过自适应权重使SMA在保持快速收敛的同时避免陷入局部最优,同时振动参数允许以特定的方式收缩,确保了早期的搜索效率和准确性。
黏菌在觅食过程中,根据空气中的气味浓度接近食物,食物浓度越高,生物振荡越强,细胞质流动越快,黏菌静脉管越粗。通过函数表达式来模拟其逼近行为,位置更新用式(1)表示:
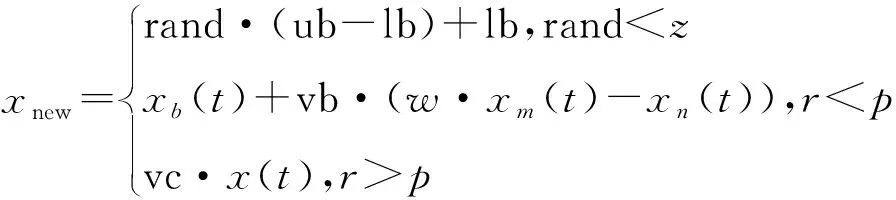
(1)
p=tanh|s(i)-DF|,i=1,2,…,k
(2)
式中 ub、lb——搜索范围的上、下界;rand——在[0,1]内的随机数;参数vb=[-a,a],参数vc从1到0线性减小;t——当前迭代;xb——当前发现食物气味浓度最高的单个位置;x——黏菌的位置;xm、xn——随机选取的2个黏菌位置;w——黏菌的重量;s(i)——x的适应度;DF——迭代中所获得的最佳适应度。
其中参数a的函数表达式为:
(3)
式中 maxt——最大迭代次数。
而w的公式见式(4):
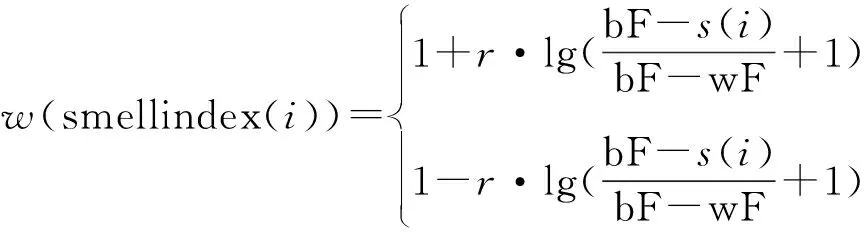
(4)
smellindex=sort(s)
(5)
式中r——[0,1]内的随机数;bF——在当前迭代过程中获得的最佳适应度;wF——在当前迭代过程中获得的最差适应度;smellindex——适应度序列。
1.1.2SMA仿真验证
为验证SMA在不同维度下的寻优能力,参考文献[14],选取Sphere、Schwefel、Rastrigin、Ackley、Griewank 5个测试函数在10、30、50、100、500维条件下对SMA进行仿真验证,并与PSO算法的仿真结果进行比较。其中单峰函数(Sphere、Schwefel)主要考察SMA、PSO的寻优速度和精度,多峰函数(Rastrigin、Ackley、Griewank)主要测试SMA、PSO的全局搜索能力。仿真测试基于Matlab 2019b对各测试函数进行20次寻优,取其平均值对算法的寻优性能进行评估,见表1。测试参数设置如下:SMA最大迭代次数为100,种群规模为50;PSO最大迭代次数为100,种群规模为50,学习因子均取2.0。
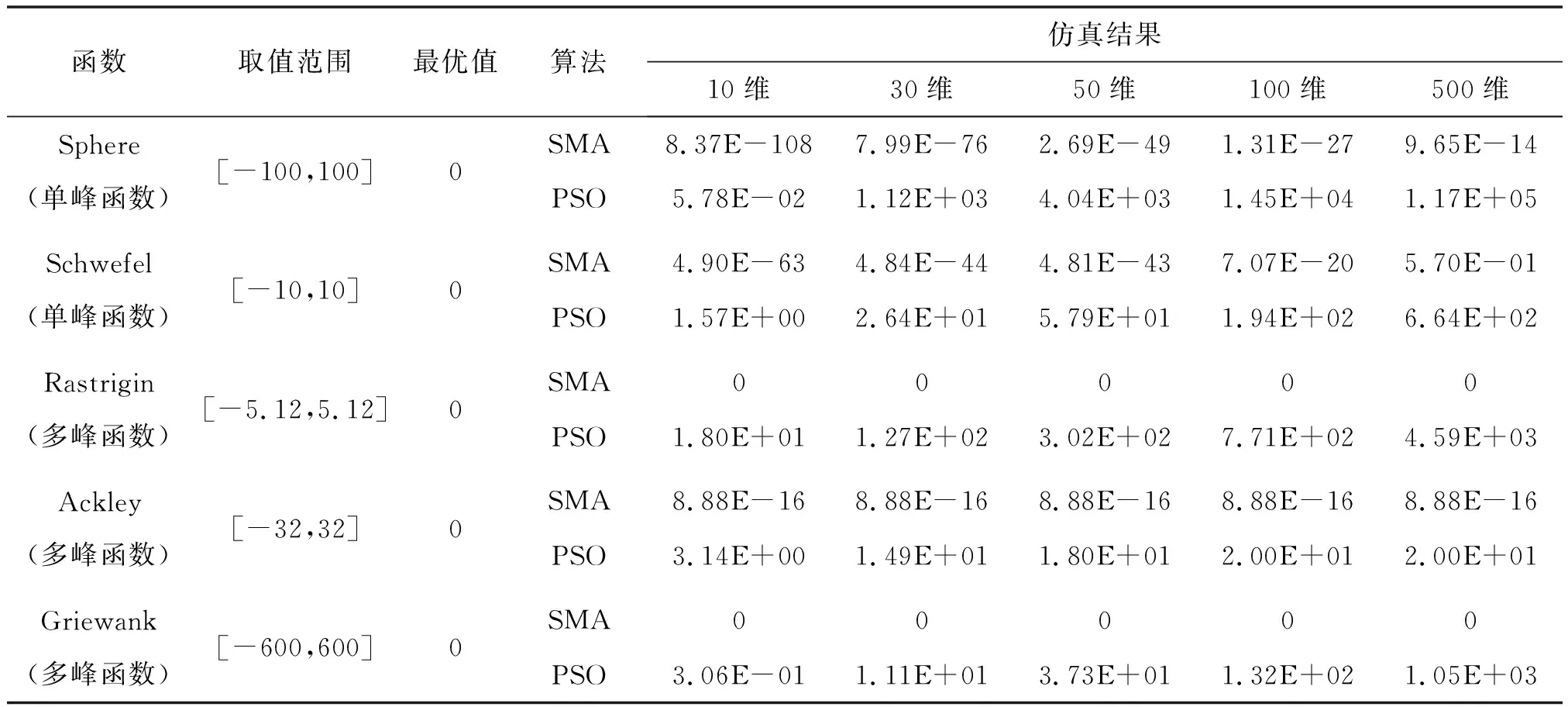
表1 函数优化对比结果
从表1可看出:对于单峰函数,SMA在不同维度条件下较PSO算法寻优精度更优;对于多峰函数Rastrigin、Griewank,SMA在不同维度条件下的20次寻优均获得了理论最优值0,说明SMA的寻优精度远优于PSO算法;对于旋转不可分函数Ackley,SMA在10、30、50、100、500维条件下趋于稳定,相比PSO算法提高了16个数量级的寻优精度。由此可见,SMA在不同维度条件下的寻优结果均优于PSO算法,表现出较好的优化效果和极值搜索能力,将其应用于LSSVM惩罚参数和核参数的寻优是可靠的。
1.2 最小二乘支持向量机
最小二乘支持向量机(Least Squares Support Vector Machine,LSSVM)由Suykens等[17]提出,是在支持向量机(SVM)上的一种改进,不仅降低计算难度,还有效提高了训练速度和精度。
根据风险结构最小化原则(SMR,Structural Risk Minimization),LSSVM的优化问题转化为带有等式约束条件的目标函数:
(6)
式中ωT——权值系数向量;γ——惩罚系数;ei——误差向量。
根据Mercer条件定义核函数:
K(mi,mj)=φ(mi)φ(mj)
(7)
式中φ(m)——核空间的非线性映射函数。
最终得到LSSVM模型的拟合函数:
(8)
式中 αi——拉格朗日乘子,≥0;b——偏差向量。
1.3 SMA-LSSVM预测模型的实现步骤
LSSVM预测模型中的惩罚参数γ和核参数σ对预测精度影响较大,选择合适的参数对预测模型的性能起着至关重要的作用。本文根据 SMA 算法在不同搜索环境下的竞争性,对最小二乘支持向量机的 2 个关键参数进行寻优,以提高模型的预测精度。SMA-LSSVM 预测模型的建模步骤如下。
步骤一参数设置。SMA算法的主要参数:黏菌种群数量N,最大迭代次数M,黏菌个体空间维度dim,黏菌种群位置上界范围ub和下界范围lb。
步骤二种群初始化。初始化黏菌空间位置,将黏菌个体的位置信息依次赋给2个参数。
步骤三更新参数。根据式(4)计算黏菌种群适应度值,并进行排序,找出当前最佳解。
步骤四更新个体位置。根据式(2)计算黏菌个体适应度值,并利用式(1)更新最优个体位置。
步骤五输出全局最优参数。根据对黏菌的所有适应度值进行排序,找出当前最优解,重复步骤二至四,当达到最大迭代次数时,终止寻优搜索,输出全局最优参数,建立SMA-LSSVM模型。
图1表示基于SMA-LSSVM的径流中长期预测的流程。
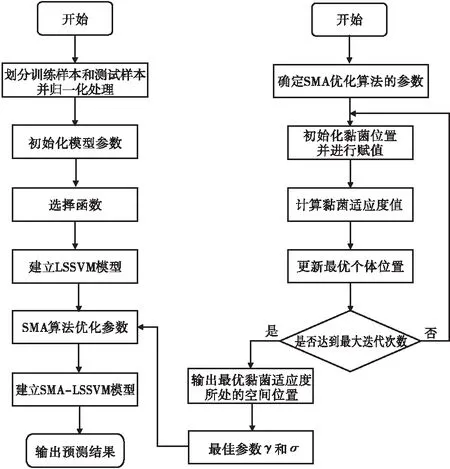
图1 基于SMA-LSSVM的径流中长期预测流程
1.4 模型性能评估
为检验中长期径流预测结果,通过均方误差(RMSE)和平均绝对百分比误差(MAPE)2个指标来对比分析。
(9)
(10)
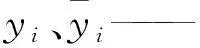
2 实例应用
为验证所提SMA-LSSVM模型的有效性和可靠性,以漫湾站和莺落峡水文站的月径流为研究对象,并分别采用80%的数据作为训练样本,20%的数据作为检验样本进行验证。
2.1 数据来源
漫湾水电站位于中国云南省西部,距昆明450 km,是澜沧江干流水电基地开发的第一座百万千瓦级的水电站。漫湾水电站坝址处的控制流域面积为11.45万km2,多年平均流量1 230 m3/s。选取漫湾站1953年1月至1994年12月的月径流数据作为模型的训练样本,1995年1月至2004年12月的月径流数据作为模型的检验样本。
黑河是中国第二大内陆河,发源于青海省祁连县,上游的莺落峡作为祁连山口的控制峡口,其控制流域面积1.000 9万km2。采用莺落峡水文站1956—2009年[18]的数据进行分析,其中1956—1998年的月径流数据用于训练模型,1999—2009年的月径流数据用于检验模型。
2.2 模型的输入和输出
根据预测结果精度,采用试错法确定模型的输入。假设实测值Q=(Q1,Q2,…Qi,…Qn-1),Qi表示第i个时刻样本点,在漫湾站实例中,采用前13个月的径流数据作为模型输入,预测第14个月的径流量,样本结构见式(11)。而在莺落峡实例中,则采用前12个月的径流数据作为模型的输入,预测第13个月的径流量,样本结构见式(12)。
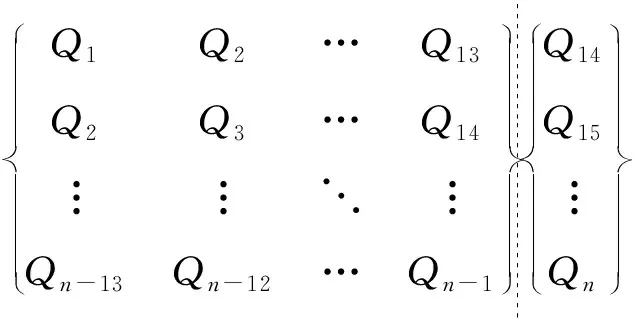
Q1Q2…Q13Q2Q3…Q14︙︙⋱︙Qn-13Qn-12…Qn-1Q14Q15︙Qn
(11)
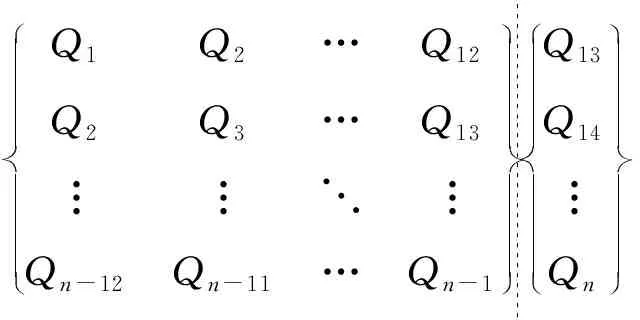
Q1Q2…Q12Q2Q3…Q13︙︙⋱︙Qn-12Qn-11…Qn-1Q13Q14︙Qn
(12)
其中式(11)、(12)前一项表示模型输入,后一项表示模型输出。
2.3 参数设置
在实际应用中,LSSVM模型的性能依赖于参数的选择,要建立最优化的模型需进行参数寻优。SMA作为一种新的随机优化算法为LSSVM的参数优化提供了新方法。由于径向基函数(RBF)的参数和受限条件相对较少,本文选择RBF作为核函数,提高训练速度。为验证SMA-LSSVM模型的预测性能和优势,建立PSO-LSSVM模型进行对比,模型的建立均基于Matlab 2019b软件下完成。
粒子群算法的参数设置为:种群规模N=50,学习因子c1=2,c2=2,最大迭代次数M=100。黏菌算法的参数设置为:种群数量N=50,最大迭代次数M=100。两算法的惩罚参数和核参数寻优范围均为[10-3,104]。寻优结果见表2。
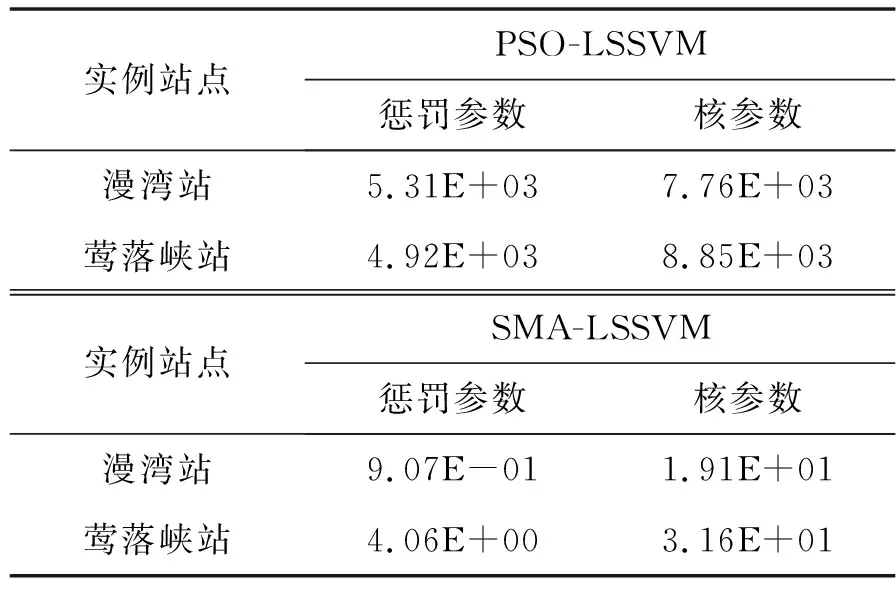
表2 2种算法优化模型参数结果
通过表2对比分析,得出SMA优化LSSVM模型参数的结果均小于PSO优化参数的结果,并结合表1中2个算法对不同函数优化的结果,认为SMA算法各方面表现均优于PSO算法。
2.4 结果分析
a)漫湾站。图2a表示SMA-LSSVM预测模型应用到漫湾站训练期的效果,图2b则表示检验期的效果。其中黑色实线代表径流实测值,蓝色实线代表LSSVM模型的预测值,绿色实线代表PSO-LSSVM模型的预测值,红色实线代表SMA-LSSVM模型的预测值。图2可看出:无论是训练期还是检验期,PSO-LSSVM模型和SMA-LSSVM模型相较于LSSVM模型的预测效果均更优,说明进行参数优化是非常必要的。图2a中PSO-LSSVM模型在个别峰值处的训练效果比SMA-LSSVM模型稍好,但总体来说,本文所提模型的预测效果更优。表3为3个模型应用到漫湾站的对比结果,更加直观看出模型间的差异。
新型消能减震复合墙板试验与模拟的骨架曲线、滞回曲线如图4所示,其试验平均值与模拟值得到的关键点数值对比见表2。由图4和表2可知,不同位移下的试验结果与有限元模拟分析结果相差很小,误差基本在20%以内,有限元模型能较好的反映构件的性能,表明数值模型基本是正确合理的。
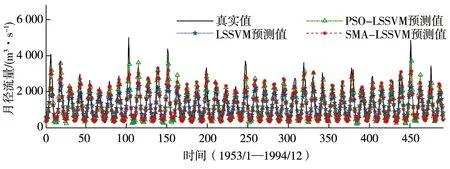
a)训练期
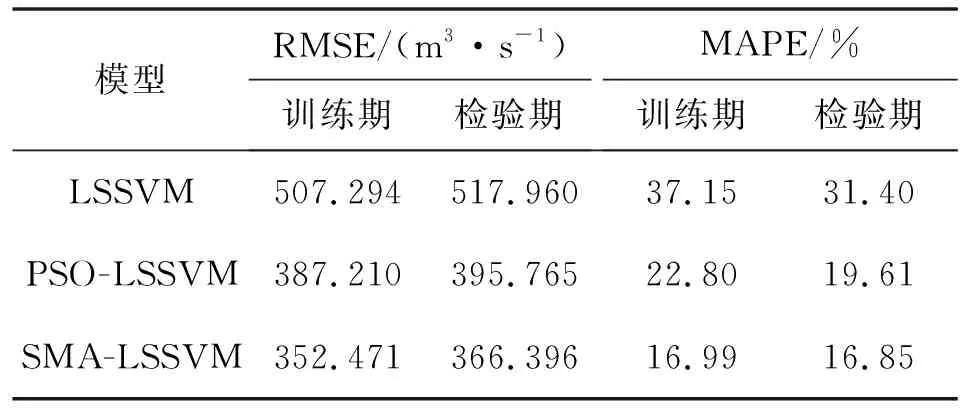
表3 漫湾站的评价指标结果对比
表3通过RMSE、MAPE 2个评价指标分析得:SMA-LSSVM模型相比LSSVM模型和PSO-LSSVM模型的RMSE在训练期分别减少30.52%和8.97%,在检验期分别减少29.26%和7.42%;MAPE在训练期分别减少54.26%和25.47%,在检验期分别减少46.36%和14.10%,进一步说明SMA-LSSVM模型的训练效果更加优越,预测结果与实测值的吻合度较高。
b)莺落峡站。为验证SMA-LSSVM模型的预测精度和泛化能力在不同地区的适用性,将上述所提模型应用于莺落峡水文站,图3为SMA-LSSVM预测模型应用于莺落峡水文站训练期和检验期的效果,表4为莺落峡水文站不同模型训练期和检验期的预测对比结果。
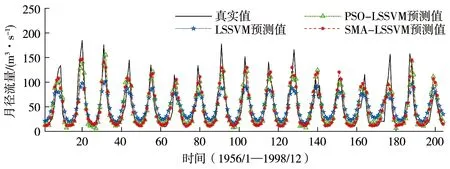
a)训练期
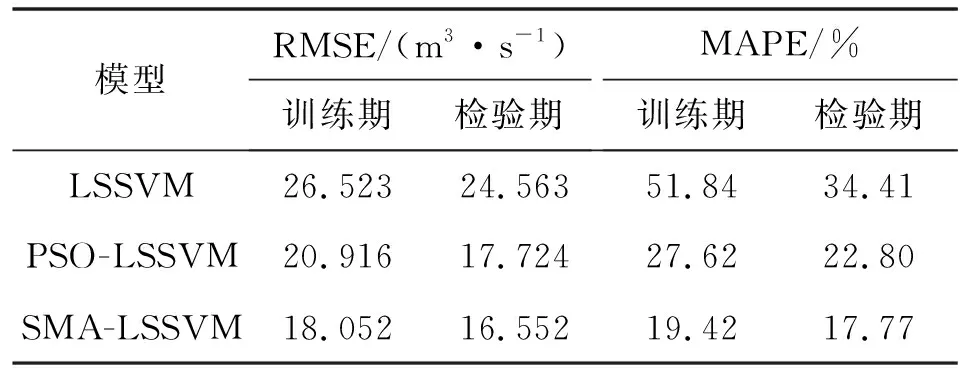
表4 莺落峡站的评价指标结果对比
通过图3及表4可得出以下结论:①SMA-LSSVM模型对实例预测的RMSE为16.552 m3/s,MAPE为17.77%,预测精度和泛化能力均优于其他模型,表明SMA能有效寻优LSSVM模型的惩罚参数和核参数,SMA-LSSVM模型用于月径流预测是可靠的;②SMA-LSSVM模型较LSSVM模型的RMSE、MAPE分别减少32.61%、48.37%,说明利用SMA优化LSSVM的关键参数可以有效提高LSSVM模型的预测精度和泛化能力;③对于同一模型采用不同的优化算法(PSO、SMA),发现LSSVM模型经过SMA参数寻优后能有效提高预测精度。
通过上述实例可知,参数寻优能充分挖掘模型本身特性,以达到模型最优性能。本文所提模型相比LSSVM模型和PSO-LSSVM模型在径流预测中具有更好的预测效果,为提高月径流预测精度提供新方法。
3 结论
利用黏菌算法(SMA),提出SMA与LSSVM相结合的径流预测模型,通过云南省漫湾水电站和黑河流域莺落峡水文站的月径流实例对模型进行验证,并与LSSVM、PSO-LSSVM模型的预测结果进行对比,得出以下结论。
a)利用5个仿真测试函数对SMA、PSO算法进行仿真测试,证明了SMA算法在不同维度条件下的寻优精度和全局搜索能力均优于PSO算法,将其应用到LSSVM惩罚参数和核参数寻优是可行的。
b)利用SMA优化LSSVM模型的关键参数,有效避免人为选择LSSVM模型参数所造成的误差,使LSSVM模型的预测精度得到较大提高。并通过2个水文站的月径流预测实例验证了SMA-LSSVM模型相比LSSVM和PSO-LSSVM模型误差更小,表明本文所提模型具有更强的泛化能力和更高的预测精度。
猜你喜欢
水利水电快报(2022年8期)2022-11-23
导航定位学报(2022年5期)2022-10-13
水力发电(2022年8期)2022-10-12
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
黑龙江大学自然科学学报(2022年1期)2022-03-29
绿色科技(2016年18期)2017-01-18
太空探索(2016年7期)2016-07-10
